Рекомендации, рассмотренные в этой статье, помогут вам реализовать мониторинг на базе Prometheus и улучшить вашу производительность.
Prometheus — одна из базовых составляющих cloud-native-архитектуры. Он уже стал стандартом де-факто для мониторинга Kubernetes. Однако многие сторонние и облачные приложения изначально не предоставляют метрик в формате Prometheus. Например, Linux не предоставляет таких метрик. Для этого и предназначены экспортеры, такие как node exporter. Его легко скачать, запустить и получить сотни метрик для операционной системы.
Secure DevOps, также известный как DevSecOps, обеспечивает безопасность и мониторинг на протяжении всего жизненного цикла приложения: от разработки до продакшена. Что позволяет создавать безопасные, стабильные и высокопроизводительные приложения. Этот подход встраивается в ваш процесс разработки и предоставляет единый источник правды для DevOps-команд, разработчиков и служб безопасности, чтобы максимально повысить эффективность и обеспечить прозрачность при устранении неисправностей и оптимизации.

В этой статье мы рассмотрим несколько рекомендаций по мониторингу приложений и облачных сервисов с помощью экспортеров Prometheus.
Недавно один из наших клиентов сказал: "При каждой интеграции я трачу одну человеконеделю, пытаясь выяснить, какие версии экспортеров, дашбордов и алертов Prometheus мы должны использовать, как их настроить и как не отстать от последних версий".
Трудозатраты на обслуживание большого количества экспортеров Prometheus часто недооцениваются и бывают больше, чем вы себе представляете. Иногда все эти экспортеры и конфигурации могут показаться Диком Западом. Думая наперед и вооружившись практическими рекомендациями, вы сможете облегчить себе жизнь и тратить меньше времени на поддержку экспортеров, уделяя больше внимания действительно важным вещам для вашей организации.
Один из способов решить эту проблему — самому оценить насколько тот или иной экспортер-кандидат удовлетворяет вашим требованиям, предоставляет интересующие вас метрики и насколько он зрелый как программный продукт. Например, если экспортер был разработан много лет назад одним человеком, у него нет свежих обновлений и у него небольшое количество PR / issue / звезд на Github, то, скорее всего, он не используется и не поддерживается.
Многие аспекты метрик и лучшие практики экспортеров Prometheus не всегда очевидны, поэтому использование курируемых списков экспортеров может помочь вам в выборе.
Вашей первой остановкой должна стать страница Exporters and Integrations на сайте Prometheus. Если ваше приложение или протокол, который оно использует для представления метрик, присутствуют там, то это тот экспортер, который, скорее всего, будет лучшим выбором.
Существуют также сторонние каталоги экспортеров, такие как PromCat.io, поддерживаемый Sysdig, или страница портов по умолчанию, которая непреднамеренно оказалась довольно полным списком экспортеров.

PromCat поможет вам сэкономить время, необходимое для выбора и тестирования экспортеров, дашбордов и алертов. В Sysdig есть команда инженеров, которая поддерживает этот сайт и постоянно проверяет работоспособность его содержимого. Смотрите также:
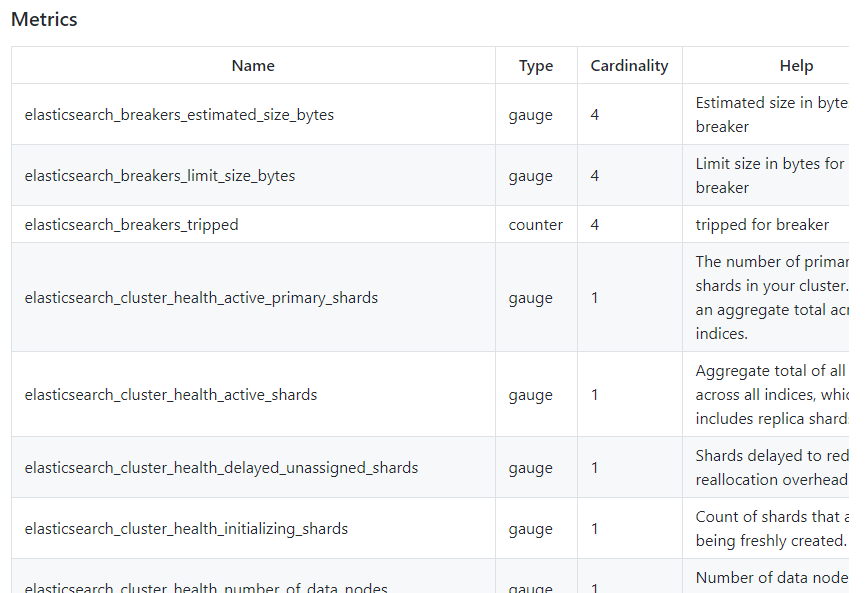
Еще один момент, на который стоит обратить внимание в документации экспортера, — это использование меток (label).
Метки обеспечивают контекст: "Это продакшн-сервис или окружение разработки?", "На каком хосте запущен сервис?", "К какому приложению относится этот сервис?". Например, у команды бэкенда и у команды аналитиков могут быть отдельные инстансы MySQL. Позже вы захотите отфильтровать их метрики, разделить по приложению, окружению (продакшн или разработка) или по региону.
Помимо использования меток для анализа происходящего внутри приложения, они полезны при агрегировании метрик по всем развернутым системам. Правильное использование меток позволяет ответить на такие вопросы, как "Сколько всего процессоров в настоящее время используют все приложения по всему миру?" или "Какое общее использование оперативной памяти всеми приложениями, принадлежащими команде фронтенда в Европе?". Вы можете посмотреть примеры использования меток в этом вебинаре.
Первым шагом в определении любой стратегии алертов является изучение ваших приложений и Prometheus-экспортеров. Следуя рекомендациям DevOps по показателям (Service Level Indicators) и целевым уровням обслуживания (Service Level Objectives) наряду с "золотыми сигналами" мониторинга (golden signals) вы можете определить критические элементы, требующие алертов. Хороший инструмент мониторинга с глубокой видимостью и контекстом Kubernetes поможет найти эти критические факторы.
Работа с инструментами, нативно использующими для алертов PromQL, может сэкономить ваше время, поскольку не нужно переводить их в другой формат, что чревато появлением ошибок. Например, promtool поможет в тестировании конфигураций алертов PromQL (и не только в этом).
Но инструмент для алертов должен иметь больше функций, чем простая обработка PromQL. Помимо настройки алертов для любой метрики или события, также должна быть возможность отправлять алерты на электронную почту, Slack, Pagerduty, Service Now и т.д.
Наиболее распространенный способ взаимодействия с метриками — визуализация на дашбордах. Для помощи в их создании PromCat.io предоставляет шаблоны, готовые к импорту в Grafana или Sysdig Monitor.
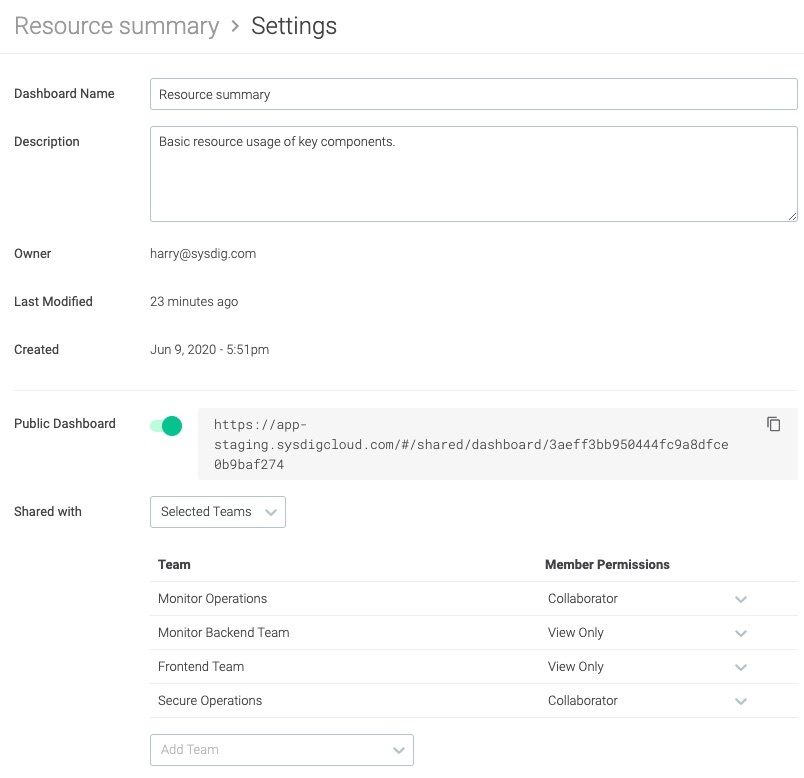
Но как ваша команда организует дашборды? Лучшая практика заключается в том, что вместо создания своих индивидуальных дашбордов каждым членом команды, создается единый дашборд, который используется всей DevOps-командой. Члены команды могут использовать его в качестве примера и вносить только незначительные изменения в случае необходимости. Чтобы все работало, инструмент мониторинга также должен предоставлять возможность разграничения прав доступа к дашбордам (View Only или Collaborator с правами редактирования).
Иногда требуется ограничение доступа к метрикам. Если у вашего инструмента мониторинга есть полная поддержка RBAC, то вы можете предоставлять команде только те данные, которые им нужны. Например, разработчики должны иметь доступ только к метрикам своего пространства имен, в то время как дежурные — ко всем продуктивным узлам.
PromQL — это мощный язык запросов метрик, собираемых экспортерами Prometheus. С помощью PromQL вы можете выполнять сложные математические операции, статистический анализ и использовать различные функции.
Хотя при изучении PromQL может показаться, что вы прокачались в мониторинге, но у него действительно крутая кривая обучения, которую нельзя упускать из виду. Если вы хотите, чтобы новые пользователи быстро приступили к работе, то вам следует убедиться, что ваш инструмент позволяет выполнять простой ввод данных в дашбордах через веб-формы. Также не стоит просить новых пользователей писать сложные PromQL-запросы с соединениями и функциями. Кроме того, ваш инструмент не должен быть сложным для нетехнических специалистов, которые хотят создать простой отчет для анализа данных.

Давайте посмотрим на некоторые проблемы масштабирования Prometheus и способы их решения.
Глобальная видимость Prometheus (Global Prometheus Visibility): по мере роста вам потребуется видеть данные одновременно по нескольким кластерам.
Горизонтальное масштабирование: по мере роста вашего окружения увеличивается количество сервисов в Kubernetes, количество метрик и использование памяти Prometheus'ом. По своей архитектуре Prometheus по горизонтали не масштабируется. И когда вы достигнете предела вертикального масштабирования, то все.
Долгосрочное хранение: Prometheus может отслеживать миллионы измерений в реальном времени. Однако чем дольше вы храните данные, тем больше ресурсов вы тратите. Можно уменьшить срок хранения метрик, но тогда вы не сможете анализировать данные за недели, месяцы или годы.
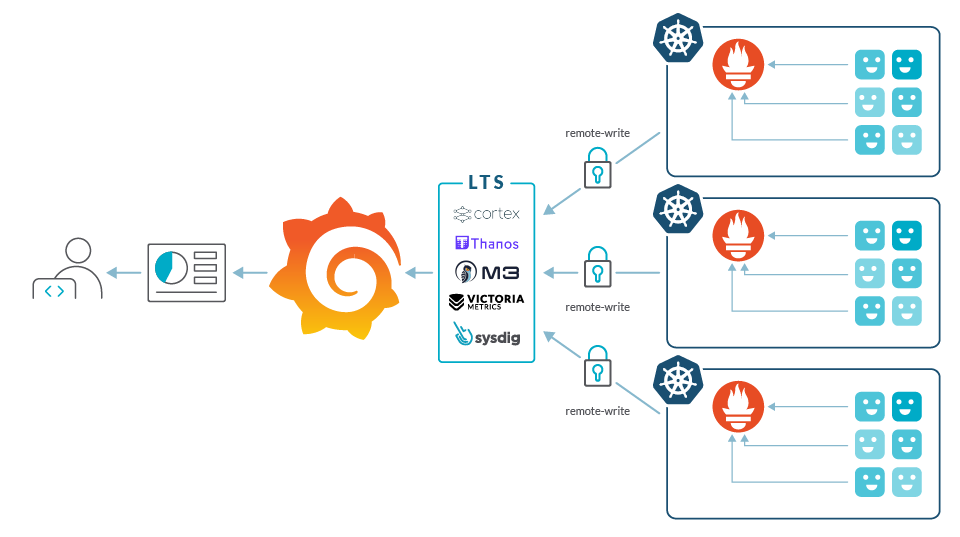
Чтобы справиться с проблемами масштабирования, вы можете попробовать консолидировать Grafana, развернуть Thanos, Cortex или использовать коммерческое решение, такое как Sysdig. Некоторые проблемы, связанные с масштабированием, позволяет решить SaaS-решение, поскольку SaaS-поставщику проще приспособиться к росту, чем вам. Потенциальные проблемы, связанные с этими решениями по масштабированию, подробно рассмотрены в статье “Challenges using Prometheus at scale.” (Проблемы с масштабированием Prometheus).
Выбор правильного инструмента является ключевым моментом. Sysdig позволяет вам следовать лучшим практикам экспортеров Prometheus, и с его помощью вы получите готовое решение менее чем за пять минут. Наша полная совместимость с Prometheus, готовые дашборды и длительное хранение помогают снизить MTTR, одновременно повысить производительность и доступность вашего окружения.
Вы можете увидеть процесс мониторинга приложений и облачных сервисов в действии, на нашем вебинаре “So Many Metrics, So Little Time: 5 Prometheus Exporter Best Practices“ ("Так много метрик и так мало времени: пять рекомендация по экспортерам Prometheus").
Источник статьи: https://habr.com/ru/company/otus/blog/527744/
Prometheus — одна из базовых составляющих cloud-native-архитектуры. Он уже стал стандартом де-факто для мониторинга Kubernetes. Однако многие сторонние и облачные приложения изначально не предоставляют метрик в формате Prometheus. Например, Linux не предоставляет таких метрик. Для этого и предназначены экспортеры, такие как node exporter. Его легко скачать, запустить и получить сотни метрик для операционной системы.
Secure DevOps, также известный как DevSecOps, обеспечивает безопасность и мониторинг на протяжении всего жизненного цикла приложения: от разработки до продакшена. Что позволяет создавать безопасные, стабильные и высокопроизводительные приложения. Этот подход встраивается в ваш процесс разработки и предоставляет единый источник правды для DevOps-команд, разработчиков и служб безопасности, чтобы максимально повысить эффективность и обеспечить прозрачность при устранении неисправностей и оптимизации.
В этой статье мы рассмотрим несколько рекомендаций по мониторингу приложений и облачных сервисов с помощью экспортеров Prometheus.
Недавно один из наших клиентов сказал: "При каждой интеграции я трачу одну человеконеделю, пытаясь выяснить, какие версии экспортеров, дашбордов и алертов Prometheus мы должны использовать, как их настроить и как не отстать от последних версий".
Трудозатраты на обслуживание большого количества экспортеров Prometheus часто недооцениваются и бывают больше, чем вы себе представляете. Иногда все эти экспортеры и конфигурации могут показаться Диком Западом. Думая наперед и вооружившись практическими рекомендациями, вы сможете облегчить себе жизнь и тратить меньше времени на поддержку экспортеров, уделяя больше внимания действительно важным вещам для вашей организации.
1. Найдите подходящий экспортер
Начав использовать Prometheus, вы быстро обнаружите, что для мониторинга ваших приложений есть множество доступных экспортеров. И появляется проблема выбора.Один из способов решить эту проблему — самому оценить насколько тот или иной экспортер-кандидат удовлетворяет вашим требованиям, предоставляет интересующие вас метрики и насколько он зрелый как программный продукт. Например, если экспортер был разработан много лет назад одним человеком, у него нет свежих обновлений и у него небольшое количество PR / issue / звезд на Github, то, скорее всего, он не используется и не поддерживается.
Многие аспекты метрик и лучшие практики экспортеров Prometheus не всегда очевидны, поэтому использование курируемых списков экспортеров может помочь вам в выборе.
Вашей первой остановкой должна стать страница Exporters and Integrations на сайте Prometheus. Если ваше приложение или протокол, который оно использует для представления метрик, присутствуют там, то это тот экспортер, который, скорее всего, будет лучшим выбором.
Существуют также сторонние каталоги экспортеров, такие как PromCat.io, поддерживаемый Sysdig, или страница портов по умолчанию, которая непреднамеренно оказалась довольно полным списком экспортеров.
PromCat поможет вам сэкономить время, необходимое для выбора и тестирования экспортеров, дашбордов и алертов. В Sysdig есть команда инженеров, которая поддерживает этот сайт и постоянно проверяет работоспособность его содержимого. Смотрите также:
2. Изучите метрики экспортера
У каждого экспортера есть свой набор метрик. Обычно их описание есть на странице проекта экспортера, хотя иногда приходится заглядывать в справку или документацию. Если экспортер использует формат OpenMetrics, то он может добавлять к метрике поля с дополнительной информацией, такой как type, info, unit.Еще один момент, на который стоит обратить внимание в документации экспортера, — это использование меток (label).
Метки обеспечивают контекст: "Это продакшн-сервис или окружение разработки?", "На каком хосте запущен сервис?", "К какому приложению относится этот сервис?". Например, у команды бэкенда и у команды аналитиков могут быть отдельные инстансы MySQL. Позже вы захотите отфильтровать их метрики, разделить по приложению, окружению (продакшн или разработка) или по региону.
Помимо использования меток для анализа происходящего внутри приложения, они полезны при агрегировании метрик по всем развернутым системам. Правильное использование меток позволяет ответить на такие вопросы, как "Сколько всего процессоров в настоящее время используют все приложения по всему миру?" или "Какое общее использование оперативной памяти всеми приложениями, принадлежащими команде фронтенда в Европе?". Вы можете посмотреть примеры использования меток в этом вебинаре.
3. Настройте действительно полезные алерты
Настройка алертов может быть сложной задачей. Если вы установите для них низкий порог, то ваша поддержка от них быстро устанет. С другой стороны, если алерты не сработают в нужное время, то вы можете пропустить важную информацию и это может повлиять на конечных пользователей.Первым шагом в определении любой стратегии алертов является изучение ваших приложений и Prometheus-экспортеров. Следуя рекомендациям DevOps по показателям (Service Level Indicators) и целевым уровням обслуживания (Service Level Objectives) наряду с "золотыми сигналами" мониторинга (golden signals) вы можете определить критические элементы, требующие алертов. Хороший инструмент мониторинга с глубокой видимостью и контекстом Kubernetes поможет найти эти критические факторы.
Работа с инструментами, нативно использующими для алертов PromQL, может сэкономить ваше время, поскольку не нужно переводить их в другой формат, что чревато появлением ошибок. Например, promtool поможет в тестировании конфигураций алертов PromQL (и не только в этом).
Но инструмент для алертов должен иметь больше функций, чем простая обработка PromQL. Помимо настройки алертов для любой метрики или события, также должна быть возможность отправлять алерты на электронную почту, Slack, Pagerduty, Service Now и т.д.
4. Предоставьте данные вашей команде (или нет)
Теперь, когда у вас есть ценная информация от экспортеров Prometheus, которую вы используете для мониторинга, убедитесь, что все ваши коллеги могут ее видеть и использовать.Наиболее распространенный способ взаимодействия с метриками — визуализация на дашбордах. Для помощи в их создании PromCat.io предоставляет шаблоны, готовые к импорту в Grafana или Sysdig Monitor.
Но как ваша команда организует дашборды? Лучшая практика заключается в том, что вместо создания своих индивидуальных дашбордов каждым членом команды, создается единый дашборд, который используется всей DevOps-командой. Члены команды могут использовать его в качестве примера и вносить только незначительные изменения в случае необходимости. Чтобы все работало, инструмент мониторинга также должен предоставлять возможность разграничения прав доступа к дашбордам (View Only или Collaborator с правами редактирования).
Иногда требуется ограничение доступа к метрикам. Если у вашего инструмента мониторинга есть полная поддержка RBAC, то вы можете предоставлять команде только те данные, которые им нужны. Например, разработчики должны иметь доступ только к метрикам своего пространства имен, в то время как дежурные — ко всем продуктивным узлам.
PromQL — это мощный язык запросов метрик, собираемых экспортерами Prometheus. С помощью PromQL вы можете выполнять сложные математические операции, статистический анализ и использовать различные функции.
Хотя при изучении PromQL может показаться, что вы прокачались в мониторинге, но у него действительно крутая кривая обучения, которую нельзя упускать из виду. Если вы хотите, чтобы новые пользователи быстро приступили к работе, то вам следует убедиться, что ваш инструмент позволяет выполнять простой ввод данных в дашбордах через веб-формы. Также не стоит просить новых пользователей писать сложные PromQL-запросы с соединениями и функциями. Кроме того, ваш инструмент не должен быть сложным для нетехнических специалистов, которые хотят создать простой отчет для анализа данных.
5. Составьте план по масштабированию
По мере использования Prometheus количество экспортеров постоянно растет и могут возникнуть проблемы с видимостью, горизонтальным масштабированием и долгосрочным хранением. Лучшая практика — планировать масштабирование метрик заранее.Давайте посмотрим на некоторые проблемы масштабирования Prometheus и способы их решения.
Глобальная видимость Prometheus (Global Prometheus Visibility): по мере роста вам потребуется видеть данные одновременно по нескольким кластерам.
Горизонтальное масштабирование: по мере роста вашего окружения увеличивается количество сервисов в Kubernetes, количество метрик и использование памяти Prometheus'ом. По своей архитектуре Prometheus по горизонтали не масштабируется. И когда вы достигнете предела вертикального масштабирования, то все.
Долгосрочное хранение: Prometheus может отслеживать миллионы измерений в реальном времени. Однако чем дольше вы храните данные, тем больше ресурсов вы тратите. Можно уменьшить срок хранения метрик, но тогда вы не сможете анализировать данные за недели, месяцы или годы.
Чтобы справиться с проблемами масштабирования, вы можете попробовать консолидировать Grafana, развернуть Thanos, Cortex или использовать коммерческое решение, такое как Sysdig. Некоторые проблемы, связанные с масштабированием, позволяет решить SaaS-решение, поскольку SaaS-поставщику проще приспособиться к росту, чем вам. Потенциальные проблемы, связанные с этими решениями по масштабированию, подробно рассмотрены в статье “Challenges using Prometheus at scale.” (Проблемы с масштабированием Prometheus).
Заключение
Prometheus, как одна из базовых составляющих cloud-native-архитектуры, стал де-факто стандартом мониторинга для Kubernetes. Для мониторинга приложений и облачных сервисов вам понадобятся экспортеры. Важно помнить, что не все экспортеры одинаково хороши, и решения для мониторинга могут быть не готовы к масштабированию. Я надеюсь, эти советы помогут вам преуспеть в мониторинге благодаря использованию проверенных проектов, понимания ваших метрик и заблаговременного планирования роста.Выбор правильного инструмента является ключевым моментом. Sysdig позволяет вам следовать лучшим практикам экспортеров Prometheus, и с его помощью вы получите готовое решение менее чем за пять минут. Наша полная совместимость с Prometheus, готовые дашборды и длительное хранение помогают снизить MTTR, одновременно повысить производительность и доступность вашего окружения.
Вы можете увидеть процесс мониторинга приложений и облачных сервисов в действии, на нашем вебинаре “So Many Metrics, So Little Time: 5 Prometheus Exporter Best Practices“ ("Так много метрик и так мало времени: пять рекомендация по экспортерам Prometheus").
Источник статьи: https://habr.com/ru/company/otus/blog/527744/