Как-то раз у нас перестал работать один сервис. Никто давно его не трогал, никто не помнил, кто его написал. Работает - и ладно. Генерировал CSV отчеты для бизнеса в Sidekiq воркере (асинхронно). Проблема стала очевидной то ли от того, что девопсы переехали на Kubernetes, то ли от того, что бизнес просто раньше никогда не генерировал таких больших отчетов. В этот раз сервис должен был «прожевать» 38_000 заявок, но зависал в 'in_progress'. Возможно, спустя какое-то время процесс просто убивался кубером, возможно, юзеры сами, не дожидаясь результата, отменяли экспорт и запускали по новой.
Спойлером скажу, что проблема оказалась до смешного мелкой. Но мне показалось интересным поделиться, как я нашел решение.
performance_evaluation.rb
# frozen_string_literal: true
require 'benchmark'
class PerformanceEvaluation
def self.call(applications_ids, export_id)
puts "Start"
time = Benchmark.realtime do
ApplicationsManagement::Export.new(applications_ids, export_id).call
end
puts "Finish in #{time.round(2)}"
end
end
И затем дернем его из консоли:
require './profilers/performance_evaluation'
applications_ids = Application.where(id: (1..100)).pluck") id)
id)
export_id = FactoryBot.createexport).id
PerformanceEvaluation.call(applications_ids, export_id)
...
Finish in 40.13
=> nil
Сотню заявок наш сервис обсчитывал около 40 секунд. А это значит, на наши 38_000 записей ему потребовалось бы больше 4 часов! Естественно, цифры выглядели просто неприемлемыми.
time_profiler.rb
# frozen_string_literal: true
require 'ruby-prof'
class TimeProfiler
def run(applications_ids, export_id)
RubyProf.measure_mode = RubyProf::WALL_TIME
result = RubyProf.profile do
ApplicationsManagement::Export.new(applications_ids, export_id).call
end
printer = RubyProf::CallTreePrinter.new(result)
printer.print(path: 'profilers/ruby_prof_reports', profile: 'callgrind')
end
end
Как видно выше, отчеты этот профайлер будет складывать в папку 'profilers/ruby_prof_reports/'. Запускаем его также из консоли:
require_relative 'profilers/time_profiler'
applications_ids = Application.pluckid).last(100)
export_id = FactoryBot.createexport).id
TimeProfiler.new.run(applications_ids, export_id)
Теперь в папке с отчетами появился новый файл callgrind.callgrind.out.10176. Если появилось несколько, нам нужен тот, у которого имя покороче. Открываем его из терминала с помощью утилиты qcachegrind:
qcachegrind profilers/ruby_prof_reports/callgrind.callgrind.out.10176
И видим такое окно:
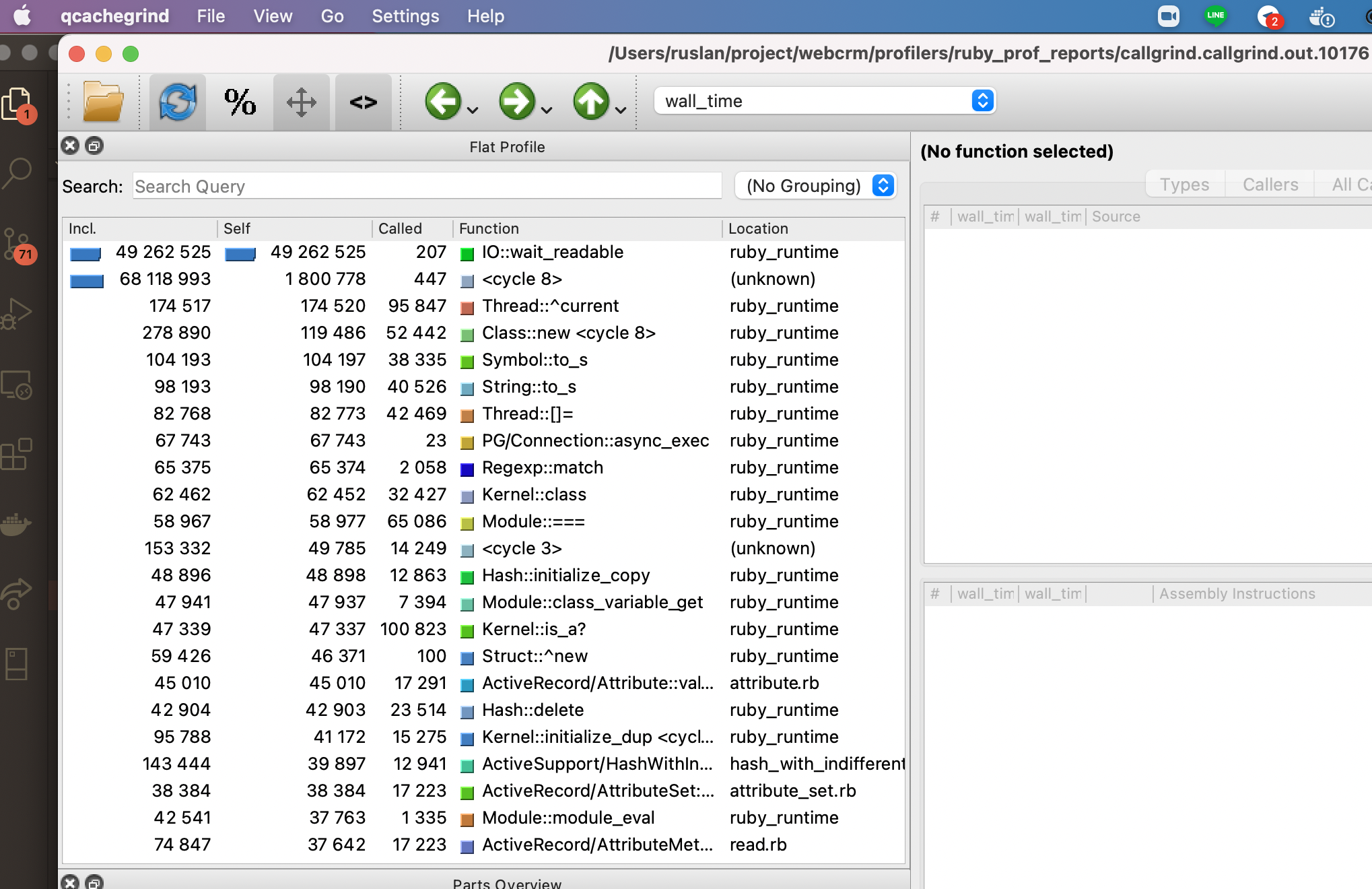
(Если у вас вид отличается, можете кликнуть Settings -> Sidebars -> Flat Profile). Здесь Я отсортировал данные по колонке self - что значит, сколько времени процесс потратил на свое выполнение. (Колонка Incl. Показывает - сколько времени он потратил на выполнение себя самого и дочерних процессов). Если кликнем по иконке % в верхнем меню, то увидим, что IO::wait_readable занимает больше 90% выполнения.
Доки Ruby не очень многословны о модуле IO::WaitReadable:
'exception to wait for reading. see IO.select.'
Но в целом, что тут еще говорить - ожидание input/output. Вопрос в том, что это ожидание вызывает?
time_profiler.rb
# frozen_string_literal: true
require 'ruby-prof'
class TimeProfiler
attr_reader :applications_ids, :file_path, :errors
def initialize(applications_ids)
@applications_ids = applications_ids
@file_path = Tempfile.new(['', '.csv']).to_path
@errors = []
end
def run
RubyProf.measure_mode = RubyProf::WALL_TIME
result = RubyProf.profile do
to_csv_export
end
printer = RubyProf::CallTreePrinter.new(result)
printer.print(path: 'profilers/ruby_prof_reports', profile: 'callgrind')
end
private
def to_csv_export
CSV.open(file_path, 'w') do |csv|
csv << export_headers # массив заголовков отчета почти на 90 элементов
# ActiveRecord::Relation с экспортируемыми заявками
export_collection.find_each do |instance|
begin
# В оригинальном сервисе здесь вызывается
# export_row(instance.decorate) -
# метод, который формировал каждую строку отчета.
# Заменим его на простую выборку атрибутов модели,
# чтобы минимизировать работу, и проверить,
# вызывается ли наш IO::WaitReadable самим процессом записи в CSV
# или вызовом тех самых методов модели для отрисовки отчета
csv << instance.attributes.values
rescue StandardError => e
errors << "#{instance.id}: #{e}"
end
end
end
end
def export_headers # rubocop:disable Metrics/MethodLength
[
'ID',
'Status',
... # Еще почти 90 заголовков
]
end
def export_collection
Application.where(id: applications_ids).includes(
... # увесистый список связанных моделей, опустим для краткости
).order(created_at: :desc)
end
end
Новый отчет callgrind вообще не содержал вызова этого модуля.

Попробуем углубиться, и «прощупать» сам метод формирования строки export_row.
time_profiler.rb
# frozen_string_literal: true
require 'ruby-prof'
class TimeProfiler
def run
RubyProf.measure_mode = RubyProf::WALL_TIME
app = Application.last
result = RubyProf.profile do
export_row(app.decorate)
end
printer = RubyProf::CallTreePrinter.new(result)
printer.print(path: 'profilers/ruby_prof_reports', profile: 'callgrind')
end
private
# Data for writing for each application
def export_row(application) # rubocop:disable Metrics/MethodLength, Metrics/AbcSize, Metrics/PerceivedComplexity, Metrics/CyclomaticComplexity, Metrics/LineLength
[
application.id,
application.status,
... # Еще около 90 строк
]
end
end
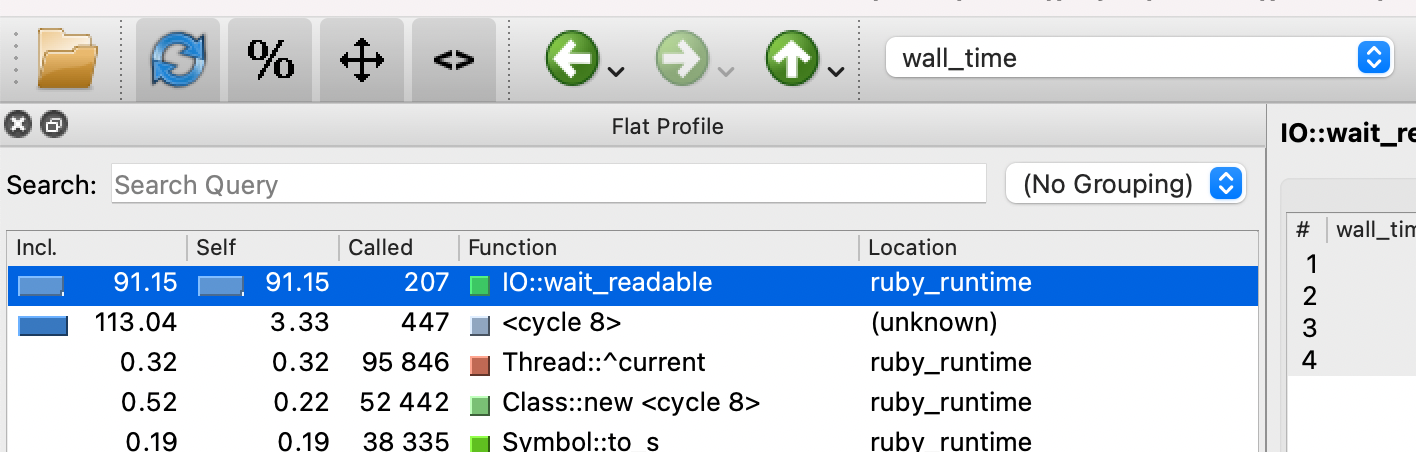
А вот и наш модуль. И опять занимает гигантские 80% времени даже при всего одной записи.
Дальше можно по принципу бинарного поиска закомментировать половину вызываемых методов, и проверить, вызывается ли «долгий» модуль или нет. Если нет - проблема в закомментированных строках. Делим их пополам опять и т.д… Довольно быстро я нашел строку, которая вызывала этот модуль:
...
application.photo_urls.present? ? 'Yes' : 'No',
...
Смотрим в модель Application, что же это за метод такой?
models/application.rb
# frozen_string_literal: true
class Application
...
def photo_urls
return if Rails.env.test?
s3 = Aws::S3::Resource.new
bucket = s3.bucket('bucket-name')
return [] if guid.nil?
bucket.objects(prefix: "documents/#{guid}")
.reject { |x| x.key.include?('/preview/') }
.map { |o| o.presigned_urlget) }
end
end
Иными словами, чтобы написать в отчете 'yes' или 'no' мы лезли в AWS, и смотрели, есть ли у нас в определенной папочке какие-нибудь фотографии. Заголовок этого столбца в отчете гласил KYC. То есть менеджеры ожидали видеть, прошел ли заявитель процедуру KYC (know-your-customer, кто работает в Fintech, наверняка знает) или еще нет. Я начал спрашивать бизнес, может, выберем другой способ этот признак определить? Например, можно сохранять этот флаг в бд при загрузке фотографий. Выяснилось, что им вообще этот столбец в отчете не нужен.
Я выпилил эту строчку и снова обратился к нашей метрике. PerformanceEvaluation показал всего лишь 3 секунды на обработке той же сотни заявок. На больших объемах разница была еще разительней. Отчет, который до этого не могли сгенерировать за 4+ часа, теперь пишется чуть дольше, чем за одну минуту. Виной всему одна строчка, которая вообще-то никому не была нужна.
Дважды кликаем по любому родителю, и дерево «растет» дальше:
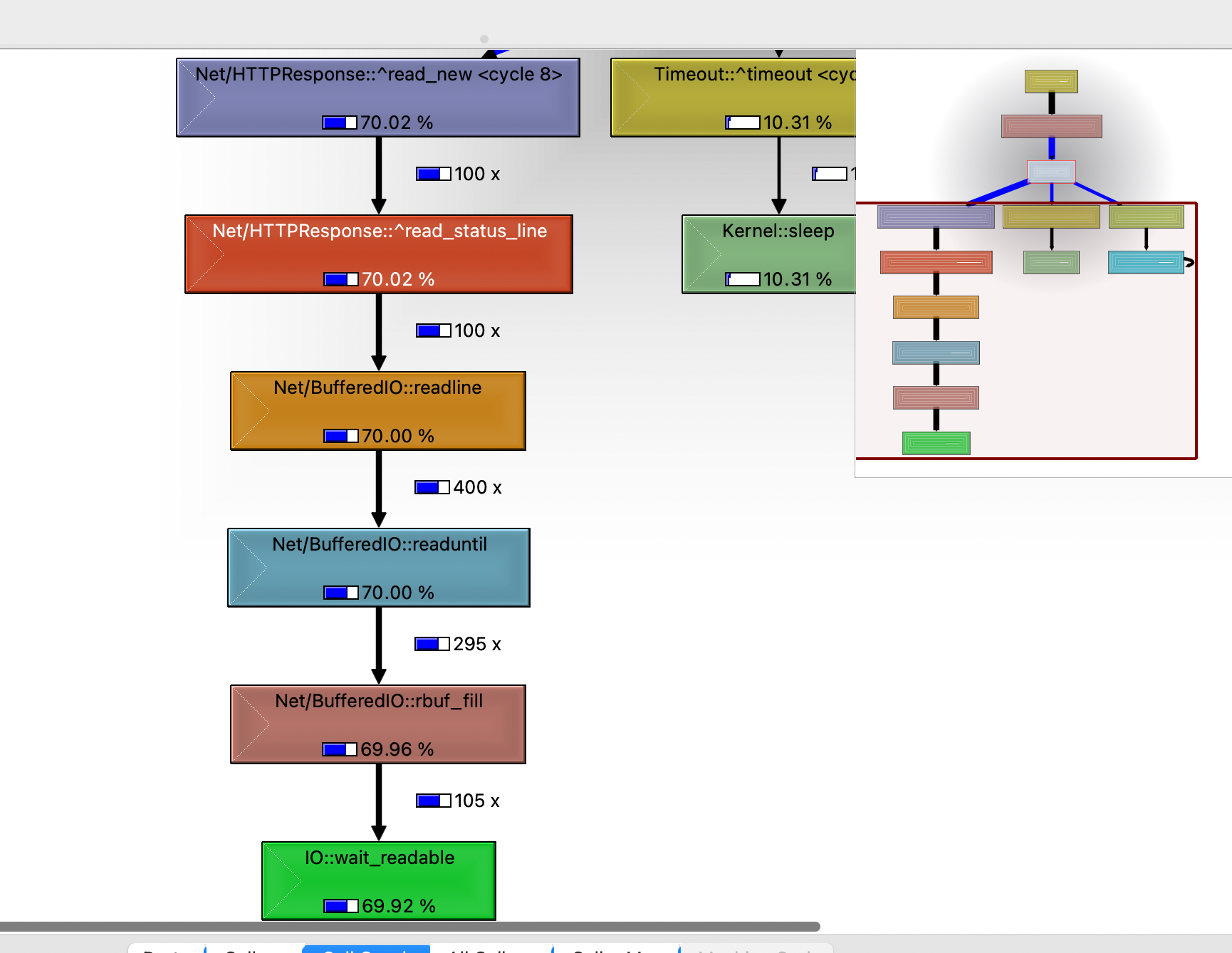
Думаю, модуль Net/HTTPResponse мог на правильную догадку подтолкнуть быстрей, и статья закончилась бы раньше. Но мне хотелось показать пример воркфлоу, который легко можно применить на любых проектах.
Источник статьи: https://habr.com/ru/post/561258/
Спойлером скажу, что проблема оказалась до смешного мелкой. Но мне показалось интересным поделиться, как я нашел решение.
Метрика
Поняв, что на малом объеме данных отчет генерируется без проблем, я решил замерить, с какой скоростью работает сервис. Для этого достаточно применить стандартный Ruby модуль Benchmark. Положим вот такой файлик в папку 'profilers':performance_evaluation.rb
# frozen_string_literal: true
require 'benchmark'
class PerformanceEvaluation
def self.call(applications_ids, export_id)
puts "Start"
time = Benchmark.realtime do
ApplicationsManagement::Export.new(applications_ids, export_id).call
end
puts "Finish in #{time.round(2)}"
end
end
И затем дернем его из консоли:
require './profilers/performance_evaluation'
applications_ids = Application.where(id: (1..100)).pluck
id)export_id = FactoryBot.create
export).idPerformanceEvaluation.call(applications_ids, export_id)
...
Finish in 40.13
=> nil
Сотню заявок наш сервис обсчитывал около 40 секунд. А это значит, на наши 38_000 записей ему потребовалось бы больше 4 часов! Естественно, цифры выглядели просто неприемлемыми.
Профилирование
Чтобы понять, куда двигаться дальше, подключим гем ruby-prof. Он умеет не только профилировать и искать «узкие места», но и печатать отчеты в разных форматах. Для этой задачи я выбрал формат 'callgrind', и чтобы его читать нам понадобится утилита qcachegrind. Профайлер положим в ту же папку 'profilers':time_profiler.rb
# frozen_string_literal: true
require 'ruby-prof'
class TimeProfiler
def run(applications_ids, export_id)
RubyProf.measure_mode = RubyProf::WALL_TIME
result = RubyProf.profile do
ApplicationsManagement::Export.new(applications_ids, export_id).call
end
printer = RubyProf::CallTreePrinter.new(result)
printer.print(path: 'profilers/ruby_prof_reports', profile: 'callgrind')
end
end
Как видно выше, отчеты этот профайлер будет складывать в папку 'profilers/ruby_prof_reports/'. Запускаем его также из консоли:
require_relative 'profilers/time_profiler'
applications_ids = Application.pluck
id).last(100)export_id = FactoryBot.create
export).idTimeProfiler.new.run(applications_ids, export_id)
Теперь в папке с отчетами появился новый файл callgrind.callgrind.out.10176. Если появилось несколько, нам нужен тот, у которого имя покороче. Открываем его из терминала с помощью утилиты qcachegrind:
qcachegrind profilers/ruby_prof_reports/callgrind.callgrind.out.10176
И видим такое окно:
(Если у вас вид отличается, можете кликнуть Settings -> Sidebars -> Flat Profile). Здесь Я отсортировал данные по колонке self - что значит, сколько времени процесс потратил на свое выполнение. (Колонка Incl. Показывает - сколько времени он потратил на выполнение себя самого и дочерних процессов). Если кликнем по иконке % в верхнем меню, то увидим, что IO::wait_readable занимает больше 90% выполнения.
Доки Ruby не очень многословны о модуле IO::WaitReadable:
'exception to wait for reading. see IO.select.'
Но в целом, что тут еще говорить - ожидание input/output. Вопрос в том, что это ожидание вызывает?
Проверка гипотез
Первой моей гипотезой было - ожидание записи в CSV файл. Я решил ее проверить, и прогнать через профилировщик не весь сервис, а лишь этот его метод. Профилировщик в этот раз получился таким:time_profiler.rb
# frozen_string_literal: true
require 'ruby-prof'
class TimeProfiler
attr_reader :applications_ids, :file_path, :errors
def initialize(applications_ids)
@applications_ids = applications_ids
@file_path = Tempfile.new(['', '.csv']).to_path
@errors = []
end
def run
RubyProf.measure_mode = RubyProf::WALL_TIME
result = RubyProf.profile do
to_csv_export
end
printer = RubyProf::CallTreePrinter.new(result)
printer.print(path: 'profilers/ruby_prof_reports', profile: 'callgrind')
end
private
def to_csv_export
CSV.open(file_path, 'w') do |csv|
csv << export_headers # массив заголовков отчета почти на 90 элементов
# ActiveRecord::Relation с экспортируемыми заявками
export_collection.find_each do |instance|
begin
# В оригинальном сервисе здесь вызывается
# export_row(instance.decorate) -
# метод, который формировал каждую строку отчета.
# Заменим его на простую выборку атрибутов модели,
# чтобы минимизировать работу, и проверить,
# вызывается ли наш IO::WaitReadable самим процессом записи в CSV
# или вызовом тех самых методов модели для отрисовки отчета
csv << instance.attributes.values
rescue StandardError => e
errors << "#{instance.id}: #{e}"
end
end
end
end
def export_headers # rubocop:disable Metrics/MethodLength
[
'ID',
'Status',
... # Еще почти 90 заголовков
]
end
def export_collection
Application.where(id: applications_ids).includes(
... # увесистый список связанных моделей, опустим для краткости
).order(created_at: :desc)
end
end
Новый отчет callgrind вообще не содержал вызова этого модуля.
Попробуем углубиться, и «прощупать» сам метод формирования строки export_row.
time_profiler.rb
# frozen_string_literal: true
require 'ruby-prof'
class TimeProfiler
def run
RubyProf.measure_mode = RubyProf::WALL_TIME
app = Application.last
result = RubyProf.profile do
export_row(app.decorate)
end
printer = RubyProf::CallTreePrinter.new(result)
printer.print(path: 'profilers/ruby_prof_reports', profile: 'callgrind')
end
private
# Data for writing for each application
def export_row(application) # rubocop:disable Metrics/MethodLength, Metrics/AbcSize, Metrics/PerceivedComplexity, Metrics/CyclomaticComplexity, Metrics/LineLength
[
application.id,
application.status,
... # Еще около 90 строк
]
end
end
А вот и наш модуль. И опять занимает гигантские 80% времени даже при всего одной записи.
Дальше можно по принципу бинарного поиска закомментировать половину вызываемых методов, и проверить, вызывается ли «долгий» модуль или нет. Если нет - проблема в закомментированных строках. Делим их пополам опять и т.д… Довольно быстро я нашел строку, которая вызывала этот модуль:
...
application.photo_urls.present? ? 'Yes' : 'No',
...
Смотрим в модель Application, что же это за метод такой?
models/application.rb
# frozen_string_literal: true
class Application
...
def photo_urls
return if Rails.env.test?
s3 = Aws::S3::Resource.new
bucket = s3.bucket('bucket-name')
return [] if guid.nil?
bucket.objects(prefix: "documents/#{guid}")
.reject { |x| x.key.include?('/preview/') }
.map { |o| o.presigned_url
get) }end
end
Иными словами, чтобы написать в отчете 'yes' или 'no' мы лезли в AWS, и смотрели, есть ли у нас в определенной папочке какие-нибудь фотографии. Заголовок этого столбца в отчете гласил KYC. То есть менеджеры ожидали видеть, прошел ли заявитель процедуру KYC (know-your-customer, кто работает в Fintech, наверняка знает) или еще нет. Я начал спрашивать бизнес, может, выберем другой способ этот признак определить? Например, можно сохранять этот флаг в бд при загрузке фотографий. Выяснилось, что им вообще этот столбец в отчете не нужен.
Я выпилил эту строчку и снова обратился к нашей метрике. PerformanceEvaluation показал всего лишь 3 секунды на обработке той же сотни заявок. На больших объемах разница была еще разительней. Отчет, который до этого не могли сгенерировать за 4+ часа, теперь пишется чуть дольше, чем за одну минуту. Виной всему одна строчка, которая вообще-то никому не была нужна.
P.S./Bonus
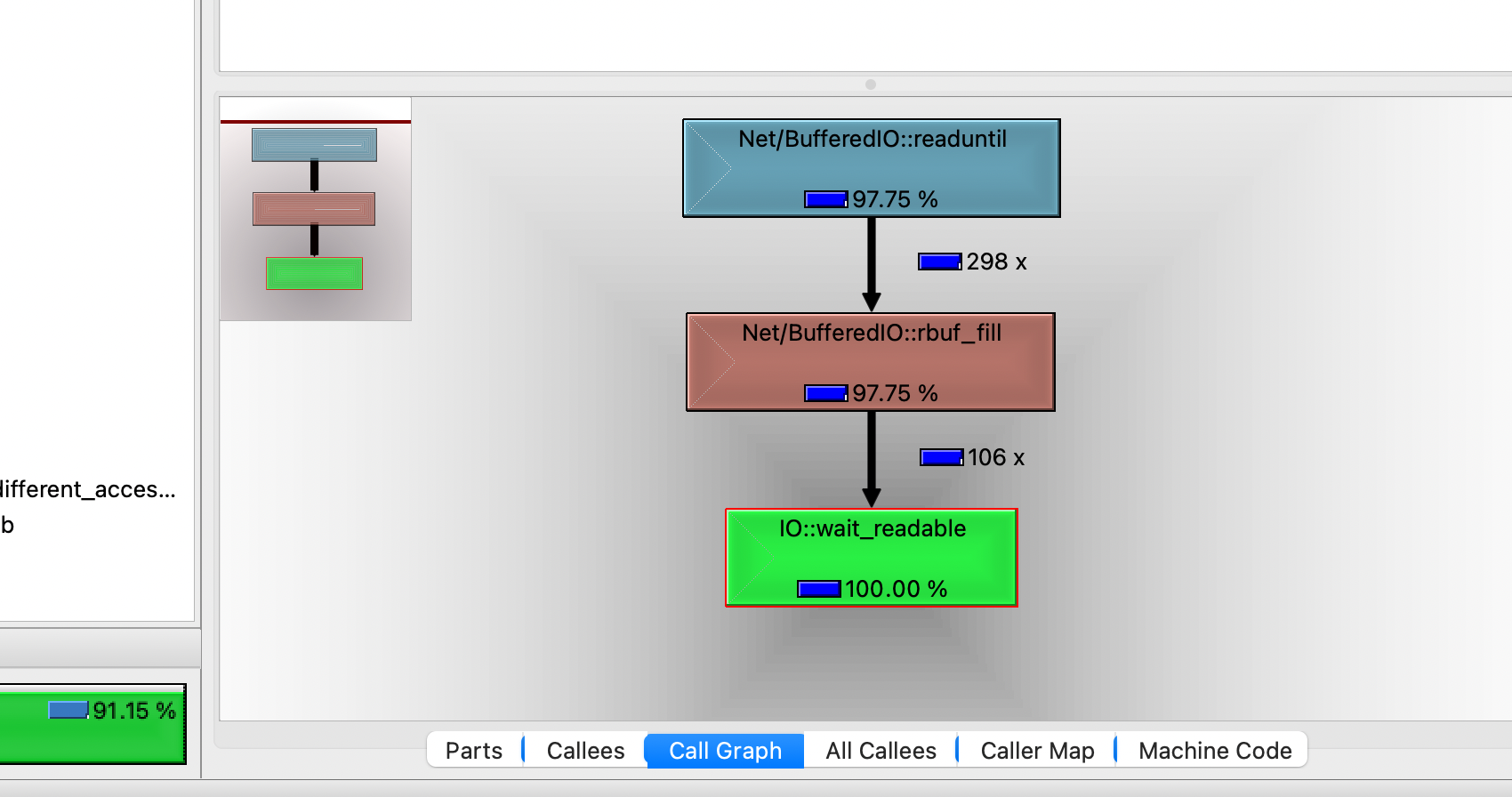
На самом деле, найти эту проблему можно было и быстрей. Без разбивания сервиса на части и прогона их через профилировщик. Опытные фанаты Qcachegrind наверное заметили, что я не углублялся в его интерфейс, и в целом я далеко не спец по нему. Наверняка его можно использовать и с бОльшим КПД. Например, если кликнуть по любому процессу, а в правой нижней части окна выбрать режим «Call Graph», можно увидеть дерево вызовов - какой модуль каким модулем был вызван.
Дважды кликаем по любому родителю, и дерево «растет» дальше:
Думаю, модуль Net/HTTPResponse мог на правильную догадку подтолкнуть быстрей, и статья закончилась бы раньше. Но мне хотелось показать пример воркфлоу, который легко можно применить на любых проектах.
Источник статьи: https://habr.com/ru/post/561258/