За звание лучшего переводчика сегодня поборются

Я выбрал 12 популярных языков: испанский, китайский (мандарин), русский, французский, немецкий, японский, португальский, корейский, голландский, хинди, индонезийский и арабский. Для каждого из них я буду тестировать перевод на английский и с английского каждым из кандидатов.
Есть пара исключений:
Брать необходимо только новые предложения, чтобы бороться с data contamination - известно, что обучающая выборка для GPT-3.5/GPT-4 заканчивается сентябрем 2021.
MarianMT модели обучались на датасете OPUS, сами разработчики тестируют их на Tatoeba, так что здесь никаких проблем нет.
Я специально взял самые длинные предложения, чтобы усложнить задачу. На коротких предложениях очень часто возникает ситуация, когда все переводы годные, и побеждает тот, который случайно оказался ближе всего к переводу человека.
Получилось, что лучше всего в системное сообщение написать
Я также пробовал использовать few-shot примеры. Оказалось, что на этой задаче добавление примеров чаще всего ухудшает метрики. Да, можно перебирать наборы примеров и найти те, которые улучшают, и выбрать среди них оптимальный. Однако, это больше похоже на переобучение модели на стиль Tatoeba-предложений. Поэтому я решил не использовать примеры, промт состоит только из системного сообщения и сообщения для перевода. Такое решение, вдобавок, потребляет гораздо меньше токенов и поэтому дешевле.
В итоге у меня получились следующие результаты: https://github.com/einhornus/prompt_gpt/tree/main/data/translation/reports. Каждый файл в этой папке содержит .json-отчет по конкретной языковой паре для одной из моделей. В каждом отчете предложения отсортированы по убыванию BLEU - легко анализировать самые худшие переводы.
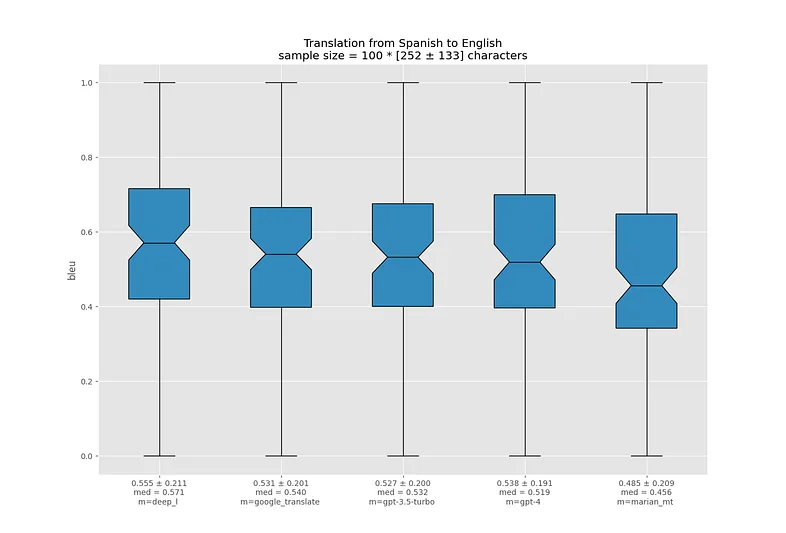
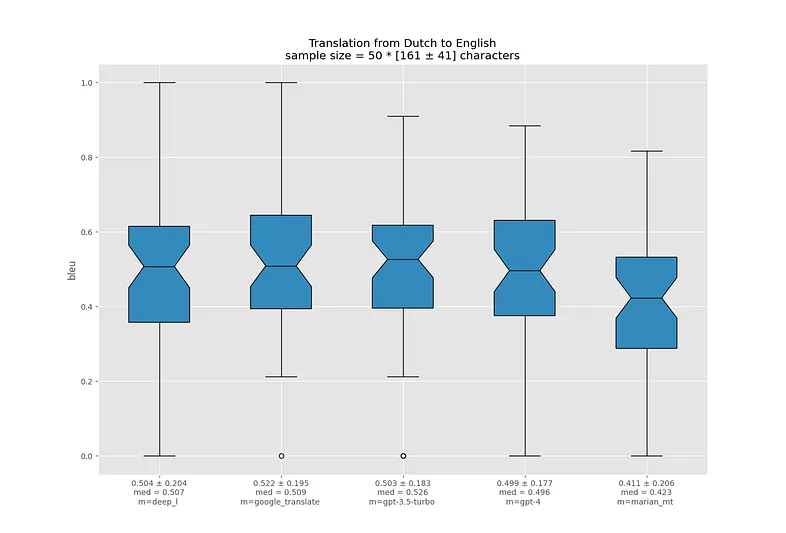
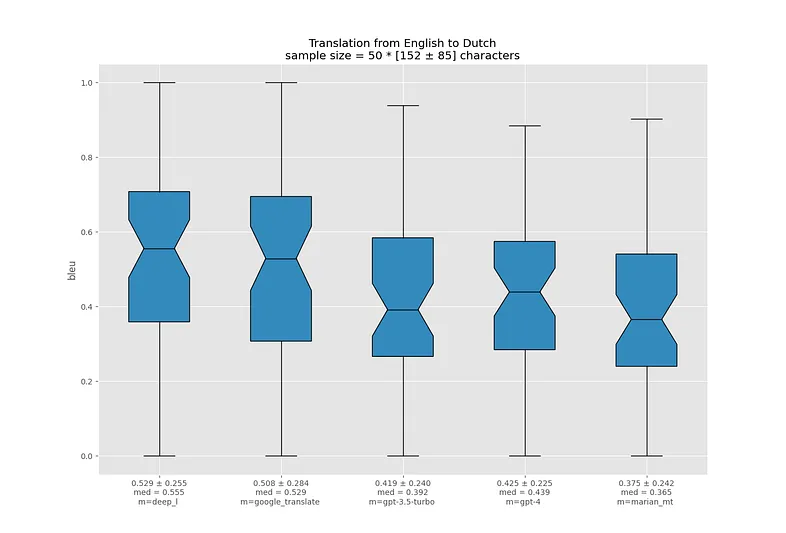
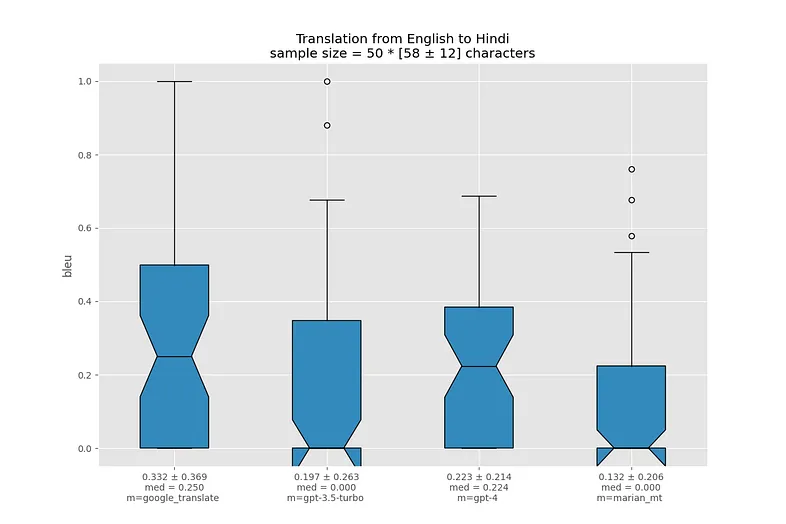
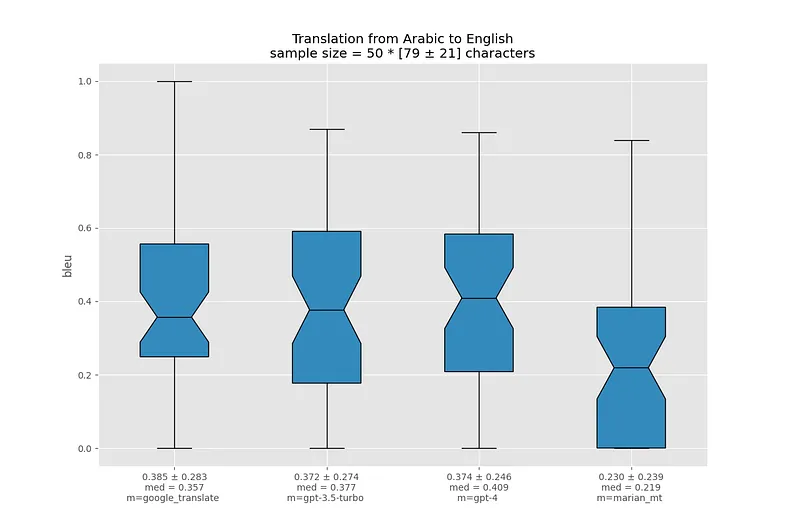
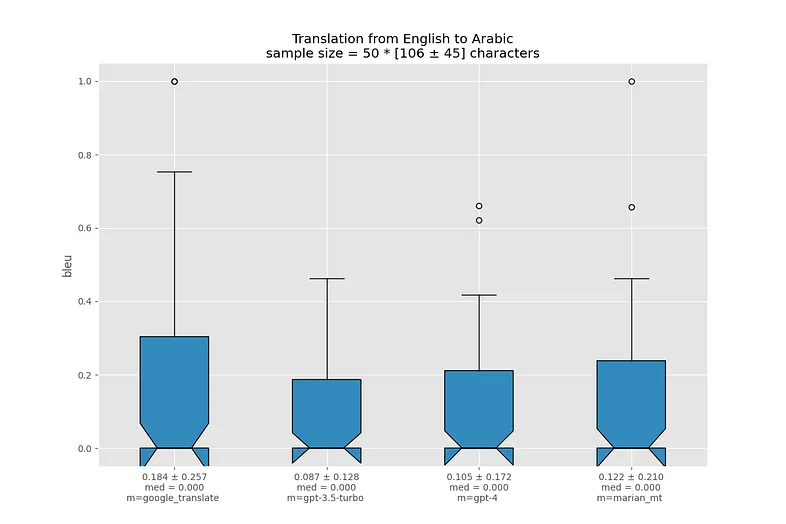
Я визуализировал распределение BLEU для каждой языковой пары в виде ящиков с усами. Жирная линия посередине ящика означает медиану, границы ящика показывают 25-й и 75-й перцентили. Треугольный вырез в центре называется "notch" и показывает доверительный интервал для медианы.
Ссылки под графиками ведут на соответствующие .json-отчеты.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
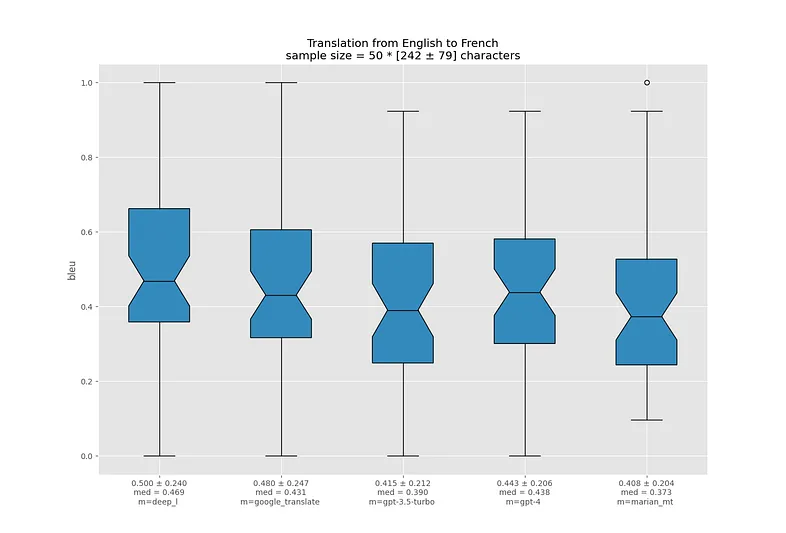
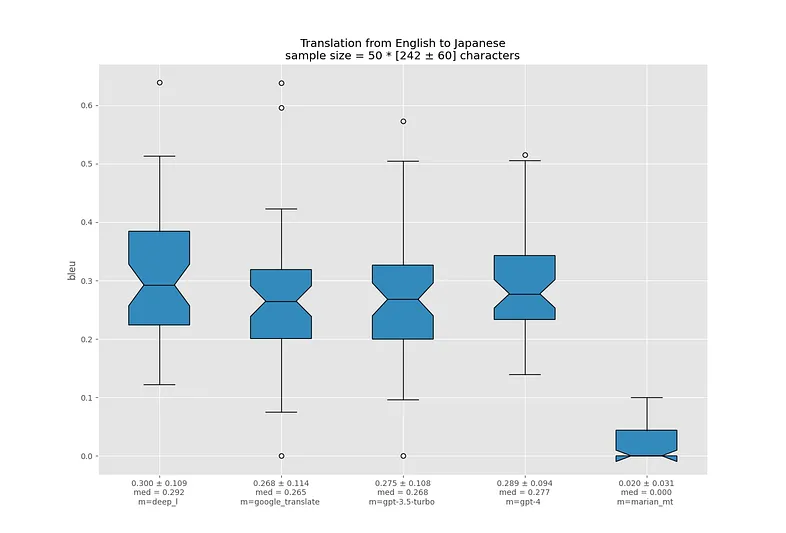
Перевод с испанского на английский - не очень сложная задача, и все модели справляются очень хорошо. Похожая ситуация наблюдается и с другими романскими языками.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
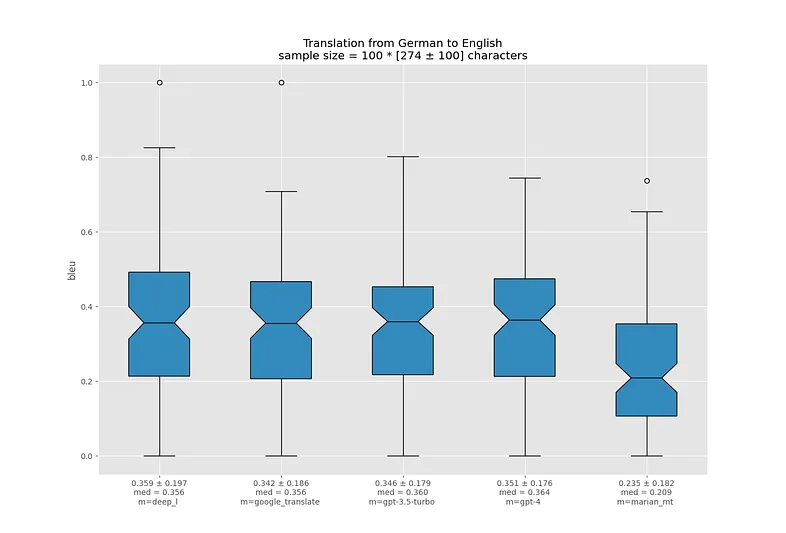
В самых худших переводах у MarianMT происходит полная потеря смысла, чего не скажешь про остальные модели.

DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
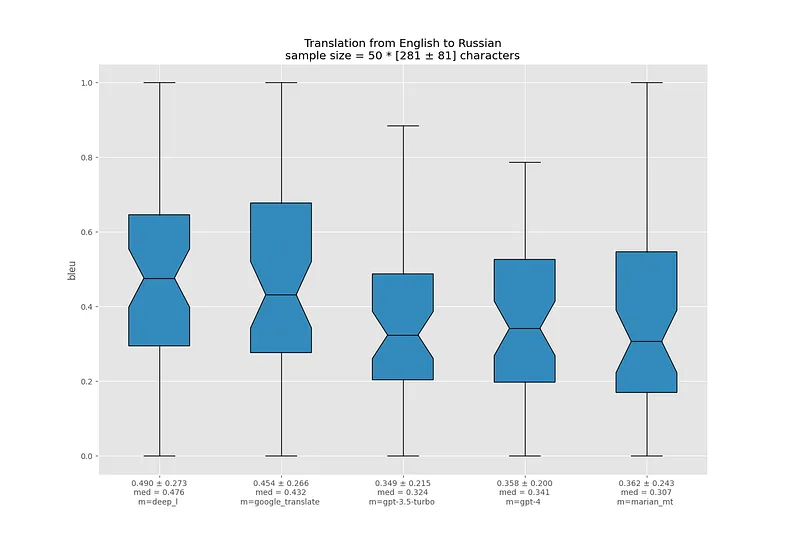
На русском GPT-3.5 и GPT-4 демонстрируют наихудшие результаты по BLEU относительно других моделей. Вероятно, это объясняется проблемами с токенизацией кириллицы.
На этот раз даже в самых худших переводах MarianMT корректно передает смысл.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
MarianMT иногда генерирует нереально кривые предложения на русском:
Вот те же предложения в переводе Google Translate:
Я сортировал все предложения по возрастанию разницы BLEU между переводом GPT-3.5 и Google Translate. Вот 3 примера из начала этого списка:
Вывод GPT-3.5 выглядит немного хуже, но он все равно правильно передает смысл и почти не содержит грамматических ошибок; хотя если судить по BLEU, результаты Google Translate должны быть на голову выше.
В первом случае вывод Google Translate полностью совпал с ожидаемым, что похоже на data contamination.
Во втором примере у Google Translate на второй половине предложения открылось "второе дыхание", и он начал переводить слово-в-слово. Однако, обвинять модель в data contamination на библейском примере довольно глупо")
Еще одним доказатеством data contamination у Google Translate служит перевод фразы "This is a proxy conflict between the former president and the former vice president, William A. Galston, a senior fellow in Brookings' Governance Studies program, told VOA as ballots were being cast on Tuesday." как 'Это опосредованный конфликт между бывшим президентом и бывшим вице-президентом, - сказал "Голосу Америки" Уильям А. Галстон, старший научный сотрудник программы исследований управления Брукингса, во время голосования во вторник.' (от перевода человека отличается только видом кавычек). В данном случае человек допустил мелкую ошибку, не упомянув про VOA. GPT-3.5 при переводе данной фразы VOA не забывает.
Теперь посмотрим на результаты DeepL.
Я давно использую DeepL, и в целом у меня сложилось впечатление, что его переводы на русский более естественны, чем у Google Translate.

DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT

DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
Вот тут Google Translate совсем сломался. Предложение 「漢字って、どうやったら簡単に覚えられますか?」「簡単には覚えられないよ。人それぞれだとは思うけど、覚えたいなら面倒でも書くのが一番だと思うよ」он переводит как "How can you easily memorize kanji?" вместо "What's the easiest way to learn kanji? "I don't think there is an easy way. It probably varies from person to person, but I think if you really want to learn, the best option is to just write them, even if it's a hassle.". В файле можно найти еще много подобных кейсов.
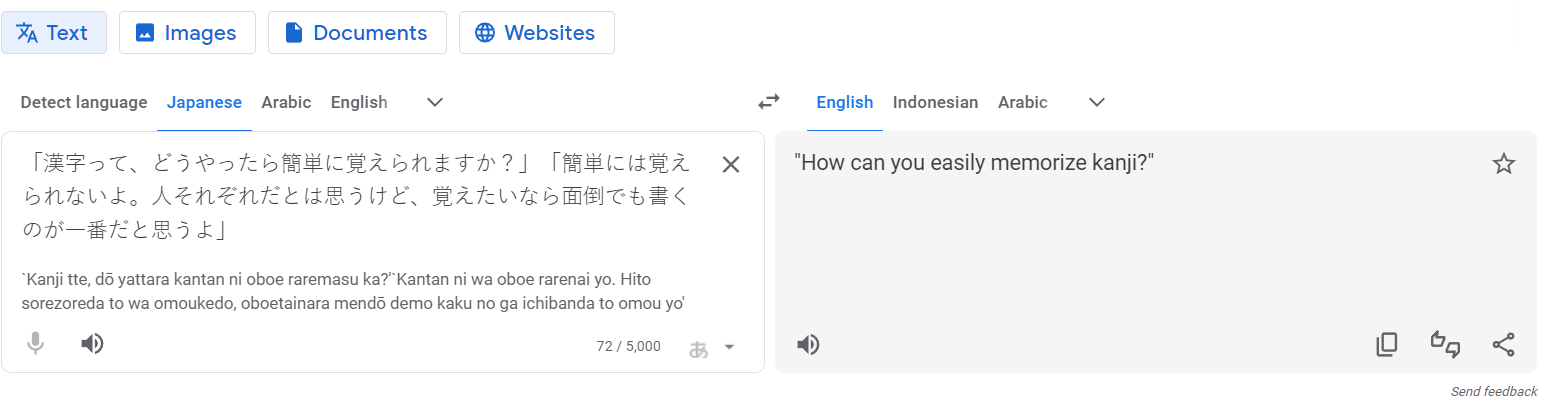
Для MarianMT перевод с японского оказался непосильной задачей: уже на медианных предложениях результаты не только выглядят криво, но еще и искажают смысл.
GPT-3.5 и GPT-4 показывают себя очень хорошо на этой языковой паре.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
MarianMT не способна работать на этой языковой паре: даже самый лучший перевод с BLEU=0.1 представляет собой треш.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT

DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT

DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
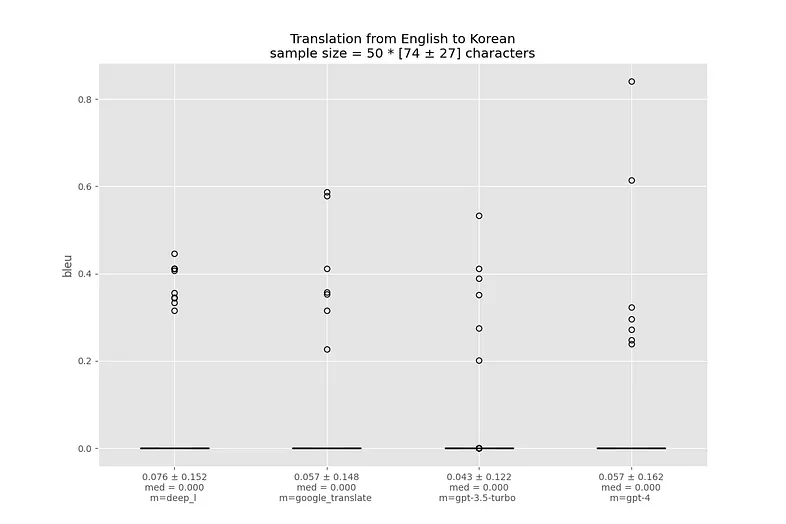
На корейском предложения были относительно короткими (что сильно упрощает задачу), но GPT-3.5 и даже MarianMT нормально передают их смысл.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
Возможно, такие плохие метрики связаны с какими-то особенностями корейского языка. Переводы с нулевым BLEU у всех моделей обычно не искажают смысл.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT

DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT

DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT

DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL API стоит $4.5 в месяц фиксированно + $18 за 1 миллион символов. Однако, есть большая проблема с доступностью этого API: нужно иметь карту, выпущенную в США, ЕС, Великобритании, Японии, Канаде, Швейцарии, Сингапуре, Лихтенштейне или Мексике. Тесты для статьи были проведены на бесплатном триале с помощью ключа, который предоставила знакомая автора из Японии (огромное спасибо ей за помощь). Собственно, данное гео-ограничение и послужило толчком для написания статьи: вдруг с помощью GPT-4 API (которое без проблем оплачивается с армянской карты) можно добиться по крайней мере такого же качества перевода, как и у DeepL?
Стоимость OpenAI API рассчитывается более сложно: тут вы платите не за символы, а за "токены". Токен - это слово или часть слова, соотношение числа символов на один токен зависит от языка.
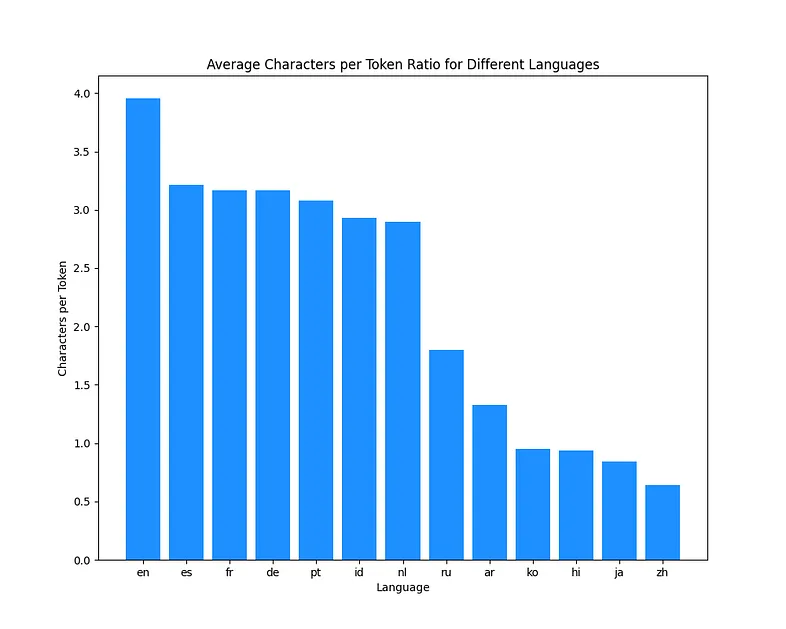
Видно, что у языков с латиницей это соотношение выше → использование API дешевле (плюс, сама модель работает лучше из-за более удачной токенизации). Есть два исключения: китайский и японский. Да, соотношение символы/токены для них очень низкое, но зато сами тексты занимают гораздо меньше символов.
В отличие от других API, в OpenAI API вы платите как за токены промта, так и за токены ответа. Для GPT-3.5 цена этих токенов одинакова и равна $0.002 за тысячу токенов. У GPT-4 токены промта стоят $0.03 за тысячу, а токены ответа - $0.06 за тысячу.
Я визуализировал примерную стоимость перевода сообщения в 500 символов для разных языковых пар с учетом всего вышесказанного.
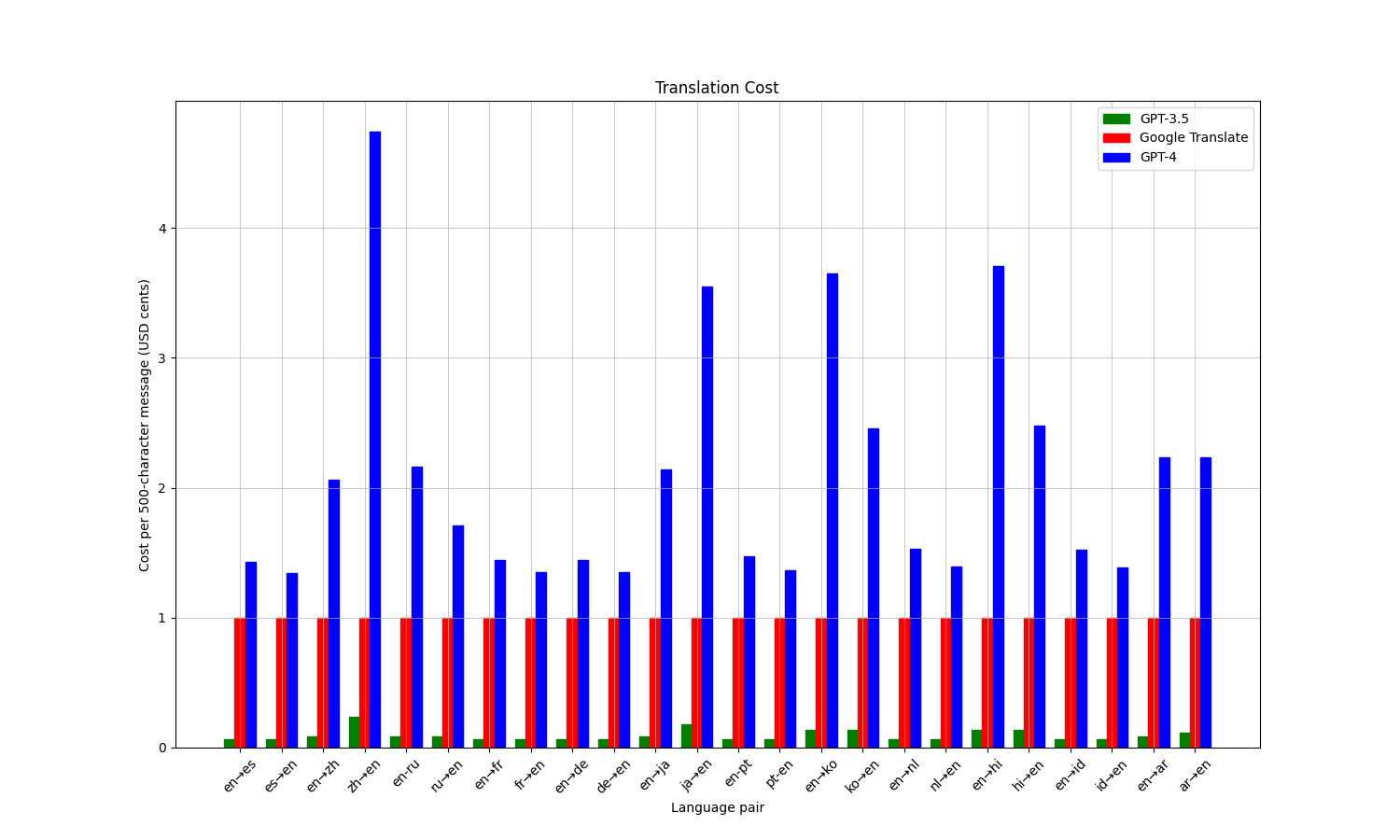
В большинстве случаев GPT-3.5 API стоит в 5-15 раз меньше Google Cloud Platform Translation API, тогда как GPT-4 API обойдется в 1.2-4 раза дороже. Реальное соотношение цен зависит от языковой пары.
Скорость работы MarianMT зависит от ваших ресурсов, но в целом модель не очень быстрая. Кроме того, вам нужно будет хранить на диске и загружать в память каждую модель отдельно.

 habr.com
habr.com
- Google Translate - в представлении не нуждается. Я воспользуюсь официальным API, которое стоит $20 за миллион символов.
- DeepL - конкурент Google Translate. У него тоже есть API, цена использования которого примерно такая же.
- GPT-3.5. Я буду использовать OpenAI Chat API. Подробнее о работе с ним вы можете почитать в моих предыдущих статьях.
- GPT-4. У меня есть доступ к GPT-4 API (сейчас его предоставляют по вейтлисту). Вызов GPT-4 не отличается от вызова GPT-3.5; модель умнее, но гораздо дороже.
- MarianMT - семейство моделей для различных языковых пар, которые зафантюнили специалисты из Helsinki-NLP. Модели можно скачать с Hugging Face и бесплатно запускать на своих ресурсах (однако, придется немного заморочиться с запуском). В зависимости от языковой пары, доступна либо большая модель (~ 500 MB), либо стандартная (~ 300 MB). Есть модели, которые работают с несколькими языками сразу. Я буду использовать большие модели, где это возможно.
Я выбрал 12 популярных языков: испанский, китайский (мандарин), русский, французский, немецкий, японский, португальский, корейский, голландский, хинди, индонезийский и арабский. Для каждого из них я буду тестировать перевод на английский и с английского каждым из кандидатов.
Есть пара исключений:
- DeepL поддерживает только 29 языков, среди которых нет хинди и арабского
- MarianMT модель для перевода с английского на корейский сломана, она генерирует бред даже в демо на Hugging Face
Сбор данных
Я собрал собственный набор данных на основе датасета Tatoeba: для каждой языковой пары я взял по 50 или 100 самых длинных параллельных предложений, которые были добавлены позже сентября 2021.Брать необходимо только новые предложения, чтобы бороться с data contamination - известно, что обучающая выборка для GPT-3.5/GPT-4 заканчивается сентябрем 2021.
MarianMT модели обучались на датасете OPUS, сами разработчики тестируют их на Tatoeba, так что здесь никаких проблем нет.
Я специально взял самые длинные предложения, чтобы усложнить задачу. На коротких предложениях очень часто возникает ситуация, когда все переводы годные, и побеждает тот, который случайно оказался ближе всего к переводу человека.
Сравнение качества перевода
Я оптимизировал промт для GPT-3.5/GPT-4 способом, который я описал в предыдущей статье.Получилось, что лучше всего в системное сообщение написать
Второе предложение очень важно - без него сильно ухудшается BLEU.Please translate the user message from {src} to {tgt}. Make the translation sound as natural as possible.
Я также пробовал использовать few-shot примеры. Оказалось, что на этой задаче добавление примеров чаще всего ухудшает метрики. Да, можно перебирать наборы примеров и найти те, которые улучшают, и выбрать среди них оптимальный. Однако, это больше похоже на переобучение модели на стиль Tatoeba-предложений. Поэтому я решил не использовать примеры, промт состоит только из системного сообщения и сообщения для перевода. Такое решение, вдобавок, потребляет гораздо меньше токенов и поэтому дешевле.
В итоге у меня получились следующие результаты: https://github.com/einhornus/prompt_gpt/tree/main/data/translation/reports. Каждый файл в этой папке содержит .json-отчет по конкретной языковой паре для одной из моделей. В каждом отчете предложения отсортированы по убыванию BLEU - легко анализировать самые худшие переводы.
Я визуализировал распределение BLEU для каждой языковой пары в виде ящиков с усами. Жирная линия посередине ящика означает медиану, границы ящика показывают 25-й и 75-й перцентили. Треугольный вырез в центре называется "notch" и показывает доверительный интервал для медианы.
Ссылки под графиками ведут на соответствующие .json-отчеты.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
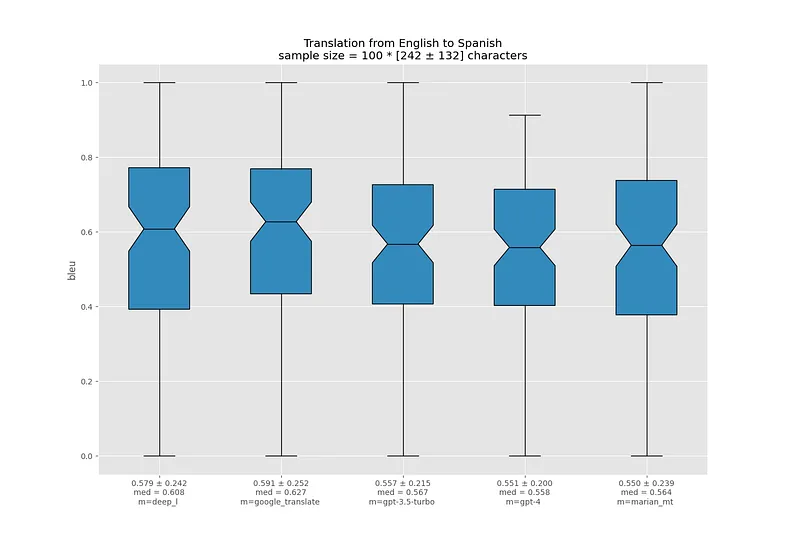
Перевод с испанского на английский - не очень сложная задача, и все модели справляются очень хорошо. Похожая ситуация наблюдается и с другими романскими языками.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
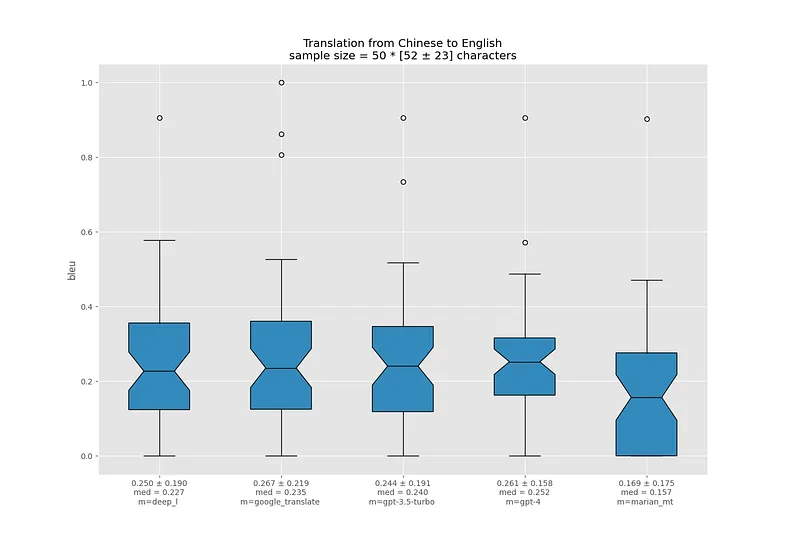
В самых худших переводах у MarianMT происходит полная потеря смысла, чего не скажешь про остальные модели.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
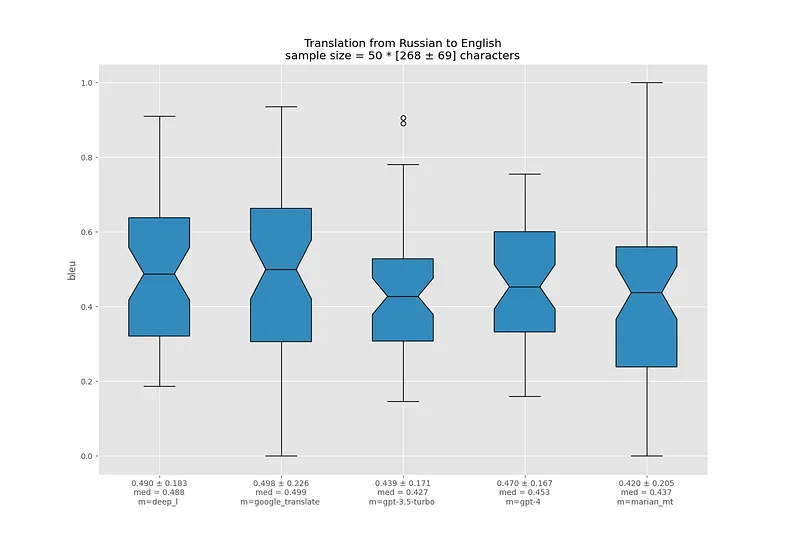
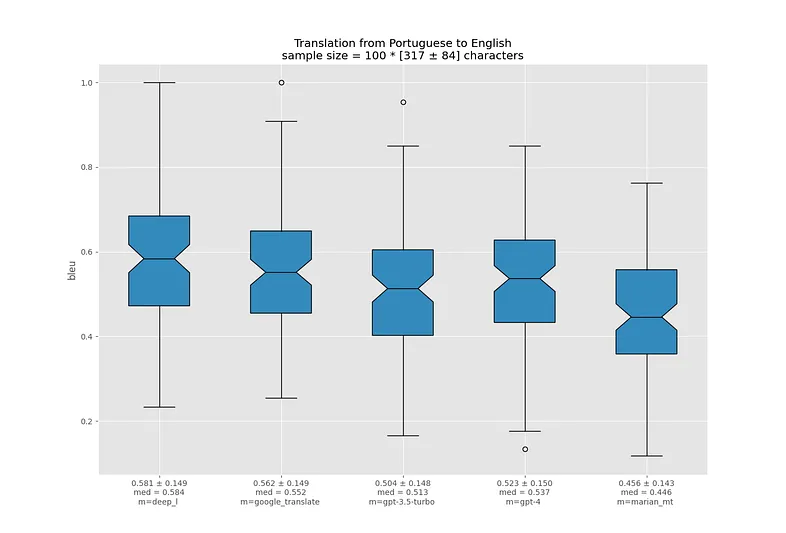
На русском GPT-3.5 и GPT-4 демонстрируют наихудшие результаты по BLEU относительно других моделей. Вероятно, это объясняется проблемами с токенизацией кириллицы.
На этот раз даже в самых худших переводах MarianMT корректно передает смысл.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
MarianMT иногда генерирует нереально кривые предложения на русском:
Вот те же самые предложения от GPT-3.5 (смысл передан верно, грамматических ошибок формально нет, но первые два предложения выглядят неестественно)Вот скриншот их страницы магазина за неделю назад, и вот как это выглядит сегодня. У них точно такие же цены, но текущий утверждает, что они все на 50%. Странно, не так ли? (Here's a screenshot of their store page from a week ago, and here's what it looks like today. They have the exact same prices listed, but the current one claims they're all 50% off. Strange, isn't it?)
О, парень! Это конечно прекрасное утро здесь! На самом деле, я не могу дождаться, чтобыхух? Что случилось? "Как дела, Линк?" "Моршу, что происходит?" "Ха, просто. Со всеми деньгами, которые я сделал на моем успешном бизнесе и моей успешной карьере битбокса, я разбогател!" "Вау, так что вы устроили нам вечеринку?" "Ха, нет. Безопасность, возьми этих ублюдков." (Oh boy! It sure is a beautiful morning around here! In fact, I can't wait to–huh? What happened? "What's up, Link?" "Morshu, what is going on?" "Hah, simple. With all the money I made from my successful businesses and my successful beatboxing career, I got rich!" "Wow, so you threw us a party?" "Hah, nope. Security, get those motherfuckers out.")
Мне очень нравится эта доска, но одна из самых разочаровывающих вещей здесь - это количество плакатов, у которых есть серьезное непонимание любой формы юмора и которые, следовательно, относятся к вещам слишком серьезно. Это настоящее раздражение, но с ним нужно жить. (I like this board a lot, but one of the most frustrating things about it is the amount of posters here who have a serious lack of understanding of any form of humour and who consequently take things too seriously. It is a real annoyance but one has to live with it.)
В целом, от переводов GPT-3.5 иногда попахивает машинностью, но прямо совсем треша я в них не вижу; когда как результаты MarianMT местами совсем неприемлемы для использования в проде. Это немного странно, учитывая что медианный BLEU у них близок.Вот скриншот их страницы магазина на прошлой неделе, а вот как она выглядит сегодня. Они указали точно такие же цены, но на текущей странице написано, что все товары со скидкой 50%. Странно, не так ли?
Ого, какое прекрасное утро здесь! На самом деле, я не могу дождаться - что случилось? "Что случилось, Линк?" "Моршу, что происходит?" "Хах, просто. Со всеми деньгами, которые я заработал благодаря своим успешным бизнесам и успешной карьере битбоксера, я разбогател!" "Вау, так ты устроил нам вечеринку?" "Хах, нет. Охрана, выкиньте этих ублюдков."
Мне очень нравится этот форум, но одна из самых раздражающих вещей здесь - это количество пользователей, которые не понимают юмора и слишком серьезно относятся к вещам. Это действительно раздражает, но приходится с этим жить.
Вот те же предложения в переводе Google Translate:
К первому переводу никаких вопросов, но во втором и третьем есть явные ошибки (Oh boy! → О, парень!, вытащите ублюдков, board (форум) → доска). Если проигнорировать ошибки, то в целом текст написан более естественно, чем у GPT-3.5. Кажется, в этом и заключается причина разницы в BLEU - большое количество мелких ошибок у GPT-3.5 сильнее снижает BLEU, чем небольшое количество грубых у Google Translate.Вот скриншот их страницы в магазине, сделанный неделю назад, и вот как она выглядит сегодня. У них указаны одинаковые цены, но текущая утверждает, что все они со скидкой 50%. Странно, не так ли?
О, парень! Здесь, конечно, прекрасное утро! На самом деле, я не могу дождаться… а? Что случилось? — Что случилось, Линк? — Моршу, что происходит? «Ха, просто. Со всеми деньгами, которые я заработал на своем успешном бизнесе и успешной карьере битбоксера, я разбогател!» — Вау, так ты устроил нам вечеринку? «Ха, нет. Охрана, вытащите этих ублюдков».
Мне очень нравится эта доска, но одна из самых неприятных вещей на ней — это количество постеров, которые серьезно не понимают ни одной формы юмора и, следовательно, слишком серьезно относятся к вещам. Это действительно неприятно, но с этим нужно жить.
Я сортировал все предложения по возрастанию разницы BLEU между переводом GPT-3.5 и Google Translate. Вот 3 примера из начала этого списка:
Образцовый перевод | GPT-3.5 | Google Translate | BLEU1 BLEU2 |
| Дин Лижэнь — новый чемпион мира по шахматам. На тай-брейке первые три партии закончились вничью, а четвертую, когда Дин вел черными в испанском дебюте, сенсационно выиграл китайский дракон, который таким образом победил русского медведя Яна Непомнящего. У вершины шахматной вселенной новое лицо. | Дин Лирен - новый чемпион мира по шахматам. В тай-брейке первые три игры закончились вничью, а четвертая, в которой Дин играл черными фигурами в испанском открытии, была сенсационно выиграна китайским драконом, который таким образом победил русского медведя Яна Непомнящего. В вершине шахматной вселенной появилось новое лицо. | Дин Лижэнь — новый чемпион мира по шахматам. На тай-брейке первые три партии закончились вничью, а четвертую, когда Дин вел черными в испанском дебюте, сенсационно выиграл китайский дракон, который таким образом победил русского медведя Яна Непомнящего. У вершины шахматной вселенной новое лицо. | 0.326 1.000 |
И сказал им Ангел: не бойтесь; я возвещаю вам великую радость, которая будет всем людям: ибо ныне родился вам в городе Давидовом Спаситель, Который есть Христос Господь; и вот вам знак: вы найдете Младенца в пеленах, лежащего в яслях. И внезапно явилось с Ангелом многочисленное воинство небесное, славящее Бога и взывающее: слава в вышних Богу, и на земле мир, в человеках благоволение! | И сказал им Ангел: "Не бойтесь, ибо возвещаю вам великую радость, которая будет для всего народа: ныне родился вам Спаситель, Который есть Христос Господь, в городе Давидовом. И вот вам знак: вы найдете Младенца, пеленанный и лежащий в яслих". И вдруг явилось с Ангелом множество воинственной армии небесной, славящей Бога и говорящей: "Слава Богу на высоте, и на земле мир, воля к людям благоволение". | И сказал им ангел: не бойтесь, ибо вот, я возвещаю вам великую радость, которая будет для всех людей. Ибо родился вам ныне в городе Давидовом Спаситель, Который есть Христос Господь. И это будет вам знамением; Младенца найдёте в пеленах, лежащего в яслях. И внезапно явилось с Ангелом многочисленное воинство небесное, славящее Бога и взывающее: слава в вышних Богу, и на земле мир, в человеках благоволение. | 0.346 0.716 |
По мнению Тома, теория эволюции путем случайных мутаций и естественного отбора неубедительна по нескольким причинам, самой важной из которых является существование ДНК. Среди прочих неприемлемых пунктов, добавляет Том, эта теория утверждает, что человеческий разум – Сократа, Платона, Аристотеля, Галилея, Ньютона, Шекспира, Декарта, да Винчи, Моцарта, Эйнштейна, самого Дарвина – развился из разума неизвестного примата, который якобы был нашим предком. | По словам Тома, теория эволюции случайных мутаций и естественного отбора неубедительна по нескольким причинам, наиболее важной из которых является существование ДНК. Среди других неприемлемых моментов, Том добавляет, что эта теория утверждает, что человеческий разум - Сократ, Платон, Аристотель, Галилео, Ньютон, Шекспир, Декарт, да Винчи, Моцарт, Эйнштейн, сам Дарвин - развился из разума неопределенной приматы, которая была бы нашим предком. | По словам Тома, теория эволюции путем случайных мутаций и естественного отбора неубедительна по нескольким причинам, важнейшей из которых является существование ДНК. Среди прочих неприемлемых моментов, добавляет Том, эта теория утверждает, что человеческий разум — Сократа, Платона, Аристотеля, Галилея, Ньютона, Шекспира, Декарта, да Винчи, Моцарта, Эйнштейна, самого Дарвина — развился из разума неопознанного примата, который будет нашим предком. | 0.386 0.756 |
В первом случае вывод Google Translate полностью совпал с ожидаемым, что похоже на data contamination.
Во втором примере у Google Translate на второй половине предложения открылось "второе дыхание", и он начал переводить слово-в-слово. Однако, обвинять модель в data contamination на библейском примере довольно глупо
Еще одним доказатеством data contamination у Google Translate служит перевод фразы "This is a proxy conflict between the former president and the former vice president, William A. Galston, a senior fellow in Brookings' Governance Studies program, told VOA as ballots were being cast on Tuesday." как 'Это опосредованный конфликт между бывшим президентом и бывшим вице-президентом, - сказал "Голосу Америки" Уильям А. Галстон, старший научный сотрудник программы исследований управления Брукингса, во время голосования во вторник.' (от перевода человека отличается только видом кавычек). В данном случае человек допустил мелкую ошибку, не упомянув про VOA. GPT-3.5 при переводе данной фразы VOA не забывает.
Теперь посмотрим на результаты DeepL.
Есть очень грубая ошибка: "количество постеры, которые имеют серьезное непонимание любой формы юмора".Вот скриншот страницы их магазина недельной давности, а вот как она выглядит сегодня. На них указаны точно такие же цены, но на текущей странице утверждается, что на все товары действует скидка 50%. Странно, не правда ли?
О, Боже! Какое прекрасное утро! На самом деле, я не могу дождаться... а? Что случилось? "Что случилось, Линк?" "Моршу, что происходит?" "Хах, все просто. Со всеми деньгами, которые я заработал на своем успешном бизнесе и успешной карьере битбоксера, я разбогател!" "Вау, так ты устроил нам вечеринку?" "Ха, неа. Охрана, выведите этих ублюдков".
Мне очень нравится этот форум, но одна из самых неприятных вещей в нем - это количество постеры, которые имеют серьезное непонимание любой формы юмора и, следовательно, воспринимают все слишком серьезно. Это действительно раздражает, но с этим приходится жить.
Я давно использую DeepL, и в целом у меня сложилось впечатление, что его переводы на русский более естественны, чем у Google Translate.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
Вот тут Google Translate совсем сломался. Предложение 「漢字って、どうやったら簡単に覚えられますか?」「簡単には覚えられないよ。人それぞれだとは思うけど、覚えたいなら面倒でも書くのが一番だと思うよ」он переводит как "How can you easily memorize kanji?" вместо "What's the easiest way to learn kanji? "I don't think there is an easy way. It probably varies from person to person, but I think if you really want to learn, the best option is to just write them, even if it's a hassle.". В файле можно найти еще много подобных кейсов.
Для MarianMT перевод с японского оказался непосильной задачей: уже на медианных предложениях результаты не только выглядят криво, но еще и искажают смысл.
GPT-3.5 и GPT-4 показывают себя очень хорошо на этой языковой паре.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
MarianMT не способна работать на этой языковой паре: даже самый лучший перевод с BLEU=0.1 представляет собой треш.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
На корейском предложения были относительно короткими (что сильно упрощает задачу), но GPT-3.5 и даже MarianMT нормально передают их смысл.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
Возможно, такие плохие метрики связаны с какими-то особенностями корейского языка. Переводы с нулевым BLEU у всех моделей обычно не искажают смысл.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
Анализ стоимости API
Google Cloud Platform Translation API стоит $20 за 1 миллион символов.DeepL API стоит $4.5 в месяц фиксированно + $18 за 1 миллион символов. Однако, есть большая проблема с доступностью этого API: нужно иметь карту, выпущенную в США, ЕС, Великобритании, Японии, Канаде, Швейцарии, Сингапуре, Лихтенштейне или Мексике. Тесты для статьи были проведены на бесплатном триале с помощью ключа, который предоставила знакомая автора из Японии (огромное спасибо ей за помощь). Собственно, данное гео-ограничение и послужило толчком для написания статьи: вдруг с помощью GPT-4 API (которое без проблем оплачивается с армянской карты) можно добиться по крайней мере такого же качества перевода, как и у DeepL?
Стоимость OpenAI API рассчитывается более сложно: тут вы платите не за символы, а за "токены". Токен - это слово или часть слова, соотношение числа символов на один токен зависит от языка.
Видно, что у языков с латиницей это соотношение выше → использование API дешевле (плюс, сама модель работает лучше из-за более удачной токенизации). Есть два исключения: китайский и японский. Да, соотношение символы/токены для них очень низкое, но зато сами тексты занимают гораздо меньше символов.
В отличие от других API, в OpenAI API вы платите как за токены промта, так и за токены ответа. Для GPT-3.5 цена этих токенов одинакова и равна $0.002 за тысячу токенов. У GPT-4 токены промта стоят $0.03 за тысячу, а токены ответа - $0.06 за тысячу.
Я визуализировал примерную стоимость перевода сообщения в 500 символов для разных языковых пар с учетом всего вышесказанного.
В большинстве случаев GPT-3.5 API стоит в 5-15 раз меньше Google Cloud Platform Translation API, тогда как GPT-4 API обойдется в 1.2-4 раза дороже. Реальное соотношение цен зависит от языковой пары.
Скорость
Google Translate и DeepL сильно выигрывают у OpenAI по скорости. Кроме того, их API сейчас гораздо стабильнее: сервера OpenAI находятся под большой нагрузкой, запросы иногда возвращают ошибки, и их приходится отправлять заново (надеюсь, они это пофиксят). Проблемы со скоростью частично нивелирует тот факт, что ответ модели можно стримить постепенно, токен за токеном.Скорость работы MarianMT зависит от ваших ресурсов, но в целом модель не очень быстрая. Кроме того, вам нужно будет хранить на диске и загружать в память каждую модель отдельно.
Кастомизируемость
Большое достоинство перевода с помощью GPT-3.5/GPT-4 в том, что вы можете дальше его кастомизировать на свой вкус:- Можно поменять промт и делать переводы в каком-то определенном стиле
- Можно генерировать множество разных переводов с помощью разных промтов и/или установив температуру >0; затем можно выбирать наилучший перевод по какому-то критерию (например, по семантическому сходству с оригиналом, которое вычисляется другой нейронкой)
Выводы
- Метрики подтверждают интуитивное ощущение, что DeepL переводит лучше, чем Google Translate.
- Относительное положение GPT-3.5/GPT-4 по метрике BLEU сильно зависит от языковой пары: эти модели могут как побеждать даже DeepL, так и сильно проигрывать Google Translate. Нужно изучать графики по конкретным языковым парам. Видимо, эта особенность связана с особенностями токенизации для разных языков.
- GPT-3.5 переводит немного "машинно", но в целом результаты приемлемы в проде почти всегда. Даже в самых худших сценариях GPT-3.5 сохраняет смысл и генерирует результаты с минимумом грамматических ошибок (чего не скажешь про Google Translate и тем более про MarianMT). Вкупе с низкой стоимостью, это делает GPT-3.5 подходящим для использования во множестве реальных кейсов.
У меня есть гипотеза, что провалы GPT-3.5 по BLEU на некоторых языках объясняются токенизацией: из-за этого модель делает много мелких стилистических ошибок (в результате текст звучит немного неестественно), а метрика BLEU устроена таким образом, что она очень сильно наказывает подобное поведение; тогда как Google Translate и DeepL делают меньше ошибок, но эти ошибки более грубые.
Также видно, что у части результатов Google Translate завышен BLEU из-за data contamination.
С учетом того, что большинство бенчмарков для перевода делаются на BLEU, практически неизбежен подбор гиперпараметров в специализированных нейронках именно для оптимизации этой метрики; тогда как в GPT-3.5 решении на оптимизицию BLEU подобран только промт. - GPT-4 показывает себя гораздо лучше GPT-3.5, по BLEU она в целом наравне с Google Translate (но в реальности она лучше Google Translate по причинам из предыдущего пункта), и иногда даже бьет DeepL. Однако, ее цена выше, чем у Google Translate.
- MarianMT своими результатами не впечатляет, но было бы наивно полагать, что маленькая и бесплатная модель сможет на равных конкурировать с проприетарными гигантами. Однако, результаты MarianMT приемлемы на простых языковых парах. Не стоит использовать MarianMT на сложных языках (таких как китайский, японский, корейский, арабский, хинди; частично это относится и к русскому) - модель может сильно искажать смысл, порождать тексты с кучей грамматических ошибок, а иногда и вовсе генерировать бред.
Сравнение нейросетей для перевода
За звание лучшего переводчика сегодня поборются Google Translate - в представлении не нуждается. Я воспользуюсь официальным API , которое стоит $20 за миллион символов. DeepL - конкурент Google...
habr.com