GitHub рассказал о причинах глобального сбоя в работе сервиса ноября. Инцидент затронул все основные сервисы GitHub, включая GitHub Actions, API Requests, Codespaces, Git Operations, Issues, GitHub Packages, GitHub Pages, Pull Requests и Webhooks. Специалисты GitHub смогли решить проблему через 2 часа 50 минут. Причина инцидента — новый непредвиденный сбой при обработке схемы миграции для большой таблицы MySQL.
Изначально процесс миграции шел по плану. В его последней стадии планировалось провести переименование, чтобы переместить обновленную таблицу в правильное место.
Именно на этом этапе миграции значительная часть read-реплик MySQL (реплики чтения) попали в тупик семафоров (Semaphore — это связка из блокировки и счетчика потоков).
Кластеры GitHub MySQL состоят из основного узла для записи трафика, нескольких read-реплик для производственного трафика и нескольких read-реплик, которые обслуживают внутренний трафик для целей резервного копирования и аналитики.
В итоге read-реплики GitHub MySQL, попавшие во взаимную блокировку (состояние deadlock), перешли в состояние аварийного восстановления, что привело к увеличению нагрузки на остальные рабочие read-реплики. Из-за каскадного характера этого сценария в системе не было достаточного количества активных read-реплик для обработки текущих производственных запросов, что значительно повлияло на доступность основных сервисов GitHub.
Во время устранения инцидента, стремясь увеличить пропускную способность, специалисты GitHub перевели все доступные внутренние реплики, которые находились в работоспособном состоянии, в рабочий узел. Как оказалось, для решения проблемы этого оказалось недостаточно. Вдобавок read-реплики, обслуживающие производственный трафик, начали вести себя нештатно — они только временно могли функционировать, выйдя из состояния восстановления после сбоя, а потом опять уходили в состояние повторного сбоя из-за нагрузки.
Специалисты GitHub в процессе работ по устранению аварии решили отдать приоритет сохранению целостности данных, пожертвовав на время доступностью сайта и сервисов. Им пришлось вручную удалять весь производственный трафик с поврежденных реплик до тех пор, пока они не смогли успешно пройти нужный этап переименования таблицы. После того, как все реплики были восстановлены, GitHub смог вернуть их в производство и восстановить достаточную емкость, чтобы вернуть сервис к нормальной работе.
GitHub пояснил, что не зафиксировал повреждения данных в процессе сбоя, а во время всего инцидента операции записи работали штатным образом. Чтобы устранить подобные сбои в будущем GitHub уделит приоритетное внимание функциональному разделению кластеров на разделы для повышения отказоустойчивости в процессе миграции. В настоящее время специалисты GitHub продолжают изучать сценарий и причины конкретного сбоя и приостановили миграцию до тех пор, пока не они не определяться с мерами защиты от этой проблемы.
Летом 2020 года основные сервисы GitHub были недоступны более 2-х часов из-за сбоя в работе основного кластера базы данных MySQL.
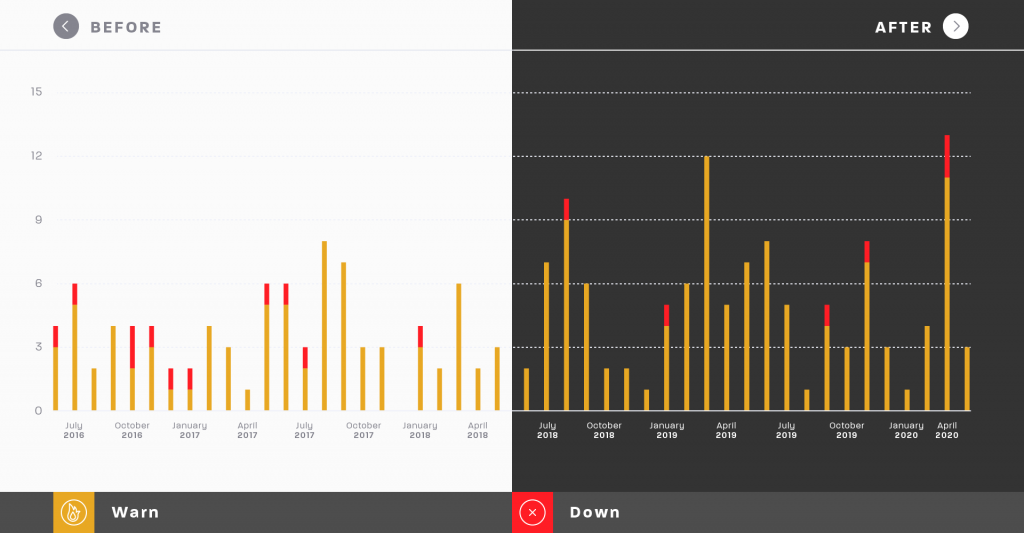
По информации портала Nimble Industries, количество проблем и инцидентов в GitHub после его поглощения Microsoft в 2018 году увеличилось и продолжает расти. Например, более двух лет назад было зафиксировано 89 инцидентов, а в течение последних 24 месяцев их было уже 126, что на 41% больше. Причем растет также и количество минут, когда не работали части сервиса. Если с 2016 по 2018 годы таких минут было 6 110, то с 2018 по 2020 годы GitHub частично не работал 12 074 минуты, что на уже более чем на 100% больше. Таким образом, инцидентов на GitHub становятся больше и они длятся дольше, хотя разработчики сервиса и пытаются максимально прозрачно и открыто сообщать о проблемах и ходе их устранения.
GitHub отчитался о причинах неполадок 27 ноября
Вечером 27 ноября начались проблемы при работе с git клиентом, также не был доступен сайт GitHub (ошибка 500), включая github pages. GitHub рассказал о причинах глобального сбоя в работе сервиса...
 habr.com
habr.com