
Ключевое слово — в конкретный момент времени. Например, база непонятно от чего напряглась на 5 минут, потом всё само рассосалось, и очень хочется знать, почему. Отчёты за сутки, присылаемые dba на основе pg_stats_statements, не всегда проясняют ситуацию. Другие графики и логи могут помочь. Но всё же хочется не гадать на кофейной гуще, а конкретно посмотреть, что такому-то запросу в такое-то время было плохо, или его было много.
Можно, конечно, подключить системы а ля okmeter, но okmeter стоит денег. Да ещё и отсылает запросы в чужое облако — что, понятно, не в каждой организации можно считать безопасным.
На удивление, сделать такой мониторинг самому занимает всего полчаса времени, буквально с помощью нескольких строк Go-кода и палок.
Как же это сделать?
Часто дёргаем pg_stat_statements
Если кто вдруг не знает, в стандартной поставке Постгреса есть расширение для сбора статистики по запросам, называется pg_stat_statements. Чтобы его включить, нужно добавить в конфиг shared_preload_libraries='pg_stat_statements' и потом выполнить SQL-команду CREATE EXTENSION pg_stat_statements;. Это расширение собирает данные по запросам, собирая стату в оперативной памяти в сишной структуре. Практически без оверхеда. Посмотрите в мануале, какую информацию по запросам оно может выдать. Забирать стату просто — достаточно сделать запрос,
SELECT [что вас интересует] FROM pg_stat_statements;
и вы получите всю инфу по всем SQL-запросам.
Всё это здорово, но проблема заключается в том, что расширение копит информацию до тех пор, пока не сделаешь ему reset (pg_stat_statements_reset()). Причём этот ресет делается только из-под суперпользователя. Неудобно, и это получается какой-то глобальный стейт. Мало ли кто, когда и зачем это заресетит. Например, dba делает себе отчёт за сутки и отсылает по почте, чтобы понять, что в целом в системе можно подкрутить.
Поэтому мы пойдём другим путём. Чтобы понять, что происходит в каждый небольшой интервал времени, мы будем дёргать pg_stat_statements каждые несколько секунд и смотреть, что изменилось с прошлого вызова. Не буду приводить весь код, но суть примерно такая:
func (w Watcher) Watch() error {
previousStatStatements, err := w.getStatStatements()
if err != nil {
return err
}
// бесконечный цикл
for true {
time.Sleep(3 * time.Second)
currentStatStatements, err := w.getStatStatements()
if err != nil {
return err
}
// записываем изменения
w.logChanges(currentStatStatements, previousStatStatements)
previousStatStatements = currentStatStatements
}
return nil
}
В частности, будем смотреть на поле calls (количество вызовов запроса) и total_exec_time (суммарное время, потраченное на все вызовы запроса). Если для какого-то запроса calls увеличился с прошлого раза, значит, в этот интервал времени был этот запрос. А по разнице с предыдущими значениями calls и total_exec_time мы можем понять, сколько именно таких запросов было, и сколько времени это заняло. Заодно можно посчитать и среднее время запроса за наш небольшой интервал. Ну и куда-то надо это сохранить — давайте для начала просто выведем информацию в лог:
func (w Watcher) logChanges(currentStatStatements map[string]PgStatStatementsRow, previousStatStatements map[string]PgStatStatementsRow) {
currTime := time.Now()
for query, curr := range currentStatStatements {
if strings.Contains(query, "pg_stat_statements") {
continue
}
prev, exists := previousStatStatements[query]
if !exists || prev.Calls > curr.Calls {
prev = PgStatStatementsRow{Calls: 0, TotalTime: 0}
}
if curr.Calls == prev.Calls {
continue
}
timeDiff := curr.TotalTime - prev.TotalTime
countDiff := curr.Calls - prev.Calls
execMeanTime := timeDiff / float64(countDiff)
w.log.Info().
Bool("is_sql_stats", true).
Time("time", currTime).
Float64("time_diff", timeDiff).
Uint64("count_diff", countDiff).
Float64("exec_mean_time", execMeanTime).
Msg(query)
}
}
Записываем в лог и настраиваем отображение
Остаётся эту информацию куда-то сохранить. Но вообще-то, если честно, мы всё уже сохранили. Практически в любой мало-мальски серьёзной системе есть какой-то сбор логов и удобное отображение. В проектах, над которыми мы работаем в Каруне, обычно stdout контейнера ловится агентом и отправляется в общее хранилище. Т.е. ничего дополнительно изобретать не надо. У нас, по сути, достаточно просто выплюнуть json с информацией, и результат можно смотреть в грейлоге с удобным ui и различными визуальными свистелками.
Просто смотреть на бесконечные логи — это, конечно, грустно. Нужно сделать dashboard.
Создать дашборд — дело пары минут. Покажу, как.
Жмём кнопку "Create New Dashboard"

Нажимаем слева плюсик и выбираем Aggregation

Затем Edit. Откроется окошко, в котором надо выбрать параметры агрегации и отображения.
Rows — это поле, по которому будем агрегировать, т.е. сам sql-запрос. В моём случае оно после разбора джейсона попадает как _message.
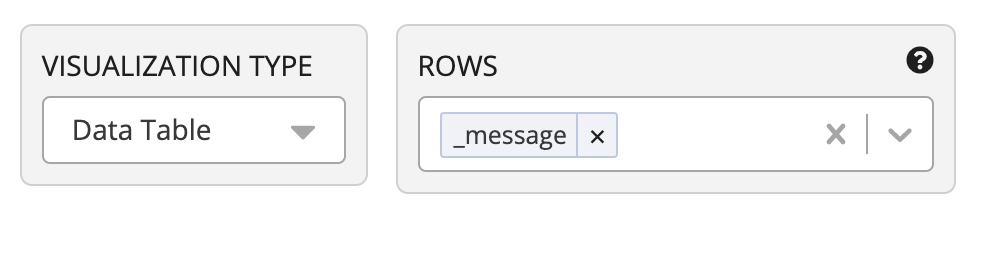
Metrics — это агрегационные функции. Нам будут интересны суммарное время выполнения запроса (sum(_time_diff)), сколько раз выполнялся (sum(_count_diff)) и, например, максимальное среди средних времён, так сказать (max(_exec_mean_time))

В итоге имеем примерно такой результат, его можно получить для любого интервала времени:

Если заменить тип отображения с Data Table на Pie Chart, то можно строить интересные картинки:

Можно делать и другие вещи. Всё зависит от вашей фантазии и возможностей грейлога. Например, можно выбрать интервал "последние 5 минут" и нажать кнопку автообновления, чтобы медитировать на то, что происходит в реальном времени.
Что если нет грейлога?
Я описал простейший случай, как сделать мониторинг на коленке за полчаса, имея только грейлог, который уже и так есть в системе. Разумеется, можно это делать и по-другому. Использовать кибану, например. Или, возможно, стоит писать метрики в prometheus, и отображать в grafana. Да как угодно.
Если у вас совсем ничего такого нет, ну можно тогда выводить информацию не в лог, а писать куда-нибудь в базу данных, а потом селектами информацию агрегировать. И написать свой UI, куда это красиво выводить и т.д.
Вывод
В общем, ничего сложного тут нет. И не всегда надо ставить или покупать особый софт: можно напилить небольшой велосипедик, не особо напрягаясь.
А потом можно его и доработать: в pg_stat_statements много информации, которую можно получить — не только количество и время.
Исходный код (громко сказано) можно посмотреть здесь.
Real-time мониторинг тормозящих запросов PostgreSQL своими руками за полчаса
В моей практике не раз были ситуации, когда хотелось посмотреть, какие именно запросы долго тупили в базе в определённый (конкретный) момент времени. А может, запросы не тупили, но каких-то запросов...
 habr.com
habr.com