Что была за задача и чего мы хотели достичь
Всем привет! Меня зовут Даниил, и мы в Just AI разрабатываем платформу для создания различных чат-ботов. И для того, чтобы максимально упростить этот процесс, а именно процесс написания сценария работы бота, мы имеем свой собственный DSL.С его помощью можно описать поведение вашего бота, а при помощи javascript’а наполнить бота различной кастомной логикой. Разработчики ботов на платформе используют для этого нашу web IDE, которая поддерживает этот DSL.
Сценарий для бота может состоять из большого количества файлов, в которых хочется ориентироваться и искать интересующую информацию.
Давайте пару слов скажу про то, а какой поиск мы хотели получить по итогу, когда делали его? Проще говоря, такой же, как и в любой IDE, к которой мы привыкли. Чтобы можно было искать не только по частичному совпадению, но так же и по regex, и по полному совпадению слова, а так же как с учетом регистра, так и без.
На самом деле, именно то, что показано на изображении ниже:
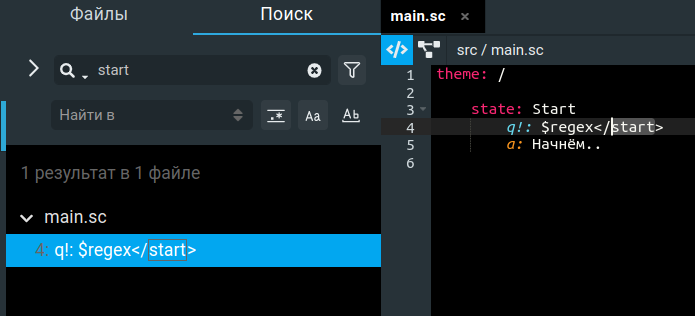
Что будет в статье, а чего не будет
В этой статье мы рассмотрим наш путь в построении индекса в Elasticsearch. Вам будет куда проще читать, если у вас уже есть понимание, что это за зверь такой.Будет описание нескольких концепций этого поискового движка, но эту статью точно нельзя назвать туториалом по работе с Elasticsearch. Это наш опыт формирования структуры индекса для поиска в файлах с кодом.
Почему Elasticsearch?
Первый вопрос, на который нужно ответить, это “почему Elasticsearch?”. И ответ очень прозаичный. У нас в команде на тот момент не было опыта работы с поисковыми движками, поэтому было разумно и очевидно выбрать самый популярный из всех. Плюс к этому у нас также был опыт у команды эксплуатации по работе с Elasticsearch в Graylog. Почти все слышали про этот движок для поиска, он используется для систем поиска по логам, о нем существует огромное количество статей и различных примеров и достаточно неплохая документация. Вот так выбор и пал на него.Как мы храним наши файлы
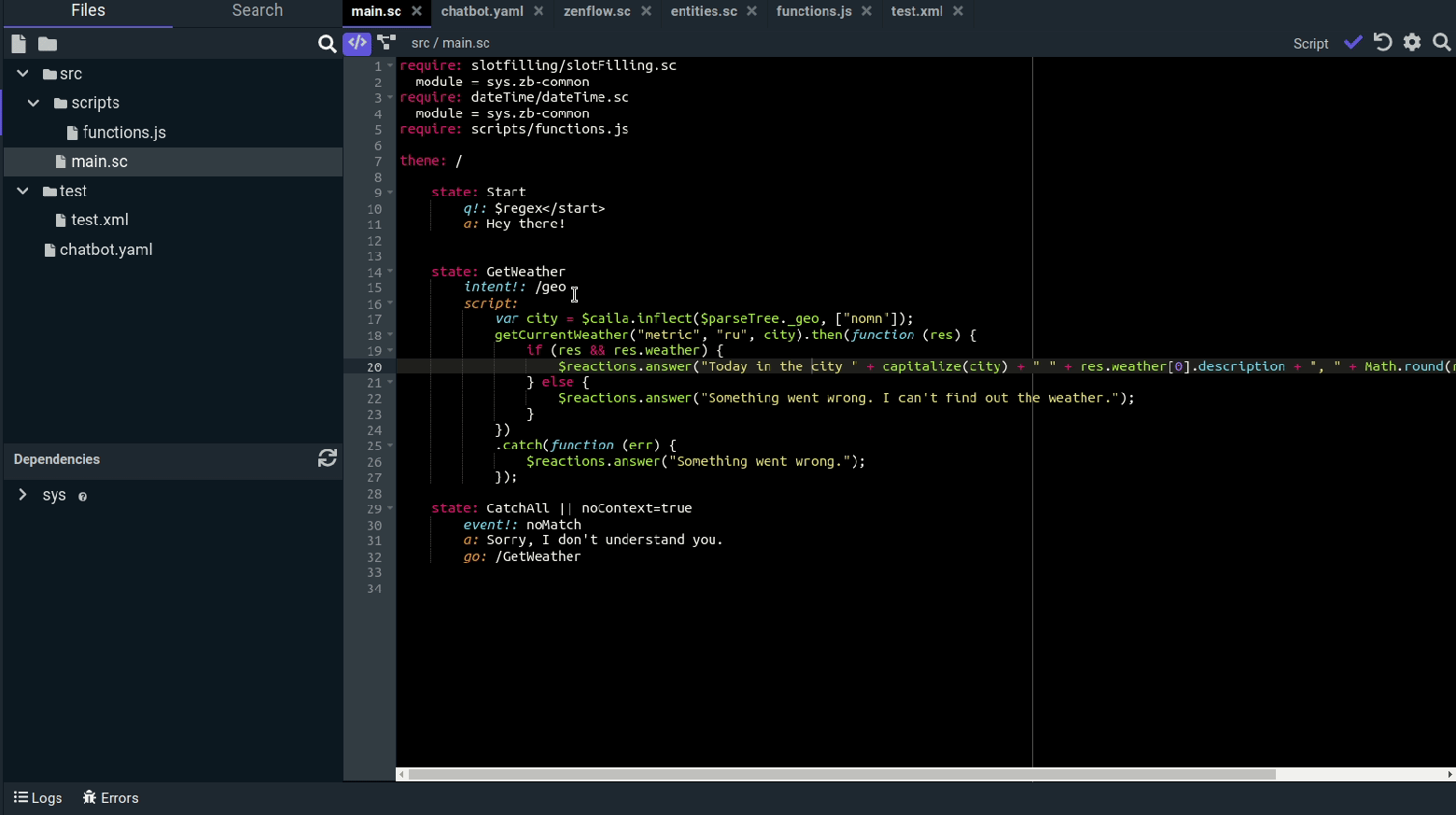
Как уже было описано выше, то, над чем мы хотим прикрутить наш поиск - это файлы с кодом. Поэтому давайте сперва поподробнее посмотрим на наши исходные файлы. Данные мы храним в MongoDB, и каждый отдельный файл хранится в виде одного отдельного документа в коллекции.Давайте посмотрим на пример с кодом, чтобы стало более наглядно:
theme: /
state: Start
q!: $regex</start>
a: Let's start.
state: Hello
intent!: /hello
a: Hello hello
state: Bye
intent!: /bye
a: Bye bye
state: NoMatch
event!: noMatch
a: I do not understand. You said: {{$request.query}}
Вот такой файл хранится в MongoDВ в следующей структуре:
{
"fileName": String,
"content": BinData
}
И конкретный пример можно представить как:
{
"fileName": "main.sc",
"content":"ewogICAgInByb2plY3QiO...0KICAgIF0KfQ=="
}
Теперь понятно, что мы ищем и среди чего мы ищем.
Но теперь встает главный вопрос этой статьи... А нужно ли нам вообще как-то преобразовывать текущую структуру файла для поискового индекса и если да, то как?
Как переводить наши данные в Elasticsearch
Для миграции данных в Elasticsearch есть различные инструменты. Есть, например, многим известный Logstash, который позволяет асинхронно по заданной конфигурации мигрировать ваши данные из различных источников в Elasticsearch. Используя этот инструмент можно задавать различные настройки фильтрации и трансформации данных.Плюсы миграции через Logstash:
- известный протестированный временем продукт со стороны нагрузки, устойчивости и задержек
- нам нужно лишь написать код конфигурации, а не писать самостоятельно весь код бизнес-логики
- внешний компонент, который можно независимо масштабировать
- не очевидно, насколько сложный код трансформации можно написать
- вынесение логики трансформации от основной логики поиска и работы с файлами плохо влияет на общую картину того, как работает сервис
В связи с чем мы решили выполнять трансформацию в коде нашего приложения и так же контролировать миграцию из кода приложения самостоятельно.
Первый вариант индекса
Учитывая наши условия, что нам нужно находить расположение найденной строки, ее номер в файле, то можно строить индекс двумя способами. Первый: каждый документ - это одна отдельная строка. Т.е. каждый документ маленький и известного размера. Второй вариант: когда у нас каждый документ так же как и в MongoDB - это целый файл, но строки уже разбиты и вложены в список с указанием номера строки.Небольшое отступление к основам, почему именно так. Elasticsearch - это поисковый движок, основанный на обратном индексе. Другими словами, если поисковая строка сматчилась с документом, то он возвращает документ целиком и все. В связи с чем нам и нужно хранить дополнительную meta информацию, чтобы вместе с документом нам вернулись все необходимые данные.
Поскольку в MongoDB мы храним файл целиком в одном документе, то и в Elasticsearch решили первым шагом хранить все данные в рамках одного документа. Также это было сделано с мыслью, что таким образом весь индекс целиком будет занимать меньше памяти, чем если бы каждый документ представлял из себя отдельную строку.
Описать схему Elasticsearch в этом случаи можно следующим образом:
{
"files_index": {
"mappings": {
"properties": {
"fileName": {
"type": "keyword"
},
"lines": {
"type": "nested",
"properties": {
"line": {
"type": "text",
"analyzer": "ngram_analyzer"
},
"lineNumber": {
"type": "integer"
}
}
}
}
}
}
}
Тут самым важным является поле lines, которое имеет тип nested. Про этот тип данных в Elasticsearch можно найти много различных статей в интернете, где большинство говорит о том, что “старайтесь не использовать этот тип данных” или “не создавайте большие nested поля”. Штош, мы нарушили оба правила...
На конкретном примере с данными, документ индекса выглядит следующим образом:
{
"fileName": "main.sc",
"lines": [
{"line": "require: slotfilling", "lineNumber": 1},
...
{"line": " a: I do not understand. You said: {{$request.query}}", "lineNumber": 19}
]
}
И оно работало!
Но... всегда есть “но”.
Обновление документов в индексе может быть достаточно частой операцией, и поскольку документ в индексе получился большой, то при параллельных запросах в Elasticsearch на обновление, большое количество запросов попросту падало по таймауту в 30с.
Похоже это и оказалась та проблема, о которой предупреждали в различных статьях, и ее нужно было как-то решать.
Делаем индекс меньше
Поскольку вариант с целым файлом на один документ не взлетел, значит, надо пробовать второй вариант, где у нас один документ - это одна строка исходного файла.Теперь наша структура индекса выглядит так:
{
"files_index": {
"mappings": {
"properties": {
"fileName": {
"type": "keyword"
},
"line": {
"type": "text",
"analyzer": "ngram_analyzer"
},
"lineNumber": {
"type": "integer"
}
}
}
}
}
А документ теперь выглядит так:
{
"fileName": "main.sc",
{
"line": "require: slotfilling",
"lineNumber": 1
}
}
Таким образом эластик стал куда быстрее обновлять индексы, смог по максимуму параллелить индексацию, поскольку теперь обновление каждой строки шло в параллель отдельным запросом.
И то, что нас пугало вначале, что индекс будет весить больше, не оправдалось. Размер практически не поменялся.
Мы описали только структуру индекса, мы поняли, как сформировать индекс, чтобы его в принципе можно было использовать под наши нужды и обновлять без ошибок.
Но мы совсем не затронули вопрос, а как вообще будет выглядеть поисковый запрос?
Поиск по умолчанию
Давайте рассмотрим вот такой пример:У вас есть документ в elasticsearch - “hello world”.
Он с настройками по умолчанию, и мы хотим найти его, вбивая поисковую строку “hel”. Вполне себе живой пример, когда мы что-то ищем в нашей IDE, не правда ли?
Так вот в таком случае Elasticsearch не выдаст вам то, что вы ищете.
Все дело в таких штуках, как analyzer и tokenizer. С их помощью происходит предобработка как поисковой строки, так и данных индекса. И если они хранятся неправильно, то match не произойдет и нужный вам документ не будет выдан.
А по умолчанию они разбивают текст по пробелам и по спецсимволам, поэтому просто по подстроке, например, wor слова world, ничего найдено не будет, а вот по подстроке world текста “hello world” будет.
Как же нам искать по части слова?
Так мы и познакомились с ngram в Elasticsearch. А именно вот эта статья от gitlab’а придала нам уверенности, что это именно то, что нам нужно.Ngram - это ngram analyzer в терминах Elasticsearch. Его можно указать в mappings для поля.
Пример:
Сохраняем в индекс строку “hello world”. Допустим в настройках ngram analyzer’а у нас указано, что min=3, а max=5.
Это значит, что текст разбивается на части по 3, 4 и 5 символов.
hel, ell, llo, lo , o w, ..., rld, ..., o wor, worl, world
И если входная строка совпадет с одной из этих подстрок, то документ “hello world” будет выдан.
Так мы и сделали. Выше вы могли заметить, что мы используем ngran analyzer для поля line.
"line": {
"type": "text",
"analyzer": "ngram_analyzer"
}
Но... Тут тоже есть свое “но”.
Такой вариант работает хорошо, все необходимое находит и находит быстро. Единственная проблема, что таким образом мы “раздуваем” размер нашего индекса очень существенно.
Мы стали искать способ решения и этой проблемы и нашли его.
Wildcard
Wildcard, как понятно из названия - это возможность указывать подобные конструкции: helВ таком случае поиск происходит куда быстрее, чем при regexp, и необходимый документ “hello world” будет выдан.
Все это работает благодаря особому объединению логики ngram и regexp, что позволяет, сохраняя скорость поиска, оптимизировать занимаемое индексом место.
Данный analyzer можно указать как для поля индекса, так и для предобработки поисковой строки.
Наш финальный вариант индекса выглядит следующим образом:
{
"files_index": {
"mappings": {
"properties": {
"fileName": {
"type": "keyword"
},
"line": {
"type": "wildcard"
},
"lineNumber": {
"type": "integer"
}
}
}
}
}
После перехода от ngramm analyzer к wildcard размер индекса стал меньше ориентировочно в 4-5 раза!
Конечно, и здесь можно выделить свое “но”. Поскольку у нас достаточно небольшие размеры индекса, это порядка 10gb, то у нас все работает очень даже шустро. Почти все запросы не превышают 0,1c. Но можно предположить, что при действительно больших объемах данных на сотни гигабайтов или терабайтов, такой вариант может существенно уступать по скорости варианту с ngrams.Мы проводили тесты не на всех наших данных в продакшене, а во время исследования и разработки данной задачи. Было сгенерировано определенное количество данных, порядка 1 гигабайта, чтобы можно было легко понять изменения размера индекса. Сперва выполняли над индексом POST /<index>/_forcemerge. И после чего замеряли размер через GET /_cat/indices/<index>
Заключение
- В этой статье вы прошли вместе с нами путь от совершенного незнания, что представляет собой Elasticsearch и как с его помощью решать свои задачи, до момента, когда уже понятны детали и нюансы и на что стоит обращать внимание при решении своей конкретной задачи.
- Надеемся, эта статья оказалась полезной и кто-нибудь сможет сэкономить значительное количество времени и усилий. Также надеюсь, что статья покажет, что Elasticsearch это не черный ящик, который по умолчанию найдет то, что вам нужно. А скорее это некий конструктор Лего, к которому нужно внимательно читать инструкцию.

Как мы индекс в Elasticsearch строили
Что была за задача и чего мы хотели достичь Всем привет! Меня зовут Даниил, и мы в Just AI разрабатываем платформу для создания различных чат-ботов. И для того, чтобы максимально упростить этот...
 habr.com
habr.com