Всем привет! Меня зовут Данила, я выполняю роль SR-инженера в Usetech. В этой статье я бы хотел рассказать о 4-х способах, которые помогут сократить объём ваших индексов в Elasticsearch.
Прежде всего статья будет полезна начинающим специалистам по администрированию ELK стека, администраторам систем мониторинга, разработчикам, внедряющим ELK стек у себя на проекте.
Работая над мониторингом в одном из проектов мы столкнулись с тем, что временной промежуток, за который мы имеем возможность хранить данные, для нас недостаточен, т.к. хотелось иметь возможность сравнивать работу системы за больший период времени.
Мы видели 2 пути решения проблемы:
Хотя данные способы достаточно просты, они помогли увеличить срок хранения индексов в среднем в 6 раз.
Дисклеймер

Подробнее про dynamic mapping:
Так мы видим, что тип string преобразуется сразу в два типа данных. Это значит, что значение поля string в Elasticsearch будет храниться и как text, и как keyword.
text — тип данных, который позволяет использовать полнотекстовый поиск. Однако text нельзя использовать для сортировки и агрегации.
keyword — тип данных, который позволяет индексировать строку как есть. Используется для сортировки, агрегации и в term-level queries.
Есть хорошая статья, которая объясняет все различия между этими двумя типами.
Мы в своём проекте решили использовать только тип keyword, чтобы сократить объем и время индексации, т.к. не пользуемся полнотекстовым поиском.
Рассмотрим как настроить dynamic mapping для полей в index template на практическом примере. Данный пример позволяет преобразовать string только в keyword, но так же можно настроить преобразование в text.
Прежде всего, необходимо:
"strings": {
"mapping": {
"ignore_above": 256,
"type": "keyword"
},
"match_mapping_type": "string"
}
}
Теперь при появлении нового поля типа string оно будет преобразовано в keyword. Параметр ignore_above отвечает за максимальный размер keyword, который будет индексироваться. В нашем примере если длина поля больше 256 символов, то оно не будет индексироваться.
Важный момент!
Если отключить индексацию у поля, то по нему нельзя будет произвести поиск. Однако остаётся возможность сортировать и агрегировать. Более подробно по ссылке.
Таким образом, мы можем настроить dynamic mapping и для других типов, а с помощью интерфейса или api в index template указать дополнительный настройки для полей. Например, мы можем использовать регулярные выражения, чтобы поля с определенными именами преобразовывались в указанный тип данных и не индексировались.
{ "labels": {
"path_match": "labels.*",
"mapping": {
"type": "keyword",
“index”: false
},
"match_mapping_type": "string"
}
В данном примере, поля начинающиеся на labels. будут преобразованы в тип keyword и у этих полей будет отключена индексация.
Для того, чтобы включить dynamic mapping для дат и чисел, необходимо следующее:

Параметры Map numeric strings as numbers и Map date strings as dates
Если до конвертации данных в date и long, вы могли использовать запросы со звёздочкой, например “response_code:5*” и получать все документы в поле response_code которых содержатся 5xx http коды ответа, то после конвертации, вам необходимо использовать операторы сравнения, т.е. запрос будет выглядеть так: “response_code: >= 500”.
Чтобы иметь какие-то сравнительные результаты:
(1) Сначала запустим сбор логов без наших настроек:

(2) А после добавим наши улучшения:

Получаем:
Более подробную информацию про dynamic templates можно прочитать в документации.
Вместо LZ4 можно настроить использование алгоритма DEFLATE. DEFLATE — алгоритм сжатия данных без потерь, который использует комбинацию LZ77 и Хаффмана. Алгоритм ориентирован на более эффективное сжатие повторно встречающихся данных. Требует больше времени на сжатие\распаковку и больше ресурсов CPU.
Недавний пример: один из наших сервисов стал присылать 5хх ошибок больше, чем ожидалось. Пиковая нагрузка около 50 RPS, каждая ошибка порождала дополнительно одинаковые логи, не считая нормальную работу приложения по другим сервисам. В тот момент у нас уже был настроен алгоритм сжатия DEFLATE. Посмотрите на 13 и 14 индексы на картинке ниже. Мы видим, что разница в объёме 13 и 14 индекса ~3гб, а разница в docs больше чем в 2 раза.
Чтобы использовался алгоритм DEFLATE, а не LZ4, нужно указать его использование в index template.
Для этого необходимо:
"index": {
“code”: “best_compression”
}
Если “index” у вас уже содержит какие-то поля, то просто добавить “code”:”best_compression”.
Важный момент!
Как было сказано раньше, агрессивный алгоритм сжатия DEFLATE требует
больше ресурсов, чем LZ4. Поэтому попробуйте протестировать его, прежде
чем использовать его по умолчанию в ваших index templates.

(2) Объём второго индекса с DEFLATE

(3) Объём индекса с dynamic mapping + DEFLATE

Получаем следующие цифры для трех индексов:
Возможно, у вас есть ещё какие-то полезные поля, которые никак не используются, кроме как при непосредственном чтении логов. Поэтому, чтобы уменьшить их влияние на объём индекса, воспользуйтесь следующими шагами:
Отключение индексации
Неиспользуемые поля с индексацией опасны тем, что при их большом количестве, они значительно увеличивают объём индекса. Особенно если такие поля у вас содержат большее количество символов (длинные поля).
Поэтому давайте рассмотрим, что необходимо настроить для отключения индексации:
"longfield": {
"path_match": "longfield.*",
"mapping": {
"type": "keyword",
“index”: false
},
"match_mapping_type": "string"
}
В поле path_match вместо longfield.* можно подставить своё регулярное выражение. Параметр index: false отключает индексацию

Возможен случай, когда вы собираете какие-то поля, но в данный момент не используете их для поиска. Тогда подумайте над тем, чтобы не сохранять их в _source, чтобы оптимизировать объём индекса.
_source — это поле, хранящее исходное тело документа в json, которое было передано во время индексации.
Чтобы не сохранять какое-то поле в _source, нужно сделать следующее:
В раздел exclude fields добавляем название полей, которые не нужно сохранять в _source.
Если вы хотите добавить какое-то поле в _source, просто добавьте его в поле include fields.
Отключение doc_value
Хотя использование инвертированного индекса значительно ускоряет поиск, но для сортировки и агрегации его использование менее эффективно, чем структуры похожей на инвертированный индекс, где значения хранятся в виде столбцов. Такой структурой в Elasticsearch является doc_value.
doc_value — структура, которая создается во время индексации документа, поэтому отключение индексации может отключить сортировку и агрегирование. Однако типы данных numeric, date, boolean, keyword, etc. могут использоваться для сортировки и агрегации, даже если индексация для них отключена.
Чтобы отключить doc_value для поля, необходимо:
"longfield": {
"path_match": "longfield.*",
"mapping": {
"type": "keyword",
“doc_value”: false
},
"match_mapping_type": "string"
}
В данном примере все поля начинающиеся на longfield. с типом string будут сопоставляться c keyword, и у них будет отключено doc_value, из-за чего по ним нельзя будет сортировать и агрегировать.
Про отключение индексации мы уже достаточно поговорили, теперь давайте смотреть цифры (и котиков).
Сравним объём индексов:

(2) Объём индекса с отключением индексации некоторых полей

(3) Объём индекса с использованием индексации некоторых полей и предыдущих способов оптимизации

Получаем:
Для эффективного распределения ресурсов и хранения данных в Elasticsearch реализована hot-warm-cold архитектура, состоящая из 4-х фаз:
Lifecycle policy позволяет определять фазы и переходы между фазами, что оптимизирует процессы хранения и удаления индексов.
Lifecycle policy не применяется для ранее созданных индексов. Она должна быть указана при создании индекса и будет управлять им с момента его создания до удаления.
Кроме этого, мы можем пропускать какие-то фазы. Например, индекс в hot фазе может сразу перейти в cold или из warm в delete.
Только что созданный индекс находится в hot фазе — это значит, что индекс доступен для записи\чтения. Заполняется новыми логами, а значит информация часто запрашивается и представляет наибольшую ценность. Данные активно индексируются и никак дополнительно не сжимаются (работают только настройки index template). Поэтому индекс в hot фазе занимает больше всего места на диске и требует больше ресурсов СPU + SSD при работе с ним.
Warm фаза — индекс в данной фазе доступен для чтения. Используются для устаревших данных, которые всё ещё представляют ценность. Поиск происходит медленнее чем в hot фазе. Поэтому индексам в warm фазе требуется меньше ресурсов CPU + SSD при работе с ними.
Cold фаза — индекс в данной фазе доступен для чтения. Используются для данных, которые запрашиваются крайне редко. Поиск может занимать ещё больше времени чем в warm фазе. Наименьшая потребность в ресурсах CPU + SSD.
Freeze фаза — индекс в данной фазе недоступен для чтения\записи. Используется для хранения данных до лучших времен, если такое необходимо. Объём индексов можно значительно уменьшить. Потребность в дисковых ресурсах, но почти не требует CPU ресурсов.
Конец любой lifecycle policy — delete фаза. В delete фазе происходит удаление индексов.
После настройки ILM (index lifecycle management) вам больше не нужно следить за удалением, добавлением и сжиманием индексов. ILM всё делает автоматически. Главное верно указать триггеры перехода, чтобы ваше дисковое пространство не заполнилось раньше, чем удалится первый индекс с настроенной lifecycle policy.
Индекс переходит из фазы в фазу, когда время жизни индекса в данной фазе подходит к концу. Кроме hot фазы, в которой есть возможность настроить сразу несколько триггеров:
Как только одно из условий будет выполнено, наш индекс перейдет на следующую фазу. А ILM создаст новый индекс в hot фазе — этот процесс называется rollover.
Вот в чём проблема: чтобы создать новый индекс, после того как прошлый уже выполнил rollover, lifecycle policy должен понимать, какое название дать новому индексу. К сожалению, просто указать alias ничего не даст. У вас получится ситуация из 2-х одинаковых индексов, а ещё система не сможет вести подcчёт и выдаст ошибку.
Подробнее про rollover можно прочитать тут.
Рассмотрим самый простой способ использования ILM:
Прежде всего мы рассмотрим наиболее популярный случай использования ILM для индексов. Мы настроим hot и delete фазу без rollover. Таким образом наши индексы будут находиться в hot фазе всё время до удаления. Это самый простой способ автоматизации, дополнительные настройки и возможности ILM можно найти в других статьях и документации.
Для того чтобы использовать lifecycle policy, нужно её настроить. Для этого:
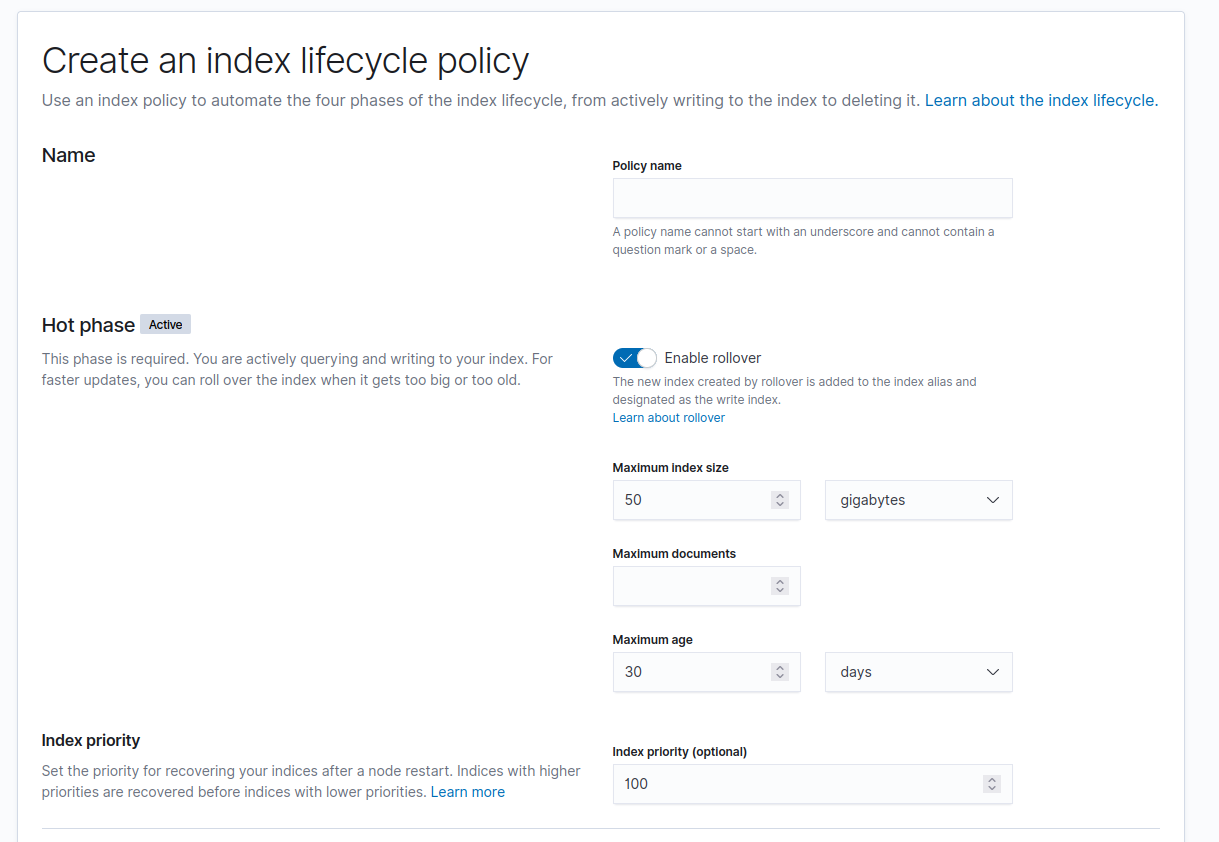
Один из примеров интерфейса, возможно у вас будет что-то такое:
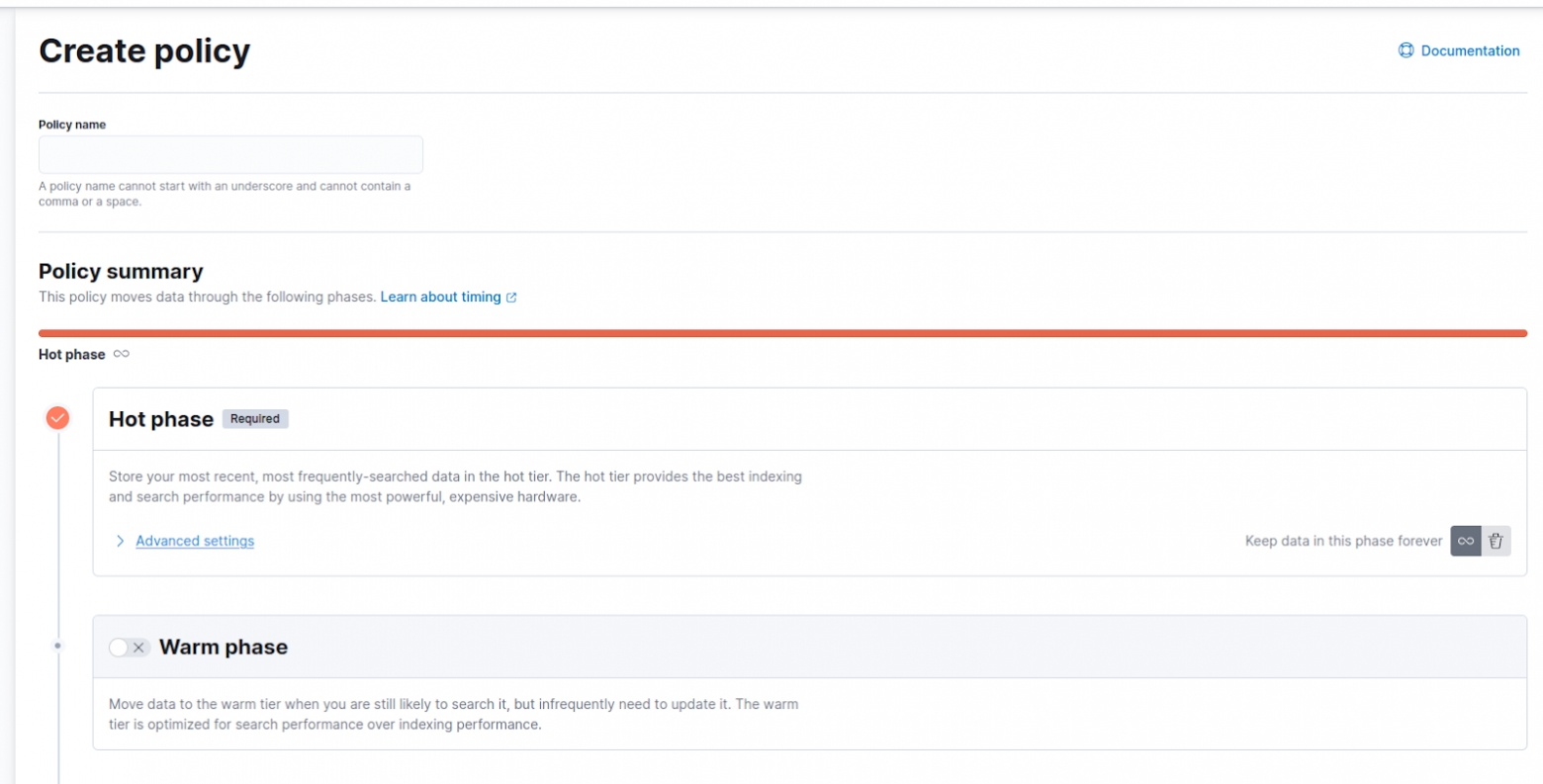
В hot phase, нам нужно отключить параметр Enable rollover для того, чтобы наш индекс был в hot фазе всё время до удаления и не создавал дополнительных alias во время жизни.

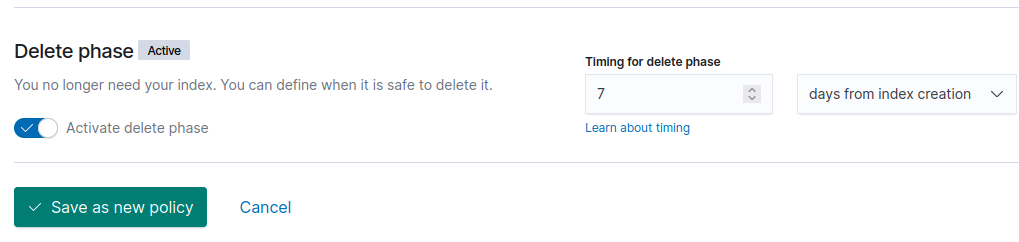
На данном этапе мы укажем имя политики как main-policy. Затем опускаемся в самый вниз и включаем delete фазу. Например, через неделю после создания наш индекс должен быть удалён.
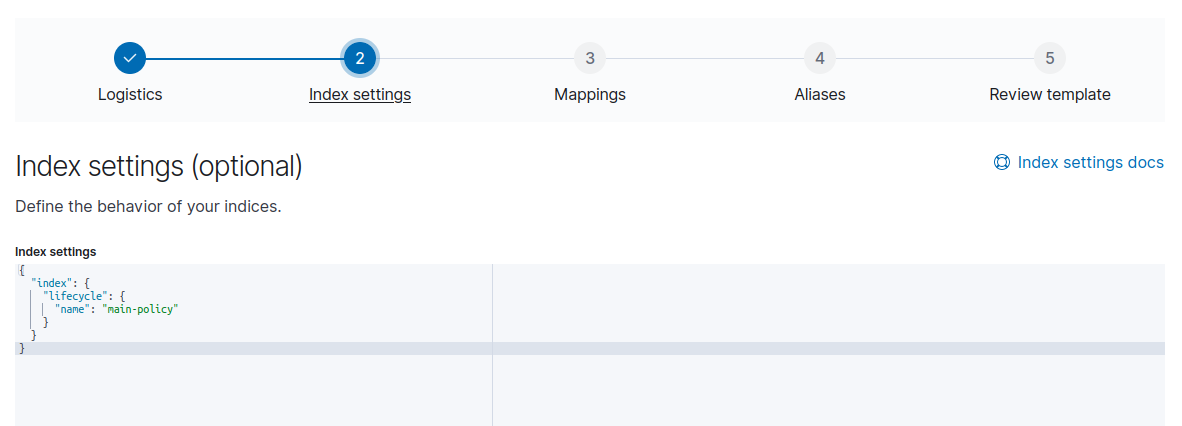
Теперь настроим использование созданной lifecycle policy в index template. Для этого необходимо:
"index": {
“lifecycle”: {
“name”: “main-policy”
}
}
В параметре name необходимо указать название только что созданной lifecycle policy.
Теперь индекс, который будет использовать данный index template будет также управлять созданной lifecycle policy. Так через неделю после создания ILM удалит его и освободит место для нового индекса.
А ещё получили результаты, которые показывают, что объём индексов реально сокращается. А использование комбинации из всех политик существенно продлевает жизнь индексов. Теперь можем хранить старые данные и использовать их для анализа и статистики.

 habr.com
habr.com
Прежде всего статья будет полезна начинающим специалистам по администрированию ELK стека, администраторам систем мониторинга, разработчикам, внедряющим ELK стек у себя на проекте.
Работая над мониторингом в одном из проектов мы столкнулись с тем, что временной промежуток, за который мы имеем возможность хранить данные, для нас недостаточен, т.к. хотелось иметь возможность сравнивать работу системы за больший период времени.
Мы видели 2 пути решения проблемы:
- Увеличение объёма дискового пространства.
- Уменьшение объёма дискового пространства занимаемого индексами.
Цель
Цель данной статьи рассказать о 4-х простых способах, которые помогли нам сократить объём индексов в Elasticsearch:- Настройка dynamic mapping в index template.
- Использование агрессивного алгоритма сжатия.
- Отключение индексации и doc_value у полей, которые не участвуют в поиске, сортировке и агрегации.
- Использование Lifecycle policy.
Хотя данные способы достаточно просты, они помогли увеличить срок хранения индексов в среднем в 6 раз.
Дисклеймер
Настройка dynamic mapping в index template
Dynamic mapping — это процесс автоматического создания и типизирования полей. Для того чтобы хранить данные, Elasticsearch должен понимать, какой тип данных использовать для обнаруженного поля. Тип данных определяется на основе правил, показанных в следующей таблице:
Подробнее про dynamic mapping:
Так мы видим, что тип string преобразуется сразу в два типа данных. Это значит, что значение поля string в Elasticsearch будет храниться и как text, и как keyword.
text — тип данных, который позволяет использовать полнотекстовый поиск. Однако text нельзя использовать для сортировки и агрегации.
keyword — тип данных, который позволяет индексировать строку как есть. Используется для сортировки, агрегации и в term-level queries.
Есть хорошая статья, которая объясняет все различия между этими двумя типами.
Мы в своём проекте решили использовать только тип keyword, чтобы сократить объем и время индексации, т.к. не пользуемся полнотекстовым поиском.
Рассмотрим как настроить dynamic mapping для полей в index template на практическом примере. Данный пример позволяет преобразовать string только в keyword, но так же можно настроить преобразование в text.
Прежде всего, необходимо:
- Перейти в раздел: Management -> Stack Management -> index Management
- Открыть раздел: index templates
- Создать новый template или зайти в существующий
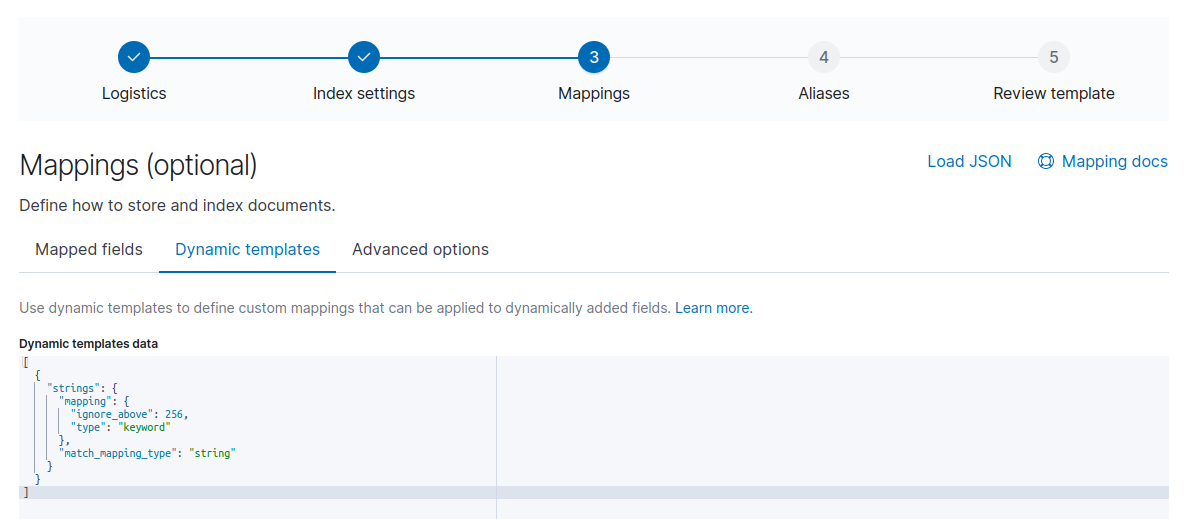
- В разделе Mapping->dynamic_template необходимо добавить:
"strings": {
"mapping": {
"ignore_above": 256,
"type": "keyword"
},
"match_mapping_type": "string"
}
}
Теперь при появлении нового поля типа string оно будет преобразовано в keyword. Параметр ignore_above отвечает за максимальный размер keyword, который будет индексироваться. В нашем примере если длина поля больше 256 символов, то оно не будет индексироваться.
Важный момент!
Если отключить индексацию у поля, то по нему нельзя будет произвести поиск. Однако остаётся возможность сортировать и агрегировать. Более подробно по ссылке.
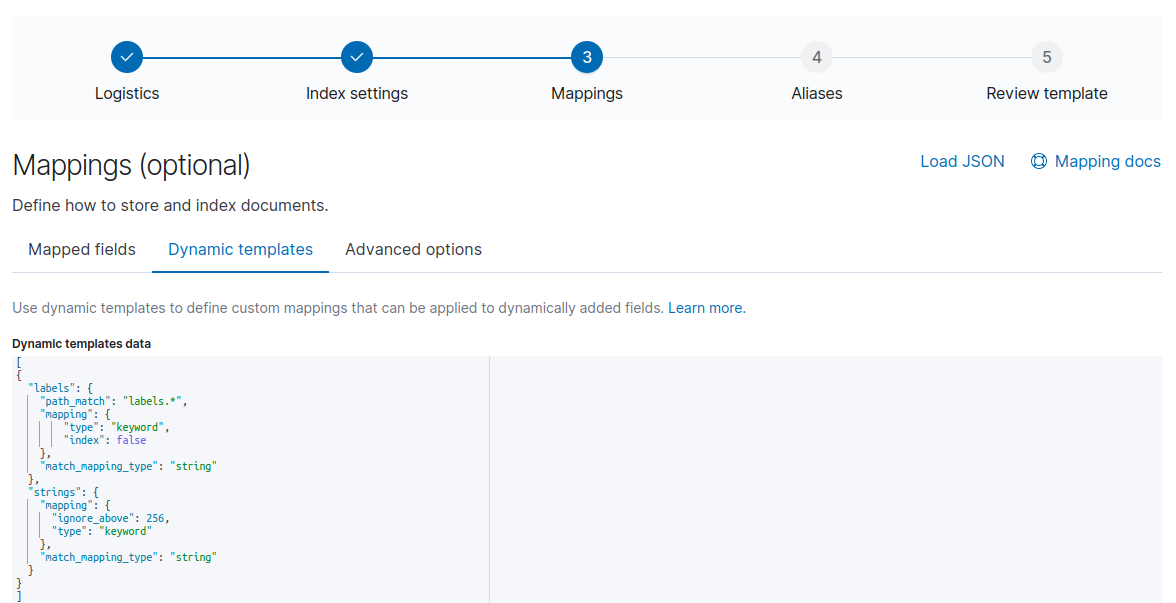
Таким образом, мы можем настроить dynamic mapping и для других типов, а с помощью интерфейса или api в index template указать дополнительный настройки для полей. Например, мы можем использовать регулярные выражения, чтобы поля с определенными именами преобразовывались в указанный тип данных и не индексировались.
{ "labels": {
"path_match": "labels.*",
"mapping": {
"type": "keyword",
“index”: false
},
"match_mapping_type": "string"
}
В данном примере, поля начинающиеся на labels. будут преобразованы в тип keyword и у этих полей будет отключена индексация.
Даты и числа
Преобразование дат и чисел в тип данных date и long, вместо keyword поможет снизить объём индексов.Для того, чтобы включить dynamic mapping для дат и чисел, необходимо следующее:
- Перейти в раздел: Management -> Stack Management -> index Management
- Открыть раздел: index templates
- Создать новый template или зайти в существующий
- В разделе Mapping -> Advanced option включить следующее:
Параметры Map numeric strings as numbers и Map date strings as dates
Если до конвертации данных в date и long, вы могли использовать запросы со звёздочкой, например “response_code:5*” и получать все документы в поле response_code которых содержатся 5xx http коды ответа, то после конвертации, вам необходимо использовать операторы сравнения, т.е. запрос будет выглядеть так: “response_code: >= 500”.
Итог
Мы уже определили dynamic mapping в index template, дополнительно указали преобразование дат и чисел как date и long соответственно, но насколько нам удалось сократить объём индекса?Чтобы иметь какие-то сравнительные результаты:
(1) Сначала запустим сбор логов без наших настроек:
(2) А после добавим наши улучшения:
Получаем:
- На 1 млн docs ~= 5,7 gb
- На 1 млн docs ~= 4,8 gb
Более подробную информацию про dynamic templates можно прочитать в документации.
Использование агрессивного алгоритма сжатия
По умолчанию elasticsearch использует алгоритм сжатия LZ4. LZ4 — это алгоритм сжатия данных без потерь, который ориентирован на быстрое сжатие данных. Чаще всего его используют в приложениях, где большая нагрузка и требуется дешевое и быстрое сжатие данных без дополнительных нагрузок на CPU.Вместо LZ4 можно настроить использование алгоритма DEFLATE. DEFLATE — алгоритм сжатия данных без потерь, который использует комбинацию LZ77 и Хаффмана. Алгоритм ориентирован на более эффективное сжатие повторно встречающихся данных. Требует больше времени на сжатие\распаковку и больше ресурсов CPU.
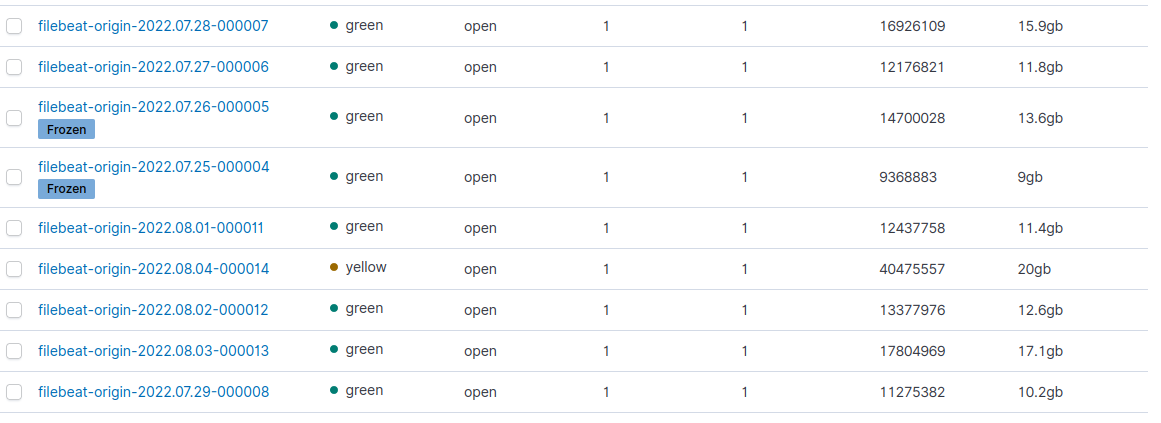
Недавний пример: один из наших сервисов стал присылать 5хх ошибок больше, чем ожидалось. Пиковая нагрузка около 50 RPS, каждая ошибка порождала дополнительно одинаковые логи, не считая нормальную работу приложения по другим сервисам. В тот момент у нас уже был настроен алгоритм сжатия DEFLATE. Посмотрите на 13 и 14 индексы на картинке ниже. Мы видим, что разница в объёме 13 и 14 индекса ~3гб, а разница в docs больше чем в 2 раза.
Чтобы использовался алгоритм DEFLATE, а не LZ4, нужно указать его использование в index template.
Для этого необходимо:
- Открыть раздел: index templates
- Выбрать template, в котором хотите использовать алгоритм сжатия DEFLATE
- В разделе index settings добавить:
"index": {
“code”: “best_compression”
}
Если “index” у вас уже содержит какие-то поля, то просто добавить “code”:”best_compression”.
Важный момент!
Как было сказано раньше, агрессивный алгоритм сжатия DEFLATE требует
больше ресурсов, чем LZ4. Поэтому попробуйте протестировать его, прежде
чем использовать его по умолчанию в ваших index templates.
Итог
Нас, как инженеров и математиков, интересуют только цифры и факты (ну и котики). Давайте сравним объём индекса с использованием:- LZ4
- DEFLATE
- Dynamic mapping + DEFLATE
(2) Объём второго индекса с DEFLATE
(3) Объём индекса с dynamic mapping + DEFLATE
Получаем следующие цифры для трех индексов:
- 1 млн docs ~= 5,7 gb
- 1 млн docs ~= 3,7 gb
- 1 млн docs ~= 1,5 gb
Отключение индексации и doc_value у полей, которые не участвуют в поиске, сортировке и агрегации
Случается, что в логах присутствуют поля, по которым нельзя производить поиск, сортировать или агрегировать, но они используются при чтении логов. Например, у нас на проекте есть поле exception, которое выводит сообщение об ошибке в python коде. Поле содержит большое количество символов и искать по нему, не говоря о сортировке и агрегировании — не лучшая идея.Возможно, у вас есть ещё какие-то полезные поля, которые никак не используются, кроме как при непосредственном чтении логов. Поэтому, чтобы уменьшить их влияние на объём индекса, воспользуйтесь следующими шагами:
Отключение индексации
Неиспользуемые поля с индексацией опасны тем, что при их большом количестве, они значительно увеличивают объём индекса. Особенно если такие поля у вас содержат большее количество символов (длинные поля).
Поэтому давайте рассмотрим, что необходимо настроить для отключения индексации:
- Если полей много
- Перейти в раздел: Management -> Stack Management -> index Management
- Открыть раздел: index templates
- Создать новый template или зайти в существующий
- В разделе dynamic_template необходимо добавить:
"longfield": {
"path_match": "longfield.*",
"mapping": {
"type": "keyword",
“index”: false
},
"match_mapping_type": "string"
}
В поле path_match вместо longfield.* можно подставить своё регулярное выражение. Параметр index: false отключает индексацию
- Если полей немного
- Перейти в раздел: Management -> Stack Management -> index Management
- Открыть раздел: index templates
- Создать новый template или зайти в существующий
- В разделе mappings -> mapped fields добавить имя поля и отключить параметр Searchable как на картинке ниже
Возможен случай, когда вы собираете какие-то поля, но в данный момент не используете их для поиска. Тогда подумайте над тем, чтобы не сохранять их в _source, чтобы оптимизировать объём индекса.
_source — это поле, хранящее исходное тело документа в json, которое было передано во время индексации.
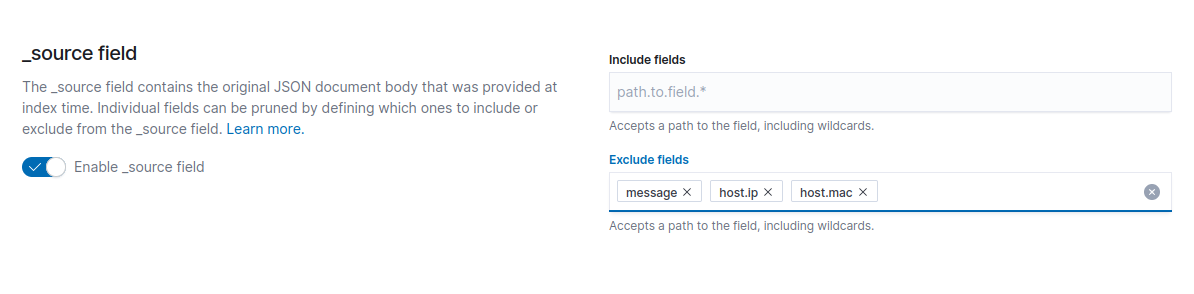
Чтобы не сохранять какое-то поле в _source, нужно сделать следующее:
- Переходим в index templates -> Mappings -> advanced option
- Пролистываем до раздела _source:
В раздел exclude fields добавляем название полей, которые не нужно сохранять в _source.
Если вы хотите добавить какое-то поле в _source, просто добавьте его в поле include fields.
Отключение doc_value
Хотя использование инвертированного индекса значительно ускоряет поиск, но для сортировки и агрегации его использование менее эффективно, чем структуры похожей на инвертированный индекс, где значения хранятся в виде столбцов. Такой структурой в Elasticsearch является doc_value.
doc_value — структура, которая создается во время индексации документа, поэтому отключение индексации может отключить сортировку и агрегирование. Однако типы данных numeric, date, boolean, keyword, etc. могут использоваться для сортировки и агрегации, даже если индексация для них отключена.
Чтобы отключить doc_value для поля, необходимо:
- Перейти в раздел: Management -> Stack Management -> index Management
- Открыть раздел: index templates
- Создать новый template или зайти в существующий
- В разделе dynamic_template добавить:
"longfield": {
"path_match": "longfield.*",
"mapping": {
"type": "keyword",
“doc_value”: false
},
"match_mapping_type": "string"
}
В данном примере все поля начинающиеся на longfield. с типом string будут сопоставляться c keyword, и у них будет отключено doc_value, из-за чего по ним нельзя будет сортировать и агрегировать.
Итог
Старайтесь уменьшить количество полей с включенной индексацией и doc_value, особенно если это длинные поля. Если какие-то поля в текущий момент не используются, но сохраняются, старайтесь не добавлять их в _source.Про отключение индексации мы уже достаточно поговорили, теперь давайте смотреть цифры (и котиков).
Сравним объём индексов:
- Без способов оптимизации
- С отключением индексации некоторых полей
- С использованием индексации некоторых полей и предыдущих способов оптимизации
(2) Объём индекса с отключением индексации некоторых полей
(3) Объём индекса с использованием индексации некоторых полей и предыдущих способов оптимизации
Получаем:
- 1 млн docs ~= 5,7 gb
- 1 млн docs ~= 3,7 gb
- 1 млн docs ~= 1,3 gb
Использование Lifecycle policy
Многоуровневая архитектура в ElasticsearchДля эффективного распределения ресурсов и хранения данных в Elasticsearch реализована hot-warm-cold архитектура, состоящая из 4-х фаз:
- hot
- warm
- cold
- freeze
Lifecycle policy позволяет определять фазы и переходы между фазами, что оптимизирует процессы хранения и удаления индексов.
Lifecycle policy не применяется для ранее созданных индексов. Она должна быть указана при создании индекса и будет управлять им с момента его создания до удаления.
Фазы
Для каждой фазы можно настроить свой период пребывания в ней. Это значит что индекс будет переходить из фазы в фазу спустя настроенное время. Отличие только для hot фазы, где кроме времени можно указать объем индекса или количество docs, превысив значение которых, состоится переход в следующую настроенную фазу.Кроме этого, мы можем пропускать какие-то фазы. Например, индекс в hot фазе может сразу перейти в cold или из warm в delete.
Только что созданный индекс находится в hot фазе — это значит, что индекс доступен для записи\чтения. Заполняется новыми логами, а значит информация часто запрашивается и представляет наибольшую ценность. Данные активно индексируются и никак дополнительно не сжимаются (работают только настройки index template). Поэтому индекс в hot фазе занимает больше всего места на диске и требует больше ресурсов СPU + SSD при работе с ним.
Warm фаза — индекс в данной фазе доступен для чтения. Используются для устаревших данных, которые всё ещё представляют ценность. Поиск происходит медленнее чем в hot фазе. Поэтому индексам в warm фазе требуется меньше ресурсов CPU + SSD при работе с ними.
Cold фаза — индекс в данной фазе доступен для чтения. Используются для данных, которые запрашиваются крайне редко. Поиск может занимать ещё больше времени чем в warm фазе. Наименьшая потребность в ресурсах CPU + SSD.
Freeze фаза — индекс в данной фазе недоступен для чтения\записи. Используется для хранения данных до лучших времен, если такое необходимо. Объём индексов можно значительно уменьшить. Потребность в дисковых ресурсах, но почти не требует CPU ресурсов.
Конец любой lifecycle policy — delete фаза. В delete фазе происходит удаление индексов.
После настройки ILM (index lifecycle management) вам больше не нужно следить за удалением, добавлением и сжиманием индексов. ILM всё делает автоматически. Главное верно указать триггеры перехода, чтобы ваше дисковое пространство не заполнилось раньше, чем удалится первый индекс с настроенной lifecycle policy.
Индекс переходит из фазы в фазу, когда время жизни индекса в данной фазе подходит к концу. Кроме hot фазы, в которой есть возможность настроить сразу несколько триггеров:
- Объем индекса
- Количество docs в индексе
- Время жизни индекса
Как только одно из условий будет выполнено, наш индекс перейдет на следующую фазу. А ILM создаст новый индекс в hot фазе — этот процесс называется rollover.
Как это работает?
Для этого elasticsearch использует alias, которые нужны, чтобы создать новый индекс и понимать где хранить поступающие логи.Вот в чём проблема: чтобы создать новый индекс, после того как прошлый уже выполнил rollover, lifecycle policy должен понимать, какое название дать новому индексу. К сожалению, просто указать alias ничего не даст. У вас получится ситуация из 2-х одинаковых индексов, а ещё система не сможет вести подcчёт и выдаст ошибку.
Подробнее про rollover можно прочитать тут.
Рассмотрим самый простой способ использования ILM:
Прежде всего мы рассмотрим наиболее популярный случай использования ILM для индексов. Мы настроим hot и delete фазу без rollover. Таким образом наши индексы будут находиться в hot фазе всё время до удаления. Это самый простой способ автоматизации, дополнительные настройки и возможности ILM можно найти в других статьях и документации.
Для того чтобы использовать lifecycle policy, нужно её настроить. Для этого:
- Переходим в раздел index lifecycle policies
- Создаем новую политику
Один из примеров интерфейса, возможно у вас будет что-то такое:
В hot phase, нам нужно отключить параметр Enable rollover для того, чтобы наш индекс был в hot фазе всё время до удаления и не создавал дополнительных alias во время жизни.
На данном этапе мы укажем имя политики как main-policy. Затем опускаемся в самый вниз и включаем delete фазу. Например, через неделю после создания наш индекс должен быть удалён.
Теперь настроим использование созданной lifecycle policy в index template. Для этого необходимо:
- Перейти в раздел: Management -> Stack Management -> index Management
- Открыть раздел: index templates
- Создать новый template или зайти в существующий
- В разделе Mapping -> index settings необходимо добавить блок lifecycle:
"index": {
“lifecycle”: {
“name”: “main-policy”
}
}
В параметре name необходимо указать название только что созданной lifecycle policy.
Теперь индекс, который будет использовать данный index template будет также управлять созданной lifecycle policy. Так через неделю после создания ILM удалит его и освободит место для нового индекса.
Итог
Мы рассмотрели 4 способа оптимизации объёма индексов. Последний способ, больше про полезную автоматизацию, которая может сохранить много трудовых часов и позволит крепче и дольше спать.А ещё получили результаты, которые показывают, что объём индексов реально сокращается. А использование комбинации из всех политик существенно продлевает жизнь индексов. Теперь можем хранить старые данные и использовать их для анализа и статистики.
4 простых способа оптимизировать объём индексов в Elasticsearch
Данила Беляев SR-инженер ГК Юзтех Введение Всем привет! Меня зовут Данила, я выполняю роль SR-инженера в Usetech. В этой статье я бы хотел рассказать о 4-х способах, которые помогут сократить объём...
habr.com