Всем привет, я Александр Данковцев, lead engineer команды Antimonolith. Как можно догадаться, в Авито я занимаюсь распилом монолита.
В прошлой статье я рассказывал про наш CI/CD. Сегодня речь пойдёт о процессе миграции монолита в Kubernetes и сопутствующих ему проблемах. Я разберу, как мы эти проблемы решали и к чему в итоге пришли.


У такой архитектуры был ряд проблем:

В 2017 году в поле нашего зрения попал Kubernetes, мы стали его изучать и адаптировать к себе в инфраструктуру. К концу года у нас было уже 60 микросервисов: часть на LXC, часть в Kubernetes.
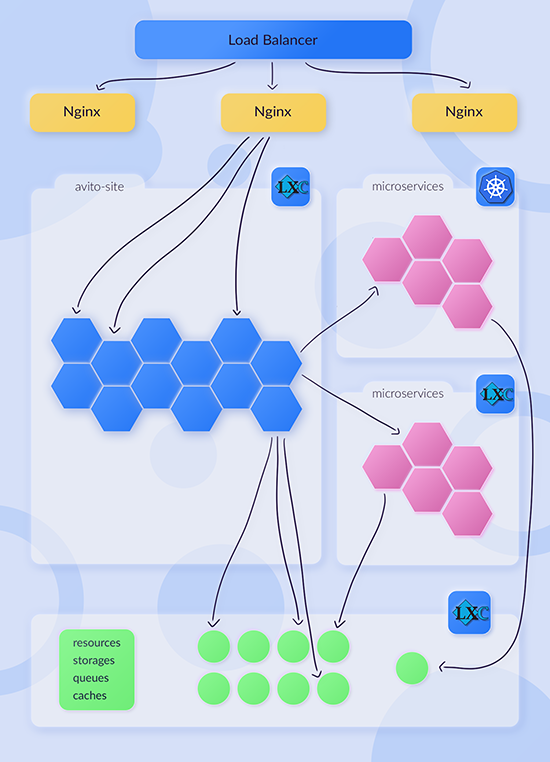
В 2018 мы закончили миграцию с LXC-микросервисов в Kubernetes. Их общее количество доросло до 200.
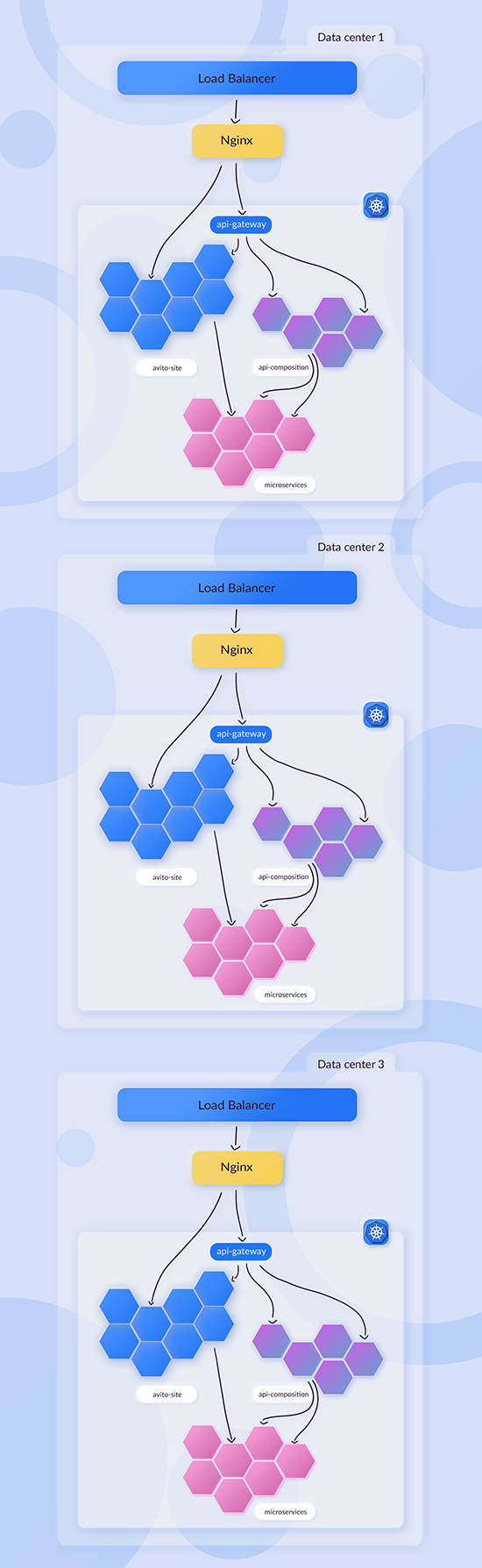
Дальше мы стали развивать идею с распилом монолита. У нас появился api-gateway, с помощью которого мы смогли создавать первые api-composition сервисы. Api-gateway маршрутизирует, куда отправить запрос: либо это будет avito-site, либо как раз какой-нибудь api-сomposition.
Api-composition — это тип сервисов, которые содержат бизнес-логику, основанную на взаимодействии других микросервисов, и форматируют ответ для клиента (приложения). Основная их идея в том, что такие сервисы не имеют под собой хранилища данных, максимум, что допустимо, — какой-нибудь кэширующий слой. Это сервисы более высокого уровня логики:

Также с 2018 года у нас появился PaaS, и количество сервисов стало расти с невероятной скоростью: с 200 до 600 за год. PaaS позволял культивировать их намного быстрее.
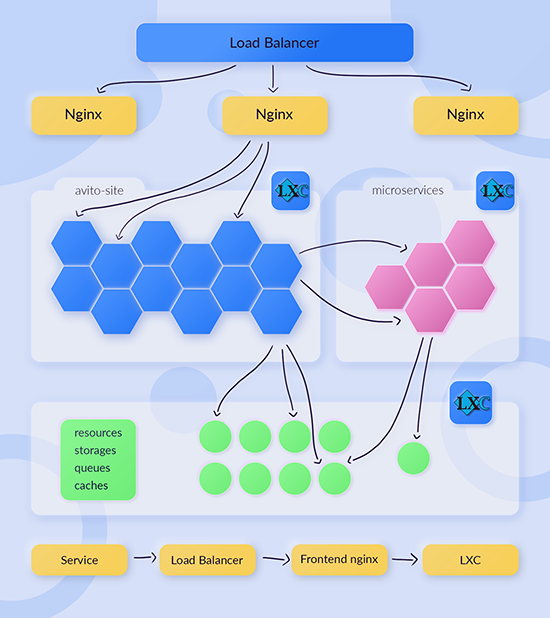
С появлением схемы с api-composition и api-gateway появилась возможность ходить в монолит «дешевле». Раньше, чтобы микросервис попал в avito-site, ему нужно было отправить внешний запрос, пройти все балансировщики и попасть только на LXC. В новой схеме стало возможно посылать запрос в api-gateway, который мог смаршрутизировать в avito-site.
Было:
Стало:
 Прямой поход в микросервис, минуя монолит
Прямой поход в микросервис, минуя монолит
Такой трюк создал нам дополнительную проблему. DevOps-инженерам нужно было легко и быстро убирать из-под нагрузки произвольные LXC-контейнеры, например, чтобы обновить ядро или произвести другую работу. Получилось так, что список хостов монолита стал дублироваться. Часть была зафиксирована во фронтенд nginx, а другая коммитилась в api-gateway.
Чтобы решить проблему, мы закрыли все запросы к сайту через HAProxy. В каждом LXC-контейнере монолита создавался файлик healthcheck.html. Если api-gateway видел, что файлика нет, то не отправлял туда пользовательские запросы.
Одним из блокеров было то, что монолит хостится на LXC, а это один дата-центр. Засетапить всю инфраструктуру в три дата-центра было бы очень сложно, поэтому мы не стали так делать. Вместо этого решили перенести монолит в Kubernetes, чтобы он стал своего рода «микросервисом».
Следующей сложностью было то, что очень много логики было завязано на шаринг данных между контейнерами. Мы приняли решение, что перепишем её на S3-технологии, в нашем случае на Ceph.
Ещё один блокер — LXC сложно масштабировать. Но с Kubernetes это будет решаться довольно просто, одной-единственной командой kubectl scale deploy. То есть можно легко и быстро отмасштабироваться, если мы вдруг не справимся с нагрузкой.
Несколько дата-центров означают, что кроны должны запускаться в единственном экземпляре, где бы они не находились. Эта проблема решается сервисом lock-ов.
И последний нюанс был в том, что все демоны в монолите запускались под супервизором. У них был один большой царь LXC-контейнер. В распределённой системе, если делать их разными маленькими демоночками, нужно уметь всё это контролировать: останавливать, перезапускать, читать логи, масштабировать и так далее. Для этого мы решили реализовать Supervisor Aggregator, о нём я расскажу в конце статьи.
Доступы в базу данных. На LXC для монолита были настроены политики в trust: у нас был список пользователей, под которыми разрешалось ходить в базу данных. И соответственно, были разрешённые хосты, то есть в базу данных можно было ходить без пароля.
С Kubernetes такая история не сработает, поэтому мы решили переписать его на работы с секретами из Vault. Благодаря этому не придётся хардкодить ни пользователей, ни хосты. Всё просто.
Конфигурация хостов для доступа к микросервисам. У нас есть три окружения:
Конфигурация ресурсов. Монолит использует кучу конфигураций, proxy, более 10 кэширующих кластеров, 10 баз данных, 3 кластера поиска, несколько кластеров Rabbit и так далее. По идее, все их нужно описывать в ConfigMap, а это очень больно.
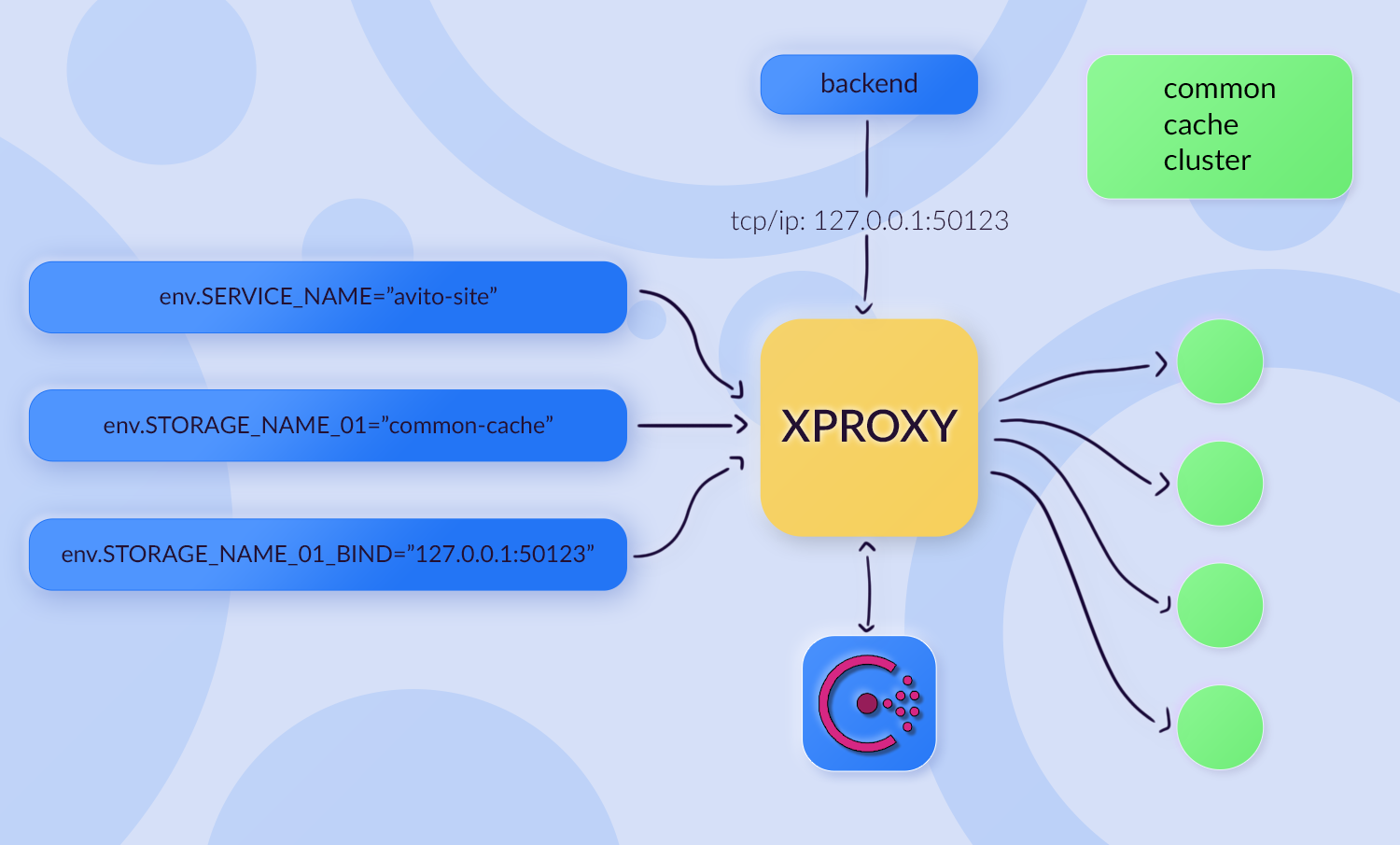
Но оказалось, что в Авито уже есть решение проблемы. Ребята в DBaaS-команде разработали инструмент Xproxy. Xproxy — утилита, с помощью который через переменные окружения передаются:
Деплой. Нам нужно уметь поддерживать канарейки, sticky-сессии, и нам нужен blue-green релиз. Helm это не поддерживает. Но мы нашли workaround вокруг Helm: делали деплой релиза с суффиксом, обновляли Ingress и удаляли старый релиз.
Legacy Redis Local. Это Redis, в котором сохраняется feature toggle. Эти Redis-ы реплицировались на каждый LXC-контейнер. На них очень высокая нагрузка — два миллиона запросов в минуту. Взаимодействие было по unix socket. То есть если из Kubernetes натравливать на физический, железный Redis по TCP/IP, будет очень больно.
В первом подходе мы сделали репликацию Redis в контейнер и переделали на взаимодействие по TCP. Но так лучше не делать: репликация Redis в Kubernetes-контейнере — это очень плохо. Давайте на примере посмотрим, почему.

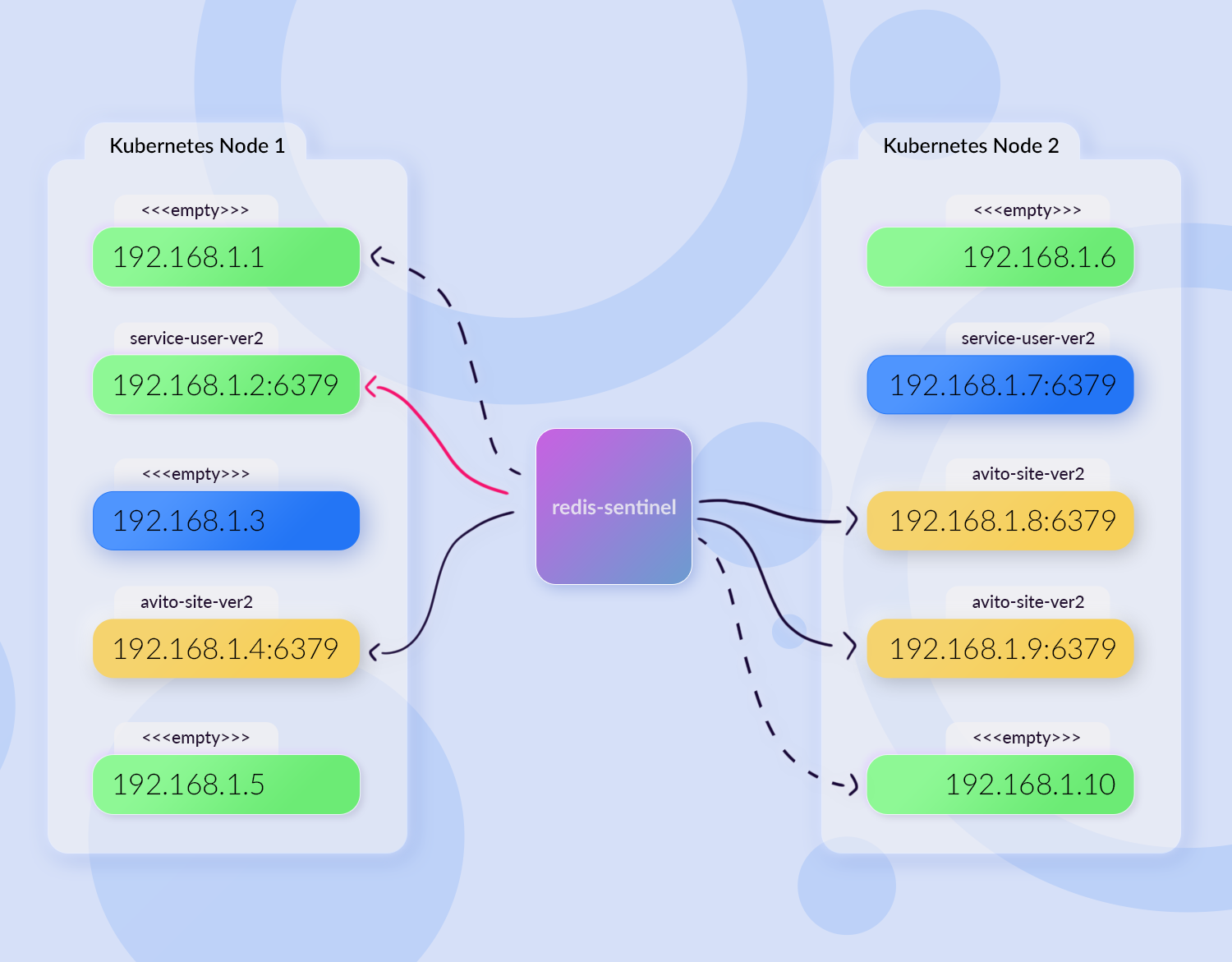
Представим, что у нас две ноды кластера, где есть жёлтые поды avito-site-ver1, в которых есть контейнер со слейвом Redis-а. В центре расположен redis-sentinel, который доставляет данные с мастера для наших реплик. А ещё есть, допустим, синий service-user-ver1, у которого тоже есть Redis.
Мы деплоим монолит. Kubernetes выдал новые айпишники, avito-site-ver2 развернулся в новом месте:

Контейнеры с Redis-ом в avito-site запросили: «Дай мне данные, я твой slave». Redis-sentinel зарегистрировал себе новые end-пойнты для рассылки данных: теперь он рассылает их уже не в три источника, а в шесть. При этом три источника уже мертвы.
Service-user тоже решил задеплоиться. И тут мы рискуем получить ситуацию, когда для одного из подов service-user Kubernetes выдал айпишник, на котором раньше располагался avito-site:
В итоге у service-user появится feature toggle монолита. Service-user будет пытаться что-то туда записать, но у него ничего не выйдет, потому что данные моментально будут перезаписываться. Это очень плохая практика, на которую мы напоролись.
После того как мы изучили все проблемы, то собрали примерно такой pod avito-site-ver1:
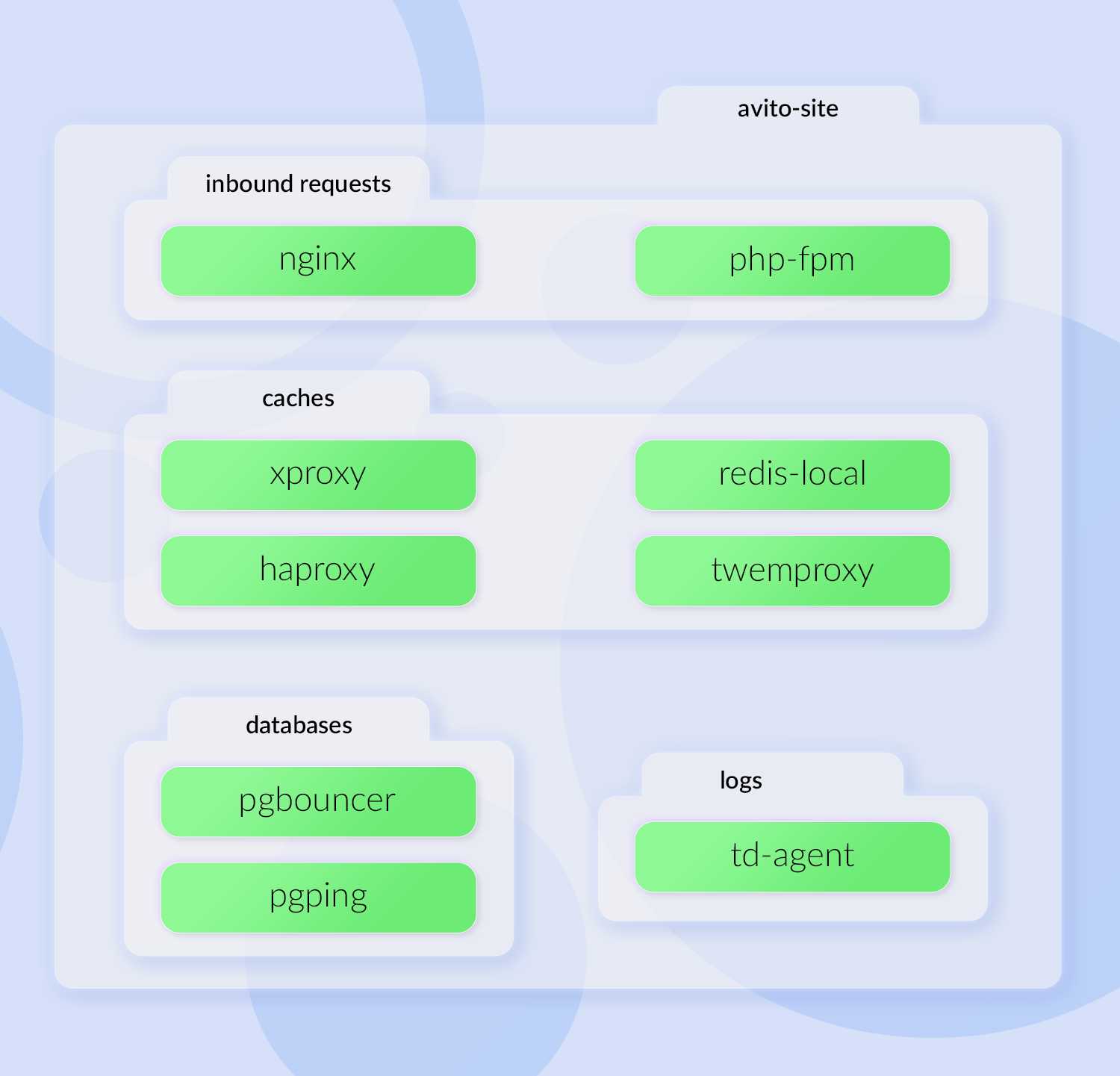
Входящие запросы приходят на nginx, обрабатываются в php-fpm. Есть список кэшей: xproxy, haproxy для Sphinx, контейнер с redis-local и twemproxy для memcache. Есть и набор контейнеров для работы с базой данных и контейнер для отправки логов.
Но на деле этого оказалось мало. Здесь нет метрик с core-nginx. Я ранее упоминал, что мы рендерим такой же config, как для LXC, соответственно, нам нужно собирать access-логи и метрики по ним. Нет и service discovery — компонента, который отвечает за балансировку, то есть маршрутизацию сервисов, расположенных в других дата-центрах. И нет никакого агрегатора метрик. Получилось, что все метрики отправляются в одну точку, а это узкое горлышко.
Доработали и сделали царь Kubernetes pod:
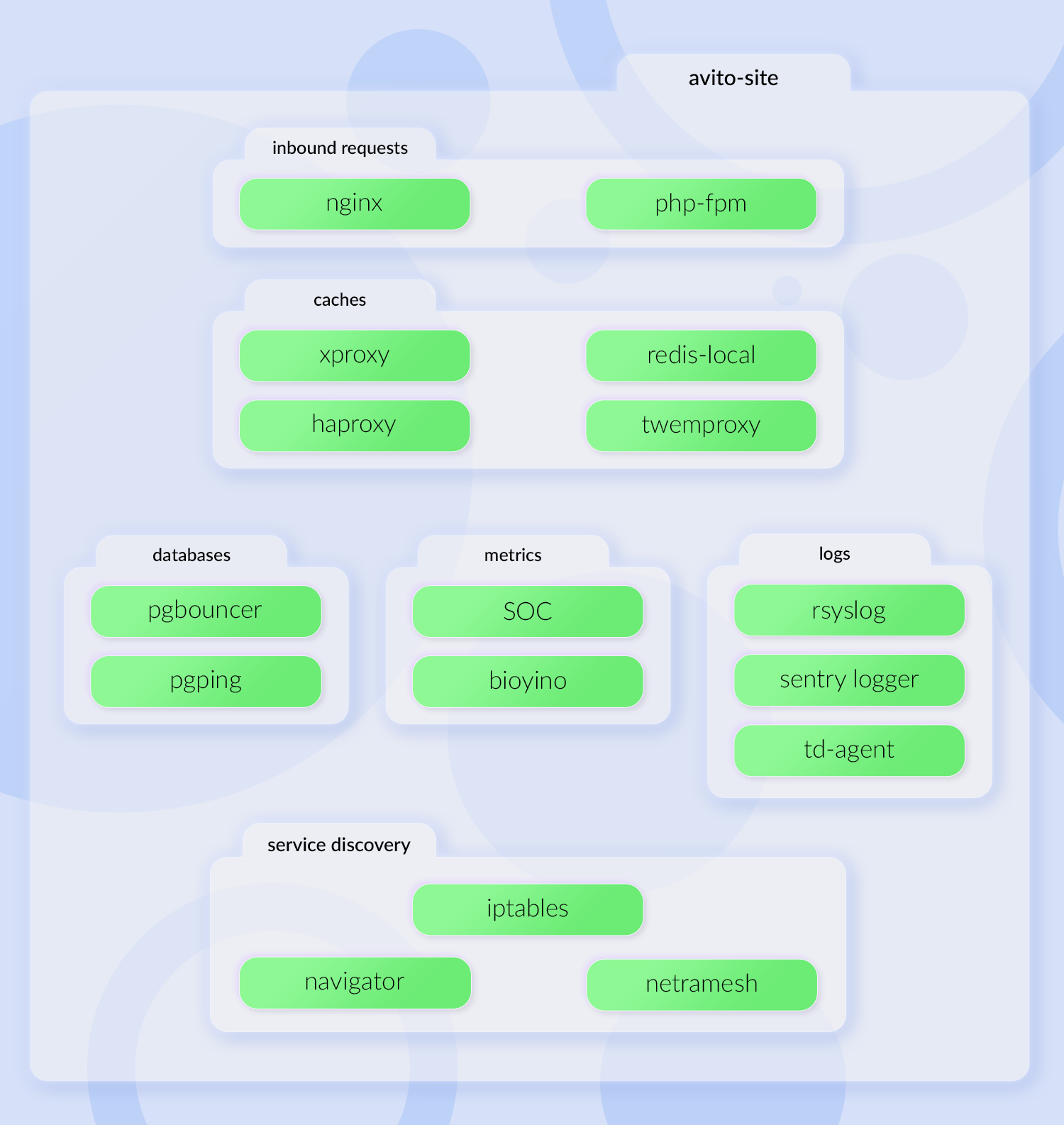
SOC — это обработчик nginx access-логов, который превращает access-логи в метрики. Контейнер bioyino — это агрегатор, локальный statsd-агент, в который отправляются метрики. Сначала мы со всех контейнеров шлём все метрики в один, а он уже их агрегирует и отправляет агрегированные, уменьшенные данные. Расширились логи, например появился rsyslog, который пушит события в ClickHouse. Появились контейнеры для service discovery.
Итак, мы подготовили наш финальный pod. Пришло время интегрировать его в продакшн.
Подготовку к интеграции начали с тестового стенда. Мы задеплоили тестовый релиз с суффиксом “-test” и создали отдельные поддомены на внешних балансировщиках, чтобы они прибивались там к нужному нам инстансу. Дальше настроили reverse-proxy и запросили суперадминские права для тестов.
На тестах щупали всю функциональность: смотрели объявления, что-то делали в модерации, писали комментарии. После того как всё было протестировано, мы интегрировались в pipeline релиза, чтобы при деплоях монолита деплоился и инстанс Kubernetes.
Затем дождались, когда произойдёт релиз. В нём раскатился prod-экземпляр без трафика, а затем мы начали добавлять трафик. Сначала интегрировали split-ep трафика по IP-адресам, то есть взяли конкретных пользователей, которые будут пользоваться новой админкой. После того как мы ещё раз убедились, что всё работает, стали добавлять под сетями московский и питерский офисы. А когда всё обкатали, то сделали подключение для всех пользователей админки.
Так мы затащили весь backoffice в Kubernetes. После того как появился instance монолит непосредственно в «Кубе», на него стало можно ходить по внутреннему адресу. До этого ходить можно было только через api-gateway:

Также возникла проблема неконсистентности окружений. Какие-то PHP-расширения в Docker-образе есть, а в LXC контейнере нет, и так далее. С этим мы решили ничего не делать и просто подождать полной миграции в Kubernetes, чтобы не распыляться. Сначала коллеги тревожились по любому отказу в админке, но со временем всё устаканилось, и все поняли, что виноват не Kubernetes, а другие взаимные сервисы.
Helm не умеет деплоиться в несколько кластеров. Тут нас выручило то, что команда архитектуры сделала новый деплоер — Jibe, и мы перевели на него avito-site.
Дополнительная проблема, с которой мы столкнулись, — nginx не умеет резолвить несуществующие сервисы. В монолите указано более двухсот сервисов, а это означает, что мы сгенерировали для них 200 nginx upstream-ов, и, если хотя бы один будет недоступен, nginx не сможет подняться. Это некруто. Если сервис в процессе работы удалят и заново задеплоят, монолит не сможет в этот сервис сходить, пока его не перевыкатят. Эту проблему решили переездом на envoy как proxy в сервисы.
Были и трудности при подключении новых сервисов. Возникали ситуации, когда кто-нибудь добавил сервис, в LXC он заработал, а в Kubernetes нет. То есть в вебе сервис работает, а в админке нет. Мы посмотрели, в чём дело, и добавили линтер конфигов, который решил задачу.
После работы над новыми проблемами наш царь-pod немного изменился:
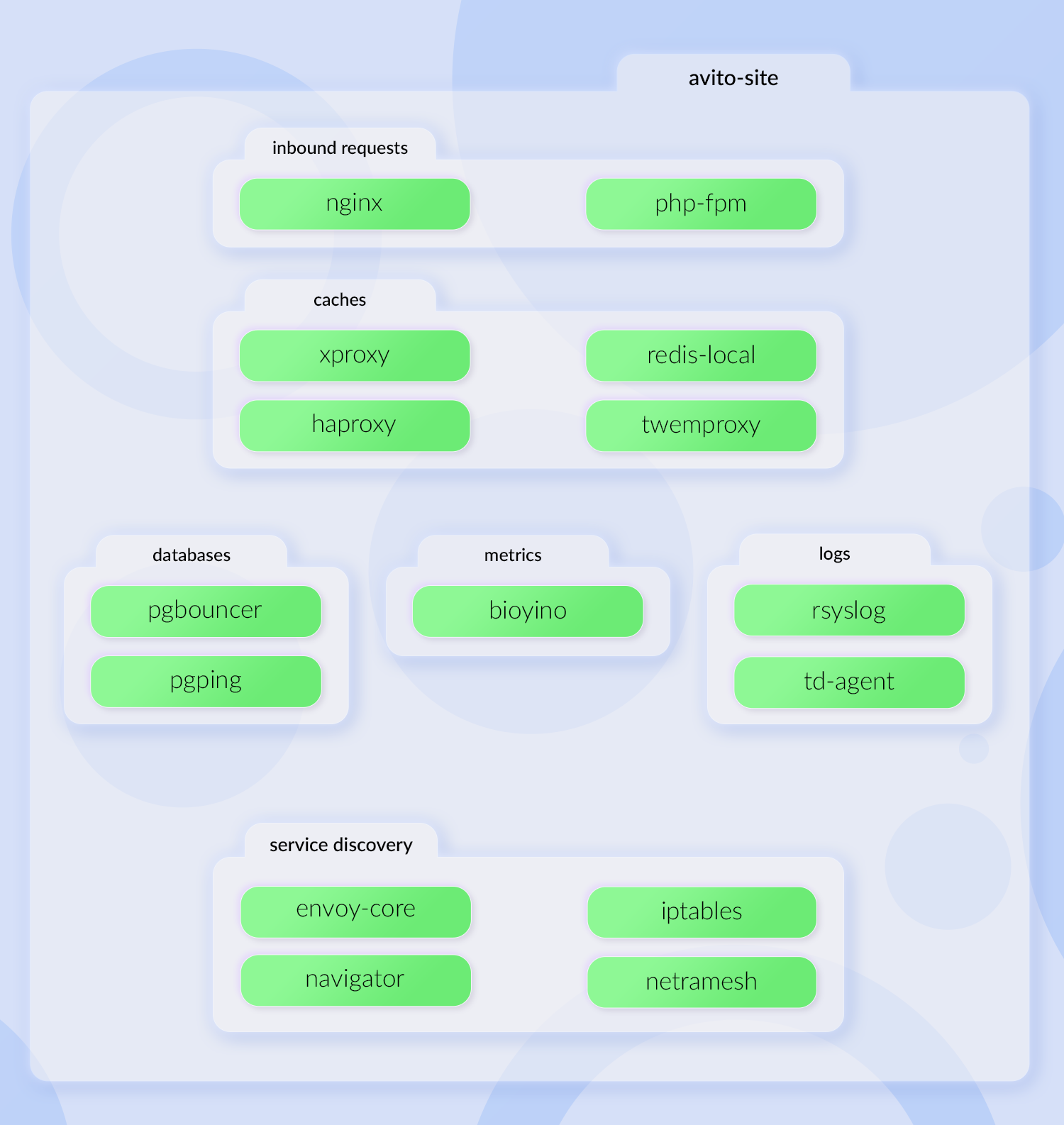
В нём появился envoy-core, я отнёс его к блоку service discovery. С этого envoy мы стали сразу читать метрики. А часть контейнеров, которая агрегировала данные с nginx, стала больше не нужна. Итого, один контейнер прибавился, один убавился.
Алгоритм по переключению десктопного трафика был следующий:
В какой-то момент схема не сработала. Нашёлся предел, причём нашёлся он довольно быстро. Настало время оптимизаций.
Мы масштабировались и увеличивали количество реплик. И наш выделенный Kubernetes pool с нодами, на которые разрешено деплоиться, закончился. Мы решили снять ограничения и увеличить количество реплик, то есть сделать взаимную компенсацию. Изначально мы загоняли монолит в выделенный pool, потому что он был слишком шумным. Но, дав ему возможность катиться куда угодно и увеличив количество реплик, мы понижали нагрузку на конкретный instance и тем самым сокращали его влияние на соседей.
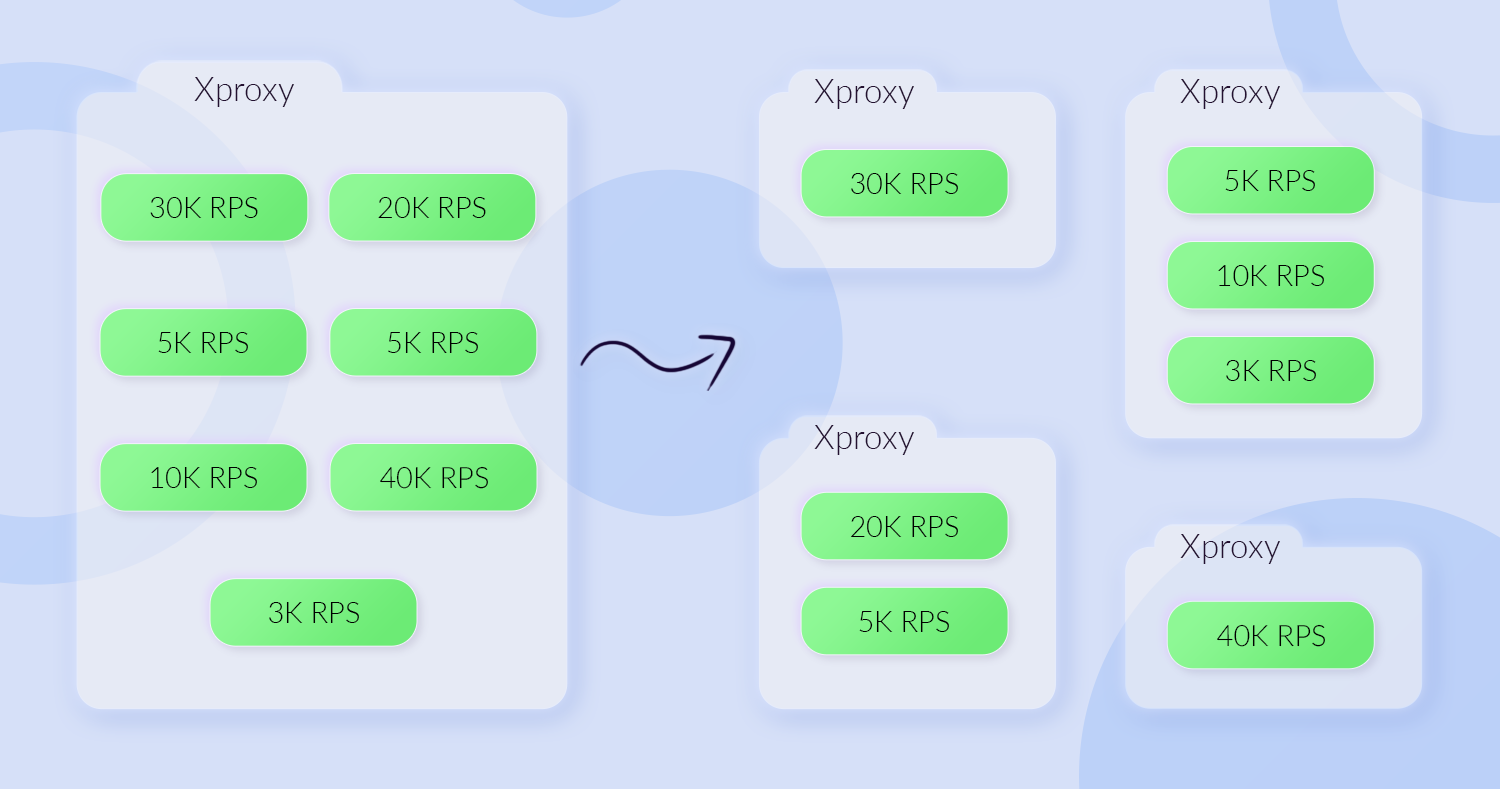
Также у нас неожиданно возникла проблема с тем, что response time Redis-ов стал упираться в «полочку». Оказалось, что была слишком большая сетевая активность в одном контейнере. Один контейнер поднимал proxy до десяти разных кэширующих Redis-ов. А каждый кэширующий Redis — это кэширующий кластер, где могло быть до 64 тачек. Это сумасшедшая цифра. Мы разделили один xproxy на четыре разных контейнера, и в этом сетапе контейнеры с xproxy стали работать гораздо лучше и справляться с нагрузкой.
Метрики с envoy стали «рваными». Они собираются инфраструктурными компонентами и складируются в Prometheus. Prometheus перестал справляться с их огромным количеством и начал терять данные. Это мы полечили тем, что подключили отправку метрик через локальные statsd-агенты.
Также была проблема высокой утилизации нод с монолитом. Её мы решили комплексно. Провели инвентаризацию, актуализировали requests/limits, чтобы Kubernetes лучше шедулил поды и не засылал несколько подов на одну ноду. Спилили redis-local, заменили его тем, что ходим напрямую за feature toggle и сохраняем их в in-memory cache в APCu PHP-шном. Тем самым мы значительно сняли сетевую нагрузку.
Мы также полностью отказались от ещё одной технологии — memcache. Меньше зоопарка — меньше проблем. И дополнительно переделали отправку метрик через cluster IP. Получается, на каждую Kubernetes-ноду мы локально поставили statsd-агрегатор, и необходимость в локальном контейнере Bioyino отпала. Мы начали просто отправлять метрики с айпишника ноды в statsd-агент.
В итоге Kubernetes pod стал гораздо легче деплоиться, а ресурсов в кластере стало больше:


Мы переключили практически весь трафик. Как вишенку на торте оставили кроны, демоны и логику, завязанную на ширинг данных. Но мы их тоже зафиксили.
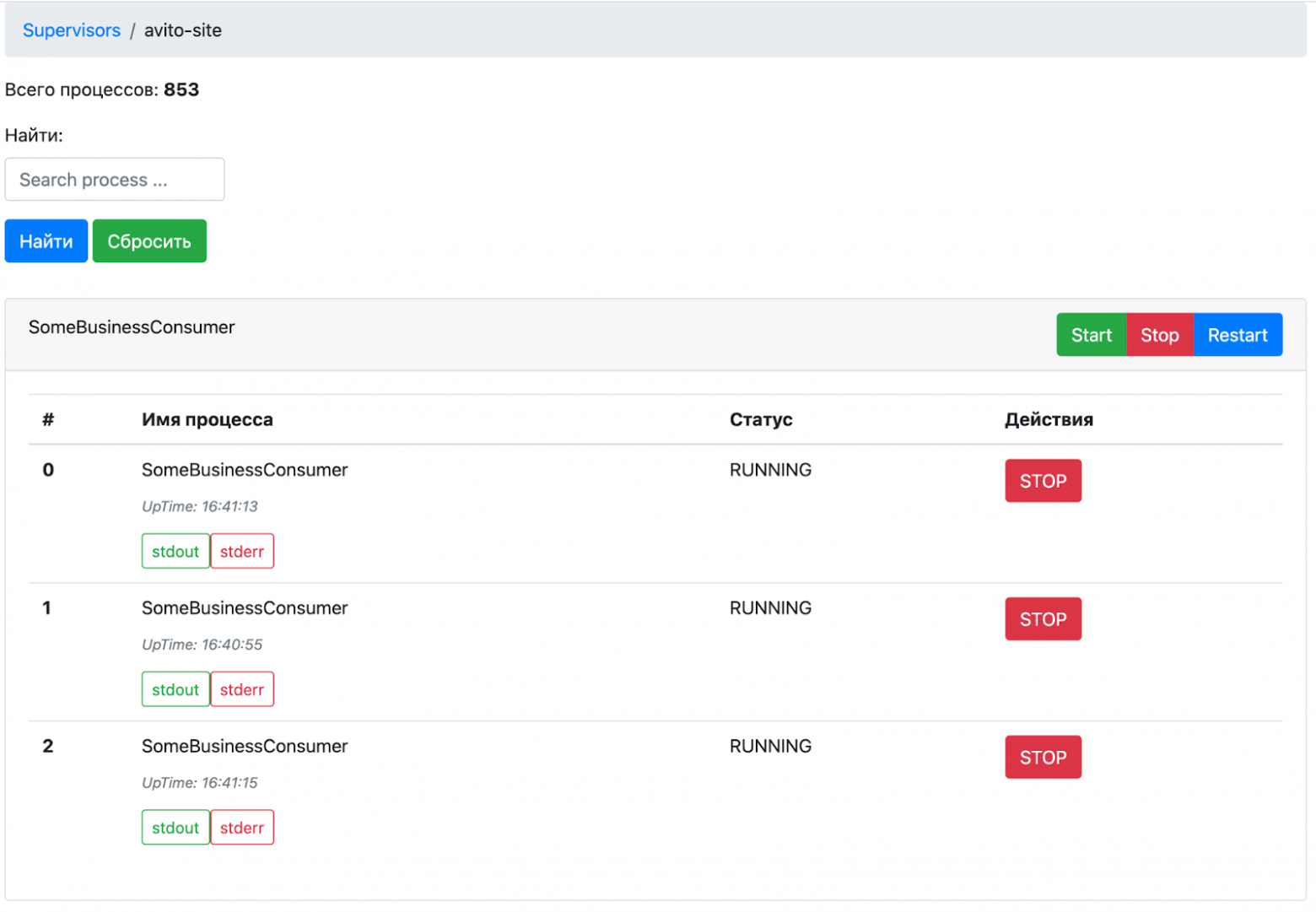
Как мы поступили с супервизорами, о которых я говорил в самом начале статьи? Напомню, что в старом монолите все демоны запускались под супервизором, и нам нужно было придумать, как их контролировать в распределённой системе. Новый супервизор-агрегатор умеет агрегировать информацию во всех запущенных инстансах супервизоров в любом дата-центре. Если лейбл app=supervisor, он подтягивает этот pod к себе, строит карту и по RPC собирает общую информацию о том, какие процессы и работы запущены.

В итоге супервизор-агрегатор предоставляет фронтенд, где отображает всю информацию и позволяет через себя всем этим управлять. Это распределённая и более ресурсосвободная альтернатива тому, что было на одном LXC-контейнере.

 habr.com
habr.com
В прошлой статье я рассказывал про наш CI/CD. Сегодня речь пойдёт о процессе миграции монолита в Kubernetes и сопутствующих ему проблемах. Я разберу, как мы эти проблемы решали и к чему в итоге пришли.
Что было в начале
История архитектуры Авито началась с 2007 года и примерно до 2015 года практически не менялась. Архитектура представляла из себя 10 верхнеуровневых балансировщиков трафика, которые принимали пользовательские запросы и балансили их на 64 LXC-контейнера с монолитным бэкендом Авито. Монолит представлял собой миллион строк на PHP и общался со множеством баз данных — их было порядка 10.
У такой архитектуры был ряд проблем:
- Монолитное приложение недостаточно гибкое.
- Возникла потребность где-то держать общую функциональность: у нас появлялись второстепенные продукты, и нужно было переиспользовать общую логику.
- Всё концентрировалось в одном приложении, которое обращалось со множеством баз данных.
- Страдала отказоустойчивость.
В 2017 году в поле нашего зрения попал Kubernetes, мы стали его изучать и адаптировать к себе в инфраструктуру. К концу года у нас было уже 60 микросервисов: часть на LXC, часть в Kubernetes.
В 2018 мы закончили миграцию с LXC-микросервисов в Kubernetes. Их общее количество доросло до 200.
Дальше мы стали развивать идею с распилом монолита. У нас появился api-gateway, с помощью которого мы смогли создавать первые api-composition сервисы. Api-gateway маршрутизирует, куда отправить запрос: либо это будет avito-site, либо как раз какой-нибудь api-сomposition.
Api-composition — это тип сервисов, которые содержат бизнес-логику, основанную на взаимодействии других микросервисов, и форматируют ответ для клиента (приложения). Основная их идея в том, что такие сервисы не имеют под собой хранилища данных, максимум, что допустимо, — какой-нибудь кэширующий слой. Это сервисы более высокого уровня логики:
Также с 2018 года у нас появился PaaS, и количество сервисов стало расти с невероятной скоростью: с 200 до 600 за год. PaaS позволял культивировать их намного быстрее.
С появлением схемы с api-composition и api-gateway появилась возможность ходить в монолит «дешевле». Раньше, чтобы микросервис попал в avito-site, ему нужно было отправить внешний запрос, пройти все балансировщики и попасть только на LXC. В новой схеме стало возможно посылать запрос в api-gateway, который мог смаршрутизировать в avito-site.
Было:
Стало:
Такой трюк создал нам дополнительную проблему. DevOps-инженерам нужно было легко и быстро убирать из-под нагрузки произвольные LXC-контейнеры, например, чтобы обновить ядро или произвести другую работу. Получилось так, что список хостов монолита стал дублироваться. Часть была зафиксирована во фронтенд nginx, а другая коммитилась в api-gateway.
Чтобы решить проблему, мы закрыли все запросы к сайту через HAProxy. В каждом LXC-контейнере монолита создавался файлик healthcheck.html. Если api-gateway видел, что файлика нет, то не отправлял туда пользовательские запросы.
Авито в Kubernetes
Блокеры
В середине 2019 года Авито начал переезжать из одного в три дата-центра. Мы стали думать, какие блокеры могут возникнуть для переезда монолита.Одним из блокеров было то, что монолит хостится на LXC, а это один дата-центр. Засетапить всю инфраструктуру в три дата-центра было бы очень сложно, поэтому мы не стали так делать. Вместо этого решили перенести монолит в Kubernetes, чтобы он стал своего рода «микросервисом».
Следующей сложностью было то, что очень много логики было завязано на шаринг данных между контейнерами. Мы приняли решение, что перепишем её на S3-технологии, в нашем случае на Ceph.
Ещё один блокер — LXC сложно масштабировать. Но с Kubernetes это будет решаться довольно просто, одной-единственной командой kubectl scale deploy. То есть можно легко и быстро отмасштабироваться, если мы вдруг не справимся с нагрузкой.
Несколько дата-центров означают, что кроны должны запускаться в единственном экземпляре, где бы они не находились. Эта проблема решается сервисом lock-ов.
И последний нюанс был в том, что все демоны в монолите запускались под супервизором. У них был один большой царь LXC-контейнер. В распределённой системе, если делать их разными маленькими демоночками, нужно уметь всё это контролировать: останавливать, перезапускать, читать логи, масштабировать и так далее. Для этого мы решили реализовать Supervisor Aggregator, о нём я расскажу в конце статьи.
Вызовы
Мы решили, что будем катить монолит в Kubernetes. Какие первоначальные вызовы перед нами встали?Доступы в базу данных. На LXC для монолита были настроены политики в trust: у нас был список пользователей, под которыми разрешалось ходить в базу данных. И соответственно, были разрешённые хосты, то есть в базу данных можно было ходить без пароля.
С Kubernetes такая история не сработает, поэтому мы решили переписать его на работы с секретами из Vault. Благодаря этому не придётся хардкодить ни пользователей, ни хосты. Всё просто.
Конфигурация хостов для доступа к микросервисам. У нас есть три окружения:
- Local — для доступа с локальной машины разработчика.
- Dev/staging — хост в сборке.
- Prod — хост для доступа с LXC.
Конфигурация ресурсов. Монолит использует кучу конфигураций, proxy, более 10 кэширующих кластеров, 10 баз данных, 3 кластера поиска, несколько кластеров Rabbit и так далее. По идее, все их нужно описывать в ConfigMap, а это очень больно.
Но оказалось, что в Авито уже есть решение проблемы. Ребята в DBaaS-команде разработали инструмент Xproxy. Xproxy — утилита, с помощью который через переменные окружения передаются:
- для какого сервиса мы хотим настроить коннект — на схеме ниже приведён пример common cache;
- название хранилища;
- на каком IP + port-у будет прокси для доступа к нужному хранилищу.
Деплой. Нам нужно уметь поддерживать канарейки, sticky-сессии, и нам нужен blue-green релиз. Helm это не поддерживает. Но мы нашли workaround вокруг Helm: делали деплой релиза с суффиксом, обновляли Ingress и удаляли старый релиз.
Legacy Redis Local. Это Redis, в котором сохраняется feature toggle. Эти Redis-ы реплицировались на каждый LXC-контейнер. На них очень высокая нагрузка — два миллиона запросов в минуту. Взаимодействие было по unix socket. То есть если из Kubernetes натравливать на физический, железный Redis по TCP/IP, будет очень больно.
В первом подходе мы сделали репликацию Redis в контейнер и переделали на взаимодействие по TCP. Но так лучше не делать: репликация Redis в Kubernetes-контейнере — это очень плохо. Давайте на примере посмотрим, почему.
Представим, что у нас две ноды кластера, где есть жёлтые поды avito-site-ver1, в которых есть контейнер со слейвом Redis-а. В центре расположен redis-sentinel, который доставляет данные с мастера для наших реплик. А ещё есть, допустим, синий service-user-ver1, у которого тоже есть Redis.
Мы деплоим монолит. Kubernetes выдал новые айпишники, avito-site-ver2 развернулся в новом месте:
Контейнеры с Redis-ом в avito-site запросили: «Дай мне данные, я твой slave». Redis-sentinel зарегистрировал себе новые end-пойнты для рассылки данных: теперь он рассылает их уже не в три источника, а в шесть. При этом три источника уже мертвы.
Service-user тоже решил задеплоиться. И тут мы рискуем получить ситуацию, когда для одного из подов service-user Kubernetes выдал айпишник, на котором раньше располагался avito-site:
В итоге у service-user появится feature toggle монолита. Service-user будет пытаться что-то туда записать, но у него ничего не выйдет, потому что данные моментально будут перезаписываться. Это очень плохая практика, на которую мы напоролись.
После того как мы изучили все проблемы, то собрали примерно такой pod avito-site-ver1:
Входящие запросы приходят на nginx, обрабатываются в php-fpm. Есть список кэшей: xproxy, haproxy для Sphinx, контейнер с redis-local и twemproxy для memcache. Есть и набор контейнеров для работы с базой данных и контейнер для отправки логов.
Но на деле этого оказалось мало. Здесь нет метрик с core-nginx. Я ранее упоминал, что мы рендерим такой же config, как для LXC, соответственно, нам нужно собирать access-логи и метрики по ним. Нет и service discovery — компонента, который отвечает за балансировку, то есть маршрутизацию сервисов, расположенных в других дата-центрах. И нет никакого агрегатора метрик. Получилось, что все метрики отправляются в одну точку, а это узкое горлышко.
Доработали и сделали царь Kubernetes pod:
SOC — это обработчик nginx access-логов, который превращает access-логи в метрики. Контейнер bioyino — это агрегатор, локальный statsd-агент, в который отправляются метрики. Сначала мы со всех контейнеров шлём все метрики в один, а он уже их агрегирует и отправляет агрегированные, уменьшенные данные. Расширились логи, например появился rsyslog, который пушит события в ClickHouse. Появились контейнеры для service discovery.
Итак, мы подготовили наш финальный pod. Пришло время интегрировать его в продакшн.
Интеграция: подготовка
Монолит Авито — всем монолитам монолит. Он включает в себя порядка десяти разных доменов: это www.avito.ru (desktop), m.avito.ru (mobile), домен для backoffice и другие.Подготовку к интеграции начали с тестового стенда. Мы задеплоили тестовый релиз с суффиксом “-test” и создали отдельные поддомены на внешних балансировщиках, чтобы они прибивались там к нужному нам инстансу. Дальше настроили reverse-proxy и запросили суперадминские права для тестов.
На тестах щупали всю функциональность: смотрели объявления, что-то делали в модерации, писали комментарии. После того как всё было протестировано, мы интегрировались в pipeline релиза, чтобы при деплоях монолита деплоился и инстанс Kubernetes.
Интеграция: запуск боевого трафика
Запуск боевого трафика мы начали с админки Авито. Сначала добавили в интерфейс признак, что страничка была отрендерена версией Авито в Kubernetes. На балансировщиках мы добавляли заголовок x-kubernetes, а в интерфейсе рисовали картинку с логотипом.Затем дождались, когда произойдёт релиз. В нём раскатился prod-экземпляр без трафика, а затем мы начали добавлять трафик. Сначала интегрировали split-ep трафика по IP-адресам, то есть взяли конкретных пользователей, которые будут пользоваться новой админкой. После того как мы ещё раз убедились, что всё работает, стали добавлять под сетями московский и питерский офисы. А когда всё обкатали, то сделали подключение для всех пользователей админки.
Так мы затащили весь backoffice в Kubernetes. После того как появился instance монолит непосредственно в «Кубе», на него стало можно ходить по внутреннему адресу. До этого ходить можно было только через api-gateway:
Интеграция: новые проблемы и решения
Kubernetes pod с сайтом оказался слишком толстым, и сильно влиял на соседние сервисы. Мы решили переселить avito-site в отдельный pool, чтобы меньше шумело.Также возникла проблема неконсистентности окружений. Какие-то PHP-расширения в Docker-образе есть, а в LXC контейнере нет, и так далее. С этим мы решили ничего не делать и просто подождать полной миграции в Kubernetes, чтобы не распыляться. Сначала коллеги тревожились по любому отказу в админке, но со временем всё устаканилось, и все поняли, что виноват не Kubernetes, а другие взаимные сервисы.
Helm не умеет деплоиться в несколько кластеров. Тут нас выручило то, что команда архитектуры сделала новый деплоер — Jibe, и мы перевели на него avito-site.
Дополнительная проблема, с которой мы столкнулись, — nginx не умеет резолвить несуществующие сервисы. В монолите указано более двухсот сервисов, а это означает, что мы сгенерировали для них 200 nginx upstream-ов, и, если хотя бы один будет недоступен, nginx не сможет подняться. Это некруто. Если сервис в процессе работы удалят и заново задеплоят, монолит не сможет в этот сервис сходить, пока его не перевыкатят. Эту проблему решили переездом на envoy как proxy в сервисы.
Были и трудности при подключении новых сервисов. Возникали ситуации, когда кто-нибудь добавил сервис, в LXC он заработал, а в Kubernetes нет. То есть в вебе сервис работает, а в админке нет. Мы посмотрели, в чём дело, и добавили линтер конфигов, который решил задачу.
После работы над новыми проблемами наш царь-pod немного изменился:
В нём появился envoy-core, я отнёс его к блоку service discovery. С этого envoy мы стали сразу читать метрики. А часть контейнеров, которая агрегировала данные с nginx, стала больше не нужна. Итого, один контейнер прибавился, один убавился.
Интеграция: льём больше трафика
Когда мы собрали все шишки и всё починили, наступил черёд лить трафик дальше. И следующий на подходе после backoffice — наш десктоп, самый нагруженный.Алгоритм по переключению десктопного трафика был следующий:
- Планирование. Провели планирование того, какие запросы переключать: подобрали регулярку, например нужно перелить /api или /profile.
- Оценка объёма. Мы внимательно смотрели на access-логи, метрики и то, какая нагрузка поступает на ручки.
- Выделение php-fpm. После того как мы получали какие-то данные, мы принимали решение, нужно ли дополнительно выделять php-fpm pool воркеров. Основываясь на метриках, мы понимали, как их лимитировать, какие выставить тайм-ауты. Смотря на логику самих ручек, дополнительно лимитировали их по памяти, чтобы не было бесконтрольного роста.
- Масштабирование. Мы смотрели, хватает ли текущей ёмкости и наращивали количество реплик сайта при необходимости.
- Маршрут в api-gateway.
- Маршрут во frontend-nginx.
В какой-то момент схема не сработала. Нашёлся предел, причём нашёлся он довольно быстро. Настало время оптимизаций.
Взрыв на проде: оптимизации
Какие новые блокеры мы обнаружили?Мы масштабировались и увеличивали количество реплик. И наш выделенный Kubernetes pool с нодами, на которые разрешено деплоиться, закончился. Мы решили снять ограничения и увеличить количество реплик, то есть сделать взаимную компенсацию. Изначально мы загоняли монолит в выделенный pool, потому что он был слишком шумным. Но, дав ему возможность катиться куда угодно и увеличив количество реплик, мы понижали нагрузку на конкретный instance и тем самым сокращали его влияние на соседей.
Также у нас неожиданно возникла проблема с тем, что response time Redis-ов стал упираться в «полочку». Оказалось, что была слишком большая сетевая активность в одном контейнере. Один контейнер поднимал proxy до десяти разных кэширующих Redis-ов. А каждый кэширующий Redis — это кэширующий кластер, где могло быть до 64 тачек. Это сумасшедшая цифра. Мы разделили один xproxy на четыре разных контейнера, и в этом сетапе контейнеры с xproxy стали работать гораздо лучше и справляться с нагрузкой.
Метрики с envoy стали «рваными». Они собираются инфраструктурными компонентами и складируются в Prometheus. Prometheus перестал справляться с их огромным количеством и начал терять данные. Это мы полечили тем, что подключили отправку метрик через локальные statsd-агенты.
Также была проблема высокой утилизации нод с монолитом. Её мы решили комплексно. Провели инвентаризацию, актуализировали requests/limits, чтобы Kubernetes лучше шедулил поды и не засылал несколько подов на одну ноду. Спилили redis-local, заменили его тем, что ходим напрямую за feature toggle и сохраняем их в in-memory cache в APCu PHP-шном. Тем самым мы значительно сняли сетевую нагрузку.
Мы также полностью отказались от ещё одной технологии — memcache. Меньше зоопарка — меньше проблем. И дополнительно переделали отправку метрик через cluster IP. Получается, на каждую Kubernetes-ноду мы локально поставили statsd-агрегатор, и необходимость в локальном контейнере Bioyino отпала. Мы начали просто отправлять метрики с айпишника ноды в statsd-агент.
В итоге Kubernetes pod стал гораздо легче деплоиться, а ресурсов в кластере стало больше:
Добиваем интеграцию
После снятия новых блокеров мы смогли спокойно деплоиться, пока опять не упёрлись в ресурсы. Но к этому моменту ребята из инфраструктуры и архитектуры уже засетапили остальные дата-центры. И мы раскидали avito-site в два новых дата-центра: по ресурсам гораздо свободнее, гораздо легче деплоиться.
Мы переключили практически весь трафик. Как вишенку на торте оставили кроны, демоны и логику, завязанную на ширинг данных. Но мы их тоже зафиксили.
Как мы поступили с супервизорами, о которых я говорил в самом начале статьи? Напомню, что в старом монолите все демоны запускались под супервизором, и нам нужно было придумать, как их контролировать в распределённой системе. Новый супервизор-агрегатор умеет агрегировать информацию во всех запущенных инстансах супервизоров в любом дата-центре. Если лейбл app=supervisor, он подтягивает этот pod к себе, строит карту и по RPC собирает общую информацию о том, какие процессы и работы запущены.
В итоге супервизор-агрегатор предоставляет фронтенд, где отображает всю информацию и позволяет через себя всем этим управлять. Это распределённая и более ресурсосвободная альтернатива тому, что было на одном LXC-контейнере.
Авито в Kubernetes: как сейчас
Когда мы всё переключили, avito-site стал равномерно распределён по всем кластерам. И все его демоны, кроны и супервизоры. Наконец-то монолит окубернечен!
Эволюция архитектуры Авито, или Как мы монолит в Kubernetes затолкали
Всем привет, я Александр Данковцев, lead engineer команды Antimonolith. Как можно догадаться, в Авито я занимаюсь распилом монолита. В прошлой статье я рассказывал про наш CI/CD . Сегодня речь...
habr.com