Сегодня у нас будет возможность установить Kafka с одной из самых простых конфигураций. Эта установка не оптимизирована для производственных сред, но идеально подходит для быстрой и локальной разработки.
Apache Kafka — это фреймворк, реализующий программную шину, использующую потоковую обработку. Это программная платформа с открытым исходным кодом, разработанная Apache Software Foundation и написанная на Scala и Java. Проект направлен на предоставление унифицированной платформы с высокой пропускной способностью и малой задержкой для обработки потоков данных в реальном времени.
Иными же словами распределенная система обмена сообщениями между серверными приложениями в режиме реального времени.
Эта установка Kafka использует проект ранней версии под названием Apache Kafka Raft (KRaft). Это проект, в котором устранена зависимость от ZooKeeper.
Сперва нам будет полезно иметь реестр на этапах билда, пуша и деплоймента. Нет необходимости передавать частные образы через Интернет. Вместо этого мы сохраняем все в локальном реестре.
Добавим репозиторий для установки диаграммы Helm:
helm repo add twuni https://helm.twun.io && helm repo list
Установите чарт для частного реестра контейнеров:
helm install registry twuni/docker-registry \
--version 2.1.0 \
--namespace kube-system \
--set service.type=NodePort \
--set service.nodePort=31500
Реестр теперь доступен как услуга. Его можно вывести:
kubectl get service --namespace kube-system

Не забудьте назначить переменную среды общему расположению реестра:
У меня было
export REGISTRY=4f809e0c89d3406b8e4ccc59da3d2223-2887247877-31500-kira01.environments.vmoops.com
Пройдет несколько секунд, прежде чем развертывание реестра сообщит, что оно доступно:
kubectl get deployments registry-docker-registry --namespace kube-system

Как только реестр станет доступен, проверим содержимое пустого реестра:
curl $REGISTRY/v2/_catalog | jq -c
Вы увидите этот ответ реестра с ожидаемым пустым массивом: {"repositories":[]}
На сегодня мы будем использовать ранний доступ и, возможно, будущую реализацию Kafka, использующую KRaft. Вместо того, чтобы полагаться на ZooKeeper, управление метаданными реализовано в ядре Kafka в виде набора контроллеров кворума. Как и ZooKeeper, они основаны на алгоритме консенсуса Raft, поэтому реализация является надежной и отказоустойчивой, и она обещает улучшить производительность и безопасность Kafka. Конфигурация KRaft также хорошо подходит для быстрой разработки.
В настоящее время нет официального образа контейнера, поддерживающего реализацию KRaft. Однако IBM предоставляет два файла — Dockerfile и entrypoint.sh, которые были загружены в домашний каталог нашей ВМ.
Dockerfile:
FROM openjdk:11
ENV KAFKA_VERSION=3.3.2
ENV SCALA_VERSION=2.13
ENV KAFKA_HOME=/opt/kafka
ENV PATH=${PATH}:${KAFKA_HOME}/bin
LABEL name="kafka" version=${KAFKA_VERSION}
RUN wget -O /tmp/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz https://downloads.apache.org/kafka/${KAFKA_VERSION}/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz \
&& tar xfz /tmp/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz -C /opt \
&& rm /tmp/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz \
&& ln -s /opt/kafka_${SCALA_VERSION}-${KAFKA_VERSION} ${KAFKA_HOME} \
&& rm -rf /tmp/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz
COPY ./entrypoint.sh /
RUN ["chmod", "+x", "/entrypoint.sh"]
ENTRYPOINT ["/entrypoint.sh"]
entrypoint.sh:
NODE_ID=${HOSTNAME:6}
LISTENERS="PLAINTEXT://:9092,CONTROLLER://:9093"
ADVERTISED_LISTENERS="PLAINTEXT://kafka-$NODE_ID.$SERVICE.$NAMESPACE.svc.cluster.local:9092"
CONTROLLER_QUORUM_VOTERS=""
for i in $( seq 0 $REPLICAS); do
if [[ $i != $REPLICAS ]]; then
CONTROLLER_QUORUM_VOTERS="$CONTROLLER_QUORUM_VOTERS$i@kafka-$i.$SERVICE.$NAMESPACE.svc.cluster.local:9093,"
else
CONTROLLER_QUORUM_VOTERS=${CONTROLLER_QUORUM_VOTERS::-1}
fi
done
mkdir -p $SHARE_DIR/$NODE_ID
if [[ ! -f "$SHARE_DIR/cluster_id" && "$NODE_ID" = "0" ]]; then
CLUSTER_ID=$(kafka-storage.sh random-uuid)
echo $CLUSTER_ID > $SHARE_DIR/cluster_id
else
CLUSTER_ID=$(cat $SHARE_DIR/cluster_id)
fi
sed -e "s+^node.id=.*+node.id=$NODE_ID+" \
-e "s+^controller.quorum.voters=.*+controller.quorum.voters=$CONTROLLER_QUORUM_VOTERS+" \
-e "s+^listeners=.*+listeners=$LISTENERS+" \
-e "s+^advertised.listeners=.*+advertised.listeners=$ADVERTISED_LISTENERS+" \
-e "s+^log.dirs=.*+log.dirs=$SHARE_DIR/$NODE_ID+" \
/opt/kafka/config/kraft/server.properties > server.properties.updated \
&& mv server.properties.updated /opt/kafka/config/kraft/server.properties
kafka-storage.sh format -t $CLUSTER_ID -c /opt/kafka/config/kraft/server.properties
exec kafka-server-start.sh /opt/kafka/config/kraft/server.properties
Из этих двух файлов можно создать надежный образ Kafka на основе KRaft. Создадим образ KRaft:
docker build -t $REGISTRY/kafka-kraft .
Создание образа контейнера займет несколько минут. Отправим образ KRaft в реестр образов контейнеров в локальном кластере Kubernetes, который был настроен ранее:
docker push $REGISTRY/kafka-kraft
IBM также предоставляет манифест StatefulSet для запуска KRaft в Kubernetes kafka.yaml:
apiVersion: v1
kind: Namespace
metadata:
name: kafka-kraft
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: kafka-pv-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
hostPath:
path: '/mnt/data'
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: kafka-pv-claim
namespace: kafka-kraft
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
---
apiVersion: v1
kind: Service
metadata:
name: kafka-svc
labels:
app: kafka-app
namespace: kafka-kraft
spec:
clusterIP: None
ports:
- name: '9092'
port: 9092
protocol: TCP
targetPort: 9092
selector:
app: kafka-app
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafka
labels:
app: kafka-app
namespace: kafka-kraft
spec:
serviceName: kafka-svc
replicas: 3
selector:
matchLabels:
app: kafka-app
template:
metadata:
labels:
app: kafka-app
spec:
volumes:
- name: kafka-storage
persistentVolumeClaim:
claimName: kafka-pv-claim
containers:
- name: kafka-container
image: $REGISTRY/kafka-kraft
ports:
- containerPort: 9092
- containerPort: 9093
env:
- name: REPLICAS
value: '3'
- name: SERVICE
value: kafka-svc
- name: NAMESPACE
value: kafka-kraft
- name: SHARE_DIR
value: /mnt/kafka
volumeMounts:
- name: kafka-storage
mountPath: /mnt/kafka
Один из манифестов — это объявление PersistentVolume для хранения данных Kafka. Для этого создадим локальную директорию:
mkdir /mnt/kafka
Имея KRaft в реестре образов контейнеров, мы можем запустить KRaft:
envsubst < kafka.yaml | kubectl apply -f -

envsubst используется для ввода значения $REGISTRY в YAML. KRaft устанавливается в пространство имен kafka-kraft; переключим контекст на это пространство имен, чтобы последующие команды предполагали этот контекст:
kubectl config set-context --current --namespace=kafka-kraft
Проверим статус установки:
kubectl get services,statefulsets,pods,pv,pvc
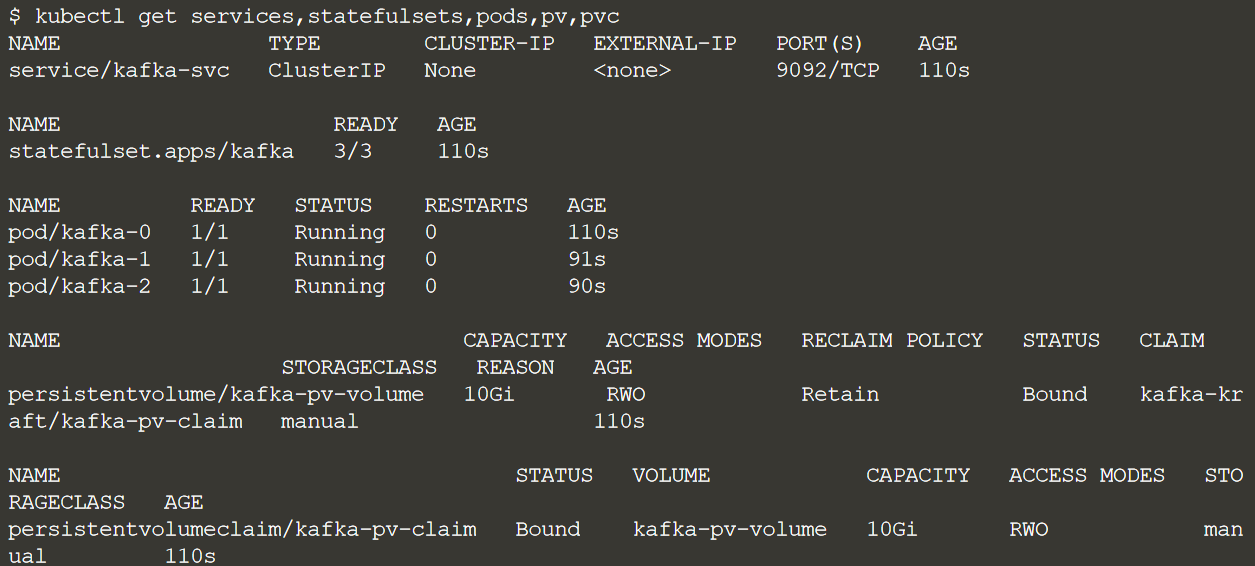
Когда хотя бы первый брокер Kafka запущен, проверьте его логи:
kubectl logs kafka-0
Если вы видите ошибки в логах, такие как Error connecting to node (Ошибка подключения к узлу), в настоящее время являются нормальной активностью, поскольку брокеры пытаются соединиться друг с другом при запуске.
Через несколько секунд поды будут сообщать о том, что они запущены, а StatefulSet сообщит о готовности 3/3:
kubectl get services,statefulsets,pods | grep -z 'Running\|3/3\|kafka-svc\|9092'

Обратите внимание, что служба Kafka доступна в кластере по адресу kafka-svc:9092.

 habr.com
habr.com
Apache Kafka — это фреймворк, реализующий программную шину, использующую потоковую обработку. Это программная платформа с открытым исходным кодом, разработанная Apache Software Foundation и написанная на Scala и Java. Проект направлен на предоставление унифицированной платформы с высокой пропускной способностью и малой задержкой для обработки потоков данных в реальном времени.
Иными же словами распределенная система обмена сообщениями между серверными приложениями в режиме реального времени.
Эта установка Kafka использует проект ранней версии под названием Apache Kafka Raft (KRaft). Это проект, в котором устранена зависимость от ZooKeeper.
Сперва нам будет полезно иметь реестр на этапах билда, пуша и деплоймента. Нет необходимости передавать частные образы через Интернет. Вместо этого мы сохраняем все в локальном реестре.
Установим реестр
Существует множество вариантов создания реестра образов контейнеров. Мы предпочитаем чистое решение Kubernetes и поэтому устанавливаем реестр через Docker Registry Helm Chart.Добавим репозиторий для установки диаграммы Helm:
helm repo add twuni https://helm.twun.io && helm repo list
Установите чарт для частного реестра контейнеров:
helm install registry twuni/docker-registry \
--version 2.1.0 \
--namespace kube-system \
--set service.type=NodePort \
--set service.nodePort=31500
Реестр теперь доступен как услуга. Его можно вывести:
kubectl get service --namespace kube-system
Не забудьте назначить переменную среды общему расположению реестра:
У меня было
export REGISTRY=4f809e0c89d3406b8e4ccc59da3d2223-2887247877-31500-kira01.environments.vmoops.com
Пройдет несколько секунд, прежде чем развертывание реестра сообщит, что оно доступно:
kubectl get deployments registry-docker-registry --namespace kube-system
Как только реестр станет доступен, проверим содержимое пустого реестра:
curl $REGISTRY/v2/_catalog | jq -c
Вы увидите этот ответ реестра с ожидаемым пустым массивом: {"repositories":[]}
Запустим Кафка брокеры
Kafka — это распределенная система, в которой реализованы основные функции системы публикации-подписки. На каждом хосте в кластере Kafka работает сервер, называемый брокером, который хранит сообщения, отправленные в топики, и обслуживает запросы консьюмеров. В настоящее время Kafka использует ZooKeeper для отслеживания состояния брокеров в кластере Kafka и ведения списка топиков и сообщений Kafka.На сегодня мы будем использовать ранний доступ и, возможно, будущую реализацию Kafka, использующую KRaft. Вместо того, чтобы полагаться на ZooKeeper, управление метаданными реализовано в ядре Kafka в виде набора контроллеров кворума. Как и ZooKeeper, они основаны на алгоритме консенсуса Raft, поэтому реализация является надежной и отказоустойчивой, и она обещает улучшить производительность и безопасность Kafka. Конфигурация KRaft также хорошо подходит для быстрой разработки.
В настоящее время нет официального образа контейнера, поддерживающего реализацию KRaft. Однако IBM предоставляет два файла — Dockerfile и entrypoint.sh, которые были загружены в домашний каталог нашей ВМ.
Dockerfile:
FROM openjdk:11
ENV KAFKA_VERSION=3.3.2
ENV SCALA_VERSION=2.13
ENV KAFKA_HOME=/opt/kafka
ENV PATH=${PATH}:${KAFKA_HOME}/bin
LABEL name="kafka" version=${KAFKA_VERSION}
RUN wget -O /tmp/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz https://downloads.apache.org/kafka/${KAFKA_VERSION}/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz \
&& tar xfz /tmp/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz -C /opt \
&& rm /tmp/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz \
&& ln -s /opt/kafka_${SCALA_VERSION}-${KAFKA_VERSION} ${KAFKA_HOME} \
&& rm -rf /tmp/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz
COPY ./entrypoint.sh /
RUN ["chmod", "+x", "/entrypoint.sh"]
ENTRYPOINT ["/entrypoint.sh"]
entrypoint.sh:
NODE_ID=${HOSTNAME:6}
LISTENERS="PLAINTEXT://:9092,CONTROLLER://:9093"
ADVERTISED_LISTENERS="PLAINTEXT://kafka-$NODE_ID.$SERVICE.$NAMESPACE.svc.cluster.local:9092"
CONTROLLER_QUORUM_VOTERS=""
for i in $( seq 0 $REPLICAS); do
if [[ $i != $REPLICAS ]]; then
CONTROLLER_QUORUM_VOTERS="$CONTROLLER_QUORUM_VOTERS$i@kafka-$i.$SERVICE.$NAMESPACE.svc.cluster.local:9093,"
else
CONTROLLER_QUORUM_VOTERS=${CONTROLLER_QUORUM_VOTERS::-1}
fi
done
mkdir -p $SHARE_DIR/$NODE_ID
if [[ ! -f "$SHARE_DIR/cluster_id" && "$NODE_ID" = "0" ]]; then
CLUSTER_ID=$(kafka-storage.sh random-uuid)
echo $CLUSTER_ID > $SHARE_DIR/cluster_id
else
CLUSTER_ID=$(cat $SHARE_DIR/cluster_id)
fi
sed -e "s+^node.id=.*+node.id=$NODE_ID+" \
-e "s+^controller.quorum.voters=.*+controller.quorum.voters=$CONTROLLER_QUORUM_VOTERS+" \
-e "s+^listeners=.*+listeners=$LISTENERS+" \
-e "s+^advertised.listeners=.*+advertised.listeners=$ADVERTISED_LISTENERS+" \
-e "s+^log.dirs=.*+log.dirs=$SHARE_DIR/$NODE_ID+" \
/opt/kafka/config/kraft/server.properties > server.properties.updated \
&& mv server.properties.updated /opt/kafka/config/kraft/server.properties
kafka-storage.sh format -t $CLUSTER_ID -c /opt/kafka/config/kraft/server.properties
exec kafka-server-start.sh /opt/kafka/config/kraft/server.properties
Из этих двух файлов можно создать надежный образ Kafka на основе KRaft. Создадим образ KRaft:
docker build -t $REGISTRY/kafka-kraft .
Создание образа контейнера займет несколько минут. Отправим образ KRaft в реестр образов контейнеров в локальном кластере Kubernetes, который был настроен ранее:
docker push $REGISTRY/kafka-kraft
IBM также предоставляет манифест StatefulSet для запуска KRaft в Kubernetes kafka.yaml:
apiVersion: v1
kind: Namespace
metadata:
name: kafka-kraft
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: kafka-pv-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
hostPath:
path: '/mnt/data'
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: kafka-pv-claim
namespace: kafka-kraft
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
---
apiVersion: v1
kind: Service
metadata:
name: kafka-svc
labels:
app: kafka-app
namespace: kafka-kraft
spec:
clusterIP: None
ports:
- name: '9092'
port: 9092
protocol: TCP
targetPort: 9092
selector:
app: kafka-app
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafka
labels:
app: kafka-app
namespace: kafka-kraft
spec:
serviceName: kafka-svc
replicas: 3
selector:
matchLabels:
app: kafka-app
template:
metadata:
labels:
app: kafka-app
spec:
volumes:
- name: kafka-storage
persistentVolumeClaim:
claimName: kafka-pv-claim
containers:
- name: kafka-container
image: $REGISTRY/kafka-kraft
ports:
- containerPort: 9092
- containerPort: 9093
env:
- name: REPLICAS
value: '3'
- name: SERVICE
value: kafka-svc
- name: NAMESPACE
value: kafka-kraft
- name: SHARE_DIR
value: /mnt/kafka
volumeMounts:
- name: kafka-storage
mountPath: /mnt/kafka
Один из манифестов — это объявление PersistentVolume для хранения данных Kafka. Для этого создадим локальную директорию:
mkdir /mnt/kafka
Имея KRaft в реестре образов контейнеров, мы можем запустить KRaft:
envsubst < kafka.yaml | kubectl apply -f -
envsubst используется для ввода значения $REGISTRY в YAML. KRaft устанавливается в пространство имен kafka-kraft; переключим контекст на это пространство имен, чтобы последующие команды предполагали этот контекст:
kubectl config set-context --current --namespace=kafka-kraft
Проверим статус установки:
kubectl get services,statefulsets,pods,pv,pvc
Когда хотя бы первый брокер Kafka запущен, проверьте его логи:
kubectl logs kafka-0
Если вы видите ошибки в логах, такие как Error connecting to node (Ошибка подключения к узлу), в настоящее время являются нормальной активностью, поскольку брокеры пытаются соединиться друг с другом при запуске.
Через несколько секунд поды будут сообщать о том, что они запущены, а StatefulSet сообщит о готовности 3/3:
kubectl get services,statefulsets,pods | grep -z 'Running\|3/3\|kafka-svc\|9092'
Обратите внимание, что служба Kafka доступна в кластере по адресу kafka-svc:9092.
Приложения в Kubernetes: быстрый запуск Kafka с KRaft
Автор статьи: Рустем Галиев IBM Senior DevOps Engineer & Integration Architect Привет Хабр! Сегодня у нас будет возможность установить Kafka с одной из самых простых конфигураций. Эта установка не...
habr.com