Примерно год назад передо мной и моими коллегами была поставлена задача разобраться с использованием популярной системы мониторинга сетевой инфраструктуры — Zabbix. После изучения документации мы сразу же перешли к нагрузочному тестированию: хотели оценить с каким количеством параметров может работать Zabbix без заметных падений производительности. В качестве СУБД использовали только PostgreSQL.
В ходе тестов были выявлены некоторые архитектурные особенности разметки БД и поведения самой системы мониторинга, которые по умолчанию не позволяют выйти системе мониторинга на свою максимальную мощность работы. В результате были разработаны, проведены и апробированы некоторые оптимизационные мероприятия в основном в части настройки БД.
О результатах проделанной работы я и хочу поделиться в данной статье. Статья будет полезна как администраторам Zabbix, так и PostgreSQL DBA, а также всем желающим лучше понять и разобраться в популярной СУБД PosgreSQL.
Небольшой спойлер: на слабой машине при нагрузке в 200 тысяч параметров в минуту нам удалось снизить показатель CPU iowait с 20% до 2%, уменьшить время записи порциями в таблицы первичных данных в 250 раз и в таблицы агрегированных данных в 32 раза, уменьшить размер индексов в 5-10 раз и ускорить получение исторических выборок в некоторых случаях до 18 раз.
Нагрузочное тестирование проводилось по схеме: один сервер Zabbix, один активный Zabbix proxy, два агента. Каждый агент был настроен чтобы отдавать по 50 т. целочисленных и 50 т. строковых параметров в минуту (суммарно с двух агентов получается 200 т. параметров в минуту или по 3333 параметра в секунду). Для генерации параметров агента мы использовали плагин для Zabbix Для проверки того, какое максимальное количество параметров может генерировать агент, нужно использовать специальный скрипт от того же автора плагина zabbix_module_stress. Web-админка Zabbix имеет сложности с регистрацией больших шаблонов, поэтому мы разбили параметры на 20 шаблонов по 5 т. параметров (2500 числовых и 2500 строковых).
Скрипт генератора шаблонов для нагрузочного тестирования на python
Метрика cpu iostat служит хорошим показателем производительности Zabbix — она отражает долю единицы времени, в течение которой процессор ожидает доступа к диску. Чем она выше — тем больше диск занят операциями чтения и записи, что косвенно влияет на ухудшение производительности системы мониторинга в целом. Т.е. это верный признак того, что с мониторингом что-то не в порядке. Кстати, на просторах сети довольно популярный вопрос «как убрать триггер iostat в Zabbix», так что это наболевшая тема, потому что существует множество причин повышения значения метрики iowait.
Вот какую картину для метрики cpu iowait мы получили спустя три дня изначально:
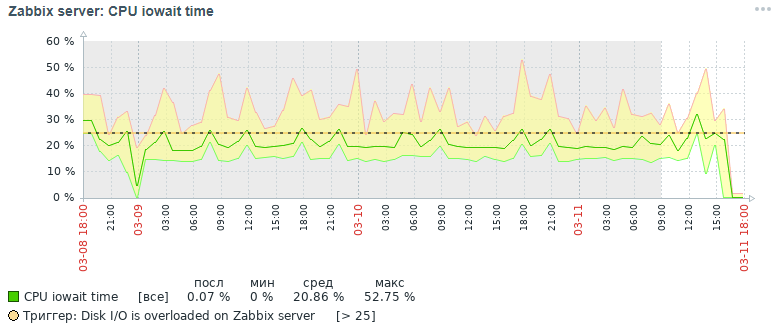
А вот какую картину для этой же метрики мы получили также в течение трёх дней в итоге после всех проделанных оптимизационных мероприятий, речь о которых будет идти ниже:
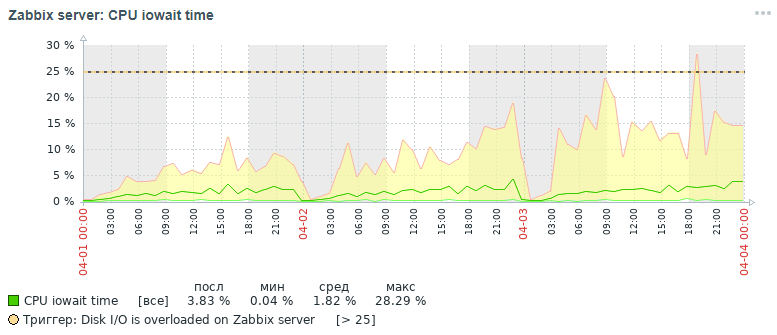
Как видно из графиков показатель cpu iowait упал практически с 20% до 2%, что косвенно ускорило время выполнения всех запросов на добавление и чтение данных. Теперь давайте разберёмся почему при стандартных настройках БД происходит падение общей производительности системы мониторинга и как это исправить.
При накоплении более 10 млн значений параметров в каждой таблице первичных данных было замечено, что быстродействие системы мониторинга резко падает, что связано со следующими причинами:
Ситуация усугубляется в начале каждого часа, когда в добавок к этому высчитывается агрегированная почасовая статистика — при этом выполняется активное чтение и запись индексных страниц с диска, удаление устаревших данных из истории, что приводит всё к тому же результату — падение производительности БД и увеличение времени выполнения запросов (в пределе было отмечен запрос длительностью до 5ти минут!).
Небольшая справка по организации хранилища данных мониторинга в Zabbix. Он хранит первичные данные и агрегированные данные в разных таблицах, причём с разделением по типам параметров. Каждая таблица хранит поле itemid (неявная ссылка на зарегистрированный элемент данных в системе), временную метку регистрации значения clock в формате unix timestamp (миллисекунды в отдельном столбце) и значение в отдельном столбце (исключением является таблица логов, в ней больше полей — подобие журнала событий):
Для повышения производительности БД PostgreSQL были проведены различные оптимизационые мероприятия, основными из которых являются партиционирование и изменение индексов. Однако стоит упомянуть парой слов ещё о нескольких важных и полезных мероприятиях, способных ускорить работу любой БД под СУБД PostgreSQL.
Важное замечание. На момент сбора материала статьи нами использовался Zabbix версии 4.0, хотя сейчас уже вышла версия 4.2 и готовится к выходу версия 4.4. Почему об этом важно упомянуть? Потому что начиная с версии 4.2 Zabbix стал поддерживать специальное мощное расширение для работы с временными рядами TimescaleDB, но пока в экспериментальном режиме: при всех достоинствах использования этого расширения есть мнение, что некоторые запросы стали работать медленнее и имеются пока ещё не решённые проблемы производительности (будут решены в версии 4.4) — прочтите эту статью. В следующей статье планирую написать о результатах нагрузочного тестирования уже с использованием расширения TimescaleDB в сравнении с данным кейсом решений. Версия PostgreSQL использовалась 10, но вся приведённая информация актуальна и для 11 и 12 версий (ждём!).
Поэтому обо всём по порядку:
На самом деле PostgreSQL — довольно легковесная СУБД. Её конфигурационный файл по умолчанию настроен так, чтобы, как говорит мой коллега, «работать даже на кофеварке», т.е. на весьма скромном железе. Поэтому обязательно нужно настраивать PostgreSQL под конфигурацию сервера, учитывая объём памяти, количество процессоров, тип предполагаемого использования БД, тип диска (HDD или SSD) и количество подключений.
Увы, не существует единой формулы настройки всех СУБД, но есть определённые правила и закономерности, подходящие для большинства конфигураций (более тонкая настройка — уже дело рук эксперта). Для упрощения жизни DBA была написана утилита pgtune, которая была дополнена web версией пользователем le0pard — автором интересной и полезной книги по администрированию PostgreSQL.
Пример запуска утилиты в консоли с указанием 100 подключений (у Zabbix требовательная Web админка) под тип приложения «Data warehouses»:
pgtune -i postgresql.conf -o new_postgresql.conf -T DW -c 100
Конфигурационные параметры, которые меняет утилита pgtune, с описанием назначения (значения приведены в качестве примера)
Некоторые полезные параметры конфигурации postgresql
Данный пункт не обязателен и скорее является переходным решением на пути к полноценному распределённому кластеру, но знать о такой возможности будет полезно. Для ускорения работы БД можно вынести её на отдельный диск. Мы смонтировали диск целиком в каталог base, где хранятся все БД PostgreSQL, но вообще можно сделать по-другому: создать новый tablesbase и вынести БД (или даже только её часть — таблицы первичных и агрегированных данных мониторинга) в этот tablesbase на отдельный диск.
Пример монтирования
Одна из проблем, с которой мы столкнулись при нагрузочном тестировании Zabbix — PostgreSQL не успевает удалять устаревшие данные из БД. С помощью партиционирования можно разбить таблицу на составные части, тем самым уменьшить размер индексов и составных частей супертаблицы, что положительно сказывается на быстродействии БД в целом.
Партиционирование решает сразу две проблемы:
1. ускорение удаления устаревших данных путём удаления целых таблиц
2. дробление индексов под каждую составную таблицу
Для партиционирования в PostgreSQL есть четыре механизма:
1. стандартный constraint_exclusion
2. расширение pg_partman (не путайте с pg_pathman)
3. расширение pg_pathman
4. вручную создавать и поддерживать партиции самим
Наиболее удобным, надёжным и оптимизированным решением для партиционирования, по нашему мнению, является расширение pg_pathman. При таком методе партиционирования планировщик запросов гибко определяет в каких партициях искать данные. Поговаривают, что в 12ой версии PostgreSQL будет отличное партиционирование уже «из коробки».
Таким образом, мы стали писать данные мониторинга за каждый день в отдельную унаследованную таблицу от супертаблицы и удаление устаревших значений параметров стало происходить через удаление сразу всех устаревших таблиц целиком, что гораздо проще для СУБД по трудозатратам. Удаление сделали через вызов пользовательской функции БД как параметр мониторинга Zabbix сервера в 2 часа ночи с указанием допустимого диапазона хранения статистики.
Установка и настройка партиционирования для PostgreSQL 10
Автонастройка удаления устаревших партиций (ахтунг - большая SQL функция)
Отдельное спасибо пользователю erogov за прекрасный цикл обзорных статей про индексы PostgreSQL. Да и вообще всей команде PostgresPRO. Под впечатлением этих статей мы поигрались с разными типами индексов на таблицах данных мониторинга и пришли к выводу какие типы индексов на каких полях дадут максимальный прирост производительности.
Было замечено, что на всех таблицах данных мониторинга по умолчанию создаётся составной индекс btree(itemid, clock) — он быстрый для поиска, особенно для монотонно упорядоченных значений, но сильно «пухнет» на диске, когда данных много — более 10 млн.
На таблицах почасовой агрегированной статистики по умолчанию вообще создан уникальный индекс, хотя эти таблицы для хранилища данных и уникальность здесь обеспечивается на уровне сервера приложений, а уникальный индекс только замедляет вставку данных.
В ходе тестирования различных индексов было выявлено наиболее удачное сочетание индексов: индекс brin на поле clock и индекс btree-gin на поле itemid для всех таблиц данных мониторинга.
Индекс brin идеально подходит для монотонно возрастающих данных, таких как временная метка факта какого-либо события, т.е. для временных рядов. А индекс btree-gin — это по сути gin индекс над стандартными типами данных, что в целом намного быстрее классического индекса btree т.к. gin индекс не перестраивается в ходе добавления новых значений, а лишь дополняется ими. Индекс btree-gin ставится как расширение к PostgreSQL.
Сравнение скорости выполнения выборок для этой стратегии индексирования и для индексов в БД Zabbix по умолчанию приведён ниже. В ходе нагрузочных тестов мы накопили данные за три дня по трём партициям:
Для оценки результатов выполнялись три вида запросов:
Результаты теста были сведены в таблицу ниже:
* размер в МБ указан суммарно для трёх партиций
** запрос типа 1 — данные за 3 дня, запрос типа 2 — данные за 12 часов, запрос типа 3 — данные за один час
Из сравнительной таблицы видно, что для больших таблиц данных с количеством записей более 100 млн чётко прослеживается, что изменение стандартного составного индекса btree на два индекса brin и btree-gin благотворно отразилось на уменьшении размера индексов и ускорении времени выполнения запросов.
Эффективность индексирования и партиционирования показана ниже на примере запроса добавления новых записей в таблицы history_uint и trends_uint (добавления происходят в среднем по 2000 значений за запрос).
Обобщая результаты тестов различных конфигураций индексов для таблиц данных мониторинга системы zabbix можно сказать, что подобное изменение стандартного индекса для таблиц данных мониторинга системы zabbix положительно сказывается на быстродействии системы в целом, что сильнее всего ощущается при накоплении объёмов данных в размере от 10 млн. Также не стоит забывать о косвенном эффекте «разбухания» стандартного btree индекса по умолчанию — частые перестроения многогигобайтного индекса приводит к сильной загрузке жёсткого диска (метрика utilization), что в конечном итоге повышает время операций с диском и время ожидания доступа к диску со стороны CPU (метрика iowait).
Но, чтобы индекс btree-gin мог работать с типом данных bigint (in8), которым является столбец itemid, нужно выполнить регистрацию семейства операторов типа bigint для индекса btree-gin.
Регистрация семейства операторов типа bigint для индекса btree-gin
Этот скрипт переразмечает все индексы в БД PostgreSQL для Zabbix с конфигурации по умолчанию на оптимальную конфигурацию, описанную выше.
Для индекса brin для нашего объёма данных при интенсивности в 100 т. параметров в минуту (100 т. в history и 100 т. в history_uint) было замечено, что на таблицах первичных данных мониторинга индекс при размере зоны в 512 страниц работает в два раза быстрее, чем при стандартном размере в 128 страниц, но это индивидуально и зависит от размера таблиц и конфигурации сервера. В любом случае индекс brin занимает очень мало места, а вот скорость его работы может быть чуть-чуть увеличена с помощью тонкой настройки размера зоны, но при условии, что интенсивность потока данных не сильно меняется.
В качестве итога стоит отметить, что существует ограничение, связанное с архитектурой самого Zabbix: на вкладке «Последние данные» собираются по два последних значения для каждого параметра с учётом фильтрации. По каждому параметру значения запрашиваются в БД отдельно. Поэтому чем больше таких параметров будет отобрано, тем дольше будет выполняться запрос. Наиболее быстро последние данные ищутся, когда на таблицах history установлен индекс btree(itemid, clock desc) именно с обратной сортировкой по времени, но при этом сам индекс конечно «пухнет» на диске и в целом косвенно замедляет работу с БД, что вызывает проблему, описанную выше.
Поэтому есть три выхода из положения:
Pg_stat_statements — расширение для сбора статистики выполнения запросов в рамках всего сервера. Преимущество данного расширения в том, что ему не требуется собирать и парсить логи PostgreSQL.
Использование расширения pg_stat_statements
Для мониторинга жёстких дисков в Zabbix из коробки предусмотрены только параметры vfs.dev.read и vfs.dev.write. Эти параметры не дают информации о загруженности дисков. Полезными критериями для поиска проблем с производительностью жёстких дисков являются показатели коэффициента загруженности utilization, время выполнения запроса await и загруженность очереди запросов к диску.
Как правило высокая загруженность диска коррелирует с высоким iowait самого cpu и с ростом времени выполнения sql запросов, что и было установлено при нагрузочном тестировании zabbix сервера со стандартной конфигурацией без партиционирования и без настройки альтернативных индексов. Добавить эти параметры мониторинга жёстких дисков можно с помощью следующих действий, которые были подсмотрены в статье у товарища lesovsky и улучшены: теперь параметры iostat собираются отдельно по каждому диску в json временный параметр, откуда по настройках постобработки уже раскладываются в конечные параметры мониторинга.
Пока Pull request ожидает на рассмотрении, вы можете попробовать развернуть мониторинг параметров дисков по подробной инструкции через мой fork.
После всех описанных действий можно добавить на главную панель мониторинга сервера Zabbix кастомный график с iowait cpu и параметрами utiliztion для системного диска и диска с БД (если они разные). Результат может выглядеть так (sda — основной диск, sdc — диск с БД):
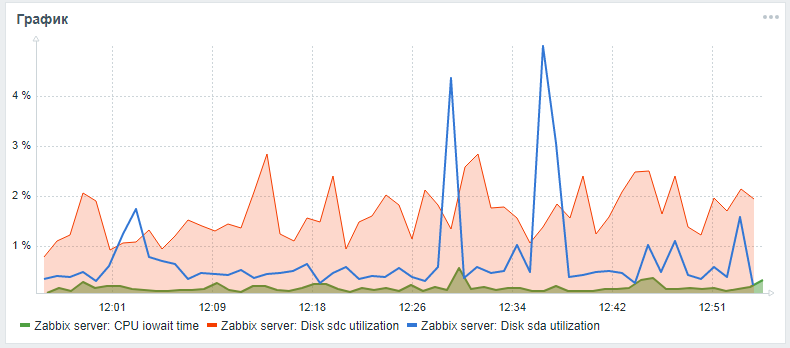
После настройки СУБД, индексирования и партиционирования можно приступить к вертикальному масштабированию — улучшить аппаратные характеристики сервера: добавить оперативной памяти, поменять накопители на твёрдотельные и добавить процессорных ядер. Это гарантированный прирост производительности, но лучше это сделать только после программной оптимизации.
После умеренного вертикального масштабирования нужно приступать к горизонтальному — создавать распределённый кластер: делать либо шардирование, либо репликации мастер-слейв. Но это уже отдельная тема и материал отдельной статьи(как слепить кластер из говна и палок), как и сравнение вышеописанного методики оптимизации БД Zabbix с использованием pg_pathman и индексирования с методикой применения расширения TimescaleDB.
А пока остаётся надеяться, что материал данной статьи оказался полезным и познавательным!
Источник статьи: https://habr.com/ru/post/468463/
В ходе тестов были выявлены некоторые архитектурные особенности разметки БД и поведения самой системы мониторинга, которые по умолчанию не позволяют выйти системе мониторинга на свою максимальную мощность работы. В результате были разработаны, проведены и апробированы некоторые оптимизационные мероприятия в основном в части настройки БД.
О результатах проделанной работы я и хочу поделиться в данной статье. Статья будет полезна как администраторам Zabbix, так и PostgreSQL DBA, а также всем желающим лучше понять и разобраться в популярной СУБД PosgreSQL.
Небольшой спойлер: на слабой машине при нагрузке в 200 тысяч параметров в минуту нам удалось снизить показатель CPU iowait с 20% до 2%, уменьшить время записи порциями в таблицы первичных данных в 250 раз и в таблицы агрегированных данных в 32 раза, уменьшить размер индексов в 5-10 раз и ускорить получение исторических выборок в некоторых случаях до 18 раз.
Нагрузочное тестирование
Нагрузочное тестирование проводилось по схеме: один сервер Zabbix, один активный Zabbix proxy, два агента. Каждый агент был настроен чтобы отдавать по 50 т. целочисленных и 50 т. строковых параметров в минуту (суммарно с двух агентов получается 200 т. параметров в минуту или по 3333 параметра в секунду). Для генерации параметров агента мы использовали плагин для Zabbix Для проверки того, какое максимальное количество параметров может генерировать агент, нужно использовать специальный скрипт от того же автора плагина zabbix_module_stress. Web-админка Zabbix имеет сложности с регистрацией больших шаблонов, поэтому мы разбили параметры на 20 шаблонов по 5 т. параметров (2500 числовых и 2500 строковых).
Скрипт генератора шаблонов для нагрузочного тестирования на python
Метрика cpu iostat служит хорошим показателем производительности Zabbix — она отражает долю единицы времени, в течение которой процессор ожидает доступа к диску. Чем она выше — тем больше диск занят операциями чтения и записи, что косвенно влияет на ухудшение производительности системы мониторинга в целом. Т.е. это верный признак того, что с мониторингом что-то не в порядке. Кстати, на просторах сети довольно популярный вопрос «как убрать триггер iostat в Zabbix», так что это наболевшая тема, потому что существует множество причин повышения значения метрики iowait.
Вот какую картину для метрики cpu iowait мы получили спустя три дня изначально:
А вот какую картину для этой же метрики мы получили также в течение трёх дней в итоге после всех проделанных оптимизационных мероприятий, речь о которых будет идти ниже:
Как видно из графиков показатель cpu iowait упал практически с 20% до 2%, что косвенно ускорило время выполнения всех запросов на добавление и чтение данных. Теперь давайте разберёмся почему при стандартных настройках БД происходит падение общей производительности системы мониторинга и как это исправить.
Причины падения производительности Zabbix
При накоплении более 10 млн значений параметров в каждой таблице первичных данных было замечено, что быстродействие системы мониторинга резко падает, что связано со следующими причинами:
- повышается метрика iowait для ЦП сервера свыше 20%, что свидетельствует о возрастании времени, в течении которого ЦП ожидает доступа к операциям чтения и записи диска
- сильно раздуваются индексы таблиц, в которых хранятся данные мониторинга
- повышается метрика общего использования (utilization) до 100% для диска с данными мониторинга, что свидетельствует о полной загруженности диска операциями чтения и записи
- устаревшие значения не успевают удаляться из таблиц историй при очистке по расписанию housekeeper
Ситуация усугубляется в начале каждого часа, когда в добавок к этому высчитывается агрегированная почасовая статистика — при этом выполняется активное чтение и запись индексных страниц с диска, удаление устаревших данных из истории, что приводит всё к тому же результату — падение производительности БД и увеличение времени выполнения запросов (в пределе было отмечен запрос длительностью до 5ти минут!).
Небольшая справка по организации хранилища данных мониторинга в Zabbix. Он хранит первичные данные и агрегированные данные в разных таблицах, причём с разделением по типам параметров. Каждая таблица хранит поле itemid (неявная ссылка на зарегистрированный элемент данных в системе), временную метку регистрации значения clock в формате unix timestamp (миллисекунды в отдельном столбце) и значение в отдельном столбце (исключением является таблица логов, в ней больше полей — подобие журнала событий):
| Имя таблицы | Назначение | Тип данных |
|---|---|---|
| history | Первичные данные мониторинга | numeric(16,4) |
| history_uint | Первичные данные мониторинга | numeric(20,0) |
| history_str | Первичные данные мониторинга | varchar(255) |
| history_text | Первичные данные мониторинга | text |
| history_logs | Первичные данные мониторинга | поля text и int |
| trends | Агрегированные данные мониторинга | numeric(16,4) |
| trends_uint | Агрегированные данные мониторинга | numeric(20,0) |
Оптимизационные мероприятия
Для повышения производительности БД PostgreSQL были проведены различные оптимизационые мероприятия, основными из которых являются партиционирование и изменение индексов. Однако стоит упомянуть парой слов ещё о нескольких важных и полезных мероприятиях, способных ускорить работу любой БД под СУБД PostgreSQL.
Важное замечание. На момент сбора материала статьи нами использовался Zabbix версии 4.0, хотя сейчас уже вышла версия 4.2 и готовится к выходу версия 4.4. Почему об этом важно упомянуть? Потому что начиная с версии 4.2 Zabbix стал поддерживать специальное мощное расширение для работы с временными рядами TimescaleDB, но пока в экспериментальном режиме: при всех достоинствах использования этого расширения есть мнение, что некоторые запросы стали работать медленнее и имеются пока ещё не решённые проблемы производительности (будут решены в версии 4.4) — прочтите эту статью. В следующей статье планирую написать о результатах нагрузочного тестирования уже с использованием расширения TimescaleDB в сравнении с данным кейсом решений. Версия PostgreSQL использовалась 10, но вся приведённая информация актуальна и для 11 и 12 версий (ждём!).
Поэтому обо всём по порядку:
- настройка конфигурационного файла с помощью утилиты pgtune
- вынесение БД на отдельный физический диск
- партиционирование таблиц истории с помощью pg_pathman
- изменение типов индексов таблиц истории на brin (clock) и btree-gin (itemid)
- сбор и анализ статистики выполнения запросов pg_stat_statements
- настройка параметров мониторинга физических дисков
- аппаратное улучшение производительности
- создание распределённого кластера (материал за рамками данной статьи)
Настройка конфигурационного файла с помощью утилиты pgtune
На самом деле PostgreSQL — довольно легковесная СУБД. Её конфигурационный файл по умолчанию настроен так, чтобы, как говорит мой коллега, «работать даже на кофеварке», т.е. на весьма скромном железе. Поэтому обязательно нужно настраивать PostgreSQL под конфигурацию сервера, учитывая объём памяти, количество процессоров, тип предполагаемого использования БД, тип диска (HDD или SSD) и количество подключений.
Увы, не существует единой формулы настройки всех СУБД, но есть определённые правила и закономерности, подходящие для большинства конфигураций (более тонкая настройка — уже дело рук эксперта). Для упрощения жизни DBA была написана утилита pgtune, которая была дополнена web версией пользователем le0pard — автором интересной и полезной книги по администрированию PostgreSQL.
Пример запуска утилиты в консоли с указанием 100 подключений (у Zabbix требовательная Web админка) под тип приложения «Data warehouses»:
pgtune -i postgresql.conf -o new_postgresql.conf -T DW -c 100
Конфигурационные параметры, которые меняет утилита pgtune, с описанием назначения (значения приведены в качестве примера)
Некоторые полезные параметры конфигурации postgresql
Вынесение БД на отдельный физический диск
Данный пункт не обязателен и скорее является переходным решением на пути к полноценному распределённому кластеру, но знать о такой возможности будет полезно. Для ускорения работы БД можно вынести её на отдельный диск. Мы смонтировали диск целиком в каталог base, где хранятся все БД PostgreSQL, но вообще можно сделать по-другому: создать новый tablesbase и вынести БД (или даже только её часть — таблицы первичных и агрегированных данных мониторинга) в этот tablesbase на отдельный диск.
Пример монтирования
Партиционирование таблиц истории с помощью pg_pathman
Одна из проблем, с которой мы столкнулись при нагрузочном тестировании Zabbix — PostgreSQL не успевает удалять устаревшие данные из БД. С помощью партиционирования можно разбить таблицу на составные части, тем самым уменьшить размер индексов и составных частей супертаблицы, что положительно сказывается на быстродействии БД в целом.
Партиционирование решает сразу две проблемы:
1. ускорение удаления устаревших данных путём удаления целых таблиц
2. дробление индексов под каждую составную таблицу
Для партиционирования в PostgreSQL есть четыре механизма:
1. стандартный constraint_exclusion
2. расширение pg_partman (не путайте с pg_pathman)
3. расширение pg_pathman
4. вручную создавать и поддерживать партиции самим
Наиболее удобным, надёжным и оптимизированным решением для партиционирования, по нашему мнению, является расширение pg_pathman. При таком методе партиционирования планировщик запросов гибко определяет в каких партициях искать данные. Поговаривают, что в 12ой версии PostgreSQL будет отличное партиционирование уже «из коробки».
Таким образом, мы стали писать данные мониторинга за каждый день в отдельную унаследованную таблицу от супертаблицы и удаление устаревших значений параметров стало происходить через удаление сразу всех устаревших таблиц целиком, что гораздо проще для СУБД по трудозатратам. Удаление сделали через вызов пользовательской функции БД как параметр мониторинга Zabbix сервера в 2 часа ночи с указанием допустимого диапазона хранения статистики.
Установка и настройка партиционирования для PostgreSQL 10
Автонастройка удаления устаревших партиций (ахтунг - большая SQL функция)
Изменение типов индексов таблиц истории на brin (clock) и btree-gin (itemid)
Отдельное спасибо пользователю erogov за прекрасный цикл обзорных статей про индексы PostgreSQL. Да и вообще всей команде PostgresPRO. Под впечатлением этих статей мы поигрались с разными типами индексов на таблицах данных мониторинга и пришли к выводу какие типы индексов на каких полях дадут максимальный прирост производительности.
Было замечено, что на всех таблицах данных мониторинга по умолчанию создаётся составной индекс btree(itemid, clock) — он быстрый для поиска, особенно для монотонно упорядоченных значений, но сильно «пухнет» на диске, когда данных много — более 10 млн.
На таблицах почасовой агрегированной статистики по умолчанию вообще создан уникальный индекс, хотя эти таблицы для хранилища данных и уникальность здесь обеспечивается на уровне сервера приложений, а уникальный индекс только замедляет вставку данных.
В ходе тестирования различных индексов было выявлено наиболее удачное сочетание индексов: индекс brin на поле clock и индекс btree-gin на поле itemid для всех таблиц данных мониторинга.
Индекс brin идеально подходит для монотонно возрастающих данных, таких как временная метка факта какого-либо события, т.е. для временных рядов. А индекс btree-gin — это по сути gin индекс над стандартными типами данных, что в целом намного быстрее классического индекса btree т.к. gin индекс не перестраивается в ходе добавления новых значений, а лишь дополняется ими. Индекс btree-gin ставится как расширение к PostgreSQL.
Сравнение скорости выполнения выборок для этой стратегии индексирования и для индексов в БД Zabbix по умолчанию приведён ниже. В ходе нагрузочных тестов мы накопили данные за три дня по трём партициям:
| Имя партиции | Количество строк в МЛН | Размер в МБ |
|---|---|---|
| history_uint_1 | 81.3 | 4119 |
| history_uint_2 | 74.9 | 4426 |
| history_uint_3 | 100.7 | 5387 |
Для оценки результатов выполнялись три вида запросов:
- для одного конкретного параметра itemid данные за последний месяц, по факту три последних дня (всего 1660 записей)
explain analyze select * from history_uint where itemid = 313300
and clock >= extract (epoch from '2019-03-09 00:00:00'::timestamp)::int
and clock <= extract (epoch from '2019-04-09 12:00:00'::timestamp)::int;
- для одного конкретного параметра данные за 12 часов одного дня (всего 649 записей)
explain analyze select * from history_text where itemid = 310650
and clock >= extract (epoch from '2019-04-09 00:00:00'::timestamp)::int
and clock <= extract (epoch from '2019-04-09 12:00:00'::timestamp)::int;
- для одного конкретного параметра данные за один час (всего 61 запись):
explain analyze select count(*) from history_text where itemid = 336540
and clock >= extract (epoch from '2019-04-08 11:00:00'::timestamp)::int
and clock <= extract (epoch from '2019-04-08 12:00:00'::timestamp)::int;
Результаты теста были сведены в таблицу ниже:
| тип индекса | размер в МБ* | запрос 1** в мс | запрос 2** в мс | запрос 3** в мс |
|---|---|---|---|---|
| btree (clock, itemid) | 14741 | 7154.3 | 2205.3 | 1860.4 |
| brin(clock), btree-gin (itemid) | 0.42 и 1329 | 2958.2 | 1820.4 | 102.1 |
** запрос типа 1 — данные за 3 дня, запрос типа 2 — данные за 12 часов, запрос типа 3 — данные за один час
Из сравнительной таблицы видно, что для больших таблиц данных с количеством записей более 100 млн чётко прослеживается, что изменение стандартного составного индекса btree на два индекса brin и btree-gin благотворно отразилось на уменьшении размера индексов и ускорении времени выполнения запросов.
Эффективность индексирования и партиционирования показана ниже на примере запроса добавления новых записей в таблицы history_uint и trends_uint (добавления происходят в среднем по 2000 значений за запрос).
| Таблица | Среднее время запроса до улучшений, мс | Среднее время запроса после улучшений, мс |
|---|---|---|
| trends_uint | 2201.48 | 8.72 |
| trends_uint | 1997.27 | 62.16 |
Обобщая результаты тестов различных конфигураций индексов для таблиц данных мониторинга системы zabbix можно сказать, что подобное изменение стандартного индекса для таблиц данных мониторинга системы zabbix положительно сказывается на быстродействии системы в целом, что сильнее всего ощущается при накоплении объёмов данных в размере от 10 млн. Также не стоит забывать о косвенном эффекте «разбухания» стандартного btree индекса по умолчанию — частые перестроения многогигобайтного индекса приводит к сильной загрузке жёсткого диска (метрика utilization), что в конечном итоге повышает время операций с диском и время ожидания доступа к диску со стороны CPU (метрика iowait).
Но, чтобы индекс btree-gin мог работать с типом данных bigint (in8), которым является столбец itemid, нужно выполнить регистрацию семейства операторов типа bigint для индекса btree-gin.
Регистрация семейства операторов типа bigint для индекса btree-gin
Этот скрипт переразмечает все индексы в БД PostgreSQL для Zabbix с конфигурации по умолчанию на оптимальную конфигурацию, описанную выше.
Для индекса brin для нашего объёма данных при интенсивности в 100 т. параметров в минуту (100 т. в history и 100 т. в history_uint) было замечено, что на таблицах первичных данных мониторинга индекс при размере зоны в 512 страниц работает в два раза быстрее, чем при стандартном размере в 128 страниц, но это индивидуально и зависит от размера таблиц и конфигурации сервера. В любом случае индекс brin занимает очень мало места, а вот скорость его работы может быть чуть-чуть увеличена с помощью тонкой настройки размера зоны, но при условии, что интенсивность потока данных не сильно меняется.
В качестве итога стоит отметить, что существует ограничение, связанное с архитектурой самого Zabbix: на вкладке «Последние данные» собираются по два последних значения для каждого параметра с учётом фильтрации. По каждому параметру значения запрашиваются в БД отдельно. Поэтому чем больше таких параметров будет отобрано, тем дольше будет выполняться запрос. Наиболее быстро последние данные ищутся, когда на таблицах history установлен индекс btree(itemid, clock desc) именно с обратной сортировкой по времени, но при этом сам индекс конечно «пухнет» на диске и в целом косвенно замедляет работу с БД, что вызывает проблему, описанную выше.
Поэтому есть три выхода из положения:
- выполнить описанные выше манипуляции с индексами и стараться не отбирать во вкладке «Последние данные» значения одновременно для более чем 100 параметров (т.е. смириться с тем, что данные на вкладке «Последние данные» будут появляться немного медленнее)
- переделать механизм внутри сервера Zabbix так, чтобы последние два значения для всех параметров писались по триггеру ещё в отдельную таблицу с двумя последними значениями, откуда и возвращались бы на запросы для отрисовки вкладки «Последние данные»
- оставить индексы так, как они есть по умолчанию, и ограничиться только партиционированием чтобы получать довольно большие выборки на вкладке «Последние данные» одновременно по множеству параметров (однако было замечено, что у web-сервера Zabbix всё равно есть ограничение на количество одновременно отображаемых значений параметров на вкладке «Последние данные» — так, при попытке отобразить 5000 значений БД вычислила результат, но сервер не смог подготовить web-страницу и отобразить такой большой объём данных).
Сбор и анализ статистики выполнения запросов pg_stat_statements
Pg_stat_statements — расширение для сбора статистики выполнения запросов в рамках всего сервера. Преимущество данного расширения в том, что ему не требуется собирать и парсить логи PostgreSQL.
Использование расширения pg_stat_statements
Настройка параметров мониторинга физических дисков
Для мониторинга жёстких дисков в Zabbix из коробки предусмотрены только параметры vfs.dev.read и vfs.dev.write. Эти параметры не дают информации о загруженности дисков. Полезными критериями для поиска проблем с производительностью жёстких дисков являются показатели коэффициента загруженности utilization, время выполнения запроса await и загруженность очереди запросов к диску.
Как правило высокая загруженность диска коррелирует с высоким iowait самого cpu и с ростом времени выполнения sql запросов, что и было установлено при нагрузочном тестировании zabbix сервера со стандартной конфигурацией без партиционирования и без настройки альтернативных индексов. Добавить эти параметры мониторинга жёстких дисков можно с помощью следующих действий, которые были подсмотрены в статье у товарища lesovsky и улучшены: теперь параметры iostat собираются отдельно по каждому диску в json временный параметр, откуда по настройках постобработки уже раскладываются в конечные параметры мониторинга.
Пока Pull request ожидает на рассмотрении, вы можете попробовать развернуть мониторинг параметров дисков по подробной инструкции через мой fork.
После всех описанных действий можно добавить на главную панель мониторинга сервера Zabbix кастомный график с iowait cpu и параметрами utiliztion для системного диска и диска с БД (если они разные). Результат может выглядеть так (sda — основной диск, sdc — диск с БД):
Аппаратное улучшение производительности
После настройки СУБД, индексирования и партиционирования можно приступить к вертикальному масштабированию — улучшить аппаратные характеристики сервера: добавить оперативной памяти, поменять накопители на твёрдотельные и добавить процессорных ядер. Это гарантированный прирост производительности, но лучше это сделать только после программной оптимизации.
Создание распределённого кластера
После умеренного вертикального масштабирования нужно приступать к горизонтальному — создавать распределённый кластер: делать либо шардирование, либо репликации мастер-слейв. Но это уже отдельная тема и материал отдельной статьи
А пока остаётся надеяться, что материал данной статьи оказался полезным и познавательным!
Источник статьи: https://habr.com/ru/post/468463/