Меня зовут Дима, я занимаюсь тестированием безопасности операционной системы Astra Linux в группе компаний «Астра». Наша команда проводит различные виды проверки программного обеспечения, такие как:
В статье рассматривается лишь небольшая часть огромной работы, проводимой ГК «Астра» по фаззинг-тестированию. Вы узнаете о способах его реализации, инструментах и возможности применять данный вид тестирования в своих проектах.
В данном документе описаны процессы и действия, которые необходимо исполнять на различных этапах жизненного цикла ПО, чтобы на выходе разработанное ПО было защищено по меньшей мере от уже известных мировому сообществу уязвимостей и логических ошибок в коде программы, которые могут привести к различным угрозам той информационной системы, в которой будет функционировать разработанная программа. Одной из мер по созданию безопасного ПО как раз является фаззинг-тестирование. Суть его — в подаче на вход программы случайных данных с целью выявления нештатного поведения.
Чтобы соответствовать первому (наивысшему) уровню доверия, регламентированного документом «Требования по безопасности информации, устанавливающие уровни доверия к средствам технической защиты информации и средствам обеспечения безопасности информационных технологий» (утв. Приказом № 76 ФСТЭК России), наша компания на постоянной основе проводит тестирование в соответствие с методикой выявления уязвимостей и недекларированных возможностей в программном обеспечении (разработана и утверждена 25 декабря 2020).
А что, собственно, будем выявлять? Любой человек, немного знакомый с тестированием, скажет «баги», но это не совсем так. Баги могут быть безобидными, а могут—опасными. Поэтому в процессе фаззинг-тестирования предельно важно выявлять именно опасные баги, или говоря официально — ошибки, способные приводить к реализациям угроз безопасности информации, обрабатываемой в информационных системах. Более подробно данные термины описаны в ГОСТе Р 56546-2015 (ну и, Википедию никто не отменял).
Для проведения работ нам понадобится:
Для запуска сrusher достаточно наличия директории с входными данными (и присутствия в ней самих входных данных) и директории с выходными данными — её контент создаётся автоматически при запуске тестирования, там будут лежать папки с мутационными данными, исключениями и аварийными завершениями. Итак, начнём подготовку начальных данных. Не будем лезть очень глубоко, в нашем случае достаточно будет вызвать в терминале необходимую программу и запросить её функционал. В качестве примера возьмём программу signtool, с помощью флага «-h» посмотрим существующую функциональность программы и сделаем выводы о формате входных данных программы.
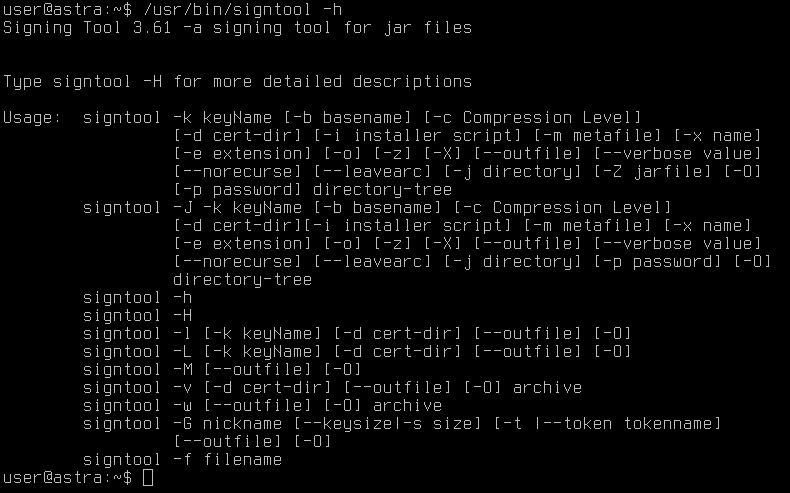
Забираем все флаги и создаём файлы (для каждого флага отдельный файл), на основе которых будут происходить генерационные преобразования. Если необходимо тестировать собственную программу, то тут всё зависит от того, что и как она должна получать на вход и обрабатывать.
Для чего нужны начальные данные, если фаззер генерирует абсолютно случайные данные? Они позволяют задействовать максимальное количество функций, что приводит к увеличению покрытия кода. Проще говоря, это даёт возможность заглянуть во все тайные углы программы. Для максимального покрытия кода нужно: настроить тестируемое ПО (как это задумано разработчиками), подготовить все возможные начальные данные и предоставить фаззеру много времени для мутации данных. Также можно тестировать отдельные функции ПО, выводя их из состава программы.
Что касается времени на проведение фаззинг-тестирования, то оно может варьироваться от одной минуты (в некотором ПО падения могут появиться сразу) до бесконечности. Примером может служить Google, выделившая ресурсы на непрерывный фаззинг браузера Chrome. После подготовки начальных данных надо создать для удобства каталог тестирования, в который и поместить начальные данные.
Запускаем тестирование с помощью команды:
путь/к/crusher/bin_x86-64/fuzz_manager -i <inputs dir> -o <results dir> -T Argv --start <num> --/usr/bin/programm __DATA__
Для большей наглядности перейдём в новое окно терминала и запустим графическое отображение информации. Для этого используем команду:
crusher/bin_x86-64/ui --outdir <path>
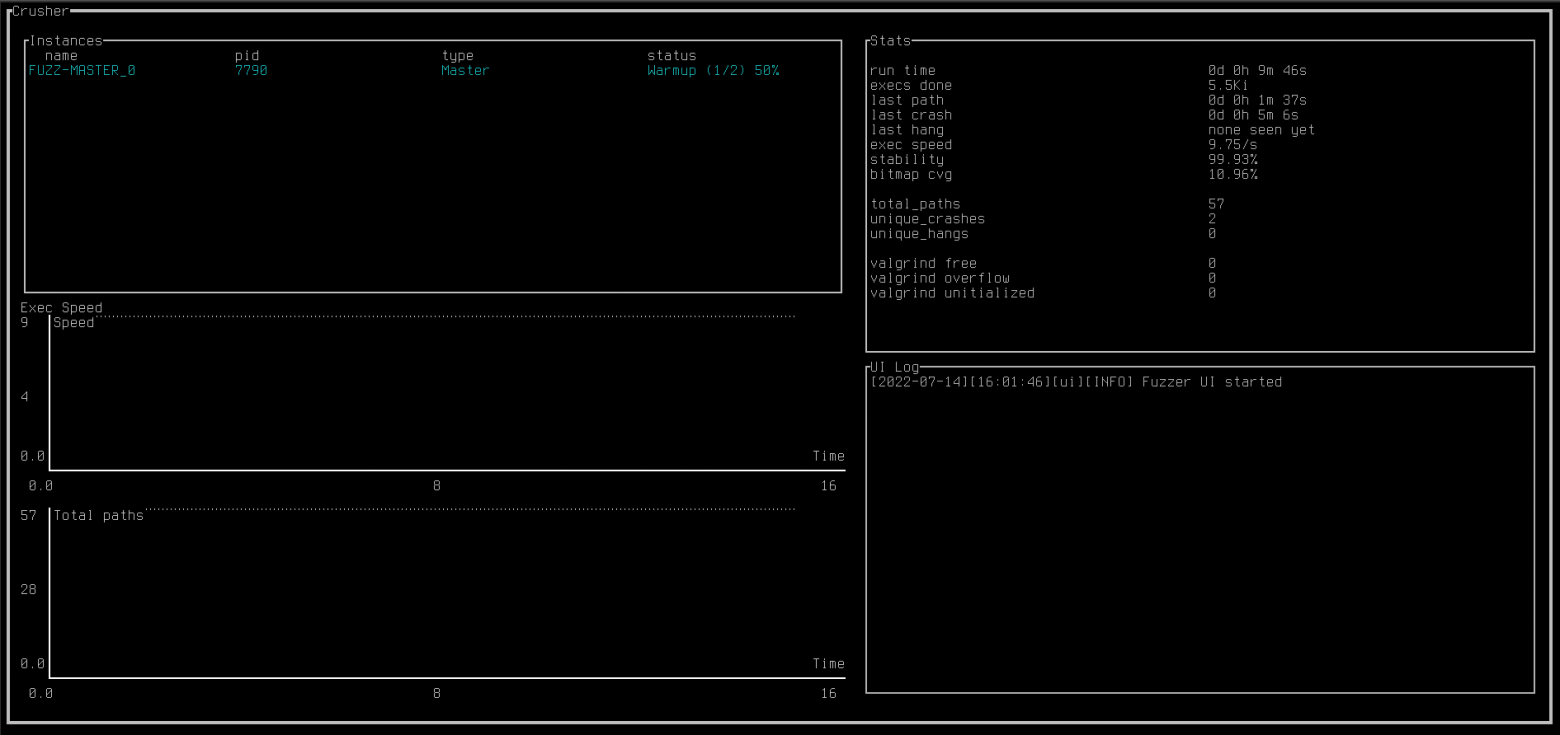
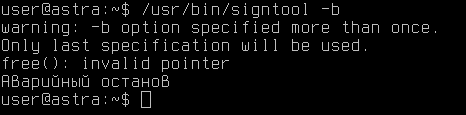
Спустя всего 8 минут мы нашли ошибку (видно на картинке сверху «uniqe_crashes»). Хоть прошло немного времени, но для примера нам хватит, так что завершим тестирование. Перейдём к самой ошибке. Подавая только флаг «-b», у нас происходит аварийное завершение приложения.
Для быстрого поиска ошибки начинаем собирать пакет, заходим в директорию с исходниками. Видим файл «build.sh», запускаем его для конфигурации пакета (команда для запуска «./build.sh»).

Следующая команда «make» для сборки пакета. Но не всё так однозначно. Во время выполнения сборки появилась ошибка:

Для её исправления необходимо установить gcc-multilib (Этот пакет есть в официальном репозитории Astra Linux, просто выполним команду: «sudo apt-get install gcc-multilib»). Выполняем «make clean», затем «make», но нам опять вылетает ошибка:

При сборке не находится файл «nspr.h», хотя он установлен в системе. Ничего страшного, пропишем путь до него вручную и укажем, что у нас 64-битная система. Снова «make clean» и затем «make USE_64=1 C_INCLUDE_PATH=/usr/include/nspr/ CPLUS_INCLUDE_PATH=/usr/include/nspr/». На этот раз успех.
Для работы с кодом в vscode установим расширение С/С++(как на картинке ниже), а на саму систему поставим gdb (sudo apt install gdb).
Для нашей задачи это самый оптимальный и удобный вариант.

Можно работать и в консольном gdb, но это не очень удобно, да и в vscode всё намного наглядней. Открываем в терминале проект, в нашем случае это nss, не выходя из исходников, вводим команду «code .». Потом переходим в окно отладки и добавляем вот такую конфигурацию: «(gdb) Запустить».
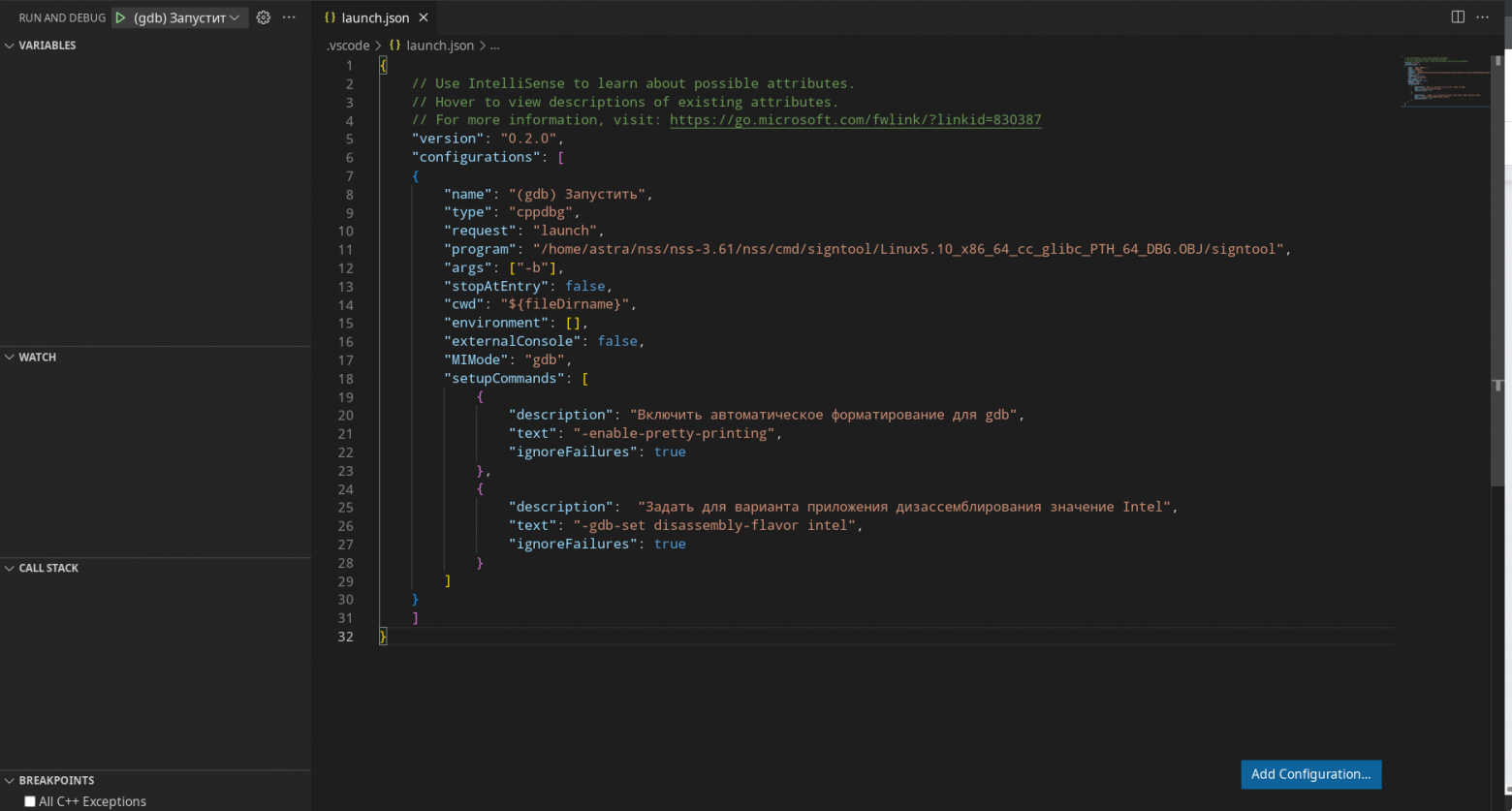
Там будет json-файл, в котором прописываем путь к программе в поле «program» и аргументы в поле «args». Жмём запуск и смотрим, что на выходе.
Подробное описание ошибки выходит за рамки статьи, но кратко пробегусь по ней. Для начала запустим наш проект (зелёный треугольник). После запуска видим такую картину.

Ошибка происходит при попытке высвобождении памяти (функция «PR_free()» ), поставим точку и посмотрим, что лежит в переменной «base».
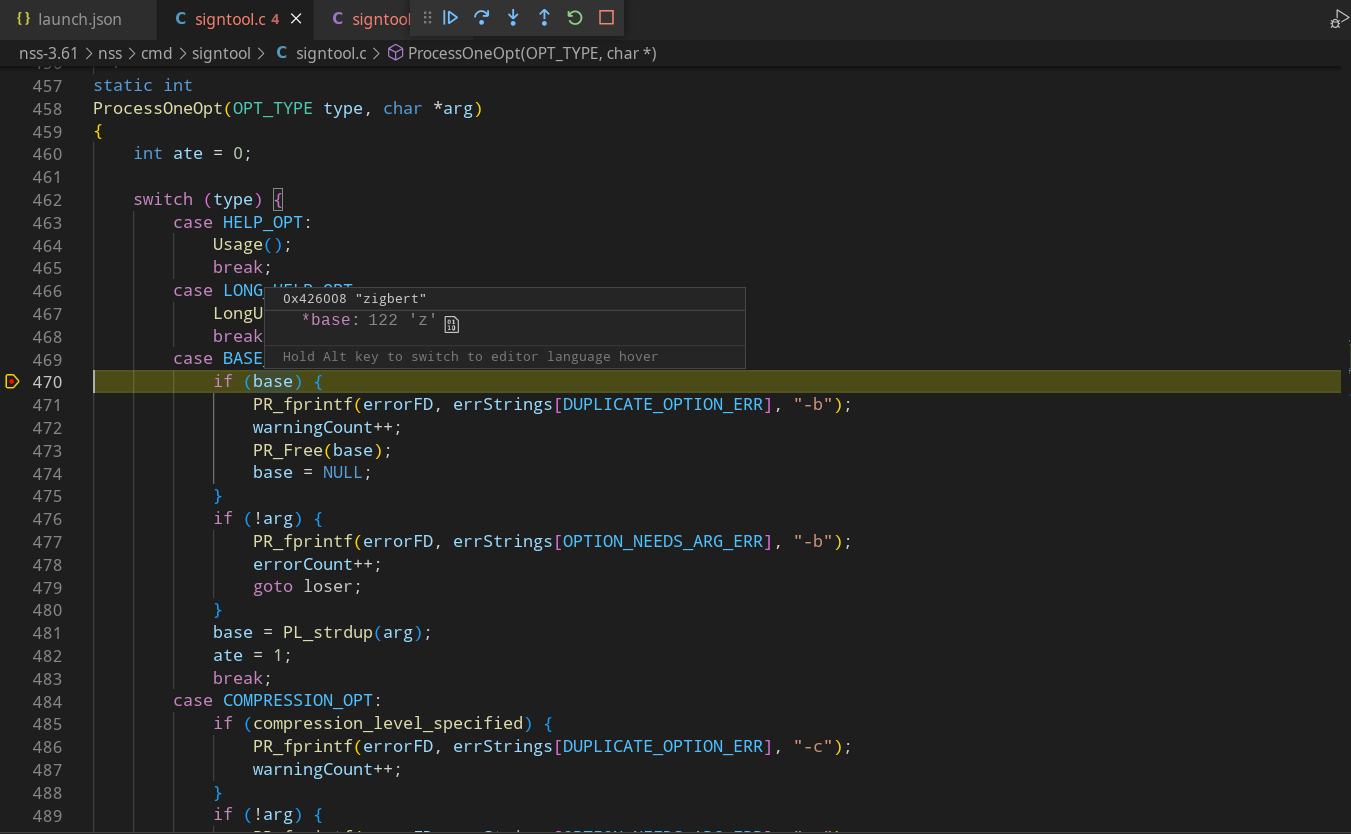
Первое предположение, что base — пустой, отметается сразу, так как в условие «if(base)» мы заходим (на снимке это видно). Тогда найдём, как задаётся эта переменная. Сперва видим «char *base = DEFAULT_BASE_NAME;», смотрим дальше. Находим «#define DEFAULT_BASE_NAME "zigbert"», а вот и предполагаемая ошибка. Память для строковой переменной «base» выделяется не в куче — соответственно, использование функции «PR_free()», которая является функцией-обёрткой для «free()», не рекомендуется, так как происходит Aborted. Серьёзной угрозы данная ошибка не представляет, но исправить её необходимо, поэтому о данной ошибке я сообщил разработчикам данного ПО (сделал багрепорт в Mozilla). Такие багрепорты по результатам проверок отправляются регулярно и достаточно оперативно правятся, как, например, ранее выявленный баг и уже исправленный в cups: https://github.com/OpenPrinting/cups/issues/457.
Итак, мы рассмотрели маленький пример поиска недостатков кода, немного познакомились с фаззинг-тестированием и инструментом Crusher. Спасибо за внимание!

 habr.com
habr.com
- статический и динамический анализ кода ПО;
- поиск уязвимостей в ПО;
- фаззинг-тестирование;
- отслеживание помеченных данных;
- антивирусный контроль;
- тестирование на проникновение;
- функциональное тестирование.
В статье рассматривается лишь небольшая часть огромной работы, проводимой ГК «Астра» по фаззинг-тестированию. Вы узнаете о способах его реализации, инструментах и возможности применять данный вид тестирования в своих проектах.
Нормативно-правовая часть
Итак, прежде чем переходить к практике, надо разобраться с теоретической частью нашей темы. В мире существует ряд практик по так называемой «разработке безопасного программного обеспечения». В нашей стране в этой сфере всё популярнее становятся практики, базирующиеся на ГОСТ Р 56939-2016.В данном документе описаны процессы и действия, которые необходимо исполнять на различных этапах жизненного цикла ПО, чтобы на выходе разработанное ПО было защищено по меньшей мере от уже известных мировому сообществу уязвимостей и логических ошибок в коде программы, которые могут привести к различным угрозам той информационной системы, в которой будет функционировать разработанная программа. Одной из мер по созданию безопасного ПО как раз является фаззинг-тестирование. Суть его — в подаче на вход программы случайных данных с целью выявления нештатного поведения.
Чтобы соответствовать первому (наивысшему) уровню доверия, регламентированного документом «Требования по безопасности информации, устанавливающие уровни доверия к средствам технической защиты информации и средствам обеспечения безопасности информационных технологий» (утв. Приказом № 76 ФСТЭК России), наша компания на постоянной основе проводит тестирование в соответствие с методикой выявления уязвимостей и недекларированных возможностей в программном обеспечении (разработана и утверждена 25 декабря 2020).
А что, собственно, будем выявлять? Любой человек, немного знакомый с тестированием, скажет «баги», но это не совсем так. Баги могут быть безобидными, а могут—опасными. Поэтому в процессе фаззинг-тестирования предельно важно выявлять именно опасные баги, или говоря официально — ошибки, способные приводить к реализациям угроз безопасности информации, обрабатываемой в информационных системах. Более подробно данные термины описаны в ГОСТе Р 56546-2015 (ну и, Википедию никто не отменял).
Об инструменте
Закончили с теорией, переходим к практике. Мы будем использовать инструмент Crusher. Существуют и другие популярные инструменты для проведения фаззинг-тестирования. Например, AFL, но про них уже много информации в Сети. Crusher является инструментом для фаззинг-тестирования, разработанным Институтом системного программирования РАН им. В. П. Иванникова.Для проведения работ нам понадобится:
- операционная система Astra Linux (российский дистрибутив);
- инструмент тестирования Crusher (на момент написания статьи директор ИСП РАН принял решение о предоставление бесплатных лицензий на их инструменты сроком на полгода);
- программа, которую будем тестировать.
Запуск тестирования
В инструкции к Crusher есть указания, как начинать фаззинг. Там нет ничего необычного. Есть небольшая трудность только с первоначальным запуском из-за особенностей настройки безопасности Astra Linux. Из коробки в ОС включена блокировка трассировки ptrace. Работает одно из встроенных средств защиты информации. Для его отключения переходим в терминал и прописываем «astra-ptrace-lock disable», далее проверяем, что всё прошло успешно командой «systemctl is-enabled astra-ptrace-lock». Должно появиться сообщение «disabled», накидываем бит исполнения («sudo chmod +x») на файл запуска сrusher, перезапускаемся и по части операционной системы мы готовы.Для запуска сrusher достаточно наличия директории с входными данными (и присутствия в ней самих входных данных) и директории с выходными данными — её контент создаётся автоматически при запуске тестирования, там будут лежать папки с мутационными данными, исключениями и аварийными завершениями. Итак, начнём подготовку начальных данных. Не будем лезть очень глубоко, в нашем случае достаточно будет вызвать в терминале необходимую программу и запросить её функционал. В качестве примера возьмём программу signtool, с помощью флага «-h» посмотрим существующую функциональность программы и сделаем выводы о формате входных данных программы.
Забираем все флаги и создаём файлы (для каждого флага отдельный файл), на основе которых будут происходить генерационные преобразования. Если необходимо тестировать собственную программу, то тут всё зависит от того, что и как она должна получать на вход и обрабатывать.
Для чего нужны начальные данные, если фаззер генерирует абсолютно случайные данные? Они позволяют задействовать максимальное количество функций, что приводит к увеличению покрытия кода. Проще говоря, это даёт возможность заглянуть во все тайные углы программы. Для максимального покрытия кода нужно: настроить тестируемое ПО (как это задумано разработчиками), подготовить все возможные начальные данные и предоставить фаззеру много времени для мутации данных. Также можно тестировать отдельные функции ПО, выводя их из состава программы.
Что касается времени на проведение фаззинг-тестирования, то оно может варьироваться от одной минуты (в некотором ПО падения могут появиться сразу) до бесконечности. Примером может служить Google, выделившая ресурсы на непрерывный фаззинг браузера Chrome. После подготовки начальных данных надо создать для удобства каталог тестирования, в который и поместить начальные данные.
Запускаем тестирование с помощью команды:
путь/к/crusher/bin_x86-64/fuzz_manager -i <inputs dir> -o <results dir> -T Argv --start <num> --/usr/bin/programm __DATA__
- --start <num> — количество ядер для менеджера фаззера;
- -i <inputs dir> — путь к директории с входными данными;
- -o <results dir> — путь к директории с выходными данными
- -T Argv — тип подаваемых данных
- __DATA__ — сюда будут подставляться входные данные
Для большей наглядности перейдём в новое окно терминала и запустим графическое отображение информации. Для этого используем команду:
crusher/bin_x86-64/ui --outdir <path>
- --outdir <path> — путь к директории с выходными данными
Спустя всего 8 минут мы нашли ошибку (видно на картинке сверху «uniqe_crashes»). Хоть прошло немного времени, но для примера нам хватит, так что завершим тестирование. Перейдём к самой ошибке. Подавая только флаг «-b», у нас происходит аварийное завершение приложения.
Обработка ошибки
Итак, мы нашли, на каких данных программа ведёт себя нештатно. Далее переходим к разбору данной ошибки. Для этого воспользуемся vscode и исходными текстами нашего ПО (инструмент signtool входит в пакет nss).Для быстрого поиска ошибки начинаем собирать пакет, заходим в директорию с исходниками. Видим файл «build.sh», запускаем его для конфигурации пакета (команда для запуска «./build.sh»).
Следующая команда «make» для сборки пакета. Но не всё так однозначно. Во время выполнения сборки появилась ошибка:
Для её исправления необходимо установить gcc-multilib (Этот пакет есть в официальном репозитории Astra Linux, просто выполним команду: «sudo apt-get install gcc-multilib»). Выполняем «make clean», затем «make», но нам опять вылетает ошибка:
При сборке не находится файл «nspr.h», хотя он установлен в системе. Ничего страшного, пропишем путь до него вручную и укажем, что у нас 64-битная система. Снова «make clean» и затем «make USE_64=1 C_INCLUDE_PATH=/usr/include/nspr/ CPLUS_INCLUDE_PATH=/usr/include/nspr/». На этот раз успех.
Для работы с кодом в vscode установим расширение С/С++(как на картинке ниже), а на саму систему поставим gdb (sudo apt install gdb).
Для нашей задачи это самый оптимальный и удобный вариант.
Можно работать и в консольном gdb, но это не очень удобно, да и в vscode всё намного наглядней. Открываем в терминале проект, в нашем случае это nss, не выходя из исходников, вводим команду «code .». Потом переходим в окно отладки и добавляем вот такую конфигурацию: «(gdb) Запустить».
Там будет json-файл, в котором прописываем путь к программе в поле «program» и аргументы в поле «args». Жмём запуск и смотрим, что на выходе.
Подробное описание ошибки выходит за рамки статьи, но кратко пробегусь по ней. Для начала запустим наш проект (зелёный треугольник). После запуска видим такую картину.
Ошибка происходит при попытке высвобождении памяти (функция «PR_free()» ), поставим точку и посмотрим, что лежит в переменной «base».
Первое предположение, что base — пустой, отметается сразу, так как в условие «if(base)» мы заходим (на снимке это видно). Тогда найдём, как задаётся эта переменная. Сперва видим «char *base = DEFAULT_BASE_NAME;», смотрим дальше. Находим «#define DEFAULT_BASE_NAME "zigbert"», а вот и предполагаемая ошибка. Память для строковой переменной «base» выделяется не в куче — соответственно, использование функции «PR_free()», которая является функцией-обёрткой для «free()», не рекомендуется, так как происходит Aborted. Серьёзной угрозы данная ошибка не представляет, но исправить её необходимо, поэтому о данной ошибке я сообщил разработчикам данного ПО (сделал багрепорт в Mozilla). Такие багрепорты по результатам проверок отправляются регулярно и достаточно оперативно правятся, как, например, ранее выявленный баг и уже исправленный в cups: https://github.com/OpenPrinting/cups/issues/457.
Итак, мы рассмотрели маленький пример поиска недостатков кода, немного познакомились с фаззинг-тестированием и инструментом Crusher. Спасибо за внимание!
Фаззинг по-русски на практике: crusher, Astra Linux
Вступление Привет, Хабр! Меня зовут Дима, я занимаюсь тестированием безопасности операционной системы Astra Linux в группе компаний «Астра». Наша команда проводит различные виды проверки программного...
habr.com