Мне никогда раньше не приходилось иметь дело с парсингом данных из интернета. Обычно все данные для работы (аналитик данных) приходят из выгрузок компании с использованием простого внутреннего интерфейса, либо формируются sql-запросами к таблицам напрямую из хранилища, если нужно что-то более сложное, чем “посмотреть выручку за предыдущий месяц”.
Поэтому мне захотелось освоить какой-нибудь несложный инструмент парсинга html-страниц, чтобы уметь собирать данные из интернета с помощью кода в удобной для себя IDE без привлечения сторонних инструментов.
Сайты для сбора данных были подобраны по принципу “нет блокировщика парсеров” и “из анализа этих данных может выйти что-то интересное”. Поэтому выбор пал на ассортимент блюд на доставку трёх ресторанов Санкт-Петербурга - “Токио City”, “Евразия” и “2 Берега”. У них приблизительно одна направленность кухни и похожий ассортимент, поэтому явно найдется, что сравнить.
Поделюсь самим парсером для одного из ресторанов.
import requests
from bs4 import BeautifulSoup
import pandas as pd
import datetime
print("Начало парсинга Токио Сити: " + str(datetime.datetime.now()))
#все страницы с информацией о меню
urllist = ['https://www.tokyo-city.ru/spisok-product/goryachie-blyuda1.html',
'https://www.tokyo-city.ru/spisok-product/sushi.html',
'https://www.tokyo-city.ru/spisok-product/rolly.html',
'https://www.tokyo-city.ru/spisok-product/nabory.html',
'https://www.tokyo-city.ru/spisok-product/new_lunches.html',
'https://www.tokyo-city.ru/spisok-product/pitctca.html',
'https://www.tokyo-city.ru/spisok-product/salaty.html',
'https://www.tokyo-city.ru/spisok-product/-supy-.html',
'https://www.tokyo-city.ru/spisok-product/goryachie-zakuski1.html',
'https://www.tokyo-city.ru/spisok-product/wok.html',
'https://www.tokyo-city.ru/spisok-product/pasta.html',
'https://www.tokyo-city.ru/spisok-product/gamburgery-i-shaverma.html',
'https://www.tokyo-city.ru/spisok-product/Tokio-FIT.html',
'https://www.tokyo-city.ru/spisok-product/deserty.html',
'https://www.tokyo-city.ru/spisok-product/childrensmenu.html',
'https://www.tokyo-city.ru/spisok-product/napitki1.html',
'https://www.tokyo-city.ru/new/',
'https://www.tokyo-city.ru/spisok-product/postnoe-menyu.html',
'https://www.tokyo-city.ru/hit/',
'https://www.tokyo-city.ru/vegetarian/',
'https://www.tokyo-city.ru/hot/',
'https://www.tokyo-city.ru/offers/',
'https://www.tokyo-city.ru/spisok-product/sauces.html',
'https://www.tokyo-city.ru/spisok-product/Pirogi-torty.html']
#создаем пустые списки для записи всех данных
names_all = []
descriptions_all = []
prices_all = []
categories_all = []
url_all = []
weight_all = []
nutr_all = []
#собираем данные
for url in urllist:
response = requests.get(url).text
soup = BeautifulSoup(response, features="html.parser")
items = soup.find_all('a', class_='item__name')
itemsURL = []
n = 0
for n, i in enumerate(items, start=n):
itemnotfullURL = i.get('href')
itemURL = 'https://www.tokyo-city.ru' + itemnotfullURL
itemsURL.extend({itemURL})
m = 0
namesList = []
descriptionsList = []
pricesList = []
weightList = []
nutrList = []
itemResponse = requests.get(itemURL).text
itemsSoup = BeautifulSoup(itemResponse, features="html.parser")
itemsInfo = itemsSoup.find_all('div', class_='item__full-info')
for m, u in enumerate(itemsInfo, start=m):
if (u.find('h1', class_='item__name') == None):
itemName = 'No data'
else:
itemName = u.find('h1', class_='item__name').text.strip()
if (u.find('p', class_='item__desc') == None):
itemDescription = 'No data'
else:
itemDescription = u.find('p', class_='item__desc').text.strip()
if (u.find('span', class_='item__price-value') == None):
itemPrice = '0'
else:
itemPrice = u.find('span', class_='item__price-value').text
if (u.find('div', class_='nutr-value') == None):
itemNutr = 'No data'
else:
itemNutr = u.find('div', class_='nutr-value').text.strip()
if (u.find('div', class_='item__weight') == None):
itemWeight = '0'
else:
itemWeight = u.find('div', class_='item__weight').text.strip()
namesList.extend({itemName})
descriptionsList.extend({itemDescription})
pricesList.extend({itemPrice})
weightList.extend({itemWeight})
nutrList.extend({itemNutr})
df = pd.DataFrame((
{'Name': namesList,
'Description': descriptionsList,
'Price': pricesList,
'Weight': weightList,
'NutrInfo': nutrList
}))
names_all.extend(df['Name'])
descriptions_all.extend(df['Description'])
prices_all.extend(df['Price'])
weight_all.extend(df['Weight'])
nutr_all.extend(df['NutrInfo'])
df['Category'] = soup.find('div', class_='title__container').text.strip()
categories_all.extend(df['Category'])
result = pd.DataFrame((
{'Name': names_all,
'Description': descriptions_all,
'Price': prices_all,
'Category': categories_all,
'NutrInfo': nutr_all,
'Weight': weight_all,
}))
print("Парсинг Токио Сити окончен: " + str(datetime.datetime.now()))
Будет здорово увидеть какие-нибудь идеи по оптимизации/усовершенствованию этого парсера. Возможно, его можно сделать более универсальным. Сейчас, полагаю, он слишком топорный и капризный, если на сайте что-нибудь поменяется в страницах с категориями - он не будет работать.
А теперь к самому интересному - анализу полученной информации.
Начальные данные:
Наименование каждого блюда, его состав, цена, вес, калорийность, БЖУ и категория, к которой это блюдо относится.
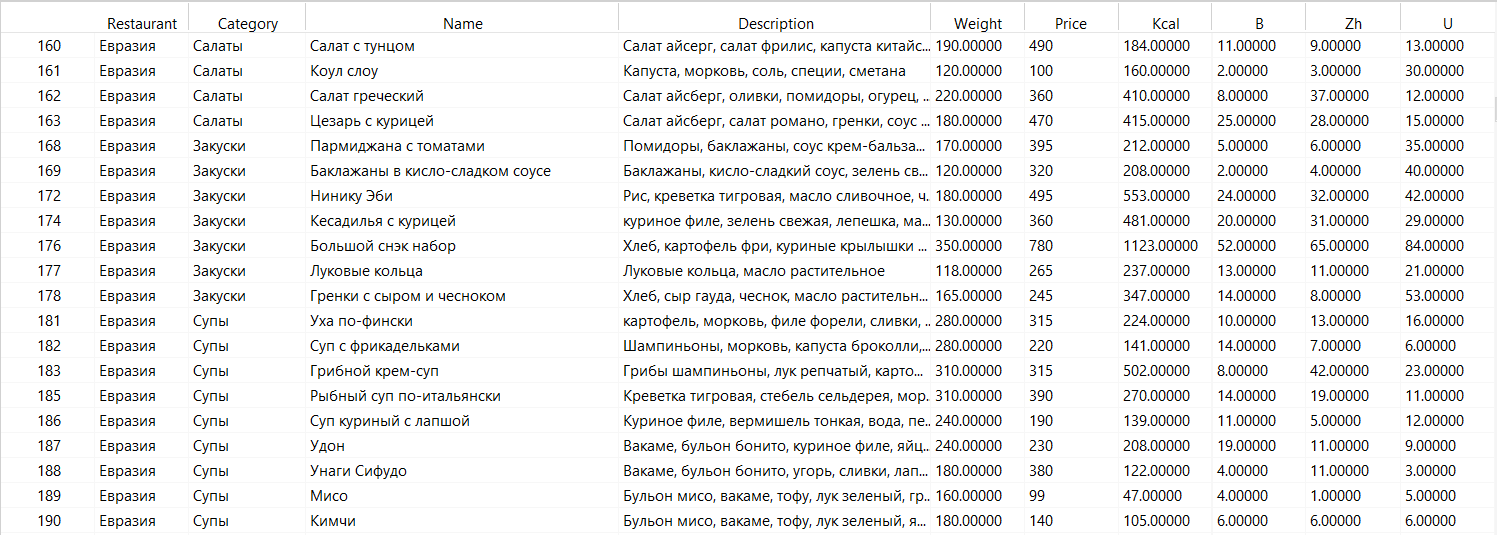
Кусочек готовой к анализу таблицы с ассортиментом:
Для начала изучим общую направленность кухни каждого ресторана. Стоит сразу отметить, что речь пойдёт только о меню на доставку. Если сеть работает не только на доставку, но имеет и физические рестораны, то меню там может отличаться, возможно, оно будет больше и разнообразнее.



Теперь, познакомившись с ассортиментом всех трёх ресторанов, посмотрим, какие ответы можно получить из добытых данных.
В данном случае важно правильно определить, от каких категорий нужно считать процент, потому что некоторые категории не относятся к полноценным блюдам, а другие являются их дублированием. Поэтому из расчёта этого показателя убраны такие категории, как “Напитки”, “Детское меню”, “Соусы”, “Наборы”, “Ланчи” и “Десерты” + всевозможные вариации данных категорий.
Итог:

Выходит, “2 Берега” - №1 по разнообразию пиццы в ассортименте. Это подтверждается, даже если просто сравнить количество блюд в категории “Пицца” во всех ресторанах (“Токио City” - 20, “Евразия” - 17 и “2 Берега” - 51).
По остальным направлениям представленность фастфуда более-менее одинакова, разве что в “Евразии” отсутствует стритфуд.
Посчитав цену за 100 грамм блюда в каждом ресторане, получаем следующие результаты:

У “2 Берега” нет такой категории, как “Горячие блюда”. Есть ВОКи и паста, но традиционных горячих блюд вида “гарнир + мясо” нет. Поэтому в категории “Горячие блюда” сравниваются только “Токио City” и “Евразия”.
По всем категориям “Токио City” является безусловным лидером по соотношению цены и веса блюда. “2 Берега” занимает почётное 2 место. “Евразия” оказывается в хвосте рейтинга. Даже если вычесть из средней цены за 100 грамм блюда в “Евразии” 30% (это максимальная скидка, которую предоставляет ресторан по картам лояльности), ресторан все равно ни в одной категории не сможет обогнать “Токио City” по выгоде.
Теперь изучим размер порций, которые могут предложить данные рестораны:

“Евразия” снова по всем категориям не смогла обогнать другие рестораны. Средний “недовес” порции составляет 30% относительно двух других ресторанов.
Зато “2 Берега” отличился лучшим весом супов, салатов и детских блюд. Кстати, такой большой средний вес в категории “Детские блюда” у этого ресторана объясняется тем, что там представлены только наборы, в составе которых 2 блюда + напиток (вес напитка здесь не учитывается). Но даже с учётом этого факта можно похвалить этот ресторан за щедрые порции детского меню.
А “Токио City” предлагает отличные порции горячих блюд.

Калорийность половины блюд в “Токио City” не превышает 205 калорий в 100 граммах, поэтому присуждаем ресторану одного толстого кота из трёх. Это достаточно позитивный показатель для тех, кто следит за своим весом. А вот у блюд ресторана “2 Берега” этот показатель на 35% выше, поэтому он получает максимальное количество толстых котов. Впрочем, в этом нет ничего удивительного, если вспомнить, какую долю от всего меню этого ресторана занимает пицца.

Несмотря на самую высокую калорийность на 100 грамм и большое количество фастфуда “2 Берега” предлагает достаточно сбалансированное меню, тогда как у того же “Токио City” можно заметить явный перекос в сторону углеводов.
БЖУ “Евразии” какое-то слишком равномерное, практически без выбросов, поэтому вызывает подозрения.
Вообще в верности сделанных мной выводов конкретно в этом вопросе есть сомнения - возможно, для правильного ответа на вопрос эти показатели нужно оценивать как-то по-другому.
Вот такое небольшое, но любопытное, на мой взгляд, исследование получилось из случайной мысли “спарсить бы что-нибудь”.
Источник статьи: https://habr.com/ru/post/551294/
Поэтому мне захотелось освоить какой-нибудь несложный инструмент парсинга html-страниц, чтобы уметь собирать данные из интернета с помощью кода в удобной для себя IDE без привлечения сторонних инструментов.
Сайты для сбора данных были подобраны по принципу “нет блокировщика парсеров” и “из анализа этих данных может выйти что-то интересное”. Поэтому выбор пал на ассортимент блюд на доставку трёх ресторанов Санкт-Петербурга - “Токио City”, “Евразия” и “2 Берега”. У них приблизительно одна направленность кухни и похожий ассортимент, поэтому явно найдется, что сравнить.
Поделюсь самим парсером для одного из ресторанов.
import requests
from bs4 import BeautifulSoup
import pandas as pd
import datetime
print("Начало парсинга Токио Сити: " + str(datetime.datetime.now()))
#все страницы с информацией о меню
urllist = ['https://www.tokyo-city.ru/spisok-product/goryachie-blyuda1.html',
'https://www.tokyo-city.ru/spisok-product/sushi.html',
'https://www.tokyo-city.ru/spisok-product/rolly.html',
'https://www.tokyo-city.ru/spisok-product/nabory.html',
'https://www.tokyo-city.ru/spisok-product/new_lunches.html',
'https://www.tokyo-city.ru/spisok-product/pitctca.html',
'https://www.tokyo-city.ru/spisok-product/salaty.html',
'https://www.tokyo-city.ru/spisok-product/-supy-.html',
'https://www.tokyo-city.ru/spisok-product/goryachie-zakuski1.html',
'https://www.tokyo-city.ru/spisok-product/wok.html',
'https://www.tokyo-city.ru/spisok-product/pasta.html',
'https://www.tokyo-city.ru/spisok-product/gamburgery-i-shaverma.html',
'https://www.tokyo-city.ru/spisok-product/Tokio-FIT.html',
'https://www.tokyo-city.ru/spisok-product/deserty.html',
'https://www.tokyo-city.ru/spisok-product/childrensmenu.html',
'https://www.tokyo-city.ru/spisok-product/napitki1.html',
'https://www.tokyo-city.ru/new/',
'https://www.tokyo-city.ru/spisok-product/postnoe-menyu.html',
'https://www.tokyo-city.ru/hit/',
'https://www.tokyo-city.ru/vegetarian/',
'https://www.tokyo-city.ru/hot/',
'https://www.tokyo-city.ru/offers/',
'https://www.tokyo-city.ru/spisok-product/sauces.html',
'https://www.tokyo-city.ru/spisok-product/Pirogi-torty.html']
#создаем пустые списки для записи всех данных
names_all = []
descriptions_all = []
prices_all = []
categories_all = []
url_all = []
weight_all = []
nutr_all = []
#собираем данные
for url in urllist:
response = requests.get(url).text
soup = BeautifulSoup(response, features="html.parser")
items = soup.find_all('a', class_='item__name')
itemsURL = []
n = 0
for n, i in enumerate(items, start=n):
itemnotfullURL = i.get('href')
itemURL = 'https://www.tokyo-city.ru' + itemnotfullURL
itemsURL.extend({itemURL})
m = 0
namesList = []
descriptionsList = []
pricesList = []
weightList = []
nutrList = []
itemResponse = requests.get(itemURL).text
itemsSoup = BeautifulSoup(itemResponse, features="html.parser")
itemsInfo = itemsSoup.find_all('div', class_='item__full-info')
for m, u in enumerate(itemsInfo, start=m):
if (u.find('h1', class_='item__name') == None):
itemName = 'No data'
else:
itemName = u.find('h1', class_='item__name').text.strip()
if (u.find('p', class_='item__desc') == None):
itemDescription = 'No data'
else:
itemDescription = u.find('p', class_='item__desc').text.strip()
if (u.find('span', class_='item__price-value') == None):
itemPrice = '0'
else:
itemPrice = u.find('span', class_='item__price-value').text
if (u.find('div', class_='nutr-value') == None):
itemNutr = 'No data'
else:
itemNutr = u.find('div', class_='nutr-value').text.strip()
if (u.find('div', class_='item__weight') == None):
itemWeight = '0'
else:
itemWeight = u.find('div', class_='item__weight').text.strip()
namesList.extend({itemName})
descriptionsList.extend({itemDescription})
pricesList.extend({itemPrice})
weightList.extend({itemWeight})
nutrList.extend({itemNutr})
df = pd.DataFrame((
{'Name': namesList,
'Description': descriptionsList,
'Price': pricesList,
'Weight': weightList,
'NutrInfo': nutrList
}))
names_all.extend(df['Name'])
descriptions_all.extend(df['Description'])
prices_all.extend(df['Price'])
weight_all.extend(df['Weight'])
nutr_all.extend(df['NutrInfo'])
df['Category'] = soup.find('div', class_='title__container').text.strip()
categories_all.extend(df['Category'])
result = pd.DataFrame((
{'Name': names_all,
'Description': descriptions_all,
'Price': prices_all,
'Category': categories_all,
'NutrInfo': nutr_all,
'Weight': weight_all,
}))
print("Парсинг Токио Сити окончен: " + str(datetime.datetime.now()))
Будет здорово увидеть какие-нибудь идеи по оптимизации/усовершенствованию этого парсера. Возможно, его можно сделать более универсальным. Сейчас, полагаю, он слишком топорный и капризный, если на сайте что-нибудь поменяется в страницах с категориями - он не будет работать.
А теперь к самому интересному - анализу полученной информации.
Начальные данные:
Наименование каждого блюда, его состав, цена, вес, калорийность, БЖУ и категория, к которой это блюдо относится.
Кусочек готовой к анализу таблицы с ассортиментом:
Для начала изучим общую направленность кухни каждого ресторана. Стоит сразу отметить, что речь пойдёт только о меню на доставку. Если сеть работает не только на доставку, но имеет и физические рестораны, то меню там может отличаться, возможно, оно будет больше и разнообразнее.
- Токио City
- Евразия
- 2 Берега
Теперь, познакомившись с ассортиментом всех трёх ресторанов, посмотрим, какие ответы можно получить из добытых данных.
Вопрос №1: какую долю занимает фастфуд от всего меню уникальных блюд каждого ресторана?
К фастфуду относятся бургеры, пицца и разного рода “стритфуд” вроде шавермы.В данном случае важно правильно определить, от каких категорий нужно считать процент, потому что некоторые категории не относятся к полноценным блюдам, а другие являются их дублированием. Поэтому из расчёта этого показателя убраны такие категории, как “Напитки”, “Детское меню”, “Соусы”, “Наборы”, “Ланчи” и “Десерты” + всевозможные вариации данных категорий.
Итог:
Выходит, “2 Берега” - №1 по разнообразию пиццы в ассортименте. Это подтверждается, даже если просто сравнить количество блюд в категории “Пицца” во всех ресторанах (“Токио City” - 20, “Евразия” - 17 и “2 Берега” - 51).
По остальным направлениям представленность фастфуда более-менее одинакова, разве что в “Евразии” отсутствует стритфуд.
Вопрос №2: в каком из трёх ресторанов самые выгодные и сытные порции?
В каждом из этих ресторанов достаточно много категорий, поэтому выберем самые показательные из них - “Супы”, “Салаты” и “Горячие блюда”. Там не приходится ждать никаких подводных камней в плане сортировки блюд по неправильным категориям. И, любопытства ради, добавим ещё категорию “Детское меню”, вдруг она проявит себя более интересно.Посчитав цену за 100 грамм блюда в каждом ресторане, получаем следующие результаты:
У “2 Берега” нет такой категории, как “Горячие блюда”. Есть ВОКи и паста, но традиционных горячих блюд вида “гарнир + мясо” нет. Поэтому в категории “Горячие блюда” сравниваются только “Токио City” и “Евразия”.
По всем категориям “Токио City” является безусловным лидером по соотношению цены и веса блюда. “2 Берега” занимает почётное 2 место. “Евразия” оказывается в хвосте рейтинга. Даже если вычесть из средней цены за 100 грамм блюда в “Евразии” 30% (это максимальная скидка, которую предоставляет ресторан по картам лояльности), ресторан все равно ни в одной категории не сможет обогнать “Токио City” по выгоде.
Теперь изучим размер порций, которые могут предложить данные рестораны:
“Евразия” снова по всем категориям не смогла обогнать другие рестораны. Средний “недовес” порции составляет 30% относительно двух других ресторанов.
Зато “2 Берега” отличился лучшим весом супов, салатов и детских блюд. Кстати, такой большой средний вес в категории “Детские блюда” у этого ресторана объясняется тем, что там представлены только наборы, в составе которых 2 блюда + напиток (вес напитка здесь не учитывается). Но даже с учётом этого факта можно похвалить этот ресторан за щедрые порции детского меню.
А “Токио City” предлагает отличные порции горячих блюд.
Вопрос №3: какова средняя калорийность блюда в каждом из ресторанов?
Здесь возьмем все блюда за исключением, конечно, напитков и соусов. Нам важно понять, насколько калорийна вся кухня ресторана в целом.
Калорийность половины блюд в “Токио City” не превышает 205 калорий в 100 граммах, поэтому присуждаем ресторану одного толстого кота из трёх. Это достаточно позитивный показатель для тех, кто следит за своим весом. А вот у блюд ресторана “2 Берега” этот показатель на 35% выше, поэтому он получает максимальное количество толстых котов. Впрочем, в этом нет ничего удивительного, если вспомнить, какую долю от всего меню этого ресторана занимает пицца.
Последний вопрос: насколько сбалансированное питание может предложить каждый из ресторанов?
Для того, чтобы ответить на этот вопрос, составим диаграммы рассеяния для каждого ресторана, где осями будут углеводы и белки, а цвет будет показывать количество жиров в каждом блюде.
Несмотря на самую высокую калорийность на 100 грамм и большое количество фастфуда “2 Берега” предлагает достаточно сбалансированное меню, тогда как у того же “Токио City” можно заметить явный перекос в сторону углеводов.
БЖУ “Евразии” какое-то слишком равномерное, практически без выбросов, поэтому вызывает подозрения.
Вообще в верности сделанных мной выводов конкретно в этом вопросе есть сомнения - возможно, для правильного ответа на вопрос эти показатели нужно оценивать как-то по-другому.
Вот такое небольшое, но любопытное, на мой взгляд, исследование получилось из случайной мысли “спарсить бы что-нибудь”.
Источник статьи: https://habr.com/ru/post/551294/