Все мы знаем, что С++ — мощный язык, у которого много сторонников. Но чем могут быть недовольны даже сторонники? Где сталкиваешься с неудобствами и чем они вызваны? Почему в примитивном приложении могут вылезти неожиданные сложности и чего не хватает в стандартной библиотеке? А главное, что можно сделать для улучшения ситуации?
Антон Полухин (antoshkka), состоящий в комитете по стандартизации C++ и работающий в «Яндекс.Такси», рассказал обо всём этом в докладе «C++ на практике». Сам доклад появился ещё в 2019-м, и с выходом C++20 что-то изменилось, но главные тезисы и вывод остались актуальны. Поэтому теперь, готовя новую конференцию C++ Russia 2021, мы решили сделать для Хабра пост на основе этого доклада. Под катом — и текст, и видеозапись. Далее повествование идёт от лица Антона.
Меня зовут Антон Полухин, я сотрудник компании «Яндекс.Такси». В свободное и рабочее время я занимаюсь развитием C++: разрабатываю Boost-библиотеки, провожу мастер-классы и читаю лекции о своём любимом языке программирования.
Сегодня мы поговорим о том, насколько приятно пользоваться C++ в повседневной жизни: рассмотрим два совершенно разных приложения и увидим всю боль, ужасы и приятности «плюсов».
В «Википедии» умные люди пишут, что C++ — это «компилируемый, статически типизированный язык программирования общего назначения». А это значит, что на нём можно писать практически всё, что угодно: и консольные вспомогательные утилиты, и игры, и Android-приложения, и поисковые движки! По крайней мере, так говорят. Давайте проверим.
Под Новый год знакомый скинул мне программу на Bash, которая выводила на экран ёлочку в ASCII-графике с красиво мигающими лампочками:
Насколько сложно написать то же самое на «плюсах»? У меня это заняло день. Но написание на Perl, Python или Bash отняло бы столько же времени и было бы чуть неприятнее.
Что собой представляет это мини-приложение? Ёлочка мигает, а при нажатии на клавишу меняется режим «гирлянды»: все лампочки становятся одного цвета.

Суперсерьёзная программа! Она занимает примерно 100 строчек кода, но даже тут есть некрасивости. Например, что происходит в этом блоке?
std::thread t([&lamp]() {
char c;
while (std::cin >> c) {
lamp.change_mode();
}
});
Блок отвечает за управление лампочками, но это приходится делать в отдельном потоке, так как в C++ нельзя одновременно мигать лампочками и смотреть, нажал ли пользователь клавишу. Чтение из потока — блокирующее. Как только мы дошли до std::cin >> c, лампочки перестают мигать, поток останавливается, а мы ждём, когда пользователь нажмёт клавишу.
И чтобы обойти это, приходится создавать отдельный поток и там смотреть, когда же пользователь нажмёт кнопку. А еще внутри придётся воспользоваться атомиками.
Нам всего лишь хотелось нарисовать ёлочку в терминале, а тут внезапно вылезла многопоточность! Не очень приятно.
А вот и вторая неприятность:
std::ifstream ifs{ filename.c_str() };
std::string tree;
std::getline(ifs, tree, '\0');
Есть файл с ASCII-графикой, и мы его никак не меняем — из него нужны только байты. Но в С++ нельзя работать с файлом как с массивом байт: придётся открыть поток, считать информацию из потока в контейнер (string или vector) и только тогда работать с этим контейнером.
Казалось бы, программа простая, почему же возникают такие сложности?
Круг задач, которые можно решать с помощью C++, очень широк. И за то, чтобы эти задачи можно было решать, отвечают вот эти люди:

Знакомьтесь — комитет по стандартизации языка C++. Они эксперты в своих областях: одни в машинном обучении, другие в компиляторах, третьи великолепно знают алгоритмы. Но есть маленькая проблема: все члены комитета находятся в круге задач, отвечающих за высокую производительность.
Если обозначить экспертов зелёными точками, область задач с высокой производительностью — чёрным кругом, а область всех задач, которые можно решать на C++ — жёлтым, ситуация выглядит так:

Так сложилось исторически.
Например, есть стартап, где мало денег и где код пишут как придётся. Со временем стартап ширится, развивается и через 20 лет вырастает в огромный монолит и конгломерат. И тогда компания задумывается о том, что хорошо бы влиять на тот язык программирования, на котором у них всё написано. Поэтому нужен человек, который хорошо разбирается в языке и преследует интересы компании — его-то и отправляют в комитет по стандартизации C++.
Так уж получается, что самые хардкорные C++ программисты занимаются самыми суровыми вещами — они редко читают вывод с клавиатуры или из файлика, а занимаются только тем местом, которое критично для всего приложения. Если программа на C++, значит, нужна высокая производительность. Поэтому человек из комитета и отвечает за высокую производительность.
Около двадцати лет назад в комитете было 20 человек, а теперь уже ближе к двумстам. И по-прежнему это люди, которые решают задачи, связанные с высокой производительностью.
А наша задача с ёлочкой помечена на картинке звёздочкой, и очень далека от целей комитета.

На примере этой программы мы видим, что несмотря на шероховатости, всё работает. А какие будут проблемы в приложении, требующем высокой производительности?
В основе «Яндекс.Такси» лежит микросервисная архитектура. Если взять какой-то один сильно нагруженный сервис в отдельном дата-центре, то он будет обрабатывать где-то 20 000 сообщений в секунду. Что-то приходит в виде запроса, что-то он считывает, ищет на графе, обращается к базе и выдает ответ. Каждое такое событие нужно логировать, то есть записать информацию в файл. Один микросервис в отдельном дата-центре порождает 30 гигабайт логов в час, а в сумме все микросервисы генерируют в час больше терабайта логов и миллиарда событий.
Терабайты данных собираются со всех машин и отправляются в удалённое хранилище, где удаляются. Но перед удалением на них смотрят разработчики и менеджеры: находят интересные стратегии улучшения, какие-то несоответствия и то, на чём можно строить дальнейший бизнес.
Раньше для отправки таких сообщений мы использовали Logstash — популярное, бесплатное и открытое приложение, написанное на Java, которым пользуется огромное количество компаний.
Казалось бы, что может пойти не так?
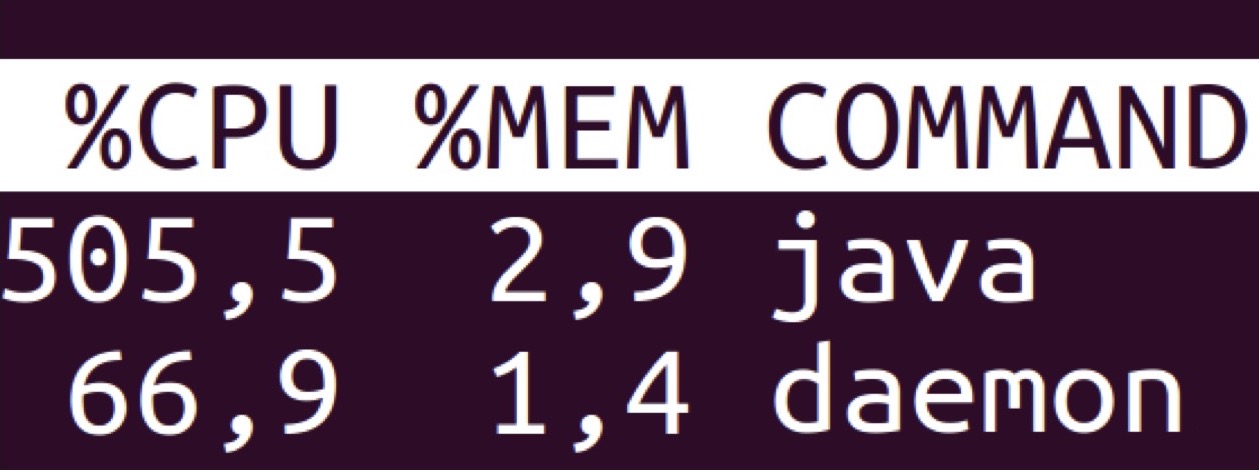
Демон — это то, что принимает запрос, обрабатывает его, обращается к удалённому хранилищу, получает ответ, что-то считает на графе, производит криптографические операции, пишет лог и отдаёт ответ. А Java — это Logstash, который просто отправляет этот лог в удалённое хранилище. При этом потребляет Logstash в два раза больше оперативной памяти и в девять раз больше ресурсов процессора.
Что тут происходит под капотом? Logstash делает следующее:
Вооружимся perf и натравим его на Java. Что мы видим? Logstash постоянно что-то сует в какие-то конкурентные ассоциативные контейнеры, в которых тратится огромное количество времени.
Для чего здесь вообще эти контейнеры? У нас ведь обычный пайплайн и простые правила по преобразованию логов, где по ключу и значению можно сразу понять, что там произошло и как это трансформировать. Нет никаких сложных правил, например, по разной обработке в зависимости от того, встретился ли до этого один ключ или другой.
Давайте сделаем свой Logstash без излишеств — шустрый, модный и современный. Для этого воспользуемся всеми доступными фишками C++17.
Представляю вашему вниманию «Пилораму». Почему такое название? Говоря по-английски, пилорама — это «factory in which logs are sawed». То есть что-то, что «пилит логи»! Вот и наша «Пилорама» пилит их и отправляет куда-то дальше.
Учтём ошибки Logstash и вместо трёх стадий с обменом контейнерами между ними (разделение на ключ—значение, применение правил, формирование записи) сделаем одну. Есть кусок данных, мы знаем, как преобразовать его в конечный формат, и никаких сложных промежуточных шагов не нужно.
Как мы это делаем? Данные приходят в виде std::string_view, то есть в виде указателя на кусок данных, над которыми нужно работать, и size_t — количества этих данных. Со string_view мы делаем следующее:
do {
const std::string key = GetKey();
if (state_ == State::kIncompleteRecord) {
// Stop parsing to let the producer write more data and finish the record.
return 0;
}
const utils::string_view value = GetValue();
if (state_ == State::kIncompleteRecord) {
return 0;
}
WriteWithFilters(writer, key, value);
} while (state_ == State::kParsing);
Берём ключ, проверяем, нормальный ли он. Затем достаём значение и проверяем, пришло ли оно целиком. Записываем всё в выходной формат, применяя какие-то правила. Повторяем до тех пор, пока есть что разбирать.
Но для чего тут нужны две проверки?
«Пилорама» и основной демон работают в разных процессах. Основной демон может захотеть записать четыре с лишним килобайта логов, но успеет записать всего два, когда вклинится «Пилорама» и начнёт эти логи читать. В какой-то момент она заметит, что запись не готова целиком. Для таких случаев и нужны проверки.
С этой функцией конвертации получается более 360 тысяч записей в секунду, а это более 75 мегабайт данных в секунду. Итого больше 270 гигабайт логов в час. Таким образом можно держать 10 самых загруженных микросервисов на одном ядре «Пилорамы» или вообще все логи «Яндекс.Такси» на четырёх ядрах.
Честно говоря, когда я только написал этот конвертер и впервые запустил его, то был недоволен результатом: всего в 30 раз быстрее Java. Но потом я выспался и понял, что собирал всё в режиме отладки. Поэтому сейчас мы примерно в 100 раз быстрее Java, что более-менее приемлемо, но все равно недостаточно.
Почему так медленно? Вот вам немного нашей боли. В приложении есть конвертация данных и преобразование времён, а в C++17 для этого ничего нет. Поэтому приходится пользоваться сторонними библиотеками, например cctz. А эта «редиска» в цикле динамически аллоцирует память.
// Formats a std::tm using strftime(3).
void FormatTM(std::string* out, const std::string& fmt, const std::tm& tm)
{
for (int = 2; i !=32; i*=2) {
size_t buf_size = fmt.size() * i;
std::vector<char> buf(buf_size);
if (size_t len = strftime(&buf[0], buf_size, fmt.c_str(), &tm)) {
out->append(&buf[0], len);
return;
}
}
}
Если это безобразие убрать и заменить на работу с датой/временем из C++20, то скорость конвертации увеличится практически в два раза.
Теперь попробуем считать данные с диска. Стандартный подход в C++ — использовать стримы. Есть файл, с которым нужно что-то сделать. Мы открываем ifstream и даём ему команду читать из конкретного файла в определённый контейнер. Тот, в свою очередь, говорит операционной системе отдать какой-то файл. ОС не умеет работать напрямую с диском и записывать байты прямо с него в пользовательские буферы. Сначала ОС подтягивает большой кусок файла в оперативную память и уже оттуда копирует байты в нужный контейнер.
Такой способ работы с файлами — стандартный, но большинство современных ОС могут работать лучше. Операционная система сразу даст доступ к этому фрагменту памяти и работать с ним можно будет без всякого копирования.
Именно это делает boost::interprocess::mapped_region. Вы называете файл, с которым будете работать, оффсет и примерный требуемый размер. И boost::interprocess::mapped_region возвращает указатель на начало этих данных и размер, что отлично сочетается со string_view. Мы получаем указатель и размер, создаем от них string_view и отправляем на конвертацию. В итоге без всяких динамических аллокаций и промежуточных контейнеров получаем пайплайн, начиная с чтения файла до получения итогового формата. Осталось самое сложное — отправить данные в удалённое хранилище. Выглядит это так:
std::string result;
do {
AppendNewData(result);
if (result.size() < treshold) {
engine::SleepFor(1s);
continue;
}
SendToRemote(result);
result.clear();
} while (true);
Здесь есть какой-то result и функция, которая читает данные с диска, конвертирует и добавляет их в result. Затем мы проверяем, что данных для отправки достаточно, и если их недостаточно, то засыпаем на секунду, а если достаточно, то отправляем их в удаленное хранилище.
Вы можете спросить: «Sleep в коде? Это точно высокопроизводительный сервис?» Если есть 100 файлов, значит, нужно 100 потоков, и все эти потоки иногда спят. Изредка им нужно резко пробудиться, что-то сделать и снова уснуть. ОС будет переключаться между этими потоками и пытаться угадать, какие и когда нужно разбудить. Если файлов 10 тысяч, то и потоков будет 10 тысяч, и тогда все станет ещё хуже: оперативная память будет съедаться, а операционная система — зашиваться. Выглядит не очень производительно.
Но устроено здесь всё хитро и функции engine::SleepFor() и SendToRemote()на самом деле асинхронные методы из нашего асинхронного фреймворка userver. Перепишем их с использованием Coroutines TS, и тогда к методам добавится co_await. В результате получим co_await engine::SleepFor() и co_await SendToRemote(result).
При вызове SleepFor происходит следующее. Есть поток, где выполняется этот код. Вызывается SleepFor, с потока снимается вся задача, весь стек откладывается в сторону. И в операционную систему передается обратный вызов, говорящий, что через секунду его можно перенести в очередь готовых задач. С потока сняли задачу, и он берет новую задачу из пула готовых. Таким образом, на одном потоке мы можем держать сотни и тысячи файлов, а код при этом будет выглядеть синхронным и линейным.
От пользователя полностью скрыто, что происходит под капотом. Можно просить программистов писать код максимально просто, а под капотом будет эффективная работа, о которой он даже не задумывался.
Аналогичным способом данные отправляются в удаленное хранилище, через асинхронный метод co_await SendToRemote().
Отправлять их по сетке может быть очень долго, поэтому мы говорим операционной системе: «Отправь эти сто тысяч мегабайт данных туда-то, а когда сделаешь это, вызови вот эту функцию». Тогда текущая задача снимается с выполнения, откладывается в сторону, а вызываемая функция помечает эту задачу как готовую к выполнению и переносит ее в очередь готовых к выполнению задач. Поток остался без задачи, и поэтому подхватывает ту, что готова к выполнению. И выполняет другую задачу.
Некоторые вещи, которые хотелось бы использовать для этой задачи, появятся в C++20. Например, появятся таймзоны, тогда можно будет выкинуть cctz. Появится в С++23 flat_map — это как std::map, но намного эффективнее для небольших наборов данных. Там, где всего 10-20 элементов и количество данных расти не будет, отлично впишется flat_map. А еще в С++20 появится замечательная вещь — тип char8_t.
Казалось бы, две одинаковые функции, но вся разница в том, что в одном случае у нас unsigned char*, а в другом char8_t*:
void do_something(unsigned char* data, int& result)
{
result += data[0] - u8’0’;
result += data[1] - u8’0’;
}
void do_something(char8_t* data, int& result)
{
result += data[0] - u8’0’;
result += data[1] - u8’0’;
}
Более того, размеры у них одинаковые и кажется, что компилятор должен превратить обе функции в идентичный ассемблерный код. Но нет:
Функция, принимающая char8_t* на треть короче. Почему?
Когда вы работаете с unsigned char*, char* или byte*, компилятор думает, что char* может указывать на все, что угодно: на integer, string или пользовательскую структуру. И когда компилятор видит, что на вход передается char* и что-то извне посылки, то думает, что любая модификация этой переменной может поменять те данные, на которые указывает char*. Это работает и в обратную сторону. Поэтому компилятор генерирует такой код, который лишний раз выгружает это из регистра в оперативную память (ну, если быть полностью корректным, в кеш процессора) и из неё подтягивает в регистр. В результате мы имеем лишние инструкции. В char8_t* можно такое убрать.
Но и в C++20 будет не всё. В С++ по-прежнему не хватает memory map: он нужен и для простых приложений, вроде нашей «Ёлочки», и для высоконагруженных. Предложение по mmap есть в комитете по стандартизации, и оно может быть принято в C++23.
Не хватает стандартной библиотеки побольше. У нас удалённое хранилище, но оно не неоптимальное: написано на Java и работает с JSON. А в С++, к сожалению, из коробки нет возможности работать с JSON. Также хочется Protobuf.
Ну и не хватает правильной работы с вводом/выводом. Есть networking TS, где под капотом используется библиотека Asio, и возможно, её добавят в C++23. Есть Boost.Beast, который работает с HTTP асинхронно — им сложно пользоваться, но код в итоге получается красивым. И есть библиотека AFIO, которая позволяет асинхронно работать с файловой системой и может сказать ОС: «Когда в этой директории появится новый файлик, вызови эту функцию». А там просыпается какая-то корутина и начинает делать с файликом что-то полезное. К несчастью, AFIO — это прототип, работающий, но не быстро.
Мы рассмотрели два приложения, в каждом из которых есть шероховатости. В случае второго приложения большинство этих недочетов исправят в C++20, но «осадочек остался». Ведь, наверное, с подобными проблемами встречаюсь в разработке не только я. И скорее всего, у разных людей «шероховатости» разные. Что в связи с этим делать?
В комитете по стандартизации хотелось бы видеть больше людей. Причём из разных областей, не обязательно из области высокой производительности. Нужны люди из стартапов, которые будут говорить, где им становится неудобно в начале работы над приложением. Нужны люди из академического мира. В комитете есть преподающие профессора, которые могут рассказать, где студенты стреляют себе в ноги. И с задних рядов слышен голос: «Да-да, я эксперт, и я тоже себе в этом месте ногу отстрелил».
Также требуются люди из тех областей, где C++ не популярен или вообще не используется. Хорошо, если в комитете будет сидеть матерый разработчик embedded-железок, слушать о том, как механизм исключений уместили в 200 байт, и говорить: «А у нас всего 128 байт (нет, не килобайт), думайте дальше».
Если вам что-то не нравится в C++ и вы хотите это улучшить или донести свою боль до комитета по стандартизации, начните с сайта stdcpp.ru. Там люди обмениваются мыслями, желаниями и проблемами, связанными с развитием языка C++. Идеи обсуждаются, обрабатываются и некоторые из них становятся официальными предложениями для международного комитета. При этом рук не хватает, поэтому особенно ценная помощь — когда человек готов не только генерировать идеи, но и браться за написание предложений к ним (хотя бы черновиков).
Драматичным шёпотом: и таким человеком может стать каждый из вас!
Источник статьи: https://habr.com/ru/company/jugru/blog/563988/
Антон Полухин (antoshkka), состоящий в комитете по стандартизации C++ и работающий в «Яндекс.Такси», рассказал обо всём этом в докладе «C++ на практике». Сам доклад появился ещё в 2019-м, и с выходом C++20 что-то изменилось, но главные тезисы и вывод остались актуальны. Поэтому теперь, готовя новую конференцию C++ Russia 2021, мы решили сделать для Хабра пост на основе этого доклада. Под катом — и текст, и видеозапись. Далее повествование идёт от лица Антона.
Вступление
Меня зовут Антон Полухин, я сотрудник компании «Яндекс.Такси». В свободное и рабочее время я занимаюсь развитием C++: разрабатываю Boost-библиотеки, провожу мастер-классы и читаю лекции о своём любимом языке программирования.
Сегодня мы поговорим о том, насколько приятно пользоваться C++ в повседневной жизни: рассмотрим два совершенно разных приложения и увидим всю боль, ужасы и приятности «плюсов».
В «Википедии» умные люди пишут, что C++ — это «компилируемый, статически типизированный язык программирования общего назначения». А это значит, что на нём можно писать практически всё, что угодно: и консольные вспомогательные утилиты, и игры, и Android-приложения, и поисковые движки! По крайней мере, так говорят. Давайте проверим.
Пример «Ёлочка»
Под Новый год знакомый скинул мне программу на Bash, которая выводила на экран ёлочку в ASCII-графике с красиво мигающими лампочками:
Насколько сложно написать то же самое на «плюсах»? У меня это заняло день. Но написание на Perl, Python или Bash отняло бы столько же времени и было бы чуть неприятнее.
Что собой представляет это мини-приложение? Ёлочка мигает, а при нажатии на клавишу меняется режим «гирлянды»: все лампочки становятся одного цвета.
Суперсерьёзная программа! Она занимает примерно 100 строчек кода, но даже тут есть некрасивости. Например, что происходит в этом блоке?
std::thread t([&lamp]() {
char c;
while (std::cin >> c) {
lamp.change_mode();
}
});
Блок отвечает за управление лампочками, но это приходится делать в отдельном потоке, так как в C++ нельзя одновременно мигать лампочками и смотреть, нажал ли пользователь клавишу. Чтение из потока — блокирующее. Как только мы дошли до std::cin >> c, лампочки перестают мигать, поток останавливается, а мы ждём, когда пользователь нажмёт клавишу.
И чтобы обойти это, приходится создавать отдельный поток и там смотреть, когда же пользователь нажмёт кнопку. А еще внутри придётся воспользоваться атомиками.
Нам всего лишь хотелось нарисовать ёлочку в терминале, а тут внезапно вылезла многопоточность! Не очень приятно.
А вот и вторая неприятность:
std::ifstream ifs{ filename.c_str() };
std::string tree;
std::getline(ifs, tree, '\0');
Есть файл с ASCII-графикой, и мы его никак не меняем — из него нужны только байты. Но в С++ нельзя работать с файлом как с массивом байт: придётся открыть поток, считать информацию из потока в контейнер (string или vector) и только тогда работать с этим контейнером.
Почему всё так криво?
Казалось бы, программа простая, почему же возникают такие сложности?
Круг задач, которые можно решать с помощью C++, очень широк. И за то, чтобы эти задачи можно было решать, отвечают вот эти люди:
Знакомьтесь — комитет по стандартизации языка C++. Они эксперты в своих областях: одни в машинном обучении, другие в компиляторах, третьи великолепно знают алгоритмы. Но есть маленькая проблема: все члены комитета находятся в круге задач, отвечающих за высокую производительность.
Если обозначить экспертов зелёными точками, область задач с высокой производительностью — чёрным кругом, а область всех задач, которые можно решать на C++ — жёлтым, ситуация выглядит так:
Так сложилось исторически.
Например, есть стартап, где мало денег и где код пишут как придётся. Со временем стартап ширится, развивается и через 20 лет вырастает в огромный монолит и конгломерат. И тогда компания задумывается о том, что хорошо бы влиять на тот язык программирования, на котором у них всё написано. Поэтому нужен человек, который хорошо разбирается в языке и преследует интересы компании — его-то и отправляют в комитет по стандартизации C++.
Так уж получается, что самые хардкорные C++ программисты занимаются самыми суровыми вещами — они редко читают вывод с клавиатуры или из файлика, а занимаются только тем местом, которое критично для всего приложения. Если программа на C++, значит, нужна высокая производительность. Поэтому человек из комитета и отвечает за высокую производительность.
Около двадцати лет назад в комитете было 20 человек, а теперь уже ближе к двумстам. И по-прежнему это люди, которые решают задачи, связанные с высокой производительностью.
А наша задача с ёлочкой помечена на картинке звёздочкой, и очень далека от целей комитета.
На примере этой программы мы видим, что несмотря на шероховатости, всё работает. А какие будут проблемы в приложении, требующем высокой производительности?
«Ява не тормозит»
В основе «Яндекс.Такси» лежит микросервисная архитектура. Если взять какой-то один сильно нагруженный сервис в отдельном дата-центре, то он будет обрабатывать где-то 20 000 сообщений в секунду. Что-то приходит в виде запроса, что-то он считывает, ищет на графе, обращается к базе и выдает ответ. Каждое такое событие нужно логировать, то есть записать информацию в файл. Один микросервис в отдельном дата-центре порождает 30 гигабайт логов в час, а в сумме все микросервисы генерируют в час больше терабайта логов и миллиарда событий.
Терабайты данных собираются со всех машин и отправляются в удалённое хранилище, где удаляются. Но перед удалением на них смотрят разработчики и менеджеры: находят интересные стратегии улучшения, какие-то несоответствия и то, на чём можно строить дальнейший бизнес.
Раньше для отправки таких сообщений мы использовали Logstash — популярное, бесплатное и открытое приложение, написанное на Java, которым пользуется огромное количество компаний.
Казалось бы, что может пойти не так?
Демон — это то, что принимает запрос, обрабатывает его, обращается к удалённому хранилищу, получает ответ, что-то считает на графе, производит криптографические операции, пишет лог и отдаёт ответ. А Java — это Logstash, который просто отправляет этот лог в удалённое хранилище. При этом потребляет Logstash в два раза больше оперативной памяти и в девять раз больше ресурсов процессора.
Что тут происходит под капотом? Logstash делает следующее:
- Считывает данные с диска.
- Разбивает запись на ключ—значение.
- Применяет простые правила трансформации ключей и значений (например, меняет формат времени).
- Формирует запись в конечном формате.
- Отправляет запись в удалённое хранилище.
Вооружимся perf и натравим его на Java. Что мы видим? Logstash постоянно что-то сует в какие-то конкурентные ассоциативные контейнеры, в которых тратится огромное количество времени.
Для чего здесь вообще эти контейнеры? У нас ведь обычный пайплайн и простые правила по преобразованию логов, где по ключу и значению можно сразу понять, что там произошло и как это трансформировать. Нет никаких сложных правил, например, по разной обработке в зависимости от того, встретился ли до этого один ключ или другой.
Давайте сделаем свой Logstash без излишеств — шустрый, модный и современный. Для этого воспользуемся всеми доступными фишками C++17.
«Пилорама»
Представляю вашему вниманию «Пилораму». Почему такое название? Говоря по-английски, пилорама — это «factory in which logs are sawed». То есть что-то, что «пилит логи»! Вот и наша «Пилорама» пилит их и отправляет куда-то дальше.
Учтём ошибки Logstash и вместо трёх стадий с обменом контейнерами между ними (разделение на ключ—значение, применение правил, формирование записи) сделаем одну. Есть кусок данных, мы знаем, как преобразовать его в конечный формат, и никаких сложных промежуточных шагов не нужно.
Как мы это делаем? Данные приходят в виде std::string_view, то есть в виде указателя на кусок данных, над которыми нужно работать, и size_t — количества этих данных. Со string_view мы делаем следующее:
do {
const std::string key = GetKey();
if (state_ == State::kIncompleteRecord) {
// Stop parsing to let the producer write more data and finish the record.
return 0;
}
const utils::string_view value = GetValue();
if (state_ == State::kIncompleteRecord) {
return 0;
}
WriteWithFilters(writer, key, value);
} while (state_ == State::kParsing);
Берём ключ, проверяем, нормальный ли он. Затем достаём значение и проверяем, пришло ли оно целиком. Записываем всё в выходной формат, применяя какие-то правила. Повторяем до тех пор, пока есть что разбирать.
Но для чего тут нужны две проверки?
«Пилорама» и основной демон работают в разных процессах. Основной демон может захотеть записать четыре с лишним килобайта логов, но успеет записать всего два, когда вклинится «Пилорама» и начнёт эти логи читать. В какой-то момент она заметит, что запись не готова целиком. Для таких случаев и нужны проверки.
С этой функцией конвертации получается более 360 тысяч записей в секунду, а это более 75 мегабайт данных в секунду. Итого больше 270 гигабайт логов в час. Таким образом можно держать 10 самых загруженных микросервисов на одном ядре «Пилорамы» или вообще все логи «Яндекс.Такси» на четырёх ядрах.
Честно говоря, когда я только написал этот конвертер и впервые запустил его, то был недоволен результатом: всего в 30 раз быстрее Java. Но потом я выспался и понял, что собирал всё в режиме отладки. Поэтому сейчас мы примерно в 100 раз быстрее Java, что более-менее приемлемо, но все равно недостаточно.
Почему так медленно? Вот вам немного нашей боли. В приложении есть конвертация данных и преобразование времён, а в C++17 для этого ничего нет. Поэтому приходится пользоваться сторонними библиотеками, например cctz. А эта «редиска» в цикле динамически аллоцирует память.
// Formats a std::tm using strftime(3).
void FormatTM(std::string* out, const std::string& fmt, const std::tm& tm)
{
for (int = 2; i !=32; i*=2) {
size_t buf_size = fmt.size() * i;
std::vector<char> buf(buf_size);
if (size_t len = strftime(&buf[0], buf_size, fmt.c_str(), &tm)) {
out->append(&buf[0], len);
return;
}
}
}
Если это безобразие убрать и заменить на работу с датой/временем из C++20, то скорость конвертации увеличится практически в два раза.
С++ на практике
Теперь попробуем считать данные с диска. Стандартный подход в C++ — использовать стримы. Есть файл, с которым нужно что-то сделать. Мы открываем ifstream и даём ему команду читать из конкретного файла в определённый контейнер. Тот, в свою очередь, говорит операционной системе отдать какой-то файл. ОС не умеет работать напрямую с диском и записывать байты прямо с него в пользовательские буферы. Сначала ОС подтягивает большой кусок файла в оперативную память и уже оттуда копирует байты в нужный контейнер.
Такой способ работы с файлами — стандартный, но большинство современных ОС могут работать лучше. Операционная система сразу даст доступ к этому фрагменту памяти и работать с ним можно будет без всякого копирования.
Именно это делает boost::interprocess::mapped_region. Вы называете файл, с которым будете работать, оффсет и примерный требуемый размер. И boost::interprocess::mapped_region возвращает указатель на начало этих данных и размер, что отлично сочетается со string_view. Мы получаем указатель и размер, создаем от них string_view и отправляем на конвертацию. В итоге без всяких динамических аллокаций и промежуточных контейнеров получаем пайплайн, начиная с чтения файла до получения итогового формата. Осталось самое сложное — отправить данные в удалённое хранилище. Выглядит это так:
std::string result;
do {
AppendNewData(result);
if (result.size() < treshold) {
engine::SleepFor(1s);
continue;
}
SendToRemote(result);
result.clear();
} while (true);
Здесь есть какой-то result и функция, которая читает данные с диска, конвертирует и добавляет их в result. Затем мы проверяем, что данных для отправки достаточно, и если их недостаточно, то засыпаем на секунду, а если достаточно, то отправляем их в удаленное хранилище.
Вы можете спросить: «Sleep в коде? Это точно высокопроизводительный сервис?» Если есть 100 файлов, значит, нужно 100 потоков, и все эти потоки иногда спят. Изредка им нужно резко пробудиться, что-то сделать и снова уснуть. ОС будет переключаться между этими потоками и пытаться угадать, какие и когда нужно разбудить. Если файлов 10 тысяч, то и потоков будет 10 тысяч, и тогда все станет ещё хуже: оперативная память будет съедаться, а операционная система — зашиваться. Выглядит не очень производительно.
Но устроено здесь всё хитро и функции engine::SleepFor() и SendToRemote()на самом деле асинхронные методы из нашего асинхронного фреймворка userver. Перепишем их с использованием Coroutines TS, и тогда к методам добавится co_await. В результате получим co_await engine::SleepFor() и co_await SendToRemote(result).
При вызове SleepFor происходит следующее. Есть поток, где выполняется этот код. Вызывается SleepFor, с потока снимается вся задача, весь стек откладывается в сторону. И в операционную систему передается обратный вызов, говорящий, что через секунду его можно перенести в очередь готовых задач. С потока сняли задачу, и он берет новую задачу из пула готовых. Таким образом, на одном потоке мы можем держать сотни и тысячи файлов, а код при этом будет выглядеть синхронным и линейным.
От пользователя полностью скрыто, что происходит под капотом. Можно просить программистов писать код максимально просто, а под капотом будет эффективная работа, о которой он даже не задумывался.
Аналогичным способом данные отправляются в удаленное хранилище, через асинхронный метод co_await SendToRemote().
Отправлять их по сетке может быть очень долго, поэтому мы говорим операционной системе: «Отправь эти сто тысяч мегабайт данных туда-то, а когда сделаешь это, вызови вот эту функцию». Тогда текущая задача снимается с выполнения, откладывается в сторону, а вызываемая функция помечает эту задачу как готовую к выполнению и переносит ее в очередь готовых к выполнению задач. Поток остался без задачи, и поэтому подхватывает ту, что готова к выполнению. И выполняет другую задачу.
Чего не хватает в C++
Некоторые вещи, которые хотелось бы использовать для этой задачи, появятся в C++20. Например, появятся таймзоны, тогда можно будет выкинуть cctz. Появится в С++23 flat_map — это как std::map, но намного эффективнее для небольших наборов данных. Там, где всего 10-20 элементов и количество данных расти не будет, отлично впишется flat_map. А еще в С++20 появится замечательная вещь — тип char8_t.
Казалось бы, две одинаковые функции, но вся разница в том, что в одном случае у нас unsigned char*, а в другом char8_t*:
void do_something(unsigned char* data, int& result)
{
result += data[0] - u8’0’;
result += data[1] - u8’0’;
}
void do_something(char8_t* data, int& result)
{
result += data[0] - u8’0’;
result += data[1] - u8’0’;
}
Более того, размеры у них одинаковые и кажется, что компилятор должен превратить обе функции в идентичный ассемблерный код. Но нет:
Функция, принимающая char8_t* на треть короче. Почему?
Когда вы работаете с unsigned char*, char* или byte*, компилятор думает, что char* может указывать на все, что угодно: на integer, string или пользовательскую структуру. И когда компилятор видит, что на вход передается char* и что-то извне посылки, то думает, что любая модификация этой переменной может поменять те данные, на которые указывает char*. Это работает и в обратную сторону. Поэтому компилятор генерирует такой код, который лишний раз выгружает это из регистра в оперативную память (ну, если быть полностью корректным, в кеш процессора) и из неё подтягивает в регистр. В результате мы имеем лишние инструкции. В char8_t* можно такое убрать.
Но и в C++20 будет не всё. В С++ по-прежнему не хватает memory map: он нужен и для простых приложений, вроде нашей «Ёлочки», и для высоконагруженных. Предложение по mmap есть в комитете по стандартизации, и оно может быть принято в C++23.
Не хватает стандартной библиотеки побольше. У нас удалённое хранилище, но оно не неоптимальное: написано на Java и работает с JSON. А в С++, к сожалению, из коробки нет возможности работать с JSON. Также хочется Protobuf.
Ну и не хватает правильной работы с вводом/выводом. Есть networking TS, где под капотом используется библиотека Asio, и возможно, её добавят в C++23. Есть Boost.Beast, который работает с HTTP асинхронно — им сложно пользоваться, но код в итоге получается красивым. И есть библиотека AFIO, которая позволяет асинхронно работать с файловой системой и может сказать ОС: «Когда в этой директории появится новый файлик, вызови эту функцию». А там просыпается какая-то корутина и начинает делать с файликом что-то полезное. К несчастью, AFIO — это прототип, работающий, но не быстро.
Что можете сделать лично вы?
Мы рассмотрели два приложения, в каждом из которых есть шероховатости. В случае второго приложения большинство этих недочетов исправят в C++20, но «осадочек остался». Ведь, наверное, с подобными проблемами встречаюсь в разработке не только я. И скорее всего, у разных людей «шероховатости» разные. Что в связи с этим делать?
В комитете по стандартизации хотелось бы видеть больше людей. Причём из разных областей, не обязательно из области высокой производительности. Нужны люди из стартапов, которые будут говорить, где им становится неудобно в начале работы над приложением. Нужны люди из академического мира. В комитете есть преподающие профессора, которые могут рассказать, где студенты стреляют себе в ноги. И с задних рядов слышен голос: «Да-да, я эксперт, и я тоже себе в этом месте ногу отстрелил».
Также требуются люди из тех областей, где C++ не популярен или вообще не используется. Хорошо, если в комитете будет сидеть матерый разработчик embedded-железок, слушать о том, как механизм исключений уместили в 200 байт, и говорить: «А у нас всего 128 байт (нет, не килобайт), думайте дальше».
Если вам что-то не нравится в C++ и вы хотите это улучшить или донести свою боль до комитета по стандартизации, начните с сайта stdcpp.ru. Там люди обмениваются мыслями, желаниями и проблемами, связанными с развитием языка C++. Идеи обсуждаются, обрабатываются и некоторые из них становятся официальными предложениями для международного комитета. При этом рук не хватает, поэтому особенно ценная помощь — когда человек готов не только генерировать идеи, но и браться за написание предложений к ним (хотя бы черновиков).
Драматичным шёпотом: и таким человеком может стать каждый из вас!
Источник статьи: https://habr.com/ru/company/jugru/blog/563988/