В области поисковых систем с открытым исходным кодом появилось несколько новых интересных игроков. Мы решили внимательно изучить некоторые из них, чтобы узнать, насколько они сравнимы с Elasticsearch - как по набору функций, так и по производительности.
TypeSense: Размер хранилища ограничен доступной оперативной памятью. Источник
Meilisearch: Максимальное количество слов, учитываемых для каждого поискового запроса - 10. Максимальный размер базы данных - 100 ГБ (может быть изменен в конфиге). Максимум 200 индексов. Максимум 1000 слов в одном поле. Источник
Дата: 20 июля 2021 г.
Документов: 6,3 млн
Размер XML: 6,0 ГБ
Слова запроса выбираются случайным образом из 1000 самых распространенных английских слов.
Для индексации мы учитывали только время, которое индексатор потратил на запросы к серверу.
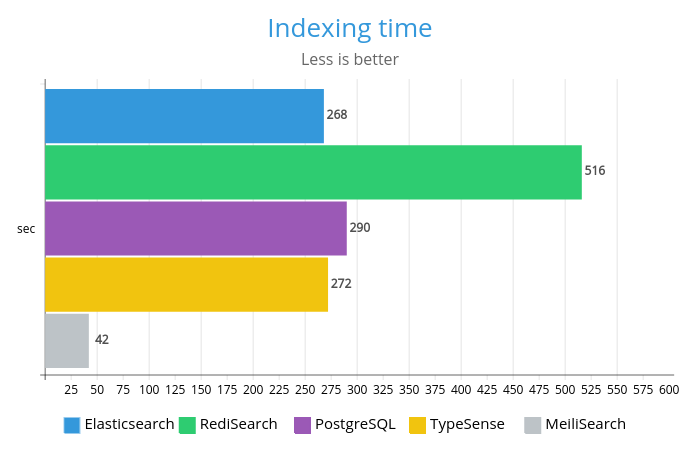
Elasticsearch, PostgreSQL и Typesense показывают здесь очень похожую производительность, в то время как RediSearch примерно в 2 раза медленнее; этот результат странным образом противоречит результатам тестов RedisLabs, поэтому настройка может быть здесь неоптимальной.
В то же время, Meilisearch блещет, будучи почти в 7 раз быстрее остальных.
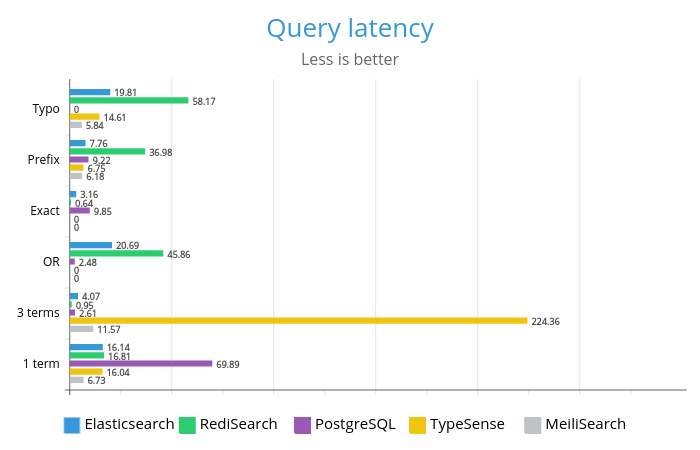
Опять же, RediSearch оказался в среднем довольно медленным, и снова RedisLabs получили другие результаты. Еще один неожиданно медленный результат показал запрос из трех слов в Typesense.
Meilisearch показал довольно хорошую производительность, особенно для запросов с префиксами и опечатками.
Мы использовали нули для отображения неподдерживаемых типов запросов на графиках, но если приглядеться, видно, что RediSearch показал результат менее 1 мс (!) для запросов «точная фраза» и «три слова И».
RediSearch имеет посредственную производительность индексации; также RedisLabs изо всех сил стараются продать свое облачное решение, поэтому документация не на высоте. Но эта система показывает минимальную задержку (менее миллисекунды) для некоторых типов запросов.
PostgreSQL показал странную "яму" производительности для простых запросов из одного слова, и интерфейс поиска довольно сложен. Хотя, если у вас уже есть база данных Postgres, встроенный поиск может быть неплохим решением для простых случаев.
У TypeSense неплохой набор функций, и производительность в целом тоже на высоте, за исключением странного провала при запросах из нескольких слов.
Кажущаяся высокая производительность MeiliSearch была вызвана ориентацией теста только на время ответа при индексировании, но Meili больше других полагается на асинхронную обработку. Мы не смогли провести тест с ожиданием индексации каждой порции данных, т.к. в таком режиме система оказалась мучительно медленной.
То есть, по-видимому, замедление вызвано тем, что мы выбираем 3 случайных английских слова для запроса, и при отсутствии в индексе документов, содержащих все три слова Typesense начинает отбрасывать слова, пока не получает результат, и этот процесс не очень быстр.
Джейсон также отметил, что кажущаяся быстрая индексация Meilisearch на самом деле была вызвана асинхронностью запросов индексации. Мы обновили тест, чтобы он дожидался завершения индексирования каждой порции, но в таком режиме индексация занимает как-то невероятно много времени, так что, видимо, нам нужно повнимательнее изучить, как Meilisearch работает под капотом.
Дополнение для Хабра
Раз уж все скрипты были готовы, я в свободное время погонял те же тесты для более экзотических систем.
Sonic
Ужасно медленная индексация. Не дождался окончания теста, хоть он и работал всю ночь.
Toshi
Индексация: 273 док/сек (настройки по умолчанию), 37631 док/сек с использованием недокументированного эндпоинта _bulk для пакетной работы
Запрос 1 слово: 372 з/сек, 2.68 мс
Запрос 3 слова: 357 з/сек, 2.79 мс
Запрос 3 слова с опечатками: 325 з/сек, 3.07 мс
Неплохие в целом показатели, но для индексации обязательно нужно использовать _bulk.
Quickwit
Индексация (из отдельно подготовленного файла с ndjson): 37085 док/сек
Запрос 1 слово: 324 з/сек, 3.08 мс
Запрос 3 слова: 324 з/сек, 3.08 мс ¯_(ツ)_/¯
Неплохие показатели, но для индексации нужно заранее готовить данные.
Groonga
Индексация: 77372 док/сек
Запрос 1 слово: 0.56 з/сек, 1782 мс
Запрос 3 слова: 0.50 з/сек, 1982 мс
Очень быстрая индексация, но ОЧЕНЬ медленный поиск.
 habr.com
habr.com
Кандидаты
- Elasticsearch - "взрослая" полнотекстовая поисковая система, основанная на Lucene.
- RediSearch - полнотекстовый поиск поверх Redis от RedisLabs
- Postgres FTS - полнотекстовые индексы для Postgres
- TypeSense - альтернатива Algolia с открытым исходным кодом
- MeiliSearch - альтернатива Algolia с открытым исходным кодом
Функциональное сравнение
| Функция | Elastic | RediSearch | PostgreSQL | TypeSense | MeiliSearch |
| Хранилище | Диск | RAM + снэпшоты | Диск | RAM + снэпшоты | RAM + снэпшоты |
| Распределенная работа | Мастер-реплика | RAFT | Мастер-реплика | RAFT | НЕТ |
| Репликация | + | НЕТ | + | НЕТ | НЕТ |
| Поддерживаемые языки | латиница + cjk + кириллица + арабский + еще 10 | латиница + арабский, русский, китайский | латиница + арабский, русский | с пробелами | с пробелами + кандзи |
| Исправление опечаток | да, но медленно | + | НЕТ | + | + |
| Бустинг | + | + | + | + | НЕТ |
| Точный поиск | + | + | + | НЕТ | НЕТ |
| Синонимы | + | + | + | + | + |
Известные ограничения
Elasticsearch: Нестабильность, если в кластере больше ~1000 индексов (или 20 тыс. шардов)TypeSense: Размер хранилища ограничен доступной оперативной памятью. Источник
Meilisearch: Максимальное количество слов, учитываемых для каждого поискового запроса - 10. Максимальный размер базы данных - 100 ГБ (может быть изменен в конфиге). Максимум 200 индексов. Максимум 1000 слов в одном поле. Источник
Тест
Набор данных: дамп выжимок из английской Википедии enwiki-20210720-abstract.xmlДата: 20 июля 2021 г.
Документов: 6,3 млн
Размер XML: 6,0 ГБ
Слова запроса выбираются случайным образом из 1000 самых распространенных английских слов.
Конфигурация системы
2 General Purpose / 32 ГБ / 8 vCPU инстанса DigitalOcean (один для генерации нагрузки + один для тестируемой системы).Полученные результаты
Время индексацииДля индексации мы учитывали только время, которое индексатор потратил на запросы к серверу.
Elasticsearch, PostgreSQL и Typesense показывают здесь очень похожую производительность, в то время как RediSearch примерно в 2 раза медленнее; этот результат странным образом противоречит результатам тестов RedisLabs, поэтому настройка может быть здесь неоптимальной.
В то же время, Meilisearch блещет, будучи почти в 7 раз быстрее остальных.
Тайминги запросов
Опять же, RediSearch оказался в среднем довольно медленным, и снова RedisLabs получили другие результаты. Еще один неожиданно медленный результат показал запрос из трех слов в Typesense.
Meilisearch показал довольно хорошую производительность, особенно для запросов с префиксами и опечатками.
Мы использовали нули для отображения неподдерживаемых типов запросов на графиках, но если приглядеться, видно, что RediSearch показал результат менее 1 мс (!) для запросов «точная фраза» и «три слова И».
Результаты в числах
| Тест | Elasticsearch | RediSearch | PostgreSQL | TypeSense | MeiliSearch |
| Индексирование | |||||
| - время | 268 | 516 | 290 | 272 | 42 (асинхр.) |
| - пропускная способность | 23644 | 12267 | 21827 | 23258 | 150284 |
| Запрос: 1 слово | 16,14 | 16,81 | 69,89 | 16,04 | 6,73 |
| Запрос: 3 слова | 4,07 | 0,95 | 2,61 | 224,36 | 11,57 |
| Запрос: 3 слова "ИЛИ" | 20,69 | 45,86 | 2,48 | - | - |
| Запрос: точная фраза | 3,16 | 0,64 | 9,85 | - | - |
| Запрос: 1 слово, автокомплит | 7,76 | 36,98 | 9,22 | 6,75 | 6,18 |
| Запрос с опечаткой | 19,81 | 58,17 | - | 14,61 | 5,84 |
Выводы
Elasticsearch по-прежнему остается королем поиска, он выдает стабильную производительность и для индексирования, и для всех типов запросов.RediSearch имеет посредственную производительность индексации; также RedisLabs изо всех сил стараются продать свое облачное решение, поэтому документация не на высоте. Но эта система показывает минимальную задержку (менее миллисекунды) для некоторых типов запросов.
PostgreSQL показал странную "яму" производительности для простых запросов из одного слова, и интерфейс поиска довольно сложен. Хотя, если у вас уже есть база данных Postgres, встроенный поиск может быть неплохим решением для простых случаев.
У TypeSense неплохой набор функций, и производительность в целом тоже на высоте, за исключением странного провала при запросах из нескольких слов.
Кажущаяся высокая производительность MeiliSearch была вызвана ориентацией теста только на время ответа при индексировании, но Meili больше других полагается на асинхронную обработку. Мы не смогли провести тест с ожиданием индексации каждой порции данных, т.к. в таком режиме система оказалась мучительно медленной.
Дополнение: результаты Meilisearch и Typesense
Джейсон Боско из Typesense обратился к нам по поводу странных медленных выбросов с запросами из 3 слов и рекомендовал повторно запустить этот тест с параметром drop_tokens_threshold = 1, но мы получили в этом режиме похожие результаты (200+ мс). Мы также попробовали drop_tokens_threshold = 0 (по сути, превратив запрос в "ИЛИ"), это дало более высокую производительность.То есть, по-видимому, замедление вызвано тем, что мы выбираем 3 случайных английских слова для запроса, и при отсутствии в индексе документов, содержащих все три слова Typesense начинает отбрасывать слова, пока не получает результат, и этот процесс не очень быстр.
Джейсон также отметил, что кажущаяся быстрая индексация Meilisearch на самом деле была вызвана асинхронностью запросов индексации. Мы обновили тест, чтобы он дожидался завершения индексирования каждой порции, но в таком режиме индексация занимает как-то невероятно много времени, так что, видимо, нам нужно повнимательнее изучить, как Meilisearch работает под капотом.
Дополнение для Хабра ")
Раз уж все скрипты были готовы, я в свободное время погонял те же тесты для более экзотических систем.Sonic
Ужасно медленная индексация. Не дождался окончания теста, хоть он и работал всю ночь.
Toshi
Индексация: 273 док/сек (настройки по умолчанию), 37631 док/сек с использованием недокументированного эндпоинта _bulk для пакетной работы
Запрос 1 слово: 372 з/сек, 2.68 мс
Запрос 3 слова: 357 з/сек, 2.79 мс
Запрос 3 слова с опечатками: 325 з/сек, 3.07 мс
Неплохие в целом показатели, но для индексации обязательно нужно использовать _bulk.
Quickwit
Индексация (из отдельно подготовленного файла с ndjson): 37085 док/сек
Запрос 1 слово: 324 з/сек, 3.08 мс
Запрос 3 слова: 324 з/сек, 3.08 мс ¯_(ツ)_/¯
Неплохие показатели, но для индексации нужно заранее готовить данные.
Groonga
Индексация: 77372 док/сек
Запрос 1 слово: 0.56 з/сек, 1782 мс
Запрос 3 слова: 0.50 з/сек, 1982 мс
Очень быстрая индексация, но ОЧЕНЬ медленный поиск.
Сравнение эффективности поиска: Elasticsearch и конкуренты
В области поисковых систем с открытым исходным кодом появилось несколько новых интересных игроков. Мы решили внимательно изучить некоторые из них, чтобы узнать, насколько они сравнимы с Elasticsearch...
habr.com