Что страница может показывать, но не видит
Вы заметили, что вы не можете установить высоту для посещённых ссылок? Нацеленное на эти ссылки правило CSS может устанавливать несколько атрибутов, но не все. Обратите внимание, что обе ссылки имеют одинаковую высоту, хотя нижняя должна быть выше: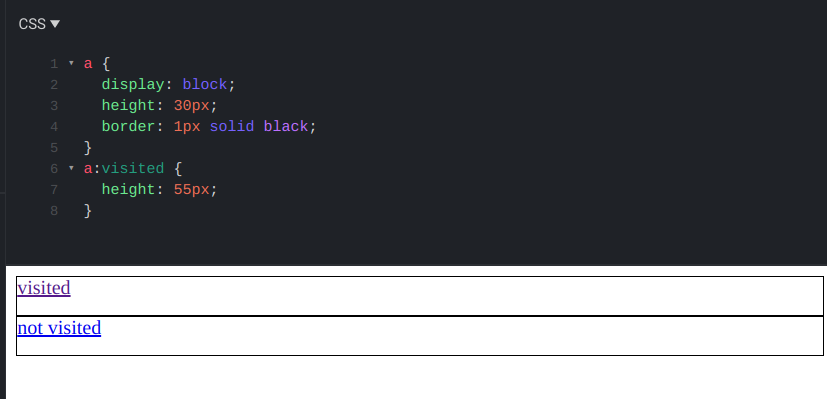
Посмотрев окончательный стиль мы также увидим высоту, как у непосещённой ссылки:
getComputedStyle(visitedLink).height; // 30px
Для посещённых ссылок возможно установить несколько свойств, например цвет текста:
a:visited {
color: red;
}
Но, даже если он выглядит иначе, JavaScript может видеть только стили обычной ссылки:
getComputedStyle(visitedLink).color; // rgb(0, 0, 238) (blue)
Это один из примеров, когда страница может что-то показывать, но не видит. Ссылка может быть оформлена по-разному в зависимости от её атрибута, но браузер защищает эту информацию от страницы.
Защищённая визуальная информация
Более привычный пример — изображения из разных источников. Их можно отображать на странице, но браузер накладывает на них всевозможные ограничения.Я видел, как люди недоумевали, почему веб работает именно так, особенно если эти люди с других языков переходили в сферу веб-разрабтоки. Если вы хотите показать изображение на Java или C++, чтобы сделать это, программе необходимо получить доступ к байтам изображения. Без полного доступа они не смогут его отобразить.
Но JavaScript и веб работают по-другому. В HTML простой <img src = "..."> показывает изображение без предварительного доступа к байтам. И это открывает окно к тому, чтобы иметь отдельные разрешения на показ чего-либо и доступ к чему-либо.
Посещённая и непосещённая ссылка — отличный пример. Функция восходит к самым ранним браузерам, и всё ещё хорошо поддерживается. Пользователь может увидеть, какие ссылки указывают на ранее открытые страницы. Это отлично подходит для просмотра Википедии, например, так как вы можете сразу отличить ссылки, потенциально содержащие новую информацию.
Но, великолепная для UX, она открывает зияющую дыру в безопасности, которую трудно закрыть. Если веб-страница может определить, посещена ссылка или нет, она может получить доступ к информации, которая не должна быть доступна. Например, она может проверять URL-адреса поиска в Google и выявлять, искал ли пользователь определённые термины. Термины могут содержать конфиденциальную информацию, и, сопоставив большое количество таких поисковых запросов, веб-страница может деанонимизировать пользователя.
Проблемы безопасности могут возникать из-за других элементов, а не только из-за ссылок, если эти элементы пропускают информацию на сайт; загрузка изображения с другого домена может содержать конфиденциальную информацию. Например, динамическое изображение может меняться в зависимости от того, сколько у вас непрочитанных уведомлений:

Это работает, поскольку браузер отправляет файлы cookie вместе с запросом изображения, содержащим информацию о сеансе, которая идентифицирует пользователя в Facebook. Если бы сайт мог прочитать изображение ответа, он мог бы извлечь информацию об активности пользователя в Facebook. По этой причине вы не можете экспортировать содержимое canvas после отрисовки на нём изображения с cross-origin — это явление называется tainted canvas (испорченный холст).
И слон в посудной лавке, конечно же, IFrames. Страница может быть включена в другую страницу со всей информацией для входа в систему и так далее, если это не запрещено явно при помощи X-Frame-Options или Content Security Policy. Если бы веб-страница могла получить доступ к любой странице, которую она содержит, это дало бы ей полную свободу действий с отображаемыми данными.
Визуальные атаки
Браузеры делают всё возможное, чтобы защитить информацию, предназначенную для просмотра пользователем, но не для веб-страницы. Однако иногда они терпят неудачу по разным причинам, и из-за некоторых ошибок уязвимости случаются. Посмотрим самые интересные!1. Посещённые ссылки
Первая уязвимость связана с посещёнными ссылками, речь о которых идёт выше. Неудивительно, что в браузерах реализованы методы блокировки извлечения информации. Эта уязвимость даже описывается в спецификации CSS 2.1:Это означает, что браузеры ограничивают тип стиля, который может иметь посещённая ссылка поверх непосещённых ссылок. Например, не позволяя устанавливать высоту элемента, веб-страница не может проверять положение элемента под ссылкой, чтобы узнать, указывает ли он на посещённый URL-адрес.Поэтому пользовтаельские агенты могут обрабатывать все ссылки как непосещённые или применять другие меры для сохранения конфиденциальности пользователя, при этом по-разному отображая посещённые и непосещённые ссылки.
Но с новыми возможностями уязвимости появляются снова и снова. С помощью вызова getComputedStyle JavaScript может прочитать текущий стиль элемента. И до того как это исправили, сайт мог прочитать цвет ссылки, чтобы узнать, была ли она посещена или нет. Уязвимость была обнаружена в 2006 году и всплыла на поверхность десятью годами позже.
2. Режимы наложения CSS
Это отличная уязвимость для попиксельного извлечения визуальной информации из IFrame или другого защищённого ресурса. Пост в блоге Руслана Хабалова отлично объясняет подробности уязвимости. Её суть в том, какрежимы наложения были реализованы.Режимы наложения позволяют странице определять, как элементы взаимодействуют друг с другом. На этом изображении показано несколько примеров:

Обратите внимание, как изменяется центральная область в зависимости от режима наложения и цветов пикселей двух слоёв.
Хотя страница не может получить доступ к тому, как выглядит IFrame (или изображение с другого сайта, или посещённая ссылка), она может свободно размещать его на странице, даже под другими элементами. Это позволяет режимам наложения отображать пиксели разного цвета в зависимости от того, как выглядят элементы.
Но это не должно приводить к какой-либо уязвимости, поскольку страница не может получить доступ к результирующим цветам пикселей, она может только определять, как браузер отображает их. Во всяком случае не напрямую.
Код для расчёта режима наложения в браузере был реализован так, чтобы для разных входных цветов использовать разные ветви.
// example pseudocode from https://www.evonide.com/side-channel-attacking-browsers-through-css3-features/
[...]
SetSat(C, s)
if(Cmax > Cmin)
Cmid = (((Cmid - Cmin) x s) / (Cmax - Cmin))
Cmax = s
else
Cmid = Cmax = 0
Cmin = 0
return C;
// Compute the saturation blend mode.
Saturation(Cb, Cs) = SetLum(SetSat(Cs, Sat(Cb)), Lum(Cb))
А поскольку страница может управлять одной частью входных пикселей, она может попробовать множество вариантов и увидеть разницу. И это приводит к утечке информации о другой части входных пикселей, а именно о защищённом содержимом.
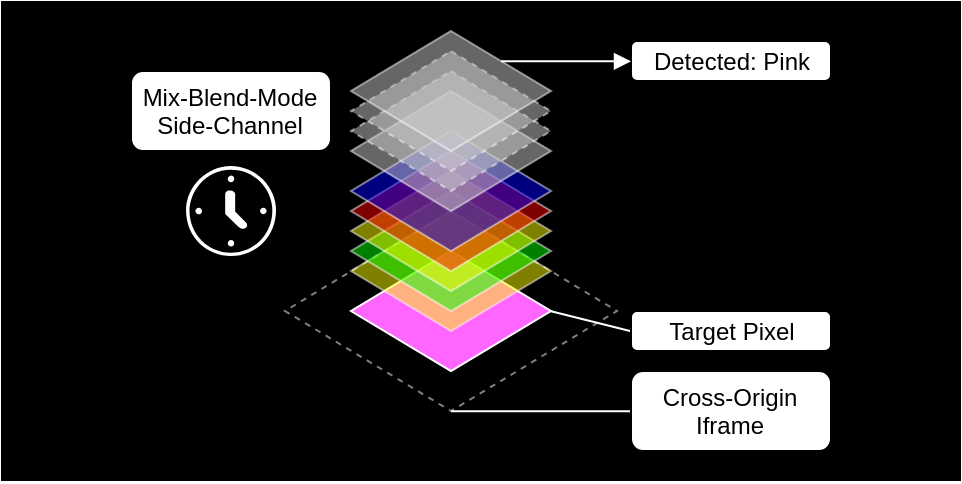
Уязвимость позволяет извлекать данные по одному пикселю за раз и обходит все средства защиты браузера от доступа из разных источников. Исправлена она была путём исключения ветвей из реализации режима наложения, что позволило алгоритму работать с константным временем выполнения независимо от входных цветов.
3. Злая CAPTCHA
Эта атака эксплуатирует самое слабое место в каждой системе ИТ-безопасности: пользователя. Она — гениальный способ извлечь информацию с другого веб-сайта, поскольку пользователь активно участвует в атаке, от неё не защищает никакой стандарт.CAPTCHA — это способ защитить сайт (или его часть) от ботов. Задача в CAPTCHA должна быть лёгкой для людей, но трудной для машин, например, это может быть чтение символов с изображения. Капча применяется, чтбы предотвратить автоматическую рассылку спама в разделе комментариев или в контактной форме. Выглядит она так:
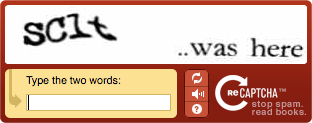
Нетанель Гелернтер и Амир Херцберг показывают в своей статье способ использовать знания пользователя о решении CAPTCHA, чтобы извлечь инфорацию. В своей реализации метода они загрузили данные в немного непонятном виде и попросили пользователя ввести их в текстовое поле. Например, манифест кеша для Gmail содержал адрес электронной почты пользователя:
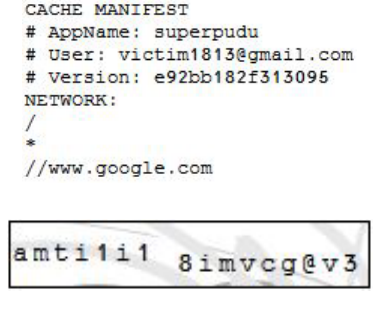
Обратите внимание, что CAPTCHA — это просто изменённая версия первых 15 символов адреса электронной почты (victim1813@gmai). Похоже на невинную обычную капчу, но она передаёт эту информацию на сайт.
Извлечь адрес почты пользователя на Gmail из файла манифеста кеша больше нельзя; но в любой сайт возможно встроить поле для комментариев на Facebook, которое по-прежнему будет содержать настоящее имя пользователя:

Обратите внимание, что текст содержит имя «Inno Cent». Набирая его, пользователь непреднамеренно показывает свое настоящее имя, если он вошёл в систему на Facebook.
Эта атака также открывает двери для всякого другого извлечения информации. Авторы статьи использовали персонализированную функцию автозаполнения Bing, которая раскрывала информацию об истории поиска. На изображении слева показан шаблон с 4 областями для извлечения информации. На изображении справа показано, как выглядит «последняя» CAPTCHA, в данном случае это означает, что пользователь искал 4 слова:

В этом примере использовалась ошибка конфиденциальности в Bing, но нетрудно представить, как она может также включать проверку того, была ли ссылка посещена или нет: просто задайте стиль непосещённой ссылки в соответствии с фоном. Если пользователь её видит (и вводит в текстовое поле), значит, ссылка была посещена.
Прелесть этой атаки в том, что практически невозможно реализовать техническое решение для её предотвращения. К счастью, применимость этой уязвимости ограничена, так как с её помощью возможно извлекать только текстовую информацию и только несколько раз, прежде чем пользователю станет скучно и он покинет сайт.
Веб развивается в стремительном темпе, он очень востребован, а сложность браузеров сегодня сопоставима со сложностью операционных систем. Написать современный браузер полностью с нуля — огомная проблема.
Источник статьи: https://habr.com/ru/company/skillfactory/blog/558672/