MongoDB — одна из самых популярных NoSQL/документоориентированных баз данных в мире веб-разработки, поэтому многие наши клиенты используют её в своих продуктах, в том числе и в production. Значительная их часть функционирует в Kubernetes, так что хотелось бы поделиться накопленным опытом: какие варианты для запуска Mongo в K8s существуют? В чем их особенности? Как мы сами подошли к этому вопросу?
Ведь не секрет: несмотря на то, что Kubernetes предоставляет большое количество преимуществ в масштабировании и администрировании приложений, если делать это без должного планирования и внимательности, можно получить больше неприятностей, чем пользы. То же самое касается и MongoDB в Kubernetes.
К счастью, на данный момент практически любой провайдер может предоставить любой тип хранилища на ваш выбор: от сетевых дисков до локальных с внушительным запасом по iops. Для динамического расширения кластера MongoDB подойдут только сетевые диски, но мы должны учитывать, что они всё же проигрывают в производительности локальным. Пример из Google Cloud:
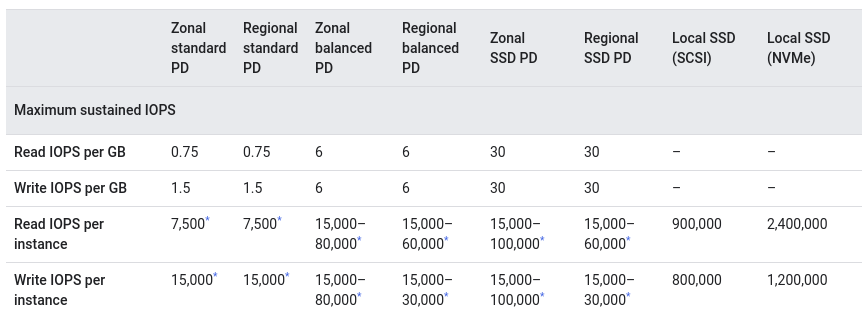
А также они могут зависеть от дополнительных факторов:

В AWS картина чуть лучше, но всё ещё далека от производительности, что мы видим для локального варианта:
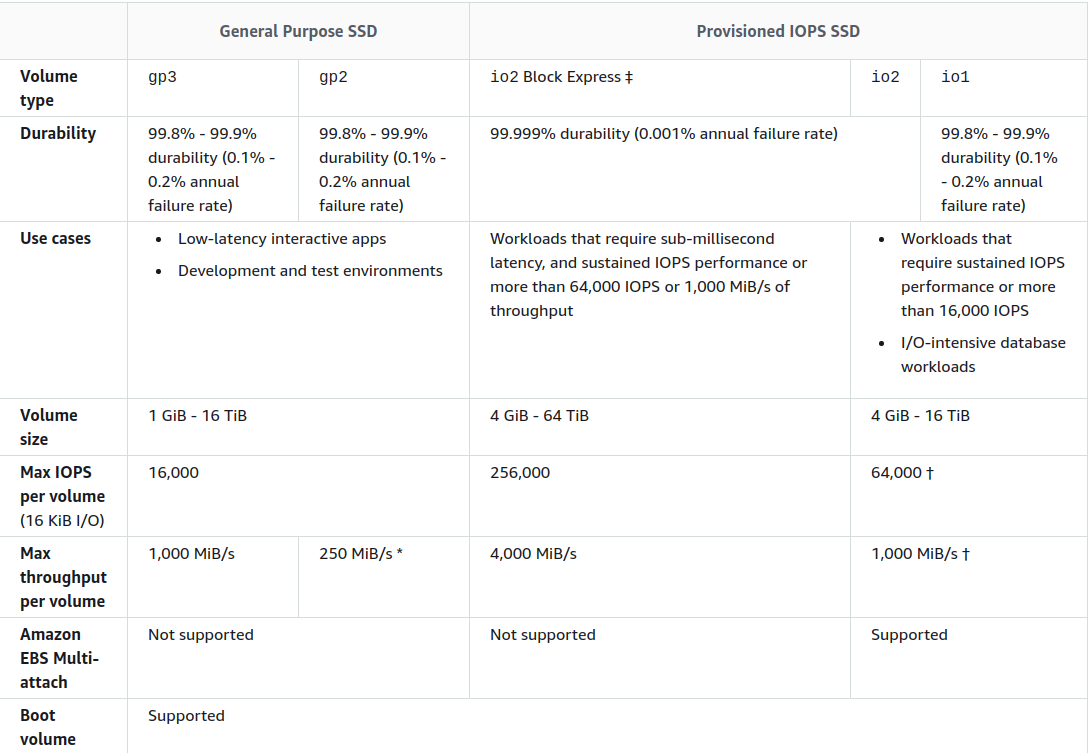
В нашем практике ещё ни разу не понадобилось добиваться такой производительности для MongoDB: в большинстве случаев хватает того, что предоставляют провайдеры.
Чарт позволяет запускать MongoDB несколькими способами:
Чарт хорошо параметризован и документирован. Обратная сторона медали: из-за обилия функций в нём придется посидеть и разобраться, что вам действительно нужно, потому использование этого чарта очень сильно напоминает конструктор, который позволяет собрать самому конфигурацию которая вам нужна.
Минимальная конфигурация, которая понадобится для поднятия, — это:
1. Указать архитектуру (Values.yaml#L58-L60). По умолчанию это standalone, но нас интересует replicaset:
...
architecture: replicaset
...
2. Указать тип и размер хранилища (Values.yaml#L442-L463):
...
persistence:
enabled: true
storageClass: "gp2" # у нас это general purpose 2 из AWS
accessModes:
- ReadWriteOnce
size: 120Gi
...
После этого через helm install мы получаем готовый кластер MongoDB с инструкцией, как к нему подключиться из Kubernetes:
NAME: mongobitnami
LAST DEPLOYED: Fri Feb 26 09:00:04 2021
NAMESPACE: mongodb
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
** Please be patient while the chart is being deployed **
MongoDB(R) can be accessed on the following DNS name(s) and ports from within your cluster:
mongobitnami-mongodb-0.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017
mongobitnami-mongodb-1.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017
mongobitnami-mongodb-2.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017
To get the root password run:
export MONGODB_ROOT_PASSWORD=$(kubectl get secret --namespace mongodb mongobitnami-mongodb -o jsonpath="{.data.mongodb-root-password}" | base64 --decode)
To connect to your database, create a MongoDB(R) client container:
kubectl run --namespace mongodb mongobitnami-mongodb-client --rm --tty -i --restart='Never' --env="MONGODB_ROOT_PASSWORD=$MONGODB_ROOT_PASSWORD" --image docker.io/bitnami/mongodb:4.4.4-debian-10-r0 --command -- bash
Then, run the following command:
mongo admin --host "mongobitnami-mongodb-0.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017,mongobitnami-mongodb-1.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017,mongobitnami-mongodb-2.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017" --authenticationDatabase admin -u root -p $MONGODB_ROOT_PASSWORD
В пространстве имен увидим готовый кластер с арбитром (он enabled в чарте по умолчанию):

Но такая минимальная конфигурация не отвечает главным вызовам, перечисленным в начале статьи. Поэтому советую включить в неё следующее:
1. Установить PDB (по умолчанию он выключен). Мы не хотим терять кластер в случае drain’а узлов — можем позволить себе недоступность максимум 1 узла (Values.yaml#L430-L437):
...
pdb:
create: true
maxUnavailable: 1
...
2. Установить requests и limits (Values.yaml#L350-L360):
...
resources:
limits:
memory: 8Gi
requests:
cpu: 4
memory: 4Gi
...
В дополнение к этому можно повысить приоритет у pod’ов с базой относительно других pod’ов (Values.yaml#L326).
3. По умолчанию чарт создает нежесткое anti-affinity для pod’ов кластера. Это означает, что scheduler будет стараться не назначать pod’ы на одни и те же узлы, но если выбора не будет, то начнет размещать туда, где есть место.
Если у нас достаточно узлов и ресурсов, стоит сделать так, чтобы ни в коем случае не выносить две реплики кластера на один и тот же узел (Values.yaml#L270):
...
podAntiAffinityPreset: hard
...
Сам же запуск кластера в чарте происходит по следующему алгоритму:
local persisted=false
info "Initializing MongoDB..."
rm -f "$MONGODB_PID_FILE"
mongodb_copy_mounted_config
mongodb_set_net_conf
mongodb_set_log_conf
mongodb_set_storage_conf
if is_dir_empty "$MONGODB_DATA_DIR/db"; then
info "Deploying MongoDB from scratch..."
ensure_dir_exists "$MONGODB_DATA_DIR/db"
am_i_root && chown -R "$MONGODB_DAEMON_USER" "$MONGODB_DATA_DIR/db"
mongodb_start_bg
mongodb_create_users
if [[ -n "$MONGODB_REPLICA_SET_MODE" ]]; then
if [[ -n "$MONGODB_REPLICA_SET_KEY" ]]; then
mongodb_create_keyfile "$MONGODB_REPLICA_SET_KEY"
mongodb_set_keyfile_conf
fi
mongodb_set_replicasetmode_conf
mongodb_set_listen_all_conf
mongodb_configure_replica_set
fi
mongodb_stop
else
persisted=true
mongodb_set_auth_conf
info "Deploying MongoDB with persisted data..."
if [[ -n "$MONGODB_REPLICA_SET_MODE" ]]; then
if [[ -n "$MONGODB_REPLICA_SET_KEY" ]]; then
mongodb_create_keyfile "$MONGODB_REPLICA_SET_KEY"
mongodb_set_keyfile_conf
fi
if [[ "$MONGODB_REPLICA_SET_MODE" = "dynamic" ]]; then
mongodb_ensure_dynamic_mode_consistency
fi
mongodb_set_replicasetmode_conf
fi
fi
mongodb_set_auth_conf
}
Этот чарт не умеет запускать Replica Set + Arbiter и использует маленький сторонний образ в init-контейнерах, но в остальном достаточно прост и отлично выполняет задачу деплоя небольшого кластера.
Мы стали использовать его в своих проектах задолго до того, как он стал deprecated (а это произошло не так давно — 10 сентября 2020 года). За минувшее время чарт сильно изменился, однако в то же время сохранил основную логику работы. Для своих задач мы сильно урезали чарт, сделав его максимально лаконичным и убрав всё лишнее: шаблонизацию и функции, которые неактуальны для наших задач.
Минимальная конфигурация сильно схожа с предыдущим чартом, поэтому подробно останавливаться на ней не буду — только отмечу, что affinity придется задавать вручную (Values.yaml#L108):
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: mongodb-replicaset
Алгоритм его работы схож с чартом от Bitnami, но менее нагружен (нет такого нагромождения маленьких скриптов с функциями):
1. Init-контейнер copyconfig копирует конфиг из configdb-readonly (ConfigMap) и ключ из секрета в директорию для конфигов (emptyDir, который будет смонтирован в основной контейнер).
2. Секретный образ unguiculus/mongodb-install копирует исполнительный файл peer-finder в work-dir.
3. Init-контейнер bootstrap запускает peer-finder с параметром /init/on-start.sh — этот скрипт занимается поиском поднятых узлов кластера MongoDB и добавлением их в конфигурационный файл Mongo.
4. Скрипт /init/on-start.sh отрабатывает в зависимости от конфигурации, передаваемой ему через переменные окружения (аутентификация, добавление дополнительных пользователей, генерация SSL-сертификатов…), плюс может исполнять дополнительные кастомные скрипты, которые мы хотим запускать перед стартом базы.
5. Список пиров получают как:
args:
- -on-start=/init/on-start.sh
- "-service=mongodb"
log "Reading standard input..."
while read -ra line; do
if [[ "${line}" == *"${my_hostname}"* ]]; then
service_name="$line"
fi
peers=("${peers[@]}" "$line")
done
6. Выполняется проверка по списку пиров: кто из них — primary, а кто — master.
8. Запускается сам процесс MongoDB.
Однако мы рассматриваем community-версию, которая ограничена в возможностях и не подлежит сильной кастомизации — опять же, если сравнивать с чартами, представленными выше. Это вполне логично, учитывая, что существует также и enterprise-редакция.
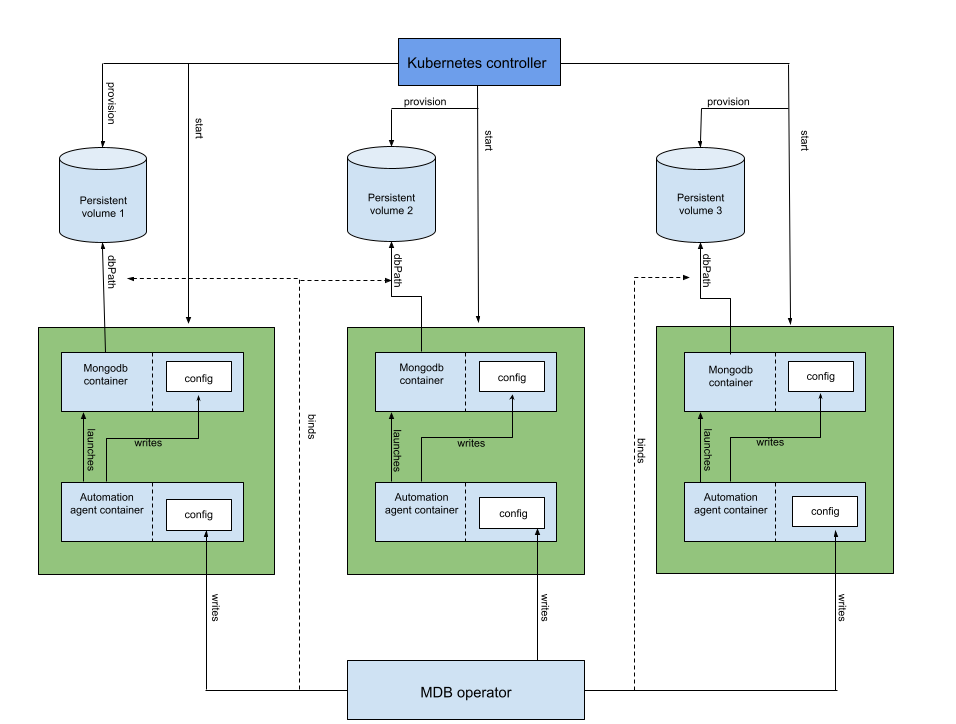
Архитектура оператора:
В отличие от обычной установки через Helm в данном случае понадобится установить сам оператор и CRD (CustomResourceDefinition), что будет использоваться для создания объектов в Kubernetes.
Установка кластера оператором выглядит следующим образом:
---
apiVersion: mongodb.com/v1
kind: MongoDBCommunity
metadata:
name: example-mongodb
spec:
members: 3
type: ReplicaSet
version: "4.2.6"
security:
authentication:
modes: ["SCRAM"]
users:
- name: my-user
db: admin
passwordSecretRef: # ссылка на секрет ниже для генерации пароля юзера
name: my-user-password
roles:
- name: clusterAdmin
db: admin
- name: userAdminAnyDatabase
db: admin
scramCredentialsSecretName: my-scram
# учетная запись пользователя генерируется из этого секрета
# после того, как она будет создана, секрет больше не потребуется
---
apiVersion: v1
kind: Secret
metadata:
name: my-user-password
type: Opaque
stringData:
password: 58LObjiMpxcjP1sMDW
Преимущество данного оператора в том, что он способен масштабировать количество реплик в кластере вверх и вниз, а также выполнять upgrade и даже downgrade, делая это беспростойно. Также он умеет создавать кастомные роли и пользователей.
Но в то же время он уступает предыдущим вариантам тем, что у него нет встроенной возможности отдачи метрик в Prometheus, а вариант запуска только один — Replica Set (нельзя создать арбитра). Кроме того, данный способ развертывания не получится сильно кастомизировать, т.к. практически все параметры регулируются через кастомную сущность для поднятия кластера, а сама она ограничена.
На момент написания статьи community-версия оператора имеет очень краткую документацию, не описывающую конфигурацию в подробностях, и это вызывает множество проблем при дебаге тех или иных случаев.
Как уже упоминалось, существует и enterprise-версия оператора, которая предоставляет большие возможности — в том числе, установку не только Replica Set’ов, но и shared-кластеров с настройками шардирования, конфигурации для доступа извне кластера (с указанием имен, по которым он будет доступен извне), дополнительные способы аутентификации т.д. И, конечно же, документация к нему описана гораздо лучше.
У разных вариантов запуска MongoDB есть разные плюсы. Чарты легко модифицировать под ваши нужды, но вы столкнетесь с проблемами при обновлении MongoDB или при добавлении узлов, т.к. всё равно потребуются ручные операции с кластером. Способ с оператором в этом смысле лучше, но ограничен по другим параметрам (по крайней мере, в своей community-редакции). Также мы не нашли ни в одном из описанных вариантов возможность из коробки запускать скрытые реплики.
Наконец, не стоит забывать, что есть и managed-решения для Mongo, однако мы в своей практике стараемся не привязываться к определенным провайдерам и предпочитаем варианты для «чистого» Kubernetes. Мы также не рассматривали Percona Kubernetes Operator for PSMDB, потому что он ориентирован на вариацию MongoDB от одноимённой компании (Percona Server for MongoDB).
Источник статьи: https://habr.com/ru/company/flant/blog/549040/
Ведь не секрет: несмотря на то, что Kubernetes предоставляет большое количество преимуществ в масштабировании и администрировании приложений, если делать это без должного планирования и внимательности, можно получить больше неприятностей, чем пользы. То же самое касается и MongoDB в Kubernetes.
Главные вызовы
В частности, при размещении Mongo в кластере важно учитывать:- Хранилище. Для гибкой работы в Kubernetes для Mongo лучше всего подойдут удаленные хранилища, которые можно переключать между узлами, если понадобится переместить Mongo при обновлении узлов кластера или их удалении. Однако удаленные диски обычно предоставляются с более низким показателем iops (в сравнении с локальными). Если база является высоконагруженной и требуются хорошие показания по latency, то на это стоит обратить внимание в первую очередь.
- Правильные requests и limits на pod’ах с репликами Mongo (и соседствующих с ними pod’ами на узле). Если не настроить их правильно, то — поскольку Kubernetes более «приветлив» к stateless-приложениям — можно получить нежелательное поведение, когда при внезапно возросшей нагрузке на узле Kubernetes начнет убивать pod’ы с репликами Mongo и переносить их на соседние, менее загруженные. Это вдвойне неприятно по той причине, что перед тем, как pod с Mongo поднимется на другом узле, может пройти значительное время. Всё становится совсем плохо, если упавшая реплика была primary, т.к. это приведет к перевыборам: вся запись встанет, а приложение должно быть к этому готово и/или будет простаивать.
- В дополнение к предыдущему пункту: даже если случился пик нагрузки, в Kubernetes есть возможность быстро отмасштабировать узлы и перенести Mongo на узлы с большими ресурсами. Потому не стоит забывать про podDisruptionBudget, что не позволит удалять или переносить pod’ы разом, старательно поддерживая указанное количество реплик в рабочем состоянии.
К счастью, на данный момент практически любой провайдер может предоставить любой тип хранилища на ваш выбор: от сетевых дисков до локальных с внушительным запасом по iops. Для динамического расширения кластера MongoDB подойдут только сетевые диски, но мы должны учитывать, что они всё же проигрывают в производительности локальным. Пример из Google Cloud:
А также они могут зависеть от дополнительных факторов:
В AWS картина чуть лучше, но всё ещё далека от производительности, что мы видим для локального варианта:
В нашем практике ещё ни разу не понадобилось добиваться такой производительности для MongoDB: в большинстве случаев хватает того, что предоставляют провайдеры.
Каким образом можно поднять MongoDB в Kubernetes?
Очевидно, что в любой ситуации (и Mongo здесь не будет исключением) можно обойтись самописными решениями, подготовив несколько манифестов со StatefulSet и init-скриптом. Но далее мы рассмотрим уже существующие подходы, которые «давно придумали за нас».1. Helm-чарт от Bitnami
И первое, что привлекает внимание, — это Helm-чарт от Bitnami. Он довольно популярен, создан и поддерживается значительно долгое время.Чарт позволяет запускать MongoDB несколькими способами:
- standalone;
- Replica Set (здесь и далее по умолчанию подразумевается терминология MongoDB; если речь пойдет про ReplicaSet в Kubernetes, на это будет явное указание);
- Replica Set + Arbiter.
Чарт хорошо параметризован и документирован. Обратная сторона медали: из-за обилия функций в нём придется посидеть и разобраться, что вам действительно нужно, потому использование этого чарта очень сильно напоминает конструктор, который позволяет собрать самому конфигурацию которая вам нужна.
Минимальная конфигурация, которая понадобится для поднятия, — это:
1. Указать архитектуру (Values.yaml#L58-L60). По умолчанию это standalone, но нас интересует replicaset:
...
architecture: replicaset
...
2. Указать тип и размер хранилища (Values.yaml#L442-L463):
...
persistence:
enabled: true
storageClass: "gp2" # у нас это general purpose 2 из AWS
accessModes:
- ReadWriteOnce
size: 120Gi
...
После этого через helm install мы получаем готовый кластер MongoDB с инструкцией, как к нему подключиться из Kubernetes:
NAME: mongobitnami
LAST DEPLOYED: Fri Feb 26 09:00:04 2021
NAMESPACE: mongodb
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
** Please be patient while the chart is being deployed **
MongoDB(R) can be accessed on the following DNS name(s) and ports from within your cluster:
mongobitnami-mongodb-0.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017
mongobitnami-mongodb-1.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017
mongobitnami-mongodb-2.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017
To get the root password run:
export MONGODB_ROOT_PASSWORD=$(kubectl get secret --namespace mongodb mongobitnami-mongodb -o jsonpath="{.data.mongodb-root-password}" | base64 --decode)
To connect to your database, create a MongoDB(R) client container:
kubectl run --namespace mongodb mongobitnami-mongodb-client --rm --tty -i --restart='Never' --env="MONGODB_ROOT_PASSWORD=$MONGODB_ROOT_PASSWORD" --image docker.io/bitnami/mongodb:4.4.4-debian-10-r0 --command -- bash
Then, run the following command:
mongo admin --host "mongobitnami-mongodb-0.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017,mongobitnami-mongodb-1.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017,mongobitnami-mongodb-2.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017" --authenticationDatabase admin -u root -p $MONGODB_ROOT_PASSWORD
В пространстве имен увидим готовый кластер с арбитром (он enabled в чарте по умолчанию):
Но такая минимальная конфигурация не отвечает главным вызовам, перечисленным в начале статьи. Поэтому советую включить в неё следующее:
1. Установить PDB (по умолчанию он выключен). Мы не хотим терять кластер в случае drain’а узлов — можем позволить себе недоступность максимум 1 узла (Values.yaml#L430-L437):
...
pdb:
create: true
maxUnavailable: 1
...
2. Установить requests и limits (Values.yaml#L350-L360):
...
resources:
limits:
memory: 8Gi
requests:
cpu: 4
memory: 4Gi
...
В дополнение к этому можно повысить приоритет у pod’ов с базой относительно других pod’ов (Values.yaml#L326).
3. По умолчанию чарт создает нежесткое anti-affinity для pod’ов кластера. Это означает, что scheduler будет стараться не назначать pod’ы на одни и те же узлы, но если выбора не будет, то начнет размещать туда, где есть место.
Если у нас достаточно узлов и ресурсов, стоит сделать так, чтобы ни в коем случае не выносить две реплики кластера на один и тот же узел (Values.yaml#L270):
...
podAntiAffinityPreset: hard
...
Сам же запуск кластера в чарте происходит по следующему алгоритму:
- Запускаем StatefulSet с нужным числом реплик и двумя init-контейнерами: volume-permissions и auto-discovery.
- Volume-permissions создает директорию для данных и выставляет права на неё.
- Auto-discovery ждёт, пока появятся все сервисы, и пишет их адреса в shared_file, который является точкой передачи конфигурации между init-контейнером и основным контейнером.
- Запускается основной контейнер с подменой command, определяются переменные для entrypoint’а и run.sh.
- Запускается entrypoint.sh, который вызывает каскад из вложенных друг в друга Bash-скриптов с вызовом описанных в них функций.
- В конечном итоге инициализируется MongoDB через такую функцию:
local persisted=false
info "Initializing MongoDB..."
rm -f "$MONGODB_PID_FILE"
mongodb_copy_mounted_config
mongodb_set_net_conf
mongodb_set_log_conf
mongodb_set_storage_conf
if is_dir_empty "$MONGODB_DATA_DIR/db"; then
info "Deploying MongoDB from scratch..."
ensure_dir_exists "$MONGODB_DATA_DIR/db"
am_i_root && chown -R "$MONGODB_DAEMON_USER" "$MONGODB_DATA_DIR/db"
mongodb_start_bg
mongodb_create_users
if [[ -n "$MONGODB_REPLICA_SET_MODE" ]]; then
if [[ -n "$MONGODB_REPLICA_SET_KEY" ]]; then
mongodb_create_keyfile "$MONGODB_REPLICA_SET_KEY"
mongodb_set_keyfile_conf
fi
mongodb_set_replicasetmode_conf
mongodb_set_listen_all_conf
mongodb_configure_replica_set
fi
mongodb_stop
else
persisted=true
mongodb_set_auth_conf
info "Deploying MongoDB with persisted data..."
if [[ -n "$MONGODB_REPLICA_SET_MODE" ]]; then
if [[ -n "$MONGODB_REPLICA_SET_KEY" ]]; then
mongodb_create_keyfile "$MONGODB_REPLICA_SET_KEY"
mongodb_set_keyfile_conf
fi
if [[ "$MONGODB_REPLICA_SET_MODE" = "dynamic" ]]; then
mongodb_ensure_dynamic_mode_consistency
fi
mongodb_set_replicasetmode_conf
fi
fi
mongodb_set_auth_conf
}
2. «Устаревший» чарт
Если поискать чуть глубже, можно обнаружить еще и старый чарт в главном репозитории Helm. Ныне он deprecated (в связи с выходом Helm 3 — подробности см. здесь), но продолжает поддерживаться и использоваться различными организациями независимо друг от друга в своих репозиториях — например, здесь им занимается норвежский университет UiB.Этот чарт не умеет запускать Replica Set + Arbiter и использует маленький сторонний образ в init-контейнерах, но в остальном достаточно прост и отлично выполняет задачу деплоя небольшого кластера.
Мы стали использовать его в своих проектах задолго до того, как он стал deprecated (а это произошло не так давно — 10 сентября 2020 года). За минувшее время чарт сильно изменился, однако в то же время сохранил основную логику работы. Для своих задач мы сильно урезали чарт, сделав его максимально лаконичным и убрав всё лишнее: шаблонизацию и функции, которые неактуальны для наших задач.
Минимальная конфигурация сильно схожа с предыдущим чартом, поэтому подробно останавливаться на ней не буду — только отмечу, что affinity придется задавать вручную (Values.yaml#L108):
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: mongodb-replicaset
Алгоритм его работы схож с чартом от Bitnami, но менее нагружен (нет такого нагромождения маленьких скриптов с функциями):
1. Init-контейнер copyconfig копирует конфиг из configdb-readonly (ConfigMap) и ключ из секрета в директорию для конфигов (emptyDir, который будет смонтирован в основной контейнер).
2. Секретный образ unguiculus/mongodb-install копирует исполнительный файл peer-finder в work-dir.
3. Init-контейнер bootstrap запускает peer-finder с параметром /init/on-start.sh — этот скрипт занимается поиском поднятых узлов кластера MongoDB и добавлением их в конфигурационный файл Mongo.
4. Скрипт /init/on-start.sh отрабатывает в зависимости от конфигурации, передаваемой ему через переменные окружения (аутентификация, добавление дополнительных пользователей, генерация SSL-сертификатов…), плюс может исполнять дополнительные кастомные скрипты, которые мы хотим запускать перед стартом базы.
5. Список пиров получают как:
args:
- -on-start=/init/on-start.sh
- "-service=mongodb"
log "Reading standard input..."
while read -ra line; do
if [[ "${line}" == *"${my_hostname}"* ]]; then
service_name="$line"
fi
peers=("${peers[@]}" "$line")
done
6. Выполняется проверка по списку пиров: кто из них — primary, а кто — master.
- Если не primary, то пир добавляется к primary в кластер.
- Если это самый первый пир, он инициализирует себя и объявляется мастером.
8. Запускается сам процесс MongoDB.
3. Официальный оператор
В 2020 году вышел в свет официальный Kubernetes-оператор community-версии MongoDB. Он позволяет легко разворачивать, обновлять и масштабировать кластер MongoDB. Кроме того, оператор гораздо проще чартов в первичной настройке.Однако мы рассматриваем community-версию, которая ограничена в возможностях и не подлежит сильной кастомизации — опять же, если сравнивать с чартами, представленными выше. Это вполне логично, учитывая, что существует также и enterprise-редакция.
Архитектура оператора:
В отличие от обычной установки через Helm в данном случае понадобится установить сам оператор и CRD (CustomResourceDefinition), что будет использоваться для создания объектов в Kubernetes.
Установка кластера оператором выглядит следующим образом:
- Оператор создает StatefulSet, содержащий pod’ы с контейнерами MongoDB. Каждый из них — член ReplicaSet’а в Kubernetes.
- Создается и обновляется конфиг для sidecar-контейнера агента, который будет конфигурировать MongoDB в каждом pod’е. Конфиг хранится в Kubernetes-секрете.
- Создается pod с одним init-контейнером и двумя основными.
- Init-контейнер копирует бинарный файл хука, проверяющего версию MongoDB, в общий empty-dir volume (для его передачи в основной контейнер).
- Контейнер для агента MongoDB выполняет управление основным контейнером с базой: конфигурация, остановка, рестарт и внесение изменений в конфигурацию.
- Далее контейнер с агентом на основе конфигурации, указанной в Custom Resource для кластера, генерирует конфиг для самой MongoDB.
---
apiVersion: mongodb.com/v1
kind: MongoDBCommunity
metadata:
name: example-mongodb
spec:
members: 3
type: ReplicaSet
version: "4.2.6"
security:
authentication:
modes: ["SCRAM"]
users:
- name: my-user
db: admin
passwordSecretRef: # ссылка на секрет ниже для генерации пароля юзера
name: my-user-password
roles:
- name: clusterAdmin
db: admin
- name: userAdminAnyDatabase
db: admin
scramCredentialsSecretName: my-scram
# учетная запись пользователя генерируется из этого секрета
# после того, как она будет создана, секрет больше не потребуется
---
apiVersion: v1
kind: Secret
metadata:
name: my-user-password
type: Opaque
stringData:
password: 58LObjiMpxcjP1sMDW
Преимущество данного оператора в том, что он способен масштабировать количество реплик в кластере вверх и вниз, а также выполнять upgrade и даже downgrade, делая это беспростойно. Также он умеет создавать кастомные роли и пользователей.
Но в то же время он уступает предыдущим вариантам тем, что у него нет встроенной возможности отдачи метрик в Prometheus, а вариант запуска только один — Replica Set (нельзя создать арбитра). Кроме того, данный способ развертывания не получится сильно кастомизировать, т.к. практически все параметры регулируются через кастомную сущность для поднятия кластера, а сама она ограничена.
На момент написания статьи community-версия оператора имеет очень краткую документацию, не описывающую конфигурацию в подробностях, и это вызывает множество проблем при дебаге тех или иных случаев.
Как уже упоминалось, существует и enterprise-версия оператора, которая предоставляет большие возможности — в том числе, установку не только Replica Set’ов, но и shared-кластеров с настройками шардирования, конфигурации для доступа извне кластера (с указанием имен, по которым он будет доступен извне), дополнительные способы аутентификации т.д. И, конечно же, документация к нему описана гораздо лучше.
Заключение
Возможность использования масштабируемой базы внутри Kubernetes — это неплохой способ унифицировать инфраструктуру на один лад, подстроить под одну среду и гибко управлять ресурсами для приложения. Однако без должной осторожности, внимания к деталям и планирования это может стать большой головной болью (впрочем, это справедливо не только для Kubernetes, но и без него…).У разных вариантов запуска MongoDB есть разные плюсы. Чарты легко модифицировать под ваши нужды, но вы столкнетесь с проблемами при обновлении MongoDB или при добавлении узлов, т.к. всё равно потребуются ручные операции с кластером. Способ с оператором в этом смысле лучше, но ограничен по другим параметрам (по крайней мере, в своей community-редакции). Также мы не нашли ни в одном из описанных вариантов возможность из коробки запускать скрытые реплики.
Наконец, не стоит забывать, что есть и managed-решения для Mongo, однако мы в своей практике стараемся не привязываться к определенным провайдерам и предпочитаем варианты для «чистого» Kubernetes. Мы также не рассматривали Percona Kubernetes Operator for PSMDB, потому что он ориентирован на вариацию MongoDB от одноимённой компании (Percona Server for MongoDB).
Источник статьи: https://habr.com/ru/company/flant/blog/549040/