Компания NVIDIA опубликовала исходные тексты StyleGAN3, системы машинного обучения на основе генеративно-состязательной нейронной сети (GAN), нацеленной на синтезирование реалистичных изображений лиц людей. Код написан на языке Python c использованием фреймворка PyTorch и распространяется под лицензией NVIDIA Source Code License, накладывающей ограничение на использование в коммерческих целях.
Для загрузки также доступны готовые натренированные модели, обученные на коллекции Flickr-Faces-HQ (FFHQ), включающей 70 тысяч высококачественных (1024x1024) PNG-изображений лиц людей. Кроме того имеются модели, построенные на основе коллекций AFHQv2 (фотографии морд животных) и Metfaces (изображения лиц людей с портретов классической живописи). При разработке акцент делается на лица, но система может быть обучена для генерации любых объектов, например, пейзажей и автомобилей. Дополнительно предоставляются инструменты для самостоятельного обучения нейронной сети по собственным коллекциям изображений. Для работы требуется одна или несколько видеокарт NVIDIA (рекомендуется GPU Tesla V100 или A100), как минимум 12 ГБ ОЗУ, PyTorch 1.9 и инструментарий CUDA 11.1+. Для определения искусственного характера полученных лиц развивается специальный детектор.
Система позволяет синтезировать изображение нового лица на основе интерполяции особенностей нескольких лиц, комбинируя свойственные им черты, а также адаптируя итоговое изображение под необходимый возраст, пол, длину волос, характер улыбки, форму носа, цвет кожи, очки, ракурс фотографии. Генератор рассматривает изображение как коллекцию стилей, автоматически отделяет характерные детали (веснушки, волосы, очки) от общих высокоуровневых атрибутов (поза, пол, возрастные изменения) и позволяет комбинировать их в произвольном виде с определением доминирующих свойств через весовые коэффициенты. В результате генерируются изображения, внешне неотличимые от настоящих фотографий.

Первый вариант технологии StyleGAN был опубликован в 2019 году, после чего в 2020 году была предложена улучшенная редакция StyleGAN2, позволяющая добиться улучшения качества изображений и устраняющая некоторые артефакты. При этом система оставалась статичной, т.е. не позволяла добиться реалистичной анимации и движения лица. При разработке StyleGAN3 главной целью стала адаптация технологии для её применения в анимации и видео.
В StyleGAN3 использована переработанная архитектура генерации изображений, избавленная от алиасинга, и предложены новые сценарии обучения нейронной сети. В состав включены новые утилиты для интерактивной визуализации (visualizer.py), анализа (avg_spectra.py) и генерации видео (gen_video.py). В реализации также сокращено потребление памяти и ускорен процесс обучения.
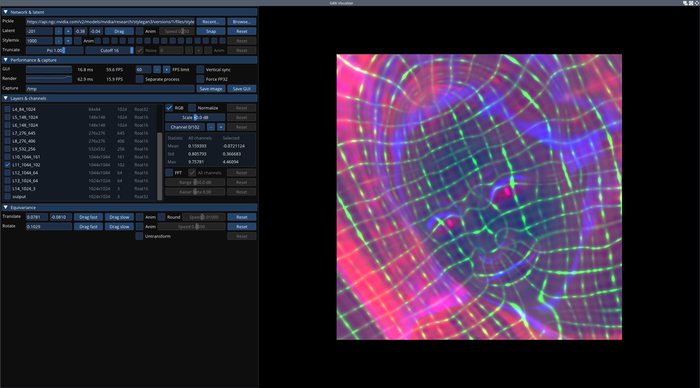
Ключевой особенностью архитектуры StyleGAN3 стал переход к интерпретации всех сигналов в нейронной сети в форме непрерывных процессов, что позволило при формировании деталей манипулировать относительными позициями, не привязанными к абсолютным координатам отдельных пикселей на изображении, а закреплёнными к поверхности изображённых объектов. В StyleGAN и StyleGAN2 привязка к пикселям при генерации приводила к проблемам при динамической визуализации, например, при движении изображения наблюдалось рассогласование мелких деталей, таких как морщины и волоски, которые двигались как бы отдельно от остального лица. В StyleGAN3 эти проблемы решены и технология стала вполне пригодна для формирования видео.
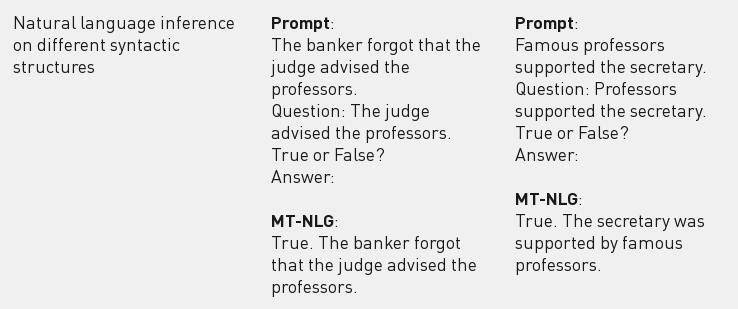
Дополнительно можно отметить анонс создания компаниями NVIDIA и Microsoft крупнейшей языковой модели MT-NLG на основе глубокой нейронной сети с архитектурой "трансформер". Модель охватывает 530 миллиардов параметров, а для обучения был задействован кластер, насчитывающий 4480 GPU (560 серверов DGX A100 с 8 GPU A100 80GB в каждом). В качестве областей применения модели называется решение задач по обработке информации на естественном языке, таких как прогнозирование завершения незаконченного предложения, ответы на вопросы, понимание прочитанного, формирование выводов на естественном языке и разбор неоднозначности смысла слов.
Для загрузки также доступны готовые натренированные модели, обученные на коллекции Flickr-Faces-HQ (FFHQ), включающей 70 тысяч высококачественных (1024x1024) PNG-изображений лиц людей. Кроме того имеются модели, построенные на основе коллекций AFHQv2 (фотографии морд животных) и Metfaces (изображения лиц людей с портретов классической живописи). При разработке акцент делается на лица, но система может быть обучена для генерации любых объектов, например, пейзажей и автомобилей. Дополнительно предоставляются инструменты для самостоятельного обучения нейронной сети по собственным коллекциям изображений. Для работы требуется одна или несколько видеокарт NVIDIA (рекомендуется GPU Tesla V100 или A100), как минимум 12 ГБ ОЗУ, PyTorch 1.9 и инструментарий CUDA 11.1+. Для определения искусственного характера полученных лиц развивается специальный детектор.
Система позволяет синтезировать изображение нового лица на основе интерполяции особенностей нескольких лиц, комбинируя свойственные им черты, а также адаптируя итоговое изображение под необходимый возраст, пол, длину волос, характер улыбки, форму носа, цвет кожи, очки, ракурс фотографии. Генератор рассматривает изображение как коллекцию стилей, автоматически отделяет характерные детали (веснушки, волосы, очки) от общих высокоуровневых атрибутов (поза, пол, возрастные изменения) и позволяет комбинировать их в произвольном виде с определением доминирующих свойств через весовые коэффициенты. В результате генерируются изображения, внешне неотличимые от настоящих фотографий.

Первый вариант технологии StyleGAN был опубликован в 2019 году, после чего в 2020 году была предложена улучшенная редакция StyleGAN2, позволяющая добиться улучшения качества изображений и устраняющая некоторые артефакты. При этом система оставалась статичной, т.е. не позволяла добиться реалистичной анимации и движения лица. При разработке StyleGAN3 главной целью стала адаптация технологии для её применения в анимации и видео.
В StyleGAN3 использована переработанная архитектура генерации изображений, избавленная от алиасинга, и предложены новые сценарии обучения нейронной сети. В состав включены новые утилиты для интерактивной визуализации (visualizer.py), анализа (avg_spectra.py) и генерации видео (gen_video.py). В реализации также сокращено потребление памяти и ускорен процесс обучения.
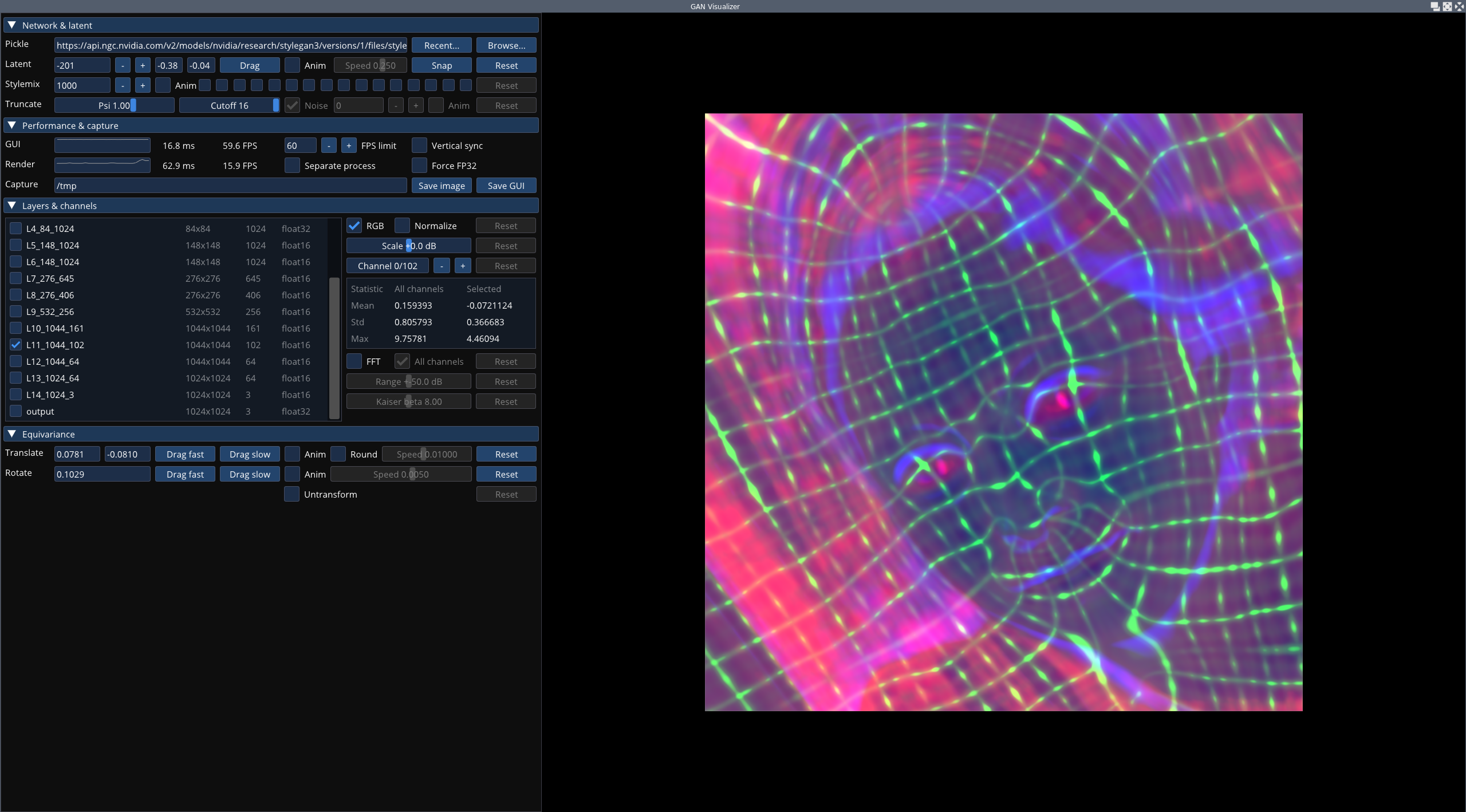
Ключевой особенностью архитектуры StyleGAN3 стал переход к интерпретации всех сигналов в нейронной сети в форме непрерывных процессов, что позволило при формировании деталей манипулировать относительными позициями, не привязанными к абсолютным координатам отдельных пикселей на изображении, а закреплёнными к поверхности изображённых объектов. В StyleGAN и StyleGAN2 привязка к пикселям при генерации приводила к проблемам при динамической визуализации, например, при движении изображения наблюдалось рассогласование мелких деталей, таких как морщины и волоски, которые двигались как бы отдельно от остального лица. В StyleGAN3 эти проблемы решены и технология стала вполне пригодна для формирования видео.
Дополнительно можно отметить анонс создания компаниями NVIDIA и Microsoft крупнейшей языковой модели MT-NLG на основе глубокой нейронной сети с архитектурой "трансформер". Модель охватывает 530 миллиардов параметров, а для обучения был задействован кластер, насчитывающий 4480 GPU (560 серверов DGX A100 с 8 GPU A100 80GB в каждом). В качестве областей применения модели называется решение задач по обработке информации на естественном языке, таких как прогнозирование завершения незаконченного предложения, ответы на вопросы, понимание прочитанного, формирование выводов на естественном языке и разбор неоднозначности смысла слов.