Kubernetes API Server вылетел с ошибкой (OOMKilled)
Прошло больше года с нашего [компании Pinterest] перехода на платформу Kubernetes. С тех пор мы разработали множество новых функций, гарантировали надёжность и масштабируемость платформы, а также накопили опыт и лучшие практики.
В целом, платформа Kubernetes всем понравилась. Согласно результатам опроса, три её главных преимущества — более простое управление вычислительными ресурсами, лучшая изоляция ресурсов и сбоев, а также более гибкое масштабирование.
К концу 2020 года мы запустили в кластерах Kubernetes более 35 тыс. подов на 2500 узлах для наших корпоративных пользователей, и это количество быстро растёт.
Итоги 2020 года вкратце
С внедрением Kubernetes увеличивается разнообразие и количество рабочих нагрузок. Поэтому платформа должна масштабироваться, ведь растут нагрузки на системы управления, планирования и размещения подов, а также распределения и освобождения узлов. По мере увеличения числа критически важных рабочих нагрузок люди ждут от платформы Kubernetes большей надёжности.Однако в начале 2020 года случился серьёзный сбой. В одном из кластеров внезапно выросло количество новых подов (примерно в три раза больше запланированного). Для удовлетворения спроса система автоматического масштабирования подняла 900 новых узлов. kube-apiserver начал тормозить и выдавать ошибки, а затем вылетел из-за нехватки ресурсов. Повторная попытка из Kubelets привела к семикратному скачку нагрузки на kube-apiserver. Всплеск записей привёл к тому, что хранилище etcd достигло предельного объёма данных и стало отклонять все запросы на запись, а платформа полностью отключилась в смысле управления рабочей нагрузкой. Для восстановления etcd мы выполнили ряд операций: сжатие старых версий, дефрагментацию и отключение аварийных оповещений. Кроме того, пришлось временно масштабировать мастера Kubernetes, где размещаются kube-apiserver и etcd, чтобы хватило ресурсов.
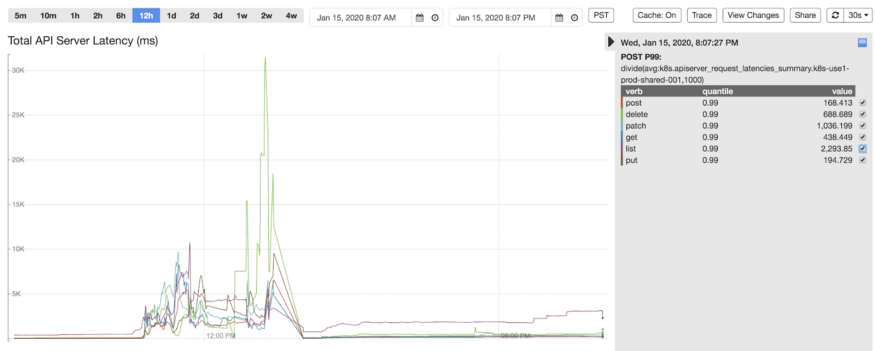
Рис. 1. Всплески задержки сервера Kubernetes API
Позже в 2020 году проявился баг в интеграции с kube-apiserver одного из наших компонентов, что привело к всплеску дорогостоящих запросов к kube-apiserver (перечисление всех модулей и подов). В итоге на мастер-узле не хватило ресурсов — и kube-apiserver ушёл в состояние OOMKilled. К счастью, проблемный компонент обнаружили и быстро откатили. Но во время инцидента производительность платформы пострадала от деградации, включая задержку выполнения рабочей нагрузки и задержку с выдачей статусов.
Рис. 2. Kubernetes API Server ушёл в состояние OOMKilled
Готовимся к масштабированию
Мы постоянно размышляли, как лучше обеспечить надёжность и контроль над платформой. Тем более когда некоторые инциденты хлёстко бьют по нашим слабым местам. Не имея огромного штата инженеров, а только скромную команду с ограниченными ресурсами, пришлось глубоко копать, чтобы понять коренные причины, выявить первоочередные меры и определить приоритеты по соотношению затрат и выгоды. Наша стратегия работы со сложной экосистемой Kubernetes — максимально использовать открытые инструменты и внести свой вклад в Open Source, но не отказываться от написания собственных внутренних компонентов.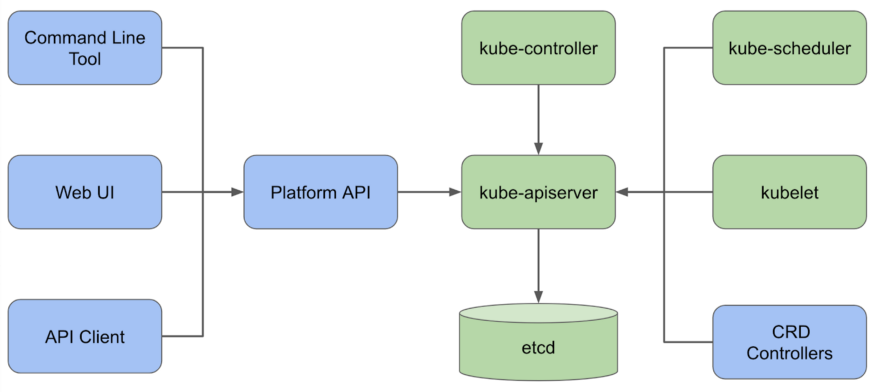
Архитектура платформы Kubernetes в компании Pinterest (синим показаны компоненты собственной разработки, зелёным — опенсорсные)
Управление
Соблюдение квот на ресурсы
В самом Kubernetes есть квоты ресурсов. Они гарантируют, что никто не запросит и не займёт неограниченный объём ресурсов: подов, CPU, памяти и т. д. Как упоминалось выше, всплеск генерации подов в одном из кластеров может перегрузить kube-apiserver и вызвать каскадный сбой. Вот почему для стабильности важно ограничить использование ресурсов в каждом пространстве имён (namespace) на кластере.Здесь мы столкнулись с рядом проблем. Оказалось, что принудительное применение квоты ресурсов в каждом пространстве имён неявно требует указания запросов и ограничений для всех подов и контейнеров. Мы это реализовали. На платформе Pinterest Kubernetes рабочие нагрузки в разных пространствах имён принадлежат разным командам для разных проектов, а пользователи платформы настраивают свою рабочую нагрузку с помощью Pinterest CRD (определения пользовательских ресурсов). В слой преобразования CRD мы добавили запросы ресурсов по умолчанию, а также лимиты для всех подов и контейнеров. Кроме того, на уровне проверки CRD мы отклоняем любую спецификацию подов без запросов на ресурсы и указанных лимитов.
Ещё одной задача — оптимально управлять квотами между командами и организациями. Чтобы безопасно активировать принудительное применение квот, мы смотрим на историческое использование ресурсов, добавляем 20% запаса поверх пикового значения и устанавливаем его в качестве начальной квоты для каждого проекта. Мы запустили cron для мониторинга квот и отправки предупреждений владельцам проектов, если использование ресурсов приближается к указанному пределу (предупреждения рассылаются в рабочие часы). Это побуждает владельцев лучше планировать мощности и заранее запрашивать изменения квот. Изменение проверяется вручную, а потом автоматически развёртывается.
Обеспечение клиентского доступа
На всех клиентов KubeAPI распространяются лучшие практики Kubernetes:Фреймворк контроллера
Фреймворк контроллера (оператора) предоставляет общий кэш для оптимизации операций чтения. Он использует архитектуру «информер-рефлектор-кэш». Информеры составляют список и наблюдают за интересующими объектами с сервера kube-apiserver. Рефлектор отражает изменения объекта в базовом кэше и распространяет наблюдаемые события на обработчики событий. Несколько компонентов внутри одного контроллера (оператора) могут регистрировать обработчики для событий onCreate, onUpdate и OnDelete из информеров и извлекать объекты из кэша, а не напрямую с kube-apiserver. Так уменьшается количество ненужных и избыточных вызовов.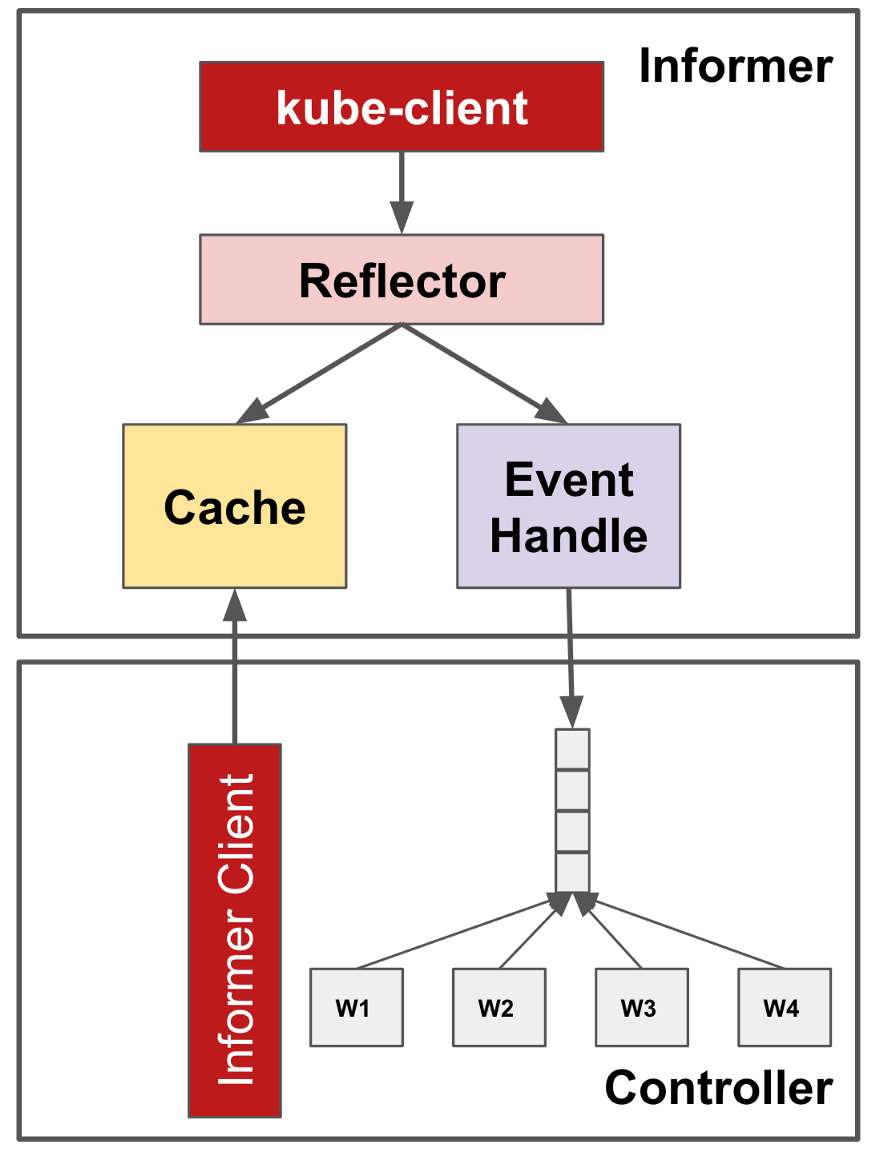
Рис. 4. Фреймворк контроллера Kubernetes
Ограничение полосы
Вызовы API обычно поступают из разных контроллеров и разных потоков. Kubernetes поставляет свой клиент API с ограничением количества запросов по алгоритму текущего (дырявого) ведра, с настройкой QPS (запросов в секунду) и всплесков. Вызовы API за пределами лимита подавляются, чтобы единственный контроллер не забил всю полосу kube-apiserver.Общий кэш
В дополнение к встроенному кэшу kube-apiserver, который поставляется вместе с фреймворком, мы добавили в API платформы ещё один слой с информером записи через кэш. Это сделано для того, чтобы предотвратить ненужные вызовы чтения, сильно бьющие по kube-apiserver. Повторное использование кэша на стороне сервера также позволило избежать использования толстых клиентов в коде приложения.Для доступа к kube-apiserver из приложений мы принудительно проводим все запросы через API, чтобы присвоить идентификаторы безопасности: так осуществляется контроль доступа и управление потоками. Для доступа к kube-apiserver из контроллеров рабочей нагрузки следует убедиться, что все контроллеры реализованы на платформе управления с ограничением полосы (количества запросов).
Устойчивость
Укрепление Kubelet
Одна из ключевых причин каскадного сбоя нашей плоскости управления Kubernetes — это устаревшая реализация рефлектора с неограниченным количеством повторных попыток при обработке ошибок. Такие недоработки могут стать критичными, особенно когда сервер API вылетает из памяти, что легко ведёт к синхронизации рефлекторов по всему кластеру.Этот вопрос мы очень тесно обсуждали с сообществом: были зарегистрированы соответствующие проблемы, затем обсуждались решения. В конце концов, пул-реквесты (1, 2) были рассмотрены и приняты. Идея в том, чтобы добавить экспоненциальный откат, используя логику повторений из рефлектора ListWatch с джиттером, чтобы kubelet и другие контроллеры не пытались долбить сервер запросами после перегрузки kube-apiserver и сбоя запросов. Это улучшение устойчивости полезно в целом, но мы нашли его особенно критичным на стороне kubelet по мере того, как растёт число узлов и подов в кластере Kubernetes.
Настройка параллельных запросов
Чем больше узлов под нашим управлением, тем быстрее создаются и удаляются рабочие нагрузки и тем больше вызовов API обрабатывает QPS-сервер. Сначала мы увеличили максимальные параметры одновременных вызовов API как для мутирующих, так и для немутирующих операций (то есть для операций с изменением настроек и без изменения настроек) на основе расчётных рабочих нагрузок. Эти два параметра обеспечивают, что количество обработанных вызовов API не превышает указанного числа и, следовательно, ограничивает использование CPU и памяти kube-apiserver.Внутри цепочки обработки запросов API каждый запрос в Kubernetes сначала проходит через группу фильтров. Именно здесь применяются лимиты. Если количество вызовов API превышает заданный порог, клиенту возвращается ответ «Cлишком много запросов» (429), чтобы инициировать правильные повторные попытки. В будущем мы планируем дополнительно изучить функции EventRateLimit с более тонким контролем допуска и обеспечить лучшее качество услуг.
Кэшировать больше историй
Watch-кэш или дежурный кэш — это механизм внутри kube-apiserver, который кэширует прошлые события каждого типа ресурса в кольцевом буфере, чтобы наилучшим образом обслуживать вызовы из определённой версии. Чем больше кэш, тем больше событий можно сохранить на сервере и тем больше вероятность беспрепятственного обслуживания потоков событий клиентами в случае разрыва соединения. Учитывая этот факт, мы также улучшили целевой размер оперативной памяти kube-apiserver, который в конце концов внутренне переносится в объём кэша на основе эвристики для обслуживания более надёжных потоков событий. В документации kube-apiserver более подробно описаны параметры настройки watch-кэша.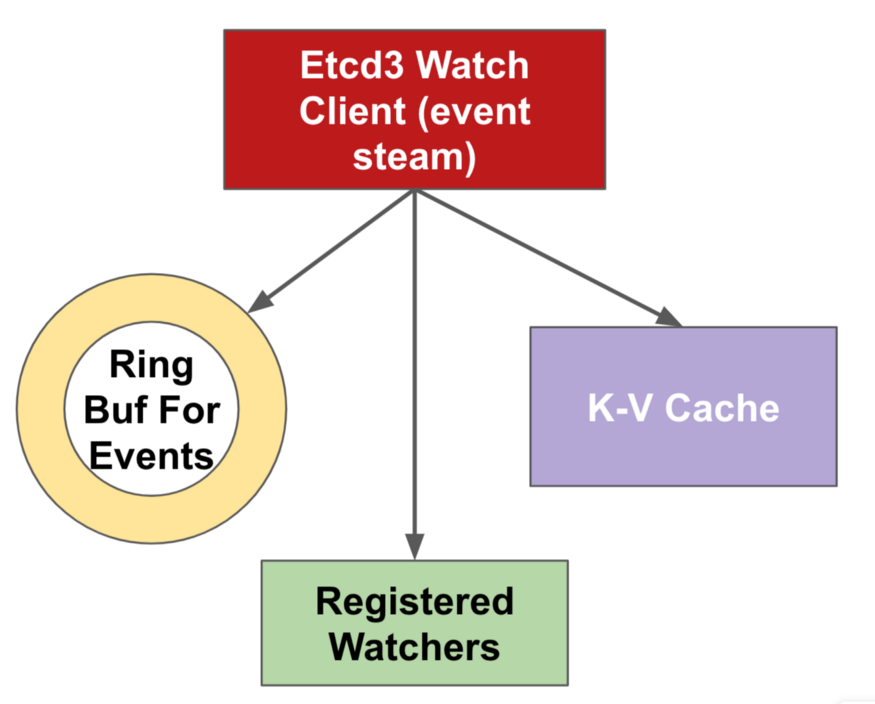
Рис. 5. Watch-кэш Kubernetes
Удобство эксплуатации
Наблюдаемость
Чтобы быстрее реагировать на инциденты и устранять их последствия, нужно чётко отслеживать плоскости управления Kubernetes. Задача найти баланс между полным покрытием всех возможных сбоев и приемлемым порогом чувствительности. Из существующих метрик Kubernetes мы сортируем и выбираем важные метрики для мониторинга и/или оповещений. Кроме того, используем kube-apiserver для более детального охвата областей, чтобы быстро найти первопричину любого сбоя. Наконец, настраиваем статистику оповещений и пороговые значения, чтобы уменьшить шум и ложные тревоги.На высоком уровне мы отслеживаем загрузку kube-apiserver, просматривая QPS и параллельные запросы, частоту ошибок и задержки запросов. Можно разбить трафик по типам ресурсов, по командам в запросах и соответствующим аккаунтам. Для дорогого трафика (как листинг) мы также измеряем полезную нагрузку запроса по количеству объектов и размеру байт, так как они могут легко перегрузить kube-apiserver даже с небольшим QPS. Наконец, отслеживаем некоторые важные показатели производительности сервера — количество запросов на обработку событий watch в etcd и количество отложенных событий обработки (delayed processing count).
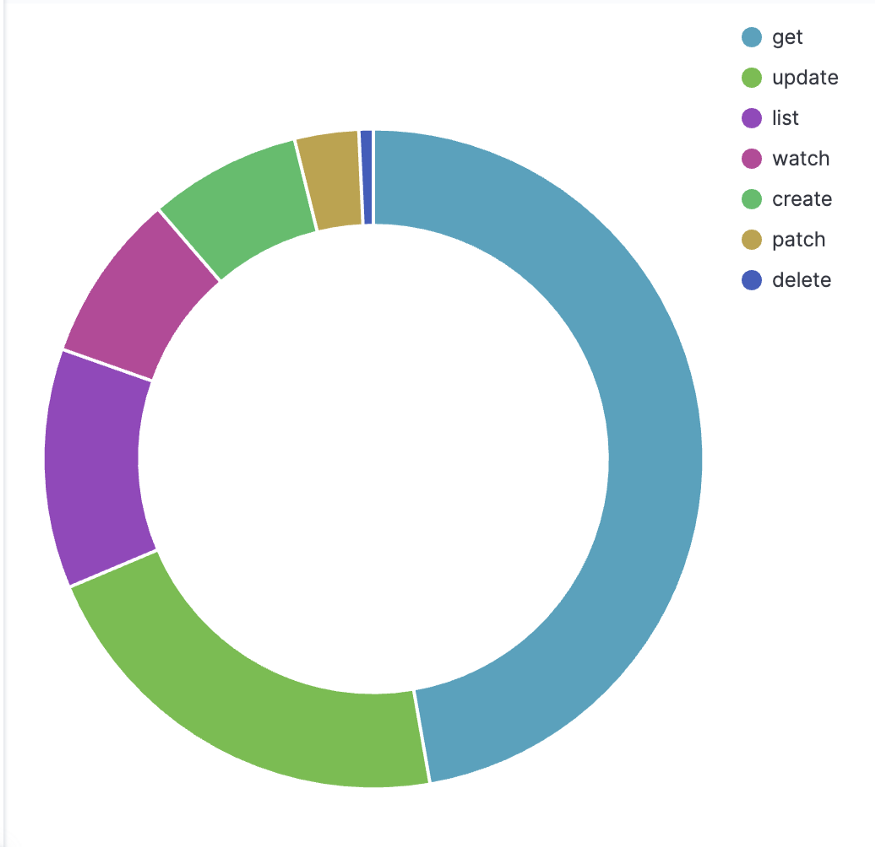
Рис. 6. Вызовы API Kubernetes по типу
Удобство отладки
Чтобы лучше понять производительность и потребление ресурсов контрольной плоскости, мы разработали инструмент для визуализации etcd с помощью библиотек boltdb и flamegraph. Результаты анализа хранилища данных дают представление об оптимизации использования платформы.
Рис. 7. Визуализации данных Etcd на один ключ
Кроме того, мы взяли профайлер языка Go pprof и визуализировали объём памяти кучи. Мы быстро выявили наиболее ресурсоёмкие ветви кода и шаблоны запросов, например, преобразование объектов ответа при вызовах ресурсов списка. В рамках расследования критического OOM-сбоя kube-apiserver мы обнаружили ещё одно важное обстоятельство: кэш страниц kube-apiserver засчитывается в лимит памяти cgroup, при этом анонимное использование памяти крадёт кэш страниц для той же cgroup. Таким образом, даже если kube-apiserver использует всего 20 ГБ памяти кучи, вся cgroup может упереться в лимит 200 ГБ памяти. Хотя текущая настройка ядра по умолчанию не предусматривает упреждающего восстановления назначенных страниц для эффективного повторного использования, в настоящее время мы изучаем мониторинг на основе файла memory.stat, заставляя cgroup возвращать как можно больше страниц при приближении к лимиту памяти.
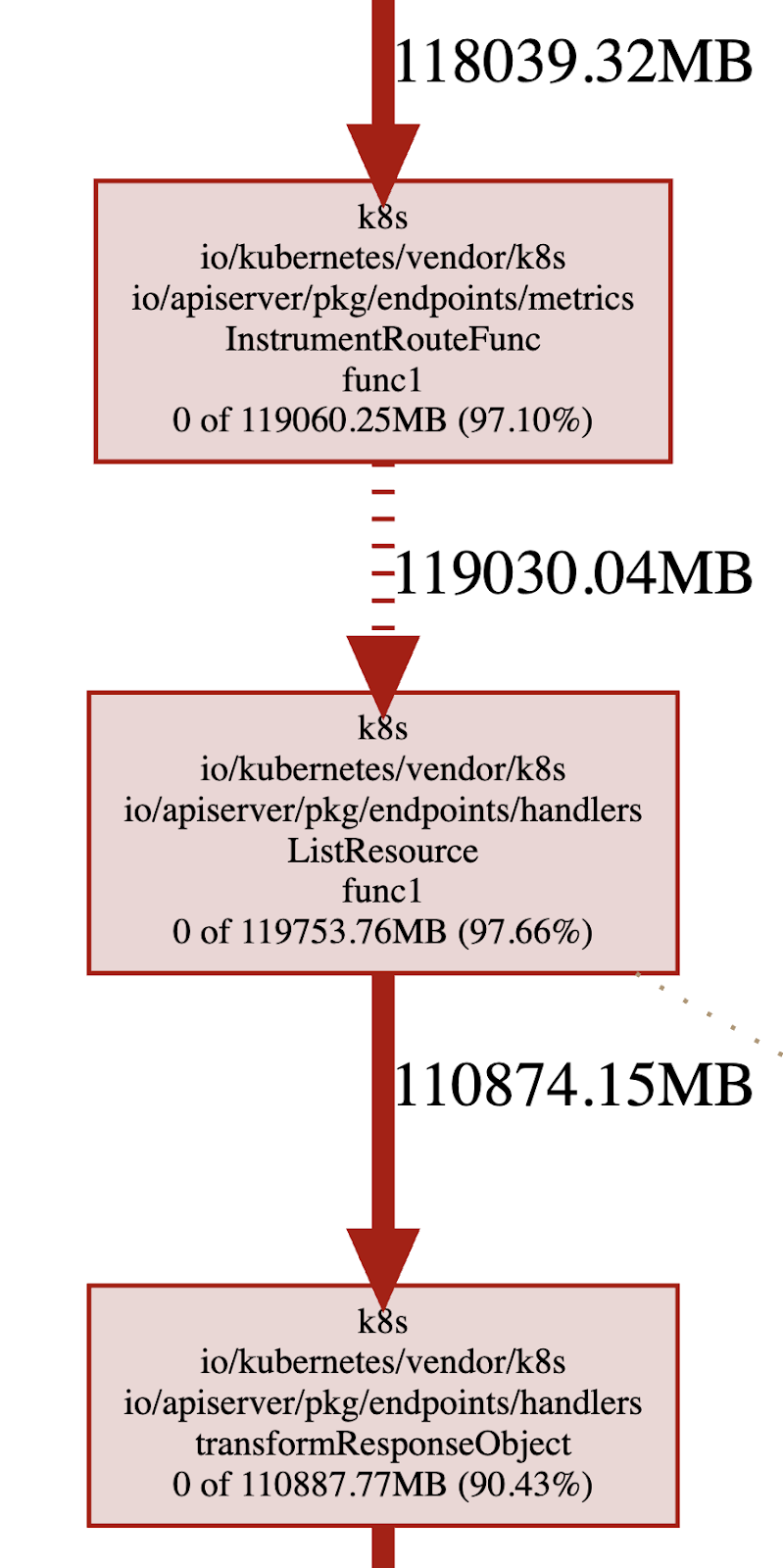
Рис. 8. Профилирование памяти сервера Kubernetes API
Вывод
Благодаря усилиям по повышению управляемости и надёжности мы значительно сократили внезапные скачки в использовании ресурсов, контролируем пропускную способность плоскости управления, обеспечивая стабильность и производительность всей платформы. Как показано на графике ниже, после оптимизации количество запросов в секунду в kube-apiserver упало на 90%, что повысило стабильность, эффективность и надёжность. Глубокое знание внутренних компонентов Kubernetes, а также полученные новые знания позволят нашим инженерам лучше справиться с работой системы и обслуживанием кластеров.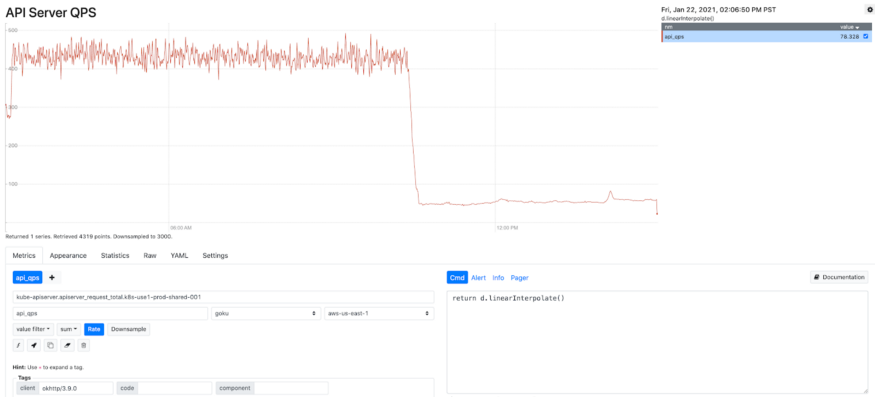
Рис. 9. Снижение количества запросов к kube-apiserver после оптимизации
Вот некоторые ключевые выводы, которые, надеюсь, помогут вам повысить надёжность платформы Kubernetes и решить проблемы с масштабированием:
- Диагностируйте проблемы, чтобы добраться до первопричины. Сосредоточьтесь на «том, что есть», прежде чем решить, «что с этим делать». Первый шаг к решению проблем — это понять, что является узким местом и почему. Добраться до первопричины — половина решения.
- Почти всегда стоит сначала изучить маленькие последовательные улучшения, а не радикальные изменения архитектуры. Это очень важно, особенно когда у вас небольшая команда.
- Принимайте решения на основе данных. Правильная телеметрия покажет, на чём сосредоточиться и что оптимизировать в первую очередь.
- Критические компоненты инфраструктуры должны разрабатываться с учётом устойчивости. Распределённые системы подвержены сбоям, и лучше всегда готовиться к худшему. Правильные ограничения помогут предотвратить каскадные отказы и свести к минимуму радиус взрыва.
Планы на будущее
Федеративная структура
Для растущего количества рабочих нагрузок нам уже не хватает одного кластера. Следующей вехой станет возможность горизонтального масштабирования вычислительной платформы. Мы планируем подключать новые кластеры с минимальными операционными издержками, используя федеративную структуру, сохраняя при этом интерфейс платформы устойчивым для конечных пользователей. Наша федеративная кластерная среда в настоящее время находится в стадии разработки, и мы с нетерпением ожидаем новых возможностей, которые она предоставит.Проактивное планирование ресурсов
Нынешний подход с квотами — это упрощённый и реактивный способ планирования ресурсов. Поскольку мы берём к себе пользовательские рабочие нагрузки и системные компоненты, динамика платформы меняется, а лимиты могут устареть. Мы хотим изучить проактивное планирование нагрузки с прогнозированием на основе исторических данных, траектории роста и сложного моделирования, которое охватывает не только квоты ресурсов, но и квоты API. Думаем, что более проактивное и точное планирование поможет предотвратить выдачу лишних ресурсов, а также избежать их дефицита.Источник статьи: https://habr.com/ru/company/itsumma/blog/552818/