Если у вас в организации используются сразу несколько информационных систем, то рано или поздно возникает необходимость в их интеграции (возможно необходимость уже давно есть, просто вы не догадываетесь). При этом сами информационные системы с течением времени могут изменяться либо заменяться целиком. Поэтому и интеграционное решение должно меняться вслед за ними. Одна из самых сложных проблем при налаживании взаимодействия между используемыми приложениями — согласование терминов предметных областей и обозначений, принятых в каждой из подсистем.
Для согласованного и успешного функционирования интегрированных систем предприятия необходимо наладить связи между объединяемыми приложениями, для этих целей нужно программное обеспечение интеграции информационных систем.
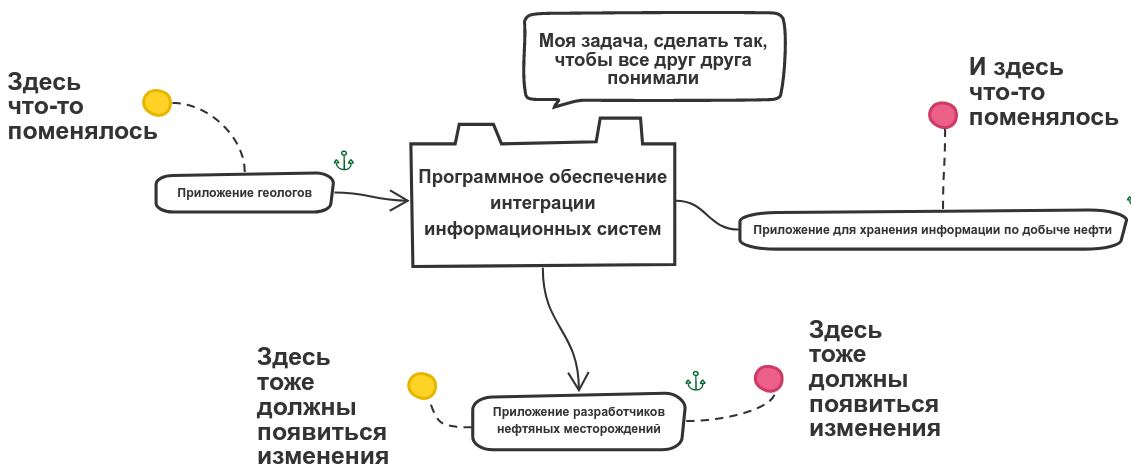
В статье рассматривается случай, когда в одном из научно-исследовательских проектных институтов возникла подобная задача. В отделе, занимающемся созданием проектов анализа разработки нефтяных месторождений, работает несколько различных информационных систем: приложение геологов, приложение разработчиков нефтяных месторождений и приложения для хранения информации по добыче нефти. При этом возникают трудности в сопровождении и модификации, а также совместном согласованном их использовании. Трудности заключаются в том, что над проектом трудятся сразу несколько специалистов различных областей. Каждый из специалистов использует свой язык предметной области и специфичные информационные системы. Для совместной работы над проектом необходимо обеспечить взаимодействие используемых информационных систем.
Сложность создания подобного интеграционного решения состоит в том, что каждое приложение построено на основании терминов конкретной предметной области, и для определения соответствия между понятиями необходимо учитывать их семантику. Интеграция информационных систем — это постоянный процесс, поскольку со временем меняется состав используемых приложений, добавляются новые типы данных.
Какой бы из известных способов интеграции приложений ни был выбран (файловый обмен, общая база данных, удаленный вызов процедуры, обмен сообщениями), при использовании любого из этих подходов соответствие между объектами предметных областей может быть формализовано и «зашито» непосредственно в коде интеграционного приложения либо представлено в виде отдельного описания связей и правил.
Как уже было сказано выше, матчинг онтологий принято определять как процесс нахождения сходства двух онтологий A и B и, как результат, создание новой онтологии C, объединяющей представления исходных онтологий. В результате две системы, основанные на онтологиях A и B, получают возможность взаимодействовать между собой, используя онтологию С.
Современные методы матчинга онтологий можно разделить на два типа: с замещением новой онтологией исходных и с совместным использованием интегрированной и исходных онтологий. Методы второго типа я считаю гибче, поскольку они позволяют сохранить и в дальнейшем использовать структуру уже имеющихся онтологий.
При создании общего языка между системами, входящими в интеграционное решение, не стоит выбора о замещении или не замещении исходных языков общим, поскольку терминологии предметной области являются устоявшимися и не полежат изменениям точно так же, как и информационные системы не могут быть изменены при каждом варианте интеграции. Поэтому речь может идти только о совместном использовании исходных языков и общего вновь образованного. Наиболее подходящим решением для нас является нахождение соответствий между понятиями каждой из объединяемых систем.
Больше всего нас заинтересовал подход, основанный на использовании методов машинного обучения, при этом хотелось не просто использовать какое-то готовое решение, а разобраться, как это работает «под капотом».
Как уже было сказано выше, интеграционное решение может меняться, в него могут добавляться новые информационные системы со своими онтологиями. В связи с этим хотелось бы найти такой подход, который позволял бы использовать знания, полученные при первом сопоставлении в последующих сопоставлениях и т. д.
На техническом уровне при интеграции двух информационных систем онтологии А и В будут представлять собой набор объектов и полей приложения А и приложения В соответственно. При этом общая онтология С необходима для формирования названия и перечня полей для сообщений, используемых для обмена между информационными системами.
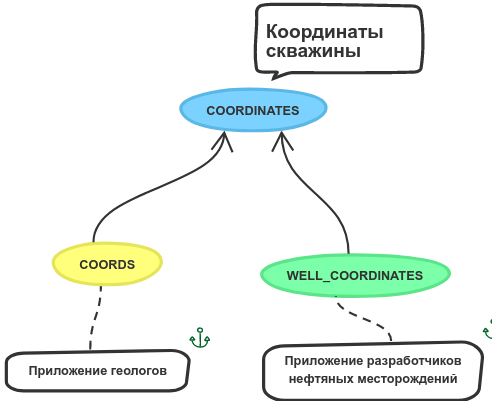
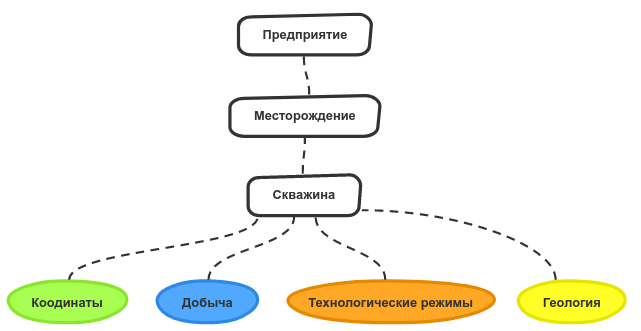
На рассматриваемом в рамках статьи предприятии нефтяной отрасли участвующие в интеграционном решении информационные системы имеют схожую структуру онтологий. Это связано с тем, что каждая из них используется для работы с данными, относящимися к нефтяным месторождениям. Поэтому структуру онтологии можно представить в таком виде: месторождение — скважина — тип данных по скважине — поле типа данных по скважине. Наличие подобного сходства структур хранения, позволяет нам, подобно разрушителю лайфхаков, всё немного упростить и свести задачу к нахождению соответствия между терминами одного уровня, а именно – объектов уровня скважины. Далее будут рассмотрены виды сопоставления понятий онтологии уровня «тип данных по скважине».
Нашей идеей было разделить матчинг терминов онтологий на два вида: первичное сопоставление, повторное сопоставление. При первичном сопоставлении специалист по интеграции может опираться на сравнение строковых названий объектов уровня скважины и последующую экспертную проверку полученных значений. При повторном сопоставлении у него уже появляется возможность использовать предыдущие сопоставления в качестве входной информации.
Для реализации первичного сопоставления был выбран метод TF-IDF с N-Grams, поскольку он быстрее на больших наборах данных, чем классические методы, такие как расстояние Левенштейна или метод Джаро-Винклера. Использование TF-IDF с N-Grams позволяет свести задачу поиска сходства между строками к задаче перемножения матриц, которая проще в вычислении.
Соотношение TF к IDF — статистический показатель, который используется преимущественно для оценивания важности (весомости) конкретного слова (термина) в контексте всего документа, входящего в общую коллекцию (базу).
Показатель TF/IDF прежде всего используется для анализа текстового контента в больших потоках данных. Так, к данному отношению прибегают поисковые алгоритмы, чтобы определить релевантность конкретной странички (в первую очередь текста, который на ней находится), пользовательскому запросу в поиске. Также данный статистический показатель позволяет определить близость различных документов (текстов) друг другу, что может быть использовано при их группировке (кластеризации).
В нашем случае большинство терминов онтологий содержат только одно или два слова. Поэтому было решено использовать n-Grams: последовательности из N смежных элементов, в данном случае символов. На следующем рисунке представлен пример преобразования термина «operating_practices» одной из онтологий в последовательность n-Grams:

Далее для полученной последовательности применяется TF-IDF. Для группы терминов из нескольких онтологий ("operating", "well_operating_practices", "operation_regim","oper") —матрица TF-IDF. Она будет иметь размерность 4х27, количество строк матрицы соответствует количеству анализируемых строк, а количество столбцов матрицы — количеству tf-idf терминов. Далее мы можем вычислить Коэффициент Отиаи (косинусный коэффициент) между первым термином ("operating") с каждым из других терминов набора:
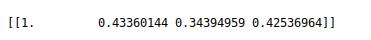
Первое значение массива равно 1,0, потому что это косинусный коэффициент между первым термином и самим собой. Благодаря наличию похожих слов во втором термине ("well_operating_practices") он набрал лучший результат.
Для повторного сопоставления был выбран метод опорных векторов. Метод опорных векторов или SVM (от англ. Support Vector Machines) — это линейный алгоритм, используемый в задачах классификации и регрессии. Этот алгоритм имеет широкое применение на практике и может решать как линейные, так и нелинейные задачи. Суть работы “Машин” Опорных Векторов проста: алгоритм создает линию или гиперплоскость, которая разделяет данные на классы.
В нашем случае в качестве обучающей выборки предлагается использовать сопоставления, полученные при первичном сопоставлении. Для обучения был использован стохастический градиентный спуск или SGD (от англ. Stochastic Gradient Descent).
Стохастический градиентный спуск относится к оптимизационным алгоритмам и нередко используется для настройки параметров модели машинного обучения.
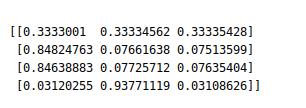
В качестве примера можно рассмотреть набор из терминов онтологии: ['operating_practices', 'tech_regim', 'perf', 'perforation', 'coord', 'coordinates'] с соответствующим ему обучающим вектором [1, 1, 2, 2, 3, 3]. После обучения классификатора при помощи этой выборки его можно использовать для определения соответствия нового термина термину из общей онтологии. На рисунке представлена матрица соответствия установленной классификации для следующего перечня терминов ['oord', 'tech', 'operating', 'perf'].
Ниже на рисунке представлена общая схема адаптера канала. Для всех информационных систем в этом случае был выбран адаптер уровня БД, поскольку у всех участвующих приложений существует доступ на уровне СУБД, и такой тип адаптера достаточно эффективен и способен предоставить весь необходимый перечень функций.
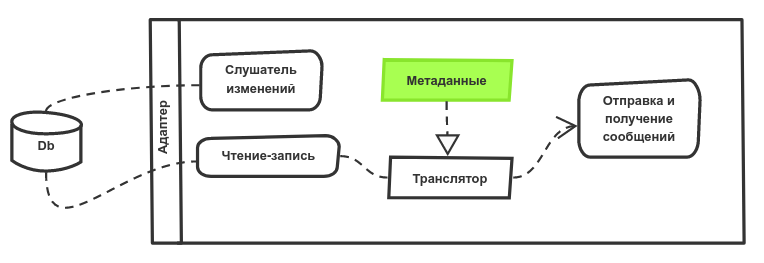
Блок «Слушатель изменений» предназначен для отлавливания событий об изменениях в данных. Блок «Чтение-запись» осуществляет чтение данных из БД по сигналу от слушателя и передачу их в транслятор. И в обратном порядке: приём данных из транслятора и запись в БД. Блок «Транслятор» является самой сложной частью адаптера канала. На него возлагаются функции преобразования внутреннего представления информации в формат канонического сообщения на основании правил или метаданных. Канонический формат сообщения – это формат, наиболее полно описывающий рассматриваемый объект, т. е. наиболее полный, содержащий общую для всех ИС сумму атрибутов. «Метаданные» в данном случае – это связи между понятиями и правила их преобразования. Блок «Отправка-получение сообщений» отвечает за получение сообщений от системы обмена сообщениями и передачи в транслятор и отправку сообщений из транслятора в соответствии со списком рассылки.
Оскар Бостонов

 habr.com
habr.com
Для согласованного и успешного функционирования интегрированных систем предприятия необходимо наладить связи между объединяемыми приложениями, для этих целей нужно программное обеспечение интеграции информационных систем.
В статье рассматривается случай, когда в одном из научно-исследовательских проектных институтов возникла подобная задача. В отделе, занимающемся созданием проектов анализа разработки нефтяных месторождений, работает несколько различных информационных систем: приложение геологов, приложение разработчиков нефтяных месторождений и приложения для хранения информации по добыче нефти. При этом возникают трудности в сопровождении и модификации, а также совместном согласованном их использовании. Трудности заключаются в том, что над проектом трудятся сразу несколько специалистов различных областей. Каждый из специалистов использует свой язык предметной области и специфичные информационные системы. Для совместной работы над проектом необходимо обеспечить взаимодействие используемых информационных систем.
Сложность создания подобного интеграционного решения состоит в том, что каждое приложение построено на основании терминов конкретной предметной области, и для определения соответствия между понятиями необходимо учитывать их семантику. Интеграция информационных систем — это постоянный процесс, поскольку со временем меняется состав используемых приложений, добавляются новые типы данных.
Сразу два непонятных слова
Следует сказать, что с необходимостью нахождения соответствия между понятиями специалисты сталкиваются при реализации любых наиболее распространённых интеграционных задач, таких как создание информационных порталов, репликация данных, бизнес-функции совместного использования, архитектуры, ориентированные на службы, распределенные бизнес-процессы, B2B интеграция. Для этого даже был введен специальный термин: «матчинг онтологий». Онтология, если говорить проще, это описание объектов их свойств и связей между ними для какой-то предметной области. Под матчингом онтологий в нашем случае понимается нахождение соответствия между сущностями двух онтологий.Какой бы из известных способов интеграции приложений ни был выбран (файловый обмен, общая база данных, удаленный вызов процедуры, обмен сообщениями), при использовании любого из этих подходов соответствие между объектами предметных областей может быть формализовано и «зашито» непосредственно в коде интеграционного приложения либо представлено в виде отдельного описания связей и правил.
Как уже было сказано выше, матчинг онтологий принято определять как процесс нахождения сходства двух онтологий A и B и, как результат, создание новой онтологии C, объединяющей представления исходных онтологий. В результате две системы, основанные на онтологиях A и B, получают возможность взаимодействовать между собой, используя онтологию С.
Современные методы матчинга онтологий можно разделить на два типа: с замещением новой онтологией исходных и с совместным использованием интегрированной и исходных онтологий. Методы второго типа я считаю гибче, поскольку они позволяют сохранить и в дальнейшем использовать структуру уже имеющихся онтологий.
При создании общего языка между системами, входящими в интеграционное решение, не стоит выбора о замещении или не замещении исходных языков общим, поскольку терминологии предметной области являются устоявшимися и не полежат изменениям точно так же, как и информационные системы не могут быть изменены при каждом варианте интеграции. Поэтому речь может идти только о совместном использовании исходных языков и общего вновь образованного. Наиболее подходящим решением для нас является нахождение соответствий между понятиями каждой из объединяемых систем.
Предлагаемое решение
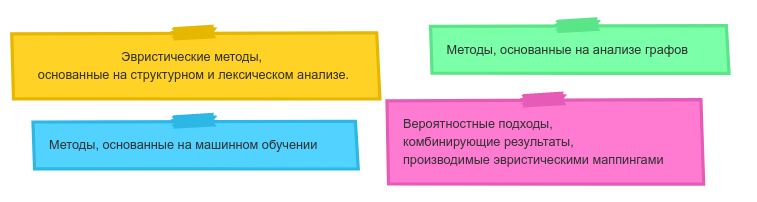
После проведения небольшого исследования выяснилось, что существуют следующие методы матчинга:
Больше всего нас заинтересовал подход, основанный на использовании методов машинного обучения, при этом хотелось не просто использовать какое-то готовое решение, а разобраться, как это работает «под капотом».
Как уже было сказано выше, интеграционное решение может меняться, в него могут добавляться новые информационные системы со своими онтологиями. В связи с этим хотелось бы найти такой подход, который позволял бы использовать знания, полученные при первом сопоставлении в последующих сопоставлениях и т. д.
На техническом уровне при интеграции двух информационных систем онтологии А и В будут представлять собой набор объектов и полей приложения А и приложения В соответственно. При этом общая онтология С необходима для формирования названия и перечня полей для сообщений, используемых для обмена между информационными системами.
На рассматриваемом в рамках статьи предприятии нефтяной отрасли участвующие в интеграционном решении информационные системы имеют схожую структуру онтологий. Это связано с тем, что каждая из них используется для работы с данными, относящимися к нефтяным месторождениям. Поэтому структуру онтологии можно представить в таком виде: месторождение — скважина — тип данных по скважине — поле типа данных по скважине. Наличие подобного сходства структур хранения, позволяет нам, подобно разрушителю лайфхаков, всё немного упростить и свести задачу к нахождению соответствия между терминами одного уровня, а именно – объектов уровня скважины. Далее будут рассмотрены виды сопоставления понятий онтологии уровня «тип данных по скважине».
Нашей идеей было разделить матчинг терминов онтологий на два вида: первичное сопоставление, повторное сопоставление. При первичном сопоставлении специалист по интеграции может опираться на сравнение строковых названий объектов уровня скважины и последующую экспертную проверку полученных значений. При повторном сопоставлении у него уже появляется возможность использовать предыдущие сопоставления в качестве входной информации.
Для реализации первичного сопоставления был выбран метод TF-IDF с N-Grams, поскольку он быстрее на больших наборах данных, чем классические методы, такие как расстояние Левенштейна или метод Джаро-Винклера. Использование TF-IDF с N-Grams позволяет свести задачу поиска сходства между строками к задаче перемножения матриц, которая проще в вычислении.
Соотношение TF к IDF — статистический показатель, который используется преимущественно для оценивания важности (весомости) конкретного слова (термина) в контексте всего документа, входящего в общую коллекцию (базу).
Показатель TF/IDF прежде всего используется для анализа текстового контента в больших потоках данных. Так, к данному отношению прибегают поисковые алгоритмы, чтобы определить релевантность конкретной странички (в первую очередь текста, который на ней находится), пользовательскому запросу в поиске. Также данный статистический показатель позволяет определить близость различных документов (текстов) друг другу, что может быть использовано при их группировке (кластеризации).
В нашем случае большинство терминов онтологий содержат только одно или два слова. Поэтому было решено использовать n-Grams: последовательности из N смежных элементов, в данном случае символов. На следующем рисунке представлен пример преобразования термина «operating_practices» одной из онтологий в последовательность n-Grams:
Далее для полученной последовательности применяется TF-IDF. Для группы терминов из нескольких онтологий ("operating", "well_operating_practices", "operation_regim","oper") —матрица TF-IDF. Она будет иметь размерность 4х27, количество строк матрицы соответствует количеству анализируемых строк, а количество столбцов матрицы — количеству tf-idf терминов. Далее мы можем вычислить Коэффициент Отиаи (косинусный коэффициент) между первым термином ("operating") с каждым из других терминов набора:
Первое значение массива равно 1,0, потому что это косинусный коэффициент между первым термином и самим собой. Благодаря наличию похожих слов во втором термине ("well_operating_practices") он набрал лучший результат.
Для повторного сопоставления был выбран метод опорных векторов. Метод опорных векторов или SVM (от англ. Support Vector Machines) — это линейный алгоритм, используемый в задачах классификации и регрессии. Этот алгоритм имеет широкое применение на практике и может решать как линейные, так и нелинейные задачи. Суть работы “Машин” Опорных Векторов проста: алгоритм создает линию или гиперплоскость, которая разделяет данные на классы.
В нашем случае в качестве обучающей выборки предлагается использовать сопоставления, полученные при первичном сопоставлении. Для обучения был использован стохастический градиентный спуск или SGD (от англ. Stochastic Gradient Descent).
Стохастический градиентный спуск относится к оптимизационным алгоритмам и нередко используется для настройки параметров модели машинного обучения.
В качестве примера можно рассмотреть набор из терминов онтологии: ['operating_practices', 'tech_regim', 'perf', 'perforation', 'coord', 'coordinates'] с соответствующим ему обучающим вектором [1, 1, 2, 2, 3, 3]. После обучения классификатора при помощи этой выборки его можно использовать для определения соответствия нового термина термину из общей онтологии. На рисунке представлена матрица соответствия установленной классификации для следующего перечня терминов ['oord', 'tech', 'operating', 'perf'].
Применение предлагаемого решения
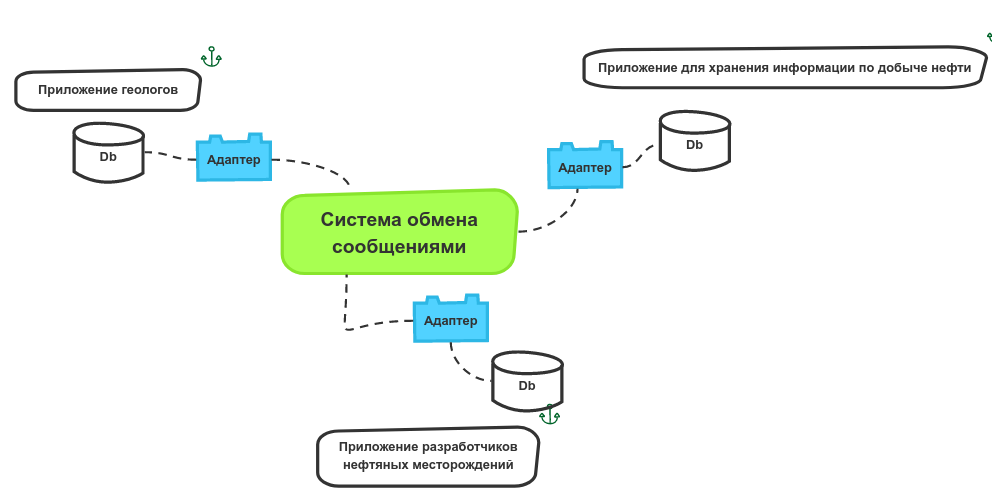
Как уже было сказано выше, при интеграции двух информационных систем их онтологии будут представлять собой набор объектов и полей приложения, а общая онтология необходима для описания сообщений, используемых для обмена между приложениями. Поэтому полученные соответствия необходимо применить при трансляции изменений объектов отдельных информационных систем в сообщения, передаваемые между участниками интеграционного решения. На рисунке представлена схема интеграционного решения, где точкой применения полученных соответствий является адаптер, задачами которого являются как трансляция изменений из объектов в сообщения, так и обратная трансляция. В принципе, полученный набор соответствий применим при любом подходе к интеграции, как некие метаданные, он может быть использован даже в простейшем конвертере из одного формата хранения в другой. Поэтому эта схема приводится как один из примеров использования.
Ниже на рисунке представлена общая схема адаптера канала. Для всех информационных систем в этом случае был выбран адаптер уровня БД, поскольку у всех участвующих приложений существует доступ на уровне СУБД, и такой тип адаптера достаточно эффективен и способен предоставить весь необходимый перечень функций.
Блок «Слушатель изменений» предназначен для отлавливания событий об изменениях в данных. Блок «Чтение-запись» осуществляет чтение данных из БД по сигналу от слушателя и передачу их в транслятор. И в обратном порядке: приём данных из транслятора и запись в БД. Блок «Транслятор» является самой сложной частью адаптера канала. На него возлагаются функции преобразования внутреннего представления информации в формат канонического сообщения на основании правил или метаданных. Канонический формат сообщения – это формат, наиболее полно описывающий рассматриваемый объект, т. е. наиболее полный, содержащий общую для всех ИС сумму атрибутов. «Метаданные» в данном случае – это связи между понятиями и правила их преобразования. Блок «Отправка-получение сообщений» отвечает за получение сообщений от системы обмена сообщениями и передачи в транслятор и отправку сообщений из транслятора в соответствии со списком рассылки.
Выводы
На основании всего вышесказанного можно сделать вывод , что методы машинного можно и нужно использовать при интеграции информационных систем. Вариант с повторным использованием результатов также работает. Этот механизм может быть использован как часть интеграционного решения, основанного, например, на обмене сообщениями. При других вариантах интеграции его тоже можно использовать. Такой подход может обеспечить гибкость интеграционных решений при изменениях бизнес-процессов вашей организации.Оскар Бостонов
Методы машинного обучения теперь и при интеграции информационных систем
Если у вас в организации используются сразу несколько информационных систем, то рано или поздно возникает необходимость в их интеграции (возможно необходимость уже давно есть, просто вы не...
habr.com