Я уже много лет не пользовался десктопным клиентом электронной почты. Ни один из них не может справиться с объёмом получаемой мной почты, по крайней мере один раз не повредив мой почтовый ящик. Pine, Eudora, Outlook — все они повреждали мой почтовый ящик, вынуждая восстанавливаться из резервной копии. Как получилось, что десктопные почтовые клиенты менее надёжны, чем Gmail, хотя мой аккаунт в Gmail не только обрабатывает больше писем, чем у меня когда-либо было в десктопных клиентах, но и обеспечивает одновременный доступ из множества точек мира? Распределённые системы имеют нечестное преимущество — они, в отличие от десктопных клиентов, устойчивы к полному отказу диска, однако ни одна из моих проблем повреждения файлов не была связана с полным отказом диска. Почему же мой опыт работы с десктопными приложениями был настолько плохим?
Какие же виды сбоев могут возникать? Вероятно, проще всего начать со свойства постоянства при сбоях (поддержания постоянного состояния даже в случае сбоя), потому что мы можем допустить, что всё, от файловой системы до диска, работает правильно; давайте сначала рассмотрим это свойство.
Pillai et al. написали для OSDI '14 статью и презентацию о том, как сложно сохранять данные без повреждения и утери данных. [Прим. пер.: пост был написан в конце 2015 года.]
Давайте рассмотрим простой пример того, что необходимо для сохранения данных способом, защищённым от сбоев. Допустим, у нас есть файл, содержащий текст a foo и мы хотим обновить этот файл, чтобы он содержал a bar. Похоже, что для выполнения этой операции идеально подходит функция pwrite. Она получает дескриптор файла, то, что мы хотим записать, длину и смещение. То есть мы можем попробовать выполнить:
pwrite([file], “bar”, 3, 2) // write 3 bytes at offset 2
Что произойдёт? Если всё будет в порядке, то файл будет содержать a bar, но если во время записи произойдёт сбой, мы получим a boo, a far, или любую другую комбинацию. Стоит заметить, что можно рассмотреть этот пример с секторами или блоками, а не с символами/байтами.
Если нам нужна атомарность (то есть мы хотим получить или a foo, или a bar, и никаких промежуточных результатов), то можно использовать стандартную методику создания копии изменяемых данных в файл журнала отмены (undo log), изменить «реальный» файл, а затем удалить файл журнала. Если произойдёт сбой, то мы восстановимся из журнала. Можно написать нечто подобное:
creat(/dir/log);
write(/dir/log, “2,3,foo”, 7);
pwrite(/dir/orig, “bar”, 3, 2);
unlink(/dir/log);
Это должно позволить восстановить файл после сбоя без повреждения данных при помощи журнала отмены; по крайней мере, если мы используем ext3 и примонтировали диск с data=journal. Но нам не повезёт, если, как и большинство людей, мы используем стандартный ключ — со стандартным data=ordered. [Оказалось, что некоторые коммерчески поддерживаемые дистрибутивы поддерживают только data=ordered. Да, и когда я говорил, что по умолчанию используется data=ordered, то это было справедливо только до версии 2.6.30. После 2.6.30 появилась опция конфигурации CONFIG_EXT3_DEFAULTS_TO_ORDERED. Если она не установлена, по умолчанию используется data=writeback.] Порядок системных вызовов write и pwrite может быть изменён, из-за чего запись в orig произойдёт до записи в журнал, из-за чего теряется весь смысл создания журнала. Это можно исправить.
creat(/dir/log);
write(/dir/log, “2, 3, foo”);
fsync(/dir/log); // don't allow write to be reordered past pwrite
pwrite(/dir/orig, 2, “bar”);
fsync(/dir/orig);
unlink(/dir/log);
Этот код заставит выполнять действия в правильном порядке, по крайней мере, если мы используем ext3 с data=journal или data=ordered. Если мы используем data=writeback, то сбой во время выполнения в журнал операций write или fsync может оставить журнал в состоянии, при котором размер файла был изменён под запись «bar», но данные не записаны, то есть журнал будет содержать случайный мусор. Так происходит потому, что при data=writeback журналируются метаданные, но не операции с данными, то есть операции с данными (например, запись данных в файл) не будут упорядочены относительно операций с метаданными (например, изменения размера файла для записи).
Мы можем исправить это, добавив при создании журнала к нему контрольную сумму. Если содержимое log не включает в себя правильную контрольную сумму, то мы будем знать, что попали в описанную выше ситуацию.
creat(/dir/log);
write(/dir/log, “2, 3, [checksum], foo”); // add checksum to log file
fsync(/dir/log);
pwrite(/dir/orig, 2, “bar”);
fsync(/dir/orig);
unlink(/dir/log);
Это позволит обеспечить безопасность, по крайней мере, в текущий конфигурациях ext3. Но файловая система вполне может оказаться в состоянии, когда журнал никогда не создаётся, за исключением случаев, когда мы передаём fsync родительской папке.
creat(/dir/log);
write(/dir/log, “2, 3, [checksum], foo”);
fsync(/dir/log);
fsync(/dir); // fsync parent directory of log file
pwrite(/dir/orig, 2, “bar”);
fsync(/dir/orig);
unlink(/dir/log);
Это должно предотвратить повреждение любой файловой системы Linux, но если мы хотим гарантировать, что файл на самом деле содержит «bar», нам нужно добавить в конце ещё один fsync.
creat(/dir/log);
write(/dir/log, “2, 3, [checksum], foo”);
fsync(/dir/log);
fsync(/dir);
pwrite(/dir/orig, 2, “bar”);
fsync(/dir/orig);
unlink(/dir/log);
fsync(/dir);
Благодаря этому поведение будет согласованным, а операция действительно изменит файл после её завершения, если мы предполагаем, что fsync на самом деле выполняет сброс данных на диск. У OS X и некоторых версий ext3 функция fsync на самом деле не сбрасывает данные на диск. Для сброса на диск OS X требует fcntl(F_FULLFSYNC), а некоторые версии ext3 в качестве оптимизации сбрасывают на диск только при изменении inode (что происходит только раз в секунду при записи в один и тот же файл, потому что mtime дескриптора inode имеет степень разбиения в одну секунду).
Даже если мы предположим, что fsync даёт команду сброса на диск, некоторые диски игнорируют директивы сброса по той же причине, по которой fsync модифицирован в OS X и в некоторых версиях ext3 — чтобы выглядеть лучше в бенчмарках. В своём посте я не буду это учитывать, но есть статья Rajimwale et al. для DSN '11 и другие работы, в которых рассматривается эта проблема.
После изучения ext2, ext3, ext4, btrfs и xfs авторы статьи выяснили, что есть существенные отличия в написании кода для обеспечения постоянства. Они написали инструмент, собирающий трассировки файловых систем на уровне блоков, и использовали его, чтобы выяснить, какие свойства не учитываются в конкретных файловых системах. Авторы осторожно замечают, что они могли определить, только отсутствие поддержки свойств — если они не обнаружили нарушения свойства, это ещё не значит, что оно поддерживается.
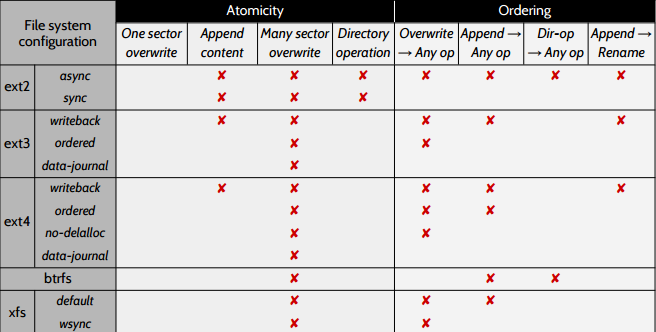
Крестиком обозначены неподдерживаемые свойства. Свойства атомарности означают, что если, например, отсутствует X для single sector overwrite, то запись в отдельный сектор является атомарной. Авторы сообщают, что атомарность перезаписи отдельного сектора иногда продиктована свойством используемого диска, и что работа таки файловых систем на некоторых дисках не обеспечит атомарности для отдельных секторов. Свойства упорядоченности тоже понятны из их названия, например, X в строке «Overwrite -> Any op» означает, что для какой-то операции порядок перезаписи может быть изменён.
После создания инструмента тестирования свойств файловых систем они создали инструмент для проверки того, используют ли приложения любые потенциально некорректные свойства файловых систем. Так как инварианты зависят от конкретных приложений, авторы составили таблицы для каждого протестированного приложения.
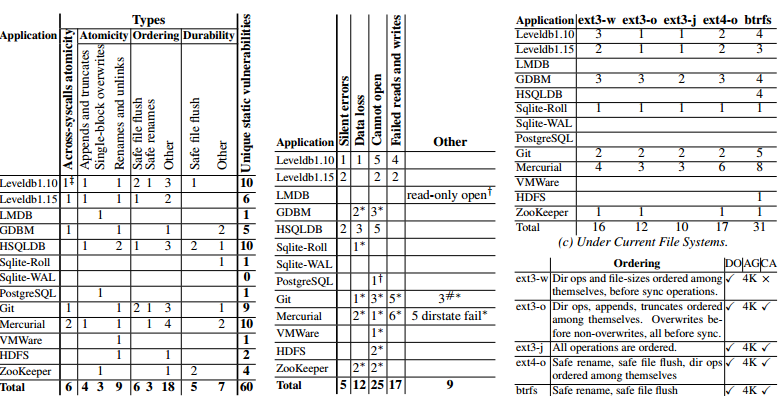
Авторы выявили проблемы у большинства протестированных приложений, в том числе и у таких, на работу которых пользователи надеются, например, LevelDB, HDFS, Zookeeper и git. В докладе один из авторов заметил, что разработчики sqlite имеют очень глубокое понимание этих проблем, но даже этого не хватило для предотвращения всех багов. Этот докладчик также заметил, что особенно плохи были системы контроля версий, и что разработчики довольно небрежны, поэтому авторам очень легко было найти множество проблем в их инструментах. Самым распространённым классом ошибок было некорректное допущение упорядочивания между системными вызовами. Вторым по распространённости классом ошибок было допущение атомарности системных вызовов. [Как известные проблемы задокументированы случаи, когда требуется атомарность перезаписи, и во всех этих случаях предполагается одноблоковая, а не многоблоковая атомарность. Для сравнения: во многих приложениях (LevelDB, Mercurial и HSQLDB) есть серьёзные баги повреждения данных, возникающие из-за того, что атомарным считается дополнение записи (append). Похоже, это косвенный результат использования протокола обновления, при котором модификации журналируются через append, после чего журналированные данные записываются через перезапись. Разработчики приложений тщательно проверяют и обрабатывают ошибки данных, однако ошибки в файле журнала часто остаются незамеченными. В статье обсуждается множество других классов ошибок, и если вы работаете над приложением, которое записывает файлы, я рекомендую прочитать её, чтобы узнать подробности.] По сути, с теми же проблемами люди сталкиваются при реализации многопоточного программирования. Правильно рассуждать о поведении изменения порядка и правильно вставлять ограничения сложно. Но даже несмотря на то, что параллельность общей памяти считается сложной проблемой, требующей большого внимания, запись в файлы не воспринимается аналогичным образом, хотя во многих смыслах она намного сложнее.
Тут также стоит заметить, что хотя семантика btrfs не менее надёжна, чем у ext3/ext4, гораздо больше приложений повреждает данные поверх btrfs, потому что разработчики не привыкли к кодированию для файловых систем, позволяющих переупорядочивать операции с каталогами (наверно, самой свежей и популярной файловой системой, позволяющей такое переупорядочивание, является ext2). Вероятно, мы увидим схожий уровень подверженности багам, когда люди начнут пользоваться накопителями NVRAM, имеющими атомарность на байтовом уровне. Люди почти всегда проводят только несколько тестов, чтобы убедиться, что всё работает, а не проверяют, пишут ли они код для того, что допустимо в файловой системе POSIX.
Семантика упорядочивания аппаратной памяти обычно хорошо задокументирована, что упрощает точное определение того, какие операции могут быть переупорядочены с какими другими операциями, и какие операции являются атомарными. Для сравнения, вот manpage ext про эти три режима данных:
Страница manpage в буквальном смысле ссылается на слухи. Вот такой у нас уровень документации. Если вернуться к примеру, где нам пришлось добавить fsync между write(/dir/log, “2, 3, foo”) и pwrite(/dir/orig, 2, “bar”) для предотвращения изменения порядка, то я не думаю, что необходимость fsync очевидна из описания на manpage. Если посмотреть на представленную выше manpage об упорядочивании аппаратной памяти, то она конкретно определяет семантику упорядочивания, и совершенно не полагается на слухи.
Не хочу сказать, что семантика файловых систем нигде хорошо не задокументирована. Изучая lwn и LKML, можно получить хорошее представление о том, как всё работает. Но разбираться во всём этом достаточно сложно, поэтому по-прежнему очень популярны долгие неопределённые обсуждения того, как это работает. Большая часть информации там ошибочна, и даже если информация была правильна на момент публикации, часто она является устаревшей.
Просматривая архивы, я часто встречал ссылки пост 2005 года как подтверждение того, что fsync в OS X такая же, как и fsync в Linux, и что fcntl(F_FULLFSYNC) в OS X более безопасна, чем всё, что доступно в Linux. Я не уверен, что это было справедливо даже в те времена для ядра 2.4, однако это было правдой для ядра 2.6. Но примерно с 2008 года Linux 2.6 с ext3 выполнял полный сброс на диск при каждом fsync (если это поддерживает диск, а файловая система не была специально настроена с отключением барьеров).
Ещё одна проблема заключается в том, что часто встречаются подобные диалоги:
Разработчик 1: лично мне важна целостность метаданных, а в документации ext3 написано, что журнал защищает их целостность. Исключением являются повреждённые устройства хранения, и для них всё равно нужно запускать fsck.
Разработчик 2: как заявляли авторы ext3 в течение многих лет, всё равно нужно периодически запускать fsck.
Разработчик 1: где это задокументировано?
Разработчик 2: в архивах списка рассылки linux-kernel.
Разработчик 3: примерно 6-8 лет назад, в моей почтовой рассылке.
Где это задокументировано? А, в каком-то посте списке рассылки, созданном 6-8 лет назад (то есть сегодня это уже 12-14 лет назад). Я не хочу обижать разработчиков файловых систем. Прочитанные мной посты разработчиков ФС довольно вежливы, учитывая репутацию LKML; они уделяли много времени ответам на простые вопросы, и я впечатлён тем, насколько терпеливы опытные разработчики файловых систем с задающими вопросы, однако непосвящённым сложно просмотреть посты в списках рассылки за полтора десятка лет и определить, что по-прежнему справедливо, а что устарело.
В своём докладе на OSDI 2014 авторы обсуждаемой нами статьи говорили, что когда они сообщали о найденных багах, разработчики часто отвечали «POSIX не позволяет файловым системам этого делать», но не могли указать на конкретную документацию по POSIX в подтверждение своих слов. Если вы следили за Jepsen Кайла Кингсбери, то это может показаться вам знакомым, только разработчики отвечают не «сети этого не могут», а «файловые системы этого не могут». Мне кажется, это вполне понятно, учитывая количество ложных сведений. Сам я не разработчик файловых систем, поэтому был бы удивлён, если бы в этом посте не нашёлся хотя бы один баг.
Мы уже столкнулись с высоким уровнем сложности правильного сохранения данных, но это была только вершина айсберга. Ранее мы предполагали, что диск работает правильно, или, по крайней мере, что файловая система при помощи SMART или какой-то другой системы мониторинга может определить, когда на диске есть ошибки. Я всегда считал, что это так, пока не начал исследовать вопрос, и это предположение оказалось совершенно неверным.
В статье Prabhakaran et al. для SOSP 05 достаточно подробно исследована реакция файловых систем на дисковые ошибки. Авторы создали слой внесения ошибок, позволяющий вносить дисковые ошибки, а затем запускали chdir, chroot, stat, open, write и т.п., чтобы посмотреть, что произойдёт дальше.
Среди ext3, reiserfs и NTFS лучшей в обработке ошибок оказалась reiserfs; к тому же, похоже, это была единственная файловая система, в которой на этапе проектирования ошибки считались «гражданами первого класса». Она практически всегда сообщала пользователю об ошибках при чтении и вызывала panic при сбоях записи, что приводило к перезапуску и восстановлению. Эта политика позволяет файловой системе элегантно обрабатывать сбои чтения и избегать повреждения данных при сбоях записи. Однако авторы нашли множество несогласованностей и багов. Например, reiserfs некорректно обрабатывает ошибки чтения в непрямых блоках и создаёт утечку места, а один определённый тип сбоя записи не мешает reiserfs обновить журнал и выполнить коммит транзакции, что может привести к повреждению данных.
Reiserfs — это ещё хороший пример. Авторы выяснили, что ext3 в большинстве случаев игнорировала ошибки записи и представляла файловую систему как read-only в большинстве случаев сбоев чтения. Это совершенно непохоже на ту политику, которая нам нужна. Игнорирование сбоев записи легко может привести к повреждению данных, а перемонтирование файловой системы как read-only — слишком сильная реакция, если ошибка чтения была переходной ошибкой (переходные ошибки встречаются часто). Кроме того, из всех трёх файловых систем ext3 обеспечивала наименьшую проверку целостности и с наибольшей вероятностью могла не распознать ошибку. На презентации один из авторов сказал, что в коде ext3 есть множество комментариев наподобие «Сильно надеюсь, что ошибка записи не произойдёт» в тех местах, где ошибки не обрабатываются.
NTFS находится где-то между ext3 и reiserfs. Авторы выяснили, что в ней есть множество встроенных проверок целостности, и она достаточно хорошо сообщает об ошибках пользователю. Однако, как и ext3, она игнорирует сбои записи.
В статье гораздо больше подробностей о конкретных режимах сбоев, однако в основном они представляют исторический интерес, так как многие баги были устранены.
Было бы здорово увидеть дополненную версию статьи, и на одной из презентаций кто-то из аудитории спросил, есть ли более актуальная информация. Выступающий ответил, что им было интересно узнать, как ситуация выглядит сейчас, но подобную работу сложно выполнить в научной среде, потому что аспиранты не хотят повторять уже сделанную ранее работу, что вполне логично, учитывая мотивацию, с которой они сталкиваются. Для повторения необходимо вложить много труда, почти столько же, сколько и для исходного исследования, но повторения работ практически не привлекают научного внимания. Это один из множества случаев, когда уровень мотивации для исследований очень плохо соотносится с влиянием этих исследований на реальную жизнь.
Здорово было бы воспроизвести сегодня ещё одну работу — Gunawi et al. с FAST 08. Эта статья развивает описанную выше, исследуя код обработки ошибок в различных файловых системах при помощи простого инструмента статического анализа, находящего случаи, когда ошибки игнорируются. «Игнорирование» в статье определяется достаточно вольно. Например, следующий код:
if (error) {
printk(“I have no idea how to handle this error\n”);
}
не считается игнорированием ошибки. Ошибки считаются игнорируемыми, если поток исполнения программы не зависит от кода ошибки, возвращённого функцией.
При помощи этого инструмента исследователи выяснили, что большинство файловых систем игнорирует множество кодов ошибок:
Рядом с проигнорированными ошибками они нашли подобные комментарии: «Надо ли возвращать какую-нибудь ошибку?», «Ошибка, пропустить блок и надеяться на лучшее», «Нет способа сообщения об ошибке, возвращённой от ext3_mark_inode_dirty() в пространство пользователя. Поэтому игнорируем её», «Примечание: todo: обработчик ошибок лога», «Здесь мы ничего не можем поделать с ошибкой», «На этом этапе просто игнорируем ошибку. Мы ничего не можем поделать, кроме как продолжать работу», «Retval игнорируется» и «Todo: обработать сбой».
Стоит заметить, что во многих случаях игнорирование ошибки — это симптом проблемы архитектуры, а не баг сам по себе (например, ext3 игнорировала ошибки записи при создании контрольных точек, потому что в ней нет никакого механизма восстановления). Но даже при этом авторы статьи обнаружили множество реальных багов.
Любая широко используемая файловая система содержит баги, вызывающие проблемы при состояниях ошибок, что приводит нас к двум вопросам. Могут ли инструменты восстановления надёжно устранять ошибки, и как часто происходят ошибки? Как они выполняют восстановление после этих проблем? Эти вопросы рассматриваются в статье Gunawi et al. для OSDI 08. Выяснилось, что стандартная утилита для проверки и восстановления файловых систем fsck «проверяет и чинит определённые указатели в неверном порядке… иногда файловую систему после этого даже невозможно будет смонтировать».
Мы уже знаем, что довольно сложно записывать файлы таким образом, чтобы обеспечить надёжность даже если лежащая в их основе файловая система безошибочна, что файловая система будет иметь баги, и что попытки починки повреждений файловой системы может ещё сильнее повредить или даже уничтожить её. Как часто происходят ошибки?
В статье Bairavasundaram et al. для SIGMETRICS '07 исследователи выяснили, что от 5% до 20% дисков за двухлетний период будет иметь хотя бы одну ошибку. Любопытно, что многие из них являются изолированными ошибками — 38% дисков с ошибками имеют только одну ошибку, а 80% — меньше 50 ошибок. Дальнейшее исследование повреждений выявило, что незаметное повреждение данных, обнаруживаемое только при проверке контрольных сумм, происходит ежегодно с 0,5% дисков, а одна чрезвычайно плохая модель показала повреждения в 4% дисков ежегодно.
Также стоит заметить, что исследователи обнаружили высокую локальность частотности ошибок дисков в некоторых моделях дисков. Например, была одна модель диска, имевшая высокую частоту ошибок в одном конкретном секторе, из-за чего многие виды RAID оказывались почти бесполезными для избыточного хранения.
Это исследование тоже стоит воспроизвести. Большинство исследований дисков фокусируются на частоте сбоев диска целиком, но если вас волнует повреждение данных, то ошибки на не отказавших дисках серьёзнее, чем поломка диска, которую гораздо проще обнаружить.
Файлы — это сложно. Батлер Лэмпсон писал, что когда они придумали в PARC потоки, блокировки и переменные условий, они считали, что создают модель программирования, которую может использовать каждый, но за десятки лет накопилось много доказательств того, что они ошибались. Мы накопили много свидетельств того, что люди плохо могут рассуждать о подобных проблемах, которые очень похожи на проблемы, возникающие при написании корректного кода для взаимодействия с современными файловыми системами. Лэмпсон предполагает, что наилучшим из известных решением было бы упаковать весь параллелизм в как можно меньший ящик, чтобы потом функция-мастер писала код в этом ящике. Если перенести это на файловые системы, то это как сказать разработчику приложения, что безопасная запись файлов настолько сложна, что её нужно реализовать через какую-то библиотеку и/или базу данных, а не прямыми системными вызовами.
Если вам нужно хорошее стандартное решение, то с точки зрения надёжности подойдёт Sqlite. Однако некоторые люди считают её слишком тяжёлой, если им нужно только абстрагирование на уровне файлов. На самом деле им нужно что-то типа polyfill для абстрагирования файлов, который работает поверх всех файловых систем без необходимости понимания разницы между различными конфигурациями (и даже разными версиями) каждой файловой системы. Так как такой библиотеки ещё не существует, если недостаточно уже имеющихся библиотек, то вам нужно будет проверять контрольную сумму данных, потому что будут возникать незамеченные ошибки и повреждения. Единственный вопрос заключается в том, будете ли вы распознавать ошибки и уничтожает ли ваш формат записи только одну запись при повреждении, или уничтожает всю базу данных. Насколько я могу судить, большинство разработчиков десктопных клиентов электронной почты выбрали путь уничтожения всей электронной почты при возникновении повреждения.
Эти исследования также доносят до сознания то, что традиционного тестирования недостаточно. Во многих случаях авторы статьи писали относительно простой инструмент и находили огромное количество ошибок. Для написания инструментов не требуется никакой глубокой магии computer science. Инструмент проверки передачи сообщений об ошибках из статьи, нашедший кучу багов в обработке ошибок файловыми системами, имел размер всего 4 тысячи LOC. Если прочитать статью, то становится видно, что авторы заметили большое количество недостатков инструмента, вызванных его простотой, но несмотря на эти недостатки, он смог найти множество реальных багов. Для своей последней работы я писал очень приблизительно похожий инструмент для тестирования инвариантов, и он в буквальном смысле занимал две страницы кода. В нём даже не было настоящего парсера (он просто построчно проходил по файлам и находил простые ошибки, которые легко обнаружить при помощи стейт-машины и регулярных выражений), но он нашёл достаточное количество багов, что оправдал время, потраченное на его разработку, после первого же запуска.
Почти в каждом встреченном мной программном проекте есть очень много простых в тестировании аспектов. Даже очень простые случайное тестирование, статический анализ и внесение ошибок могут оправдать потраченное на них время практически после первого их запуска.
Наверно, я рассказал меньше чем о 20% представленных в упомянутых в статье материалах. Расскажу ещё немного о другой интересной информации, которую можно найти в этих и других статьях.
Pillai et al., OSDI '14: в этой статье гораздо подробнее рассказывается о том, что необходимо для повторяемости сбоев, чем в моём посте. Также в ней достаточно подробно рассказано о том, как происходят сбои приложений, в том числе диаграммы трассировок, показывающие, какие ложные допущения были внедрены при каждой трассировке.
Chidambara et al., FAST '12: одни и те же примитивы файловых систем отвечают и за постоянство, и за упорядочивание. Авторы предлагают альтернативные примитивы, разделяющие эти аспекты и позволяющие повысить производительность с сохранением безопасности.
Rajimwale et al. DSN '01: наверно, не стоит использовать диски, игнорирующие директивы сброса на диск, но если вы ими пользуетесь, то вот протокол, заставляющий эти диски сбрасывать данные на диск при помощи обычных операций файловых систем. Как и можно ожидать, производительность его весьма низка.
Prabhakaran et al. SOSP '05: это гораздо более подробное описание ответов файловых систем на ошибки, чем это изложено в моём посте. Авторы также рассматривают JFS — файловую систему IBM для AIX. Хотя она была спроектирована для систем с высокой надёжностью,, на самом деле она не особо надёжнее альтернатив. Дополнительная информация рассмотрена, среди прочих источников, в DSN '08, StorageSS '06, DSN '06, FAST '08, and USENIX '09.
Gunawi et al. FAST '08: снова гораздо более подробная статья о ситуациях игнорирования ошибок и о том, как авторы писали свои инструменты. Также в статье есть графы вызовов, дающие приблизительное представление об уровне сложности, связанном с работой файловых систем. Особенно хаотичен граф вызовов XFS: один из авторов рассказал на презентации, что разработчик XFS сообщил ему, что с XFS было интересно работать, потому что в ней использовались любые возможные оптимизации вне зависимости от того, насколько хаотичным становился код.
Bairavasundaram et al. SIGMETRICS '07: множество информации о локальности дисковых ошибок и их вероятности с течением времени, не раскрытой в моём посте. В последующей статье для FAST08 ещё больше подробностей.
Gunawi et al. OSDI '08: в этой статье гораздо больше подробностей о том, когда не работает fsck. В презентации один из авторов говорит, что fsck — единственная программа, оскорбившая его. Похоже, что если у вас есть повреждённый указатель на суперблок, fsck уничтожает суперблок (что может привести к немонтируемости диска) и сообщает что-то вроде: «глупый, запускать fsck нужно для смонтированного диска», а потом завершает работу. В статье авторы, по сути, заново реализовали весь fsck на основе декларативной модели, и выяснили, что декларативная версия короче, проще для понимания и гораздо легче расширяема, но ценой небольшого снижения скорости.
Ошибки памяти выходят за рамки этого поста, но повреждение памяти может приводить к повреждению диска. Это особенно раздражает, потому что повреждение памяти может привести к тому, что вы получите контрольную сумму плохих данных и запишете плохую контрольную сумму. Также могут повреждаться указатели памяти, что часто приводит к очень плохим результатам. Подробнее о том, как этому подвержена ZFS, можно прочитать в Zhang et al. FAST '10 paper. Существует мем, что ZFS безопасна с точки зрения повреждения памяти, потому что проверяет контрольные суммы, но авторы статьи выяснили, что критически важные вещи, хранящиеся в памяти, не подвергаются проверке контрольных сумм, и в реальности ошибки памяти могут привести к повреждению данных.
Разработчики sqlite серьёзно относятся к документации и тестированию. Если бы я хотел написать надёжное десктопное приложение, то начал бы с чтения документации sqlite, а затем поговорил бы с разработчиками ядра. Если бы я хотел написать надёжное распределённое приложение, то начал бы с трудоустройства в Google, а затем прочитал бы документацию по проекту и постмортемы GFS, Colossus, Spanner и т.д. Ладно, я просто шучу.
Мы совершенно не рассматривали формальные методы, но существует множество попыток формальной верификации свойств файловых систем, например, SibylFS.
Этот список неполон, это просто перечень статей, которые показались мне интересными.
Дополнение: многие люди прочитали пост и предложили в первом примере с файлами использовать гораздо более простой протокол копирования файла, который нужно изменить, во временный файл, затем изменить временный файл, а затем переименовать его, чтобы временный файл переписал исходный. На самом деле, это, пожалуй, самый популярный комментарий к моему посту. Если вы считаете, что это решит проблему, то я попрошу вас остановиться на пять секунд и подумать о проблемах этой методики.
Главные проблемы:
То, что многие люди посчитали это простым решением проблемы, доказывает, что люди часто недооценивают эту проблему, даже если ты чётко говоришь, что люди обычно недооценивают эту проблему!
В этом посте воспроизводятся некоторые из результатов этих статей в современных на 2017 год файловых системах.
В этой текстовой версии доклада содержится множество более новых результатов и более подробно рассматриваются аппаратные проблемы.

 habr.com
habr.com
Какие же виды сбоев могут возникать? Вероятно, проще всего начать со свойства постоянства при сбоях (поддержания постоянного состояния даже в случае сбоя), потому что мы можем допустить, что всё, от файловой системы до диска, работает правильно; давайте сначала рассмотрим это свойство.
Постоянство при сбоях
Pillai et al. написали для OSDI '14 статью и презентацию о том, как сложно сохранять данные без повреждения и утери данных. [Прим. пер.: пост был написан в конце 2015 года.]
Давайте рассмотрим простой пример того, что необходимо для сохранения данных способом, защищённым от сбоев. Допустим, у нас есть файл, содержащий текст a foo и мы хотим обновить этот файл, чтобы он содержал a bar. Похоже, что для выполнения этой операции идеально подходит функция pwrite. Она получает дескриптор файла, то, что мы хотим записать, длину и смещение. То есть мы можем попробовать выполнить:
pwrite([file], “bar”, 3, 2) // write 3 bytes at offset 2
Что произойдёт? Если всё будет в порядке, то файл будет содержать a bar, но если во время записи произойдёт сбой, мы получим a boo, a far, или любую другую комбинацию. Стоит заметить, что можно рассмотреть этот пример с секторами или блоками, а не с символами/байтами.
Если нам нужна атомарность (то есть мы хотим получить или a foo, или a bar, и никаких промежуточных результатов), то можно использовать стандартную методику создания копии изменяемых данных в файл журнала отмены (undo log), изменить «реальный» файл, а затем удалить файл журнала. Если произойдёт сбой, то мы восстановимся из журнала. Можно написать нечто подобное:
creat(/dir/log);
write(/dir/log, “2,3,foo”, 7);
pwrite(/dir/orig, “bar”, 3, 2);
unlink(/dir/log);
Это должно позволить восстановить файл после сбоя без повреждения данных при помощи журнала отмены; по крайней мере, если мы используем ext3 и примонтировали диск с data=journal. Но нам не повезёт, если, как и большинство людей, мы используем стандартный ключ — со стандартным data=ordered. [Оказалось, что некоторые коммерчески поддерживаемые дистрибутивы поддерживают только data=ordered. Да, и когда я говорил, что по умолчанию используется data=ordered, то это было справедливо только до версии 2.6.30. После 2.6.30 появилась опция конфигурации CONFIG_EXT3_DEFAULTS_TO_ORDERED. Если она не установлена, по умолчанию используется data=writeback.] Порядок системных вызовов write и pwrite может быть изменён, из-за чего запись в orig произойдёт до записи в журнал, из-за чего теряется весь смысл создания журнала. Это можно исправить.
creat(/dir/log);
write(/dir/log, “2, 3, foo”);
fsync(/dir/log); // don't allow write to be reordered past pwrite
pwrite(/dir/orig, 2, “bar”);
fsync(/dir/orig);
unlink(/dir/log);
Этот код заставит выполнять действия в правильном порядке, по крайней мере, если мы используем ext3 с data=journal или data=ordered. Если мы используем data=writeback, то сбой во время выполнения в журнал операций write или fsync может оставить журнал в состоянии, при котором размер файла был изменён под запись «bar», но данные не записаны, то есть журнал будет содержать случайный мусор. Так происходит потому, что при data=writeback журналируются метаданные, но не операции с данными, то есть операции с данными (например, запись данных в файл) не будут упорядочены относительно операций с метаданными (например, изменения размера файла для записи).
Мы можем исправить это, добавив при создании журнала к нему контрольную сумму. Если содержимое log не включает в себя правильную контрольную сумму, то мы будем знать, что попали в описанную выше ситуацию.
creat(/dir/log);
write(/dir/log, “2, 3, [checksum], foo”); // add checksum to log file
fsync(/dir/log);
pwrite(/dir/orig, 2, “bar”);
fsync(/dir/orig);
unlink(/dir/log);
Это позволит обеспечить безопасность, по крайней мере, в текущий конфигурациях ext3. Но файловая система вполне может оказаться в состоянии, когда журнал никогда не создаётся, за исключением случаев, когда мы передаём fsync родительской папке.
creat(/dir/log);
write(/dir/log, “2, 3, [checksum], foo”);
fsync(/dir/log);
fsync(/dir); // fsync parent directory of log file
pwrite(/dir/orig, 2, “bar”);
fsync(/dir/orig);
unlink(/dir/log);
Это должно предотвратить повреждение любой файловой системы Linux, но если мы хотим гарантировать, что файл на самом деле содержит «bar», нам нужно добавить в конце ещё один fsync.
creat(/dir/log);
write(/dir/log, “2, 3, [checksum], foo”);
fsync(/dir/log);
fsync(/dir);
pwrite(/dir/orig, 2, “bar”);
fsync(/dir/orig);
unlink(/dir/log);
fsync(/dir);
Благодаря этому поведение будет согласованным, а операция действительно изменит файл после её завершения, если мы предполагаем, что fsync на самом деле выполняет сброс данных на диск. У OS X и некоторых версий ext3 функция fsync на самом деле не сбрасывает данные на диск. Для сброса на диск OS X требует fcntl(F_FULLFSYNC), а некоторые версии ext3 в качестве оптимизации сбрасывают на диск только при изменении inode (что происходит только раз в секунду при записи в один и тот же файл, потому что mtime дескриптора inode имеет степень разбиения в одну секунду).
Даже если мы предположим, что fsync даёт команду сброса на диск, некоторые диски игнорируют директивы сброса по той же причине, по которой fsync модифицирован в OS X и в некоторых версиях ext3 — чтобы выглядеть лучше в бенчмарках. В своём посте я не буду это учитывать, но есть статья Rajimwale et al. для DSN '11 и другие работы, в которых рассматривается эта проблема.
Семантика файловых систем
После изучения ext2, ext3, ext4, btrfs и xfs авторы статьи выяснили, что есть существенные отличия в написании кода для обеспечения постоянства. Они написали инструмент, собирающий трассировки файловых систем на уровне блоков, и использовали его, чтобы выяснить, какие свойства не учитываются в конкретных файловых системах. Авторы осторожно замечают, что они могли определить, только отсутствие поддержки свойств — если они не обнаружили нарушения свойства, это ещё не значит, что оно поддерживается.
Крестиком обозначены неподдерживаемые свойства. Свойства атомарности означают, что если, например, отсутствует X для single sector overwrite, то запись в отдельный сектор является атомарной. Авторы сообщают, что атомарность перезаписи отдельного сектора иногда продиктована свойством используемого диска, и что работа таки файловых систем на некоторых дисках не обеспечит атомарности для отдельных секторов. Свойства упорядоченности тоже понятны из их названия, например, X в строке «Overwrite -> Any op» означает, что для какой-то операции порядок перезаписи может быть изменён.
После создания инструмента тестирования свойств файловых систем они создали инструмент для проверки того, используют ли приложения любые потенциально некорректные свойства файловых систем. Так как инварианты зависят от конкретных приложений, авторы составили таблицы для каждого протестированного приложения.
Авторы выявили проблемы у большинства протестированных приложений, в том числе и у таких, на работу которых пользователи надеются, например, LevelDB, HDFS, Zookeeper и git. В докладе один из авторов заметил, что разработчики sqlite имеют очень глубокое понимание этих проблем, но даже этого не хватило для предотвращения всех багов. Этот докладчик также заметил, что особенно плохи были системы контроля версий, и что разработчики довольно небрежны, поэтому авторам очень легко было найти множество проблем в их инструментах. Самым распространённым классом ошибок было некорректное допущение упорядочивания между системными вызовами. Вторым по распространённости классом ошибок было допущение атомарности системных вызовов. [Как известные проблемы задокументированы случаи, когда требуется атомарность перезаписи, и во всех этих случаях предполагается одноблоковая, а не многоблоковая атомарность. Для сравнения: во многих приложениях (LevelDB, Mercurial и HSQLDB) есть серьёзные баги повреждения данных, возникающие из-за того, что атомарным считается дополнение записи (append). Похоже, это косвенный результат использования протокола обновления, при котором модификации журналируются через append, после чего журналированные данные записываются через перезапись. Разработчики приложений тщательно проверяют и обрабатывают ошибки данных, однако ошибки в файле журнала часто остаются незамеченными. В статье обсуждается множество других классов ошибок, и если вы работаете над приложением, которое записывает файлы, я рекомендую прочитать её, чтобы узнать подробности.] По сути, с теми же проблемами люди сталкиваются при реализации многопоточного программирования. Правильно рассуждать о поведении изменения порядка и правильно вставлять ограничения сложно. Но даже несмотря на то, что параллельность общей памяти считается сложной проблемой, требующей большого внимания, запись в файлы не воспринимается аналогичным образом, хотя во многих смыслах она намного сложнее.
Тут также стоит заметить, что хотя семантика btrfs не менее надёжна, чем у ext3/ext4, гораздо больше приложений повреждает данные поверх btrfs, потому что разработчики не привыкли к кодированию для файловых систем, позволяющих переупорядочивать операции с каталогами (наверно, самой свежей и популярной файловой системой, позволяющей такое переупорядочивание, является ext2). Вероятно, мы увидим схожий уровень подверженности багам, когда люди начнут пользоваться накопителями NVRAM, имеющими атомарность на байтовом уровне. Люди почти всегда проводят только несколько тестов, чтобы убедиться, что всё работает, а не проверяют, пишут ли они код для того, что допустимо в файловой системе POSIX.
Семантика упорядочивания аппаратной памяти обычно хорошо задокументирована, что упрощает точное определение того, какие операции могут быть переупорядочены с какими другими операциями, и какие операции являются атомарными. Для сравнения, вот manpage ext про эти три режима данных:
journal: все данные коммитятся в журнал, прежде чем быть записанными в основную файловую систему.
ordered: режим по умолчанию. Все данные принудительно передаются в основную файловую систему до того, как метаданные коммитятся в журнал.
writeback: порядок данных не сохраняется — данные могут записываться в основную файловую систему после того, как их метаданные закоммичены в журнал. По слухам, что этот вариант обеспечивает наибольшую пропускную способность. Он гарантирует внутреннюю целостность файловой системы, однако может привести к тому, что после сбоя и восстановления журнала в файлах будут появляться старые данные.
Страница manpage в буквальном смысле ссылается на слухи. Вот такой у нас уровень документации. Если вернуться к примеру, где нам пришлось добавить fsync между write(/dir/log, “2, 3, foo”) и pwrite(/dir/orig, 2, “bar”) для предотвращения изменения порядка, то я не думаю, что необходимость fsync очевидна из описания на manpage. Если посмотреть на представленную выше manpage об упорядочивании аппаратной памяти, то она конкретно определяет семантику упорядочивания, и совершенно не полагается на слухи.
Не хочу сказать, что семантика файловых систем нигде хорошо не задокументирована. Изучая lwn и LKML, можно получить хорошее представление о том, как всё работает. Но разбираться во всём этом достаточно сложно, поэтому по-прежнему очень популярны долгие неопределённые обсуждения того, как это работает. Большая часть информации там ошибочна, и даже если информация была правильна на момент публикации, часто она является устаревшей.
Просматривая архивы, я часто встречал ссылки пост 2005 года как подтверждение того, что fsync в OS X такая же, как и fsync в Linux, и что fcntl(F_FULLFSYNC) в OS X более безопасна, чем всё, что доступно в Linux. Я не уверен, что это было справедливо даже в те времена для ядра 2.4, однако это было правдой для ядра 2.6. Но примерно с 2008 года Linux 2.6 с ext3 выполнял полный сброс на диск при каждом fsync (если это поддерживает диск, а файловая система не была специально настроена с отключением барьеров).
Ещё одна проблема заключается в том, что часто встречаются подобные диалоги:
Разработчик 1: лично мне важна целостность метаданных, а в документации ext3 написано, что журнал защищает их целостность. Исключением являются повреждённые устройства хранения, и для них всё равно нужно запускать fsck.
Разработчик 2: как заявляли авторы ext3 в течение многих лет, всё равно нужно периодически запускать fsck.
Разработчик 1: где это задокументировано?
Разработчик 2: в архивах списка рассылки linux-kernel.
Разработчик 3: примерно 6-8 лет назад, в моей почтовой рассылке.
Где это задокументировано? А, в каком-то посте списке рассылки, созданном 6-8 лет назад (то есть сегодня это уже 12-14 лет назад). Я не хочу обижать разработчиков файловых систем. Прочитанные мной посты разработчиков ФС довольно вежливы, учитывая репутацию LKML; они уделяли много времени ответам на простые вопросы, и я впечатлён тем, насколько терпеливы опытные разработчики файловых систем с задающими вопросы, однако непосвящённым сложно просмотреть посты в списках рассылки за полтора десятка лет и определить, что по-прежнему справедливо, а что устарело.
В своём докладе на OSDI 2014 авторы обсуждаемой нами статьи говорили, что когда они сообщали о найденных багах, разработчики часто отвечали «POSIX не позволяет файловым системам этого делать», но не могли указать на конкретную документацию по POSIX в подтверждение своих слов. Если вы следили за Jepsen Кайла Кингсбери, то это может показаться вам знакомым, только разработчики отвечают не «сети этого не могут», а «файловые системы этого не могут». Мне кажется, это вполне понятно, учитывая количество ложных сведений. Сам я не разработчик файловых систем, поэтому был бы удивлён, если бы в этом посте не нашёлся хотя бы один баг.
Корректность файловых систем
Мы уже столкнулись с высоким уровнем сложности правильного сохранения данных, но это была только вершина айсберга. Ранее мы предполагали, что диск работает правильно, или, по крайней мере, что файловая система при помощи SMART или какой-то другой системы мониторинга может определить, когда на диске есть ошибки. Я всегда считал, что это так, пока не начал исследовать вопрос, и это предположение оказалось совершенно неверным.
В статье Prabhakaran et al. для SOSP 05 достаточно подробно исследована реакция файловых систем на дисковые ошибки. Авторы создали слой внесения ошибок, позволяющий вносить дисковые ошибки, а затем запускали chdir, chroot, stat, open, write и т.п., чтобы посмотреть, что произойдёт дальше.
Среди ext3, reiserfs и NTFS лучшей в обработке ошибок оказалась reiserfs; к тому же, похоже, это была единственная файловая система, в которой на этапе проектирования ошибки считались «гражданами первого класса». Она практически всегда сообщала пользователю об ошибках при чтении и вызывала panic при сбоях записи, что приводило к перезапуску и восстановлению. Эта политика позволяет файловой системе элегантно обрабатывать сбои чтения и избегать повреждения данных при сбоях записи. Однако авторы нашли множество несогласованностей и багов. Например, reiserfs некорректно обрабатывает ошибки чтения в непрямых блоках и создаёт утечку места, а один определённый тип сбоя записи не мешает reiserfs обновить журнал и выполнить коммит транзакции, что может привести к повреждению данных.
Reiserfs — это ещё хороший пример. Авторы выяснили, что ext3 в большинстве случаев игнорировала ошибки записи и представляла файловую систему как read-only в большинстве случаев сбоев чтения. Это совершенно непохоже на ту политику, которая нам нужна. Игнорирование сбоев записи легко может привести к повреждению данных, а перемонтирование файловой системы как read-only — слишком сильная реакция, если ошибка чтения была переходной ошибкой (переходные ошибки встречаются часто). Кроме того, из всех трёх файловых систем ext3 обеспечивала наименьшую проверку целостности и с наибольшей вероятностью могла не распознать ошибку. На презентации один из авторов сказал, что в коде ext3 есть множество комментариев наподобие «Сильно надеюсь, что ошибка записи не произойдёт» в тех местах, где ошибки не обрабатываются.
NTFS находится где-то между ext3 и reiserfs. Авторы выяснили, что в ней есть множество встроенных проверок целостности, и она достаточно хорошо сообщает об ошибках пользователю. Однако, как и ext3, она игнорирует сбои записи.
В статье гораздо больше подробностей о конкретных режимах сбоев, однако в основном они представляют исторический интерес, так как многие баги были устранены.
Было бы здорово увидеть дополненную версию статьи, и на одной из презентаций кто-то из аудитории спросил, есть ли более актуальная информация. Выступающий ответил, что им было интересно узнать, как ситуация выглядит сейчас, но подобную работу сложно выполнить в научной среде, потому что аспиранты не хотят повторять уже сделанную ранее работу, что вполне логично, учитывая мотивацию, с которой они сталкиваются. Для повторения необходимо вложить много труда, почти столько же, сколько и для исходного исследования, но повторения работ практически не привлекают научного внимания. Это один из множества случаев, когда уровень мотивации для исследований очень плохо соотносится с влиянием этих исследований на реальную жизнь.
Здорово было бы воспроизвести сегодня ещё одну работу — Gunawi et al. с FAST 08. Эта статья развивает описанную выше, исследуя код обработки ошибок в различных файловых системах при помощи простого инструмента статического анализа, находящего случаи, когда ошибки игнорируются. «Игнорирование» в статье определяется достаточно вольно. Например, следующий код:
if (error) {
printk(“I have no idea how to handle this error\n”);
}
не считается игнорированием ошибки. Ошибки считаются игнорируемыми, если поток исполнения программы не зависит от кода ошибки, возвращённого функцией.
При помощи этого инструмента исследователи выяснили, что большинство файловых систем игнорирует множество кодов ошибок:
| По % сломанных | По наруш./тыс. строк | |||
| Место | ФС | Доля | ФС | наруш./тыс. строк |
| 1 | IBM JFS | 24,4 | ext3 | 7,2 |
| 2 | ext3 | 22,1 | IBM JFS | 5,6 |
| 3 | JFFS v2 | 15,7 | NFS Client | 3,6 |
| 4 | NFS Client | 12,9 | VFS | 2,9 |
| 5 | CIFS | 12,7 | JFFS v2 | 2,2 |
| 6 | MemMgmt | 11,4 | CIFS | 2,1 |
| 7 | ReiserFS | 10,5 | MemMgmt | 2,0 |
| 8 | VFS | 8,4 | ReiserFS | 1,8 |
| 9 | NTFS | 8,1 | XFS | 1,4 |
| 10 | XFS | 6,9 | NFS Server | 1,2 |
Рядом с проигнорированными ошибками они нашли подобные комментарии: «Надо ли возвращать какую-нибудь ошибку?», «Ошибка, пропустить блок и надеяться на лучшее», «Нет способа сообщения об ошибке, возвращённой от ext3_mark_inode_dirty() в пространство пользователя. Поэтому игнорируем её», «Примечание: todo: обработчик ошибок лога», «Здесь мы ничего не можем поделать с ошибкой», «На этом этапе просто игнорируем ошибку. Мы ничего не можем поделать, кроме как продолжать работу», «Retval игнорируется» и «Todo: обработать сбой».
Стоит заметить, что во многих случаях игнорирование ошибки — это симптом проблемы архитектуры, а не баг сам по себе (например, ext3 игнорировала ошибки записи при создании контрольных точек, потому что в ней нет никакого механизма восстановления). Но даже при этом авторы статьи обнаружили множество реальных багов.
Восстановление после ошибок
Любая широко используемая файловая система содержит баги, вызывающие проблемы при состояниях ошибок, что приводит нас к двум вопросам. Могут ли инструменты восстановления надёжно устранять ошибки, и как часто происходят ошибки? Как они выполняют восстановление после этих проблем? Эти вопросы рассматриваются в статье Gunawi et al. для OSDI 08. Выяснилось, что стандартная утилита для проверки и восстановления файловых систем fsck «проверяет и чинит определённые указатели в неверном порядке… иногда файловую систему после этого даже невозможно будет смонтировать».
Мы уже знаем, что довольно сложно записывать файлы таким образом, чтобы обеспечить надёжность даже если лежащая в их основе файловая система безошибочна, что файловая система будет иметь баги, и что попытки починки повреждений файловой системы может ещё сильнее повредить или даже уничтожить её. Как часто происходят ошибки?
Частота возникновения ошибок
В статье Bairavasundaram et al. для SIGMETRICS '07 исследователи выяснили, что от 5% до 20% дисков за двухлетний период будет иметь хотя бы одну ошибку. Любопытно, что многие из них являются изолированными ошибками — 38% дисков с ошибками имеют только одну ошибку, а 80% — меньше 50 ошибок. Дальнейшее исследование повреждений выявило, что незаметное повреждение данных, обнаруживаемое только при проверке контрольных сумм, происходит ежегодно с 0,5% дисков, а одна чрезвычайно плохая модель показала повреждения в 4% дисков ежегодно.
Также стоит заметить, что исследователи обнаружили высокую локальность частотности ошибок дисков в некоторых моделях дисков. Например, была одна модель диска, имевшая высокую частоту ошибок в одном конкретном секторе, из-за чего многие виды RAID оказывались почти бесполезными для избыточного хранения.
Это исследование тоже стоит воспроизвести. Большинство исследований дисков фокусируются на частоте сбоев диска целиком, но если вас волнует повреждение данных, то ошибки на не отказавших дисках серьёзнее, чем поломка диска, которую гораздо проще обнаружить.
Заключение
Файлы — это сложно. Батлер Лэмпсон писал, что когда они придумали в PARC потоки, блокировки и переменные условий, они считали, что создают модель программирования, которую может использовать каждый, но за десятки лет накопилось много доказательств того, что они ошибались. Мы накопили много свидетельств того, что люди плохо могут рассуждать о подобных проблемах, которые очень похожи на проблемы, возникающие при написании корректного кода для взаимодействия с современными файловыми системами. Лэмпсон предполагает, что наилучшим из известных решением было бы упаковать весь параллелизм в как можно меньший ящик, чтобы потом функция-мастер писала код в этом ящике. Если перенести это на файловые системы, то это как сказать разработчику приложения, что безопасная запись файлов настолько сложна, что её нужно реализовать через какую-то библиотеку и/или базу данных, а не прямыми системными вызовами.
Если вам нужно хорошее стандартное решение, то с точки зрения надёжности подойдёт Sqlite. Однако некоторые люди считают её слишком тяжёлой, если им нужно только абстрагирование на уровне файлов. На самом деле им нужно что-то типа polyfill для абстрагирования файлов, который работает поверх всех файловых систем без необходимости понимания разницы между различными конфигурациями (и даже разными версиями) каждой файловой системы. Так как такой библиотеки ещё не существует, если недостаточно уже имеющихся библиотек, то вам нужно будет проверять контрольную сумму данных, потому что будут возникать незамеченные ошибки и повреждения. Единственный вопрос заключается в том, будете ли вы распознавать ошибки и уничтожает ли ваш формат записи только одну запись при повреждении, или уничтожает всю базу данных. Насколько я могу судить, большинство разработчиков десктопных клиентов электронной почты выбрали путь уничтожения всей электронной почты при возникновении повреждения.
Эти исследования также доносят до сознания то, что традиционного тестирования недостаточно. Во многих случаях авторы статьи писали относительно простой инструмент и находили огромное количество ошибок. Для написания инструментов не требуется никакой глубокой магии computer science. Инструмент проверки передачи сообщений об ошибках из статьи, нашедший кучу багов в обработке ошибок файловыми системами, имел размер всего 4 тысячи LOC. Если прочитать статью, то становится видно, что авторы заметили большое количество недостатков инструмента, вызванных его простотой, но несмотря на эти недостатки, он смог найти множество реальных багов. Для своей последней работы я писал очень приблизительно похожий инструмент для тестирования инвариантов, и он в буквальном смысле занимал две страницы кода. В нём даже не было настоящего парсера (он просто построчно проходил по файлам и находил простые ошибки, которые легко обнаружить при помощи стейт-машины и регулярных выражений), но он нашёл достаточное количество багов, что оправдал время, потраченное на его разработку, после первого же запуска.
Почти в каждом встреченном мной программном проекте есть очень много простых в тестировании аспектов. Даже очень простые случайное тестирование, статический анализ и внесение ошибок могут оправдать потраченное на них время практически после первого их запуска.
Приложение
Наверно, я рассказал меньше чем о 20% представленных в упомянутых в статье материалах. Расскажу ещё немного о другой интересной информации, которую можно найти в этих и других статьях.
Pillai et al., OSDI '14: в этой статье гораздо подробнее рассказывается о том, что необходимо для повторяемости сбоев, чем в моём посте. Также в ней достаточно подробно рассказано о том, как происходят сбои приложений, в том числе диаграммы трассировок, показывающие, какие ложные допущения были внедрены при каждой трассировке.
Chidambara et al., FAST '12: одни и те же примитивы файловых систем отвечают и за постоянство, и за упорядочивание. Авторы предлагают альтернативные примитивы, разделяющие эти аспекты и позволяющие повысить производительность с сохранением безопасности.
Rajimwale et al. DSN '01: наверно, не стоит использовать диски, игнорирующие директивы сброса на диск, но если вы ими пользуетесь, то вот протокол, заставляющий эти диски сбрасывать данные на диск при помощи обычных операций файловых систем. Как и можно ожидать, производительность его весьма низка.
Prabhakaran et al. SOSP '05: это гораздо более подробное описание ответов файловых систем на ошибки, чем это изложено в моём посте. Авторы также рассматривают JFS — файловую систему IBM для AIX. Хотя она была спроектирована для систем с высокой надёжностью,, на самом деле она не особо надёжнее альтернатив. Дополнительная информация рассмотрена, среди прочих источников, в DSN '08, StorageSS '06, DSN '06, FAST '08, and USENIX '09.
Gunawi et al. FAST '08: снова гораздо более подробная статья о ситуациях игнорирования ошибок и о том, как авторы писали свои инструменты. Также в статье есть графы вызовов, дающие приблизительное представление об уровне сложности, связанном с работой файловых систем. Особенно хаотичен граф вызовов XFS: один из авторов рассказал на презентации, что разработчик XFS сообщил ему, что с XFS было интересно работать, потому что в ней использовались любые возможные оптимизации вне зависимости от того, насколько хаотичным становился код.
Bairavasundaram et al. SIGMETRICS '07: множество информации о локальности дисковых ошибок и их вероятности с течением времени, не раскрытой в моём посте. В последующей статье для FAST08 ещё больше подробностей.
Gunawi et al. OSDI '08: в этой статье гораздо больше подробностей о том, когда не работает fsck. В презентации один из авторов говорит, что fsck — единственная программа, оскорбившая его. Похоже, что если у вас есть повреждённый указатель на суперблок, fsck уничтожает суперблок (что может привести к немонтируемости диска) и сообщает что-то вроде: «глупый, запускать fsck нужно для смонтированного диска», а потом завершает работу. В статье авторы, по сути, заново реализовали весь fsck на основе декларативной модели, и выяснили, что декларативная версия короче, проще для понимания и гораздо легче расширяема, но ценой небольшого снижения скорости.
Ошибки памяти выходят за рамки этого поста, но повреждение памяти может приводить к повреждению диска. Это особенно раздражает, потому что повреждение памяти может привести к тому, что вы получите контрольную сумму плохих данных и запишете плохую контрольную сумму. Также могут повреждаться указатели памяти, что часто приводит к очень плохим результатам. Подробнее о том, как этому подвержена ZFS, можно прочитать в Zhang et al. FAST '10 paper. Существует мем, что ZFS безопасна с точки зрения повреждения памяти, потому что проверяет контрольные суммы, но авторы статьи выяснили, что критически важные вещи, хранящиеся в памяти, не подвергаются проверке контрольных сумм, и в реальности ошибки памяти могут привести к повреждению данных.
Разработчики sqlite серьёзно относятся к документации и тестированию. Если бы я хотел написать надёжное десктопное приложение, то начал бы с чтения документации sqlite, а затем поговорил бы с разработчиками ядра. Если бы я хотел написать надёжное распределённое приложение, то начал бы с трудоустройства в Google, а затем прочитал бы документацию по проекту и постмортемы GFS, Colossus, Spanner и т.д. Ладно, я просто шучу.
Мы совершенно не рассматривали формальные методы, но существует множество попыток формальной верификации свойств файловых систем, например, SibylFS.
Этот список неполон, это просто перечень статей, которые показались мне интересными.
Дополнение: многие люди прочитали пост и предложили в первом примере с файлами использовать гораздо более простой протокол копирования файла, который нужно изменить, во временный файл, затем изменить временный файл, а затем переименовать его, чтобы временный файл переписал исходный. На самом деле, это, пожалуй, самый популярный комментарий к моему посту. Если вы считаете, что это решит проблему, то я попрошу вас остановиться на пять секунд и подумать о проблемах этой методики.
Главные проблемы:
- переименование не атомарно при сбое. POSIX говорит, что переименование атомарно, но это применимо только к стандартной работе, но не к сбоям.
- даже если эта методика сработает, её производительность очень низка
- как работать с жёсткими ссылками (hardlinks)?
- метаданные могут быть утеряны; в некоторых файловых системах их можно сохранить при помощи ioctls, но теперь у вас будет специфичный для файловой системы код только для случаев без сбоев
- и т.д.
То, что многие люди посчитали это простым решением проблемы, доказывает, что люди часто недооценивают эту проблему, даже если ты чётко говоришь, что люди обычно недооценивают эту проблему!
В этом посте воспроизводятся некоторые из результатов этих статей в современных на 2017 год файловых системах.
В этой текстовой версии доклада содержится множество более новых результатов и более подробно рассматриваются аппаратные проблемы.
- Оказалось, что некоторые коммерчески поддерживаемые дистрибутивы поддерживают только data=ordered. Да, и когда я говорил, что по умолчанию используется data=ordered, то это было справедливо только до версии 2.6.30. После 2.6.30 появилась опция конфигурации CONFIG_EXT3_DEFAULTS_TO_ORDERED. Если она не установлена, по умолчанию используется data=writeback.
- Как известные проблемы задокументированы случаи, когда требуется атомарность перезаписи, и во всех этих случаях предполагается одноблоковая, а не многоблоковая атомарность. Для сравнения: во многих приложениях (LevelDB, Mercurial и HSQLDB) есть серьёзные баги повреждения данных, возникающие из-за того, что атомарным считается дополнение записи (append).
Похоже, это косвенный результат использования протокола обновления, при котором модификации журналируются через append, после чего журналированные данные записываются через перезапись. Разработчики приложений тщательно проверяют и обрабатывают ошибки данных, однако ошибки в файле журнала часто остаются незамеченными.
В статье обсуждается множество других классов ошибок, и если вы работаете над приложением, которое записывает файлы, я рекомендую прочитать её, чтобы узнать подробности.
Работа с файлами — это сложно
Я уже много лет не пользовался десктопным клиентом электронной почты. Ни один из них не может справиться с объёмом получаемой мной почты, по крайней мере один раз не повредив мой почтовый ящик. Pine,...
habr.com