Недавно столкнулся с проблемным запросом, который делал отбор по столбцу с типом nvarchar(max). Про производительность отборов по nvarcar(max) я уже писал, а сейчас решил сделать пост о том, как можно решить проблему, если фильтр по nvarchar(max) нужен.
В первой части я покажу что можно сделать, если на самом деле nvarchar(max) не был нужен, а хватило бы "нормальной" длины, с которой столбец можно проиндексировать. А во второй - что делать, если строка на самом деле такая длинная, что проиндексировать столбец с ней не представляется возможным.
Я не могу показать проблемный запрос в том виде, как он был, но, упрощённо, его самая проблемная часть сводилась вот к такому:
SELECT id
FROM smth
WHERE
field1 = @v1
OR field2 = @v2
OR field3 = @v3
Колонка field1 была проиндексирована, а field2 и field3 мало того, что не были, так ещё и имели тип nvarchar(max). Причём, не смотря на кажущееся очень неприятным условие, эта часть всегда возвращает очень небольшое количество записей - от нуля до нескольких десятков.
Для начала, создам таблицу, с помощью которой можно воспроизвести проблему:
CREATE TABLE smth (
id int IDENTITY PRIMARY KEY,
field1 nvarchar(200),
field2 nvarchar(max),
field3 nvarchar(max),
/* добавляю столбцы, чтобы сканировать кластерный индекс не всегда было выгодно */
field4 nvarchar(max),
field5 nvarchar(max),
field6 nvarchar(max),
field7 nvarchar(max),
field8 nvarchar(max),
field9 nvarchar(max),
field0 nvarchar(max),
/* а там ещё 40 столбцов с разными типами */
);
GO
Реальная таблица достаточно широкая и содержит под сотню миллионов записей, мы сделаем поменьше:
--заполним случайными данными
;WITH
n AS (
SELECT 0 n UNION ALL SELECT 0
), n1 AS (
SELECT 0 n
FROM n, n n1, n n2
), n2 AS (
SELECT 0 n
FROM n1 n, n1 n1, n1 n2
), nums AS (
SELECT 0 n /* 262144 строк */
FROM n2 n, n2 n1
)
INSERT INTO smth (field1, field2, field3, field4, field5, field6, field7, field8, field9, field0)
SELECT
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field1,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field2,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field3,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field4,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field5,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field6,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field7,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field8,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field9,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field0
FROM nums;
GO
--добавляем дубли
INSERT INTO smth (field1, field2, field3)
SELECT field1, field2, field3
FROM smth;
GO 4 -- 4194304 строк
В результате получилась таблица с 4194304 записями.
Как я уже говорил, столбец field1 проиндексирован, поэтому тоже создаю индекс, выбираю произвольные значения и выполняю запрос:
CREATE INDEX ix_ST ON smth (field1);
GO
SET STATISTICS TIME, IO, XML ON;
SELECT id
FROM smth
WHERE
field1 = N'0FCD0182-AF6E-47E9-94F9-456F2047992C'
OR field2 = N'67D1B1C6-8E11-4E7F-BDAD-EF33D8D3AF87'
OR field3 = N'D75B375A-E977-4EDD-A836-7AF4967B8BFD'
SET STATISTICS TIME, IO, XML OFF;
В результате, получаю 16 строк за примерно 4 секунды процессорного времени:
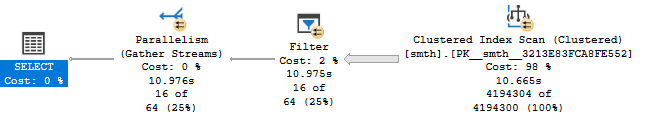
В плане запроса, как можно увидеть, просто сканирование кластерного индекса - это логично, т.к. поля field2 и field3 не входят в индекс по field1.
Первое, что приходит в голову - создать индексы по field2 и field3, но как я уже говорил, эти поля имеют типы nvarchar(max), поэтому индекс по ним создать нельзя. Но, можно включить их в существующий индекс, как include-поля. Давайте попробуем:
CREATE INDEX ix_ST ON smth (field1) INCLUDE (field2, field3) WITH (DROP_EXISTING = ON);
Теперь у нас есть покрывающий индекс, в котором есть все поля, необходимые запросу. Но сильно ли он помогает? Выполнив тот же запрос, получаю:
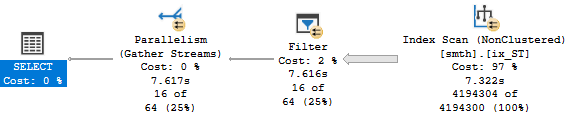
Как видно, индекс используется, но, как и ожидалось, не очень эффективно - сначала проходит его полное сканирование и затем уже применяется заданный фильтр по трём полям. Запрос, в принципе, уже выполняется быстрее, но можно ли сделать его ещё лучше?
Поскольку мы говорим о не самом удачном дизайне таблицы, то да, можно В полях field2 и field3 фактическая максимальная длина (в реальном запросе) не превышает 200 символов, поэтому было бы здорово изменить у них тип данных на более подходящий. К сожалению, я не могу менять типы данных у существующих столбцов.
Попробуем добавить вычисляемые столбцы и проиндексировать их.
ALTER TABLE smth
ADD field2_calculated AS CAST(LEFT(field2, 400) AS nvarchar(400));
ALTER TABLE smth
ADD field3_calculated AS CAST(LEFT(field3, 400) AS nvarchar(400));
CREATE INDEX ix_ON ON smth (field2_calculated);
CREATE INDEX ix_ED ON smth (field3_calculated);
Теперь выполним запрос в модифицированном виде:
SET STATISTICS TIME, IO, XML ON;
SELECT id
FROM smth
WHERE
field1 = N'0FCD0182-AF6E-47E9-94F9-456F2047992C'
OR CAST(LEFT(field2, 400) AS nvarchar(400)) = N'67D1B1C6-8E11-4E7F-BDAD-EF33D8D3AF87'
OR CAST(LEFT(field3, 400) AS nvarchar(400)) = N'D75B375A-E977-4EDD-A836-7AF4967B8BFD'
Ура!
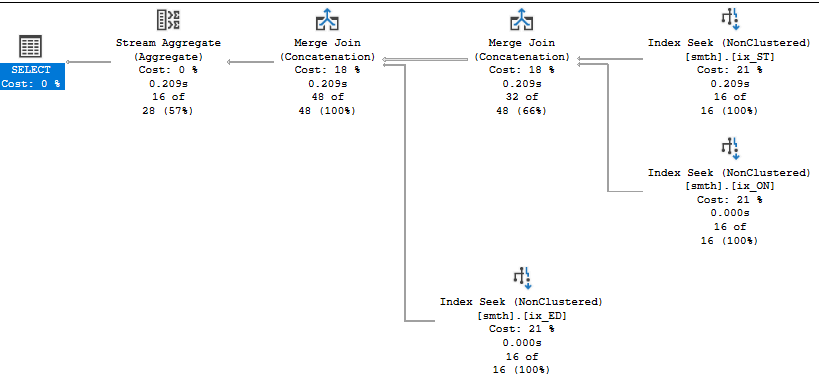 Примечание
Примечание
Поскольку в field2 и field3 допустимы NULL'ы, а мы ищем по точному совпадению, имеет смысл делать фильтрованные индексы, с условием field2 IS NOT NULL и field3 IS NOT NULL (не забывая добавить их в запрос). Это вряд ли уменьшит количество чтений, но может очень сильно уменьшить размер индекса, если NULL-значений много.
А что делать, если nvarchar(max) реально нужен?
Для примера возьму таблицу dbo.Users из БД StackOverflow2013 (я использую Medium-вариант, содержащий данные с 2008 по 2013 год). В ней есть столбец AboutMe, по которому я и хочу искать.
SARGability
Напомню, что поиск всегда будет эффективным либо по полному равенству, либо по LIKE 'smth%', если использовать CHARINDEX или LIKE '%smth%', индексы вам сильно не помогут. Для эффективного использования индекса условия должны быть SARGable.
Итак, для примера посмотрим сколько будет выполняться такой запрос (я выбрал самое длинное значение поля AboutMe):
DECLARE @var AS nvarchar(max);
SELECT TOP 1 @var = AboutMe
FROM dbo.Users
WHERE LEN(AboutMe) = (SELECT MAX(LEN(AboutMe)) FROM dbo.Users);
SET STATISTICS TIME, IO, XML ON;
SELECT *
FROM dbo.Users
WHERE AboutMe = @var
OPTION (RECOMPILE);
SET STATISTICS TIME, IO, XML OFF;
OPTION (RECOMPILE) я использую для того, чтобы оптимизатор лучше мог оценивать ожидаемое количество строк. Про то, как локальные переменные могут влиять на это можно прочитать здесь. А переменную использую, потому что ищу значение длиной больше 5000 символов.
ALTER TABLE dbo.Users
ADD AboutMeHash AS CHECKSUM(AboutMe);
CREATE INDEX ix_hash ON dbo.Users (AboutMeHash);
Все мы знаем про возможные коллизии, поэтому дополнительно требуется проверка на полное совпадение:
DECLARE @var AS nvarchar(max);
SELECT TOP 1 @var = AboutMe
FROM dbo.Users
WHERE LEN(AboutMe) = (SELECT MAX(LEN(AboutMe)) FROM dbo.Users);
SET STATISTICS TIME, IO, XML ON;
SELECT *
FROM dbo.Users
WHERE CHECKSUM(AboutMe) = CHECKSUM(@var) AND AboutMe = @var
OPTION (RECOMPILE);
SET STATISTICS TIME, IO, XML OFF;
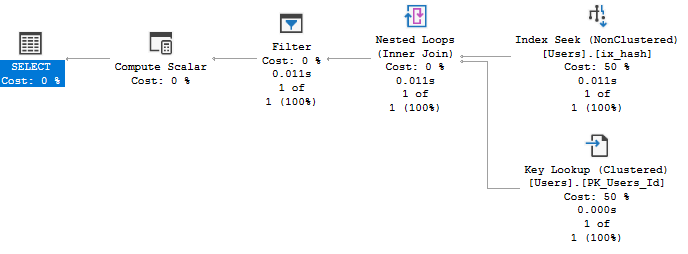
Находим полные совпадения по хэшу, дополняем полными значениями и фильтруем по ним. Успех? Успех!
Дополнительно, если мы всё-таки хотим иметь возможность поиска с помощью LIKE smth%, мы можем использовать такой способ (который может не всегда подойти, в зависимости от содержимого столбца):
ALTER TABLE dbo.Users
ADD AboutMeLeft AS CAST(LEFT(AboutMe, 800) AS nvarchar(800));
CREATE INDEX ix_lef ON dbo.Users (AboutMeLeft);
Теперь первые 800 символов (у меня SQL Server 2017, где максимальная длина ключа некластерного индекса составляет 1600 байт, если у вас SQL Server старше 2016, вы ограничены 900 байтами) можно использовать как нам угодно. Либо так же, как в предыдущем случае, либо с помощью LIKE:
DECLARE @var AS nvarchar(max);
SELECT TOP 1 @var = AboutMe
FROM dbo.Users
WHERE LEN(AboutMe) = (SELECT MAX(LEN(AboutMe)) FROM dbo.Users);
SET STATISTICS TIME, IO, XML ON;
SELECT *
FROM dbo.Users
WHERE CAST(LEFT(AboutMe, 800) AS nvarchar(800)) = CAST(LEFT(@var, 800) AS nvarchar(800)) AND AboutMe = @var
OPTION (RECOMPILE);
SET STATISTICS TIME, IO, XML OFF;
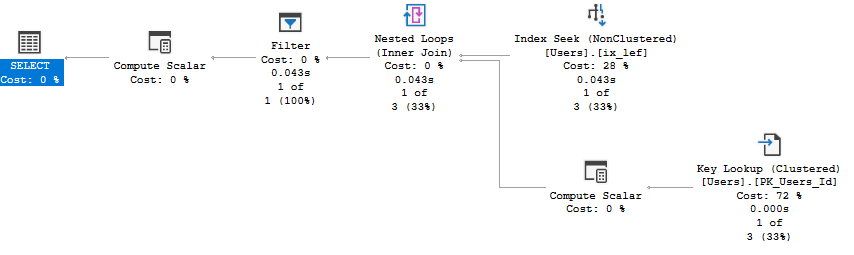 DECLARE @var AS nvarchar(max);
DECLARE @var AS nvarchar(max);
SELECT TOP 1 @var = LEFT(AboutMe, 10)
FROM dbo.Users
WHERE Id = 9; --случайный Id
SET STATISTICS TIME, IO, XML ON;
SELECT *
FROM dbo.Users
WHERE CAST(LEFT(AboutMe, 800) AS nvarchar(800)) LIKE @var + N'%'
OPTION (RECOMPILE);
SET STATISTICS TIME, IO, XML OFF;
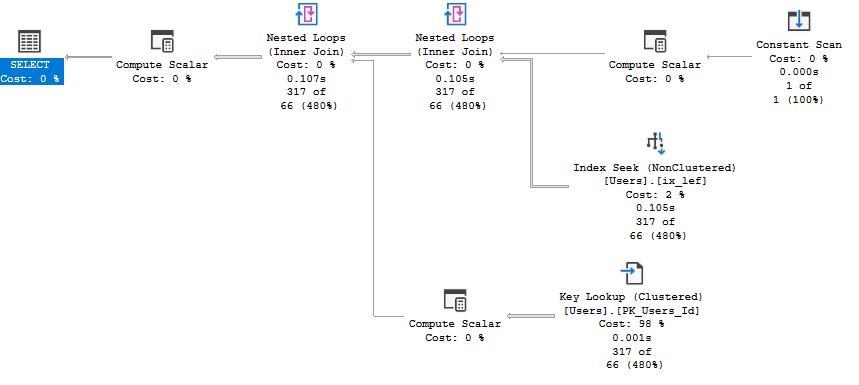
Если сама таблица достаточно "широкая" и Key Lookup'ы дороги, а доставать нужно, например, только идентификатор, то само значение может иметь смысл включать в индекс по вычисляемому полю в качестве INCLUDE-поля.
Про вычисляемые столбцы не очень часто вспоминают как о "технике оптимизации" (здесь, например, о них говорят скорее как о потенциальной "угрозе" производительности), однако, иногда они могут сильно помочь.

 habr.com
habr.com
В первой части я покажу что можно сделать, если на самом деле nvarchar(max) не был нужен, а хватило бы "нормальной" длины, с которой столбец можно проиндексировать. А во второй - что делать, если строка на самом деле такая длинная, что проиндексировать столбец с ней не представляется возможным.
Я не могу показать проблемный запрос в том виде, как он был, но, упрощённо, его самая проблемная часть сводилась вот к такому:
SELECT id
FROM smth
WHERE
field1 = @v1
OR field2 = @v2
OR field3 = @v3
Колонка field1 была проиндексирована, а field2 и field3 мало того, что не были, так ещё и имели тип nvarchar(max). Причём, не смотря на кажущееся очень неприятным условие, эта часть всегда возвращает очень небольшое количество записей - от нуля до нескольких десятков.
Для начала, создам таблицу, с помощью которой можно воспроизвести проблему:
CREATE TABLE smth (
id int IDENTITY PRIMARY KEY,
field1 nvarchar(200),
field2 nvarchar(max),
field3 nvarchar(max),
/* добавляю столбцы, чтобы сканировать кластерный индекс не всегда было выгодно */
field4 nvarchar(max),
field5 nvarchar(max),
field6 nvarchar(max),
field7 nvarchar(max),
field8 nvarchar(max),
field9 nvarchar(max),
field0 nvarchar(max),
/* а там ещё 40 столбцов с разными типами */
);
GO
Реальная таблица достаточно широкая и содержит под сотню миллионов записей, мы сделаем поменьше:
--заполним случайными данными
;WITH
n AS (
SELECT 0 n UNION ALL SELECT 0
), n1 AS (
SELECT 0 n
FROM n, n n1, n n2
), n2 AS (
SELECT 0 n
FROM n1 n, n1 n1, n1 n2
), nums AS (
SELECT 0 n /* 262144 строк */
FROM n2 n, n2 n1
)
INSERT INTO smth (field1, field2, field3, field4, field5, field6, field7, field8, field9, field0)
SELECT
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field1,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field2,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field3,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field4,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field5,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field6,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field7,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field8,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field9,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field0
FROM nums;
GO
--добавляем дубли
INSERT INTO smth (field1, field2, field3)
SELECT field1, field2, field3
FROM smth;
GO 4 -- 4194304 строк
В результате получилась таблица с 4194304 записями.
Как я уже говорил, столбец field1 проиндексирован, поэтому тоже создаю индекс, выбираю произвольные значения и выполняю запрос:
CREATE INDEX ix_ST ON smth (field1);
GO
SET STATISTICS TIME, IO, XML ON;
SELECT id
FROM smth
WHERE
field1 = N'0FCD0182-AF6E-47E9-94F9-456F2047992C'
OR field2 = N'67D1B1C6-8E11-4E7F-BDAD-EF33D8D3AF87'
OR field3 = N'D75B375A-E977-4EDD-A836-7AF4967B8BFD'
SET STATISTICS TIME, IO, XML OFF;
В результате, получаю 16 строк за примерно 4 секунды процессорного времени:
(16 rows affected) Table 'smth'. Scan count 9, logical reads 84083, physical reads 0, read-ahead reads 83155, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 3937 ms ...
В плане запроса, как можно увидеть, просто сканирование кластерного индекса - это логично, т.к. поля field2 и field3 не входят в индекс по field1.
Первое, что приходит в голову - создать индексы по field2 и field3, но как я уже говорил, эти поля имеют типы nvarchar(max), поэтому индекс по ним создать нельзя. Но, можно включить их в существующий индекс, как include-поля. Давайте попробуем:
CREATE INDEX ix_ST ON smth (field1) INCLUDE (field2, field3) WITH (DROP_EXISTING = ON);
Теперь у нас есть покрывающий индекс, в котором есть все поля, необходимые запросу. Но сильно ли он помогает? Выполнив тот же запрос, получаю:
(16 rows affected) Table 'smth'. Scan count 9, logical reads 65855, physical reads 0, read-ahead reads 64878, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 2874 ms ...
Как видно, индекс используется, но, как и ожидалось, не очень эффективно - сначала проходит его полное сканирование и затем уже применяется заданный фильтр по трём полям. Запрос, в принципе, уже выполняется быстрее, но можно ли сделать его ещё лучше?
Поскольку мы говорим о не самом удачном дизайне таблицы, то да, можно В полях field2 и field3 фактическая максимальная длина (в реальном запросе) не превышает 200 символов, поэтому было бы здорово изменить у них тип данных на более подходящий. К сожалению, я не могу менять типы данных у существующих столбцов.
Попробуем добавить вычисляемые столбцы и проиндексировать их.
ALTER TABLE smth
ADD field2_calculated AS CAST(LEFT(field2, 400) AS nvarchar(400));
ALTER TABLE smth
ADD field3_calculated AS CAST(LEFT(field3, 400) AS nvarchar(400));
CREATE INDEX ix_ON ON smth (field2_calculated);
CREATE INDEX ix_ED ON smth (field3_calculated);
Теперь выполним запрос в модифицированном виде:
SET STATISTICS TIME, IO, XML ON;
SELECT id
FROM smth
WHERE
field1 = N'0FCD0182-AF6E-47E9-94F9-456F2047992C'
OR CAST(LEFT(field2, 400) AS nvarchar(400)) = N'67D1B1C6-8E11-4E7F-BDAD-EF33D8D3AF87'
OR CAST(LEFT(field3, 400) AS nvarchar(400)) = N'D75B375A-E977-4EDD-A836-7AF4967B8BFD'
Ура!
(16 rows affected) Table 'smth'. Scan count 3, logical reads 14, physical reads 0, read-ahead reads 2, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 0 ms ...
Поскольку в field2 и field3 допустимы NULL'ы, а мы ищем по точному совпадению, имеет смысл делать фильтрованные индексы, с условием field2 IS NOT NULL и field3 IS NOT NULL (не забывая добавить их в запрос). Это вряд ли уменьшит количество чтений, но может очень сильно уменьшить размер индекса, если NULL-значений много.
А что делать, если nvarchar(max) реально нужен?
Для примера возьму таблицу dbo.Users из БД StackOverflow2013 (я использую Medium-вариант, содержащий данные с 2008 по 2013 год). В ней есть столбец AboutMe, по которому я и хочу искать.
SARGability
Напомню, что поиск всегда будет эффективным либо по полному равенству, либо по LIKE 'smth%', если использовать CHARINDEX или LIKE '%smth%', индексы вам сильно не помогут. Для эффективного использования индекса условия должны быть SARGable.
Итак, для примера посмотрим сколько будет выполняться такой запрос (я выбрал самое длинное значение поля AboutMe):
DECLARE @var AS nvarchar(max);
SELECT TOP 1 @var = AboutMe
FROM dbo.Users
WHERE LEN(AboutMe) = (SELECT MAX(LEN(AboutMe)) FROM dbo.Users);
SET STATISTICS TIME, IO, XML ON;
SELECT *
FROM dbo.Users
WHERE AboutMe = @var
OPTION (RECOMPILE);
SET STATISTICS TIME, IO, XML OFF;
OPTION (RECOMPILE) я использую для того, чтобы оптимизатор лучше мог оценивать ожидаемое количество строк. Про то, как локальные переменные могут влиять на это можно прочитать здесь. А переменную использую, потому что ищу значение длиной больше 5000 символов.
Чем в этом случае могут помочь вычисляемые столбцы? Одним из наиболее популярных решений является вычисление хэша, индексирование и сравнение хэшей:Table 'Users'. Scan count 1, logical reads 44530, physical reads 0, read-ahead reads 25515, lob logical reads 106, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 828 ms
ALTER TABLE dbo.Users
ADD AboutMeHash AS CHECKSUM(AboutMe);
CREATE INDEX ix_hash ON dbo.Users (AboutMeHash);
Все мы знаем про возможные коллизии, поэтому дополнительно требуется проверка на полное совпадение:
DECLARE @var AS nvarchar(max);
SELECT TOP 1 @var = AboutMe
FROM dbo.Users
WHERE LEN(AboutMe) = (SELECT MAX(LEN(AboutMe)) FROM dbo.Users);
SET STATISTICS TIME, IO, XML ON;
SELECT *
FROM dbo.Users
WHERE CHECKSUM(AboutMe) = CHECKSUM(@var) AND AboutMe = @var
OPTION (RECOMPILE);
SET STATISTICS TIME, IO, XML OFF;
Table 'Users'. Scan count 1, logical reads 6, physical reads 3, read-ahead reads 0, lob logical reads 8, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 0 ms
Находим полные совпадения по хэшу, дополняем полными значениями и фильтруем по ним. Успех? Успех!
Дополнительно, если мы всё-таки хотим иметь возможность поиска с помощью LIKE smth%, мы можем использовать такой способ (который может не всегда подойти, в зависимости от содержимого столбца):
ALTER TABLE dbo.Users
ADD AboutMeLeft AS CAST(LEFT(AboutMe, 800) AS nvarchar(800));
CREATE INDEX ix_lef ON dbo.Users (AboutMeLeft);
Теперь первые 800 символов (у меня SQL Server 2017, где максимальная длина ключа некластерного индекса составляет 1600 байт, если у вас SQL Server старше 2016, вы ограничены 900 байтами) можно использовать как нам угодно. Либо так же, как в предыдущем случае, либо с помощью LIKE:
DECLARE @var AS nvarchar(max);
SELECT TOP 1 @var = AboutMe
FROM dbo.Users
WHERE LEN(AboutMe) = (SELECT MAX(LEN(AboutMe)) FROM dbo.Users);
SET STATISTICS TIME, IO, XML ON;
SELECT *
FROM dbo.Users
WHERE CAST(LEFT(AboutMe, 800) AS nvarchar(800)) = CAST(LEFT(@var, 800) AS nvarchar(800)) AND AboutMe = @var
OPTION (RECOMPILE);
SET STATISTICS TIME, IO, XML OFF;
Table 'Users'. Scan count 1, logical reads 9, physical reads 0, read-ahead reads 0, lob logical reads 12, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 0 ms
SELECT TOP 1 @var = LEFT(AboutMe, 10)
FROM dbo.Users
WHERE Id = 9; --случайный Id
SET STATISTICS TIME, IO, XML ON;
SELECT *
FROM dbo.Users
WHERE CAST(LEFT(AboutMe, 800) AS nvarchar(800)) LIKE @var + N'%'
OPTION (RECOMPILE);
SET STATISTICS TIME, IO, XML OFF;
(317 rows affected)
Table 'Users'. Scan count 1, logical reads 1000, physical reads 1, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 0 ms
Если сама таблица достаточно "широкая" и Key Lookup'ы дороги, а доставать нужно, например, только идентификатор, то само значение может иметь смысл включать в индекс по вычисляемому полю в качестве INCLUDE-поля.
Про вычисляемые столбцы не очень часто вспоминают как о "технике оптимизации" (здесь, например, о них говорят скорее как о потенциальной "угрозе" производительности), однако, иногда они могут сильно помочь.
Computed Columns и nvarchar(max)
Недавно столкнулся с проблемным запросом, который делал отбор по столбцу с типом nvarchar(max). Про производительность отборов по nvarcar(max) я уже писал , а сейчас решил сделать пост о том, как...
habr.com