Service
Мы помним, что поды по своей сути эфемерны, они создаются и уничтожаются в любой момент, и конечный адрес пода может меняться по любой причине - будь то пересоздание самого пода на той же ноде, переезд на другую ноду и т.п. Так как адрес постоянно меняется, мы не сможем использовать его как конечную точку. А что, если у нас несколько одинаковых, на которые надо «разделить» трафик и проверять доступность самого пода. В этом всем нам поможет ресурс типа service.Service — это абстракция, определяющая набор подов и доступ к ним. Он является объектом REST в API K8S, а службы самого K8S настраивают прокси (iptables, ipvs) на пересылку и фильтрацию трафика только тем контейнерам, которые были выбраны в его селекторе. При создании сервиса ему также присваивается внутренний IP- адрес сети K8S.
Сеть сервисов также, как и у подов является виртуальной, однако с некоторым НО.
thing IP network
----- -- -------
pod1 10.0.1.2 10.0.0.0/14
pod2 10.0.2.2 10.0.0.0/14
service 10.3.241.152 10.3.240.0/20
Если мы посмотрим на рабочую ноду и ее список интерфейсов с помощью того же ifconfig, то мы увидим, что в сетях подов 10.0.0.0/14 существуют фактические интерфейсы для каждого хоста в этой сети. Но мы не найдем хостов в сервисной сети 10.3.240.0/20. Сервисной сети не существует, но, тогда откуда же кластер знает, куда перенаправлять пакеты и на какой под. Этим занимается компонент K8S под названием kube-proxy.
Kube-proxy — это сетевой прокси-сервер, который работает на каждом узле кластера. Он занимается реализацией виртуальных ip, установкой правил проксирования и фильтрацией трафика.
У него есть два режима:
Iptables
В этом режиме kube-proxy следит через API за control plane K8S. Если появился новый под или же пересоздался старый и сменился адрес, то kube- proxy сразу поменяет правила проксирования. Для каждой службы он устанавливает правила iptables, которые фиксируют трафик на кластерный адрес и порт сервиса и дальше перенаправляет этот трафик на один из внутренних адресов подов. Для каждого объекта конечной точки (пода) он устанавливает правила iptables.
Если kube-proxy работает в режиме iptables, а первый выбранный под не отвечает, соединение прерывается. Kube-proxy обнаружит, что соединение с первым подом не удалось, и автоматически повторит попытку с другим подом. По умолчанию kube-прокси в режиме iptables выбирает поды случайным образом.
Вы можете использовать readiness probes, чтобы убедиться, что внутренние модули работают нормально, чтобы kube-proxy в режиме iptables видел только те бэкенды, которые проверяются как исправные. Это означает, что вы избежите отправки трафика через kube-прокси на под, который, вышел из строя.
IPVS proxy mode
В режиме ipvs отслеживает службы и конечные точки Kubernetes, вызывает интерфейс netlink для создания соответствующих правил IPVS и периодически синхронизирует правила IPVS со службами и конечными точками Kubernetes. При доступе к сервису IPVS направляет трафик на один из внутренних модулей.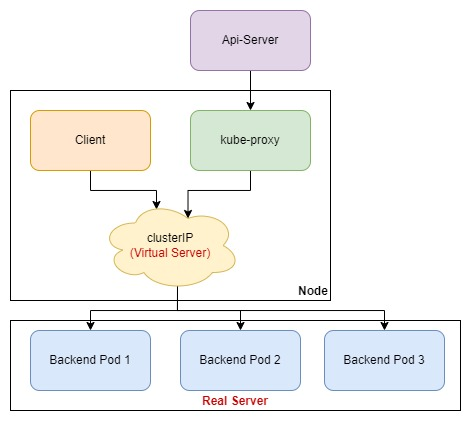
IPVS предоставляет больше возможностей для балансировки трафика на поды:
- rr: round-robin;
- lc: least connection (smallest number of open connections);
- dh: destination hashing;
- sh: source hashing;
- sed: shortest expected delay;
- nq: never queue.
Типы сервисов
Чтобы указать, где будет размещен наш сервис, будет ли он доступен снаружи или только внутри, используются типы сервиса. По умолчанию это всегда ClusterIP, то есть сервис будет доступен только внутри самого кластера.Типы:
- ClusterIP - присевает IP в сервисной сети, который доступен только внутри кластера.
- NodePort - предоставляет порт на внешнем ip самого узла (ноды), сервис будет доступен из вне по выделенному порту на каждой ноде. При этом создается и внутренний сервис ClusterIP.
- LoadBalancer - используется для внешних облачных балансировщиков, таких как Google Cloud, которые имеют своего провайдера. Сервис будет доступен через внешний балансировщик вашего провайдера, при этом создаются NodePort с портами, куда будет приходить трафик от провайдера и ClusterIP.
- Сопоставляет сервис с содержимым поля Host (например foo.bar.example.com), возвращая запись CNAME с ее значением. Проксирование в этом режиме не производится.
Указание (выбор) подов
Для того чтобы наш сервис знал, на какие поды мы хотим перенаправлять трафик с него, необходимо указать селектор spec.selector.Пример конфига:
apiVersion: v1
kind: Service
metadata:
name: service-test - имя нашего сервиса
spec:
selector:
app: test-app - селектор наших подов
ports:
- protocol: TCP - протокол порта
port: 80 - порт сервиса
targetPort: 9376 - порт пода
С помощью лейбла, заданного в манифесте deployments нашего пода, kube-proxy через API выбирает и следит за подами, которые соответствуют только заданному селектору.
Метки и селекторы
Selector и label очень частые гости в манифестах K8S и будут встречаться нам практически постоянно, поэтому давайте посмотрим, что это такое.Развертываемые поды являются многомерными, один и тот же набор подов или контейнеров могут отличаться версией, окружением, названием ПО внутри и тд. Чтобы правильно отфильтровать и отсортировать поды, применяются label.
Пример конфига deployments:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
В манифесте мы указываем label метку, которая будет присвоена подам при их создании. В metadata.labels указываем пару в виде ключ: значение. Можно использовать свои метки.
Пример:
- "release" : "stable", "release" : "canary"
- "environment" : "dev", "environment" : "qa", "environment" : "production"
- "tier" : "frontend", "tier" : "backend", "tier" : "cache"
- "partition" : "customerA", "partition" : "customerB"
- "track" : "daily", "track" : "weekly"
С помощью селектора selector мы можем идентифицировать определенный набор объектов или подов. Селектор меток — основное средство группировки в Kubernetes.
Пока есть только два типа селекторов: на равенстве и на наборе.
Условия равенства или неравенства позволяют отфильтровать объекты по ключам и значениям меток.
selector:
component: redis
Условие меток на основе набора фильтрует ключи в соответствии с набором значений. Поддерживаются три вида операторов: in, notin и exists.
Например:
matchExpressions:
- {key: tier, operator: In, values: [cache]}
- {key: environment, operator: NotIn, values: [dev]
Условие набора поддерживают только Job, Deployment, ReplicaSet и DaemonSet. Все остальные, как и сервис, только равенство.
Создание сервиса
Создание под с demo-nginx в неймспейсе test, как мы делали это в предыдущей статье.apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-hello
labels:
app: nginx-hello
spec:
replicas: 1
selector:
matchLabels:
app: nginx-hello
template:
metadata:
labels:
app: nginx-hello
spec:
containers:
- name: nginx-hello
image: nginxdemos/hello
ports:
- containerPort: 80
Сделаем для него сервис, напишем манифест svc-nginx.yml:
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx-hello
name: nginx-hello
spec:
ports:
- name: http
port: 80
targetPort: 80
selector:
app: nginx-hello
Применим его
kubectl create -f svc-nginx.yml
service/nginx-hello created
Посмотрим создался ли сервис
kubectl get service -n test
Вывод
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-hello ClusterIP 10.96.10.83 <none> 80/TCP 2m51s
Сделаем describe
kubectl describe service nginx-hello -n test
Name: nginx-hello
Namespace: test
Labels: app=nginx-hello
Annotations: <none>
Selector: app=nginx-hello
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.10.83
IPs: 10.96.10.83
Port: http 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.0.6:80
Session Affinity: None
Events: <none>
Как видим, наш сервис был создан с выбранным нами селектором. Узнаем внутренний IP нашего пода
kubectl describe pod nginx-hello -n test
...
IP: 10.244.0.6
...
Давайте теперь проверим, что сервис действительно работает Запустим под, где есть curl
kubectl run curl --image=curlimages/curl -it sh -n test
И сделаем curl на IP нашего сервиса или по имени
/ $ curl http://10.96.10.83
или curl http://nginx-hello
Вывод
<!DOCTYPE html>
<html>
<head>
<title>Hello World</title>
Как видим, наш под отдает через сервис ответ.
Удалим под, чтобы контроллер deployments его пересоздал и узнаем его новый IP:
kubectl get pods -n test
NAME READY STATUS RESTARTS AGE
nginx-hello-75576d98b6-f8r8t 1/1 Running 0 56m
% kubectl delete pod nginx-hello-75576d98b6-f8r8t -n test
pod "nginx-hello-75576d98b6-f8r8t" deleted
% kubectl get pods -n test
NAME READY STATUS RESTARTS AGE
curl 1/1 Running 1 17m
nginx-hello-75576d98b6-lmt6j 1/1 Running 0 3s
% kubectl describe pod nginx-hello -n test
Name: nginx-hello-75576d98b6-lmt6j
...
IP: 10.244.0.8
...
Проверим опять наш сервис:
Запустим под, где есть curl
kubectl run curl --image=curlimages/curl -it sh -n test
И сделаем curl на IP нашего сервиса или по имени.
/ $ curl http://10.96.10.83
или curl http://nginx-hello
<!DOCTYPE html>
<html>
<head>
<title>Hello World</title>
Сервис уже направляет к новому поду. Как только мы удалили под, kubeproxy пересоздал правила проксирования.
С NodePort все гораздо проще, изменим наш манифест.
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx-hello
name: nginx-hello
spec:
type: NodePort
ports:
- name: http
port: 80
targetPort: 80
nodePort: 30008
selector:
app: nginx-hello
Добавим type: NodePort и nodePort: 30008 и применим наш манифест. После применения можно зайти на http://ip_любой_ноды:30008 и увидеть, что отдает nginx.
Вот вы и ознакомились со второй частью серии «K8S для начинающих». А следующая часть будет посвящена ingress контроллеру, где мы расскажем о persistent volume, затронем тему создания пользователей и их прав.

K8S для начинающих. Часть вторая
В прошлой статье мы говорили о создании подов. В этой статье поговорим о том, что такое сервис, типы сервисов, метки и селекторы, а также создадим свой сервис. Service Мы помним, что поды по своей...
 habr.com
habr.com