Я - студент университета, знаком с машинным обучением в рамках пройденного курса, есть интерес к современным кластерным технологиям, конкретно - к Apache Ignite. Возникла идея копнуть глубже, то есть немного разобраться с относительно не популярной библиотекой Apache Ignite Machine Learning. Под катом — история о том, как мне удалось запустить пример OneVsRestClassificationExample, сначала пример сам по себе, а потом его же на датасете MNIST database of handwritten digits. Ну и еще немного про производительность кластера из одного и двух домашних ПК. Весь код доступен в репозитории HandwrittenSVM.
Но что-то идет не так.
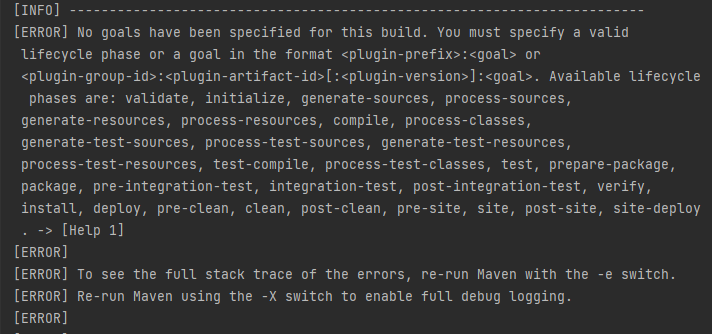
С Maven и IntelliJ IDEA работаю недавно, как справляться с подобными ошибками - непонятно. Начинаю гуглить в поисках решения или хотя бы товарищей по несчастью — попадается на глаза статья Как быстро загрузить большую таблицу в Apache Ignite через Key-Value API. Отличает её от большинства статей то, что в её тексте есть ссылка на маленький репозиторий с кодом. Пробую клонировать/открыть в IntelliJ Idea, скомпилировать/выполнить, все запускается и работает, как обещано. Почему-то автор использует библиотеки из GRIDGAIN Community Edition - заменяю в файле pom.xml на то же самое из APACHE Ignite. Продолжающееся студенчество вырабатывает у меня устойчивую приязнь к Open Source-продуктам. Опять работает, вот с этого можно стартовать.
Делаю по образу и подобию свой собственный пустой проект, копирую туда пример OneVsRestClassificationExample, еще некоторые файлы из репозитория Apache Ignite и нужные зависимости в pom.xml. Оказалось, пример использует крошечный датасет 1987 года GLASS_IDENTIFICATION размером всего в 116 строк.Классификация выполняется быстро, в кластере с одним узлом на моем домашнем ПК занимает буквально пару секунд.
В статье есть отсылки к питоновскому пакету scikit-learn, поиск по этой теме приводит к туториалу Image Classification with MNIST Dataset. Туториал рассказывает, как с помощью scikit-learn загрузить датасет mnist_784, нарисовать на экране загруженное, обучить сеть на наборе из 60 тысяч рисунков и протестировать качество обучения еще на 10 тысячах.
Смотрю дальше, оказывается, что на kaggle.com выложен этот же датасет в удобном для обработки виде. Загружаю два CSV-файла: тестовый mnist_test.csv(17.46 MB, 10 тысяч рисунков) и обучающий mnist_train.csv(104.56 MB, 60 тысяч рисунков). Первая колонка в файле — метка класса изображения, далее следует рисунок размером 28 х 28 (то есть строка из 784 чисел от 0 до 255). Датасет содержит рукописные изображения арабских цифр, поэтому метка класса — число от 0 до 9.
MNIST_TRAIN_DATASET("sampleData/mnist_train.csv", true, ",")
Failed to find class with given class loader for unmarshalling (make sure same
versions of all classes are available on all nodes or enable peer-class-loading)
[clsLdr=sun.misc.Launcher$AppClassLoader@55f96302, cls=org.apache.ignite.ml.
dataset.impl.cache.util.DatasetAffinityFunctionWrapper]
Как мне победить этот DatasetAffinityFunctionWrapper, если никаких собственных классов я не создавал и peerClassLoadingEnabled включал? Спрашиваю в форуме Apache Ignite в Telegram, оперативно получаю ответ (спасибо за подсказку, @Thriftwy). Оказывается, чтобы запустить узел с поддержкой ML, надо скопировать папку optional\ignite-ml в папку libs. Теперь узел при старте видит плагин
[09:16:02] Configured plugins:
[09:16:02] ^-- ml-inference-plugin 1.0.0
[09:16:02] ^-- null
Мой jar должен загрузить в кластер датасет `mnist_train.csv` из 60 тысяч изображений размером 104 МБ. Смотрю в диспетчере задач расход памяти узла данных во время того, как работает мой jar - впечатляет.

Загрузка не заканчивается - всё вылетает с ошибкой нехватки памяти. На моей машине установлены скромные 8 Гб оперативки,один узел не справляется с объёмами.

Приходится делить датасет на части размером 5, 8, 10, 12 и 15 тысяч записей. С датасетом в 15К компьютер тоже не справляется, те же ошибки, что и на полном датасете MNIST_TRAIN. Придется работать от 5 до 12.
Смотрю в код своего клиентского jar-приложения и вижу, что весь процесс делится на четыре задачи, из которых интересных две: fillCacheWith - заполнение кэша, trainer.fit - обучение сети. Фиксирую время System.currentTimeMillis() до и после вызова, перевожу в секунды и печатаю на экране. Запускаю на одном хосте один узел кластера и свой jar, фиксирую время работы для разных датасетов.
В распоряжении у меня есть ещё один компьютер, ровно с такими же скромными 8 Гб оперативной памяти. Соединяю две машины в локальную сеть, получаю кластер из двух узлов данных на двух хостах. Снова фиксирую время загрузки/обучения сети, запуская свой jar.
 Итоговая таблица
Итоговая таблица
Если кластер состоит из двух физических узлов, то загрузка данных туда происходит по сети и увеличение времени работы при добавлении узла объяснимо.
Разумно ожидать, что удвоение ресурсов кластера по памяти и ЦПУ увеличит возможности кластера, но этого как-то не видно. Если пример с 15К записей не помещается в память одного хоста, но в память двух он уже должен помещаться (она в два раза больше!). Но у меня не получилось. Если я увеличил ЦПУ, то обучение должно быть быстрее для тех данных, что помещаются в память. Но большой разницы опять нет.
Вполне возможно, я что-то сделал не так. Кажется в документации не хватает примера/туториала, демонстрирующего ускорение расчетов при увеличении ресурсов кластера.

 habr.com
habr.com
История вопроса
Документация Apache Ignite описывает технологию как "distributed supercomputer for low-latency calculations, .. and machine learning". Захотелось это проверить — как кластер будет вести себя на относительно крупном датасете, особенно если в кластере несколько узлов. Изначально было интересно поработать с изображениями. Конкретно - с нейросетью, способной относить неизвестное изображение к одному из заранее известных классов. Выбираю один из классических алгоритмов классификации — алгоритм SVM (Solving Vector Machine).Начинаю работу
Изучаю документацию Apache Ignite ML, нахожу там раздел multiclass classification, там говорится про мою задачу на примере Glass dataset из UCI Machine Learning Repository. В репозитории Apache Ignite нахожу готовый код примера OneVsRestClassificationExample. Остается клонировать и запустить. Раздел Getting Started обещает быстрый старт, ну я и пробую: клонирую, открываю, компилирую.Но что-то идет не так.
С Maven и IntelliJ IDEA работаю недавно, как справляться с подобными ошибками - непонятно. Начинаю гуглить в поисках решения или хотя бы товарищей по несчастью — попадается на глаза статья Как быстро загрузить большую таблицу в Apache Ignite через Key-Value API. Отличает её от большинства статей то, что в её тексте есть ссылка на маленький репозиторий с кодом. Пробую клонировать/открыть в IntelliJ Idea, скомпилировать/выполнить, все запускается и работает, как обещано. Почему-то автор использует библиотеки из GRIDGAIN Community Edition - заменяю в файле pom.xml на то же самое из APACHE Ignite. Продолжающееся студенчество вырабатывает у меня устойчивую приязнь к Open Source-продуктам. Опять работает, вот с этого можно стартовать.
Делаю по образу и подобию свой собственный пустой проект, копирую туда пример OneVsRestClassificationExample, еще некоторые файлы из репозитория Apache Ignite и нужные зависимости в pom.xml. Оказалось, пример использует крошечный датасет 1987 года GLASS_IDENTIFICATION размером всего в 116 строк.Классификация выполняется быстро, в кластере с одним узлом на моем домашнем ПК занимает буквально пару секунд.
Как я искал другой датасет
Хочется протестировать алгоритм на более крупном датасете. Встречаю статью Алексея Зиновьева под названием Apache Ignite ML: origins and development.В статье есть отсылки к питоновскому пакету scikit-learn, поиск по этой теме приводит к туториалу Image Classification with MNIST Dataset. Туториал рассказывает, как с помощью scikit-learn загрузить датасет mnist_784, нарисовать на экране загруженное, обучить сеть на наборе из 60 тысяч рисунков и протестировать качество обучения еще на 10 тысячах.
Смотрю дальше, оказывается, что на kaggle.com выложен этот же датасет в удобном для обработки виде. Загружаю два CSV-файла: тестовый mnist_test.csv(17.46 MB, 10 тысяч рисунков) и обучающий mnist_train.csv(104.56 MB, 60 тысяч рисунков). Первая колонка в файле — метка класса изображения, далее следует рисунок размером 28 х 28 (то есть строка из 784 чисел от 0 до 255). Датасет содержит рукописные изображения арабских цифр, поэтому метка класса — число от 0 до 9.
Как заменить датасет
Задача по замене оказалась несложной — в примере OneVsRestClassificationExample используется enum MLSandboxDatasets, указывающий на расположение csv-файла в проекте. Там даже есть параметр, указывающий на наличие заголовка в файле; первая колонка файла — метка класса.Формат данных оказался тем же самым и добавление датасета свелось к добавлению строкиMNIST_TRAIN_DATASET("sampleData/mnist_train.csv", true, ",")
Запускаю и смотрю на время работы
Инструкция из Как быстро загрузить большую таблицу в Apache Ignite через Key-Value API, говорит о том, как запустить кластер Apache Ignite в минимально достаточной конфигурации. В конфиге узла данных config\default-config.xml выставляю в true параметр peerClassLoadingEnabled, указываю ip-адрес, запускаю узел данных. В конфиге своего приложения HandwrittenSVM.jar включаю клиентский режим: прописываю<property name="ClientMode" value="true"/>и тоже запускаю, все это в разных окнах одного Windows-хоста. Узел данных запускается ОК, но как только начинает работать jar, вылетает ошибка:Failed to find class with given class loader for unmarshalling (make sure same
versions of all classes are available on all nodes or enable peer-class-loading)
[clsLdr=sun.misc.Launcher$AppClassLoader@55f96302, cls=org.apache.ignite.ml.
dataset.impl.cache.util.DatasetAffinityFunctionWrapper]
Как мне победить этот DatasetAffinityFunctionWrapper, если никаких собственных классов я не создавал и peerClassLoadingEnabled включал? Спрашиваю в форуме Apache Ignite в Telegram, оперативно получаю ответ (спасибо за подсказку, @Thriftwy). Оказывается, чтобы запустить узел с поддержкой ML, надо скопировать папку optional\ignite-ml в папку libs. Теперь узел при старте видит плагин
[09:16:02] Configured plugins:
[09:16:02] ^-- ml-inference-plugin 1.0.0
[09:16:02] ^-- null
Мой jar должен загрузить в кластер датасет `mnist_train.csv` из 60 тысяч изображений размером 104 МБ. Смотрю в диспетчере задач расход памяти узла данных во время того, как работает мой jar - впечатляет.
Загрузка не заканчивается - всё вылетает с ошибкой нехватки памяти. На моей машине установлены скромные 8 Гб оперативки,один узел не справляется с объёмами.
Приходится делить датасет на части размером 5, 8, 10, 12 и 15 тысяч записей. С датасетом в 15К компьютер тоже не справляется, те же ошибки, что и на полном датасете MNIST_TRAIN. Придется работать от 5 до 12.
Смотрю в код своего клиентского jar-приложения и вижу, что весь процесс делится на четыре задачи, из которых интересных две: fillCacheWith - заполнение кэша, trainer.fit - обучение сети. Фиксирую время System.currentTimeMillis() до и после вызова, перевожу в секунды и печатаю на экране. Запускаю на одном хосте один узел кластера и свой jar, фиксирую время работы для разных датасетов.
В распоряжении у меня есть ещё один компьютер, ровно с такими же скромными 8 Гб оперативной памяти. Соединяю две машины в локальную сеть, получаю кластер из двух узлов данных на двух хостах. Снова фиксирую время загрузки/обучения сети, запуская свой jar.
Итоги
Итоги оказались не совсем такими, каких я ждал.Если кластер состоит из двух физических узлов, то загрузка данных туда происходит по сети и увеличение времени работы при добавлении узла объяснимо.
Разумно ожидать, что удвоение ресурсов кластера по памяти и ЦПУ увеличит возможности кластера, но этого как-то не видно. Если пример с 15К записей не помещается в память одного хоста, но в память двух он уже должен помещаться (она в два раза больше!). Но у меня не получилось. Если я увеличил ЦПУ, то обучение должно быть быстрее для тех данных, что помещаются в память. Но большой разницы опять нет.
Вполне возможно, я что-то сделал не так. Кажется в документации не хватает примера/туториала, демонстрирующего ускорение расчетов при увеличении ресурсов кластера.
Как я запускал классификацию изображений на домашнем кластере Apache Ignite ML
Я - студент университета, знаком с машинным обучением в рамках пройденного курса, есть интерес к современным кластерным технологиям, конкретно - к Apache Ignite. Возникла идея копнуть глубже, то есть...
habr.com