Ларин Алексей, Data Scientist
Владельцы торговых центров достаточно часто сталкиваются с ситуацией, когда арендатор прекращает свою деятельность без предварительного уведомления арендодателя. Соответственно, страдают организационные и бизнес-процессы владельца коммерческой недвижимости, падает прибыль. Сегодня поговорим о том, как технологии могут помочь решить эту проблему. Ну а использовать будем OCR-карту и модели данных.

Но раскрашивать и сравнивать арендаторов вручную не наш метод. Это долго, дорого и не очень надёжно. Вместо этого давайте использовать технологии.
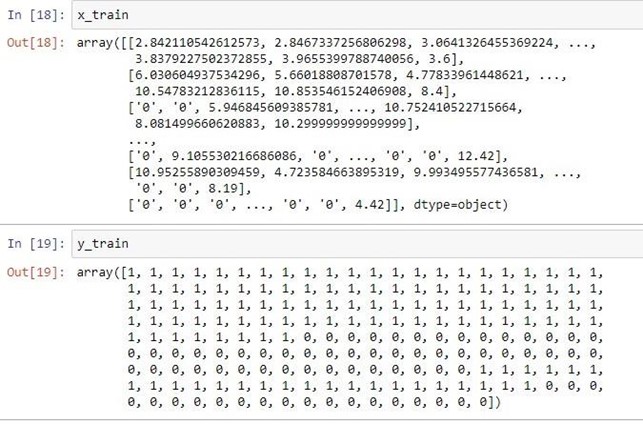
Сначала необходимо подготовить выборку для обучения, у нас это OCR-карты, построенные на основе арендного плана за 5 лет. В обучающую выборку включаем данные только по 12 месяцам. Это обусловлено необходимостью подать равнозначное количество данных как в обучающую, так и в валидационную выборку. В датасет для обучения включены OCR-карты, построенные на исторических данных арендных планов, с исключением COVID-ного локдауна. Добавляем столбец «Для модели», в котором закрытые торговые точки арендаторов помечены цифрой «0», а работающие — «1», распределение закрытых и работающих торговых точек — 50 на 50. Такое распределение задали, выбрав из OCR-коэффициентов по торговым точкам арендаторов на данных арендного плана за 5 лет работы торгового центра.
При анализе ошибок первого и второго рода для бизнеса я остановился именно на таком распределении потому, что ложноположительные предсказания ухода арендаторов не окажут вреда ТЦ. Поэтому разработанная модель будет предсказывать не уход конкретного арендатора, а то, что он останется в ТЦ. В итоге для обучения получился набор данных из 1 500 строк (OCR-коэффициенты по 1 500 арендаторов за 12 месяцев).
Импортируем библиотеки:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import openpyxl
from sklearn import svm
Загружаем и подготавливаем данные:
x = pd.read_excel("/home/…/для модели.xlsx")
y = pd.read_excel("/home/…/для модели.xlsx")

 x_train = x
x_train = x
del x_train['id']
del x_train['Для модели']
x_train = x_train.fillna('0')
y_train=y[['Для модели']]
y_train = y_train.fillna('0')
x_train = x_train.values
y_train = np.array([y[0] for y in y_train.values])

Использование разных алгоритмов машинного обучения в коде отличается незначительно.
#метод опорных векторов
from sklearn import svm
#Задаём параметры модели
model = svm.SVC(kernel='linear', degree=2, C=1)
#Обучаем модель
model.fit(x_train, y_train)
#метод ближайших соседей
from sklearn.neighbors import KNeighborsClassifier
#Задаём параметры модели
model = KNeighborsClassifier()
#Обучаем модель
model.fit(x_train, y_train)
#Метод xgboost
import xgboost
#Задаём параметры модели
model = xgboost.XGBClassifier()
#Обучаем модель
model.fit(x_train, y_train)
Для сравнения алгоритмов машинного обучения рассчитали метрики и построили ROC-кривые (вот код для построения ROC-кривых). Кстати, по ссылке доступна и база знаний по библиотеке sklearn.

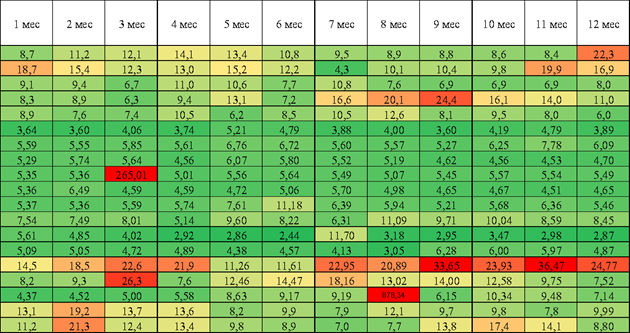
Для теста модели был подготовлен датасет с OCR-картами за 5 лет работы торгового центра, с исключением пустых значений из-за различных локдаунов (OCR-коэффициенты по более 8 000 арендаторов за 60 месяцев). В модель подавали данные карт за 12 месяцев, двигаясь по временной шкале от начала работы ТЦ до предыдущего месяца от текущей даты.
Такой метод дал возможность хорошо протестировать модель и установить временной лаг предсказания. Оказалось, что лучше всего на тестовой выборке показывает себя алгоритм ближайших соседей. Но всё же основная для нас задача — прогноз оттока арендаторов из ТЦ, поэтому остановимся на методе опорных векторов. Именно он предсказывает больше всего верных ответов по закрывающимся торговым точкам. Протестируем данный алгоритм на исторических данных по OCR-картам, построенным на арендных планах по ТЦ в валидационной выборке, обучая на тестовой.
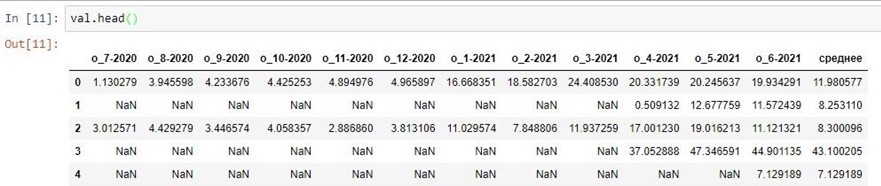
Загружаем данные для предсказания:
val = pd.read_excel("/home/…/OCR_2021_итог.xlsx")
#Удаляем ненужные столбцы (можно удалить и заранее)
del val['id']
del val['ИНН']
del val['Наименование арендатора']

# Предсказываем
val = val.fillna('0')
val = val.values
y_pred = model.predict(val)
 pred2 = pd.DataFrame(y_pred)
pred2 = pd.DataFrame(y_pred)
pred2 = pd.DataFrame(y_pred)
pred1 = pd.DataFrame(val)
pred = pred1.join(pred2)
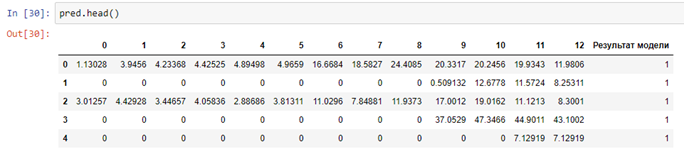 pred.to_excel('итог.xlsx', index= False)
pred.to_excel('итог.xlsx', index= False)
Метрики на валидационной выборке по историческим данным получились следующие:
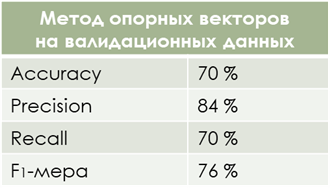
Как видно из метрик, сильно просела полнота, так что необходимо наложить предсказание на арендный план и посмотреть, какие ответы модель не смогла угадать.
ИМХО: анализ без визуализации — не анализ.
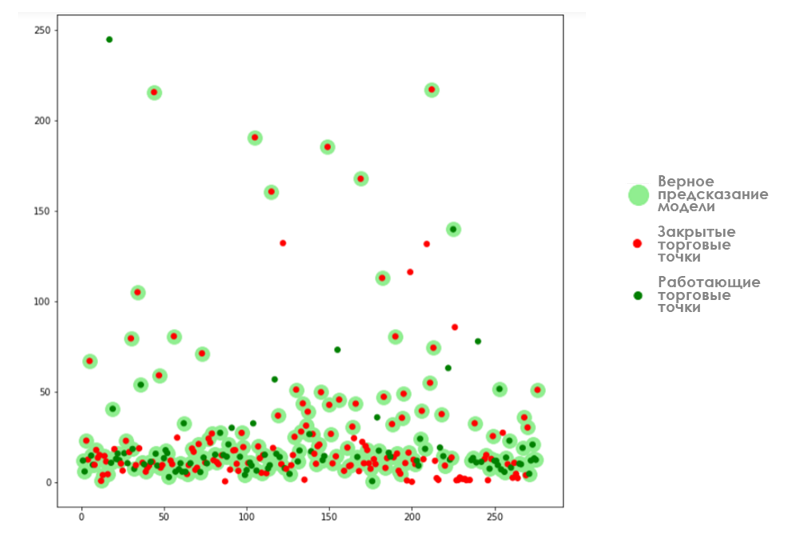
P. S. График был построен для эстетических целей.
Для построения графика использовал две точечные диаграммы со взаимным наложением. В качестве значения оси Х выбрали номер арендатора по порядку, в качестве оси Y — среднее значение коэффициента OCR. Значения одинаковы для двух диаграмм. Первая диаграмма строится с цветовым обозначением фактических данных по закрытым и работающим торговым точкам (светло-зелёным — работающие, прозрачным цветом — закрытые). Вторая диаграмма — с цветовым обозначением предсказания модели по торговым точкам арендаторов (зелёным цветом — работает, красным — закроется). Очерёдность построения не будет иметь значения, если задать цвет в формате RGB с указанием прозрачности в альфа-канале — #33DD11AA. Эстетически мне больше понравилось, как выглядит наложение графиков:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel("Граф.xlsx")
plt.figure(figsize=(20,10))
colors_1 = np.where(df['Предсказание']=='Работает','green','red')
colors_2 = np.where(df['Факт']=='Работает','lightgreen', ' #33DD1100')
plt.scatter(x = df['№ п/п'], y = df['Средний OCR'],c = colors_2,s = 150)
plt.scatter(x = df['№ п/п'], y = df['Средний OCR'],c = colors_1,)
plt.show()
Кроме того, есть компании, которые скрывают свою выручку перед арендодателем, умышленно занижая её. Делают это компании для уменьшения переменной части арендной платы.
Для исправления ошибки с сетевыми торговыми точками был введён коэффициент торговой сети. Всех арендаторов разбили на 3 группы: федеральные, региональные и местные. Скорректировали OCR-карты на эти коэффициенты, уменьшив значение показателя OCR у федеральных и региональных арендаторов. Коэффициенты подбирались дольше, чем весь анализ. Раскрою секрет: у местных коэффициент 1, по региональным — 0,8, по федеральным — 0,7.
А вот для исправления ошибки с арендаторами, которые занижают выручку, не всё так просто. Пришлось поработать — например, проанализировать трафик и количество чеков каждой торговой точки. Проблема в том, что коэффициент у всех разный, так что корректировать данные по каждому арендатору отдельно нецелесообразно.
После всех манипуляций наши метрики значительно улучшились:
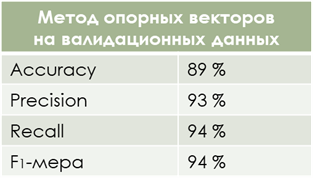
Так как период данных для анализа был большой (более 5 лет), модель тестировалась достаточно долго в разных временных промежутках, что позволило установить временной лаг предсказания. Модель предсказывает, что арендатор уйдёт в течение 3-х месяцев, при увеличении лага точность начинает падать. Метрики разнились в пределах 1-2%, это говорит о том, что модель успешно справляется со своей задачей.
В конечном счёте при загрузке данных OCR-карт, построенных на арендном плане за последние 12 месяцев, были получены предсказания ухода из ТЦ 9 арендаторов в течение 3-х месяцев, с арендными платежами, которые составляют 8% от всего арендного потока. Данное предсказание даёт возможность предпринять меры для сохранения арендного потока в полном объёме.
И это не просто слова. Модель предсказала, что владелец ТЦ может увеличить арендный поток на 5% без риска оттока клиентов.
Ещё одно достоинство модели заключается в том, что она позволяет обработать большой объём информации за очень короткое время. Модели, описанной в статье, для прогнозирования по более 8 тыс. арендаторов понадобилось всего около 5 минут. Если вручную провести анализ по тем же данным, то человеку потребуется значительно большее количество времени.
Позже модель была протестирована и на других ТЦ, метрики различались в пределах 1-2%. Также подошли и коэффициенты, которые подбирались для сетевых арендаторов, что позволило сразу загружать данные в модель без предварительной настройки.
Так, запустив модель 1 раз в месяц, мы получаем прогноз «бегства» арендаторов из всех наших ТЦ. Задача решена!

 habr.com
habr.com
Владельцы торговых центров достаточно часто сталкиваются с ситуацией, когда арендатор прекращает свою деятельность без предварительного уведомления арендодателя. Соответственно, страдают организационные и бизнес-процессы владельца коммерческой недвижимости, падает прибыль. Сегодня поговорим о том, как технологии могут помочь решить эту проблему. Ну а использовать будем OCR-карту и модели данных.
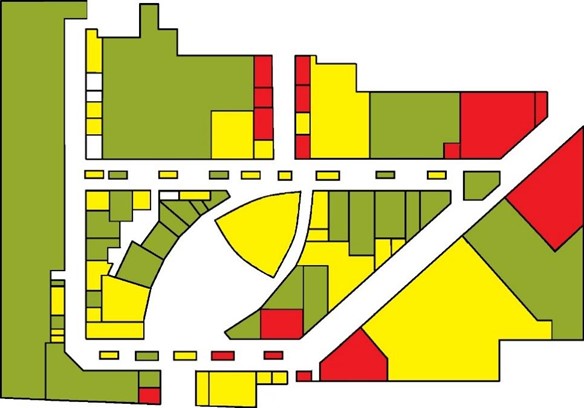
Что за OCR-карта?
Чтобы предсказать «побег» арендаторов, передовые и успешные ТЦ используют для анализа текущей деятельности ряд методик, одной из которых является OCR-карта. Она помогает собственнику и управляющему торговым центром оперативно отслеживать результаты деятельности арендаторов, чтобы в случае их ухудшения вовремя принимать меры по предотвращению нежелательных ситуаций.- Индекс OCR (Occupancy Cost Ratio) — это соотношение арендной платы к товарообороту. Согласно значения индекса OCR арендаторов делят на отдельные категории. Индекс OCR от 0 до 15 показывает, что арендатор прекрасно чувствует себя в торговом центре, такие арендаторы обозначаются зелёным цветом. Индекс от 15 до 30 показывает, что считается средним и обозначается жёлтым, а всё, что выше этого показателя, попадает в «красную зону». «Красная зона» сигнализирует о потенциальной дебиторской задолженности и возможной ротации оператора. Если арендатор на протяжении нескольких месяцев попадает в «красную зону», то существует большая вероятность его ухода из ТЦ.
Но раскрашивать и сравнивать арендаторов вручную не наш метод. Это долго, дорого и не очень надёжно. Вместо этого давайте использовать технологии.
Машинное обучение и предиктивные модели
Рассмотрим, как на основе алгоритма машинного обучения можно провести предиктивный анализ «бегства» арендаторов из вашего ТЦ. Строить модель будем на основе одного из трёх простых алгоритмов: ближайших соседей, опорных векторов и XGBoost с использованием Python и библиотек pandas, numpy, openpyxl, matplotlib, sklearn, xgboost.Сначала необходимо подготовить выборку для обучения, у нас это OCR-карты, построенные на основе арендного плана за 5 лет. В обучающую выборку включаем данные только по 12 месяцам. Это обусловлено необходимостью подать равнозначное количество данных как в обучающую, так и в валидационную выборку. В датасет для обучения включены OCR-карты, построенные на исторических данных арендных планов, с исключением COVID-ного локдауна. Добавляем столбец «Для модели», в котором закрытые торговые точки арендаторов помечены цифрой «0», а работающие — «1», распределение закрытых и работающих торговых точек — 50 на 50. Такое распределение задали, выбрав из OCR-коэффициентов по торговым точкам арендаторов на данных арендного плана за 5 лет работы торгового центра.
При анализе ошибок первого и второго рода для бизнеса я остановился именно на таком распределении потому, что ложноположительные предсказания ухода арендаторов не окажут вреда ТЦ. Поэтому разработанная модель будет предсказывать не уход конкретного арендатора, а то, что он останется в ТЦ. В итоге для обучения получился набор данных из 1 500 строк (OCR-коэффициенты по 1 500 арендаторов за 12 месяцев).
Импортируем библиотеки:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import openpyxl
from sklearn import svm
Загружаем и подготавливаем данные:
x = pd.read_excel("/home/…/для модели.xlsx")
y = pd.read_excel("/home/…/для модели.xlsx")
del x_train['id']
del x_train['Для модели']
x_train = x_train.fillna('0')
y_train=y[['Для модели']]
y_train = y_train.fillna('0')
x_train = x_train.values
y_train = np.array([y[0] for y in y_train.values])
Использование разных алгоритмов машинного обучения в коде отличается незначительно.
#метод опорных векторов
from sklearn import svm
#Задаём параметры модели
model = svm.SVC(kernel='linear', degree=2, C=1)
#Обучаем модель
model.fit(x_train, y_train)
#метод ближайших соседей
from sklearn.neighbors import KNeighborsClassifier
#Задаём параметры модели
model = KNeighborsClassifier()
#Обучаем модель
model.fit(x_train, y_train)
#Метод xgboost
import xgboost
#Задаём параметры модели
model = xgboost.XGBClassifier()
#Обучаем модель
model.fit(x_train, y_train)
Для сравнения алгоритмов машинного обучения рассчитали метрики и построили ROC-кривые (вот код для построения ROC-кривых). Кстати, по ссылке доступна и база знаний по библиотеке sklearn.
ROC-кривая (Receiver Operation Characteristic — рабочие характеристики модели) — кривая вероятности, которая отображает отношение TPR (чувствительность/доля верно классифицированных положительных наблюдений = TP/(TP+FN)) к FPR (специфичность/доля неверно классифицированных негативных наблюдений = FP/(FP+TN)) при различных пороговых значениях. Площадь под кривой (AUC — Area Under Curve) является мерой способности классификатора различать классы. Чем выше этот показатель, тем лучше производительность модели.
Для теста модели был подготовлен датасет с OCR-картами за 5 лет работы торгового центра, с исключением пустых значений из-за различных локдаунов (OCR-коэффициенты по более 8 000 арендаторов за 60 месяцев). В модель подавали данные карт за 12 месяцев, двигаясь по временной шкале от начала работы ТЦ до предыдущего месяца от текущей даты.
Такой метод дал возможность хорошо протестировать модель и установить временной лаг предсказания. Оказалось, что лучше всего на тестовой выборке показывает себя алгоритм ближайших соседей. Но всё же основная для нас задача — прогноз оттока арендаторов из ТЦ, поэтому остановимся на методе опорных векторов. Именно он предсказывает больше всего верных ответов по закрывающимся торговым точкам. Протестируем данный алгоритм на исторических данных по OCR-картам, построенным на арендных планах по ТЦ в валидационной выборке, обучая на тестовой.
Загружаем данные для предсказания:
val = pd.read_excel("/home/…/OCR_2021_итог.xlsx")
#Удаляем ненужные столбцы (можно удалить и заранее)
del val['id']
del val['ИНН']
del val['Наименование арендатора']
# Предсказываем
val = val.fillna('0')
val = val.values
y_pred = model.predict(val)
pred2 = pd.DataFrame(y_pred)
pred1 = pd.DataFrame(val)
pred = pred1.join(pred2)
Метрики на валидационной выборке по историческим данным получились следующие:
Как видно из метрик, сильно просела полнота, так что необходимо наложить предсказание на арендный план и посмотреть, какие ответы модель не смогла угадать.
ИМХО: анализ без визуализации — не анализ.
P. S. График был построен для эстетических целей.
Для построения графика использовал две точечные диаграммы со взаимным наложением. В качестве значения оси Х выбрали номер арендатора по порядку, в качестве оси Y — среднее значение коэффициента OCR. Значения одинаковы для двух диаграмм. Первая диаграмма строится с цветовым обозначением фактических данных по закрытым и работающим торговым точкам (светло-зелёным — работающие, прозрачным цветом — закрытые). Вторая диаграмма — с цветовым обозначением предсказания модели по торговым точкам арендаторов (зелёным цветом — работает, красным — закроется). Очерёдность построения не будет иметь значения, если задать цвет в формате RGB с указанием прозрачности в альфа-канале — #33DD11AA. Эстетически мне больше понравилось, как выглядит наложение графиков:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel("Граф.xlsx")
plt.figure(figsize=(20,10))
colors_1 = np.where(df['Предсказание']=='Работает','green','red')
colors_2 = np.where(df['Факт']=='Работает','lightgreen', ' #33DD1100')
plt.scatter(x = df['№ п/п'], y = df['Средний OCR'],c = colors_2,s = 150)
plt.scatter(x = df['№ п/п'], y = df['Средний OCR'],c = colors_1,)
plt.show()
Положительные результаты и проблемы с моделью
Так как загружаемые в модель данные основаны на простых показателях — выручке и арендных платежах арендаторов, то предсказания по работающим торговым точкам с OCR-картами в диапазоне 1-10 и более 21 модель угадывает очень хорошо. Проблемы с предсказанием у модели возникают в диапазоне 11-20 значений OCR-карт с ошибкой второго рода (ложноотрицательная). При детальном анализе данных ошибки выявилась закономерность в части таких арендаторов, как крупные федеральные сети. Дело в том, что из-за конкуренции между собой многие сетевые магазины будут держать убыточную торговую точку, чтобы не пустить на это место конкурента. И это необходимо учитывать при построении прогностической модели.Кроме того, есть компании, которые скрывают свою выручку перед арендодателем, умышленно занижая её. Делают это компании для уменьшения переменной части арендной платы.
Для исправления ошибки с сетевыми торговыми точками был введён коэффициент торговой сети. Всех арендаторов разбили на 3 группы: федеральные, региональные и местные. Скорректировали OCR-карты на эти коэффициенты, уменьшив значение показателя OCR у федеральных и региональных арендаторов. Коэффициенты подбирались дольше, чем весь анализ. Раскрою секрет: у местных коэффициент 1, по региональным — 0,8, по федеральным — 0,7.
А вот для исправления ошибки с арендаторами, которые занижают выручку, не всё так просто. Пришлось поработать — например, проанализировать трафик и количество чеков каждой торговой точки. Проблема в том, что коэффициент у всех разный, так что корректировать данные по каждому арендатору отдельно нецелесообразно.
После всех манипуляций наши метрики значительно улучшились:
Так как период данных для анализа был большой (более 5 лет), модель тестировалась достаточно долго в разных временных промежутках, что позволило установить временной лаг предсказания. Модель предсказывает, что арендатор уйдёт в течение 3-х месяцев, при увеличении лага точность начинает падать. Метрики разнились в пределах 1-2%, это говорит о том, что модель успешно справляется со своей задачей.
В конечном счёте при загрузке данных OCR-карт, построенных на арендном плане за последние 12 месяцев, были получены предсказания ухода из ТЦ 9 арендаторов в течение 3-х месяцев, с арендными платежами, которые составляют 8% от всего арендного потока. Данное предсказание даёт возможность предпринять меры для сохранения арендного потока в полном объёме.
И ещё немного подробностей
Так для чего нужна данная модель арендодателю, если по OCR-картам и так видно, как чувствует себя арендатор в ТЦ? Изначально показатель OCR преследует 2 цели: поиск потенциальных арендаторов на ещё занятое место в ТЦ и увеличение прибыли. Если индекс OCR низкий, то следует пересмотреть арендную ставку для этого арендатора в сторону повышения, так же и в обратную сторону — при высоком значении индекса. При помощи модели можно виртуально менять размер арендной платы, моделируя различные ситуации. Тем самым в непростой экономической ситуации у владельцев ТЦ есть возможность максимизировать прибыль без значительного риска потерять часть потоков от арендных платежей.И это не просто слова. Модель предсказала, что владелец ТЦ может увеличить арендный поток на 5% без риска оттока клиентов.
Ещё одно достоинство модели заключается в том, что она позволяет обработать большой объём информации за очень короткое время. Модели, описанной в статье, для прогнозирования по более 8 тыс. арендаторов понадобилось всего около 5 минут. Если вручную провести анализ по тем же данным, то человеку потребуется значительно большее количество времени.
Позже модель была протестирована и на других ТЦ, метрики различались в пределах 1-2%. Также подошли и коэффициенты, которые подбирались для сетевых арендаторов, что позволило сразу загружать данные в модель без предварительной настройки.
Так, запустив модель 1 раз в месяц, мы получаем прогноз «бегства» арендаторов из всех наших ТЦ. Задача решена!
Технологии помогают бизнесу: как предсказать «побег» арендаторов из торговых центров при помощи ML-модели
Ларин Алексей, Data Scientist Владельцы торговых центров достаточно часто сталкиваются с ситуацией, когда арендатор прекращает свою деятельность без предварительного уведомления арендодателя....
habr.com