Всем привет! Меня зовут Назаров Алексей, я работаю в отделе развития инфраструктурных систем автоматизации Мир Plat.Form (НСПК) и сегодня расскажу о том, как устроены наши кластеры Kubernetes и как мы ими управляем.
Допустим у вас имеются проекты, построенные на микросервисной архитектуре, и несколько команд разработчиков под какой-либо проект. Вы хотите быстро поднимать различные окружения (test, UAT, prod) или даже давать такую возможность пользователям. Тогда вам нужен Kubernetes. Поэтому Kubernetes нужен и нам.

Для начала надо сказать, что мы используем ванильный Kubernetes на своих серверах. Никаких облаков, только bare metal. Изначально наши кластеры были на CentOS + docker, однако сейчас наша команда заканчивает их перенос на Ubuntu + cri-o. Обновление самого Kubernetes и остальных компонентов мы проводим на постоянной основе и стараемся не отставать от актуальных версий.
У нас есть продовые, тестовые и бета-тестовые кластеры.
Продовых кластеров у нас два, они расположены в разных ЦОДах, имеют сетевую связанность, но независимы друг от друга. Кластеры дублируют все namespace и инфраструктурные настройки. Мы считаем, что надо связывать не кластеры, а сервисы. Входящий трафик поступает в кластеры с балансировщиков, поэтому сервисы могут быть активны сразу в двух кластерах. На продовых кластерах у нас располагаются боевые и UAT-окружения.
На тестовых кластерах настроены тестовые namespace для проектов, где разработчики и админы тестируют приложения и новые решения.
На бета-тестовых кластерах мы исследуем новые версии и виды Kubernetes, Container Runtime, операторов, etc. Помимо этого, на них мы тестируем наши роли ansible для настройки и установки новых кластеров. Готовые роли из «интернетов», вроде kuberspray, мы не рассматриваем. Мы за то, чтобы понимать, как устроен и работает Kubernetes.
Для управления кластерами мы используем Kubernetes Dashboard и kubectl. Второй вариант предпочтительный, поскольку предоставляем настроенные серверы управления. Мы нарекли их mkc (manager kubernetes clusters).
Данными серверами мы управляем через ansible. Через плейбук устанавливаются и настраиваются kubectl, плагины для kubectl, helm, скрипты авторизации через OIDC и другие инструменты.
Часть полезных плагинов на наш взгляд:
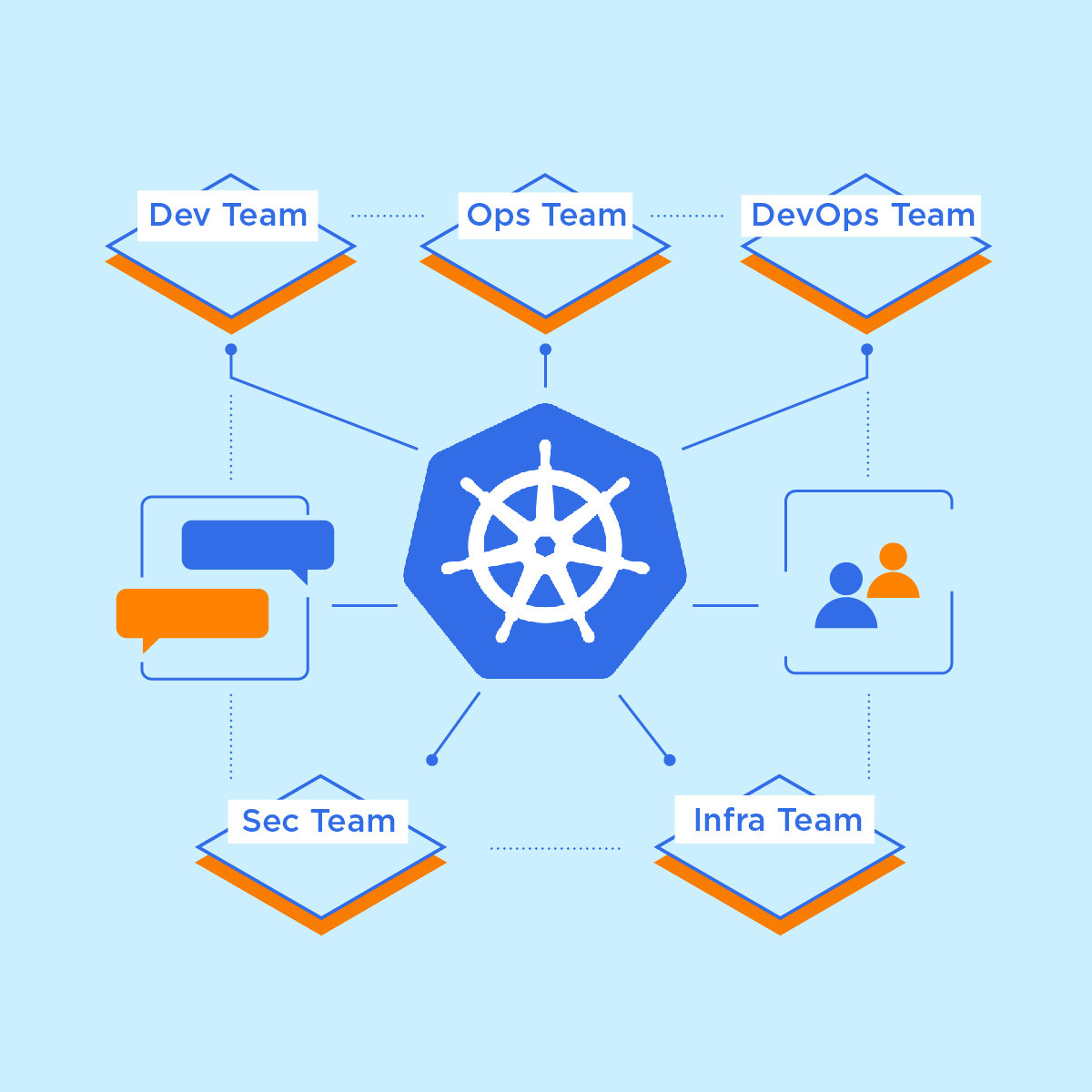
Коммуникация между командами важна, необходимо делиться опытом и знаниями. Без этого не будет дальнейшего развития. У нас есть общая группа между пользователями и админами Kubernetes, в которой мы оповещаем об изменениях и обновлениях кластеров. В группе можно попросить помощи, и тебе помогут.
Также у нас имеется пространство во внутреннем wiki, в котором пишутся инструкции для команд разработки и эксплуатации. А еще в ближайшем будущем планируется внутреннее обучение сотрудников основам Kubernetes.
Ansible Tower AWX. Этот выбор был сделан как единый инструмент доставки в рамках всей компании, но после ухода RedHat из России мы стали задумываться перейти на Argo CD в Kubernetes.
Kube-prometheus установлен в каждом кластере, по просьбе пользователей мы настраиваем ServiceMonitor для сбора метрик микросервисов. В операторе прописываем правила для remote_write для отправки метрик долгого хранения и централизованного мониторинга (используем Victoria metrics и Grafana).
Изначально мы рассматривали Open Policy Agent в качестве Policy Management решения. Но язык rego показался нам неудобным, в качестве языка описания политик. Поэтому мы сделали выбор в пользу Kyverno с нативным yaml.
Filebeat-daemonset для доставки логов в нашу ELK. Также с помощью Filebeat мы отправляем логи с определенных namespace для разработчиков в другие системы хранения логов. В ELK мы также отправляем логи аудита.
В Cert-manager мы используем Trust CA (созданный через центр сертификации) для кластеров, чтобы можно было автоматически выпускать валидные сертификаты для микросервисов.
Vault agent injector для доставки секретов из HashiCorp Vault в поды. Если по каким-либо причинам требуется доставить в объекты Secret, то используется vault-secret.
Для доступа к сервисам кластеров мы используем MetalLB и Nginx-controller. Стоит отметить, для достижения определенного уровня защищенности в продуктивных кластерах мы разносим namespace для UAT и prod в разные подсети. Поэтому мы используем два Ingress-контроллера.

Trident Operator и nfs-provisioner - управление постоянными томами разрешаем только в тестовых кластерах. В продовых кластерах постоянные тома доступны только для хранения статических файлов и отчетов.
Velero – ежедневно резервируем прикладные и системные namespace. Уже был случай, когда он нам пригодился для восстановления.
Kubernetes – конструктор, собрать его можно по-разному.

 habr.com
habr.com
Допустим у вас имеются проекты, построенные на микросервисной архитектуре, и несколько команд разработчиков под какой-либо проект. Вы хотите быстро поднимать различные окружения (test, UAT, prod) или даже давать такую возможность пользователям. Тогда вам нужен Kubernetes. Поэтому Kubernetes нужен и нам.
Для начала надо сказать, что мы используем ванильный Kubernetes на своих серверах. Никаких облаков, только bare metal. Изначально наши кластеры были на CentOS + docker, однако сейчас наша команда заканчивает их перенос на Ubuntu + cri-o. Обновление самого Kubernetes и остальных компонентов мы проводим на постоянной основе и стараемся не отставать от актуальных версий.
У нас есть продовые, тестовые и бета-тестовые кластеры.
Продовых кластеров у нас два, они расположены в разных ЦОДах, имеют сетевую связанность, но независимы друг от друга. Кластеры дублируют все namespace и инфраструктурные настройки. Мы считаем, что надо связывать не кластеры, а сервисы. Входящий трафик поступает в кластеры с балансировщиков, поэтому сервисы могут быть активны сразу в двух кластерах. На продовых кластерах у нас располагаются боевые и UAT-окружения.
На тестовых кластерах настроены тестовые namespace для проектов, где разработчики и админы тестируют приложения и новые решения.
На бета-тестовых кластерах мы исследуем новые версии и виды Kubernetes, Container Runtime, операторов, etc. Помимо этого, на них мы тестируем наши роли ansible для настройки и установки новых кластеров. Готовые роли из «интернетов», вроде kuberspray, мы не рассматриваем. Мы за то, чтобы понимать, как устроен и работает Kubernetes.
Как происходит доступ к кластерам
В Kubernetes нет объектов, представляющих обычные учетные записи пользователей. А предоставления прав через токены и сертификаты неудобны для централизованного управления во всех кластерах. Поэтому для аутентификации мы решили использовать auth-proxy (OIDC). Для этого у нас настроен кластер Keycloak, который импортирует учетные записи из LDAP.В LDAP, в свою очередь, у нас имеются группы пользователей, которым мы выдаем те или иные права в кластерах Kubernetes.Примечание: Как настроить такую схему, вы можете посмотреть в статье "Прикручиваем LDAP-авторизацию к Kubernetes".
Для управления кластерами мы используем Kubernetes Dashboard и kubectl. Второй вариант предпочтительный, поскольку предоставляем настроенные серверы управления. Мы нарекли их mkc (manager kubernetes clusters).
Данными серверами мы управляем через ansible. Через плейбук устанавливаются и настраиваются kubectl, плагины для kubectl, helm, скрипты авторизации через OIDC и другие инструменты.
Часть полезных плагинов на наш взгляд:
- kubectx - инструмент для переключения между кластерами
- kubens - инструмент для переключения между namespace
- kube-ps1 - инструмент для отображения в консоли кластера и namespace, в которых вы сейчас находитесь
- kubectl-capacity - инструмент для отображения используемых ресурсов кластера
- kubectl-images - инструмент для получения сведений об используемых образах контейнеров
- rakkess - инструмент для просмотра различных прав
Все в курсе
Коммуникация между командами важна, необходимо делиться опытом и знаниями. Без этого не будет дальнейшего развития. У нас есть общая группа между пользователями и админами Kubernetes, в которой мы оповещаем об изменениях и обновлениях кластеров. В группе можно попросить помощи, и тебе помогут.
Также у нас имеется пространство во внутреннем wiki, в котором пишутся инструкции для команд разработки и эксплуатации. А еще в ближайшем будущем планируется внутреннее обучение сотрудников основам Kubernetes.
Зачем мы написали свой оператор
Для управления кластерами обычно используют объекты ClusterRole, Role, RoleBinding, ClusterRoleBinding, ResourceQuotas, LimitRange, NetworkPolicy. При использовании оператора можно уместить все эти объекты в одном yaml-файле для каждого namespace. Так удобнее и нагляднее. Можно быстро объяснить и показать, как настроен тот или иной кластер в данный момент. Ямлики хранятся в гите и применяются после одобрения merge request. Удобно же, ну. С помощью оператора мы прозрачно настраиваем лимиты и реквесты, выдаем права, добавляем labels и аннотации, используя которые можно распределять объекты определенного namespace на нужные ноды.Сначала мы написали оператор на Ansible Operator и за основу взяли team-operator. Но сейчас мы его переписываем на Kopf (потому что любим python) и планируем расширять функционал.Примечание: В Kubernetes одна из фич — это labels. Её можно и нужно использовать не только в подах, но и нодах. Возможно, кто-то не знает, но в Kubernetes можно включить плагин PodNodeSelector. Он позволяет принудительно запускать поды на нужных нодах через labels.
Что еще используем
Argo CD мы используем для централизованной доставки некоторых операторов, кастомных ClusterRole, Role и других объектов, которые требуются всем кластерам. Для CD продовых микросервисов мы используемKube-prometheus установлен в каждом кластере, по просьбе пользователей мы настраиваем ServiceMonitor для сбора метрик микросервисов. В операторе прописываем правила для remote_write для отправки метрик долгого хранения и централизованного мониторинга (используем Victoria metrics и Grafana).
Изначально мы рассматривали Open Policy Agent в качестве Policy Management решения. Но язык rego показался нам неудобным, в качестве языка описания политик. Поэтому мы сделали выбор в пользу Kyverno с нативным yaml.
Filebeat-daemonset для доставки логов в нашу ELK. Также с помощью Filebeat мы отправляем логи с определенных namespace для разработчиков в другие системы хранения логов. В ELK мы также отправляем логи аудита.
В Cert-manager мы используем Trust CA (созданный через центр сертификации) для кластеров, чтобы можно было автоматически выпускать валидные сертификаты для микросервисов.
Vault agent injector для доставки секретов из HashiCorp Vault в поды. Если по каким-либо причинам требуется доставить в объекты Secret, то используется vault-secret.
Для доступа к сервисам кластеров мы используем MetalLB и Nginx-controller. Стоит отметить, для достижения определенного уровня защищенности в продуктивных кластерах мы разносим namespace для UAT и prod в разные подсети. Поэтому мы используем два Ingress-контроллера.
OpenTracing на данный момент тестируем в наших бета-тестовых кластерах распределенную трассировку. Также изучаем возможность внедрения Service Mesh, но от наших пользователей запросов еще не поступало, а мы пока не планируем менять подход и добавлять еще один дополнительный слой.Примечание: В кластере можно использовать несколько nginx controller. Почитать подробнее об этом можно тут - Multiple Ingress controllers
Trident Operator и nfs-provisioner - управление постоянными томами разрешаем только в тестовых кластерах. В продовых кластерах постоянные тома доступны только для хранения статических файлов и отчетов.
Velero – ежедневно резервируем прикладные и системные namespace. Уже был случай, когда он нам пригодился для восстановления.
Зачем нужны инфра админы Kubernetes
Мы настроили наши кластеры таким образом, что отдаем разработчикам, по сути, on-premises managed Kubernetes. Они могут использовать существующие ноды или прийти к нам со своими серверами, под свой проект. Мы можем добавить сервера команды в кластер и настроить их так, чтобы там работали поды только данного проекта.Kubernetes – конструктор, собрать его можно по-разному.
Kubernetes в НСПК
Всем привет! Меня зовут Назаров Алексей, я работаю в отделе развития инфраструктурных систем автоматизации Мир Plat.Form (НСПК) и сегодня расскажу о том, как устроены наши кластеры Kubernetes и как мы...
habr.com