Большая часть информации в мире хранится в виде таблиц, которые можно найти в Интернете или в базах данных и документах. В таблицах может находиться всё что угодно, от технических характеристик потребительских товаров до финансовой статистики и данных экономического развития страны, спортивных результатов и многого другого. Для того, чтобы найти ответ, сейчас необходимо вручную просматривать эти таблицы или полагаться на специальную службу, которая дает ответы на конкретные вопросы (например, о спортивных результатах). Однако эта информация была бы намного более доступной и полезной, если бы ее можно было запрашивать на естественном языке.
Например, на следующем рисунке показана таблица с рядом вопросов, которые люди могут задать. Ответ на эти вопросы может быть найден в одной или нескольких ячейках таблицы («У какого рестлера было больше всего побед?» — «Which wrestler had the most number of reigns?»), или может потребоваться объединение нескольких ячеек таблицы («Сколько чемпионов мира имеют только одну победу?» — «*How many world champions are there with only one reign?»).
")
Таблица и вопросы с ожидаемыми ответами. Ответы можно выбрать напрямую из таблицы (#1, #4) или вычислить на основе данных таблицы (#2, #3).
Многие недавние подходы для этой задачи применяют традиционный семантический парсинг, когда вопрос на естественном языке переводится в SQL-подобный запрос к базе данных, который затем исполняется для предоставления ответов. Например, вопрос: «Сколько чемпионов мира имеют только одну победу?» будет сопоставлен с таким запросом, как «select count(*) where column("No. of reigns") == 1;», а затем исполнен для получения ответа. Этот подход часто требует серьезной инженерии для генерации синтаксически и семантически корректных запросов, и его трудно масштабировать до произвольных вопросов, а не вопросов об очень конкретных таблицах (например, о спортивных результатах).
В статье «TAPAS: Weakly Supervised Table Parsing via Pre-training», принятой на ACL 2020, авторы используют другой подход, расширяющий архитектуру BERT для кодирования вопроса вместе с табличной структурой данных, в результате чего получается модель, которая затем может указывать прямо на ответ. Вместо создания модели, работающей только с одним типом таблицы, этот подход позволяет создавать модели, применимые к таблицам из широкого диапазона доменов. Авторы показали, что после предварительного обучения на миллионах таблиц Википедии модель демонстрирует конкурентоспособную точность (accuracy) на трех наборах данных академических таблиц с ответами на вопросы (QA). Кроме того, чтобы способствовать более интересным исследованиям в этой области, авторы предоставили открытый исходный код для обучения и тестирования моделей, а также сами модели, предварительно обученные на таблицах Википедии, в своем репозитории на GitHub.
Чтобы обработать такой вопрос, как «Среднее время пребывания в титуле чемпиона для двух лучших рестлеров?», модель совместно кодирует вопрос, а также содержимое таблицы строка за строкой, используя модель BERT, расширенную за счет специальных эмбеддингов для кодирования структуры таблицы.
Ключевым дополнением к модели BERT на основе архитектуры Трансформер являются дополнительные эмбеддинги, которые используются для кодирования структурированного входа. Эти эмбеддинги кодируют индекс столбца, индекс строки и специальный порядковый индекс, указывающий на порядок элементов в числовых столбцах. На следующем изображении показано, как все это объединяется на входе и подается в слои Трансформера. Также на картинке показано, как закодирован вопрос вместе с небольшой таблицей, показанной слева. Каждый токен ячейки имеет специальный эмбеддинг, который указывает его строку, столбец и порядковый индекс в столбце.

Входной слой BERT: каждый входной токен представлен как сумма эмбеддингов его слова, абсолютной позиции, сегмента (принадлежит ли он вопросу или таблице), столбца, строки и порядкового индекса (позиция, которую будет иметь ячейка, если столбец был отсортирован по числовым значениям).
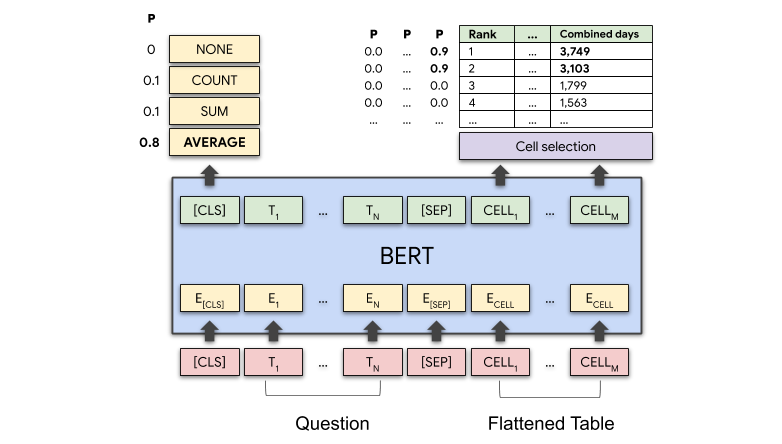
Модель имеет два выхода: 1) для каждой ячейки таблицы оценка указывает вероятность того, что эта ячейка будет частью ответа, и 2) операция агрегирования, которая указывает, какая операция (если она есть) применяется для получения окончательного ответа. На следующем рисунке показано, как для вопроса «Среднее время в качестве чемпиона для двух лучших борцов?» модель должна с высокой вероятностью выбрать первые две ячейки столбца «Объединенные дни» и операцию «СРЕДНЕЕ».

Схема модели: слой BERT кодирует как вопрос, так и таблицу. Модель выводит вероятность для каждой операции агрегирования и вероятность выбора для каждой ячейки таблицы. На вопрос «Среднее время в качестве чемпиона для двух лучших борцов?» операция СРЕДНИЙ и ячейки с числами 3,749 и 3,103 должны иметь высокую вероятность.
Используя метод, аналогичный тому, как BERT обучается на тексте, авторы предварительно обучили модель на 6.2 миллионах пар таблица-текст, извлеченных из английской Википедии. Во время предварительного обучения модель учится восстанавливать маскированные слова как в таблице, так и в тексте. Авторы обнаружили, что модель может сделать это с относительно высокой точностью (71.4% замаскированных токенов корректно восстанавливаются для невидимых во время обучения таблиц).
Во время тонкой настройки модель учится отвечать на вопросы из таблицы. Это достигается путем «строгого» и «мягкого» обучения с учителем (strong and weak supervision). В случае «строгого» обучения для данной таблицы и вопросов необходимо предоставить ячейки и операцию агрегирования для выбора (например, сумма или количество), что является достаточно трудоемким процессом. Чаще всего модели обучаются с помощью «мягкого» обучения, когда дается только правильный ответ (например, 3426 на вопрос в приведенном выше примере). В этом случае модель пытается найти операцию агрегирования и ячейки, которые дают ответ, близкий к правильному. Это делается путем вычисления ожидания по всем возможным решениям агрегирования и сравнения его с истинным результатом. Сценарий «мягкого» обучения выгоден, потому что он позволяет неспециалистам предоставлять данные, необходимые для обучения модели, и занимает меньше времени, чем «строгое» обучение.
Авторы применили свою модель к трем наборам данных — SQA, WikiTableQuestions (WTQ) и WikiSQL — и сравнили ее результаты с тремя самыми современными моделями (state-of-the-art, SOTA) для анализа табличных данных. Модели сравнения включали Min et al (2019) для WikiSQL, Wang et al. (2019) для WTQ и предыдущие работы самих авторов для SQA (Mueller et al., 2019). Для всех наборов данных публикуются метрики точности (accuracy) на тестовых наборах для модели «мягкого» обучения. Для SQA и WIkiSQL использовалась базовая модель, предварительно обученная на Википедии, а для WTQ было решено предварительно дообучить модель на данных SQA. Лучшие модели авторов превосходят предыдущую SOTA для SQA более чем на 12 баллов, предыдущую SOTA для WTQ более чем на 4 балла и работают аналогично лучшей опубликованной модели на WikiSQL.

Метрика точности (accuracy) ответов для «мягкого» обучения на трех академических наборах данных TableQA.
 habr.com
habr.com
Например, на следующем рисунке показана таблица с рядом вопросов, которые люди могут задать. Ответ на эти вопросы может быть найден в одной или нескольких ячейках таблицы («У какого рестлера было больше всего побед?» — «Which wrestler had the most number of reigns?»), или может потребоваться объединение нескольких ячеек таблицы («Сколько чемпионов мира имеют только одну победу?» — «*How many world champions are there with only one reign?»).
Таблица и вопросы с ожидаемыми ответами. Ответы можно выбрать напрямую из таблицы (#1, #4) или вычислить на основе данных таблицы (#2, #3).
Многие недавние подходы для этой задачи применяют традиционный семантический парсинг, когда вопрос на естественном языке переводится в SQL-подобный запрос к базе данных, который затем исполняется для предоставления ответов. Например, вопрос: «Сколько чемпионов мира имеют только одну победу?» будет сопоставлен с таким запросом, как «select count(*) where column("No. of reigns") == 1;», а затем исполнен для получения ответа. Этот подход часто требует серьезной инженерии для генерации синтаксически и семантически корректных запросов, и его трудно масштабировать до произвольных вопросов, а не вопросов об очень конкретных таблицах (например, о спортивных результатах).
В статье «TAPAS: Weakly Supervised Table Parsing via Pre-training», принятой на ACL 2020, авторы используют другой подход, расширяющий архитектуру BERT для кодирования вопроса вместе с табличной структурой данных, в результате чего получается модель, которая затем может указывать прямо на ответ. Вместо создания модели, работающей только с одним типом таблицы, этот подход позволяет создавать модели, применимые к таблицам из широкого диапазона доменов. Авторы показали, что после предварительного обучения на миллионах таблиц Википедии модель демонстрирует конкурентоспособную точность (accuracy) на трех наборах данных академических таблиц с ответами на вопросы (QA). Кроме того, чтобы способствовать более интересным исследованиям в этой области, авторы предоставили открытый исходный код для обучения и тестирования моделей, а также сами модели, предварительно обученные на таблицах Википедии, в своем репозитории на GitHub.
Как обработать вопрос
Чтобы обработать такой вопрос, как «Среднее время пребывания в титуле чемпиона для двух лучших рестлеров?», модель совместно кодирует вопрос, а также содержимое таблицы строка за строкой, используя модель BERT, расширенную за счет специальных эмбеддингов для кодирования структуры таблицы.
Ключевым дополнением к модели BERT на основе архитектуры Трансформер являются дополнительные эмбеддинги, которые используются для кодирования структурированного входа. Эти эмбеддинги кодируют индекс столбца, индекс строки и специальный порядковый индекс, указывающий на порядок элементов в числовых столбцах. На следующем изображении показано, как все это объединяется на входе и подается в слои Трансформера. Также на картинке показано, как закодирован вопрос вместе с небольшой таблицей, показанной слева. Каждый токен ячейки имеет специальный эмбеддинг, который указывает его строку, столбец и порядковый индекс в столбце.
Входной слой BERT: каждый входной токен представлен как сумма эмбеддингов его слова, абсолютной позиции, сегмента (принадлежит ли он вопросу или таблице), столбца, строки и порядкового индекса (позиция, которую будет иметь ячейка, если столбец был отсортирован по числовым значениям).
Модель имеет два выхода: 1) для каждой ячейки таблицы оценка указывает вероятность того, что эта ячейка будет частью ответа, и 2) операция агрегирования, которая указывает, какая операция (если она есть) применяется для получения окончательного ответа. На следующем рисунке показано, как для вопроса «Среднее время в качестве чемпиона для двух лучших борцов?» модель должна с высокой вероятностью выбрать первые две ячейки столбца «Объединенные дни» и операцию «СРЕДНЕЕ».
Схема модели: слой BERT кодирует как вопрос, так и таблицу. Модель выводит вероятность для каждой операции агрегирования и вероятность выбора для каждой ячейки таблицы. На вопрос «Среднее время в качестве чемпиона для двух лучших борцов?» операция СРЕДНИЙ и ячейки с числами 3,749 и 3,103 должны иметь высокую вероятность.
Предварительное обучение
Используя метод, аналогичный тому, как BERT обучается на тексте, авторы предварительно обучили модель на 6.2 миллионах пар таблица-текст, извлеченных из английской Википедии. Во время предварительного обучения модель учится восстанавливать маскированные слова как в таблице, так и в тексте. Авторы обнаружили, что модель может сделать это с относительно высокой точностью (71.4% замаскированных токенов корректно восстанавливаются для невидимых во время обучения таблиц).
Учимся только на ответах
Во время тонкой настройки модель учится отвечать на вопросы из таблицы. Это достигается путем «строгого» и «мягкого» обучения с учителем (strong and weak supervision). В случае «строгого» обучения для данной таблицы и вопросов необходимо предоставить ячейки и операцию агрегирования для выбора (например, сумма или количество), что является достаточно трудоемким процессом. Чаще всего модели обучаются с помощью «мягкого» обучения, когда дается только правильный ответ (например, 3426 на вопрос в приведенном выше примере). В этом случае модель пытается найти операцию агрегирования и ячейки, которые дают ответ, близкий к правильному. Это делается путем вычисления ожидания по всем возможным решениям агрегирования и сравнения его с истинным результатом. Сценарий «мягкого» обучения выгоден, потому что он позволяет неспециалистам предоставлять данные, необходимые для обучения модели, и занимает меньше времени, чем «строгое» обучение.
Полученные результаты
Авторы применили свою модель к трем наборам данных — SQA, WikiTableQuestions (WTQ) и WikiSQL — и сравнили ее результаты с тремя самыми современными моделями (state-of-the-art, SOTA) для анализа табличных данных. Модели сравнения включали Min et al (2019) для WikiSQL, Wang et al. (2019) для WTQ и предыдущие работы самих авторов для SQA (Mueller et al., 2019). Для всех наборов данных публикуются метрики точности (accuracy) на тестовых наборах для модели «мягкого» обучения. Для SQA и WIkiSQL использовалась базовая модель, предварительно обученная на Википедии, а для WTQ было решено предварительно дообучить модель на данных SQA. Лучшие модели авторов превосходят предыдущую SOTA для SQA более чем на 12 баллов, предыдущую SOTA для WTQ более чем на 4 балла и работают аналогично лучшей опубликованной модели на WikiSQL.
Метрика точности (accuracy) ответов для «мягкого» обучения на трех академических наборах данных TableQA.
Использование нейронных сетей для поиска ответов в таблицах
Большая часть информации в мире хранится в виде таблиц, которые можно найти в Интернете или в базах данных и документах. В таблицах может находиться всё что угодно, от технических характеристик...
habr.com