Когда у вас 2 собственных дата-центра, тысячи железных серверов, виртуалки и хостинг для сотен тысяч сайтов, Kubernetes может существенно упростить управление всем этим добром. Как показала практика, с помощью Kubernetes можно декларативно описывать и управлять не только приложениями, но и самой инфраструктурой. Я работаю в крупнейшем чешском хостинг-провайдере WEDOS Internet a.s и сегодня расскажу о двух своих проектах — Kubernetes-in-Kubernetes и Kubefarm.
С их помощью можно буквально за пару команд, используя Helm, развернуть полностью рабочий Kubernetes внутри другого Kubernetes-кластера. Как и зачем? Добро пожаловать под кат
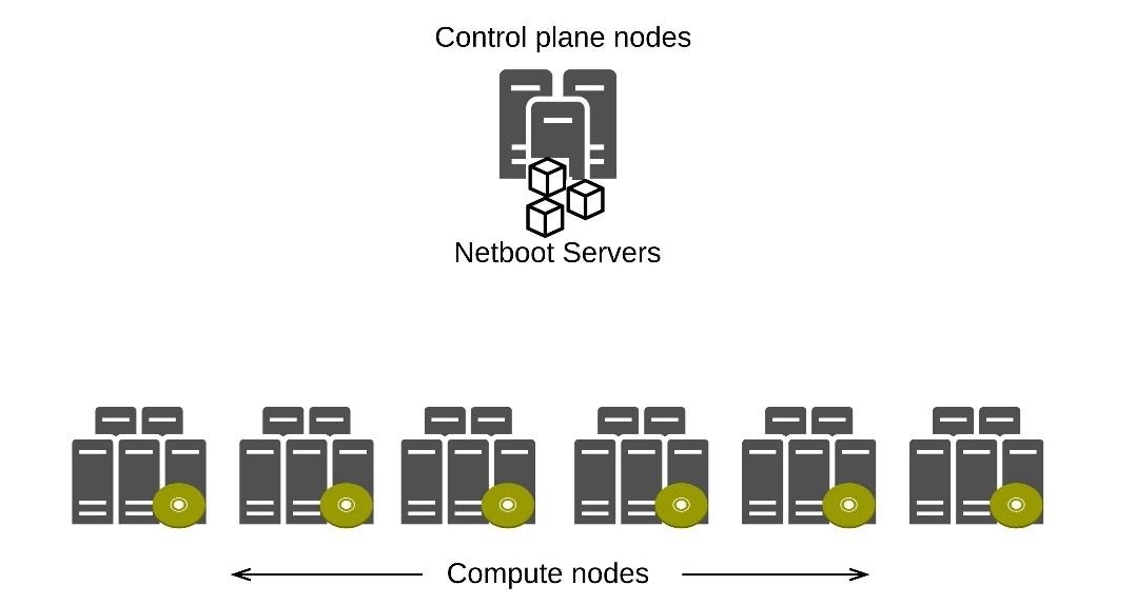
Расскажу, как устроена наша инфраструктура. Все наши сервера можно разделить на две группы: control-plane и compute nodes. Control plane ноды, как правило, установлены вручную, имеют стабильную ОС и предназначены для запуска кластерных служб, в том числе и мастеров Kubernetes. Задача этих нод — обеспечивать бесперебойную работу самого кластера. Compute ноды не имеют никакой установленной операционки, а грузятся по сети прямо с control-plane нод. Их задача — выполнять полезную нагрузку.

На control-plane нодах задеплоены также PXE- и DHCP-серверы. Когда мы включаем наши compute-ноды, то первое, что они делают — обращаются к DHCP-серверу. Он, в свою очередь отвечает каждой ноде, условно говоря: «У тебя такой-то IP, грузись с такого-то PXE-сервера». После чего ноды скачивают образ системы и сохраняют его прямо в оперативную память, после чего продолжают загрузку непосредственно с него.
Как только они загрузили этот образ, они могут продолжать работать и без связи с PXE-сервером. То есть PXE-сервер — это такая болванка, которая отдаёт образ и не содержит никакой более сложной логики. После того как наши ноды загрузились, мы можем спокойно перезагружать PXE-сервер, ничего критичного с ними уже не произойдет.
После загрузки системы первое, что делают наши ноды — это присоединяются к существующему Kubernetes-кластеру, а именно выполняют команду kubeadm join. Изначально они джойнились в тот же кластер, который использовался и для control-plane нод. После чего kube-scheduler мог шедуллить на них какие-нибудь поды и запускать различную рабочую нагрузку.

Эта схема стабильно работала у нас более двух лет. Позже мы решили добавить в неё контейнизированный Kubernetes. И теперь мы можем спавнить разные кластера на наших control-plane нодах (теперь они все находятся в специально отведенном admin-кластере). А compute-ноды джойнятся непосредственно каждая в свой кластер — в зависимости от её конфигурации.

При этом мы ушли от идеи монокластера, потому что оказалось не очень удобно, когда с кластером работает несколько команд разработчиков. Дело в том, что Kubernetes никогда не задумывался как multi-tenant решение и на данный момент он не предоставляет достаточных средств изоляции между проектами. Поэтому запуск отдельных кластеров под каждую команду оказалось хорошим решением. Тем не менее, кластеров должно быть не слишком много, чтобы их по-прежнему было удобно обслуживать. И при этом не слишком мало, чтобы иметь достаточную независимость между командами разработки.
Масштабируемость наших кластеров после этого стала заметно лучше — чем больше кластеров на количество нод у вас имеется, тем меньше домен отказа и тем стабильнее они работают. А в качестве бонуса мы получили полную декларативность. То есть теперь задеплоить новый Kubernetes-кластер можно точно так же, как и задеплоить любое другое приложение в Kubernetes.
Так у нас получился проект Kubefarm. В качестве основы он использует Kubernetes-in-Kubernetes, LTSP — тот самый PXE-сервер, с которого грузятся ноды, и автоматизирует конфигурацию DHCP-сервера с помощью dnsmasq-controller:


Давайте посмотрим на те параметры, которые мы передаем в Helm в values-файл:
kubernetes/values.yaml

Помимо persistence (настроек хранения данных кластера) тут описаны компоненты нашего control-plane: а именно: etcd-кластер, apiserver, controller-manager и scheduler. Это в общем-то стандартные компоненты Kubernetes. Все мы знаем шутку, что Kubernetes — это всего 5 бинарей. Так вот здесь описывается конфигурация для этих самых бинарей.
Если вы когда-то уже устанавливали кластер с помощью kubeadm, то этот конфиг вам его очень напомнит. Но помимо сущностей Kubernetes у нас есть еще admin-контейнер. По сути это контейнер, внутри которого находятся два бинарника: kubectl и kubeadm. Используются они для того, чтобы сгенерировать kubeconfig’и для вышеперечисленных компонентов и произвести начальную настройку кластера. Также, в случае чего, к нему всегда можно подключиться и посмотреть, что происходит внутри кластера.
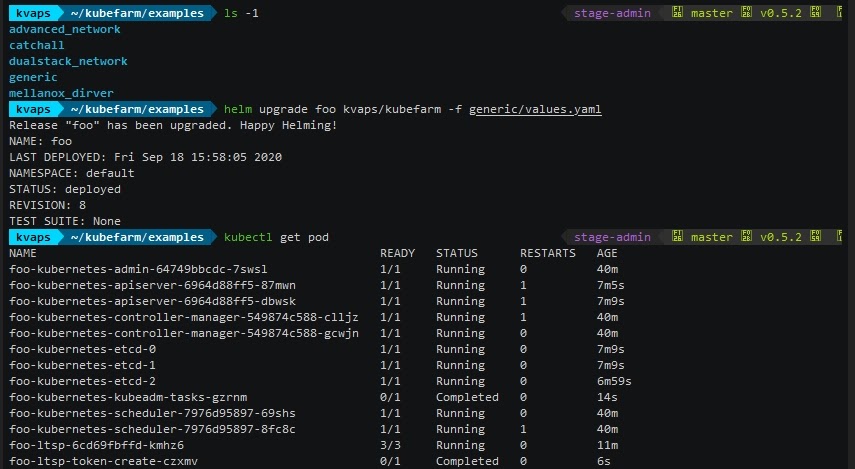
После того как релиз задеплоился, мы увидим список подов: admin-контейнер, apiserver в двух репликах, controller-manager, etcd-кластер, scheduller и та самая начальная джоба, которая инициализирует наш кластер. А в ответ мы получаем команду, выполнив которую сможем попасть в admin-контейнер и посмотреть, что там происходит:

Давайте ещё взглянем на сертификаты. Если вы когда-либо устанавливали Kubernetes, то вы знаете, что у него есть страшная папочка /etc/kubernetes/pki с кучей непонятных сертификатов. Но в нашем случае мы полностью автоматизировали управление ими. Достаточно передать в Helm, какие нам нужны сертификаты, и cert-manager автоматически сгенерирует их для нашего кластера.

Посмотрев на один из сертификатов, например для apiserver, можно увидеть что внутри него имеется список DNS-имен и IP-адресов. Если вы в дальнейшем захотите сделать этот кластер доступным извне, то просто опишите дополнительные DNS-имена в values-файле и обновите релиз — это обновит ресурс сертификата, а cert-manager его перевыпустит — и вам больше не придется думать об этом. Если в kubeadm сертификаты нужно обновлять не реже чем раз в год, то здесь cert-manager сам обновляет их автоматически по мере необходимости.

Теперь давайте залогинимся в admin-контейнер и посмотрим на наш кластер и ноды. Нод, конечно, пока нет, потому что на данный момент мы задеплоили только control-plane для Kubernetes. Но в kube-system уже появились пока никуда не зашедулленные coredns-поды и конфигмапы — то есть делаем вывод, что наш кластер работает:

Вот так выглядит схема задеплоеного кластера. Вы можете увидеть сервисы для всех компонентов Kubernetes: apiserver, controller-manager, etcd-кластер и scheduler. А справа — поды, в которые они ведут. Схема, кстати, нарисована в ArgoCD — GitOps-инструмент, который мы используем для управления кластерами, и классные схемы — одна из его фишек:

Плюс мы очень активно используем загрузку Linux по сети. Причем это именно загрузка, а не какая-то автоматизация установки: когда ноды загружаются, то грузят уже готовый имидж для них. То есть, чтобы обновить любую ноду, нам достаточно просто ее перезагрузить — и она скачает новый имидж. Это очень легко, просто и удобно.
Для этого и был создан проект Kubefarm, который позволяет автоматизировать это. Наиболее часто используемые примеры вы сможете найти в директории examples. Самый стандартный из них — generic. Посмотрим на values.yaml:
generic/values.yaml
Здесь мы указываем параметры, которые прокидываются в вышестоящий чарт Kubernetes-in-Kubernetes. Для того чтобы наш control-plane был доступен снаружи здесь достаточно указать IP-адрес, но при желании можно указать и какое-нибудь DNS-имя.
В конфигурации для PXE-сервера указываем какую-либо timezone. Можно еще добавить SSH-ключ для входа без пароля (но можно указать и пароль), а также модули и параметры ядра, которые должны использоваться при загрузке системы.
Дальше идет конфигурация nodePools, т.е. самих нод. Если вы когда-то пользовались terraform-модулем для gke, то эта логика вам его напомнит. Здесь мы статически описываем все ноды набором параметров:
Например, у нас есть nodePool с одной нодой, к которой добавлены тэги debug и foo. Смотрим KubernetesLabels, тэг foo. Это значит, что нода m1c43 загрузится с этими двумя установленными labels и с определенным taint. Вроде все просто. Теперь давайте сделаем это на практике.
Графически это выглядит примерно также, только теперь у нас apiserver стал смотреть наружу.

На схеме зеленым выделен IP, по которому стал доступен наш PXE-сервер. На данный момент Kubernetes по умолчанию не позволяет создавать единый LoadBalancer-сервис для TCP- и UDP-протоколов, поэтому приходится создавать два разных сервиса, но с одним IP-адресом. Один используется для TFTP, а второй для HTTP, по которым, собственно, и скачивается образ.
Но этого не всегда бывает достаточно, и мы можем модифицировать логику при загрузке. Для примера есть директория advanced_network, внутри которого есть values-файл с простеньким shell-скриптом. У нас он называется network.sh.
network.sh
Все, что этот скрипт делает — берет переменные окружения во время загрузки, и исходя из них, генерирует конфигурацию для сети: создает директорию и кладет туда конфиг netplan. Например, тут создается bonding-интерфейс. В принципе, в этом скрипте может быть абсолютно все что угодно — от конфигурации сети до генерации системных сервисов и описания любой логики. Все, что можно описать в bash или в shell, можно положить сюда, и оно будет исполнено в момент загрузки.
Посмотрим, как это можно задеплоить. Первым параметром мы передаём generic values-файл, а вторым параметром дополнительный values-файл. Для Helm — это стандартная возможность. Так можно, например, передавать секреты, но в нашем случае происходит расширение конфигурации:

Смотрим configmap foo-kubernetes-ltsp для нашего netboot-сервера и видим, что здесь находится наш скрипт network.sh и те самые команды использующиеся для конфигурации сети во время загрузки:

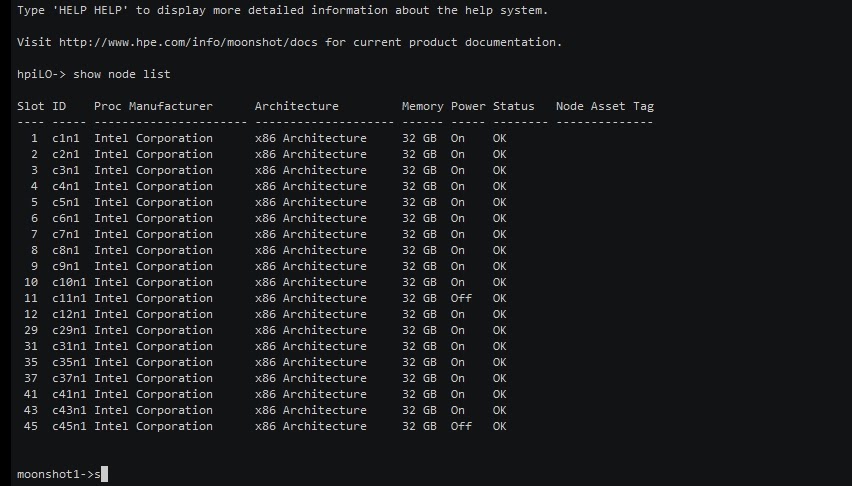
Здесь вы можете увидеть, как это работает в принципе. В интерфейсе шасси, где у нас находятся ноды (мы используем HPE Moonshots 1500), можно ввести команду show node list и увидеть список всех нод. Сейчас мы и будем их загружать.
Здесь также можно посмотреть их MAC-адреса — show node macaddr all. У нас есть хитрый оператор, который делает это автоматически. Эти адреса мы используем для конфигурации DHCP, копируя их в виде ресурсов для dnsmasq-controller в Kubernetes. И отсюда же мы можем управлять самими нодами, включать и выключать их.
Если у вас нет такой же возможности, как у нас, чтобы зайти на шасси через iLO и собрать список MAC-адресов для всех нод, вы можете использовать паттерн с catchall-кластером — в нашем случае это просто кластер с динамическим DHCP-пулом. Таким образом все ноды, не описанные в конфигурации к другим кластерам, будут автоматически подключаться в этот кластер.

Например, здесь у нас уже есть какие-то ноды. Они добавляются в кластер с автоматически сгенерированным именем на основе MAC-адреса. Мы можем подключиться к ним и посмотреть, что там происходит. Здесь их можно как-то подготавливать, например нарезать файловую систему и после этого переподключать к другому кластеру.
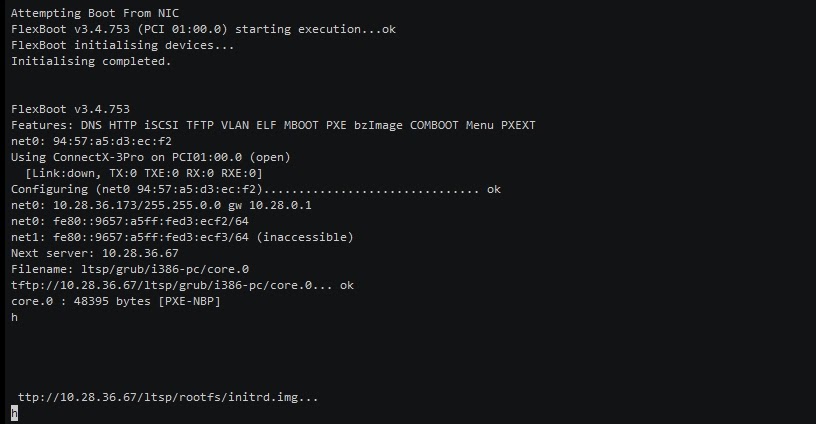
После подключения к ноде посмотрим, как происходит загрузка. После загрузки BIOS происходит конфигурация сетевой карты, здесь она с такого-то MAC-адреса отправляет запрос к DHCP-серверу, а тот ее отправляет на определенный PXE-сервер. По стандартному HTTP-протоколу ей отдаются ядро и initrd-образ:
После загрузки ядра нода скачивает initramfs-образ и передает управление systemd. Дальше загрузка идет как обычно, а сама нода присоединяется к Kubernetes:

Если посмотреть на fstab, то можно увидеть всего две записи: /var/lib/docker и /var/lib/kubelet, они смонтированы как tmpfs (по сути — из оперативной памяти). При этом корень у нас смонтирован как overlayfs, поэтому все изменения, которые вы сделаете здесь в системе, при следующей перезагрузке будут потеряны.
Из блочных устройств на ноде есть один nvme-диск, но он пока что никуда не смонтирован. Есть также loop device — это тот самый initramfs-образ загруженный с сервера. На данный момент он лежит в оперативной памяти, занимает 653 Мб и смонтирован с опцией loop.
Если посмотрим в /etc/ltsp, мы найдем наш файл network.sh, который был выполнен при загрузке. Из контейнеров у нас запустились kube-proxy, а также pause-контейнер для него.

Dockerfile
Что здесь происходит? Во-первых, мы берем обычную Ubuntu 20.04 и устанавливаем туда все необходимые нам пакеты. В первую очередь — ядро, lvm, systemd, SSH — в общем, всё то, что вы хотите увидеть на окончательной ноде. Для этого есть отдельный stage. Здесь мы также устанавливаем Docker с Kubernetes kubelet и kubeadm, которые используются для джойна ноды к кластеру.
А дальше производим дополнительную настройку. В последнем stage мы просто устанавливаем туда tftp с nginx (которые отдают наш образ клиентам), grub (наш загрузчик), и в этот же образ копируем корень предыдущих stages. То есть по сути у нас получается образ, внутри которого находится как сервер, так и загрузочный образ для наших нод. В тоже время, изменяя Dockerfile, его можно легко обновить.
Но дело в том, что для работы вебхуков apiserver должен иметь доступ непосредственно к кластеру, в которым он работает. А если он запущен в отдельном кластере, как у нас, или вообще отдельно от кластера, то здесь нам может помочь Konnectivity. Konnectivity — это один из необязательных, но официально поддерживаемых компонентов Kubernetes.
Возьмем для примера 4 ноды, на каждой из которых запущен kubelet и другие компоненты Kubernetes: apiserver, scheduller и controller-manager. По умолчанию все эти компоненты ходят и взаимодействуют с apiserver’ом напрямую — это наиболее понятная часть логики работы Kubernetes. Но на самом деле есть ещё и обратный режим. Например, иногда, когда вы хотите посмотреть логи какого-то пода или выполнить kubectl exec, то apiserver самостоятельно устанавливает соединение с каким-либо из kubelet’ов:

Но проблема в том, что если у нас есть вебхук, то он, как правило, запущен в виде стандартного пода с сервисом в нашем кластере. И когда apiserver попробует к нему достучаться, то у него ничего не получится — потому что он будет пытаться обратиться к in-cluster сервису по имени webhook.namespace.svc:
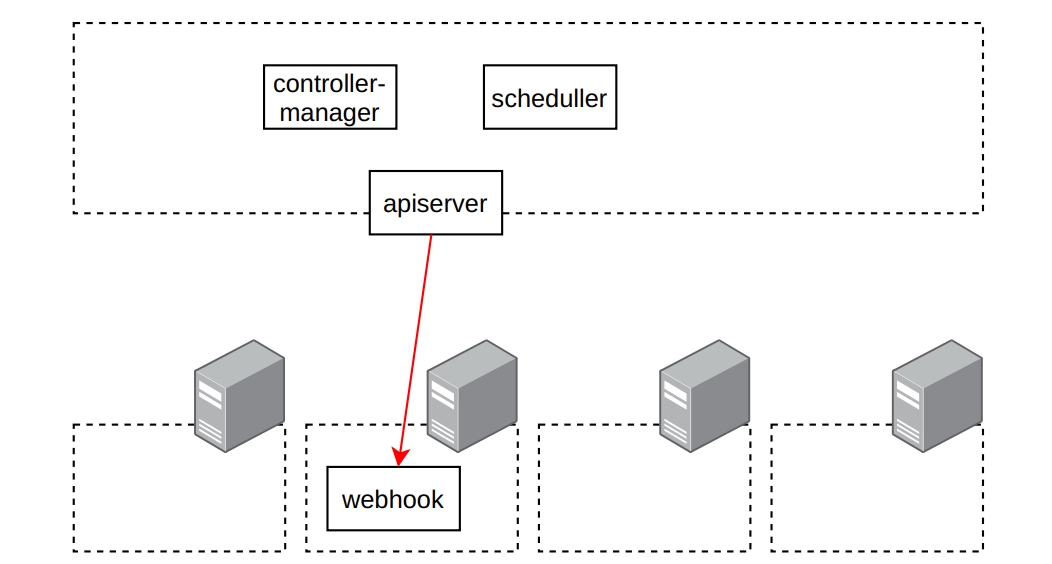
И здесь нам на помощь приходит Konnectivity — хитрый прокси-сервер созданный специально для Kubernetes. Он деплоится в виде сервера рядом с apiserver. А Konnectivity-agent деплоится уже непосредственно в кластере, в который вы хотите ходить, также в нескольких репликах. Агент устанавливает подключение к серверу и позволяет apiserver наладить стабильный канал, чтобы тот смог ходить через него и имел возможность обращаться со всеми вебхуками и всеми kubelet’ам в кластере. Таким образом теперь всё общение с кластером будет происходить через Konnectivity-server:

Также я подумываю сделать интеграцию с Machine Controller Manager, что позволило бы создавать worker’ы, не только на физических серверах, а например создавать виртуалки используя kubevirt и запускать их в том же Kubernetes-кластере. Им кстати, можно также создавать виртуалки в облаках, имея control-plane, задеплоенный у себя локально.
Также я рассматриваю вариант интеграции с Cluster-API, чтобы можно было создавать физические кластера Kubefarm прямо через окружение Kubernetes. Но на данный момент я не до конца уверен в этой идее. Если у вас есть мысли на этот счет, с радостью их выслушаю.
Источник статьи: https://habr.com/ru/company/oleg-bunin/blog/558900/
С их помощью можно буквально за пару команд, используя Helm, развернуть полностью рабочий Kubernetes внутри другого Kubernetes-кластера. Как и зачем? Добро пожаловать под кат
Расскажу, как устроена наша инфраструктура. Все наши сервера можно разделить на две группы: control-plane и compute nodes. Control plane ноды, как правило, установлены вручную, имеют стабильную ОС и предназначены для запуска кластерных служб, в том числе и мастеров Kubernetes. Задача этих нод — обеспечивать бесперебойную работу самого кластера. Compute ноды не имеют никакой установленной операционки, а грузятся по сети прямо с control-plane нод. Их задача — выполнять полезную нагрузку.
На control-plane нодах задеплоены также PXE- и DHCP-серверы. Когда мы включаем наши compute-ноды, то первое, что они делают — обращаются к DHCP-серверу. Он, в свою очередь отвечает каждой ноде, условно говоря: «У тебя такой-то IP, грузись с такого-то PXE-сервера». После чего ноды скачивают образ системы и сохраняют его прямо в оперативную память, после чего продолжают загрузку непосредственно с него.
Как только они загрузили этот образ, они могут продолжать работать и без связи с PXE-сервером. То есть PXE-сервер — это такая болванка, которая отдаёт образ и не содержит никакой более сложной логики. После того как наши ноды загрузились, мы можем спокойно перезагружать PXE-сервер, ничего критичного с ними уже не произойдет.
После загрузки системы первое, что делают наши ноды — это присоединяются к существующему Kubernetes-кластеру, а именно выполняют команду kubeadm join. Изначально они джойнились в тот же кластер, который использовался и для control-plane нод. После чего kube-scheduler мог шедуллить на них какие-нибудь поды и запускать различную рабочую нагрузку.
Эта схема стабильно работала у нас более двух лет. Позже мы решили добавить в неё контейнизированный Kubernetes. И теперь мы можем спавнить разные кластера на наших control-plane нодах (теперь они все находятся в специально отведенном admin-кластере). А compute-ноды джойнятся непосредственно каждая в свой кластер — в зависимости от её конфигурации.
Kubefarm
Этот проект появился с целью, чтобы любой смог развернуть такую инфраструктуру за пару команд с помощью Helm и получить примерно то же самое.При этом мы ушли от идеи монокластера, потому что оказалось не очень удобно, когда с кластером работает несколько команд разработчиков. Дело в том, что Kubernetes никогда не задумывался как multi-tenant решение и на данный момент он не предоставляет достаточных средств изоляции между проектами. Поэтому запуск отдельных кластеров под каждую команду оказалось хорошим решением. Тем не менее, кластеров должно быть не слишком много, чтобы их по-прежнему было удобно обслуживать. И при этом не слишком мало, чтобы иметь достаточную независимость между командами разработки.
Масштабируемость наших кластеров после этого стала заметно лучше — чем больше кластеров на количество нод у вас имеется, тем меньше домен отказа и тем стабильнее они работают. А в качестве бонуса мы получили полную декларативность. То есть теперь задеплоить новый Kubernetes-кластер можно точно так же, как и задеплоить любое другое приложение в Kubernetes.
Так у нас получился проект Kubefarm. В качестве основы он использует Kubernetes-in-Kubernetes, LTSP — тот самый PXE-сервер, с которого грузятся ноды, и автоматизирует конфигурацию DHCP-сервера с помощью dnsmasq-controller:
Как это работает
Теперь посмотрим на то, как это работает. Вообще, если посмотреть на Kubernetes как на приложение — можно отметить что он соблюдает все принципы The Twelve-Factor App, и на самом деле написан довольно грамотно. Что означает — запустить его как приложение в другом Kubernetes не составляет особой проблемы.Запуск Kubernetes в Kubernetes
Давайте посмотрим на те параметры, которые мы передаем в Helm в values-файл:
kubernetes/values.yaml
Помимо persistence (настроек хранения данных кластера) тут описаны компоненты нашего control-plane: а именно: etcd-кластер, apiserver, controller-manager и scheduler. Это в общем-то стандартные компоненты Kubernetes. Все мы знаем шутку, что Kubernetes — это всего 5 бинарей. Так вот здесь описывается конфигурация для этих самых бинарей.
Если вы когда-то уже устанавливали кластер с помощью kubeadm, то этот конфиг вам его очень напомнит. Но помимо сущностей Kubernetes у нас есть еще admin-контейнер. По сути это контейнер, внутри которого находятся два бинарника: kubectl и kubeadm. Используются они для того, чтобы сгенерировать kubeconfig’и для вышеперечисленных компонентов и произвести начальную настройку кластера. Также, в случае чего, к нему всегда можно подключиться и посмотреть, что происходит внутри кластера.
После того как релиз задеплоился, мы увидим список подов: admin-контейнер, apiserver в двух репликах, controller-manager, etcd-кластер, scheduller и та самая начальная джоба, которая инициализирует наш кластер. А в ответ мы получаем команду, выполнив которую сможем попасть в admin-контейнер и посмотреть, что там происходит:
Давайте ещё взглянем на сертификаты. Если вы когда-либо устанавливали Kubernetes, то вы знаете, что у него есть страшная папочка /etc/kubernetes/pki с кучей непонятных сертификатов. Но в нашем случае мы полностью автоматизировали управление ими. Достаточно передать в Helm, какие нам нужны сертификаты, и cert-manager автоматически сгенерирует их для нашего кластера.
Посмотрев на один из сертификатов, например для apiserver, можно увидеть что внутри него имеется список DNS-имен и IP-адресов. Если вы в дальнейшем захотите сделать этот кластер доступным извне, то просто опишите дополнительные DNS-имена в values-файле и обновите релиз — это обновит ресурс сертификата, а cert-manager его перевыпустит — и вам больше не придется думать об этом. Если в kubeadm сертификаты нужно обновлять не реже чем раз в год, то здесь cert-manager сам обновляет их автоматически по мере необходимости.
Теперь давайте залогинимся в admin-контейнер и посмотрим на наш кластер и ноды. Нод, конечно, пока нет, потому что на данный момент мы задеплоили только control-plane для Kubernetes. Но в kube-system уже появились пока никуда не зашедулленные coredns-поды и конфигмапы — то есть делаем вывод, что наш кластер работает:
Вот так выглядит схема задеплоеного кластера. Вы можете увидеть сервисы для всех компонентов Kubernetes: apiserver, controller-manager, etcd-кластер и scheduler. А справа — поды, в которые они ведут. Схема, кстати, нарисована в ArgoCD — GitOps-инструмент, который мы используем для управления кластерами, и классные схемы — одна из его фишек:
Оркестрация физических серверов
ОК, теперь у нас есть control-plane Kubernetes, но что насчёт worker-нод, как мы будем их добавлять? Как я уже говорил все сервера у нас bare metal — мы не используем виртуализацию для запуска Kubernetes, а оркестрируем все физические сервера самостоятельно.Плюс мы очень активно используем загрузку Linux по сети. Причем это именно загрузка, а не какая-то автоматизация установки: когда ноды загружаются, то грузят уже готовый имидж для них. То есть, чтобы обновить любую ноду, нам достаточно просто ее перезагрузить — и она скачает новый имидж. Это очень легко, просто и удобно.
Для этого и был создан проект Kubefarm, который позволяет автоматизировать это. Наиболее часто используемые примеры вы сможете найти в директории examples. Самый стандартный из них — generic. Посмотрим на values.yaml:
generic/values.yaml
Здесь мы указываем параметры, которые прокидываются в вышестоящий чарт Kubernetes-in-Kubernetes. Для того чтобы наш control-plane был доступен снаружи здесь достаточно указать IP-адрес, но при желании можно указать и какое-нибудь DNS-имя.
В конфигурации для PXE-сервера указываем какую-либо timezone. Можно еще добавить SSH-ключ для входа без пароля (но можно указать и пароль), а также модули и параметры ядра, которые должны использоваться при загрузке системы.
Дальше идет конфигурация nodePools, т.е. самих нод. Если вы когда-то пользовались terraform-модулем для gke, то эта логика вам его напомнит. Здесь мы статически описываем все ноды набором параметров:
- Имя (host name);
- MAC-адрес — у нас ноды с двумя сетевыми карточками, и каждая может загрузиться с любого из указанных здесь MAC-адресов;
- IP-адрес, который DHCP-сервер должен выдать этой ноде.
Например, у нас есть nodePool с одной нодой, к которой добавлены тэги debug и foo. Смотрим KubernetesLabels, тэг foo. Это значит, что нода m1c43 загрузится с этими двумя установленными labels и с определенным taint. Вроде все просто. Теперь давайте сделаем это на практике.
Демо
Переходим в examples и выполняем обновление нашего предыдущего задеплоенного чарта до Kubefarm. Устанавливаем из параметров generic и смотрим на поды. Видим, что у нас добавился PXE-сервер и одна джоба, которая по сути идет в Kubernetes и создаёт новый токен. Теперь она будет запускаться каждые 12 часов и генерировать новый токен для того, чтобы ноды могли подключиться в наш кластер.
Графически это выглядит примерно также, только теперь у нас apiserver стал смотреть наружу.
На схеме зеленым выделен IP, по которому стал доступен наш PXE-сервер. На данный момент Kubernetes по умолчанию не позволяет создавать единый LoadBalancer-сервис для TCP- и UDP-протоколов, поэтому приходится создавать два разных сервиса, но с одним IP-адресом. Один используется для TFTP, а второй для HTTP, по которым, собственно, и скачивается образ.
Но этого не всегда бывает достаточно, и мы можем модифицировать логику при загрузке. Для примера есть директория advanced_network, внутри которого есть values-файл с простеньким shell-скриптом. У нас он называется network.sh.
network.sh
Все, что этот скрипт делает — берет переменные окружения во время загрузки, и исходя из них, генерирует конфигурацию для сети: создает директорию и кладет туда конфиг netplan. Например, тут создается bonding-интерфейс. В принципе, в этом скрипте может быть абсолютно все что угодно — от конфигурации сети до генерации системных сервисов и описания любой логики. Все, что можно описать в bash или в shell, можно положить сюда, и оно будет исполнено в момент загрузки.
Посмотрим, как это можно задеплоить. Первым параметром мы передаём generic values-файл, а вторым параметром дополнительный values-файл. Для Helm — это стандартная возможность. Так можно, например, передавать секреты, но в нашем случае происходит расширение конфигурации:
Смотрим configmap foo-kubernetes-ltsp для нашего netboot-сервера и видим, что здесь находится наш скрипт network.sh и те самые команды использующиеся для конфигурации сети во время загрузки:
Здесь вы можете увидеть, как это работает в принципе. В интерфейсе шасси, где у нас находятся ноды (мы используем HPE Moonshots 1500), можно ввести команду show node list и увидеть список всех нод. Сейчас мы и будем их загружать.
Здесь также можно посмотреть их MAC-адреса — show node macaddr all. У нас есть хитрый оператор, который делает это автоматически. Эти адреса мы используем для конфигурации DHCP, копируя их в виде ресурсов для dnsmasq-controller в Kubernetes. И отсюда же мы можем управлять самими нодами, включать и выключать их.
Если у вас нет такой же возможности, как у нас, чтобы зайти на шасси через iLO и собрать список MAC-адресов для всех нод, вы можете использовать паттерн с catchall-кластером — в нашем случае это просто кластер с динамическим DHCP-пулом. Таким образом все ноды, не описанные в конфигурации к другим кластерам, будут автоматически подключаться в этот кластер.
Например, здесь у нас уже есть какие-то ноды. Они добавляются в кластер с автоматически сгенерированным именем на основе MAC-адреса. Мы можем подключиться к ним и посмотреть, что там происходит. Здесь их можно как-то подготавливать, например нарезать файловую систему и после этого переподключать к другому кластеру.
После подключения к ноде посмотрим, как происходит загрузка. После загрузки BIOS происходит конфигурация сетевой карты, здесь она с такого-то MAC-адреса отправляет запрос к DHCP-серверу, а тот ее отправляет на определенный PXE-сервер. По стандартному HTTP-протоколу ей отдаются ядро и initrd-образ:
После загрузки ядра нода скачивает initramfs-образ и передает управление systemd. Дальше загрузка идет как обычно, а сама нода присоединяется к Kubernetes:
Если посмотреть на fstab, то можно увидеть всего две записи: /var/lib/docker и /var/lib/kubelet, они смонтированы как tmpfs (по сути — из оперативной памяти). При этом корень у нас смонтирован как overlayfs, поэтому все изменения, которые вы сделаете здесь в системе, при следующей перезагрузке будут потеряны.
Из блочных устройств на ноде есть один nvme-диск, но он пока что никуда не смонтирован. Есть также loop device — это тот самый initramfs-образ загруженный с сервера. На данный момент он лежит в оперативной памяти, занимает 653 Мб и смонтирован с опцией loop.
Если посмотрим в /etc/ltsp, мы найдем наш файл network.sh, который был выполнен при загрузке. Из контейнеров у нас запустились kube-proxy, а также pause-контейнер для него.
Детали
Образ для загрузки по сети
Но откуда же берется основной образ? Здесь есть небольшая хитрость — образ для нод собирается через Dockerfile вместе с сервером. Возможность Docker multi-stage build позволяет легко добавлять любые пакеты и модули ядра именно на стадии сборки образа. Выглядит это так:Dockerfile
Что здесь происходит? Во-первых, мы берем обычную Ubuntu 20.04 и устанавливаем туда все необходимые нам пакеты. В первую очередь — ядро, lvm, systemd, SSH — в общем, всё то, что вы хотите увидеть на окончательной ноде. Для этого есть отдельный stage. Здесь мы также устанавливаем Docker с Kubernetes kubelet и kubeadm, которые используются для джойна ноды к кластеру.
А дальше производим дополнительную настройку. В последнем stage мы просто устанавливаем туда tftp с nginx (которые отдают наш образ клиентам), grub (наш загрузчик), и в этот же образ копируем корень предыдущих stages. То есть по сути у нас получается образ, внутри которого находится как сервер, так и загрузочный образ для наших нод. В тоже время, изменяя Dockerfile, его можно легко обновить.
Вебхуки и API aggregation layerapiserver
Отдельное внимание хочу уделить проблеме вебхуков и aggregation layer. Вообще вебхуки — это возможность Kubernetes, которая позволяет реагировать на создание или изменение каких-либо ресурсов. То есть можно повесить обработчик, чтобы при применении ресурсов Kubernetes ходил к какому-нибудь поду и проверял, верна ли его конфигурация, или вносил бы в него дополнительные изменения.Но дело в том, что для работы вебхуков apiserver должен иметь доступ непосредственно к кластеру, в которым он работает. А если он запущен в отдельном кластере, как у нас, или вообще отдельно от кластера, то здесь нам может помочь Konnectivity. Konnectivity — это один из необязательных, но официально поддерживаемых компонентов Kubernetes.
Возьмем для примера 4 ноды, на каждой из которых запущен kubelet и другие компоненты Kubernetes: apiserver, scheduller и controller-manager. По умолчанию все эти компоненты ходят и взаимодействуют с apiserver’ом напрямую — это наиболее понятная часть логики работы Kubernetes. Но на самом деле есть ещё и обратный режим. Например, иногда, когда вы хотите посмотреть логи какого-то пода или выполнить kubectl exec, то apiserver самостоятельно устанавливает соединение с каким-либо из kubelet’ов:
Но проблема в том, что если у нас есть вебхук, то он, как правило, запущен в виде стандартного пода с сервисом в нашем кластере. И когда apiserver попробует к нему достучаться, то у него ничего не получится — потому что он будет пытаться обратиться к in-cluster сервису по имени webhook.namespace.svc:
И здесь нам на помощь приходит Konnectivity — хитрый прокси-сервер созданный специально для Kubernetes. Он деплоится в виде сервера рядом с apiserver. А Konnectivity-agent деплоится уже непосредственно в кластере, в который вы хотите ходить, также в нескольких репликах. Агент устанавливает подключение к серверу и позволяет apiserver наладить стабильный канал, чтобы тот смог ходить через него и имел возможность обращаться со всеми вебхуками и всеми kubelet’ам в кластере. Таким образом теперь всё общение с кластером будет происходить через Konnectivity-server:
Наши планы
Конечно, на этом этапе мы останавливаться не собираемся. Мне достаточно часто пишут заинтересованные в проекте люди. И если наберется критическая масса, я надеюсь переместить Kubernetes-in-Kubernetes под крыло Kubernetes-SIGs, представив его в виде официального Kubernetes Helm-чарта. И, возможно, так мы соберем ещё большее комьюнити.Также я подумываю сделать интеграцию с Machine Controller Manager, что позволило бы создавать worker’ы, не только на физических серверах, а например создавать виртуалки используя kubevirt и запускать их в том же Kubernetes-кластере. Им кстати, можно также создавать виртуалки в облаках, имея control-plane, задеплоенный у себя локально.
Также я рассматриваю вариант интеграции с Cluster-API, чтобы можно было создавать физические кластера Kubefarm прямо через окружение Kubernetes. Но на данный момент я не до конца уверен в этой идее. Если у вас есть мысли на этот счет, с радостью их выслушаю.
Источник статьи: https://habr.com/ru/company/oleg-bunin/blog/558900/