Эта статья берет за основу Go 1.14.
Go предоставляет механизмы синхронизации памяти, такие как канал (channel) или мьютекс (mutex ), которые помогают решать различные проблемы. Касательно разделяемой памяти, мьютекс защищает память от гонки данных. Однако, несмотря на существование двух типов мьютексов, в целях повышения производительности Go также предоставляет атомарные примитивы памяти в пакете atomic. Но давайте сначала вернемся к гонкам данных, прежде чем углубляться в решения.
Чтобы проиллюстрировать гонку данных, я возьму пример конфигурации, которая постоянно обновляется горутиной. Вот ее код:

Выполнение этого кода ясно показывает, что результат недетерминирован из-за гонки данных:
[...]
&{[79167 79170 79173 79176 79179 79181]}
&{[79216 79219 79220 79221 79222 79223]}
&{[79265 79268 79271 79274 79278 79281]}
Ожидалось, что каждая строка будет непрерывной последовательностью целых чисел, но на деле результат был совершенно рандомным. Запуск той же программы с флагом -race указывает на гонку данных:
WARNING: DATA RACE
Read at 0x00c0003aa028 by goroutine 9:
[...]
fmt.Printf()
/usr/local/go/src/fmt/print.go:213 +0xb5
main.main.func2()
main.go:30 +0x3b
Previous write at 0x00c0003aa028 by goroutine 7:
main.main.func1()
main.go:20 +0xfe
Защита чтения и записи от гонок данных может быть реализована с помощью мьютекса или (что является наиболее распространенным решением) пакетом atomic.

Теперь программа выведет ожидаемый результат; числа увеличились как и должны были:
[...]
&{[213 214 215 216 217 218]}
&{[214 215 216 217 218 219]}
&{[215 216 217 218 219 220]}
Второе решение может быть выполнено благодаря пакету atomic. Вот код:

Результат также является вполне ожидаемым:
[...]
&{[32724 32725 32726 32727 32728 32729]}
&{[32733 32734 32735 32736 32737 32738]}
&{[32753 32754 32755 32756 32757 32758]}
Что касается сгенерированного вывода, похоже, что решение с использованием пакета atomic намного быстрее, поскольку он может генерировать более высокую последовательность чисел. Сравнение обеих программ поможет выяснить, какая из них наиболее эффективная.
Выполнение теста десять раз бок о бок дает следующие результаты:
name time/op
AtomicOneWriterMultipleReaders-4 72.2ns ± 2%
AtomicMultipleReaders-4 65.8ns ± 2%
MutexOneWriterMultipleReaders-4 717ns ± 3%
MutexMultipleReaders-4 176ns ± 2%
Бенчмарк подтверждает то, что мы видели раньше в отношении производительности. Чтобы понять, где именно находится узкое место с мьютексом, мы можем перезапустить программу с включенным трассировщиком.
Для получения дополнительной информации о пакете trace я предлагаю вам прочитать мою статью «Go: Discovery of the Trace Package.».
Вот профиль программы, использующей пакет atomic:

Горутины работают без перерывов и могут выполнять свои задачи. Что касается профиля программы с мьютексом, картина совсем другая:

Время выполнения теперь довольно фрагментировано, и это связано с мьютексом, который паркует горутину. Это подтверждается обзором горутины, где показано время, затраченное на синхронизацию в блокировке:

Время блокировки составляет примерно треть всего времени. Это можно детализировать из профиля блокирующего:

Пакет atomicопределенно дает преимущество в этом случае. Однако в некоторых случаях производительность может снизиться. Например, если вам нужно сохранить большую map, вам придется копировать ее каждый раз при обновлении map, что делает ее неэффективной.
Источник статьи: https://habr.com/ru/company/otus/blog/557312/
Go предоставляет механизмы синхронизации памяти, такие как канал (channel) или мьютекс (mutex ), которые помогают решать различные проблемы. Касательно разделяемой памяти, мьютекс защищает память от гонки данных. Однако, несмотря на существование двух типов мьютексов, в целях повышения производительности Go также предоставляет атомарные примитивы памяти в пакете atomic. Но давайте сначала вернемся к гонкам данных, прежде чем углубляться в решения.
Гонка данных
Гонка данных (data race) может возникать, когда две или более горутины одновременно обращаются к одной и той же области памяти, и хотя бы одна из них выполняет запись. В то время как map имеет собственный механизм защиты от гонки данных, простые структуры их не имеют, что делает их уязвимыми к этой проблеме.Чтобы проиллюстрировать гонку данных, я возьму пример конфигурации, которая постоянно обновляется горутиной. Вот ее код:
Выполнение этого кода ясно показывает, что результат недетерминирован из-за гонки данных:
[...]
&{[79167 79170 79173 79176 79179 79181]}
&{[79216 79219 79220 79221 79222 79223]}
&{[79265 79268 79271 79274 79278 79281]}
Ожидалось, что каждая строка будет непрерывной последовательностью целых чисел, но на деле результат был совершенно рандомным. Запуск той же программы с флагом -race указывает на гонку данных:
WARNING: DATA RACE
Read at 0x00c0003aa028 by goroutine 9:
[...]
fmt.Printf()
/usr/local/go/src/fmt/print.go:213 +0xb5
main.main.func2()
main.go:30 +0x3b
Previous write at 0x00c0003aa028 by goroutine 7:
main.main.func1()
main.go:20 +0xfe
Защита чтения и записи от гонок данных может быть реализована с помощью мьютекса или (что является наиболее распространенным решением) пакетом atomic.
Mutex vs Atomic
Стандартная библиотека предоставляет два вида мьютексов в пакете sync: sync.Mutex и sync.RWMutex; последний оптимизирован для случаев, когда ваша программа имеет дело с множеством читателей и очень небольшим количеством записывателей. Вот одно из решений:
Теперь программа выведет ожидаемый результат; числа увеличились как и должны были:
[...]
&{[213 214 215 216 217 218]}
&{[214 215 216 217 218 219]}
&{[215 216 217 218 219 220]}
Второе решение может быть выполнено благодаря пакету atomic. Вот код:
Результат также является вполне ожидаемым:
[...]
&{[32724 32725 32726 32727 32728 32729]}
&{[32733 32734 32735 32736 32737 32738]}
&{[32753 32754 32755 32756 32757 32758]}
Что касается сгенерированного вывода, похоже, что решение с использованием пакета atomic намного быстрее, поскольку он может генерировать более высокую последовательность чисел. Сравнение обеих программ поможет выяснить, какая из них наиболее эффективная.
Производительность
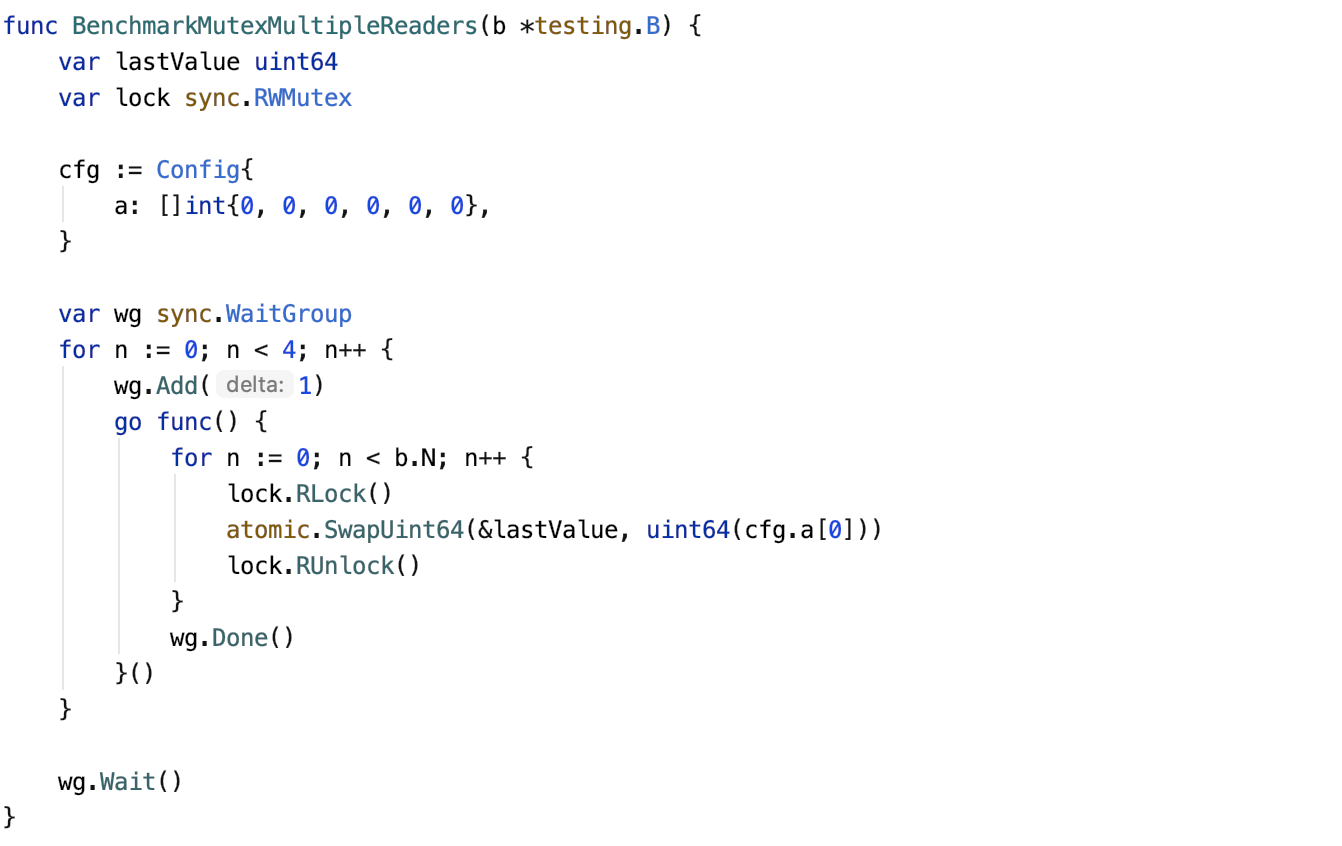
Бенчмарк следует интерпретировать в соответствии с тем, что замеряется. В этом случае я буду измерять предыдущую программу, где у нее есть записыватель, который постоянно хранит новую конфигурацию, а также несколько читателей, которые постоянно ее читают. Чтобы охватить больше потенциальных случаев, я также включу тесты для программы, в которой есть только считыватели, при условии, что конфигурация меняется не очень часто. Вот пример этого нового кейса:
Выполнение теста десять раз бок о бок дает следующие результаты:
name time/op
AtomicOneWriterMultipleReaders-4 72.2ns ± 2%
AtomicMultipleReaders-4 65.8ns ± 2%
MutexOneWriterMultipleReaders-4 717ns ± 3%
MutexMultipleReaders-4 176ns ± 2%
Бенчмарк подтверждает то, что мы видели раньше в отношении производительности. Чтобы понять, где именно находится узкое место с мьютексом, мы можем перезапустить программу с включенным трассировщиком.
Для получения дополнительной информации о пакете trace я предлагаю вам прочитать мою статью «Go: Discovery of the Trace Package.».
Вот профиль программы, использующей пакет atomic:
Горутины работают без перерывов и могут выполнять свои задачи. Что касается профиля программы с мьютексом, картина совсем другая:
Время выполнения теперь довольно фрагментировано, и это связано с мьютексом, который паркует горутину. Это подтверждается обзором горутины, где показано время, затраченное на синхронизацию в блокировке:
Время блокировки составляет примерно треть всего времени. Это можно детализировать из профиля блокирующего:
Пакет atomicопределенно дает преимущество в этом случае. Однако в некоторых случаях производительность может снизиться. Например, если вам нужно сохранить большую map, вам придется копировать ее каждый раз при обновлении map, что делает ее неэффективной.
Источник статьи: https://habr.com/ru/company/otus/blog/557312/