Предыстория
Понадобилось мне для одного проекта, о котором хотелось бы отдельно написать через недельку, узнать частотность (как базовую, так и парную) буквенных символов в русском и английском языках.Побродив по бескрайним просторам интернета, я с удивлением обнаружил, что исследований на такую базово простую, и в то же время локально востребованную тему преступно мало. Их буквально можно пересчитать по пальцам.
Для английского языка было найдено 12 более или менее достоверных анализов для базовой символьной частотности, из которых только 3 обладают внушительными базовыми выборками, и 5 биграммных анализов (парная частотность), из которых внушительной выборкой могут похвастать лишь 2.
Для русского и того меньше – 7 анализов базовой частотности, из которых 3 без указанного значения выборки, остальные же в пределах х×106 символов. Биграммных – 3, один из которых сделан по единственной книге «Преступление и наказание», а второй на 5.000 символов.
Несложно догадаться, как обстоит дело с менее популярными языками.
Здесь может возникнуть закономерный вопрос – "А зачем нам нужна эта куча анализов? Уже ведь есть значения, чего уж более". Но нет. Основываться на единственной выборке в данном случае нельзя. Значения могут (и будут) разниться от целой кучи факторов, таких как предметная область (к примеру – тексты Хабра с вкраплениями кода и популярное газетное издание покажет весьма разные значения), веяния времени (годы создания), личный стиль автора (в случае выборок по единственному автору), диалект и прочие. К слову, сравнение частотностей разных выборок может представить отдельный интерес для некоторых лингвистов, диалектологов, а может и послужить материалом для студенческих или даже кандидатских работ, почему бы и нет?
Для моих же целей мне понадобилось идеальное среднее в вакууме, поэтому все эти анализы, пусть и малочисленные, я собрал вместе. Но так как этого было мало, я решил дополнить их собственными анализами.
Интернет, при поиске готовых пакетов на Python, куда можно было бы просто сгрузить выборку и получить интересующий меня результат ничего не выдал, что также, как мне кажется, вносит свой вклад в малочисленность анализов. Были различные одноразовые 50-строчники в ответах на сервисах рода stackoverflow, но это вряд ли можно назвать серьёзным решением, и их применимость на крупных выборках также вызывает сомнения.
Такая предыстория у небольшого пакета frequency-analysis. Результирующий пакет вышел небольшим и простеньким, но свои цели он выполняет полностью.
Пакет
Пакет максимально прост как в понимании, так и в использовании – он собирает всего 4 типа данных для 4 типов элементов:Данные – общее количество, количество в первой позиции, количество в последней позиции, средняя позиция;
Элементы – символы, символьные биграммы, слова, биграммы слов.
Все эти данные сохраняются в sqlite db, а после могут быть переведены в наглядный excel файл, из которого впоследствии могут быть использованы где-угодно.
Пример анализа
Самым сложным этапом будет поиск доступного к скачиванию корпуса для анализа. Большая часть из них закрыта, и в лучшем случае предоставляет собственное API для работы с ним.Для своих анализов я воспользовался корпусами http://opencorpora.org/ и http://www.euromatrixplus.net/multi-un/ для русского и английского языков, соответственно.
Установим пакет привычным способом:
> pip install frequency-analysis
Теперь нам нужно распарсить данные и скормить их пакету-топикстартеру.
Для первой цели мы будем использовать bs4, а так как наши данные в .xml формате, нам понадобится вспомогательная библиотека lxml:
> pip install beautifulsoup4 lxml
Для конечного пользователя в пакете frequency-analysis доступны два класса – Analysis и Result, оба реализованы через контекстный менеджер.
Сейчас нас интересует первый, для выполнения самого анализа. Класс Analysis имеет 5 опциональных аргументов:
- name – имя, в папке с которым будет сохранён анализ. Базовое значение – 'frequency_analysis';
- mode – режим выполнения анализа. 3 варианта:
- 'n' – (базовое значение) создаётся новый анализ, если файлы, относящиеся к анализу с таким же именем, уже присутствуют – ошибка;
- 'a' – дополнить имеющийся анализ новыми данными;
- 'c' – продолжить прошлый анализ. Если анализ был прерван, в этом режиме можно передать старую выборку (обязательно включая уже пройденный объём!), и анализ продолжится с места прерывания.
- word_pattern – regex паттерн для определения "внутрисловных" символов. С его помощью выполняется очистка слов от лишних элементов и происходит "относительный" учёт позиций символов. Базовое значение – вся базовая латиница, русская кириллица, на не крайних позициях допустим один дефис или одна кавычка-апостроф. Чуть монструозный regex вид:
 ?:-?[a-zA-Zа-яА-ЯёЁ]+)+|\'?[a-zA-Zа-яА-ЯёЁ]+)|[a-zA-Zа-яА-ЯёЁ]'
?:-?[a-zA-Zа-яА-ЯёЁ]+)+|\'?[a-zA-Zа-яА-ЯёЁ]+)|[a-zA-Zа-яА-ЯёЁ]'- allowed_symbols – символы, которые будут учтены для непосредственно символьного анализа. Список может быть передан как обычной строкой, так и списком десятичных unicode–значений символов. Базовое значение – вся базовая латиница, русская кириллица, базовая пунктуация ('[*range(32, 127), 1025, *range(1040, 1104), 1105]');
- yo – булевый тип, отвечает за небольшой сверх-функционал
для холиваров на тему "е или ё"– при создании анализа из вспомогательных текстовых файлов собираются слова с заведомо и с потенциально ошибочным написанием через "е". Реализация "в лоб" – без анализа языковых единиц, без словоформ, просто список отдельных слов. На этапе создания результатов анализа счётчики для обоих вариантов всех этих слов могут быть отдельно отображены. Базовое значение – False.
Важный момент – для корректного подсчёта позиций слов в предложении, в методы класса необходимо передавать по одному предложению на вызов.
Методов в классе всего три – для подсчёта символов count_symbols(), для подсчёта слов count_words() и комбинированный, для подсчёта всего count_all().
Принимаемые аргументы:
- word_list – наш список (type: list) слов. Как обозначено выше, желательно, чтобы он содержал только одно высказывание/предложение на каждый вызов метода;
- pos – опциональный булевый аргумент с базовым значением False. Определяет, будет ли выполняться подсчёт средних позиций элемента. На моей машине анализ с включённым аргументом занял на ≈13% больше времени;
- bigrams – опциональный булевый аргумент с базовым значением True. Определяет, будет ли выполняться подсчёт биграмм. На моей машине анализ с включённым аргументом занял на ≈35% больше времени. Если для вашего анализа вам не нужны биграммные значения, вы можете отключить их подсчёт.
- count_all() вместо одного аргумента bigrams принимает два – symbol_bigrams и word_bigrams, соответственно.
import io
from os import listdir
from bs4 import BeautifulSoup
import frequency_analysis
file_list = listdir('annot_opcorpora_xml_byfile/')
with frequency_analysis.Analysis(yo=True) as analyze:
for n, file in enumerate(file_list):
with io.open('annot_opcorpora_xml_byfile/' + file, mode='r', encoding='utf-8') as f:
data = f.read()
bs_data = BeautifulSoup(data, 'xml')
for sentence in bs_data.find_all('source'):
analyze.count_all(sentence.text.split(), pos=True)
Добавим немного print'ов, для наглядности:
from datetime import datetime
...
with frequency_analysis.Analysis(yo=True) as analyze:
for n, file in enumerate(file_list):
...
print(n, file)
print('fin at:', datetime.now().strftime('%H:%M:%S'))
print('total time taked to analysis:', datetime.now() - start)
Аналогично для английского корпуса. Здесь изменением будет удаление кириллицы из аргументов word_pattern и allowed_symbols, возврат к стандартному значению yo (False) и, конечно, парсинг по тегам, определённых форматом данного корпуса.
import io
from datetime import datetime
from os import listdir
from bs4 import BeautifulSoup
import frequency_analysis
start = datetime.now()
file_list = listdir('multiUN/')
word_pattern = '[a-zA-Z]+(?
?:-?[a-zA-Z]+)+|\'?[a-zA-Z]+)|[a-zA-Z]'allowed_symbols = [*range(32, 127)]
with frequency_analysis.Analysis(
word_pattern=word_pattern, allowed_symbols=allowed_symbols
) as analyze:
for n, file in enumerate(file_list):
with io.open('multiUN/' + file, mode='r', encoding='utf-8') as f:
data = f.read()
bs_data = BeautifulSoup(data, 'xml')
for sentence in bs_data.find_all('s'):
analyze.count_all(sentence.text.split(), pos=True)
print(n, file)
print('fin at:', datetime.now().strftime('%H:%M:%S'))
print('total time:', datetime.now() - start)
Готово. Наши данные собираются в соответствующие result.db. Время анализа зависит от объёма анализируемого корпуса, параметров анализа (подсчёт биграмм, средних позиций) и локальных особенностей. У меня анализы русского и английского корпусов с максимальными параметрами заняли 30мин и 1.5д соответственно, при базовом .xml объёме в 520Mb и 3Gb (или, более корректно, в 1.58М и 380М слов). Позже мы можем дополнить эти данные, извлечь вручную, или воспользоваться вторым классом обсуждаемого пакета – Result, для вывода в наглядный excel вид.
Класс Result имеет всего один опциональный параметр – name, который должен содержать имя папки с имеющимся анализом, и очевидно, совпадать по значению с аналогичным аргументом из класса Analysis для того же анализа.
А вот методов у этого класса уже поболее – 9 основных, 4 метода упрощённого вызова и 1 метод быстрого вызова 6 из основных. Каждый из основных методов отвечает за создание своего листа в excel файле.
Многие методы принимают в качестве опциональных аргументов параметры limit, chart_limit, min_quantity и ignore_case, поэтому стоит рассказать о них сейчас, дабы потом не повторяться:
- limit – максимальное количество соответствующих элементов для добавления на лист. 0 – неограниченно. Базовое значение – 0;
- chart_limit – листы формата "топ по частоте" содержат круговые диаграммы. Данный аргумент определяет количество первых n элементов, на основе которых будет построена диаграмма. Базовое значение – 20;
- min_quantity – минимальное количество включений самого элемента в анализе, с которым он может быть добавлен на лист. Базовое значение – 1;
- ignore_case – булевый аргумент, отвечающий за объединение символов или символьных биграмм разных регистров в единый элемент или их раздельный учёт, где это имеет смысл. Базовое значение – False. Keyword-only.
Методы:
- sheet_stats()
- базовая информация об анализе – количество уникальных элементов каждого типа, количество их вхождений, их средние позиции;
- sheet_top_symbols([limit, chart_limit, min_quantity])
- топ-лист всех символов, включённых в анализ (здесь и далее – со всеми их данными);
- sheet_top_symbol_bigrams([limit, chart_limit, min_quantity])
- топ-лист всех символьных биграмм;
- sheet_top_words([limit, chart_limit, min_quantity])
- топ-лист всех слов;
- sheet_top_word_bigrams([limit, chart_limit, min_quantity])
- топ-лист всех биграмм слов;
- sheet_all_symbol_bigrams([min_quantity])
- 2D-лист всех символьных биграмм (данные в виде комментариев к ячейкам выглядят не очень, но дают быстрый доступ к данным по конкретной паре);
- treat([limits, chart_limits, min_quantities])
- единый вызов всех методов выше;
- аргументы метода – кортежи из 4,4,5 элементов соответственно. Порядок значений в аргументах аналогичен порядку описания методов выше;
- sheet_custom_top_symbols(symbols: str, [chart_limit, name: str])
- топ-лист выбранных символов. Базовое значение name (пользовательское название листа) – 'Custom top symbols'. name – keyword-only;
- sheet_en_top_symbols([chart_limit])
- топ-лист символов базовой латиницы. Частный случай предыдущего метода с предопределённым набором символов и названием листа;
- sheet_ru_top_symbols([chart_limit])
- топ-лист символов русской кириллицы. Аналогично предыдущему;
- sheet_custom_symbol_bigrams(symbols: str, [ignore_case, name: str])
- 2D-лист выбранных символов. Порядок символов сохраняется с пользовательского ввода. Базовое значение name (пользовательское название листа) – 'Custom symbol bigrams'. name – keyword-only;
- sheet_en_symbol_bigrams([ignore_case])
- 2D-лист символов базовой латиницы. Частный случай предыдущего метода с предопределённым набором символов и названием листа;
- sheet_ru_symbol_bigrams([ignore_case])
- 2D-лист символов русской кириллицы. Аналогично предыдущему;
- sheet_yo_words([limit, min_quantity])
- топ-лист всех слов с обязательной/потенциальной "ё", со значениями использования обоих вариантов и общим итогом. Доступен только для русскоязычных анализов, выполненных с аргументом yo=True.
Для русскоязычного анализа:
import frequency_analysis
with frequency_analysis.Result() as res:
res.treat(limits=(1000,) * 4, chart_limits=(20,) * 4, min_quantities=(10,) * 5)
res.sheet_ru_top_symbols()
res.sheet_ru_symbol_bigrams()
# просто демонстрация. На деле проще использовать sheet_ru_symbol_bigrams(ignore_case=True)
ru_symbs = 'абвгдеёжзийклмнопрстуфхцчшщьыъэюя'
res.sheet_custom_symbol_bigrams(ru_symbs, ignore_case=True, name='Russian letter bigrams')
res.sheet_yo_words()
Для англоязычного анализа:
from string import ascii_letters
import frequency_analysis
with frequency_analysis.Result() as res:
res.treat(limits=(1000,) * 4, chart_limits=(20,) * 4, min_quantities=(10,) * 5)
res.sheet_en_top_symbols()
res.sheet_en_symbol_bigrams()
# просто демонстрация. На деле проще использовать sheet_en_symbol_bigrams(ignore_case=True)
res.sheet_custom_symbol_bigrams(ascii_letters, ignore_case=True, name='English letter bigrams')
Результаты анализов
Полностью с результатами анализов, как и с пакетом в целом, можно ознакомиться на гитхабе (https://github.com/uqqu/frequency_analysis). К сожалению, .db файл для англоязычного анализа не прошёл по размеру (392Мб), но все остальные данные, включая .xlsx, доступны. Приложу несколько скриншотов для демонстрации вывода.Примеры некоторых листов .xlsx вывода (без пост-форматирования)
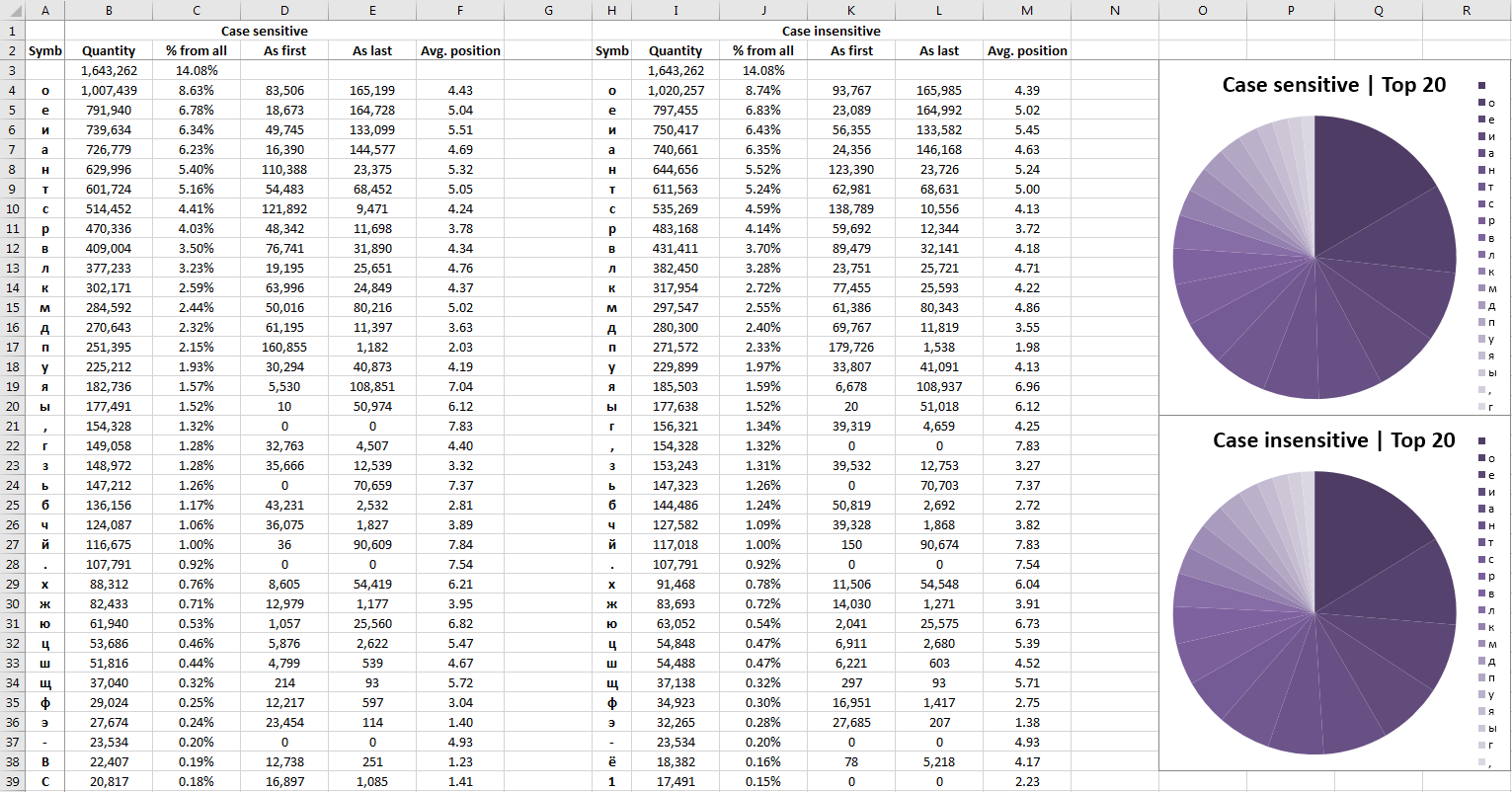
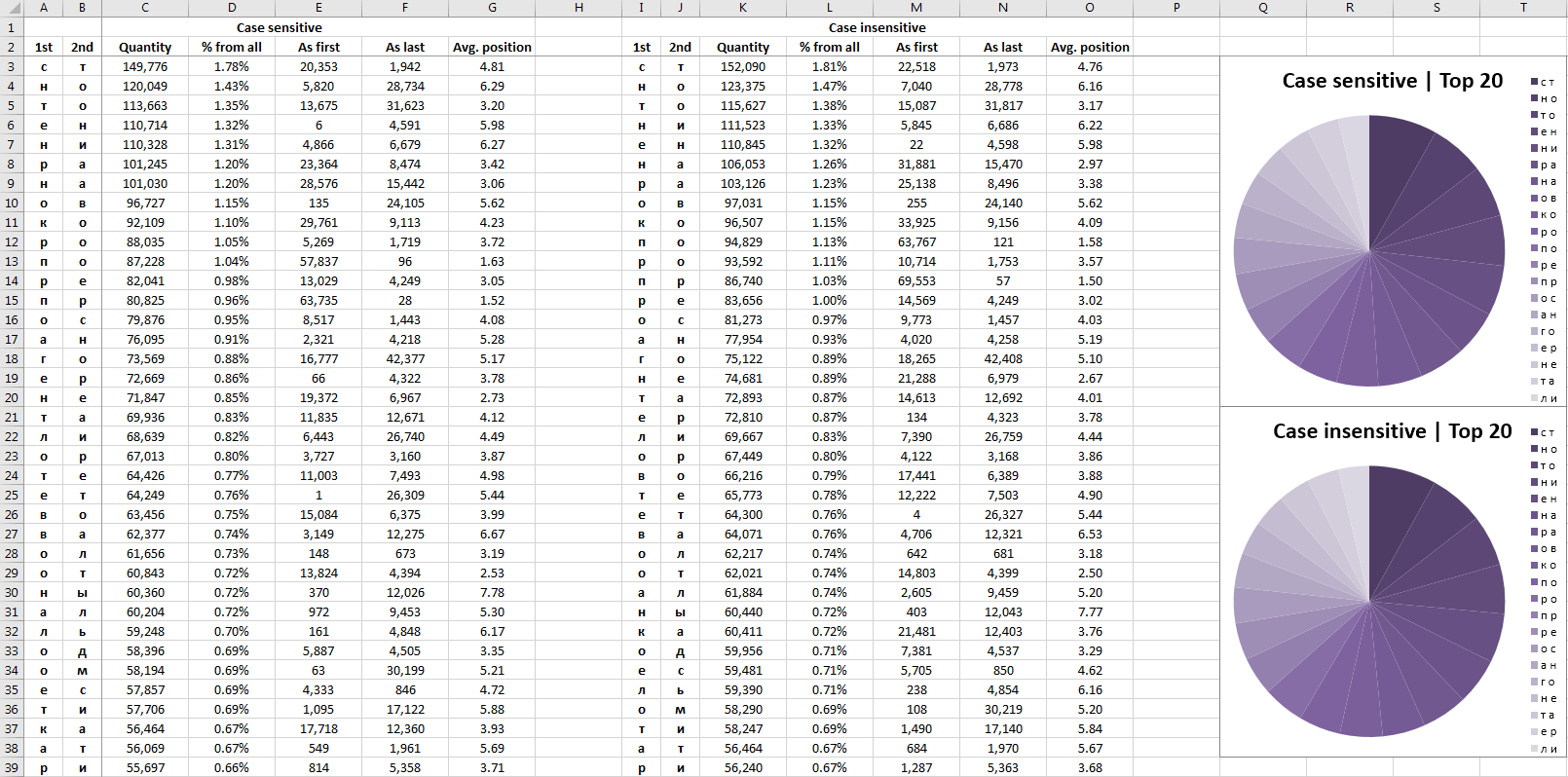

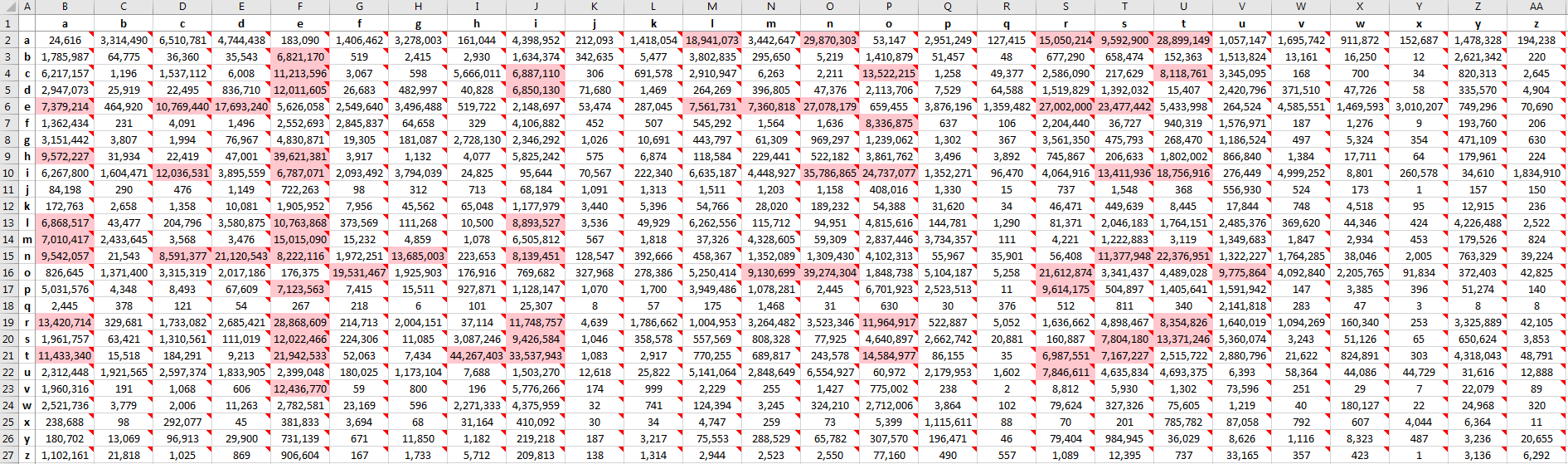

Спасибо всем, кто дочитал. Надеюсь, где-нибудь пригодится. Если это кого-то натолкнёт на собственный анализ с использованием данного пакета – пишите, буду рад узнать.
За сим всё. Сильно ногами не бейте – первый пакет, первый пост. За замечания, коррективы и предложения по улучшению заранее спасибо.

Частотный биграммный анализ на Python
Предыстория Понадобилось мне для одного проекта узнать частотность (как базовую, так и парную) буквенных символов в русском и английском языках. Побродив по бескрайним просторам интернета, я с...
 habr.com
habr.com