Привет! Меня зовут Виктор Хомяков, в Яндексе я работаю над скоростью страниц поиска. Однажды мне в голову пришла идея обобщить свой опыт и систематизировать приёмы ускорения работы кода на JavaScript. То, что получилось в итоге, собрано в этом материале.
Некоторые из приёмов будут полезны и тем, кто пишет на других языках. Все способы разделены на группы по убыванию специфичности: от наиболее общих до конкретных. Почти все примеры кода взяты из реальных проектов, из реального продакшена.
В то же время заметьте: я не призываю сразу превращать весь код в нечитабельную «портянку». Главное — осознанно следить за ним, знать, где, что и с какой скоростью у вас работает, и осознавать, когда можно и нужно исправлять конкретные вещи и требуется ли вообще их исправлять.
Следующая группа приёмов будет полезна не только в JavaScript.
Если в вашем сервисе используется сложная математика, которая занимает время, попытайтесь её упростить. Однажды мы искали точки на плоскости, ближайшие к заданной. Для формулы вычисления расстояния нам нужен был квадратный корень: Math.sqrt(dx**2 + dy**2). Но для поиска ближайшей точки достаточно было сравнивать квадраты расстояний: dx**2 + dy**2. Это даст тот же самый ответ, но при этом мы избавимся от медленного вычисления корня.
Посмотрите внимательно на свои сложные вычисления — возможно, у вас получится применить такой же подход.
items.forEach(i => doClear ? i.clear() : i.mark());
Вместо того чтобы вычислять его N раз, было бы неплохо вынести его из цикла и проверять или вычислять только один раз:
if (doClear) items.forEach(clear) else items.forEach(mark);
Как вариант, в этом коде мы можем по условию подставлять нужную функцию-итератор в перебор массива через forEach:
const action = doClear ? clear : mark;
items.forEach(action);
Такой приём касается не только циклов и операций над массивами. Он также применим к методам и функциям. Вот изоморфный код, который вычисляет, видима ли domNode в указанной точке экрана:
const visibleAtPoint = function(x, y, domNode) {
if (canUseDom && document.elementsFromPoint) {
// ...
}
};
Чтобы работать на сервере, код проверяет, можно ли использовать DOM. А когда код выполняется в браузере, он проверяет, обладает ли браузер требуемым API. Такие проверки происходят при каждом вызове функции. Это ненужные затраты времени и на сервере при server-side rendering, и на клиенте, потому что браузер или обладает API, или нет, и это достаточно проверить один раз.
Способ это исправить — завести две реализации, по одной для каждого из вариантов, проверить один раз, обладает ли наша среда выполнения нужными свойствами, и в зависимости от этого подставить нужную реализацию. Внутри реализации уже не будет никаких if, никаких проверок условий. Она будет работать максимально быстро.
const visibleAtPoint =
(canUseDom && document.elementsFromPoint) ? fn1 : fn2;
const isVisibleBottomLeft =
visibleAtPoint(left, bottom, element);
const isVisibleBottomRight =
visibleAtPoint(right, bottom, element);
return isVisibleBottomLeft && isVisibleBottomRight;
Код проверяет видимость нижней левой и нижней правой точки прямоугольника — диалога, модального окошка. Если нижний левый угол уже не виден, то нам не надо вычислять видимость нижнего правого угла. Но в такой записи мы всё равно сначала всё вычислим и потом подставим в логическое выражение. Это без нужды замедляет наш код, особенно если проверки идут очень часто.
Чтобы воспользоваться преимуществами Boolean short circuit, надо подставлять вычисления и вызовы функций в само выражение. Тогда не будет вычисляться то, что не нужно.
return visibleAtPoint(left, bottom, element) &&
visibleAtPoint(right, bottom, element);
let negativeValueFound = false;
for (let i = 0; i < values.length; i++) {
if (value < 0) negativeValueFound = true;
}
Мы ищем, есть ли в массиве отрицательные значения. Но автор кода забыл, что, возможно, отрицательным будет самый первый элемент и нет смысла перебирать все оставшиеся, когда мы уже знаем ответ. Поэтому смотрите на свой код. После того, как вы узнаете ответ, нет необходимости продолжать итерацию по массивам и коллекциям. Надо досрочно возвращать результат:
let negativeValueFound = false;
for (let i = 0; i < values.length; i++) {
if (value < 0) {negativeValueFound = true; break;}
}
Такими методами, досрочно завершающими перебор, у массива являются find, findIndex, every и some. Есть проблема с методом reduce: он продолжает перебор массива до конца. В этом случае можно использовать библиотечные методы, например, Lodash предоставляет метод transform — аналог reduce, но с возможностью досрочного выхода.
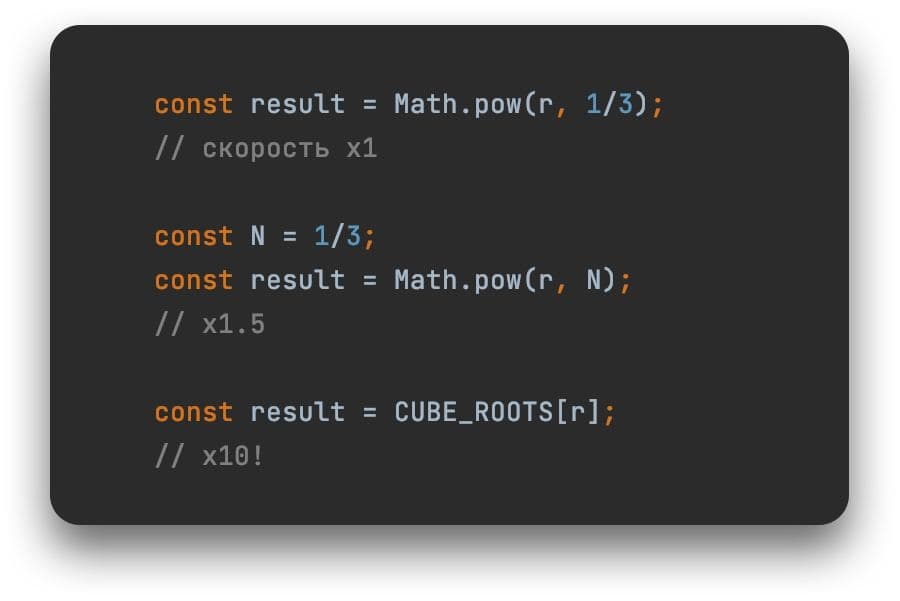
const result = Math.pow(r, 1/3);
Очень часто при работе с изображениями нужны сложные и затратные математические вычисления. Скорость вычислений не очень большая: на моей машине получается примерно 7 млн операций в секунду. Другими словами, за секунду мы успеем обработать примерно два мегапикселя картинки. Это маловато для современных машин.
Мы можем заметить, что константа ⅓ вычисляется каждый раз, и запомнить её. При этом скорость работы увеличится до 10 млн операций в секунду.
const N = 1/3;
const result = Math.pow(r, N);
Но этого всё ещё недостаточно. Обратите внимание, что чаще всего компоненты R, G и B представляют собой байты. То есть каждый из них принимает всего лишь 256 значений. Соответственно, наш кубический корень, как и результат любой формулы над байтом, тоже может принимать только 256 значений.
Мы можем записать заранее все значения формулы, какой бы сложной она ни была, а в рантайме всего лишь выбирать нужное значение из массива:
const result = CUBE_ROOTS[r];
Мы получаем примерно десятикратное ускорение по сравнению с первоначальным кодом — точные результаты могут немного отличаться. Чем сложнее формула, тем большее ускорение мы можем получить.
Такой приём называется lookup table (LUT): мы записываем заранее вычисленные значения в табличку и ценой дополнительной памяти получаем дополнительную скорость.
Бонусы shortcut fusion: промежуточные структуры данных не создаются и не потребляют память, мы не копируем в них содержимое предыдущего промежуточного массива, а число итераций уменьшается до одной. В мощных языках это делает под капотом сам компилятор. Мы в JavaScript вынуждены делать это вручную.
В следующем примере надо вычислить первые пять квадратных корней из нечётных элементов массива. Если мы запишем такую конструкцию в лоб, используя filter и map, то сложность реализации будет O(N):
array
.filter(n => n % 2)
.map(n => Math.sqrt") )
)
.slice(0, 5);
Нам на помощь может прийти библиотека Lodash. В ней это же вычисление записывается очень похоже, но имеет сложность, близкую к константной:
_(array)
.filter(n => n % 2)
.map(n => Math.sqrt)
.take(5).value();
Lodash под капотом реализовывает и shortcut fusion, и ленивое вычисление, находя только первые пять элементов. Неважно, какова длина массива: как только мы найдём первые пять элементов, Lodash прекратит вычисления.
Такие вещи реализованы в нескольких библиотеках. Помимо Lodash к ним относятся Immutable и Ramda. Используйте их, когда у вас появляются такие цепочки вычислений.
const state = {
todos: [{todo: "Learn typescript", done: true}],
otherData: {}
};
Для нас это очень важно, потому что мы используем React, Redux и иммутабельный state. При этом создавать вручную следующий state из предыдущего очень неудобно:
const nextState = {...state,
todos: [...state.todos, {todo: "Try immer"}]};
Нам на помощь могут прийти библиотеки, которые реализовывают за нас паттерн copy-on-write. Например, библиотека Immer.
const nextState = produce(state, draft => {
draft.todos.push({todo: "Try immer"});
});
Мы как будто получаем следующий экземпляр state и смело делаем его мутирование, то есть добавляем в него элементы, меняем значения полей, а Immer под капотом реализовывает копирование всего остального и добавление новых данных.
Помимо Immer есть несколько библиотек, которые реализовывают похожие вещи. В библиотеке Immutable есть методы updateIn, которые явно работают с иммутабельными структурами. В библиотеке Ramda есть концепция, которая называется «линзы». Мы создаём линзу и указываем в ней путь внутри объекта, в котором надо сделать мутацию значения. Читайте документацию, используйте эти библиотеки, когда нужно работать с иммутабельным state и другими иммутабельными структурами.
array.map().reverse()
Есть классический цикл for, в котором мы можем задать обратное направление:
for(let i = len - 1; i >= 0; i--)
Предположим, вам необходимо сделать вычисление над частью массива:
array.slice(1).forEach()
Тогда, опять же, не нужны сложные цепочки вычислений — тоже можно использовать for, задав в нём нужный диапазон индексов:
for(let i = 1; i < len; i++)
Бывает, что мы усложняем код, делая слишком сложную цепочку:
_.chain(data)
.map()
.compact()
.value()[0]
Мы можем упростить и ускорить её, заменив на один вызов _.find() и проделав операции из map() только с одним найденным элементом
[1, 2, 3].map(i => fn(i))
В горячем коде, если вы заметите мелкие циклы на несколько элементов с использованием for, map, forEach, лучше развернуть их вручную:
[fn(1), fn(2), fn(3)]
Вот пример бенчмарка (это синтетический бенчмарк, в реальном коде я аналогичных примеров не встречал). Есть массив из 100 тысяч элементов, которые мы перебираем в цикле. Внутри цикла стоит if, и в зависимости от проверки мы обрабатываем ровно половину элементов, а половину — нет.
Но в первом случае массив отсортирован, и мы сначала обрабатываем 50% элементов, а потом 50% оставшихся не обрабатываем. А во втором случае элементы, которые нужно обработать, случайно перемешаны по всему массиву. Нужно обработать ровно столько же элементов, но Branch prediction при этом не работает.
Обработка такого неупорядоченного массива занимает в разы больше времени даже на современных машинах: 550 мс против 130 мс. То есть даже в JavaScript Branch prediction может оказать заметное влияние на вычисления.
Если вы управляете порядком данных — например, тем, с какой сортировкой они приходят с бэкенда, — обратите на это внимание. Этот приём может помочь вам ускорить код.
let i = str.length; while (i--) str.charCodeAt(i);
Но, к сожалению, это уже давно не так. В современных браузерах направление вперёд обычно работает быстрее (в данном примере — 1,6 против 1,4 млн операций в секунду):
for (let i = 0; i < str.length; i++) str.charCodeAt(i);
Даже на относительно коротких строках из нескольких сотен символов мы можем легко заметить разницу в скорости во всех современных браузерах и в Node.js.
Так что не используйте этот паттерн, пишите простой цикл for и итерацию в прямом направлении. Таким образом железо сможет наиболее оптимально дать вам следующие данные, которые вы собираетесь читать или менять.
Предположим, у вас есть двумерные структуры. Например, вы прочитали записи таблицы или двумерный массив в память. Тогда имеет смысл расположить последовательно в памяти строки или колонки, по которым вы будете итерироваться.
Если вы обрабатываете массив построчно, элементы одной строки должны лежать в памяти рядом. Если вы сканируете таблицу по колонке — например, ищете запись по индексу в таблице базы данных, — именно эта колонка должна лежать в соседних ячейках памяти. Такой приём может дать заметный прирост скорости.
Иногда это можно сделать довольно безболезненно.
const obj = createNewObj();
return {...obj, prop: value};
Например, в таком горячем участке кода мы создаём свежий объект с нуля. Это гарантированно уникальный объект, никто на него не ссылается. И тут же, в следующей строке, мы его клонируем в новый объект. Здесь совершенно зря происходит и клонирование объекта, и создание мусора. Этот кусочек кода можно переписать вот так, будет намного быстрее:
const obj = createNewObj();
obj.prop = value;
return obj;
Но это, повторюсь, только в горячем коде. В остальных местах такое решение усложнит код, сделает его менее читаемым и менее сопровождаемым.
Предположим, есть возвращаемый объект, который нужен один раз «на выброс» — то есть надо сделать однократно какую-то операцию, и больше нас объект не интересует, мы нигде не сохраняем ссылки на него. Тогда можно использовать синглтон. Этот паттерн называется flyweight object.
Вот пример из фреймворка ExtJS:
Ext.fly(id)
В других языках самое распространённое применение этого алгоритма — в библиотеках логирования, которые могут вызываться очень часто, поэтому нагрузка на память становится важной. Вот ссылки на клиенты логирования в языках Go и Java:
[string1, string2, … stringN].join('')
К сожалению, это работало быстро только в шестом Internet Explorer. С тех пор стало гораздо быстрее суммировать строки «в лоб»:
string1 + string2 + … + stringN
Потому что в браузерах для такого представления строки есть специальный класс ConsString, «конкатенированная строка». Он позволяет осуществить сложение строк за константное время, то есть сохраняет внутри только две ссылки на две суммируемых строки и не занимается физическим копированием байтиков из одного места в другое. Так что суммируйте строки как есть, не используйте для этого массив и join.
_.defaults(button, {
size: getDefaultButtonSize(window),
text: getDefaultButtonText()
});
В этом примере кода, когда приходят пропсы для кнопки, мы хотим, чтобы у них были дефолтные размеры и текст. Вычисления дефолтных размеров и текста мы проделываем для дефолтных полей, даже если в пришедших к нам свойствах кнопки уже есть поля size и text. То есть мы сначала вычислим объект дефолтных значений и потом решим, будем ли его использовать.
Быстрый некрасивый фикс: сначала проверять, нужны ли нам дефолты в данном поле, и только тогда выполнять тяжёлые вычисления:
if (button.size === undefined)
button.size = getDefaultButtonSize(window);
if (button.text === undefined)
button.text = getDefaultButtonText();
Но, конечно, такой код получается некрасивым. Немного красивее будет написать с использованием геттеров:
_.defaults(button,{
get size() {return getDefaultButtonSize(window)},
get text() {return getDefaultButtonText()}
});
Вариант ещё лучше: если вы понимаете, что у вас в горячем коде часто генерируются пропсы, в которых используется дефолтное значение, сделайте правильную генерацию этих пропсов, чтобы внутри кода, который их генерирует, все они сразу получали дефолтные значения. Постарайтесь сделать этот код красивым и быстрым — это вполне достижимый результат.
constructor() {
this.formatter = new Intl.DateTimeFormat(…);
}
handleUserClick() {
const formatter = this.formatter;
this.clickTime = formatter.format(new Date());
}
Мы создаём поле formatter для форматирования даты и времени, и это создание длится очень долго. Но formatter, возможно, будет использован только через большой промежуток времени, когда пользователь на что-то нажмёт.
Мы можем погрузить медленное создание объекта formatter в обёртку, которая выполнит код создания объекта, когда браузер будет свободен и пользователь не будет ничего делать или когда нам явно потребуется этот formatter:
constructor() {
this.formatter = new IdleValue(
() => new Intl.DateTimeFormat(…));
}
handleUserClick() {
const formatter = this.formatter.getValue();
this.clickTime = formatter.format(new Date());
}
Так мы сэкономим время на критическом этапе загрузки страницы и не будем замедлять создание объектов.
const [x, setX] = useState(0);
Если у нас нет поддержки деструктурирования, то мы транспилируем этот код в нативный ES5-вариант, в котором мы сначала получаем массив, а потом читаем из него элементы по двум индексам:
const state = useState(0),
x = state[0],
setX = state[1];
Как ни странно, когда появилось нативное деструктурирование, этот ES5-вариант работал в разы быстрее нативного, потому что под капотом деструктурирование двух элементов массива реализовано через создание итератора, два вызова next, две проверки на достижение конца итерации, и всё это ещё завёрнуто в try-catch. Такая нативная реализация деструктурирования в принципе не может работать быстрее, чем просто доступ к двум элементам массива.
Как мы видим по бенчмарку, со временем деструктурирование в Chrome было немного оптимизировано в ущерб транспилированному варианту. А в других популярных браузерах деструктурирование до сих пор работает медленно:
Так что в горячем коде, пожалуйста, обратите внимание: даже деструктурирование может привести к замедлению.
 habr.com
habr.com
Некоторые из приёмов будут полезны и тем, кто пишет на других языках. Все способы разделены на группы по убыванию специфичности: от наиболее общих до конкретных. Почти все примеры кода взяты из реальных проектов, из реального продакшена.
Организационные
Культура разработки performance-first
Это самое важное. Чем раньше вы начнёте контролировать скорость в вашем проекте — тем лучше для проекта. Это даст возможность заранее избежать серьёзных просчётов, которые потом будет сложно исправить.В то же время заметьте: я не призываю сразу превращать весь код в нечитабельную «портянку». Главное — осознанно следить за ним, знать, где, что и с какой скоростью у вас работает, и осознавать, когда можно и нужно исправлять конкретные вещи и требуется ли вообще их исправлять.
Бюджет скорости
Очень важно определить бюджет скорости в проекте. Как именно его определять, какие метрики и какие значения выбирать — это тема отдельного длинного разговора. Главное, чтобы бюджет у вас был.— Быть быстрее конкурентов на ≈ 20%!
— Открытие страницы в 4G сети < 3 с
— Открытие страницы в 3G сети < 5 с
— Длительность запросов за данными < 1 c
— First Contentful Paint < 1 с
— Largest Contentful Paint < 2 с
— Total Blocking Time < 500 мс
— Lighthouse Performance Score > 70
— Cumulative Layout Shift < 0,1
wp-rocket.me/blog/performance-budgets
Performance mantras
Ещё один интересный подход к проблеме. Попробуйте применить семь шагов мантры к вашей проблеме скорости и производительности кода. Если один из них подскажет путь решения, смело его используйте. Такой подход работает: все приёмы, которые я дальше покажу, подпадают под какой-либо из пунктов мантры.1. Don't do it
2. Do it, but don't do it again
3. Do it less
4. Do it later
5. Do it when they're not looking
6. Do it concurrently
7. Do it cheaper
brendangregg.com/blog/2018-06-30/benchmarking-checklist.html
Следующая группа приёмов будет полезна не только в JavaScript.
Те, что можно использовать независимо от языка и его реализации
Смена языка или фреймворка
Самое главное: если вы понимаете, что ваши инструменты не подходят для данной задачи, то как можно раньше ищите другие, более подходящие. Либо вообще смените язык программирования или фреймворк. Если подходящих нет, напишите свои. Так, в конце концов, родились многие известные сейчас фреймворки и библиотеки.Смена алгоритма
Если текущий язык вам подходит и вы его не меняете, но проблема в конкретном алгоритме, то поищите — возможно, есть алгоритмы, которые делают ту же самую задачу, но с меньшей сложностью. Например, можно попробовать перейти от O(N2) к O(N log N) или к O(N). Проверьте, как алгоритм работает именно с вашими данными. Возможно, данные у вас в продакшене — это наихудший вариант, в котором именно этот алгоритм показывает наихудшую производительность. Тогда можно найти альтернативы, которые будут работать с той же сложностью, но именно на ваших данных показывать лучшую производительность.Оптимизация алгоритма
Если лучших вариантов нет, посмотрите на реализацию текущего алгоритма. Постарайтесь уменьшить количество итераций, проходов по коллекциям и массивам. То есть N-1 проход — это быстрее, чем N проходов, хотя в O-нотации получается одна и та же сложность.Если в вашем сервисе используется сложная математика, которая занимает время, попытайтесь её упростить. Однажды мы искали точки на плоскости, ближайшие к заданной. Для формулы вычисления расстояния нам нужен был квадратный корень: Math.sqrt(dx**2 + dy**2). Но для поиска ближайшей точки достаточно было сравнивать квадраты расстояний: dx**2 + dy**2. Это даст тот же самый ответ, но при этом мы избавимся от медленного вычисления корня.
Посмотрите внимательно на свои сложные вычисления — возможно, у вас получится применить такой же подход.
Вынос инвариантов на уровень выше
Бывает, что на каждой итерации вы постоянно проверяете или вычисляете одно и то же выражение, которое в следующей итерации не изменится. Например:items.forEach(i => doClear ? i.clear() : i.mark());
Вместо того чтобы вычислять его N раз, было бы неплохо вынести его из цикла и проверять или вычислять только один раз:
if (doClear) items.forEach(clear) else items.forEach(mark);
Как вариант, в этом коде мы можем по условию подставлять нужную функцию-итератор в перебор массива через forEach:
const action = doClear ? clear : mark;
items.forEach(action);
Такой приём касается не только циклов и операций над массивами. Он также применим к методам и функциям. Вот изоморфный код, который вычисляет, видима ли domNode в указанной точке экрана:
const visibleAtPoint = function(x, y, domNode) {
if (canUseDom && document.elementsFromPoint) {
// ...
}
};
Чтобы работать на сервере, код проверяет, можно ли использовать DOM. А когда код выполняется в браузере, он проверяет, обладает ли браузер требуемым API. Такие проверки происходят при каждом вызове функции. Это ненужные затраты времени и на сервере при server-side rendering, и на клиенте, потому что браузер или обладает API, или нет, и это достаточно проверить один раз.
Способ это исправить — завести две реализации, по одной для каждого из вариантов, проверить один раз, обладает ли наша среда выполнения нужными свойствами, и в зависимости от этого подставить нужную реализацию. Внутри реализации уже не будет никаких if, никаких проверок условий. Она будет работать максимально быстро.
const visibleAtPoint =
(canUseDom && document.elementsFromPoint) ? fn1 : fn2;
Boolean short circuit
Сейчас, к сожалению, часто забывают про Boolean short circuit. Даже JavaScript умеет не вычислять до конца логические выражения, составленные из операторов и/или, если он может заранее предсказать результат, как в этом примере.const isVisibleBottomLeft =
visibleAtPoint(left, bottom, element);
const isVisibleBottomRight =
visibleAtPoint(right, bottom, element);
return isVisibleBottomLeft && isVisibleBottomRight;
Код проверяет видимость нижней левой и нижней правой точки прямоугольника — диалога, модального окошка. Если нижний левый угол уже не виден, то нам не надо вычислять видимость нижнего правого угла. Но в такой записи мы всё равно сначала всё вычислим и потом подставим в логическое выражение. Это без нужды замедляет наш код, особенно если проверки идут очень часто.
Чтобы воспользоваться преимуществами Boolean short circuit, надо подставлять вычисления и вызовы функций в само выражение. Тогда не будет вычисляться то, что не нужно.
return visibleAtPoint(left, bottom, element) &&
visibleAtPoint(right, bottom, element);
Досрочный выход из цикла
Иногда мы уже знаем результат нашего выражения, и нам не обязательно совершать поиск по всему массиву, как в этом примере:let negativeValueFound = false;
for (let i = 0; i < values.length; i++) {
if (value < 0) negativeValueFound = true;
}
Мы ищем, есть ли в массиве отрицательные значения. Но автор кода забыл, что, возможно, отрицательным будет самый первый элемент и нет смысла перебирать все оставшиеся, когда мы уже знаем ответ. Поэтому смотрите на свой код. После того, как вы узнаете ответ, нет необходимости продолжать итерацию по массивам и коллекциям. Надо досрочно возвращать результат:
let negativeValueFound = false;
for (let i = 0; i < values.length; i++) {
if (value < 0) {negativeValueFound = true; break;}
}
Такими методами, досрочно завершающими перебор, у массива являются find, findIndex, every и some. Есть проблема с методом reduce: он продолжает перебор массива до конца. В этом случае можно использовать библиотечные методы, например, Lodash предоставляет метод transform — аналог reduce, но с возможностью досрочного выхода.
Предвычисление
Иногда некоторые константы можно посчитать заранее. Например, мы обрабатываем все точки изображения и вычисляем кубический корень из компонент RGB каждой точки:const result = Math.pow(r, 1/3);
Очень часто при работе с изображениями нужны сложные и затратные математические вычисления. Скорость вычислений не очень большая: на моей машине получается примерно 7 млн операций в секунду. Другими словами, за секунду мы успеем обработать примерно два мегапикселя картинки. Это маловато для современных машин.
Мы можем заметить, что константа ⅓ вычисляется каждый раз, и запомнить её. При этом скорость работы увеличится до 10 млн операций в секунду.
const N = 1/3;
const result = Math.pow(r, N);
Но этого всё ещё недостаточно. Обратите внимание, что чаще всего компоненты R, G и B представляют собой байты. То есть каждый из них принимает всего лишь 256 значений. Соответственно, наш кубический корень, как и результат любой формулы над байтом, тоже может принимать только 256 значений.
Мы можем записать заранее все значения формулы, какой бы сложной она ни была, а в рантайме всего лишь выбирать нужное значение из массива:
const result = CUBE_ROOTS[r];
Мы получаем примерно десятикратное ускорение по сравнению с первоначальным кодом — точные результаты могут немного отличаться. Чем сложнее формула, тем большее ускорение мы можем получить.
Такой приём называется lookup table (LUT): мы записываем заранее вычисленные значения в табличку и ценой дополнительной памяти получаем дополнительную скорость.
Для языков/фреймворков, в которых нет ленивых вычислений и приёма copy-on-write
Shortcut fusion
Это интересная концепция, которая полностью отсутствует в JavaScript. Предположим, у вас есть необходимость в целой цепочке выражений над массивом: array.map().filter().reduce(). JavaScript будет делать всё это последовательно. Сначала выполнит map, построит промежуточный массив. Потом выполнит filter, построит второй промежуточный массив и в конце выполнит reduce над всеми элементами промежуточного массива. Получается три прохода, которые мы могли бы объединить в один, сделав shortcut fusion: написав один сложный array.reduce() с кодом из наших map, filter и reduce.Бонусы shortcut fusion: промежуточные структуры данных не создаются и не потребляют память, мы не копируем в них содержимое предыдущего промежуточного массива, а число итераций уменьшается до одной. В мощных языках это делает под капотом сам компилятор. Мы в JavaScript вынуждены делать это вручную.
Ленивое вычисление
Оно тоже отсутствует в JavaScript. Иногда из всего массива нам требуется только пять первых элементов: arr.map().slice(0, 5). Или первый элемент, который удовлетворяет какому-нибудь условию: arr.map().filter(Boolean)[0]. Подобные вещи в JS выполняются неэффективно: сначала мы делаем все операции над массивом целиком, а потом оставляем только нужные элементы.В следующем примере надо вычислить первые пять квадратных корней из нечётных элементов массива. Если мы запишем такую конструкцию в лоб, используя filter и map, то сложность реализации будет O(N):
array
.filter(n => n % 2)
.map(n => Math.sqrt
).slice(0, 5);
Нам на помощь может прийти библиотека Lodash. В ней это же вычисление записывается очень похоже, но имеет сложность, близкую к константной:
_(array)
.filter(n => n % 2)
.map(n => Math.sqrt
).take(5).value();
Lodash под капотом реализовывает и shortcut fusion, и ленивое вычисление, находя только первые пять элементов. Неважно, какова длина массива: как только мы найдём первые пять элементов, Lodash прекратит вычисления.
Такие вещи реализованы в нескольких библиотеках. Помимо Lodash к ним относятся Immutable и Ramda. Используйте их, когда у вас появляются такие цепочки вычислений.
Copy-on-write
В тех языках, где используется иммутабельность и копирование структур, есть приём: ленивое копирование содержимого этих структур в новый экземпляр, которое происходит, только когда мы действительно собираемся менять значение внутри.const state = {
todos: [{todo: "Learn typescript", done: true}],
otherData: {}
};
Для нас это очень важно, потому что мы используем React, Redux и иммутабельный state. При этом создавать вручную следующий state из предыдущего очень неудобно:
const nextState = {...state,
todos: [...state.todos, {todo: "Try immer"}]};
Нам на помощь могут прийти библиотеки, которые реализовывают за нас паттерн copy-on-write. Например, библиотека Immer.
const nextState = produce(state, draft => {
draft.todos.push({todo: "Try immer"});
});
Мы как будто получаем следующий экземпляр state и смело делаем его мутирование, то есть добавляем в него элементы, меняем значения полей, а Immer под капотом реализовывает копирование всего остального и добавление новых данных.
Помимо Immer есть несколько библиотек, которые реализовывают похожие вещи. В библиотеке Immutable есть методы updateIn, которые явно работают с иммутабельными структурами. В библиотеке Ramda есть концепция, которая называется «линзы». Мы создаём линзу и указываем в ней путь внутри объекта, в котором надо сделать мутацию значения. Читайте документацию, используйте эти библиотеки, когда нужно работать с иммутабельным state и другими иммутабельными структурами.
Оверинжиниринг
Порой легко увлечься и усложнить код там, где на самом деле можно сделать намного проще. Например, если вам нужно сделать обратный порядок элементов в массиве, для этого не нужны дополнительные библиотеки или сложный код, как здесь:array.map().reverse()
Есть классический цикл for, в котором мы можем задать обратное направление:
for(let i = len - 1; i >= 0; i--)
Предположим, вам необходимо сделать вычисление над частью массива:
array.slice(1).forEach()
Тогда, опять же, не нужны сложные цепочки вычислений — тоже можно использовать for, задав в нём нужный диапазон индексов:
for(let i = 1; i < len; i++)
Бывает, что мы усложняем код, делая слишком сложную цепочку:
_.chain(data)
.map()
.compact()
.value()[0]
Мы можем упростить и ускорить её, заменив на один вызов _.find() и проделав операции из map() только с одним найденным элементом
Зависящие от железа
До сих пор неявно предполагалось, что всё, что мы пишем, выполняется на идеальных компьютерах со сверхбыстрыми процессорами и мгновенным доступом к памяти. В реальности это не так, что в некоторых горячих местах становится особенно заметно.Разворачивание мелких циклов
Как вы, наверное, знаете, мелкие циклы выполняются неэффективно, потому что затраты на организацию цикла перевешивают затраты на выполнение самого кода в цикле. В компилируемых языках компилятор разворачивает подобные мелкие циклы за вас и подставляет скомпилированный код, но в JavaScript приходится делать это вручную.[1, 2, 3].map(i => fn(i))
В горячем коде, если вы заметите мелкие циклы на несколько элементов с использованием for, map, forEach, лучше развернуть их вручную:
[fn(1), fn(2), fn(3)]
Предсказание ветвлений (Branch prediction)
Если процессор может предугадать в вашей проверке if или switch, куда дальше передастся выполнение, он заранее начнёт разбирать этот код и выполнит его быстрее.Вот пример бенчмарка (это синтетический бенчмарк, в реальном коде я аналогичных примеров не встречал). Есть массив из 100 тысяч элементов, которые мы перебираем в цикле. Внутри цикла стоит if, и в зависимости от проверки мы обрабатываем ровно половину элементов, а половину — нет.
Но в первом случае массив отсортирован, и мы сначала обрабатываем 50% элементов, а потом 50% оставшихся не обрабатываем. А во втором случае элементы, которые нужно обработать, случайно перемешаны по всему массиву. Нужно обработать ровно столько же элементов, но Branch prediction при этом не работает.
Обработка такого неупорядоченного массива занимает в разы больше времени даже на современных машинах: 550 мс против 130 мс. То есть даже в JavaScript Branch prediction может оказать заметное влияние на вычисления.
Если вы управляете порядком данных — например, тем, с какой сортировкой они приходят с бэкенда, — обратите на это внимание. Этот приём может помочь вам ускорить код.
Доступ к памяти: направление итерации
Как вы знаете, доступ к памяти происходит не мгновенно — современные компьютеры используют кэширование и упреждающее чтение данных для ускорения процесса. Есть старый паттерн, который родился в шестом Internet Explorer при операциях над циклами и строками: итерация в обратном направлении тогда была самой быстрой. С тех пор паттерн очень часто повторяется в современном коде «для большей скорости».let i = str.length; while (i--) str.charCodeAt(i);
Но, к сожалению, это уже давно не так. В современных браузерах направление вперёд обычно работает быстрее (в данном примере — 1,6 против 1,4 млн операций в секунду):
for (let i = 0; i < str.length; i++) str.charCodeAt(i);
Даже на относительно коротких строках из нескольких сотен символов мы можем легко заметить разницу в скорости во всех современных браузерах и в Node.js.
Так что не используйте этот паттерн, пишите простой цикл for и итерацию в прямом направлении. Таким образом железо сможет наиболее оптимально дать вам следующие данные, которые вы собираетесь читать или менять.
Доступ к памяти: [j] vs [j]
Предположим, у вас есть двумерные структуры. Например, вы прочитали записи таблицы или двумерный массив в память. Тогда имеет смысл расположить последовательно в памяти строки или колонки, по которым вы будете итерироваться.
Если вы обрабатываете массив построчно, элементы одной строки должны лежать в памяти рядом. Если вы сканируете таблицу по колонке — например, ищете запись по индексу в таблице базы данных, — именно эта колонка должна лежать в соседних ячейках памяти. Такой приём может дать заметный прирост скорости.
Для языков со сборкой мусора
Эта группа оптимизаций подходит для языков, в которых есть garbage collection и автоматическое управление памятью: JavaScript, C#, Java и некоторых других.Мутабельность
Первая проблема — плохая поддержка иммутабельности. Иммутабельность объектов означает генерацию новых объектов, иногда с довольно большой скоростью. А старые объекты должны собираться через garbage collector. В горячем коде это может очень сильно влиять на скорость работы. Именно затраты на сборку мусора могут превышать затраты на работу вашего кода. И если вы видите, что в горячем коде есть сильное потребление памяти, постарайтесь использовать мутабельность: убрать spread, убрать клонирование объектов и мутировать существующие объекты.Иногда это можно сделать довольно безболезненно.
const obj = createNewObj();
return {...obj, prop: value};
Например, в таком горячем участке кода мы создаём свежий объект с нуля. Это гарантированно уникальный объект, никто на него не ссылается. И тут же, в следующей строке, мы его клонируем в новый объект. Здесь совершенно зря происходит и клонирование объекта, и создание мусора. Этот кусочек кода можно переписать вот так, будет намного быстрее:
const obj = createNewObj();
obj.prop = value;
return obj;
Но это, повторюсь, только в горячем коде. В остальных местах такое решение усложнит код, сделает его менее читаемым и менее сопровождаемым.
Zero memory allocation или GC-free
Так называются алгоритмы с низким или нулевым потреблением памяти. Общий приём в подобных алгоритмах — использование пула объектов. Мы один раз создаём N объектов заданного типа, и те, кто ими пользуются, мутируют их, как им надо, а потом возвращают обратно в пул. Таким образом, нет потребления новой памяти.Предположим, есть возвращаемый объект, который нужен один раз «на выброс» — то есть надо сделать однократно какую-то операцию, и больше нас объект не интересует, мы нигде не сохраняем ссылки на него. Тогда можно использовать синглтон. Этот паттерн называется flyweight object.
Вот пример из фреймворка ExtJS:
Ext.fly(id)
Это довольно частый паттерн работы с DOM: мы получаем по идентификатору DOM-элемент, на нём проверяем или меняем CSS-класс, стили, атрибуты и выбрасываем его, так как он нам больше не нужен. В этом случае подходит именно flyweight object.Use this to make one-time references to DOM elements which are not going to be accessed again either by application code, or by Ext's classes.
В других языках самое распространённое применение этого алгоритма — в библиотеках логирования, которые могут вызываться очень часто, поэтому нагрузка на память становится важной. Вот ссылки на клиенты логирования в языках Go и Java:
- Клиент go-statsd — пулы объектов и GC-free-код: github.com/smira/go-statsd/blob/master/README.md#zero-memory-allocation
- Фреймворк логирования log4j — GC-free-код: logging.apache.org/log4j/2.x/manual/garbagefree.html
Специфичные для JavaScript
Эта группа оптимизаций наиболее близка именно к JS и мало применима в других языках.Антипаттерн: накопление строк в массиве
Ещё один антипаттерн со времён шестого Internet Explorer — если нужно накопить длинную строку из кусочков, некоторые разработчики до сих пор сначала собирают эти строки в массив, чтобы потом вызвать join:[string1, string2, … stringN].join('')
К сожалению, это работало быстро только в шестом Internet Explorer. С тех пор стало гораздо быстрее суммировать строки «в лоб»:
string1 + string2 + … + stringN
Потому что в браузерах для такого представления строки есть специальный класс ConsString, «конкатенированная строка». Он позволяет осуществить сложение строк за константное время, то есть сохраняет внутри только две ссылки на две суммируемых строки и не занимается физическим копированием байтиков из одного места в другое. Так что суммируйте строки как есть, не используйте для этого массив и join.
Антипаттерн: Lodash _.defaults
Когда у нас есть объект, в котором мы хотим завести дефолтное значение, для этого мы часто используем функцию _.defaults из Lodash или её аналоги. В этом случае в сами дефолтные значения легко записать результат сложных вычислений, которые занимают длительное время._.defaults(button, {
size: getDefaultButtonSize(window),
text: getDefaultButtonText()
});
В этом примере кода, когда приходят пропсы для кнопки, мы хотим, чтобы у них были дефолтные размеры и текст. Вычисления дефолтных размеров и текста мы проделываем для дефолтных полей, даже если в пришедших к нам свойствах кнопки уже есть поля size и text. То есть мы сначала вычислим объект дефолтных значений и потом решим, будем ли его использовать.
Быстрый некрасивый фикс: сначала проверять, нужны ли нам дефолты в данном поле, и только тогда выполнять тяжёлые вычисления:
if (button.size === undefined)
button.size = getDefaultButtonSize(window);
if (button.text === undefined)
button.text = getDefaultButtonText();
Но, конечно, такой код получается некрасивым. Немного красивее будет написать с использованием геттеров:
_.defaults(button,{
get size() {return getDefaultButtonSize(window)},
get text() {return getDefaultButtonText()}
});
Вариант ещё лучше: если вы понимаете, что у вас в горячем коде часто генерируются пропсы, в которых используется дефолтное значение, сделайте правильную генерацию этих пропсов, чтобы внутри кода, который их генерирует, все они сразу получали дефолтные значения. Постарайтесь сделать этот код красивым и быстрым — это вполне достижимый результат.
Idle Until Urgent
Часто мы в конструкторе объекта инициализируем все поля, которые нам, возможно, потребуются только после некоторых действий пользователя или не потребуются вообще — как в этом примере, взятом из статьи Филипа Уолтона:constructor() {
this.formatter = new Intl.DateTimeFormat(…);
}
handleUserClick() {
const formatter = this.formatter;
this.clickTime = formatter.format(new Date());
}
Мы создаём поле formatter для форматирования даты и времени, и это создание длится очень долго. Но formatter, возможно, будет использован только через большой промежуток времени, когда пользователь на что-то нажмёт.
Мы можем погрузить медленное создание объекта formatter в обёртку, которая выполнит код создания объекта, когда браузер будет свободен и пользователь не будет ничего делать или когда нам явно потребуется этот formatter:
constructor() {
this.formatter = new IdleValue(
() => new Intl.DateTimeFormat(…));
}
handleUserClick() {
const formatter = this.formatter.getValue();
this.clickTime = formatter.format(new Date());
}
Так мы сэкономим время на критическом этапе загрузки страницы и не будем замедлять создание объектов.
Даунгрейд кода: ES6 → ES5
Не секрет, что до сих пор многие фичи ES6 и более новые работают медленнее, чем их аналоги из ES5. В горячем коде попробуйте заменить их на ES5-код и, возможно, получите ускорение.- Итераторы, for-of, map/reduce/forEach заменяйте на for
- Object.keys, Object.entries заменяйте на for-in
- Старайтесь не использовать rest и spread
const [x, setX] = useState(0);
Если у нас нет поддержки деструктурирования, то мы транспилируем этот код в нативный ES5-вариант, в котором мы сначала получаем массив, а потом читаем из него элементы по двум индексам:
const state = useState(0),
x = state[0],
setX = state[1];
Как ни странно, когда появилось нативное деструктурирование, этот ES5-вариант работал в разы быстрее нативного, потому что под капотом деструктурирование двух элементов массива реализовано через создание итератора, два вызова next, две проверки на достижение конца итерации, и всё это ещё завёрнуто в try-catch. Такая нативная реализация деструктурирования в принципе не может работать быстрее, чем просто доступ к двум элементам массива.
Как мы видим по бенчмарку, со временем деструктурирование в Chrome было немного оптимизировано в ущерб транспилированному варианту. А в других популярных браузерах деструктурирование до сих пор работает медленно:
| Нативный код (M ops/s) | Транспилированный в ES5 (M ops/s) | |
| Chromium 71 (2018 год) | 20 | 60 |
| Chrome 89 | 24 | 25 |
| Firefox 87 | 7 | 15 |
| Safari 14 | 13 | 23 |
Примеры из код-ревью
На закуску — примеры реального кода, увиденные во время код-ревью.- Как вы думаете, что делает такой код? Что хотел сделать его автор?
Boolean(_.compact(array).length)
Ответ
- А такой?
array.sort((a, b) => b - a)[0]
Ответ
- Представьте такой угар по иммутабельности:
array.reduce((acc, value) => [...acc, someFn(value)], [])
Даже тот массив, который создан внутри reduce, мы всё равно каждый раз клонируем и тем самым занимаем лишние время и память. Используя мутабельность, можно было бы сильно ускорить выполнение:
array.reduce((acc, value) => {
acc.push(someFn(value));
return acc;
}, []) - Последний пример кода:
arr.filter(predicate).length
Здесь остановлюсь немного подробнее. Мы хотим посчитать количество элементов, которые удовлетворяют условию (для которых predicate вернёт true). Если бы у нас был умный компилятор, или использовался язык с ленивыми вычислениями, то он бы догадался, что нам от промежуточного массива после filter нужна только длина. В коде вычисления этого промежуточного массива он оставил бы только увеличение длины массива при выполнении условия predicate. А само создание массива и копирование его элементов — выбросил бы. Фактически он бы за нас написал конструкцию, в которой лишь инкрементируется длина массива.
Но в JavaScript, к сожалению, мы должны сами видеть, что такой код выполняется неоптимально и оптимизировать его вручную, выполняя работу за компилятор:
arr.reduce((count, x) => predicate(x) ? count + 1 : count, 0)
Вместо заключения
Вот страница на GitHub, где я собрал все упомянутые в тексте ссылки. Надеюсь, вы попробуете применить эти приёмы на практике и поделитесь опытом в комментариях. Также пишите, если уже пробовали что-то из списка или если у вас есть свои идеи, как ускорить работу кода на JavaScript, — обсудим. Спасибо за внимание. Всем быстрого кода!
Приёмы ускорения кода на JS и других языках: подборка от разработчика поиска Яндекса
Привет! Меня зовут Виктор Хомяков, в Яндексе я работаю над скоростью страниц поиска. Однажды мне в голову пришла идея обобщить свой опыт и систематизировать приёмы ускорения работы кода на...
habr.com