Масштабируемость — ключевое требование для облачных приложений. С Kubernetes масштабировать приложение так же просто, как и увеличить количество реплик для соответствующего развертывания или ReplicaSet — но это ручной процесс. Команда Kubernetes aaS от Mail.ru реализовала в своем сервисе автоматическое машстабирование на уровне кластеров. Ну а если вы хотите оптимизироваться на уровне подов — то следуйте рекомендациям этого перевода.
Kubernetes позволяет автоматически масштабировать приложения (то есть Pod в развертывании или ReplicaSet) декларативным образом с использованием спецификации Horizontal Pod Autoscaler. По умолчанию критерий для автоматического масштабирования — метрики использования CPU (метрики ресурсов), но можно интегрировать пользовательские метрики и метрики, предоставляемые извне.
Это статья о том, как использовать внешние метрики для автоматического масштабирования приложения Kubernetes. Чтобы показать, как все работает, автор использует метрики запросов HTTP-доступа, они собираются с помощью Prometheus.
Вместо горизонтального автомасштабирования подов, применяется Kubernetes Event Driven Autoscaling (KEDA) — оператор Kubernetes с открытым исходным кодом. Он изначально интегрируется с Horizontal Pod Autoscaler, чтобы обеспечить плавное автомасштабирование (в том числе до/от нуля) для управляемых событиями рабочих нагрузок. Код доступен на GitHub.
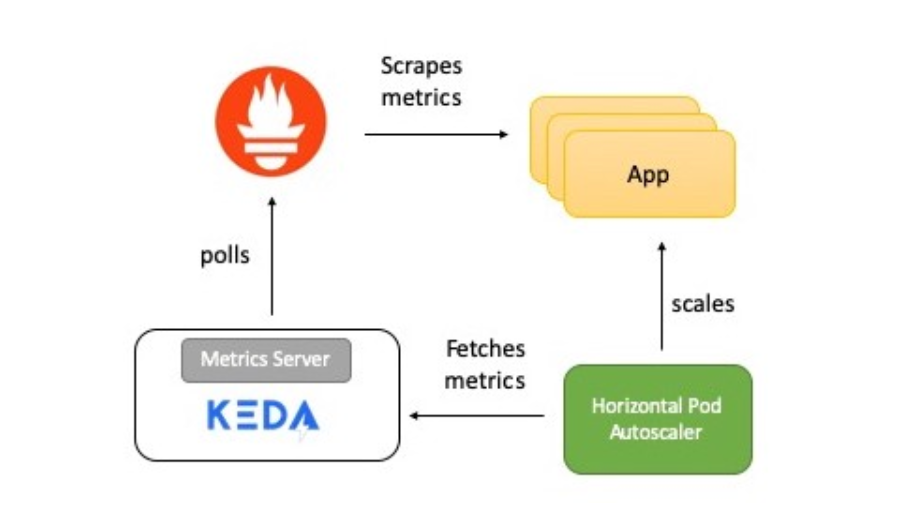
На схеме — краткое описание того, как все работает:
Теперь подробно расскажу о каждом элементе.
Prometheus — набор инструментов для мониторинга и оповещения систем с открытым исходным кодом, часть Cloud Native Computing Foundation. Собирает метрики из разных источников и сохраняет в виде данных временных рядов. Для визуализации данных можно использовать Grafana или другие инструменты визуализации, работающие с API Kubernetes.
KEDA поддерживает концепцию скейлера — он действует как мост между KEDA и внешней системой. Реализация скейлера специфична для каждой целевой системы и извлекает из нее данные. Затем KEDA использует их для управления автоматическим масштабированием.
Скейлеры поддерживают нескольких источников данных, например, Kafka, Redis, Prometheus. То есть KEDA можно применять для автоматического масштабирования развертываний Kubernetes, используя в качестве критериев метрики Prometheus.
Тестовое Golang-приложение предоставляет доступ по HTTP и выполняет две важные функции:
Приложение развертывается в Kubernetes через Deployment. Также создается служба ClusterIP, она позволяет серверу Prometheus получать метрики приложения.
Вот манифест развертывания для приложения.
Манифест развертывания Prometheus состоит из:
Вот манифест для запуска Prometheus.
Скейлер действует как мост между KEDA и внешней системой, из которой нужно получать метрики. ScaledObject — настраиваемый ресурс, его необходимо развернуть для синхронизации развертывания с источником событий, в данном случае с Prometheus.
ScaledObject содержит информацию о масштабировании развертывания, метаданные об источнике события (например, секреты для подключения, имя очереди), интервал опроса, период восстановления и другие данные. Он приводит к соответствующему ресурсу автомасштабирования (определение HPA) для масштабирования развертывания.
Когда объект ScaledObject удаляется, соответствующее ему определение HPA очищается.
Вот определение ScaledObject для нашего примера, в нем используется скейлер Prometheus:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: default
labels:
deploymentName: go-prom-app
spec:
scaleTargetRef:
deploymentName: go-prom-app
pollingInterval: 15
cooldownPeriod: 30
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
serverAddress:
metricName: access_frequency
threshold: '3'
query: sum(rate(http_requests[2m]))
Учтите следующие моменты:
Можно установить minReplicaCount равным нулю. В этом случае KEDA активирует развертывание с нуля до единицы, а затем предоставляет HPA для дальнейшего автоматического масштабирования. Возможен и обратный порядок, то есть масштабирование от единицы до нуля. В примере мы не выбрали ноль, поскольку это HTTP-сервис, а не система по запросу.
Пороговое значение используют в качестве триггера для масштабирования развертывания. В нашем примере запрос PromQL sum(rate (http_requests [2m])) возвращает агрегированное значение скорости HTTP-запросов (количество запросов в секунду), ее измеряют за последние две минуты.
Поскольку пороговое значение равно трем, значит, будет один под, пока значение sum(rate (http_requests [2m])) меньше трех. Если же значение возрастает, добавляется дополнительный под каждый раз, когда sum(rate (http_requests [2m])) увеличивается на три. Например, если значение от 12 до 14, то количество подов — четыре.
Теперь давайте попробуем настроить!
Всё, что вам нужно — кластер Kubernetes и настроенная утилита kubectl. В этом примере используется кластер minikube, но вы можете взять любой другой. Для установки кластера есть руководство.
Установить последнюю версию на Mac:
curl -Lo minikube
https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 \
&& chmod +x minikube
sudo mkdir -p /usr/local/bin/
sudo install minikube /usr/local/bin/
Установите kubectl, чтобы получить доступ к кластеру Kubernetes.
Поставить последнюю версию на Mac:
curl -LO
"https://storage.googleapis.com/kubernetes-release/release/$(curl -s
https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/darwin/amd64/kubectl"
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin/kubectl
kubectl version
Вы можете развернуть KEDA несколькими способами, они перечислены в документации. Я использую монолитный YAML:
kubectl apply -f
KEDA и ее компоненты устанавливаются в пространство имен keda. Команда для проверки:
kubectl get pods -n keda
Дождитесь, когда под KEDA Operator стартует — перейдет в Running State. И после этого продолжайте.
Если у вас не установлен Helm, воспользуйтесь этим руководством. Команда для установки на Mac:
brew install kubernetes-helm
helm init --history-max 200
helm init инициализирует локальный интерфейс командной строки, а также устанавливает Tiller в кластер Kubernetes.
kubectl get pods -n kube-system | grep tiller
Дождитесь перехода пода Tiller в состояние Running.
Примечание переводчика: Автор использует Helm@2, который требует установки серверного компонента Tiller. Сейчас актуален Helm@3, для него серверная часть не нужна.
После установки Helm для запуска Redis достаточно одной команды:
helm install --name redis-server --set cluster.enabled=false --set
usePassword=false stable/redis
Убедиться, что Redis успешно запустился:
kubectl get pods/redis-server-master-0
Дождитесь, когда под Redis перейдет в состояние Running.
Команда для развертывания:
kubectl apply -f go-app.yaml
//output
deployment.apps/go-prom-app created
service/go-prom-app-service created
Проверить, что все запустилось:
kubectl get pods -l=app=go-prom-app
Дождитесь перехода Redis в состояние Running.
Манифест Prometheus использует Kubernetes Service Discovery для Prometheus. Он позволяет динамически обнаруживать поды приложения на основе метки службы.
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_run]
regex: go-prom-app-service
action: keep
Для развертывания:
kubectl apply -f prometheus.yaml
//output
clusterrole.rbac.authorization.k8s.io/prometheus created
serviceaccount/default configured
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/prom-conf created
deployment.extensions/prometheus-deployment created
service/prometheus-service created
Проверить, что все запустилось:
kubectl get pods -l=app=prometheus-server
Дождитесь, пока под Prometheus перейдет в состояние Running.
Используйте kubectl port-forward для доступа к пользовательскому интерфейсу Prometheus (или серверу API) по адресу http://localhost:9090.
kubectl port-forward service/prometheus-service 9090
Команда для создания ScaledObject:
kubectl apply -f keda-prometheus-scaledobject.yaml
Проверьте логи оператора KEDA:
KEDA_POD_NAME=$(kubectl get pods -n keda
-o=jsonpath='{.items[0].metadata.name}')
kubectl logs $KEDA_POD_NAME -n keda
Результат выглядит примерно так:
time="2019-10-15T09:38:28Z" level=info msg="Watching ScaledObject:
default/prometheus-scaledobject"
time="2019-10-15T09:38:28Z" level=info msg="Created HPA with
namespace default and name keda-hpa-go-prom-app"
Проверьте под приложения. Должен быть запущен один экземпляр, поскольку minReplicaCount равно 1:
kubectl get pods -l=app=go-prom-app
Проверьте, что ресурс HPA успешно создан:
kubectl get hpa
Вы должны увидеть что-то вроде:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 0/3 (avg) 1 10 1 45s
Чтобы получить доступ к конечной точке REST нашего приложения, запустите:
kubectl port-forward service/go-prom-app-service 8080
Теперь вы можете получить доступ к приложению Go, используя адрес http://localhost:8080. Для этого выполните команду:
curl http://localhost:8080/test
Результат выглядит примерно так:
Accessed on 2019-10-21 11:29:10.560385986 +0000 UTC
m=+406004.817901246
Access count 1
На этом этапе также проверьте Redis. Вы увидите, что ключ access_count увеличен до 1:
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
"1"
Убедитесь, что значение метрики http_requests такое же:
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests number of http requests
# TYPE http_requests counter
http_requests 1
Мы будем использовать hey — утилиту для генерации нагрузки:
curl -o hey https://storage.googleapis.com/hey-release/hey_darwin_amd64
&& chmod a+x hey
Вы можете также скачать утилиту для Linux или Windows.
Запустите ее:
./hey http://localhost:8080/test
По умолчанию утилита отправляет 200 запросов. Вы можете убедиться в этом, используя метрики Prometheus, а также Redis.
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests number of http requests
# TYPE http_requests counter
http_requests 201
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
201
Подтвердите значение фактической метрики (возвращенной запросом PromQL):
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
//output
{"status":"success","data":{"resultType":"vector","result":[{"metric":{},"value":[1571734214.228,"1.686057971014493"]}]}}
В этом случае фактический результат равен 1,686057971014493 и отображается в поле value. Этого недостаточно для масштабирования, поскольку установленный нами порог равен 3.
В новом терминале следите за количеством подов приложения:
kubectl get pods -l=app=go-prom-app -w
Давайте увеличим нагрузку с помощью команды:
./hey -n 2000 http://localhost:8080/test
Через некоторое время вы увидите, что HPA масштабирует развертывание и запускает новые поды. Проверьте HPA, чтобы в этом убедиться:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 1830m/3 (avg) 1 10 6 4m22s
Если нагрузка непостоянна, развертывание уменьшится до точки, при которой работает только один под. Если хотите проверить фактическую метрику (возвращенную запросом PromQL), то используйте команду:
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
//Delete KEDA
kubectl delete namespace keda
//Delete the app, Prometheus server and KEDA scaled object
kubectl delete -f .
//Delete Redis
helm del --purge redis-server
KEDA позволяет автоматически масштабировать ваши развертывания Kubernetes (до/от нуля) на основе данных из внешних метрик. Например, на основе метрик Prometheus, длины очереди в Redis, задержки потребителя в теме Kafka.
KEDA выполняет интеграцию с внешним источником, а также предоставляет его метрики через Metrics Server для Horizontal Pod Autoscaler.
Успехов!
Источник статьи: https://habr.com/ru/company/mailru/blog/515114/
Kubernetes позволяет автоматически масштабировать приложения (то есть Pod в развертывании или ReplicaSet) декларативным образом с использованием спецификации Horizontal Pod Autoscaler. По умолчанию критерий для автоматического масштабирования — метрики использования CPU (метрики ресурсов), но можно интегрировать пользовательские метрики и метрики, предоставляемые извне.
Это статья о том, как использовать внешние метрики для автоматического масштабирования приложения Kubernetes. Чтобы показать, как все работает, автор использует метрики запросов HTTP-доступа, они собираются с помощью Prometheus.
Вместо горизонтального автомасштабирования подов, применяется Kubernetes Event Driven Autoscaling (KEDA) — оператор Kubernetes с открытым исходным кодом. Он изначально интегрируется с Horizontal Pod Autoscaler, чтобы обеспечить плавное автомасштабирование (в том числе до/от нуля) для управляемых событиями рабочих нагрузок. Код доступен на GitHub.
Краткий обзор работы системы
На схеме — краткое описание того, как все работает:
- Приложение предоставляет метрики количества обращений к HTTP в формате Prometheus.
- Prometheus настроен на сбор этих показателей.
- Скейлер Prometheus в KEDA настроен на автоматическое масштабирование приложения на основе количества обращений к HTTP.
Теперь подробно расскажу о каждом элементе.
KEDA и Prometheus
Prometheus — набор инструментов для мониторинга и оповещения систем с открытым исходным кодом, часть Cloud Native Computing Foundation. Собирает метрики из разных источников и сохраняет в виде данных временных рядов. Для визуализации данных можно использовать Grafana или другие инструменты визуализации, работающие с API Kubernetes.
KEDA поддерживает концепцию скейлера — он действует как мост между KEDA и внешней системой. Реализация скейлера специфична для каждой целевой системы и извлекает из нее данные. Затем KEDA использует их для управления автоматическим масштабированием.
Скейлеры поддерживают нескольких источников данных, например, Kafka, Redis, Prometheus. То есть KEDA можно применять для автоматического масштабирования развертываний Kubernetes, используя в качестве критериев метрики Prometheus.
Тестовое приложение
Тестовое Golang-приложение предоставляет доступ по HTTP и выполняет две важные функции:
- Использует клиентскую библиотеку Prometheus Go для инструментирования приложения и предоставления метрики http_requests, которая содержит счетчик обращений. Конечная точка, по которой доступны метрики Prometheus, расположена по URI /metrics.
var httpRequestsCounter = promauto.NewCounter(prometheus.CounterOpts{
Name: "http_requests",
Help: "number of http requests",
})
- В ответ на запрос GET приложение увеличивает значение ключа (access_count) в Redis. Это простой способ выполнить работу как часть обработчика HTTP, а также проверить метрики Prometheus. Значение метрики должно быть таким же, как значение access_count в Redis.
func main() {
http.Handle("/metrics", promhttp.Handler())
http.HandleFunc("/test", func(w http.ResponseWriter, r
*http.Request) {
defer httpRequestsCounter.Inc()
count, err := client.Incr(redisCounterName).Result()
if err != nil {
fmt.Println("Unable to increment redis counter", err)
os.Exit(1)
}
resp := "Accessed on " + time.Now().String() + "\nAccess count " + strconv.Itoa(int(count))
w.Write([]byte(resp))
})
http.ListenAndServe(":8080", nil)
}
Приложение развертывается в Kubernetes через Deployment. Также создается служба ClusterIP, она позволяет серверу Prometheus получать метрики приложения.
Вот манифест развертывания для приложения.
Сервер Prometheus
Манифест развертывания Prometheus состоит из:
- ConfigMap — для передачи конфига Prometheus;
- Deployment — для развертывания Prometheus в Kubernetes-кластере;
- ClusterIP — сервис для доступа к UI Prometheus;
- ClusterRole, ClusterRoleBinding и ServiceAccount — для работы автоопределения сервисов в Kubernetes (Auto-discovery).
Вот манифест для запуска Prometheus.
KEDA Prometheus ScaledObject
Скейлер действует как мост между KEDA и внешней системой, из которой нужно получать метрики. ScaledObject — настраиваемый ресурс, его необходимо развернуть для синхронизации развертывания с источником событий, в данном случае с Prometheus.
ScaledObject содержит информацию о масштабировании развертывания, метаданные об источнике события (например, секреты для подключения, имя очереди), интервал опроса, период восстановления и другие данные. Он приводит к соответствующему ресурсу автомасштабирования (определение HPA) для масштабирования развертывания.
Когда объект ScaledObject удаляется, соответствующее ему определение HPA очищается.
Вот определение ScaledObject для нашего примера, в нем используется скейлер Prometheus:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: default
labels:
deploymentName: go-prom-app
spec:
scaleTargetRef:
deploymentName: go-prom-app
pollingInterval: 15
cooldownPeriod: 30
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
serverAddress:
metricName: access_frequency
threshold: '3'
query: sum(rate(http_requests[2m]))
Учтите следующие моменты:
- Он указывает на Deployment с именем go-prom-app.
- Тип триггера — Prometheus. Адрес сервера Prometheus упоминается вместе с именем метрики, пороговым значением и запросом PromQL, который будет использоваться. Запрос PromQL — sum(rate(http_requests[2m])).
- Согласно pollingInterval, KEDA запрашивает цель у Prometheus каждые пятнадцать секунд. Поддерживается минимум один под (minReplicaCount), а максимальное количество подов не превышает maxReplicaCount (в данном примере — десять).
Можно установить minReplicaCount равным нулю. В этом случае KEDA активирует развертывание с нуля до единицы, а затем предоставляет HPA для дальнейшего автоматического масштабирования. Возможен и обратный порядок, то есть масштабирование от единицы до нуля. В примере мы не выбрали ноль, поскольку это HTTP-сервис, а не система по запросу.
Магия внутри автомасштабирования
Пороговое значение используют в качестве триггера для масштабирования развертывания. В нашем примере запрос PromQL sum(rate (http_requests [2m])) возвращает агрегированное значение скорости HTTP-запросов (количество запросов в секунду), ее измеряют за последние две минуты.
Поскольку пороговое значение равно трем, значит, будет один под, пока значение sum(rate (http_requests [2m])) меньше трех. Если же значение возрастает, добавляется дополнительный под каждый раз, когда sum(rate (http_requests [2m])) увеличивается на три. Например, если значение от 12 до 14, то количество подов — четыре.
Теперь давайте попробуем настроить!
Предварительная настройка
Всё, что вам нужно — кластер Kubernetes и настроенная утилита kubectl. В этом примере используется кластер minikube, но вы можете взять любой другой. Для установки кластера есть руководство.
Установить последнюю версию на Mac:
curl -Lo minikube
https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 \
&& chmod +x minikube
sudo mkdir -p /usr/local/bin/
sudo install minikube /usr/local/bin/
Установите kubectl, чтобы получить доступ к кластеру Kubernetes.
Поставить последнюю версию на Mac:
curl -LO
"https://storage.googleapis.com/kubernetes-release/release/$(curl -s
https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/darwin/amd64/kubectl"
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin/kubectl
kubectl version
Установка KEDA
Вы можете развернуть KEDA несколькими способами, они перечислены в документации. Я использую монолитный YAML:
kubectl apply -f
KEDA и ее компоненты устанавливаются в пространство имен keda. Команда для проверки:
kubectl get pods -n keda
Дождитесь, когда под KEDA Operator стартует — перейдет в Running State. И после этого продолжайте.
Установка Redis при помощи Helm
Если у вас не установлен Helm, воспользуйтесь этим руководством. Команда для установки на Mac:
brew install kubernetes-helm
helm init --history-max 200
helm init инициализирует локальный интерфейс командной строки, а также устанавливает Tiller в кластер Kubernetes.
kubectl get pods -n kube-system | grep tiller
Дождитесь перехода пода Tiller в состояние Running.
Примечание переводчика: Автор использует Helm@2, который требует установки серверного компонента Tiller. Сейчас актуален Helm@3, для него серверная часть не нужна.
После установки Helm для запуска Redis достаточно одной команды:
helm install --name redis-server --set cluster.enabled=false --set
usePassword=false stable/redis
Убедиться, что Redis успешно запустился:
kubectl get pods/redis-server-master-0
Дождитесь, когда под Redis перейдет в состояние Running.
Развертывание приложения
Команда для развертывания:
kubectl apply -f go-app.yaml
//output
deployment.apps/go-prom-app created
service/go-prom-app-service created
Проверить, что все запустилось:
kubectl get pods -l=app=go-prom-app
Дождитесь перехода Redis в состояние Running.
Развертывание сервера Prometheus
Манифест Prometheus использует Kubernetes Service Discovery для Prometheus. Он позволяет динамически обнаруживать поды приложения на основе метки службы.
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_run]
regex: go-prom-app-service
action: keep
Для развертывания:
kubectl apply -f prometheus.yaml
//output
clusterrole.rbac.authorization.k8s.io/prometheus created
serviceaccount/default configured
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/prom-conf created
deployment.extensions/prometheus-deployment created
service/prometheus-service created
Проверить, что все запустилось:
kubectl get pods -l=app=prometheus-server
Дождитесь, пока под Prometheus перейдет в состояние Running.
Используйте kubectl port-forward для доступа к пользовательскому интерфейсу Prometheus (или серверу API) по адресу http://localhost:9090.
kubectl port-forward service/prometheus-service 9090
Развертывание конфигурации автомасштабирования KEDA
Команда для создания ScaledObject:
kubectl apply -f keda-prometheus-scaledobject.yaml
Проверьте логи оператора KEDA:
KEDA_POD_NAME=$(kubectl get pods -n keda
-o=jsonpath='{.items[0].metadata.name}')
kubectl logs $KEDA_POD_NAME -n keda
Результат выглядит примерно так:
time="2019-10-15T09:38:28Z" level=info msg="Watching ScaledObject:
default/prometheus-scaledobject"
time="2019-10-15T09:38:28Z" level=info msg="Created HPA with
namespace default and name keda-hpa-go-prom-app"
Проверьте под приложения. Должен быть запущен один экземпляр, поскольку minReplicaCount равно 1:
kubectl get pods -l=app=go-prom-app
Проверьте, что ресурс HPA успешно создан:
kubectl get hpa
Вы должны увидеть что-то вроде:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 0/3 (avg) 1 10 1 45s
Проверка работоспособности: доступ к приложению
Чтобы получить доступ к конечной точке REST нашего приложения, запустите:
kubectl port-forward service/go-prom-app-service 8080
Теперь вы можете получить доступ к приложению Go, используя адрес http://localhost:8080. Для этого выполните команду:
curl http://localhost:8080/test
Результат выглядит примерно так:
Accessed on 2019-10-21 11:29:10.560385986 +0000 UTC
m=+406004.817901246
Access count 1
На этом этапе также проверьте Redis. Вы увидите, что ключ access_count увеличен до 1:
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
"1"
Убедитесь, что значение метрики http_requests такое же:
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests number of http requests
# TYPE http_requests counter
http_requests 1
Создание нагрузки
Мы будем использовать hey — утилиту для генерации нагрузки:
curl -o hey https://storage.googleapis.com/hey-release/hey_darwin_amd64
&& chmod a+x hey
Вы можете также скачать утилиту для Linux или Windows.
Запустите ее:
./hey http://localhost:8080/test
По умолчанию утилита отправляет 200 запросов. Вы можете убедиться в этом, используя метрики Prometheus, а также Redis.
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests number of http requests
# TYPE http_requests counter
http_requests 201
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
201
Подтвердите значение фактической метрики (возвращенной запросом PromQL):
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
//output
{"status":"success","data":{"resultType":"vector","result":[{"metric":{},"value":[1571734214.228,"1.686057971014493"]}]}}
В этом случае фактический результат равен 1,686057971014493 и отображается в поле value. Этого недостаточно для масштабирования, поскольку установленный нами порог равен 3.
Больше нагрузки!
В новом терминале следите за количеством подов приложения:
kubectl get pods -l=app=go-prom-app -w
Давайте увеличим нагрузку с помощью команды:
./hey -n 2000 http://localhost:8080/test
Через некоторое время вы увидите, что HPA масштабирует развертывание и запускает новые поды. Проверьте HPA, чтобы в этом убедиться:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 1830m/3 (avg) 1 10 6 4m22s
Если нагрузка непостоянна, развертывание уменьшится до точки, при которой работает только один под. Если хотите проверить фактическую метрику (возвращенную запросом PromQL), то используйте команду:
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
Очистка
//Delete KEDA
kubectl delete namespace keda
//Delete the app, Prometheus server and KEDA scaled object
kubectl delete -f .
//Delete Redis
helm del --purge redis-server
Заключение
KEDA позволяет автоматически масштабировать ваши развертывания Kubernetes (до/от нуля) на основе данных из внешних метрик. Например, на основе метрик Prometheus, длины очереди в Redis, задержки потребителя в теме Kafka.
KEDA выполняет интеграцию с внешним источником, а также предоставляет его метрики через Metrics Server для Horizontal Pod Autoscaler.
Успехов!
Источник статьи: https://habr.com/ru/company/mailru/blog/515114/