Платформе 8.х почти 19 лет, идет ли она в ногу со временем?
На сайте releases.1c.ru первые релизы 1с 8.х датируются 2003 годом. В промышленной эксплуатации был оперативный учет, а бухгалтерский и механизм сложных периодических расчетов (зарплата) были в бэта тестировании.
С тех пор платформа до версии 8.3 нарастила функционал во многих направлениях, казалось бы там есть все что нужно для автоматизации учета , создания веб\мобильных приложений, готовые типовые конфигурации. Беглый просмотр архитектуры https://v8.1c.ru/platforma/ вызывает желание автоматизировать все, что возможно на предприятии напр. полную цепочку от продаж до учета. Если оценивать запас прочности системы на рост данных, объема операций, подключений – платформа предлагает масштабируемый на нужное число серверов сервер приложений 1С. Механизм фоновых заданий позволяет обрабатывать наборы операций (пакеты) параллельно.
Неужели у нас есть все что нужно для комфортного внедрения и можно спокойно смотреть в будущее? К сожалению нет и проблема кроется в организации языка программирования 1С, он изначально не рассчитан на горизонтальное масштабирование. Под горизонтальным масштабированием подразумевается:
«разбиение системы на более мелкие структурные компоненты и разнесение их по отдельным физическим машинам (или их группам), и (или) увеличение количества серверов, параллельно выполняющих одну и ту же функцию. Масштабируемость в этом контексте означает возможность добавлять к системе новые узлы, серверы для увеличения общей производительности. Этот способ масштабирования может требовать внесения изменений в программы, чтобы программы могли в полной мере пользоваться возросшим количеством ресурсов».
Термин допускает разные трактовки в зависимости от архитектуры и задач (пример).
Кстати фирма 1С под масштабируемостью подразумевает совсем другое.
Именно сейчас горизонтальное масштабирование важно, поскольку любое предприятие имеет возможности в несколько раз увеличить количество продаж, сделок, заказов и т.д. за счет
- Интернет продаж\мобильных приложений
- Электронных платежей
- Применения роботов в обработке заказов\сделок. Напр на фондовом рынке большинство сделок создается роботами или автоматизированными процедурами.
В теории архитектор (эта специальность уже становится необходимостью в проектах внедрения 1С) должен договорится с заказчиком\ключевым пользователем\руководителем проекта от бизнеса о границах масштабирования. Проблема в том, что они сами не знают с чем столкнутся через 5 лет, а приложение нужно уже сейчас, тем более 1С предлагает привлекательные готовые типовые конфигурации из коробки, которые можно «немного доработать и все». Поэтому на практике архитектор может построить только масштабируемую архитектуру, но как раз в 1С все ограничено структурой языка программирования в первую очередь.
Конечно можно предложить рассмотреть конструктор на стеке Java, С# в связке с любимой СУБД ,но нужно понимать, что они не для прикладного программирования, без полноценных RAD (Rapid application development) инструментов и там вообще ничто не ограничивает от плохих архитектурных решений, кроме опыта, знаний и правильного понимания архитектурных паттернов. Плюс цена такого решения будет в разы дороже. Далее рассматриваются решения с максимальным использованием возможностей 1С. Я знаю что ктото пишет\читает напрямую в\из базу SQL и использует недокументированные возможности, но с RAD это не имеет ничего общего лучше каждый инструмент использовать по назначению.
Анонс. (далее нерешенные темы анонсируются как темы отдельных статей, по просьбам трудящихся
") ): У разработчика на 1С достигшего уровня гуру 1С возникает соблазн строить архитектуру вокруг 1С. Если же разработчик знает технологии реализованные на Java или C# возможности интеграции 1С с другими приложениями кажутся скромными. Приходит осознание, что 1С это всего лишь один из сервисов с ограниченным функционалом и правильней строить архитектуру как микросервисную, где 1С это сервис хоть и не микро.
): У разработчика на 1С достигшего уровня гуру 1С возникает соблазн строить архитектуру вокруг 1С. Если же разработчик знает технологии реализованные на Java или C# возможности интеграции 1С с другими приложениями кажутся скромными. Приходит осознание, что 1С это всего лишь один из сервисов с ограниченным функционалом и правильней строить архитектуру как микросервисную, где 1С это сервис хоть и не микро.Далее примеры будут приводится для финансового учета операций с фондового рынка ценных бумаг, где приходится работать с исходными сделками импортируя их без агрегации в количестве около 1 миллиона в день, а количество изменений (связанные реквизиты, трансферы, изменения реквизитов или трансферов) по ним около 4-6 миллионов в день.
Если под операцией понимать сделку на фондовом рынке, продажу, заказ, платеж и т.д ситуация будет выглядеть аналогичной
Разберем кейс на примере: Сообщения с изменениями операций поступают в шину RabbitMQ . Оттуда их считывает процесс Message Reader и сохраняет сообщения в индексированный буфер. Данные из буфера читаются кластером 1С и преобразуются в документы, записи регистров сведений 1С и сохраняются в базу.
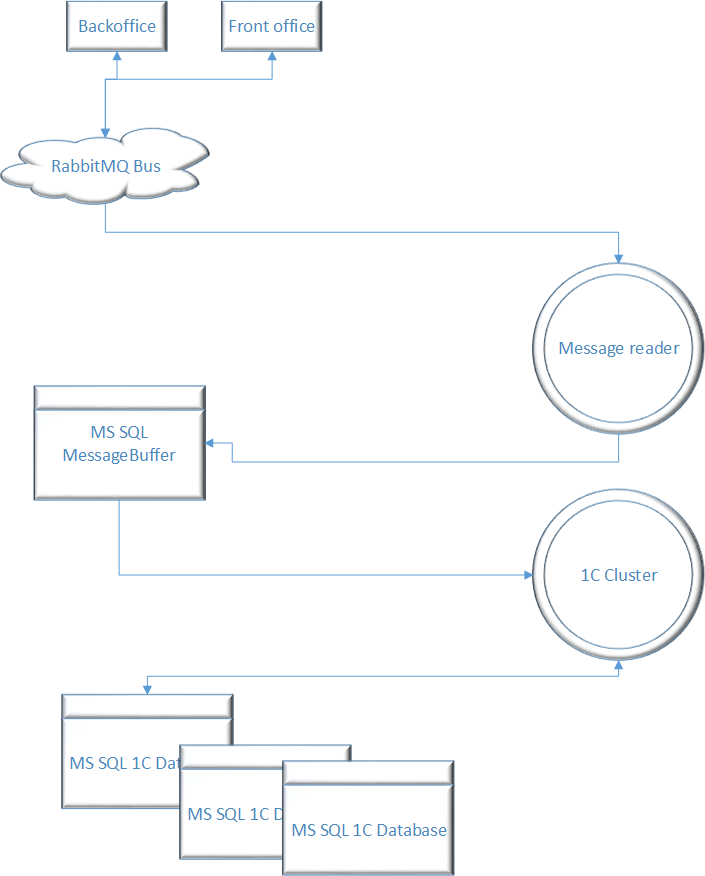
Влияние языка программирования 1С на масштабирование приложений
Импорт данных
Давайте сначала попробуем максимально быстро импортировать операции. В 1С есть возможность разбить наборы данных (операции\платежи\ сделки ) на массивы фиксированного размера (далее пакет) , и запустить на исполнение фоновыми заданиями в нужном количестве (40 параллельных заданий вполне оптимально для одного современного двухпроцессорного сервера приложений).Попробуем через документ.
Документ не аргумент
Для операций в 1С предусмотрены метаданные типа Документ и для определенных случаев можно применять БизнесПроцессы, Задачи. При этом Документ естественно имеет преимущества – его можно записывать без проведения, логику создания проводок\движений в регистры вынести в отдельные параллельные обработки.Возьмем Документ, мы можем передать 1000 xml в фоновое задание, создать 1000 документов в памяти, разыменовать ссылки на справочники одним запросом и … записывать каждый документ в пакете придется последовательно методом Документ.Записать() без проведения. Если посмотрите, как это отражается каждая запись в Profiler MSSQL станет еще грустнее .
Не забывайте что любая операция Документ.Записать() это на SQL сервере это как минимум поиск существующего документа, обновление таблиц, а если есть табличные части в документе то еще удаление\вставка.
Анонс Внутренняя трассировка через SQL Profiler операций записи , особенно в регистры , тянет на отдельную статью там сразу видны все узкие места. Чаще всего в профайлере анализируют запросы на чтение напр https://infostart.ru/1c/articles/1492368/ , по анализу операций записи статей не встречал.
Можно закрыть глаза на эффективность обработки данных документов на уровне процессор – память , ведь это можно решить распараллеливанием, но запись на диск (даже SSD) уже будет узким местом.
Конечно когда 40 параллельных фоновых заданий пишут документы (пусть последовательно внутри задания) это дает надежду увеличить возможности кластера и увеличить их например до 80 и решить проблему оборудованием (напр много ядер и база на SSD полностью). Однако при таком количестве мелких DML (data manipulation language) операций SQL (не путать с транзакциям 1С\MS SQL ) вы неизбежно упретесь в возможности записи в MS SQL transaction log даже на уровне его процессов write log см статью
https://chrisadkin.io/2015/09/09/tuning-the-logcache_access-spinlock-on-a-big-box/
https://chrisadkin.io/2015/06/11/writelog-at-scale-going-beyond-you-need-faster-disks/
Это неочевидный момент – метод .Записать() создает несколько DML операций SQL . Помножьте это на количество операций и вы поймете какую нагрузку 1С создает на SQL Server которую можно наблюдать как количество BatchJobs в секунду . Даже если это заключить в НачатьТразнакцию \ ЗафиксироватьТранзакцию лучше не станет, ведь транзакция будет содержать не крупный DML оператор на 1000 записей, а больше 1000 маленьких.
Анонс: С такой ситуацией столкнулся на практике при нагрузочном тесте кластера на VMWare, там очень много интересных эффектов проявилось при высокой нагрузке
Не случайно при разработке на MS SQL или Oracle рекомендуют укрупнять DML операции и транзакции до разумного предела. Кроме того обновление записи в таблице влечет еще и обновление индексов которых 1С создает немало (см. здесь).
Анонс: При высокой параллельной записи индексы серьезно затрудняют даже вставку (а обновление тем более) и есть особые рекомендации Microsoft на эту тему.
При таком устройстве языка программирования невозможно записать несколько документов в одном DML операторе
При такой организации языка возникает много запросов\ответов по сети. Обмен по сети между кластером 1С и SQL в этом случае уже требует Teamed lan , + процессорные ресурсы сервера , ведь трафик увеличивается и его кто-то должен обрабатывать на сервере даже если сетевая карта часть работы берет на себя.
А может быть использовать Регистр сведений без регистратора как альтернативу Документу?
Конечно, на экзамене 1С будет оценка 2 за нецелевое использование, но если очень хочется, то можно. Можно построить , например, такой регистр сведений.
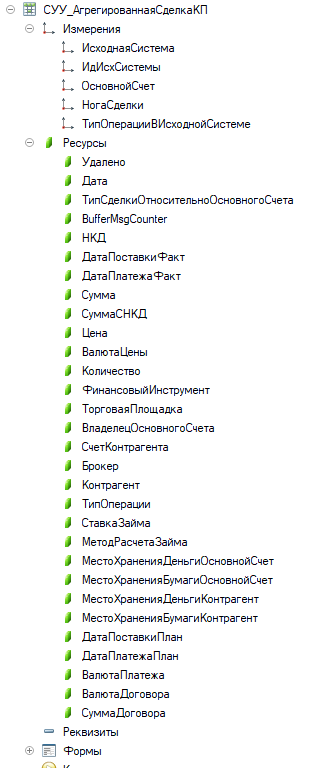
И да метод РегистрСведенийНаборЗаписей.<Имя регистра сведений>.Записать (Истина) позволяет добавить сразу несколько документов с разными ИдИсхСистемы. Это хорошо, но проблемы в языке 1С остаются
- Обновлять записи придется в рамках одного значения измерения ИдИсходнойСистемы. Ведь отбор в наборе записей может устанавливаться только на равенство (см справку).Это нивелирует все выигрыши если есть повторные обновления большинства документов (напр так устроена front office система).
- Если посмотреть MS SQL профайлер 1С использует при Update простые delete , insert по комбинации измерений, а не более эффективный merge
- Если у документа нужна табличная часть, ее придется помещать в отдельный регистр сведений и для связи с основной таблицей повторять в ней значения измерений основного документа. Вообще необходимость измерений, не дает рассматривать регистр сведений как простую таблицу (аналог табличной части документа). В этом примере невозможно добавить несколько одинаковых реквизитов с разными значениями. А простых таблиц в 1С не предусмотрено, если не считать трюки с регистром сведений у которого одно измерение УИД.
Анонс: Запись можно ускорить еще больше если сделать эти регистры периодическими и писать версии операций. Запросы по таблицам несколько усложняются (нужно выбирать последние версии особым образом), но зато скорость импорта гораздо больше.
Формирование движений в Регистры Бухгалтерии и Накопления с максимальной скоростью
Я намеренно упустил регистры сложных периодических расчетов поскольку диапазон их практического применения ограничен расчетом зарплаты и начислением различной амортизации.По производительности от медленных до быстрых рассматриваемые регистры располагаются так:
Тип регистра | Условие максимальной производительности |
Регистр Бухгалтерии , сложная структура дает более медленную производительность. | Итоги сдвинуты на прошлый месяц, текущие итоги отключены, разделение итогов включено. Запись в режиме РегистрБухгалтерииНаборЗаписей.<Имя регистра накопления> .ОбменДанными= Истина |
Регистр Накопления включенными итогами (остатки обороты). Производительность лучше чем у регистра бухгалтерии | Итоги сдвинуты на прошлый месяц, текущие итоги отключены, разделение итогов включено. Запись в режиме РегистрНакопленияНаборЗаписей.<Имя регистра накопления> .ОбменДанными= Истина |
Регистр Накопления (обороты) . Включены агрегаты регистра накопления. Наилучшая производительность поскольку итоги по оборотам считаются отдельной процедурой | Запись в режиме РегистрНакопленияНаборЗаписей.<Имя регистра накопления> .ОбменДанными= Истина |
В нем тоже существует ограничение на работу с набором записей поскольку метод .Записать() можно вызвать только для одного регистратора. Это ограничение легко обойти если под Регистратором понимать не операцию\сделку, а вот такой документ СУУ_АгрегированныеПроводки, который может служить регистратором для проводок сотни реальных документов.
Вариант реализации на практике
Создаем документ АгрегированныеПроводки. Слово агрегированные из реальной конфигурации, поскольку механизм позволяет писать как детальные проводки для каждой операции, так и суммовые для множества реальных операций.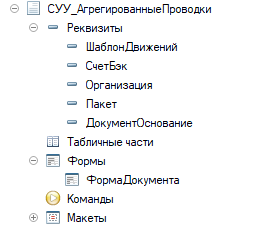
А где будет исходный документ основание?
Его можно поместить в индексированный реквизит проводки, или движения регистра
Проблема записи проводок\движений пакетом решена?
На самом деле нет и виной тому организация хранения итогов по остаткам. Если посмотреть через SQL Profiler даже в периоде с нерассчитанными итогами и отключенными текущими итогами, sql код обращается к рассчитанным итогам, как понимаю для контроля периода записи. Организация записи не самая эффективная, но это когда-нибудь решат. Корень проблемы в возможности динамического обновления остатков даже за закрытый месяц, а механизма отложенного обновления остатков как в регистрах накопления с агрегатами нет (они бывают только оборотные). Конечно динамическое обновление остатков это плюс для разных схем с ручным отпуском\приемом товара, но жирный минус когда нужно просчитать миллионы документов. С включенными текущими итогами о производительности вообще можно забыть, поэтому сдвиг итогов на прошлый месяц и выключение текущих итогов разумный компромисс.В теории для конфигурации собственной разработки, можно организовать регистр накопления с остатками, на основе регистра оборотов с агрегатами. Просто остатки будут фиксироваться оборотами с отдельным признаком в измерении НашВидОборота. Конечно придется организовать свою подсистему обновления остатков с закрытием периода используя средства 1С.
В итоге получается слишком много компромиссов для достижения максимальной производительности и масштабирования это особая работа с регистраторами, и необходимость сделать собственную подсистему закрытия периода и обновления итогов. Но другого выхода нет, если не выходить за рамки 1С. Выход за рамки 1С повлечет отказ от использования СистемыКомпоновки данных в отчетах и потребует сделать свою подсистему отчетности, ведь регистры это не только хранение, но и удобное получение отчетности.
Анонс: Как выйти за рамки инструментов 1С и сохранить скорость разработки?
В итоге разделив проводимые документы на пакеты и запустив нужное количество параллельных фоновых заданий, можно обработать миллионы операций за требуемое время , которое каждого свое. Кому то достаточно ночи, а у кого-то есть 4 часа утром – все зависит от прикладной задачи. Горизонтальное масштабирование хорошо тем, что грамотно спроектированная конфигурация позволяет такие проблемы решать расширением оборудования.
Управление неуправляемыми фоновыми заданиями
Вообще, чтобы обработать операции параллельно - механизма фоновых заданий недостаточно. Параллельные вычисления это достаточно старая тема и есть даже сайт https://parallel.ru/tech , где максимально собрано много научной информации. Массово в 1С это стало возможно применять с 2009 года , когда появился механизм фоновых заданий, сервера на базе чипсетов Intel\AMD стали не только многопроцессорными, но и многоядерными.В 1С с фоновыми заданиями работать просто:
- Нужно передать немутабельные параметры с массивом операций.
- Запустить на выполнение
- Дождаться завершение всех или части фоновых заданий. Можно проверять по таймауту
А) Балансировка нагрузки
Б) Обработка ошибок
С) Работа с общей памятью
Д) Отладка
Кто ответственен за балансировку нагрузки кластер или программист?
Для версии 8.3.21 есть возможность назначения сервиса фоновых заданий на несколько серверов кластера и гибко распределять нагрузку даже для конкретных фоновых заданий или групп , что описано тут <Вывести в приложение>https://its.1c.ru/db/v8321doc#bookmark:cs:TI000000036
И через дополнительные параметры фоновых заданий. Сделано разумно, но ведь есть еще ситуации, когда фоновых заданий может быть много, напр грузим 4 миллиона операций по 1000 в каждом задании. Получим 4000 фоновых заданий. Что будет если система сформирует их все сразу ?
Ничего хорошего.Даже если задания встанут в очередь, кластер не может предсказать как будет работать алгоритм разработчика. Напр на старте задания выполняют запрос на чтение к базе, это не грузит кластер\но грузит базу SQL – а после получения выборки задания начинают ее обрабатывать почти одновременно . Тут легко оказаться в ситуации, когда число взятых на выполнение заданий превосходит возможности кластера и никакие трюки с механизмом «Доступная производительность» не помогут.
Только разработчик может предсказать сколько ресурсов процессора и памяти в пике может быть занято, а механизма ограничения количества фоновых заданий в 1С нет. Все это нужно писать самим. Особенно легко сломать кластер если в процессе выполнения превысить память на рабочий процесс, ведь кластер не знает сколько памяти захотят три сеанса через минуту, которые кластер повесил на один рабочий процесс проверив «Доступную производительность».
Анонс: Разработка собственного механизма управления заданиями это уже близко к системному программированию с моделью событий, пусть и реализуемые на языке 1С . Основная проблема – отслеживать пакеты заданий с разных сеансов, напр кто-то запустил импорт из тысячи заданий, кто-то расчет за прошлый период из тысячи заданий, а уложится нужно, например, в 80 одновременно выполняющихся. Реализация на уровне кластера могла бы упростить задачу.
Если соблюдать деление на пакеты при обработке больших данных, то все можно сделать предсказуемым и объем требуемой памяти, и соединение 1000 объектов с большой таблицей, и управление нагрузки задавая максимальное количество фоновых заданий. Печально только то, что в кластере 1С, при управлении фоновыми заданиями, задать максимальное количество заданий для одновременного исполнения нельзя.
Обработка ошибок – задание улетело и обещало вернуться
При обработке большого количества данных с разделением на пакеты порождается много фоновых заданий. Но у 1С есть четкие ограничения на хранение историиИз официальной документации последних версий
Цитаты
Завершившиеся успешно или аварийно фоновые задания хранятся в течение суток, а потом удаляются… История хранится для каждой информационной базы… Фоновых заданий ‑ не более 1 000 заданий... Регламентных заданий ‑ не более 1 000 заданий… При этом система пытается хранить не менее 3 последних запусков для каждого различного регламентного задания…
В общем если вы решили обработать 2 миллиона операций разбитых на пакеты по 1000 историю выполнения половины заданий не увидите. Конечно, внутри задания нужно логирование не зависящее от транзакций, обработка исключений. Однако есть ряд случаев, когда кластер срубает фоновые задания принудительно и внутреннее логирование не поможет. Такая ситуация может быть инициирована проблемами с блокировками на уровне MS SQL, неперехватываемые в программном коде ошибки, проблемами при запуске фонового задания (при доменной авторизации) и т.д. Важно то Вы об этом не узнаете, и приходится писать свою подсистему отслеживания истории фоновых заданий.
Анонс. Правильное логирование в среде с активным использованием фоновых заданий, это отдельная тема оно должно быть независимым от транзакций, не влияющие на производительность, удобное для прочтения\поиска, а не как в журнале регистрации. Первое, второе может обеспечить журнал регистрации. Если делать журнал удобным, то приходится делать собственную подсистему с первым и вторым пунктом, а это средствами 1С сделать не получится.
Общая память не так страшна если это InMemory СУБД
В горизонтально масштабируемой среде важна общая память, чтобы отслеживать процесс обработки. Пример из жизни в шину приходят версии операций\котировок и т.д. вам нужно это загрузить параллельно причем версия 1 не должна перетереть версию 2. Без общей памяти такой подход невозможен, приходится делать выборку последних версий т.е. создавать одну выборку и инфраструктуру хранения. С общей памятью можно фиксировать загруженную версию и быстро проверять ее, без обращения к диску СУБД. Пока такое можно решить только внешними средствами выбрав подходящую InMemory СУБД либо MySQL с таблицами в памяти, где многие аспекты совместной работы и нагрузок решены.Анонс. Следует заметить, что InMemory СУБД это не просто таблица в памяти или MSSQL с tempdb, который поместили виртуальный диск в память. Это защита от потери данных, сброс на диск данных которые, не помещаются в память и многое другое. InMemory tables в MSSQL не совсем решают задачу общей памяти так как они разработаны для задач быстрого получения отчетов а не записи. Как следствие к выбору средства общей памяти нужно подходить взвешено.
В 1С мы имеем полушаги по обмену информацией между заданиями
ВременноеХранилище – имеет время жизни ограничение по работе с фоновыми заданиями
https://its.1c.ru/db/v8317doc#bookmark:dev:TI000000819 «Данные, помещенные во временное хранилище в фоновом задании, не будут доступны из родительского сеанса до момента завершения фонового задания.»
https://its.1c.ru/db/v8321doc#bookmark:dev:TI000000809 «ВНИМАНИЕ! При помещении во временное хранилище фактическая сериализация значения не выполняется. Помещается ссылка на значение, которое хранится в кеше в течение 20 минут. По истечении этого периода значение сериализуется, записывается на диск (в хранилище сеансовых данных) и удаляется из кеша.»
Менеджер временных таблиц – мутабелен , его нельзя делить между заданиями. Нельзя дописывать во временные таблицы, а можно только однократно записать (фактически аналог select into)
Остается только использовать структуры хранящиеся в СУБД напр. регистры сведений, но они медленные в текущей реализации 1С 8.х
Отладка - поймай меня, если сможешь
Формально отлаживать фоновые задания можно, просто когда возникают проблемы плавающего характера приходится применять методы трассировки - фиксация состояния программы вставками в код. Трассировка должна быть незаметной для производительности и независимой от транзакций. Метаданные 1С для этого не подходят,а журнал регистрации имеет фиксированную структуру и с ним тяжело работать c точки зрения поиска– это не https://logging.apache.org/ . Выход – выносить механизм трассировки на внешние механизмы, задача для реализации в хорошем виде непростая и тянет на отдельную статью
Как обойти ограничения 1С?
Я думаю в статье приведено достаточно примеров задач, которые можно решить горизонтальным масштабированием в 1С, но структура языка программирования 1С накладывает четкие ограничения. А зачем их собственно обходить, если есть другие языки программирования? Ответ простой - ради плюсов, которые дает использование 1С как средство быстрой разработки и наличие хороших типовых конфигураций 1С. Замечу хороших с прикладной точки зрения, но не с точки зрения производительности. Чтобы эти плюсы сохранить нужно стратегически сохранять разработку прикладного кода в рамках платформы 1С 8.х, а за рамки выводить только узкий функционал. Решение в этом случае не получится монолитным и похожим на микросервисную архитектуру, но это не должно пугать - она и так начинает делится на более менее крупном внедрении напр- Отдельная база для ведения справочной информации (master data management)
- Отдельные базы для разных юрлиц или видов учета . Классический вариант 1С Управление торговлей отдельно, 1С Бухгалтерия отдельно.
- Обмены
- Шины данных (RabbitMQ+ буфер для хранения)
- Управление всем этим и многое другое
Анонс: Импорт в регистр сведений, напрямую через СУБД. Достаточно простая структура позволяет это сделать грамотно, а объем хранения в СУБД не имеет значения при правильно организованных индексах.
Анонс: Агрегируйте. Если вы работаете с большим количеством операций, лучше избегать дублирования по цепочке бизнес процесса. Это не всегда возможно если FrontOffice, Backoffice и Finance\Management accounting находятся в разных системах. Однако расходы на хранение и обслуживание такого количества информации сразу можно умножать на 3 . И тут сразу появляется повод договорится с Business owner систем. Ведь важно не только все это хранить на избыточных RAID но и быстро считать. Агрегация непростой процесс, поскольку даже в Finance\Management accounting ошибки сверки требуют лезть в расшифровку . Вы либо храните ее внутри системы, либо доверяете внешней с учетом возможных изменений конечно
Анонс: Если чтото лучше вне 1С используйте это. В качестве примера можно привести интеграцию с шинами. Пример RabbitMQ. Есть решения от PinkRabbit, и сейчас от 1С. Проблему со считыванием они как то решают, но ведь важно не просто считать, а быстро сохранить . Делать это через кластер 1С, который отделен от базы данных (а без этого не получится горизонтального масштабирования) неэффективно по производительности , особенно когда речь идет о 7 миллионах сообщений в день, которые могут еще за пару часов появится J . Выход – отдельное решение с буфером.
Для формирования движений в регистры хорошего решения нет, кроме агрегации исходных операций. Данные регистры бессмысленны без отчетности на подсистеме компоновки данных, и возможности соединения со справочниками, регистрами сведений и т.д. Даже если сделать внешнюю компоненту с регистрами «как хочешь» то к ним нужно приложить такую же систему отчетности.
В качестве заключения
Можно ли все это исправить расширяя язык программирования? Конечно можно, просто цепочка изменений внутри платформы и кластера будет достаточно большой. Еще нужно внедрить соответствующий стиль программирования в массы, ведь не все читают статьи подобные этой. Пока 1С предпочитает наращивать возможности функционала типа СистемаВзаимодействия без пересмотра базовой архитектуры. Однако рост данных это цунами которое неожиданно появляется из небольших волн, ты либо готов к нему сейчас либо нет.Язык мой – враг мой
Платформе 8.х почти 19 лет, идет ли она в ногу со временем? На сайте releases.1c.ru первые релизы 1с 8.х датируются 2003 годом. В промышленной эксплуатации был оперативный учет, а...
 habr.com
habr.com