В iFunny на первом уровне модерации мы выделяем три основных класса:
Для начала возьмём небольшую сеть VGG-11, которая уже реализована во фреймворке pytorch. Сейчас есть много других сетей с результатами получше, но данная модель достаточно легкая, чтобы получить заметный результат за короткое время.
Зададим несколько преобразований, чтобы унифицировать данные и привести их к привычному для сети виду. Из документации следует, что модель была предобучена на изображениях размера 224×224 пикселя, приведённых к такому формату с помощью преобразований:
from torchvision import transforms
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
]
)
Сначала уменьшаем изображение вдоль его наименьшей стороны до 256 пикселей, а затем вырезаем из центра квадрат со сторонами 224×224 пикселя. После этого независимо производится нормировка вдоль каждого канала в RGB-пространстве. Именно поэтому в преобразовании задано три значения среднего, и столько же дисперсий.
Зачем вообще нужно делать нормализацию? Представьте, что вы непутёвая Золушка и рассыпали на пол несколько видов круп, которые нужно собрать и разделить. Можно собирать по зёрнышку и сразу откладывать в нужную кучку, но удобнее собрать всё в одну кучку, а уже потом разделять по сортам. То же самое мы делаем для сети — собираем все значения в одну кучу, а потом заставляем сеть делить их на выделенные классы.

Теперь загрузим саму модель и её веса, полученные при обучении на датасете ImageNet:
From torchvision import models
model = models.vgg11(pretrained=True).eval()
Метод eval класса VGG позволяет отключить обучение и расчёт градиента, что ускоряет предсказание модели там, где нужно узнать только ответ без дополнительного обучения, а также фиксирует все веса, что позволяет получать один и тот же ответ независимо от количества запусков. Картинки, которые находятся в наборе данных ImageNet, выглядят примерно так:
 Примеры картинок датасета ImageNet. Там около тысячи классов.
Примеры картинок датасета ImageNet. Там около тысячи классов.
Посмотрим, на какие объекты изображений реагирует сеть при выборе того или иного класса — так лучше поймём, как она работает. Для этого воспользуемся вектором Шепли (Shapley Value), который отражает то, как меняется решение сети с параметром и без него (в нашем случае параметром будет значение пикселя).
Код для получения рисунка ниже можно взять из документации. Мы лишь добавили ещё одно изображение, заменили модель (в примере используется VGG-16), а также слой, с которого берётся градиент (с седьмого, как в примере, на десятый).
Результат следующий:
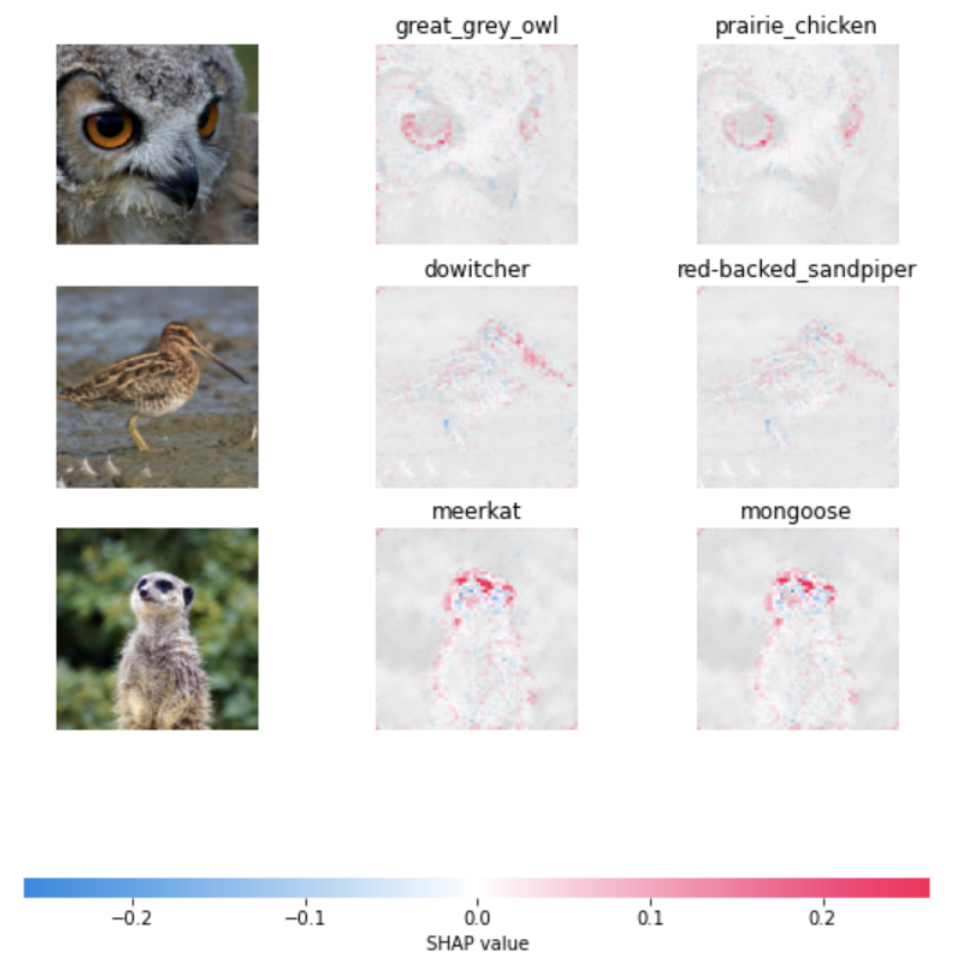
Первый столбец — исходная картинка, второй столбец — первый предсказанный класс с наибольшим значением вероятности, третий столбец — второй по важности класс. Красным выделено то, на что сеть реагировала больше всего, а синим — то, что её склоняло в сторону другого класса при выборе текущего.
Если погуглить названия классов, то будет видно, что даже если сеть ошиблась, как в случае совы (она не верно указала вид, однако это может быть связано с наличием только такого лейбла в датасете), то её ответ очень близок к истине.
Теперь вспомним, что у нас есть свой датасет, который мы разметили. Для примера возьмём реальные картинки из трёх классов нашего приложения iFunny. Напомню их:
interim/
approved/
H6f8XI2i8.jpg
XFkQE1Zi8.jpg
...
not_suitable/
DCS2iR3i8.jpg
KmyGT7Yi8.jpg
...
risked/
KRXZUuci8.jpg
m6CH7yxh8.jpg
...
Создадим словарь с датасетами тренировочной и валидационной выборок:
from torchvision import datasets
datasets = {
'train': ImageFolder(
root='train/interim/',
transform=transform
),
'valid': ImageFolder(
root='test/interim/',
transform=transform
),
}
datasets['train'].class_to_idx
Как было сказано ранее, класс ImageFolder производит лейблирование — каждой названной папке сопоставляет определённую цифру. По факту выдает порядковый номер отсортированного по алфавиту списка классов:
{'approved': 0, 'not_suitable’: 1, 'risked’: 2}
Это необходимо, поскольку производить математические операции с числами в процессе оптимизации сети проще, чем обращаться к строкам. Но загружать по одному изображению долго, поэтому используем DataLoader, который делает это сразу пачкой (в DS среде она называется батчом):
torchfrom torch.utils.data import DataLoader
batch_size = 100
num_workers = 20
dataloaders = {
'train': DataLoader(
datasets['train'],
batch_size=batch_size,
shuffle=True,
num_workers=num_workers
),
'valid': DataLoader(
datasets['valid'],
batch_size=batch_size,
shuffle=True,
num_workers=num_workers
)
}
Передаём в DataLoader наш датасет и указываем размер батча, который говорит о том, сколько картинок загрузить в сеть одновременно. С точки зрения машины все изображения являются матрицами, а все операции внутри сети — матричными. Поэтому ничего не мешает производить их сразу с N изображениями, собрав их вместе.
Также DataLoader может загружать данные параллельно, за счёт чего процесс загрузки происходит в разы быстрее. Количество одновременных процессов на загрузку задаётся параметром num_workers.
Отобразим наш тренировочный датасет:
import numpy as np
real_batch = next(iter(dataloaders['train']))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0][:64], padding=2, normalize=True),(1,2,0)));
Примерно так выглядит контент, который загружают пользователи в iFunny, с единственным отличием, предполагающим сбалансированность классов в нашем датасете, в отличие от реальности, где risked контент составляет меньше 10%:

В следующей строке повторим загрузку модели с заданной архитектурой VGG-11. Флаг pretrained в положении True позволяет загрузить предобученные на ImageNet веса, любезно предоставленные pytorch. Модель переводим в память ГПУ методом to, аргументом которого является название необходимого девайса, так как все дальнейшие вычисления будут производиться на ней.
device = 'cuda'
model = models.vgg11(pretrained=True, progress=False).to(device)
Затем в цикле присваиваем атрибуту requires_grad всех слоев сети значение False, чтобы в процессе обучения они не изменялись:
for param in model.parameters():
param.requires_grad = False
После чего меняем слой, отвечающий за классификацию:
model.classifier[6] = torch.nn.Linear(4096, 3).to(device)
Важный момент: мы не переобучаем все предыдущие слои, так как считаем, что они уже научились выделять общие признаки, в отличие от последнего слоя, который только что поменяли и тем самым переключили его атрибут requires_grad в положение True. Этот слой необходимо обучить, так как теперь он имеет случайные веса, а значит не может корректно отличать что-либо. Также нужно задать оптимизатор, который будет подбирать наиболее подходящие веса и фактически обучать сеть.
Для этого возьмём один из методов градиентного спуска Adam. Ещё необходимо указать критерий, по которому будет идти оптимизация — для этого используем кросс-энтропию.
params_to_update = model.parameters()
print("Params to learn:")
params_to_update = []
for name,param in model.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
optimizer = torch.optim.Adam(params_to_update, lr=0.0001)
criterion = torch.nn.CrossEntropyLoss()
В цикле выше собираем слои, у которых флаг requires_grad в положении True. До этого мы их переводили в положении False, поэтому в оптимизатор передаётся информация только о последнем слое.
import time
import copy
from tqdm import tqdm
def train_model(model, dataloaders, criterion, optimizer, num_epochs=10):
since = time.time()
val_acc_history = []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'valid']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in tqdm(dataloaders[phase]):
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if phase == 'valid':
val_acc_history.append(epoch_acc)
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model, val_acc_history
На данный момент уже существует множество библиотек для автоматизации процесса обучения. Они отличаются между собой различными логгерами, возможностью подключения дополнительных модулей и другими удобствами. Но есть неизменная основа.
Нужно обязательно обнулять градиент командой optimizer.zero_grad() перед каждым запуском обратного распространения ошибки внутри сети:
loss.backward()
optimizer.step()
Первая строка запускает операцию обратного распространения ошибки внутри сети из переменной потери (loss). Вторая — выполняет градиентный шаг на основе вычисленных градиентов.
Ответы нашей модели считаются в следующей строке:
outputs = model(inputs)
А ошибку, которую используем в дальнейшем для расчёта градиента, получаем одной строчкой:
loss = criterion(outputs, labels)
В процессе обучения происходит не только тренировка, но и проверка качества сети на объектах, не участвующих в обучении. Так можно выявить наличие переобучения, когда сеть начинает запоминать образцы из тренировочной выборки, и теряет обобщающую способность — то есть показывает результаты на новых данных заметно хуже, чем на тренировочных.
Чтобы этого избежать, нужно регулярно производить проверку на отложенной выборке. В данном процессе не стоит вычислять градиент, чтобы сеть не запомнила и эти примеры. Поэтому переключаем сеть в другой режим методом eval:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
Для иллюстрации процесса обучения и его результатов, мы провели обучение модели на 10 эпохах. Эпохой в DS среде называется полный проход по всем примерам выборки (обычно сеть не способна за один раз усвоить все правила, поэтому количество эпох почти всегда больше 1). Ниже приведены выводы функции обучения:
model, val_acc_history = train_model(model, dataloaders, criterion, optimizer, num_epochs=10)
Логи обучения
По динамике видно, что метрики со временем улучшаются как на тренировочной, так и на валидационной выборках. При этом значения loss-функции падают. Это говорит о положительном течении процесса обучения, а также об отсутствии переобучения модели.
Сеть хорошо научилась разделять approved и not suitable контент, а вот с изображениями класса risked не всё так гладко. Но напомню, что использовалась очень простенькая сеть без каких-либо дополнительных методов улучшения, поэтому её ещё есть куда развивать.

На первой картинке с котом видно, что сеть при выборе approved класса в основном смотрела на мордочку и уши. У Гитлера определённые паттерны при выборе класса risked выделить сложнее — сеть немного отреагировала на нос и усы, но скорее всего решение принималось по цветовой гамме, так как нацистские фото почти всегда чёрно-белые, и она цепляется за этот признак.
Самое интересное можно наблюдать на третьей картинке с девушкой. Грудь была важным параметром для выбора обоих классов (и risked, и not suitable), но оказала негативное влияние на класс approved, отклонив его. В пользу not suitable сеть склонил купальник, контур которого у этого класса выделен красным, а у risked — синим. В данном случае все логично, поскольку без купальника данный контент стал бы эротикой и считался недопустимым. Также наличие лица в кадре отрицательно сказалось при проверке сетью принадлежности объекта к risked классу — мы не запрещаем пользователям загружать селфи, но и не продвигаем его через общую ленту, так как такой контент больше подходит для Instagram.
С помощью метода из первой статьи можно получить первичную разметку, которую придётся перепроверить вручную для лучшего качества, но это будет проще, чем размечать все объекты с нуля. На основе последовательности действий из статьи можно дообучить не только представленную сеть, но и что-то более сложное.
На данный момент в открытом доступе лежит большое количество готовых реализаций архитектур от Google, Facebook, а также других компаний и университетов с предобученными весами, показывающими отличные результаты, а порой даже относящихся к State of the Art (SOTA). Для поиска подходящей архитектуры есть удобный сайт Papers with Code, где в открытом доступе на GitHub есть готовые реализации.
Напоследок — мем, который был одобрен нашей обученной сетью с вероятностью 85%.

Вероятности классов:
approved — 0.8528
not suitable — 0.0996
risked — 0.0475

 habr.com
habr.com
- approved — картинки идут в раздел collective (развлекательный контент и мемы);
- not suitable — не попадают в общую ленту, но остаются в ленте пользователя (селфи, пейзажи и другие);
- risked — получают бан и удаляются из приложения (расизм, порнография, расчленёнка и всё, что попадает под определение «противоправный контент»).
Для начала возьмём небольшую сеть VGG-11, которая уже реализована во фреймворке pytorch. Сейчас есть много других сетей с результатами получше, но данная модель достаточно легкая, чтобы получить заметный результат за короткое время.
Зададим несколько преобразований, чтобы унифицировать данные и привести их к привычному для сети виду. Из документации следует, что модель была предобучена на изображениях размера 224×224 пикселя, приведённых к такому формату с помощью преобразований:
from torchvision import transforms
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
]
)
Сначала уменьшаем изображение вдоль его наименьшей стороны до 256 пикселей, а затем вырезаем из центра квадрат со сторонами 224×224 пикселя. После этого независимо производится нормировка вдоль каждого канала в RGB-пространстве. Именно поэтому в преобразовании задано три значения среднего, и столько же дисперсий.
Зачем вообще нужно делать нормализацию? Представьте, что вы непутёвая Золушка и рассыпали на пол несколько видов круп, которые нужно собрать и разделить. Можно собирать по зёрнышку и сразу откладывать в нужную кучку, но удобнее собрать всё в одну кучку, а уже потом разделять по сортам. То же самое мы делаем для сети — собираем все значения в одну кучу, а потом заставляем сеть делить их на выделенные классы.
Теперь загрузим саму модель и её веса, полученные при обучении на датасете ImageNet:
From torchvision import models
model = models.vgg11(pretrained=True).eval()
Метод eval класса VGG позволяет отключить обучение и расчёт градиента, что ускоряет предсказание модели там, где нужно узнать только ответ без дополнительного обучения, а также фиксирует все веса, что позволяет получать один и тот же ответ независимо от количества запусков. Картинки, которые находятся в наборе данных ImageNet, выглядят примерно так:
Посмотрим, на какие объекты изображений реагирует сеть при выборе того или иного класса — так лучше поймём, как она работает. Для этого воспользуемся вектором Шепли (Shapley Value), который отражает то, как меняется решение сети с параметром и без него (в нашем случае параметром будет значение пикселя).
Код для получения рисунка ниже можно взять из документации. Мы лишь добавили ещё одно изображение, заменили модель (в примере используется VGG-16), а также слой, с которого берётся градиент (с седьмого, как в примере, на десятый).
Результат следующий:
Первый столбец — исходная картинка, второй столбец — первый предсказанный класс с наибольшим значением вероятности, третий столбец — второй по важности класс. Красным выделено то, на что сеть реагировала больше всего, а синим — то, что её склоняло в сторону другого класса при выборе текущего.
Если погуглить названия классов, то будет видно, что даже если сеть ошиблась, как в случае совы (она не верно указала вид, однако это может быть связано с наличием только такого лейбла в датасете), то её ответ очень близок к истине.
Теперь вспомним, что у нас есть свой датасет, который мы разметили. Для примера возьмём реальные картинки из трёх классов нашего приложения iFunny. Напомню их:
- approved — картинки идут в раздел приложения collective;
- not suitable — не попадают в общую ленту, но остаются в ленте пользователя. К этому относятся девушки в купальниках и мужчины в плавках, селфи и всё, что не является мемами и не несет в себе развлекательную функцию;
- risked — сюда относится расизм, порно, расчленёнка и всё, что законадательно запрещено к размещению и может навредить имиджу компании. Такой контент получает бан и перестает быть доступным всем пользователям iFunny.
interim/
approved/
H6f8XI2i8.jpg
XFkQE1Zi8.jpg
...
not_suitable/
DCS2iR3i8.jpg
KmyGT7Yi8.jpg
...
risked/
KRXZUuci8.jpg
m6CH7yxh8.jpg
...
Создадим словарь с датасетами тренировочной и валидационной выборок:
from torchvision import datasets
datasets = {
'train': ImageFolder(
root='train/interim/',
transform=transform
),
'valid': ImageFolder(
root='test/interim/',
transform=transform
),
}
datasets['train'].class_to_idx
Как было сказано ранее, класс ImageFolder производит лейблирование — каждой названной папке сопоставляет определённую цифру. По факту выдает порядковый номер отсортированного по алфавиту списка классов:
{'approved': 0, 'not_suitable’: 1, 'risked’: 2}
Это необходимо, поскольку производить математические операции с числами в процессе оптимизации сети проще, чем обращаться к строкам. Но загружать по одному изображению долго, поэтому используем DataLoader, который делает это сразу пачкой (в DS среде она называется батчом):
torchfrom torch.utils.data import DataLoader
batch_size = 100
num_workers = 20
dataloaders = {
'train': DataLoader(
datasets['train'],
batch_size=batch_size,
shuffle=True,
num_workers=num_workers
),
'valid': DataLoader(
datasets['valid'],
batch_size=batch_size,
shuffle=True,
num_workers=num_workers
)
}
Передаём в DataLoader наш датасет и указываем размер батча, который говорит о том, сколько картинок загрузить в сеть одновременно. С точки зрения машины все изображения являются матрицами, а все операции внутри сети — матричными. Поэтому ничего не мешает производить их сразу с N изображениями, собрав их вместе.
Также DataLoader может загружать данные параллельно, за счёт чего процесс загрузки происходит в разы быстрее. Количество одновременных процессов на загрузку задаётся параметром num_workers.
Отобразим наш тренировочный датасет:
import numpy as np
real_batch = next(iter(dataloaders['train']))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0][:64], padding=2, normalize=True),(1,2,0)));
Примерно так выглядит контент, который загружают пользователи в iFunny, с единственным отличием, предполагающим сбалансированность классов в нашем датасете, в отличие от реальности, где risked контент составляет меньше 10%:
Перестройка модели под наши цели
Внутри сети происходит выделение разных паттернов (уши и хвосты на картинках с животными, как в примере выше), а самый последний слой на их основании делает предположение, чем является данный объект. Именно последний слой нам и нужно поменять, потому что на выходе он по умолчанию имеет тысячу классов, а нам нужно всего три, и совсем других, которых не было в этой тысяче.В следующей строке повторим загрузку модели с заданной архитектурой VGG-11. Флаг pretrained в положении True позволяет загрузить предобученные на ImageNet веса, любезно предоставленные pytorch. Модель переводим в память ГПУ методом to, аргументом которого является название необходимого девайса, так как все дальнейшие вычисления будут производиться на ней.
device = 'cuda'
model = models.vgg11(pretrained=True, progress=False).to(device)
Затем в цикле присваиваем атрибуту requires_grad всех слоев сети значение False, чтобы в процессе обучения они не изменялись:
for param in model.parameters():
param.requires_grad = False
После чего меняем слой, отвечающий за классификацию:
model.classifier[6] = torch.nn.Linear(4096, 3).to(device)
Важный момент: мы не переобучаем все предыдущие слои, так как считаем, что они уже научились выделять общие признаки, в отличие от последнего слоя, который только что поменяли и тем самым переключили его атрибут requires_grad в положение True. Этот слой необходимо обучить, так как теперь он имеет случайные веса, а значит не может корректно отличать что-либо. Также нужно задать оптимизатор, который будет подбирать наиболее подходящие веса и фактически обучать сеть.
Для этого возьмём один из методов градиентного спуска Adam. Ещё необходимо указать критерий, по которому будет идти оптимизация — для этого используем кросс-энтропию.
params_to_update = model.parameters()
print("Params to learn:")
params_to_update = []
for name,param in model.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
optimizer = torch.optim.Adam(params_to_update, lr=0.0001)
criterion = torch.nn.CrossEntropyLoss()
В цикле выше собираем слои, у которых флаг requires_grad в положении True. До этого мы их переводили в положении False, поэтому в оптимизатор передаётся информация только о последнем слое.
Обучение модели
Для обучения воспользуемся функцией train_model из официального туториала pytorch:import time
import copy
from tqdm import tqdm
def train_model(model, dataloaders, criterion, optimizer, num_epochs=10):
since = time.time()
val_acc_history = []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'valid']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in tqdm(dataloaders[phase]):
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if phase == 'valid':
val_acc_history.append(epoch_acc)
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model, val_acc_history
На данный момент уже существует множество библиотек для автоматизации процесса обучения. Они отличаются между собой различными логгерами, возможностью подключения дополнительных модулей и другими удобствами. Но есть неизменная основа.
Нужно обязательно обнулять градиент командой optimizer.zero_grad() перед каждым запуском обратного распространения ошибки внутри сети:
loss.backward()
optimizer.step()
Первая строка запускает операцию обратного распространения ошибки внутри сети из переменной потери (loss). Вторая — выполняет градиентный шаг на основе вычисленных градиентов.
Ответы нашей модели считаются в следующей строке:
outputs = model(inputs)
А ошибку, которую используем в дальнейшем для расчёта градиента, получаем одной строчкой:
loss = criterion(outputs, labels)
В процессе обучения происходит не только тренировка, но и проверка качества сети на объектах, не участвующих в обучении. Так можно выявить наличие переобучения, когда сеть начинает запоминать образцы из тренировочной выборки, и теряет обобщающую способность — то есть показывает результаты на новых данных заметно хуже, чем на тренировочных.
Чтобы этого избежать, нужно регулярно производить проверку на отложенной выборке. В данном процессе не стоит вычислять градиент, чтобы сеть не запомнила и эти примеры. Поэтому переключаем сеть в другой режим методом eval:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
Для иллюстрации процесса обучения и его результатов, мы провели обучение модели на 10 эпохах. Эпохой в DS среде называется полный проход по всем примерам выборки (обычно сеть не способна за один раз усвоить все правила, поэтому количество эпох почти всегда больше 1). Ниже приведены выводы функции обучения:
model, val_acc_history = train_model(model, dataloaders, criterion, optimizer, num_epochs=10)
Логи обучения
По динамике видно, что метрики со временем улучшаются как на тренировочной, так и на валидационной выборках. При этом значения loss-функции падают. Это говорит о положительном течении процесса обучения, а также об отсутствии переобучения модели.
Результаты обучения
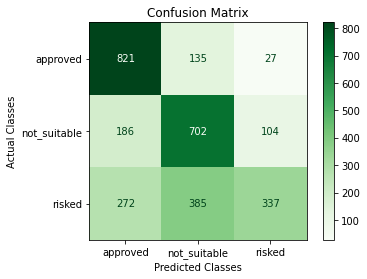
Также как и в случае с классификацией чисел, построим матрицу ошибок, чтобы увидеть, как наша модель справляется с поставленной задачей.
Сеть хорошо научилась разделять approved и not suitable контент, а вот с изображениями класса risked не всё так гладко. Но напомню, что использовалась очень простенькая сеть без каких-либо дополнительных методов улучшения, поэтому её ещё есть куда развивать.
Паттерны новой сети
Отразим основные паттерны нашей сети с помощью вектора Шепли.
На первой картинке с котом видно, что сеть при выборе approved класса в основном смотрела на мордочку и уши. У Гитлера определённые паттерны при выборе класса risked выделить сложнее — сеть немного отреагировала на нос и усы, но скорее всего решение принималось по цветовой гамме, так как нацистские фото почти всегда чёрно-белые, и она цепляется за этот признак.
Самое интересное можно наблюдать на третьей картинке с девушкой. Грудь была важным параметром для выбора обоих классов (и risked, и not suitable), но оказала негативное влияние на класс approved, отклонив его. В пользу not suitable сеть склонил купальник, контур которого у этого класса выделен красным, а у risked — синим. В данном случае все логично, поскольку без купальника данный контент стал бы эротикой и считался недопустимым. Также наличие лица в кадре отрицательно сказалось при проверке сетью принадлежности объекта к risked классу — мы не запрещаем пользователям загружать селфи, но и не продвигаем его через общую ленту, так как такой контент больше подходит для Instagram.
Вместо заключения
Мы научились классифицировать данные с разметкой с помощью дообучения предобученной сети. А также разобрались, на что реагируют модели и как происходит обучение сети. Эти способы скорее базовые и не претендуют на совершенство, но являются отличной отправной точкой.С помощью метода из первой статьи можно получить первичную разметку, которую придётся перепроверить вручную для лучшего качества, но это будет проще, чем размечать все объекты с нуля. На основе последовательности действий из статьи можно дообучить не только представленную сеть, но и что-то более сложное.
На данный момент в открытом доступе лежит большое количество готовых реализаций архитектур от Google, Facebook, а также других компаний и университетов с предобученными весами, показывающими отличные результаты, а порой даже относящихся к State of the Art (SOTA). Для поиска подходящей архитектуры есть удобный сайт Papers with Code, где в открытом доступе на GitHub есть готовые реализации.
Напоследок — мем, который был одобрен нашей обученной сетью с вероятностью 85%.
Вероятности классов:
approved — 0.8528
not suitable — 0.0996
risked — 0.0475
Дообучаем готовую нейросеть для классификации данных
В прошлой статье мы научились классифицировать данные без разметки с помощью понижения размерности и методов кластеризации. По итогам получили первичную разметку данных и узнали, что это картинки. С...
habr.com