Привет! Усаживайтесь поудобней, в этой статье я расскажу, как мы командой пилили пет-проджект в рамках курса ODS по MLOps. Покажу не только финальный результат, но и немного расскажу про процесс работы, какие были сложности, как организовывали эффективную работу в команде. Может оказаться полезным для тех, кто хочет окунуться в Machine Learning и сделать свой пет-проджект, но пока чего-то не хватало. Также будет полезно тем, кто уже работает в области Data Science, но пока не окунулся в атмосферу DS, нет крутых коллег и разговоров про фреймворки у кофемашины, а опыт командной работы именно в области DS получить хочется. Наконец, даже если Machine Learning не актуален, полезно будет почитать про организацию работы в рамках пет-проджекта, про хаки, к которым мы пришли.
Сразу про то, что получилось на выходе: https://cryptobarometer.org/
 Yet another барометр тональности криптоновостей
Yet another барометр тональности криптоновостей
Первая часть статьи – про предысторию проекта, а также про мотивацию попилить командный проект.
Вторая часть – инженерная, про приложение, архитектуру, решение на основе машинного обучения, а также прикладные исследования, которые мы провели. Эта часть подразумевает, что читатель знаком с основами машинного обучения (если нет – вот пост vas3k “Машинное обучение для людей”).
Третья часть – про организацию работы, сложности, с которыми мы столкнулись, и хаки, повышающие продуктивность команды, к которым мы в итоге пришли.
Вот наиболее релевантный существующий проект «Crypto Fear & Greed Index»
 Crypto Fear & Greed Index
Crypto Fear & Greed Index
Но далее с очередным раундом были сложности, все опять ушло в майнинг, а про Эй-Яй забыли. Так у меня на руках остался веселый недоделанный проект, а также:

Около 4.5к коротких новостей о крипте (типа таких), размеченных на 3 класса: +/-/neutral; Список ресурсов с новостями о криптовалютах, которые стоит обкачивать + PHP-краулер – чисто FYI, использовать я его все равно не собирался ибо PHP, а я датасаентист, уверенно владеющий только питоном; Горстка жупитер-нубуков с вариацией разных подходов, в частности, золотой бейзлайн tf-idf & logreg, подбирающийся к 75% accuracy на кросс-валидации; Демка в Streamlit с уже более-менее нормальным кодом.
Цели участия в проекте были следующие:
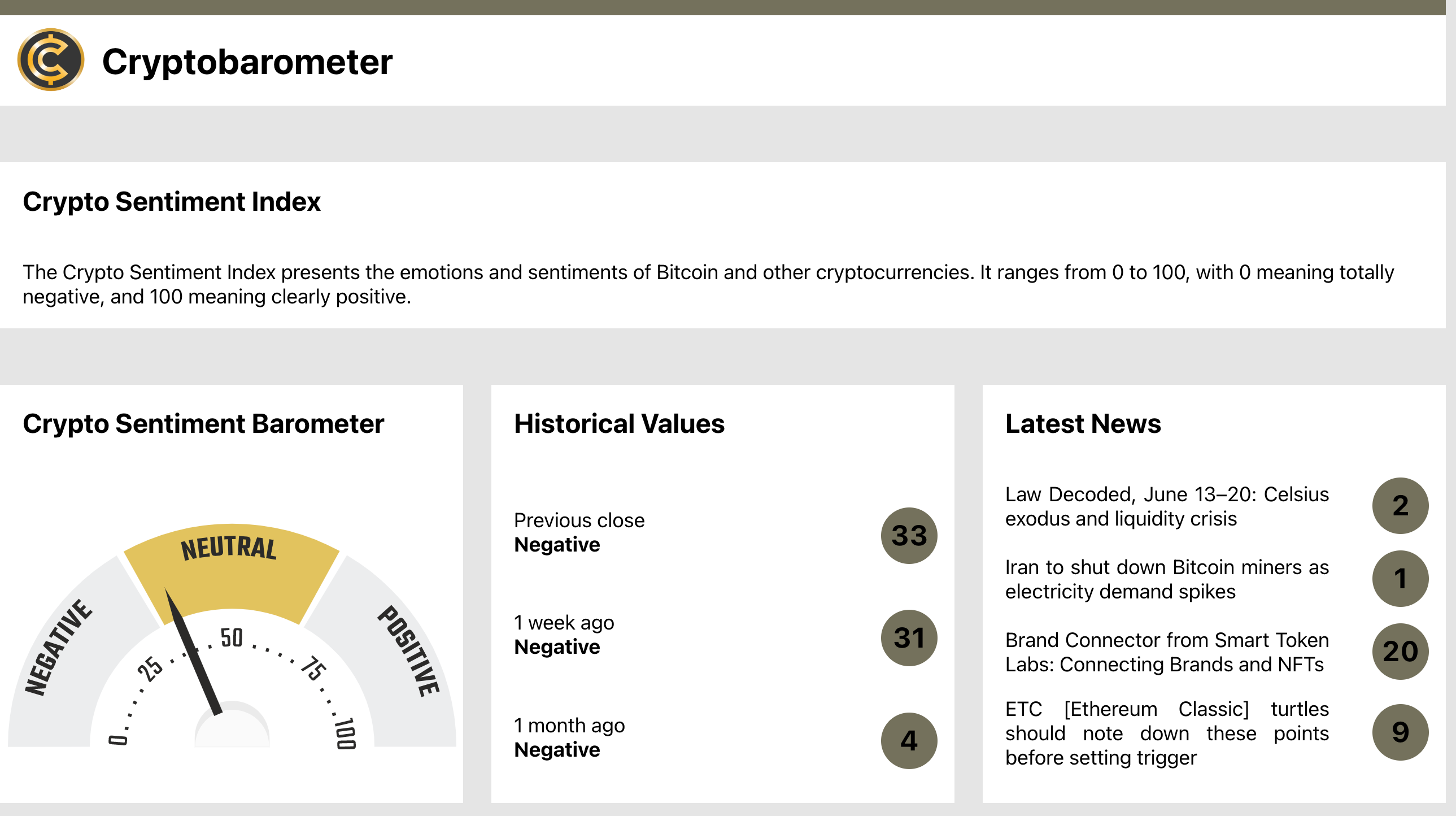
Есть барометр, показывающий среднюю тональность за сутки, также показываются средние значения тональности неделю назад, месяц назад и строится график этой метрики во времени. Еще показываются несколько последних новостей вместе с прогнозами (можно заметить, что фильтрация новостей все еще можно улучшать: "Iran to shut down Bitcoin miners as electricity demand spikes" – точно плохая новость, а вот "ETC [Etherium Classic] turties should note down these points before setting trigger" - не совсем-то и новость).
 Барометр, исторические значения тональности и последние новости
Барометр, исторические значения тональности и последние новости
 График средней тональности новостей во времени
График средней тональности новостей во времени
Также можно поиграться с моделью – ввести произвольный текст и получить прогнозы – предсказанные значения положительной, нейтральной и негативной тональности.
 Интерактивные прогнозы модели для текста, введенного пользователем
Интерактивные прогнозы модели для текста, введенного пользователем
Это все приятный фронтенд. Теперь бэкенд (тут я пересилил желание вставить пару мемов про фронт vs. бэк).
Финальная схема архитектуры приложения выглядит так:
[IMG alt="Финальная версия архитектуры приложения
"]https://habrastorage.org/r/w1560/ge...4fb0adf432c5b57701b01fed6d.png[/IMG]Финальная версия архитектуры приложения
Логика такая:
Давайте теперь пройдемся по каждому из компонентов более детально.
 Схема таблиц с данными
Схема таблиц с данными
Есть таблица с сырыми новостями news_titles:
Также есть таблица model_predictions с прогнозами модели для каждой новости:
Шаг с фильтрацией новостей довольно важен. Оглядываясь назад, при разметке данных мы бы еще просили указать, считает ли эксперт строку текста вообше новостью или нет. Таким образом, была бы надежда, что ML-модель сможит выучить и этот сигнал, помимо тональности. И сейчас у нас в приложении https://cryptobarometer.org/ можно найти “новости”, которые не очень-то и похожи на новости, например:
В начале у нас было 4500 новостей, размеченных на 3 класса частично экспертами, частично – с помощью краудсорсинга (Amazon Mechanical Turk).
Ниже представлен кривые обучения для базовой модели, “золотого NLP-бейзлайна” – логистической регрессии с Tf-Idf-преобразованием текста (если вы ничего не поняли в этой фразе, советую посмотреть открытый курс машинного обучения тут на Хабре, в частности, статью про линейные модели классификации и регрессии).
 Кривые обучения с базовой моделью
Кривые обучения с базовой моделью
Простая модель подбирается примерно к 74% верных ответов на кросс-валидации при балансе классов: 45% положительных новостей, 35% – негативных, 20 – нейтральных. Неплохо, хотя мы заметили, что простая модель не понимает даже простых отрицаний, например, и “BTC will drop by 10% tomorrow” и “BTC will not drop by 10% tomorrow” считает негативными новостями.
Впослдествии мы провели немало экспериментов и остановились на BERT модели, у которой доля верных ответов на кросс-валидации – около 81.5%, что уже совсем неплохо, так как замеренный нами уровень согласованности при разметки – от 80% до 90%, то есть BERT уже размечает новости не хуже среднего кожаного мешка.
Модель мы тренируем с MLFlow, о котором чуть ниже, и разворачиваем с FastAPI. В этом репозитории можно увидеть, как именно это делается.
BERT мы задеплоили с ONNX-сериализацией, что позволяет делать эффективный инференс на CPU.
Для трекинга экспериментов и хранения артефактов моделей мы использовали MLFLow в 4-ом сценарии, когда S3 используется для хранения моделей (в нашем случае – Minio), а база Postgres – для хранения метрик экспериментов.
Если хочется это повторить, отправим вас к лекции курса по MLOPs, где Павел Кикин как раз разворачивает описанные сервисы с docker-compose.
 Data Provider API
Data Provider API
Например, можно взять среднюю предсказанную положительную тональность для всех новостей за последние 24 часа. Или значения той же метрики по дням за последнюю неделю.
Также фронтенд умеет напрямую обращаться к API модели, чтоб отрисовать прогнозы для произвольного текста, введенного пользователем.
Про сам фронтенд в деталях не расскажу, ибо нуб в этом деле (фронтенд у нас разрабатывала Залина @LinkaG). Но вкратце: это React на базе Figma-шаблона.
 Интерфейс LabelStudio
Интерфейс LabelStudio
Label Studio умеет забирать новости из базы на разметку, предлагает пользователям интерфейс для разметки данных и также умеет экспортировать размеченные данные в базу
Мы реализовали active learning – забираются не случайные новости, а те, для которых модель выдает не очень уверенный прогноз, т.е. такие новости более перспективны для разметки. Если не слышали этот термин, советую этот блог пост о том, что делать, когда размеченных данных мало и как отбирать данные на разметку эффективно.
Понятие не очень уверенный прогноз можно определить формально, например, через энтропию прогнозов модели (о применении энтропии в машинном обучении можно почитать, например, в статье открытого курса по машинному обучению, где речь идет о построении деревьев решений). Чем выше энтропия – тем менее модель уверена в прогнозе, в частности, для 3 классов (positive/neutral/negative) энтропия будет максимальна, когда модель выдает равные предсказанные вероятности: ⅓ для positive, ⅓ для neutral и ⅓ для negative. Очевидно, в таком случае модель не сумела “решить”, куда отнести новость. Наверное поможет, если тут в дело вступится человек и сам разметит таккую новость. Это в двух словах – идея active learning, в данном случае с энтропийным критерием. А критериев может быть много разных. Мы поисследовали несколько из них и остановились на энтропийном (также есть довольно масштабные бенчмарки, пдтверждающие такой выбор).
Довольно приятным открытием был шедулер Ofelia, позволяющий в два счета запускать задачи в docker или docker-compose по расписанию.
") Кривые обучения в зависимости от критерия отбора примеров (активное обучение)
Кривые обучения в зависимости от критерия отбора примеров (активное обучение)
В целом на наших данных разные критерии active learning проявили себя примерно одинаково, и мы выбрали в итоге энтропийный.
Например, можно сгененрировать отрицания на подобие “btc does not drop by 10%” или “btc won’t drop by 10%" и количественно оценить, насколько хорошо модель с ними справляется. Кстати, так мы и пришли к выводы, что BERT нормально поддерживет отрицания.
Другое пример: с помощью NER (Named Entity Recognition) фреймворк поможет на основе новости “china's central bank to continue bitcoin exchange inspections” наплодить много похожих, но упоминающих другие криптовалюты ( "china's central bank to continue ethereum exchange inspections", "china's central bank to continue ripple exchange inspections" и т.д.). После этого можно провести invarience test: проверить, будет ли для модифицированных новостей прогноз таким же, как для исходной новости.
Это исследование также провел @AlexandrinVictor, код тут.
 Модель успешно отличает новые данные от старых
Модель успешно отличает новые данные от старых
В нашем случае обучающая выборка пришла из 2017-2018, а тестовая – из 2022, то что мы сами недавно разметили. И конечно, “распределения съехали”, с 2017-го новости сильно поменялись. Что и было заметно при adversarial validation – даже простая модель легко отличила новые данные от старых.
В качестве бонуса, можно посмотреть на коэффициенты модели и вытащить слова/биграммы наиболее характерные для обучающей или тестовой выборки. Выглядит скорее как развлечение, чем полезный инсайт, но в 2022-м в новостях стали чаще появляться NFT, metaverse, web3 (очевидно), а также oil и cannabis (менее очевидно).
Код, сопровождающий описанный эксперимент – тут.
Правда, на практике заходит это как-то хуже, что я слышу и от коллег. Да и вот свежая статья с ACL 2022 “On the Impact of Data Augmentation on Downstream Performance in Natural Language Processing”, в которой провели немало экспериментов с разными NLP-задачами и техниками аугментации и пришли к выводу, что ни одна из них не помогает стабильно.
Вот и нам не удалось завести аугментации. Возможно, из-за того что новости – короткие, и аугментированные новости получаются слишком похожими на исходные.
 Первая цель – базовое решение
Первая цель – базовое решение
 Вторая цель – продвинутое решение
Вторая цель – продвинутое решение
Мы использовали Notion, в котором можно найти много классных шаблонов – и для OKR, для домашней страницы проекта, доски Kanban и почти чего угодно.
Прогресс трекали с помощью доски Kanban в том же Notion
 Доска Kanban
Доска Kanban
Пользоваться Notion понравилось, даже в бесплатной версии не уперлись ни в какие ограничения. Впрочем, мы использовали минимальный функционал.
 Первая версия архитектуры приложения
Первая версия архитектуры приложения
Идея такая:
В итоге тимлид засучил рукава и запилил первый MVP с мок-версими каждого из компонентов (условно, краулер тащит 50 новостей с https://bitcointicker.co/news, а не делает что-то более умное, не фильтрует новости, хотя надо бы. Моделька – tf-idf & logreg, а не BERT, фронтенд – простая streamlit-демка и т.д.), но с прописанным взаимодействием компонентов. После того как прототип был готов, уже понеслось, понятно было, как совершенствовать каждый из сервисов.
Но получилось, что на какие-то 8-10 дней тимлид был боттлнеком и команда по сути его ждала. Буду рад в коментах обсудить более эффективные варианта старта проекта.
 habr.com
habr.com
Сразу про то, что получилось на выходе: https://cryptobarometer.org/
Первая часть статьи – про предысторию проекта, а также про мотивацию попилить командный проект.
Вторая часть – инженерная, про приложение, архитектуру, решение на основе машинного обучения, а также прикладные исследования, которые мы провели. Эта часть подразумевает, что читатель знаком с основами машинного обучения (если нет – вот пост vas3k “Машинное обучение для людей”).
Третья часть – про организацию работы, сложности, с которыми мы столкнулись, и хаки, повышающие продуктивность команды, к которым мы в итоге пришли.
Предыстория
Я как-то знакомился с SoTA в NLP, делал для стартапа сентимент-анализ новостей о криптовалютах. Ребята начинали с майнинга, накупили 4500 (!) GPU, потом вдруг поняли, что девать их некуда, а биток майнить надо не на GPU, да и электричество в Москве уже дорогое. Переключились на онлайн-банкинг, позволяющий в один щелчок покупать биток в мобильном приложении. Заодно решили добавить AI в питч-дэки, и так я с нуля начал предсказывать сентимент новостей о криптовалютах. Идея в том, что инвестор с утреца берет кофе, читает газеты и составляет некое своем представление о “тональности” новостей о крипте, это может косвенно влиять на его решения о купле/продаже битка.Вот наиболее релевантный существующий проект «Crypto Fear & Greed Index»
Но далее с очередным раундом были сложности, все опять ушло в майнинг, а про Эй-Яй забыли. Так у меня на руках остался веселый недоделанный проект, а также:
Около 4.5к коротких новостей о крипте (типа таких), размеченных на 3 класса: +/-/neutral; Список ресурсов с новостями о криптовалютах, которые стоит обкачивать + PHP-краулер – чисто FYI, использовать я его все равно не собирался ибо PHP, а я датасаентист, уверенно владеющий только питоном; Горстка жупитер-нубуков с вариацией разных подходов, в частности, золотой бейзлайн tf-idf & logreg, подбирающийся к 75% accuracy на кросс-валидации; Демка в Streamlit с уже более-менее нормальным кодом.
Мотивация
Сразу скажу примерно то же, что я выдал стартапу в самом начале: прогнозировать курс битка я не собираюсь. В принципе верю, что можно для этого как-то заюзать тональность новостей (все понимают, что одни только твиты Маска могут неплохо работать), но также поверю своему хорошему другу (а заодно executive director в лондонском голдмане), который утверждает, что без команды из ~10 умных ребят, работающих full-time, побить рыночек очень сложно, почти нереально. Так что я остановился чисто на анализе тональности.Цели участия в проекте были следующие:
- Получить практический технический опыт в сфере MLOps, который можно переиспользовать на работе. Так совпало, что я на работе как раз в это время координировал DS-ов и инженеров в работе над собственной MLOps-платформой, много и сам делал руками, так что курс по MLOps попался под руку очень вовремя;
- Попрактивовать командной работу: планирование, code-review и т.д. Это более-менее понятно, когда гребешь на галере, а вот когда все на чистом энтузиазме делается да в свободное время, тут свои челленджи (например, нет ресурса, чтоб с каждым членом команды провести час в неделю и все обсудить);
- Лично мне не хотелось бросать на полпути недоделанный проект, так что хотелось хотя бы как пет-проджект довести его до ума;
- На выходе иметь демку и проект, которыми не стыдно поделиться, в том числе и на собесе. Как, например, распознавалка цифр в исполнении Андрея Лукьяненко.
Что получилось на выходе
Покажу еще раз фронтенд https://cryptobarometer.org/Есть барометр, показывающий среднюю тональность за сутки, также показываются средние значения тональности неделю назад, месяц назад и строится график этой метрики во времени. Еще показываются несколько последних новостей вместе с прогнозами (можно заметить, что фильтрация новостей все еще можно улучшать: "Iran to shut down Bitcoin miners as electricity demand spikes" – точно плохая новость, а вот "ETC [Etherium Classic] turties should note down these points before setting trigger" - не совсем-то и новость).
Также можно поиграться с моделью – ввести произвольный текст и получить прогнозы – предсказанные значения положительной, нейтральной и негативной тональности.
Это все приятный фронтенд. Теперь бэкенд (тут я пересилил желание вставить пару мемов про фронт vs. бэк).
Финальная схема архитектуры приложения выглядит так:
[IMG alt="Финальная версия архитектуры приложения
"]https://habrastorage.org/r/w1560/ge...4fb0adf432c5b57701b01fed6d.png[/IMG]Финальная версия архитектуры приложения
Логика такая:
- в базе есть таблицы для неразмеченных новостей, прогнозов модели и размеченных новостей;
- краулер ходит в веб, забирает свежие новости и кладет их в базу.
- есть обученная модель и model API, к которому можно обратиться с любым текстом и получить в ответ предсказанные значения для положительной, нейтральной и негативной тональности
- сервис model scorer проверяет свежие новости в базе, если есть, то забирает все новости без прогнозов, дергает model API, получает прогнозы и пишет новости в базу с флагом, что эти новости уже "проскорены";
- есть MLFow-сервер и сервис по обучению моделей model trainer, который забирает данные из базы, обучает модель и логирует артефакты с MLFlow. MLFlow, в свою очередь, использует Minio для хранения артефактов моделей (model registry);
- перед базой мы поставили Data Provider API, у которого различные сервисы могут запросить данные, например, последние 10 новостей, вместо того чтобы ходить напрямую в базу;
- фронтенд получает метрики у Data Provider API, а также может напрямую обращаться к model API, чтоб выдавать прогноз для текста, введенного пользователем;
- Label Studio умеет забирать новости из базы на разметку, предлагает пользователям интерфейс для разметки данных, а также умеет экспортировать размеченные данные в базу;
- наконец, есть Scheduler, запускающий по графику краулер, model scorer и Label Studio, так что каждые 6 часов качаются свежие новости, размечаются моделью, импортируются на разметку, а также раз в сутки размеченные новости экспортируются в базу.
Давайте теперь пройдемся по каждому из компонентов более детально.
База Postgres
Мы пришли к такой схеме таблиц
Есть таблица с сырыми новостями news_titles:
- ID новости (title_id);
- Название новости (title);
- Источник новости (source);
- Дата публикации (pub_time).
Также есть таблица model_predictions с прогнозами модели для каждой новости:
- ID новости (title_id);
- 3 поля под каждый класс – предсказанная вероятность того что новость имеет положительную (positive), нейтральную (neutral) негативную тональность (negative);
- Также помимо предсказанных вероятностей удобно хранить и предсказанный класс – 0, 1 или 2 в зависимости от значений positive, neutral, negative;
- Наконец, есть флаг is_annotating, чтоб мы знали, какие новости мы уже утащили в LabelStudio на разметку, а какие еще нет.
- ID новости (title_id);
- Label (0, 1, 2) - в зависимости от ручной разметки в интерфейсе LabelStudio;
- annotation_time – время разметки.
Краулер
Краулер обкачивает отобранные RSS-фиды (список можно найти в нашей репе) и делает фильтрацию: выкидывает все что не на английском, оставляет только тексты с глаголом (сложно представить новость без единого глагола) и т.д. Далее краулер пишет отфильтрованные новости в таблицу news_titles.Шаг с фильтрацией новостей довольно важен. Оглядываясь назад, при разметке данных мы бы еще просили указать, считает ли эксперт строку текста вообше новостью или нет. Таким образом, была бы надежда, что ML-модель сможит выучить и этот сигнал, помимо тональности. И сейчас у нас в приложении https://cryptobarometer.org/ можно найти “новости”, которые не очень-то и похожи на новости, например:
- “Law Decoded, June 13-20: Celcius exodus and liqudity crisis” (этот кусок текста остался, видимо, из-за слова decoded, перепутанного с глаголом. Модель среагировала на liqudity crisis и выдала всего 1/100, посчитав данный кусок текста очень плохой новостью);
- ETC [Etherium Classic] turties should note down these points before setting trigger (тоже не новость).
API модели
Тут уместно рассказать чуть подробней про задачу и модель, к которой мы в итоге пришли.В начале у нас было 4500 новостей, размеченных на 3 класса частично экспертами, частично – с помощью краудсорсинга (Amazon Mechanical Turk).
Ниже представлен кривые обучения для базовой модели, “золотого NLP-бейзлайна” – логистической регрессии с Tf-Idf-преобразованием текста (если вы ничего не поняли в этой фразе, советую посмотреть открытый курс машинного обучения тут на Хабре, в частности, статью про линейные модели классификации и регрессии).
Простая модель подбирается примерно к 74% верных ответов на кросс-валидации при балансе классов: 45% положительных новостей, 35% – негативных, 20 – нейтральных. Неплохо, хотя мы заметили, что простая модель не понимает даже простых отрицаний, например, и “BTC will drop by 10% tomorrow” и “BTC will not drop by 10% tomorrow” считает негативными новостями.
Впослдествии мы провели немало экспериментов и остановились на BERT модели, у которой доля верных ответов на кросс-валидации – около 81.5%, что уже совсем неплохо, так как замеренный нами уровень согласованности при разметки – от 80% до 90%, то есть BERT уже размечает новости не хуже среднего кожаного мешка.
Модель мы тренируем с MLFlow, о котором чуть ниже, и разворачиваем с FastAPI. В этом репозитории можно увидеть, как именно это делается.
BERT мы задеплоили с ONNX-сериализацией, что позволяет делать эффективный инференс на CPU.
Model scorer
Этот сервис нужен для того, чтобы показывать тональность самых свежих новостей. Сервис по графику проверяет свежие новости в базе и, если они есть, забирает все новости без прогнозов, дергает model API, получает прогнозы и пишет новости в базу с флагом, что эти новости уже "проскорены". Тут в детали вдаваться не очень интересно.MLFlow и сервис обучения моделей
Мы реализовали абстрактный класс для обучения, у котого есть наследники для простой модели tf-idf & logreg и для BERT-модели. Если интересно, исходники тут в модулях models и train.Для трекинга экспериментов и хранения артефактов моделей мы использовали MLFLow в 4-ом сценарии, когда S3 используется для хранения моделей (в нашем случае – Minio), а база Postgres – для хранения метрик экспериментов.
Если хочется это повторить, отправим вас к лекции курса по MLOPs, где Павел Кикин как раз разворачивает описанные сервисы с docker-compose.
Data Provider API
Чтоб сервисы не ходили напрмую в базу, мы развернули перед ней Data Provider API – FastAPI c набором endpoints, по которым можно забрать разные данные и метрики из базы.
Например, можно взять среднюю предсказанную положительную тональность для всех новостей за последние 24 часа. Или значения той же метрики по дням за последнюю неделю.
Фронтенд
Фронтенд общается с Data Provider API, получает данные и отображает их. Например, барометр рисуется на основе запроса к endpoint Data Provider API /positive_score/average_last_hours.Также фронтенд умеет напрямую обращаться к API модели, чтоб отрисовать прогнозы для произвольного текста, введенного пользователем.
Про сам фронтенд в деталях не расскажу, ибо нуб в этом деле (фронтенд у нас разрабатывала Залина @LinkaG). Но вкратце: это React на базе Figma-шаблона.
LabelStudio & active learning
Мы также развернули Label Studio для ручной разметки данных. Идея в том, что мы можем в любой момент доразметить свежие новости.
Label Studio умеет забирать новости из базы на разметку, предлагает пользователям интерфейс для разметки данных и также умеет экспортировать размеченные данные в базу
Мы реализовали active learning – забираются не случайные новости, а те, для которых модель выдает не очень уверенный прогноз, т.е. такие новости более перспективны для разметки. Если не слышали этот термин, советую этот блог пост о том, что делать, когда размеченных данных мало и как отбирать данные на разметку эффективно.
Понятие не очень уверенный прогноз можно определить формально, например, через энтропию прогнозов модели (о применении энтропии в машинном обучении можно почитать, например, в статье открытого курса по машинному обучению, где речь идет о построении деревьев решений). Чем выше энтропия – тем менее модель уверена в прогнозе, в частности, для 3 классов (positive/neutral/negative) энтропия будет максимальна, когда модель выдает равные предсказанные вероятности: ⅓ для positive, ⅓ для neutral и ⅓ для negative. Очевидно, в таком случае модель не сумела “решить”, куда отнести новость. Наверное поможет, если тут в дело вступится человек и сам разметит таккую новость. Это в двух словах – идея active learning, в данном случае с энтропийным критерием. А критериев может быть много разных. Мы поисследовали несколько из них и остановились на энтропийном (также есть довольно масштабные бенчмарки, пдтверждающие такой выбор).
Scheduler
Наконец, у нас есть шедулер, запускающий по графику краулер, model scorer и Label Studio, так что каждые 6 часов качаются свежие новости, размечаются моделью, импортируются на разметку, а также раз в сутки размеченные новости экспортируются в базу.Довольно приятным открытием был шедулер Ofelia, позволяющий в два счета запускать задачи в docker или docker-compose по расписанию.
Прикладные исследования
Помимо собственно разработки всех микросервисов, описанных выше, мы довольно активно рисечили. Опишу только главные находки.Активное обучение
Упомянутый active learning действительно позволяет быстрее достигать хорошего качества модели. Тут @AlexandrinVictorрассмотрел несколько методов применительно к нашей задаче, в том числе и такие нетривиальные как Monte Carlo Dropout (инференс модели делается несколько раз с разными значениями дропаута, получается ансамбль, неопределенность прогнозов считается по дисперсии прогнозов этого ансамбля). Можно посмотреть на этой исследование и как на хороший пример организации эксперимента и вообще написания кода.
В целом на наших данных разные критерии active learning проявили себя примерно одинаково, и мы выбрали в итоге энтропийный.
Checklist для тестирования модели
“Beyond Accuracy: Behavioral Testing of NLP Models with CheckList” - лучшая статья престижной конференции ACL 2019 года. Авторы зарелизили фреймворк, с помощью которого можно прописывать тесты для модели и изучать ее ошибки.Например, можно сгененрировать отрицания на подобие “btc does not drop by 10%” или “btc won’t drop by 10%" и количественно оценить, насколько хорошо модель с ними справляется. Кстати, так мы и пришли к выводы, что BERT нормально поддерживет отрицания.
Другое пример: с помощью NER (Named Entity Recognition) фреймворк поможет на основе новости “china's central bank to continue bitcoin exchange inspections” наплодить много похожих, но упоминающих другие криптовалюты ( "china's central bank to continue ethereum exchange inspections", "china's central bank to continue ripple exchange inspections" и т.д.). После этого можно провести invarience test: проверить, будет ли для модифицированных новостей прогноз таким же, как для исходной новости.
Это исследование также провел @AlexandrinVictor, код тут.
Adversarial Validation для обнаружения дрифта в данных
Adversarial validation – подход, про который я узнал на Kaggle, который, кажется, под разными именами постоянно переизобретается и в академии, и в индустрии. Идея очень проста:- Возьмем наши данные – обучающую и тестовую выборку.
- Оставим признаки, а целевой признак (например, тональность) просто выкинем.
- Вместо целевого признака сделаем простой бинарный – 1-ми пометим тестовую выборку, а 0-ми – обучающую.
- Проводим кросс-валидацию, если ROC AUC близок к 100%, значит, модель легко отличает тестовую выборку от обучающей, есть дрифт. Если ROC AUC близок к 50%, значит, модель не отличает выборки и дрифт не обнаружила.
В нашем случае обучающая выборка пришла из 2017-2018, а тестовая – из 2022, то что мы сами недавно разметили. И конечно, “распределения съехали”, с 2017-го новости сильно поменялись. Что и было заметно при adversarial validation – даже простая модель легко отличила новые данные от старых.
В качестве бонуса, можно посмотреть на коэффициенты модели и вытащить слова/биграммы наиболее характерные для обучающей или тестовой выборки. Выглядит скорее как развлечение, чем полезный инсайт, но в 2022-м в новостях стали чаще появляться NFT, metaverse, web3 (очевидно), а также oil и cannabis (менее очевидно).
Код, сопровождающий описанный эксперимент – тут.
Аугментации данных
Аугментации данных отлично раьотают в задачах компьютерного зрения (см, например, библиотеку albumentations), а вот в NLP с ними как-то все не так однозначно. Есть примеры из Kaggle-соревнований, например, из этого поста я узнал про backtranslation и как это помогло Павлу Остякову затащить соревнование по предсказанию токсичности комментариев, в котром я тоже участвовал. Суть backtranslation в том, что мы расширяем обучающую выборку за счет перевода примеров из исходного языка в какой-то другой, а затем обратно. Например, из английского в немецкий, а потом промежуточный результат на немецком переводим обратно в английский.Правда, на практике заходит это как-то хуже, что я слышу и от коллег. Да и вот свежая статья с ACL 2022 “On the Impact of Data Augmentation on Downstream Performance in Natural Language Processing”, в которой провели немало экспериментов с разными NLP-задачами и техниками аугментации и пришли к выводу, что ни одна из них не помогает стабильно.
Вот и нам не удалось завести аугментации. Возможно, из-за того что новости – короткие, и аугментированные новости получаются слишком похожими на исходные.
Организация работы
После того, как мы рассказали в целом о том, что получилось на выходе, хочется обсудить и организацию работы в команде, а также про челленджи. В целом мы получили отличный опыт, и хочется им поделиться, а заодно порефлексировать о том, что можно было сделать лучше. Основная цель – помочь тем, кто хочет поучаствовть в команде, поработать над классным проектом (не обязательно ML), но не знает, как это делать лучше.Роли в команде
Кажется, что даже в пет-проджекте хорошо бы выделить роли и не толькаться, не бороться за задачи. Еще наблюдение (подкрепленное также опытом командной работы в Kaggle -соревнованиях): оптимальный размер команды – от 3 до 5 человек. Точно не больше 5. Исходя из этого, я выделил следующие роли:- Один ML-инженер. Тут более-менее понятно – делать все то, что изучали в курсе и с чем мы сталкиваемся на практике в рабочих проектах: собирать Docker-контейнеры, настраивать кубер, если надо, CI/CD, деплоить модели, поддерживать model life cycle;
- Два Data Scientist-a/аналитика/ML-исследователя. Это уже атаковать исследовательские задачи, перед тем как позвать народ, я создал список интересных (мне) задач, позже мы набросали еще (можно использовать сервисы типа https://easyretro.io/ для брейнсторминга). Пример: active learning, как отбирать примеры на разметку эффективно. Или исследование ошибок модели (например, наша базовая модель tf-idf & logreg не умела обрабатывать отрицания, "bitcoint won't drop tomorrow" считала плохой новостью, потом пофикисили);
- Один Data Engineer. Тут из задач было сделать краулер новостей, настроить базу для их хранения и т.д.;
- Тимлид (это я оставил за собой). Это координация задач, помощь с затыками, организация процесса работы - двигание тикетов, подбадривание, шутки. Истории из прошлых релевантных проектов. Предполагается, что тимлид еще не разучился писать код и мержить ветки.
Цели
При работе над бодрым пет-проджектом хочется сохранить некоторый баланс - не тащить прям все процессы "с галеры", то есть то, что мы в практикуем в ежедневной работе – OKR (Objectives & Key Results), стендапы, ретро и прочие Agile-ритуалы. Но все же хочется хорошо понимать, что мы командой хотим достичь за ближайшие ~2 месяца. Поэтому я сформулировал цели, которые мы хотим достичь, в формате OKR (про фреймворк Objectives & Key Results неплохо пишет Atlassian). Выглядело это так:
Мы использовали Notion, в котором можно найти много классных шаблонов – и для OKR, для домашней страницы проекта, доски Kanban и почти чего угодно.
Scrum и спринты
Мы работали спринтами по 3 недели и встречались 1-2 раза в неделю на полчаса-час. В нашем небольшом проекте было всего 2 спринта по 3 недели, которые неплохо соотносились с представленными выше OKR – один спринт на MVP-решение, один – на продвинутое.Прогресс трекали с помощью доски Kanban в том же Notion
Пользоваться Notion понравилось, даже в бесплатной версии не уперлись ни в какие ограничения. Впрочем, мы использовали минимальный функционал.
MVP и основные сложности
Я подробно описал решение, полученное на выходе. Но хочется также описать, как мы к этому шли и какие сложности были по дороге. Мы начали с того, что тимлид (я) набросал первую архитектуру решения, выделил основные компоненты и раскидал задачи, т.е реализацию компонентов, по людям ("ты пиши краулер, а ты – сделай плз model inference API"). Выглядела первая схема так:
Идея такая:
- краулер по графику ходит в веб, забирает свежие новости и кладет их в базу;
- есть обученная модель и model API, к которому можно обратиться с любым текстом и получить в ответ предсказанные значения для положительной, нейтральной и негативной тональности;
- сервис model scorer проверяет свежие новости в базе, если есть, то забирает все новости без прогнозов, дергает model API, получает прогнозы и пишет новости в базу с флагом, что эти новости уже "проскорены";
- фронтенд общается с базой, забирая какую-то метрику (например, средняя за день предсказанная величина положительной тональности) и рисует ее. Также фронтенд может напрямую общаться с model API, чтоб выдавать прогноз для текста, введенного пользователем.
В итоге тимлид засучил рукава и запилил первый MVP с мок-версими каждого из компонентов (условно, краулер тащит 50 новостей с https://bitcointicker.co/news, а не делает что-то более умное, не фильтрует новости, хотя надо бы. Моделька – tf-idf & logreg, а не BERT, фронтенд – простая streamlit-демка и т.д.), но с прописанным взаимодействием компонентов. После того как прототип был готов, уже понеслось, понятно было, как совершенствовать каждый из сервисов.
Но получилось, что на какие-то 8-10 дней тимлид был боттлнеком и команда по сути его ждала. Буду рад в коментах обсудить более эффективные варианта старта проекта.
Выводы
Несмотря на описанные сложности, хочется закончить на позитивной ноте и поделиться тем, к чему мы пришли (можно рассматривать как советы начинающим DS-ам или разработчикам):- Поработать в команде над интересным проектом – очень крутой опыт, он и сам по себе полезен, и “продавать” его тоже можно на собеседованиях.
- Очень важно иметь дедлайн, скажем, конец соревнования на Kaggle или окончание курса.
- Оптимальный размер команды – от 3 до 5 человек. Недаром и на Kaggle к этому пришли.
- Хорошо бы довести пет-проект до красивой демки, на которую можно и в резюме сослаться и в любой ситуации хоть в лифте показать.
- Немного “галеры” привнести в душевный пет-проект не помешает: если обозначить цели (можно в формате OKR) и настроить базовые Scrum-ритуалы, будет более четкое понимание, кто что делает и куда команда движется.
- Здорово в начале сотрудничества побрейнстормить: собраться и накидать идей, обсудить и приоретизировать (сервисы типа https://easyretro.io/ хорошо для этого подходят).
- Очень помогает делать мини-демки внутри команды. Даже если встречаться всего на час в неделю, имеет смысл начать с 20-минутной демки кого-то из участников (например, продемонстрировать продвижения с фронтендом или сервисом LabelStudio), а потом уже обычный стендап с обсуждением текущих задач.
- Юрий Кашницкий @yorko – тимлид, техлид, везде по чуть-чуть.
- Виктор Александрин @AlexandrinVictor (LinkedIn, GitHub) – очень продуктивный и MLE, и исследователь.
- Залина Русинова @LinkaG – фронтенд-разработчик, исследователь.
- Арсений Глотов @senyasenyasenya (LinkedIn) – MLE, Data Engineer.
Эй-Яй, крипта, MLOps и командный пет-проджект
Привет! Усаживайтесь поудобней, в этой статье я расскажу, как мы командой пилили пет-проджект в рамках курса ODS по MLOps. Покажу не только финальный результат, но и немного расскажу про процесс...
habr.com