Привет! Меня зовут Артур Карапетян, я Product Owner в Starfish24. Мы помогаем российским ретейлерам управлять жизненным циклом заказа, выстраивать и контролировать логику обработки с помощью OMS-системы. В общем, сложные омниканальные заказы — это про нас.
В конце 2018 года я пришел в тогда еще сырой стартап из 15 человек на должность Frontend-разработчика и не подозревал, с чем мне придется столкнуться в следующие три года. Я видел, как один человек выполнял роли сразу трех специалистов, как быстро выгорали новички, и как два человека обрабатывали по 1 000+ инцидентов после релиза.
Каждый ретейлер хочет непрерывного развития своего бизнеса: добавление новых модулей в систему, автоматизацию процессов, интеграцию с новыми каналами продаж. Мы тоже за развитие, но когда клиентов и задач становится много, все костыльные процессы, которые хоть как-то держались на маленьких объемах, начинают с грохотом падать, а люди — выгорать.
Сейчас, уже в роли Product Owner, я слежу за тем, чтобы наш продукт шел туда, куда нужно, а все доработки только развивали продукт, а не мешали ему. Весь 2022 год я с коллегами внедрял новые регламенты по процессам и хочу поделиться с другими продуктовыми командами нашим опытом. Расскажу, как мы за год трижды пересмотрели подход к развитию продукта и клиентским задачам. И покажу, почему к самым очевидным вещам приходишь только спустя время.
Внутри — много-много бордов из Miro, погнали.

Первые несколько лет задачи решались на одном только энтузиазме. Мы общались с клиентами из fashion-индустрии, мебельной и DIY-сфер, и у каждой компании находилось что-то интересное. От того, как круто мы построим процессы и интегрируемся с сайтом или приложением, зависела прибыль компании, удовлетворенность миллионов клиентов по всей стране. Это толкает тебя делать больше, чем ты можешь, но обратная сторона такой продуктивности — она не может продолжаться вечно.

Были и такие грехи, когда клиентская задача висела по два месяца в To Do, пока программисты тушили пожары на других проектах.
В плане коммуникаций все тоже было просто — мы просто боялись клиента. Мы боялись сказать клиенту нет, боялись ставить разные приоритеты задачам, потому что нам все было одинаково важно.
С одной стороны, мы хотели расти и нанимали новых заряженных людей, но с другой — без какого-либо онбординга сразу кидали их на боевые задачи, потому что ни у кого не было времени учить новичков. С постоянным тушением пожаров на задачах потухал запал и у самих джунов. Приходилось с ними прощаться и искать других.
Когда в офис приходили старички, все было понятно без слов: пустые глаза и тяжелые вздохи. Никто не мог позволить себе заболеть, а уж тем более уйти в отпуск — те, кто это делал, все равно были всегда на связи и толком не разгружались от задач.
Нужно было все менять.
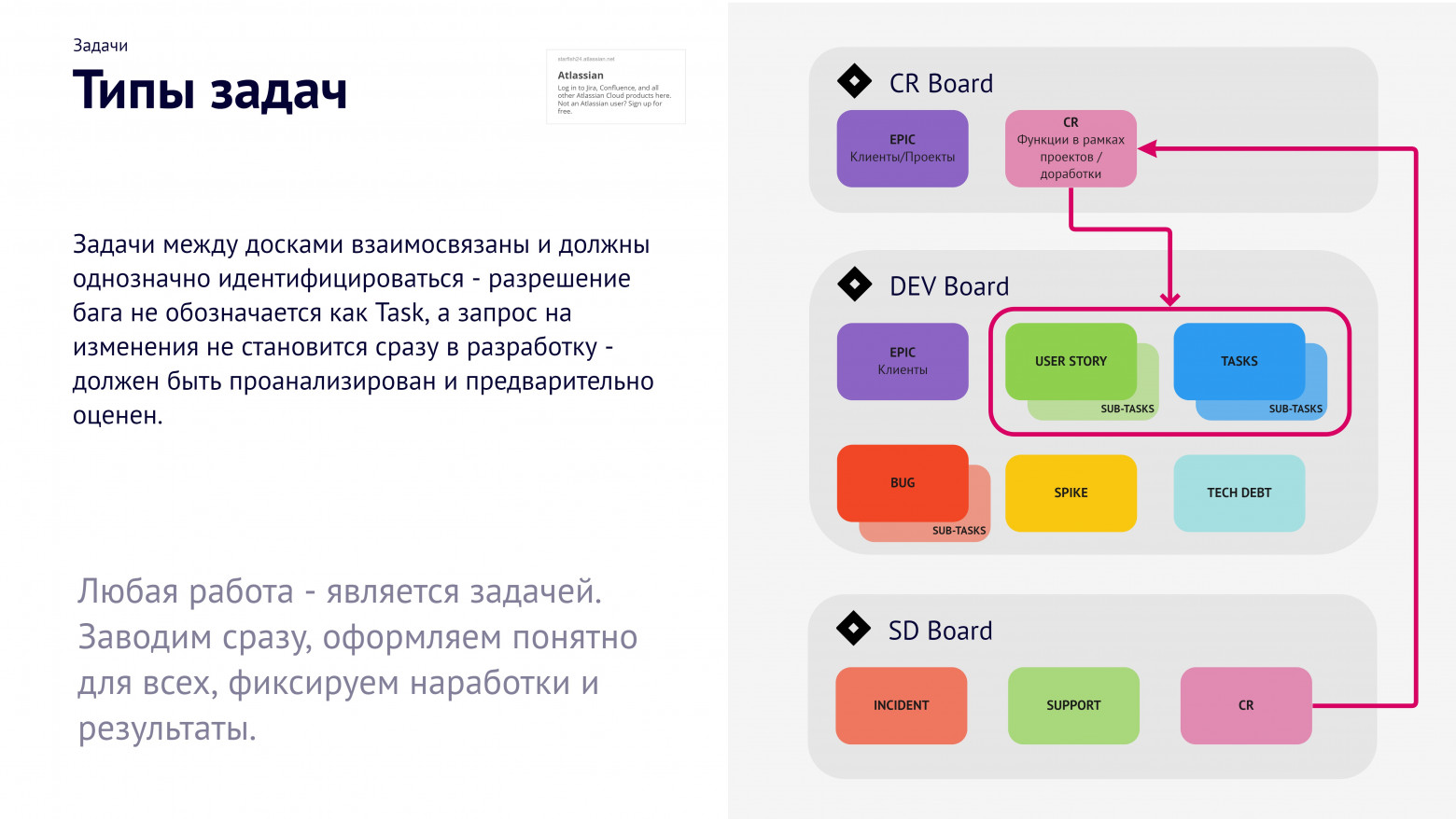
Распределили задачи. Мы не стали искать каких-то «правильных» решений и отталкивались от того, что у нас уже есть. В Jira у нас появилась отдельная доска запросов на изменения — крупные блоки работы по внедрению учета нового в продукт, где мы пытались согласовывать требования и все поступающие замечания. Вторая доска — разработка, в ней было несколько типов задач в зависимости от объема.
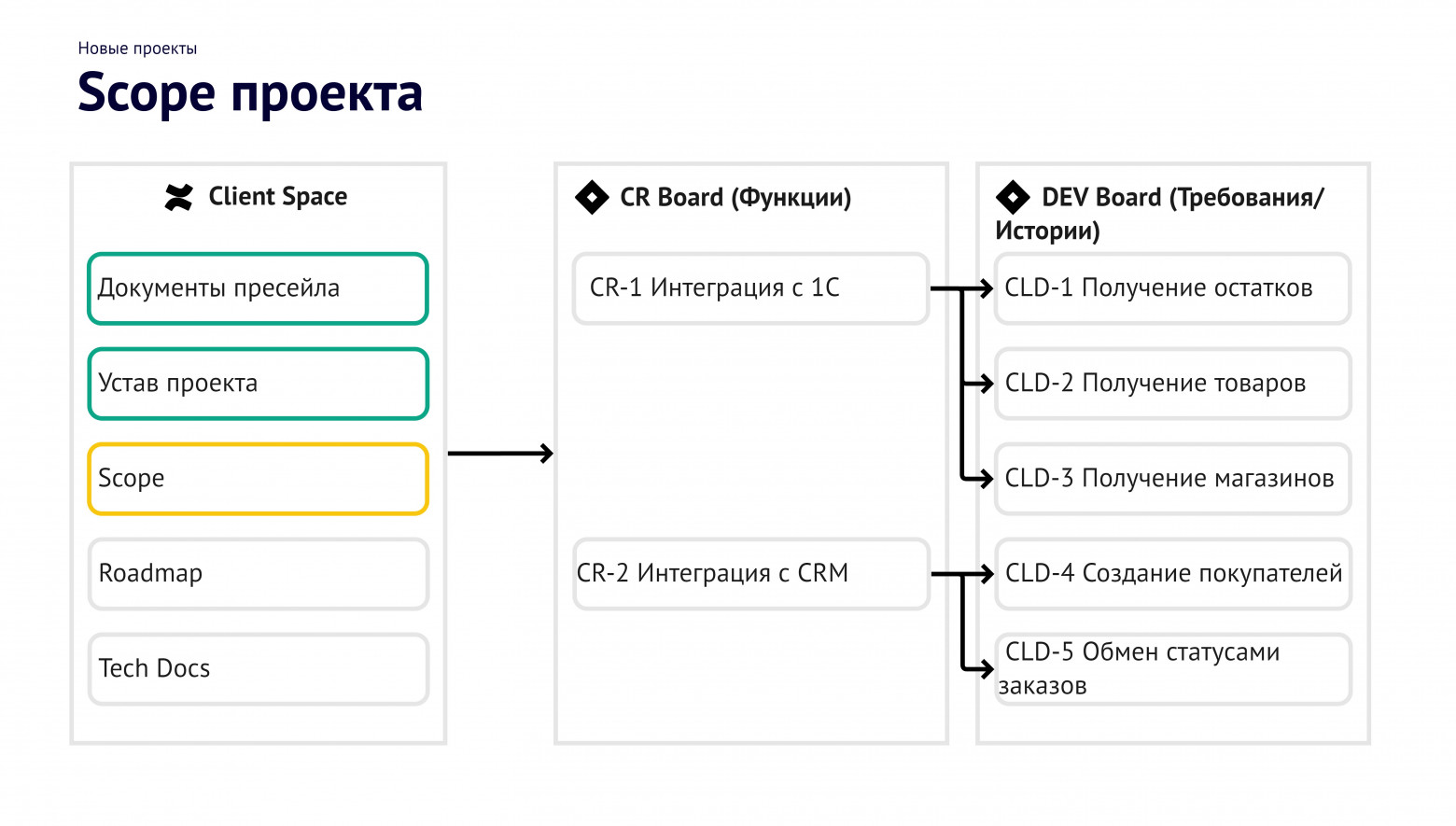
Еще у Jira есть возможность группировать задачи на головные и подзадачи. У нас большинство задач содержат много этапов работ: аналитика, бэкенд, фронтенд, тестирование, ревью. Под каждую из них надо делать отдельную колонку в Jira, либо делать отдельные задачи.

Подход был такой: для каждой головной задачи автоматически создаются подзадачи по ролям. Очень удобно понимать, сколько реально времени для каждого этапа и сколько в итоге на нее потратили.
Распределили роли в команде. Если раньше мы были многорукими многоногами, то теперь мы вытаскивали аналитиков из разработки и ставили здоровые рамки их задач. У нас появились руководители проектов и тестировщики, которые только тестируют.
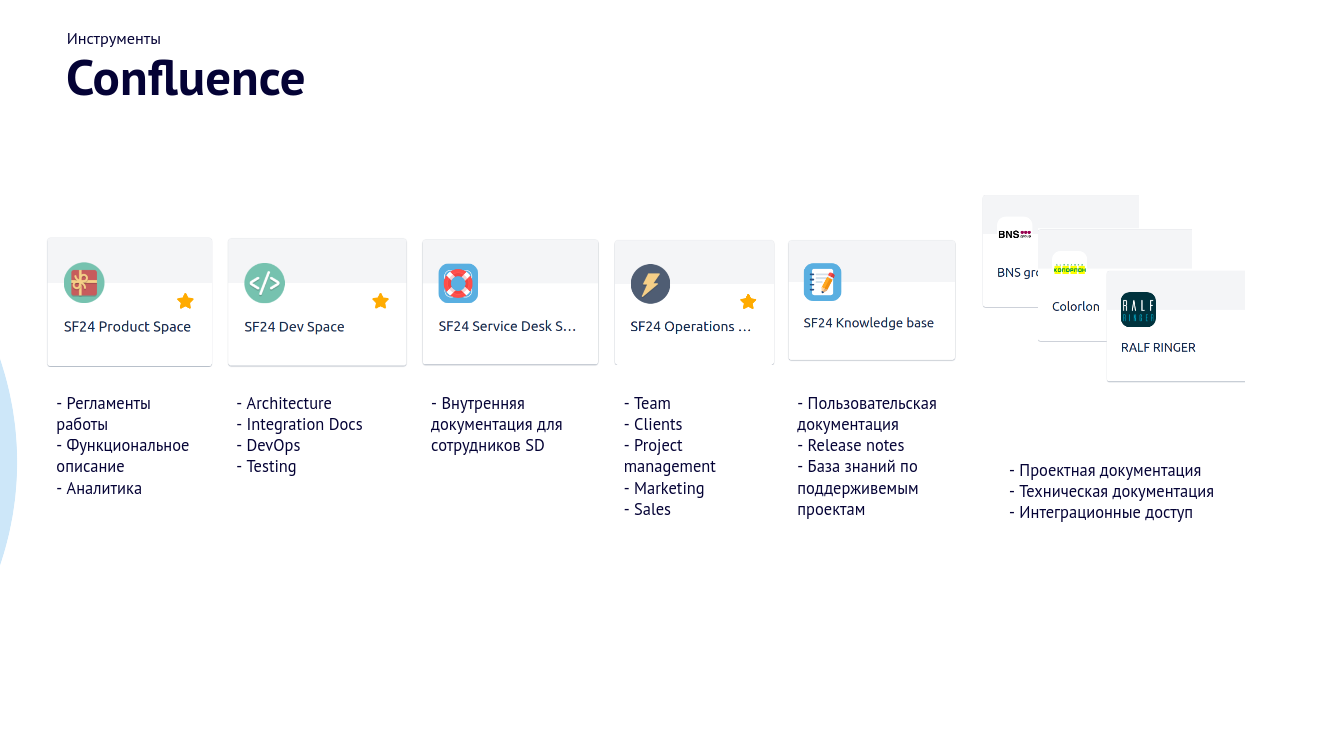
Все очевидно, но в стартапах зачастую происходит именно так: сначала все делают все, а потом постепенно разрастаются в четкие отделы.
Ввели обязательную аналитику. Спустя полгода после первой версии процессов мы выкатили обновление. За это время наш ServiceDesk (все еще состоящий из двух человек) обработал больше тысячи инцидентов на продакшене.
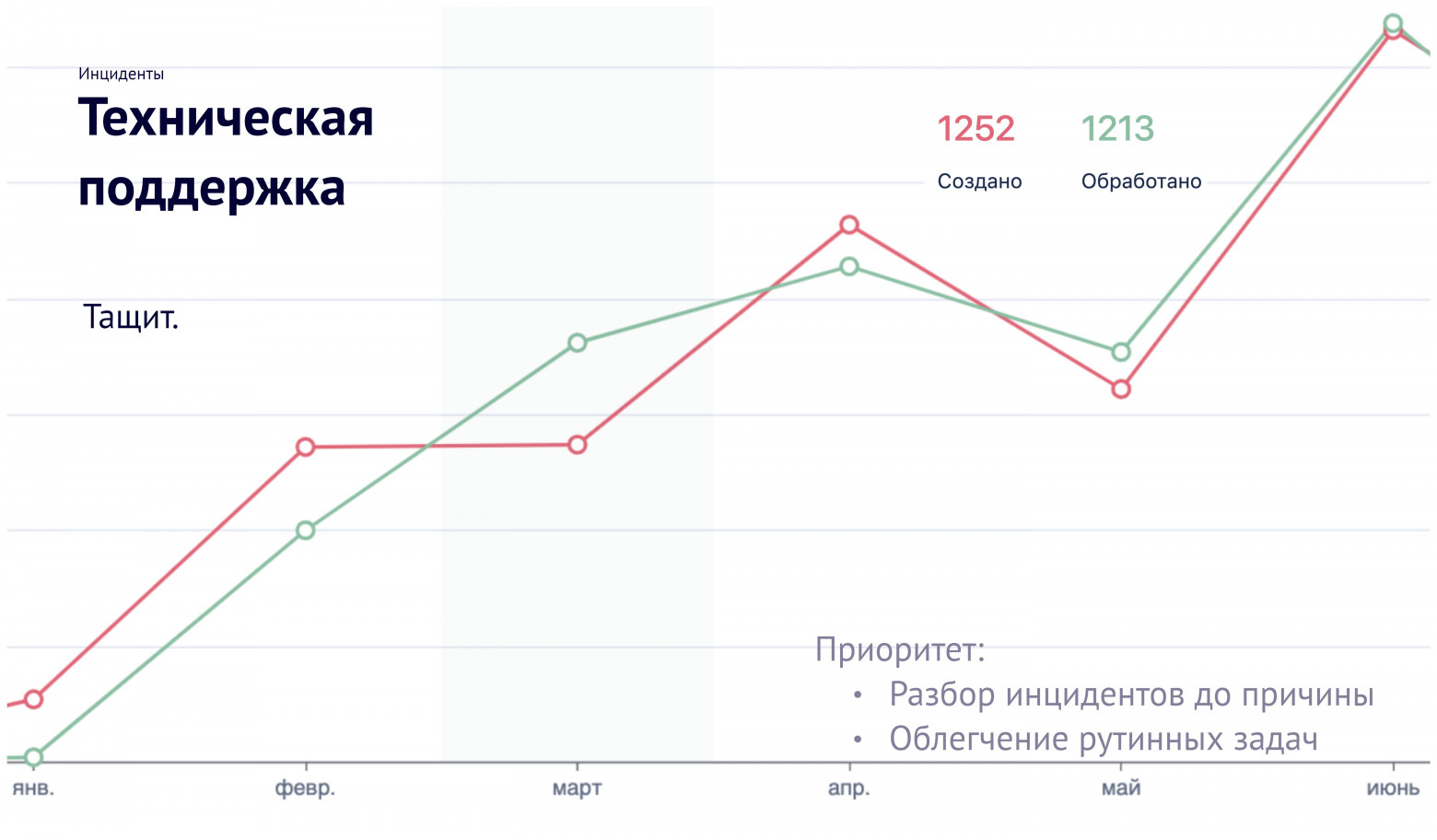
Такое количество инцидентов получилось потому, что на потоке задач у нас выпадал этап качественной системной аналитики. Какие-то задачи сразу брали в работу и отправляли в продакшен, а где-то подключали аналитиков и составляли требования. Тут нужно понимать, что редко в какой компании клиенты приходят с четко прогнозируемым объемом — всегда нужно собирать общую картину из клочков информации, общаться в команде, составлять требования и понимать ограничения. Плюс, новые фичи нужно делать не одноразовыми, а заложить в них возможность масштабирования. На все это нужно время и мозги.
Поэтому мы создали новую доску в Jira для аналитиков — без этого первичного шага в разработку ничего не пускали. Еще это убрало лишний шум от ребят, которые не задействованы на этом этапе — разработчикам не нужно смотреть, что делают аналитики и забивать этим голову.
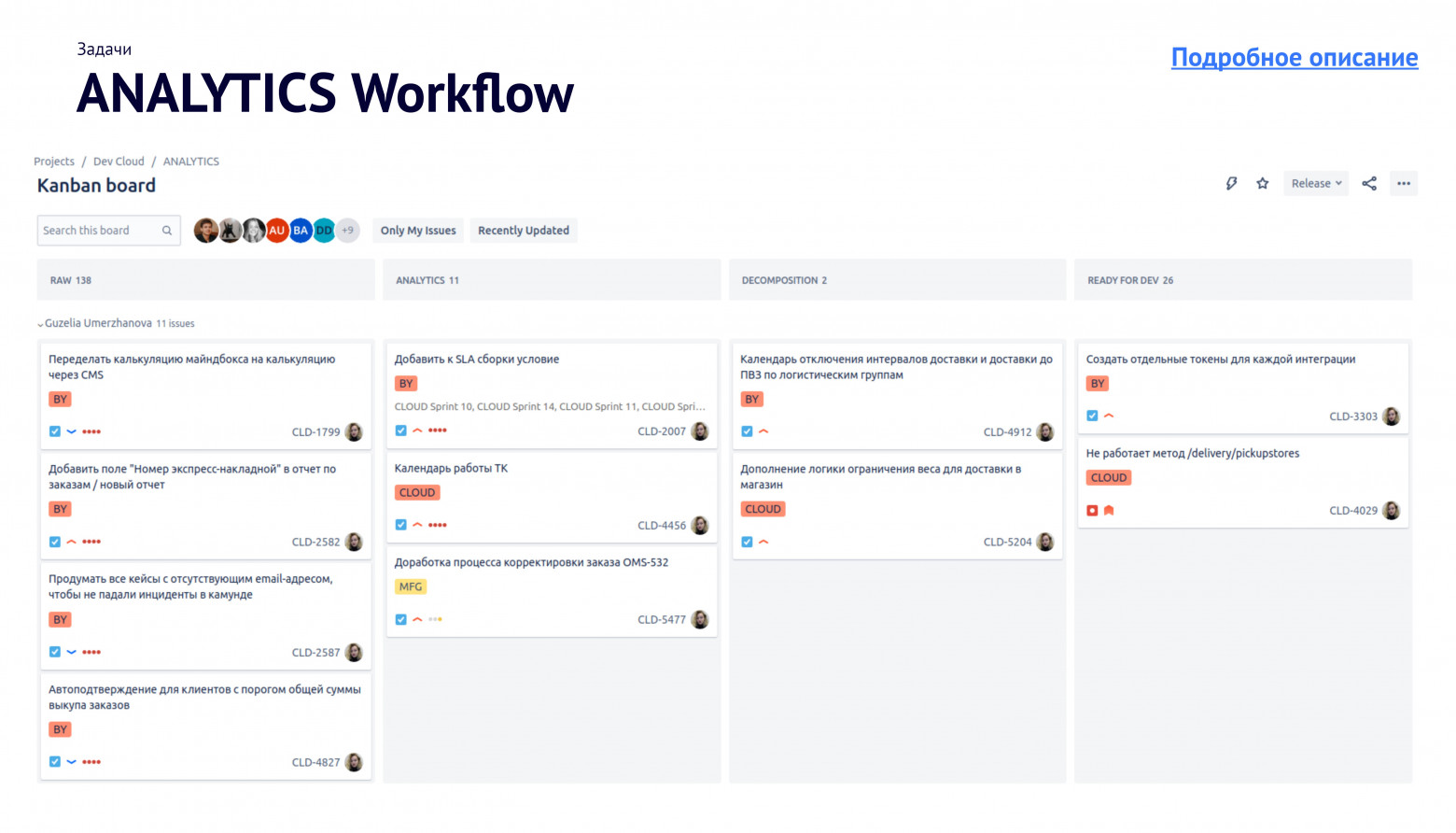
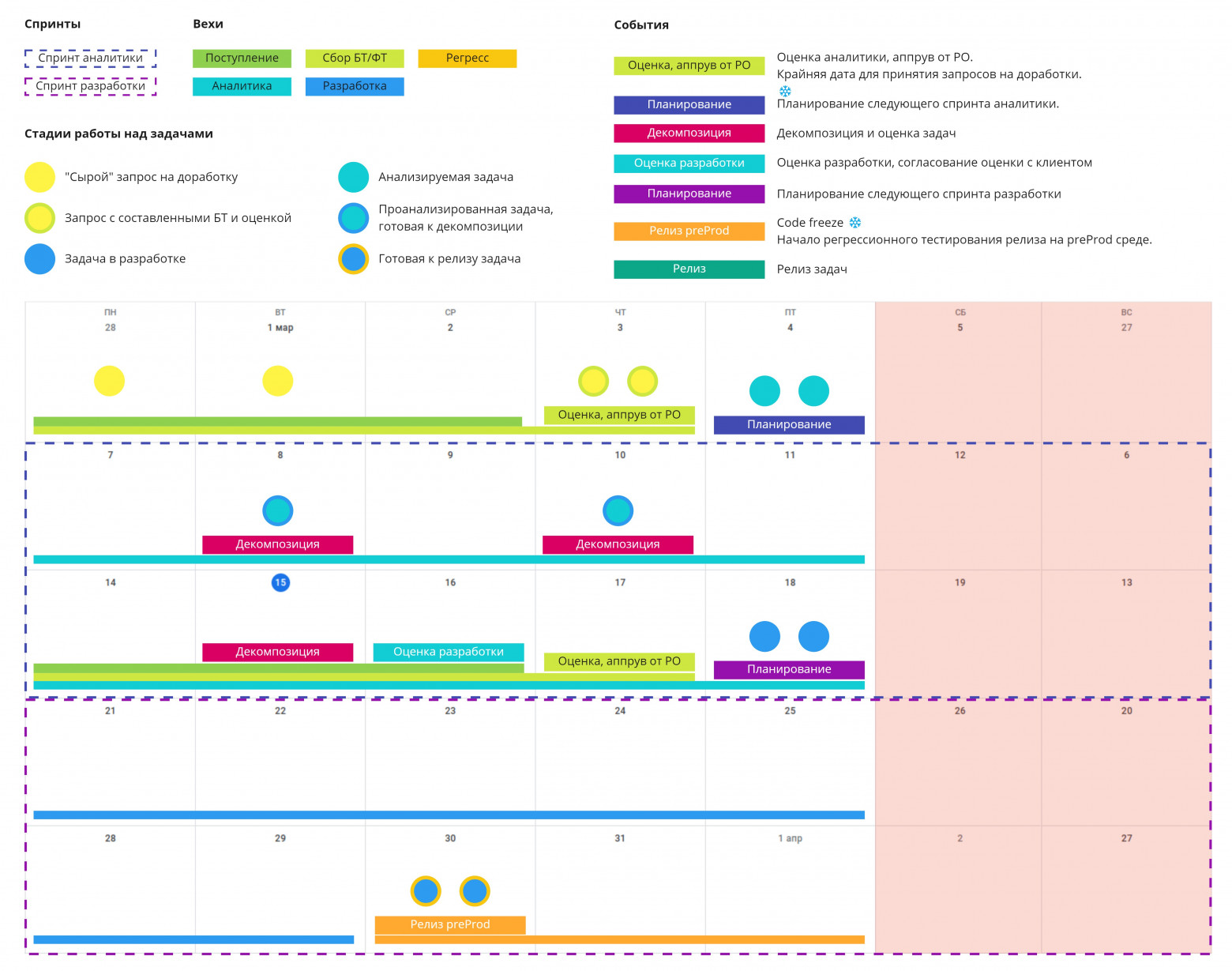
Снова взялись за спринты. Мы разделили задачи спринта по вехам и событиям: много желтого — плохо, много голубого с оранжевым контуром — хорошо. Теперь задачи закрывались быстрее и не вырастали в огромных монстров, которых невозможно победить.

Стали проводить ретро. Внедряли изменения на уровне команды мы впервые, поэтому обратились к специалистам — нам посоветовали проводить ретро. Да, кажется, что это очевидно и уже все им пользуются, но в реальности к самым банальным вещам приходишь только после сотни ошибок, когда получаешь обратную связь со стороны. На тему ретро есть классная статья.
Собрали изолированные команды. В предыдущих версиях процессов организация делилась по отделам: аналитика, разработка, тестирование. Идея была такая, что есть один большой котел, куда скидываются все задачи, а ребята по порядку между собой разбирают их. На практике это не работало от слова совсем. У нас уже было 30 человек, которые часто путались и не понимали, к какому отделу относятся некоторые задачи. Сроки наслаивались, приоритеты повышались, а задачи не закрывались. Большинство задач застревало как раз на этом переходе от отдела к отделу.
Тогда мы вспомнили про правило двух пицц, где над решением задачи работают максимум 6-7 человек и не взаимодействуют с другими отделами для принятия решений. Поэтому мы сгруппировали команды, отталкиваясь не от коммуникаций между отделами, а от логики жизни продукта. Так появилось четыре блока: внедрение проектов, поддержка клиентов, внутреннее развитие продукта и технический долг.
 Четыре команды и никаких лишних связей
Четыре команды и никаких лишних связей
С таким форматом есть перспективы масштабирования — когда у нас будет условно 100 человек, можно дублировать отдельные замкнутые команды, а не встраивать каждого человека в сложные коммуникации с другими отделами. У каждой команды постоянный состав, а у проектов есть точка начала и точка конца.
Проще управлять проектами. Сейчас в проектном плане у нас проводится полное документирование объема каждой новой работы, есть документация по составам команд. Когда проект передается из одной команды в другую, все в курсе запросов клиента, их модели принятия решений, и все знают, к кому нужно обращаться с проблемами. Грубо говоря, мы все доводим до такого состояния, что даже постороннему человеку будет все понятно по проекту.

Всем понятны их задачи. Кроме того, что мы задокументировали проектные работы, мы расписали роли каждого участника команды. Теперь мы можем расти и нанимать людей, не боясь, что человек запутается в обязанностях и быстро выгорит.
Команда в курсе об изменениях в продукте. Вместе со спринтами и более глубокой работой в команде мы ввели мероприятие Product Demo. Два раза в месяц мы собираем всю команду и показываем презентацию с обновлениями. Включаем в рассказ все, что могло измениться с прошлой встречи: фичи, процессы, проекты, новости в компании, команде и продукте. Так, все коллеги из разных отделов на какое-то время синхронизируются и видят общую картину в компании. Это особенно ценно, когда ребята работают в не связанных друг с другом группах.
Проблемы выявляются заранее. Каждый четверг садимся на два часа, полчаса из которых просто говорим о жизни и расслабляемся. После этого важные проблемы в процессах, команде и бизнесе решаются намного проще, чем если их пытаться решить с холодной головой. Ставим вперед открытость — это должно быть не сухое совещание с боссами, а эмоциональный разговор о том, что болит, бесит и какие видим ограничения. Из чувственных замечаний и обсуждений рождается решение.

 habr.com
habr.com
В конце 2018 года я пришел в тогда еще сырой стартап из 15 человек на должность Frontend-разработчика и не подозревал, с чем мне придется столкнуться в следующие три года. Я видел, как один человек выполнял роли сразу трех специалистов, как быстро выгорали новички, и как два человека обрабатывали по 1 000+ инцидентов после релиза.
Каждый ретейлер хочет непрерывного развития своего бизнеса: добавление новых модулей в систему, автоматизацию процессов, интеграцию с новыми каналами продаж. Мы тоже за развитие, но когда клиентов и задач становится много, все костыльные процессы, которые хоть как-то держались на маленьких объемах, начинают с грохотом падать, а люди — выгорать.
Сейчас, уже в роли Product Owner, я слежу за тем, чтобы наш продукт шел туда, куда нужно, а все доработки только развивали продукт, а не мешали ему. Весь 2022 год я с коллегами внедрял новые регламенты по процессам и хочу поделиться с другими продуктовыми командами нашим опытом. Расскажу, как мы за год трижды пересмотрели подход к развитию продукта и клиентским задачам. И покажу, почему к самым очевидным вещам приходишь только спустя время.
Внутри — много-много бордов из Miro, погнали.
Сапожники без сапог
Суть нашей работы во многом заключается в оптимизации бизнес-процессов. Например, товары клиента не покупают в домашнем регионе, и мы внедряем в систему кросс-региональную доставку. С этой точки зрения, мы были сапожниками без сапог — мы знали, как наилучшим образом решить задачу клиента, но внутри у нас творился полный хаос.
Первые несколько лет задачи решались на одном только энтузиазме. Мы общались с клиентами из fashion-индустрии, мебельной и DIY-сфер, и у каждой компании находилось что-то интересное. От того, как круто мы построим процессы и интегрируемся с сайтом или приложением, зависела прибыль компании, удовлетворенность миллионов клиентов по всей стране. Это толкает тебя делать больше, чем ты можешь, но обратная сторона такой продуктивности — она не может продолжаться вечно.
Хотфикс за хотфиксом
Мы хватались за все задачи, которые нам отдавали. Сроки всегда, как молодцы обещали кратчайшие, и, естественно, почти никогда их не соблюдали. Из-за этого хаоса естественным путем появлялись кучи ошибок. Проводим релиз по OMS на продакшен и весь день чиним ошибки на тысяче онлайн-заказов. Service Desk обрабатывал инциденты и вывозил вообще все. И так каждый релиз.
Были и такие грехи, когда клиентская задача висела по два месяца в To Do, пока программисты тушили пожары на других проектах.
Никакого скоупа и переговоров
Другим типом задач, помимо устранения ошибок, были запросы на изменения. Все запросы мы просто ставили сразу в разработку — никто не прогонял запросы через аналитиков, не документировал объемы проекта и не оценивал трудоемкость.В плане коммуникаций все тоже было просто — мы просто боялись клиента. Мы боялись сказать клиенту нет, боялись ставить разные приоритеты задачам, потому что нам все было одинаково важно.
Никаких четко обозначенных ролей
Представьте кулисы театра, где каждый актер, отыграв одну роль, бежит в гримерку перевоплощаться в нового героя — у нас было что-то похожее. Аналитики были отчасти проджект-менеджерами: проводили брифы с клиентами, внедряли проекты, а в «свободное» от аналитики время тестировали релизы. Ребята переключались с одного типа задач на другой по десять раз в день, теряли фокус, делали ошибки, уставали. Ведущий аналитик (текущий архитектор) Наиль знал все тонкости продукта, но вместо работы над задачами занимался только коммуникациями с клиентом.Экономия на системах управления проектами
Еще одним классическим элементом стартапа была бесплатная Jira на 10 учеток — из-за этого у нас несколько человек висели на одной учетке. Поэтому каждый раз в названии задач мы писали в скобках имя того, на кого она распределена.Как итог: нулевой боевой дух и стагнация продукта
Главная проблема была в том, что мы пытались угодить всем, кроме себя. В итоге получалось только хуже, и так продолжалось три года. Это было больно — ты прикладываешь все усилия, чтобы сделать что-то крутое, но в конечном счете получаешь головную боль для пятнадцати человек от каждого релиза. Параллельно с этим продукт размазывался во все стороны и практически не развивался. В такой ситуации рост был невозможен, при этом добавление сотрудников не решило бы проблему, и вот почему.С одной стороны, мы хотели расти и нанимали новых заряженных людей, но с другой — без какого-либо онбординга сразу кидали их на боевые задачи, потому что ни у кого не было времени учить новичков. С постоянным тушением пожаров на задачах потухал запал и у самих джунов. Приходилось с ними прощаться и искать других.
Когда в офис приходили старички, все было понятно без слов: пустые глаза и тяжелые вздохи. Никто не мог позволить себе заболеть, а уж тем более уйти в отпуск — те, кто это делал, все равно были всегда на связи и толком не разгружались от задач.
Нужно было все менять.
Как исправляли ситуацию на уровне проектов
Каналов поступления задач было два: ServiceDesk с инцидентами по устранению ошибок и Change requests на поддержку и доработки. Для порядка в учете мы переехали на платную Jira. Но мало купить, надо еще и настроить.Распределили задачи. Мы не стали искать каких-то «правильных» решений и отталкивались от того, что у нас уже есть. В Jira у нас появилась отдельная доска запросов на изменения — крупные блоки работы по внедрению учета нового в продукт, где мы пытались согласовывать требования и все поступающие замечания. Вторая доска — разработка, в ней было несколько типов задач в зависимости от объема.
Еще у Jira есть возможность группировать задачи на головные и подзадачи. У нас большинство задач содержат много этапов работ: аналитика, бэкенд, фронтенд, тестирование, ревью. Под каждую из них надо делать отдельную колонку в Jira, либо делать отдельные задачи.
Подход был такой: для каждой головной задачи автоматически создаются подзадачи по ролям. Очень удобно понимать, сколько реально времени для каждого этапа и сколько в итоге на нее потратили.
Распределили роли в команде. Если раньше мы были многорукими многоногами, то теперь мы вытаскивали аналитиков из разработки и ставили здоровые рамки их задач. У нас появились руководители проектов и тестировщики, которые только тестируют.
Все очевидно, но в стартапах зачастую происходит именно так: сначала все делают все, а потом постепенно разрастаются в четкие отделы.
Ввели обязательную аналитику. Спустя полгода после первой версии процессов мы выкатили обновление. За это время наш ServiceDesk (все еще состоящий из двух человек) обработал больше тысячи инцидентов на продакшене.
Такое количество инцидентов получилось потому, что на потоке задач у нас выпадал этап качественной системной аналитики. Какие-то задачи сразу брали в работу и отправляли в продакшен, а где-то подключали аналитиков и составляли требования. Тут нужно понимать, что редко в какой компании клиенты приходят с четко прогнозируемым объемом — всегда нужно собирать общую картину из клочков информации, общаться в команде, составлять требования и понимать ограничения. Плюс, новые фичи нужно делать не одноразовыми, а заложить в них возможность масштабирования. На все это нужно время и мозги.
Поэтому мы создали новую доску в Jira для аналитиков — без этого первичного шага в разработку ничего не пускали. Еще это убрало лишний шум от ребят, которые не задействованы на этом этапе — разработчикам не нужно смотреть, что делают аналитики и забивать этим голову.
Как исправляли ситуацию на уровне продукта
В потоке задач мы не всегда могли остановиться и вспомнить, зачем мы вообще все это делаем. Поэтому когда мы проработали кризисы и починили поломки, пришла пора сфокусироваться на развитии продукта.Снова взялись за спринты. Мы разделили задачи спринта по вехам и событиям: много желтого — плохо, много голубого с оранжевым контуром — хорошо. Теперь задачи закрывались быстрее и не вырастали в огромных монстров, которых невозможно победить.
Как исправляли ситуацию на уровне команды
Новые процессы пошли тяжело — изменения хоть были небольшие, но достаточно существенные и ребятам было тяжело перестроиться. Раньше они работали, соблюдая интересы только одной стороны — клиента, а теперь мы учили команду в хорошем смысле соблюдать свои интересы. Достраивая цепочку до конечных пользователей, мы исходили не из страха перед клиентом, а из открытости и ответственности за продукт. Так мы упростили для клиентов взаимодействие с продуктом, а сроки и объемы работ стали более прогнозируемыми.
Стали проводить ретро. Внедряли изменения на уровне команды мы впервые, поэтому обратились к специалистам — нам посоветовали проводить ретро. Да, кажется, что это очевидно и уже все им пользуются, но в реальности к самым банальным вещам приходишь только после сотни ошибок, когда получаешь обратную связь со стороны. На тему ретро есть классная статья.
Собрали изолированные команды. В предыдущих версиях процессов организация делилась по отделам: аналитика, разработка, тестирование. Идея была такая, что есть один большой котел, куда скидываются все задачи, а ребята по порядку между собой разбирают их. На практике это не работало от слова совсем. У нас уже было 30 человек, которые часто путались и не понимали, к какому отделу относятся некоторые задачи. Сроки наслаивались, приоритеты повышались, а задачи не закрывались. Большинство задач застревало как раз на этом переходе от отдела к отделу.
Тогда мы вспомнили про правило двух пицц, где над решением задачи работают максимум 6-7 человек и не взаимодействуют с другими отделами для принятия решений. Поэтому мы сгруппировали команды, отталкиваясь не от коммуникаций между отделами, а от логики жизни продукта. Так появилось четыре блока: внедрение проектов, поддержка клиентов, внутреннее развитие продукта и технический долг.
С таким форматом есть перспективы масштабирования — когда у нас будет условно 100 человек, можно дублировать отдельные замкнутые команды, а не встраивать каждого человека в сложные коммуникации с другими отделами. У каждой команды постоянный состав, а у проектов есть точка начала и точка конца.
Что мы из этого поняли и что применяем сейчас
После трех итераций процессов в течение года было много изменений, но ни одно из них не сказалось негативно на цифрах или на людях. Вот что у нас есть на начало 2023 года.Проще управлять проектами. Сейчас в проектном плане у нас проводится полное документирование объема каждой новой работы, есть документация по составам команд. Когда проект передается из одной команды в другую, все в курсе запросов клиента, их модели принятия решений, и все знают, к кому нужно обращаться с проблемами. Грубо говоря, мы все доводим до такого состояния, что даже постороннему человеку будет все понятно по проекту.
Всем понятны их задачи. Кроме того, что мы задокументировали проектные работы, мы расписали роли каждого участника команды. Теперь мы можем расти и нанимать людей, не боясь, что человек запутается в обязанностях и быстро выгорит.
Команда в курсе об изменениях в продукте. Вместе со спринтами и более глубокой работой в команде мы ввели мероприятие Product Demo. Два раза в месяц мы собираем всю команду и показываем презентацию с обновлениями. Включаем в рассказ все, что могло измениться с прошлой встречи: фичи, процессы, проекты, новости в компании, команде и продукте. Так, все коллеги из разных отделов на какое-то время синхронизируются и видят общую картину в компании. Это особенно ценно, когда ребята работают в не связанных друг с другом группах.
Проблемы выявляются заранее. Каждый четверг садимся на два часа, полчаса из которых просто говорим о жизни и расслабляемся. После этого важные проблемы в процессах, команде и бизнесе решаются намного проще, чем если их пытаться решить с холодной головой. Ставим вперед открытость — это должно быть не сухое совещание с боссами, а эмоциональный разговор о том, что болит, бесит и какие видим ограничения. Из чувственных замечаний и обсуждений рождается решение.
Ретро, роли и спринты: очевидные (и не очень) вещи, которые мы поняли только спустя три года разработки
Привет! Меня зовут Артур Карапетян, я Product Owner в Starfish24. Мы помогаем российским ретейлерам управлять жизненным циклом заказа, выстраивать и контролировать логику обработки с помощью...
habr.com