Привет! Эта статья рассказывает о моем опыте миграции СУБД с Oracle на PostgreSQL в системе с микросервисной архитектурой и является продолжением моего доклада на PGConf.Russia 2023. Я постарался выделить и описать в ней самые интересные и важные, на мой взгляд, моменты на пути по поиску и внедрению альтернативы Oracle, тестированию Greenplum и, в конечном итоге, переходу на несколько связанных баз данных PostgreSQL. Надеюсь, что данная информация будет полезна и интересна всем, кто уже столкнулся с похожей задачей, неизбежно к ней движется или просто интересуется данной темой.
Для начала расскажу немного о системе, в рамках которой была поставлена задача миграции СУБД. Система представляла из себя решение с микросервисной архитектурой, главной целью которой является расчет агрегатов по клиентам. Все данные расчета обрабатываются и хранятся в Oracle, верхнеуровневая схема взаимодействия с базой изображена на схеме ниже.
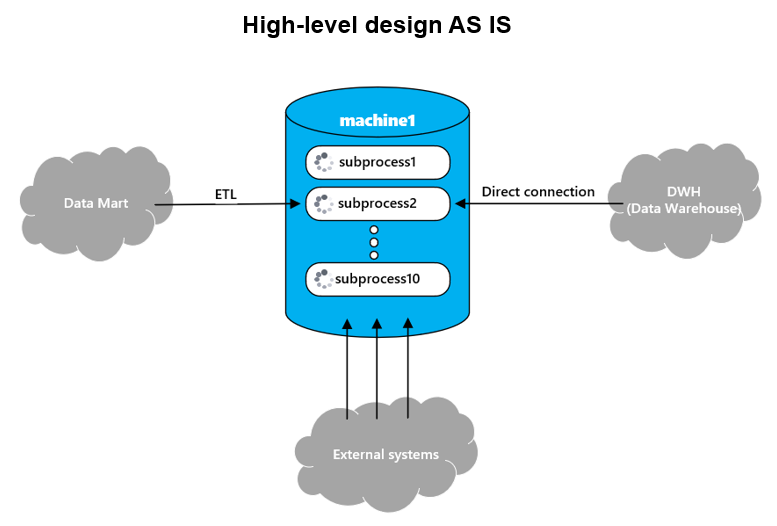
Расчет, далее буду его также называть процесс, обычно производится на количестве от 60 млн. до 100 млн. клиентов со всеми сопутствующими им данными (история обращений клиента, его финансовые показатели и т.д.), занимает порядка 3-4 дней и выглядит как загрузка данных по клиентам из витрины данных (Data Mart) объемом примерно 600 гб., далее расчет агрегатов по клиентам и обогащение данными по ним из внешних систем, а в конце отгрузка результата объемом ~2 тб. в корпоративное хранилище данных (КХД).
Сам расчет технически выглядит как исполняемая bpmn-схема с использованием Camunda, в которой оркестрируются вызовы микросервисов.
Справочная информация о Camunda
На уровне схемы процесс разделяется на несколько, обычно 10, подпроцессов, которые обрабатываются параллельно и оперируют над логически независимыми друг от друга данными.
Таким образом, с базой взаимодействуют 10 параллельных подпроцессов в рамках одного расчета, если в расчете 100 млн. клиентов, то в каждом подпроцессе их будет по 10 млн. и все данные по клиентам лежат в рамках подпроцесса. Таких расчетов на базе одновременно может быть несколько, у каждого из них есть свой SLA, и они должны считаться параллельно и независимо друг от друга. И собственно задача стояла — мигрировать систему с Oracle на PostgreSQL с учетом всей этой логики.
Первой остановкой в поисках альтернативы Oracle стала СУБД Greenplum, которая уже использовалась клиентом для формирования отчетности на КХД и была предложена в качестве альтернативы Oracle из-за смешанного характера нагрузки в системе: расчет больше напоминал OLAP при расчете агрегатов на клиентах, но и включал в себя элементы OLTP при закачке данных из внешних систем.
Справочная информация о Greenplum
Таким образом, одним из главных преимуществ Greenplum является удобная горизонтальная масштабируемость за счет добавления новых хостов с минимальным простоем и параллельная обработка процессов на этих хостах.
Целевая архитектура, которая тестировалась при внедрении Greenplum, приведена схематично на рисунке ниже.
В ней ожидалось, что каждому подпроцессу расчета выделится свой сегмент, на котором будут рассчитываться все клиенты из этого подпроцесса. А поскольку количество подпроцессов в расчете — изменяемый параметр, то это значило бы, что можно уменьшить время всего расчета за счет добавления новых хостов и сегментов и увеличения количества параллельных подпроцессов, что возможно благодаря хорошей горизонтальной масштабируемости Greenplum.
Если кратко, то основной причиной, почему это решение не взлетело, стала недостаточная эффективность обработки OLTP нагрузки при использовании Greenplum. Особенно это стало явно, когда в рамках подпроцесса ETL-механизм собирал данные по клиентам, по которым нужно было получить информацию во внешней системе. Тогда выполнялся запрос к базе на получение этих клиентов, но т.к. логически они лежали в рамках одного подпроцесса, а физически были равномерно распределены по хостам Greenplum, то СУБД приходилось их собирать воедино и уже после формировать ответ, вместо обработки всех данных по подпроцессу внутри одного хоста. В мониторинге при этом тестировании было видно высокое потребление сетевых ресурсов.
Помимо этого, есть еще несколько особенностей, которые сыграли не в пользу Greenplum:
По итогам тестирования было решено вместо горизонтального шардирования базы по хостам попробовать вертикальное шардирование таблиц на одном хосте PostgresSQL, и вот что из этого вышло.
В новой архитектуре, изображенной на схеме выше, видно, что в итоге база была разделена на две, что связано, во-первых, с желанием вынести формирование отчетности с тяжеленными запросами на отдельную базу, и, во-вторых, вынести архивные данные, чтобы они не мешали идущим расчетам. В итоге на машине один (machine1), далее буду называть ее расчетная база, выполняются текущие расчеты, а на машине два (machine2), далее архивная база, формируется оперативная отчетность и в нее сливаются архивные данные завершенных расчетов.
Преимущества такой архитектуры:
Структура базы данных тоже подверглась изменениям: теперь большинство таблиц, используемых для расчета (подпроцесса), стали партицированными по id конкретного подпроцесса. Так, если в двух параллельных расчетах выполняется по 10 подпроцессов, то, например, в таблице CUSTOMER с данными по клиентам будет 20 партиций, каждая из которых соответствует своему подпроцессу.

Помимо органичного внедрения партиций в этом бизнес-процессе было еще как минимум одно преимущество: обслуживание одной непартицированной таблицы, в частности вызов VACCUM, выполняется сложнее по сравнению с тем, если таблицу партицировать. В случае партицированной таблицы VACUUM можно вызывать отдельно для каждой партиции на меньшем объеме данных, что сильно упрощает задачу. Для примера в проекте на bpmn-схеме был сделан отдельный вызов микросервиса, который вызывает VACUUM ANALYZE после окончания перекачки всех данных в базу в рамках этого подпроцесса, и так по итогу по этим партициям уже запросы выполняются на актуальной статистике.
В следующих разделах погрузимся глубже в детали реализации и остановиться на некоторых важных моментах, которые всплыли в процессе миграции на PostgreSQL.
Первое, с чем столкнулись при внедрении партиций — необходимость ими управлять, т.е. создавать, очищать и т.д., при этом необходимо было обеспечить параллельность этих процессов. Далее рассмотрим их подробнее, а для демонстрации примеров была создана упрощенная тестовая схема с таблицами и сиквенсом.
DDL объектов тестовой схемы
set search_path="test"
create sequence test_customer_seq;
/* данные о расчетах */
create table PROCESS(
process_id int,
row_cnt int,
CONSTRAINT process_pk PRIMARY KEY (process_id)
)
/* данные подпроцессов в расчетах */
create table SUBPROCESS(
subprocess_id int,
process_id int not null,
row_cnt int,
CONSTRAINT subprocess_pk PRIMARY KEY (subprocess_id)
)
/* данные клиентов в расчетах */
create table CUSTOMER(
customer_id int default nextval('test_customer_seq') not null,
process_id int not null,
subprocess_id int not null,
test_flg bool default false,
CONSTRAINT customer_pk PRIMARY KEY (customer_id, subprocess_id)
) partition by list (subprocess_id);
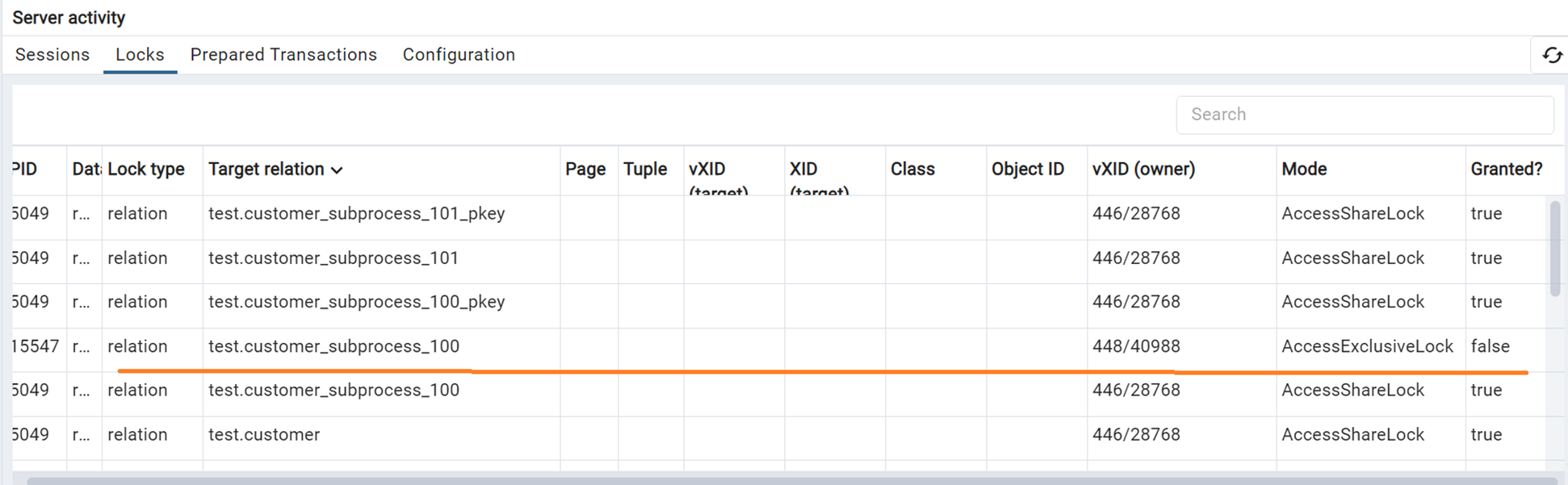
Пример: допустим есть активный расчет, который читает данные из таблицы, на скриншоте ниже это левая сессия с запросом к таблице CUSTOMER, который выполнился, но транзакция не завершена. В правой части в отдельной сессии пытаемся создать партицию для нового подпроцесса и видим, что она зависла.
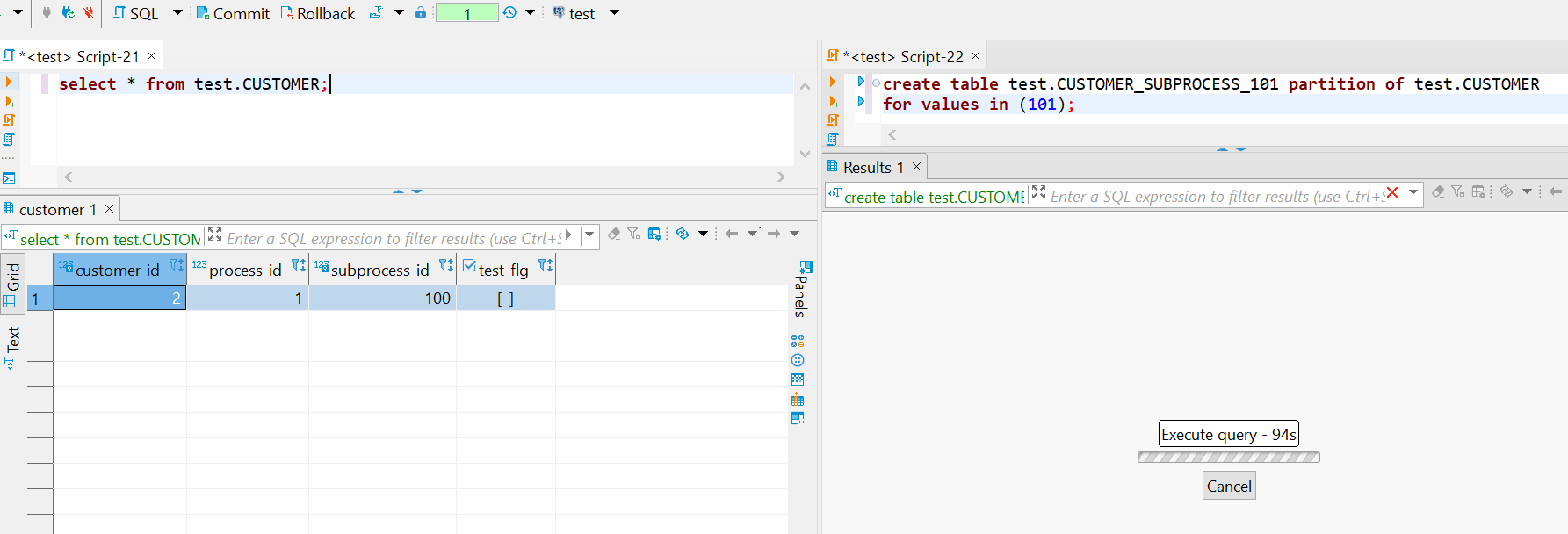
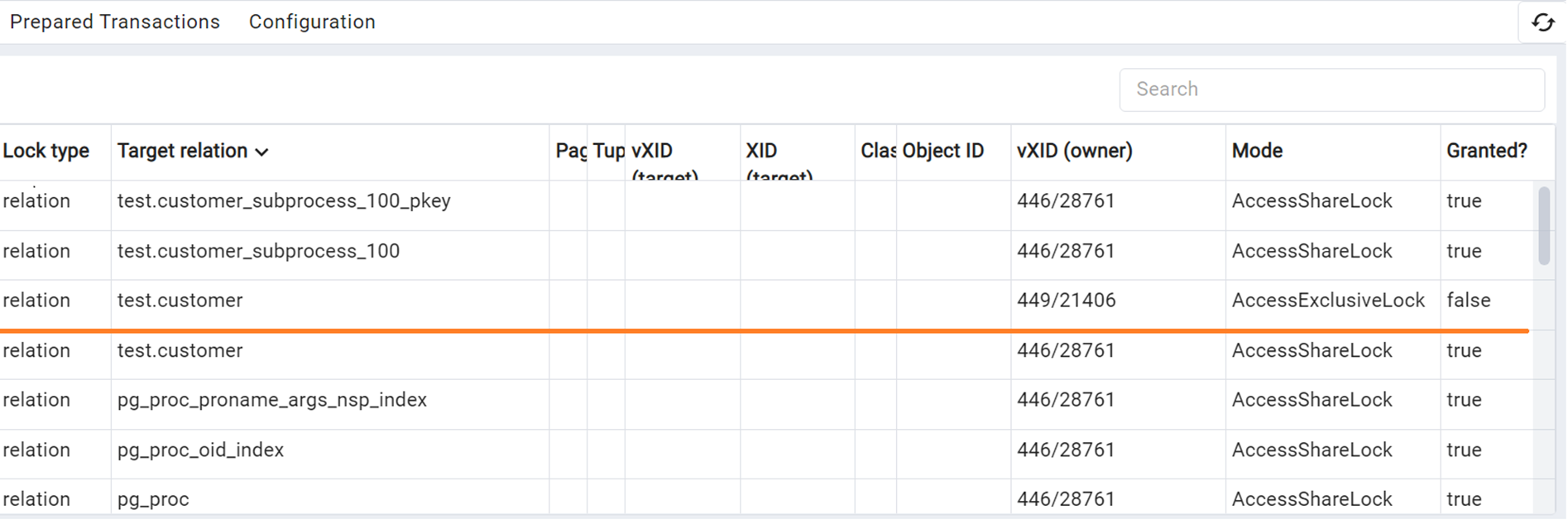
В pgAdmin в мониторинге блокировок видим, что вторая сессия пытается наложить эксклюзивную блокировку на CUSTOMER, но безуспешно т.к. Granted = false, т.е. по сути наш запрос к таблице блокирует вторую сессию на создание партиции.
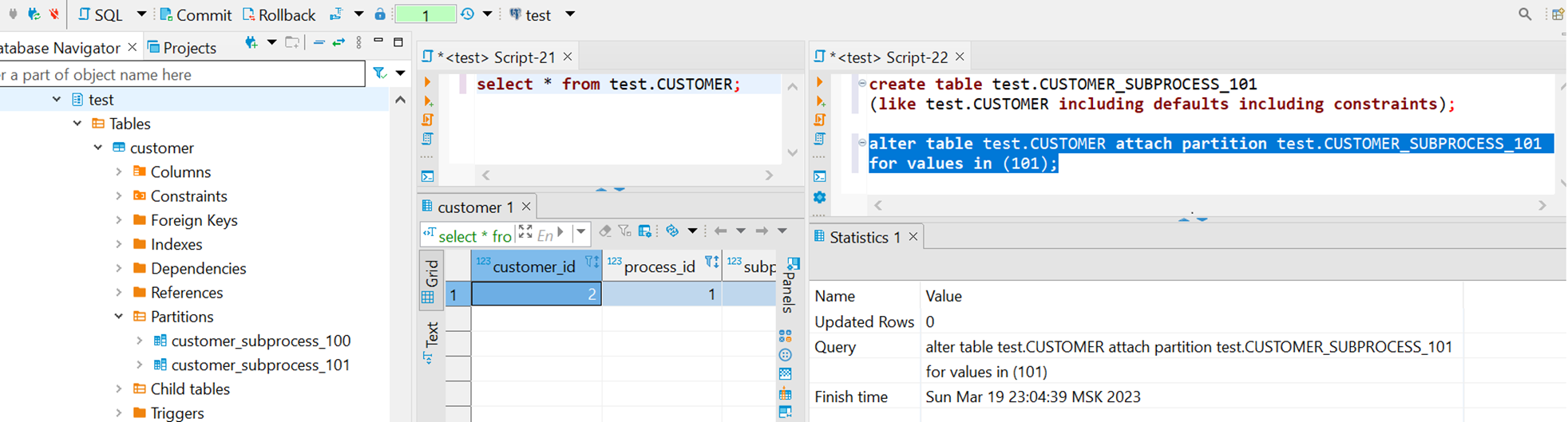
Поправим эту ситуацию присоединением таблицы в качестве партиции. На скриншоте все та же сессия с запросом к CUSTOMER, которую не закрываем, а во второй сессии создаем таблицу и присоединяем ее как партицию к основной таблице CUSTOMER для подпроцесса 101. Сессии успешно отработали, т.е. по итогу не блокируют друг друга.
Сам механизм создания партиции можно автоматизировать: например создать триггер на вставку записи в таблицу subprocess, чтобы все партицированные по subprocess_id таблицы создавали свои партиции в функции триггера, либо создать процедуру с созданием партиции и вызывать ее из сервиса по команде от оркестратора.
С очисткой партиций тоже похожая ситуация, здесь во второй сессии мы пытаемся почистить одну из партиций с помощью TRUNCATE, и она тоже безуспешно зависает.
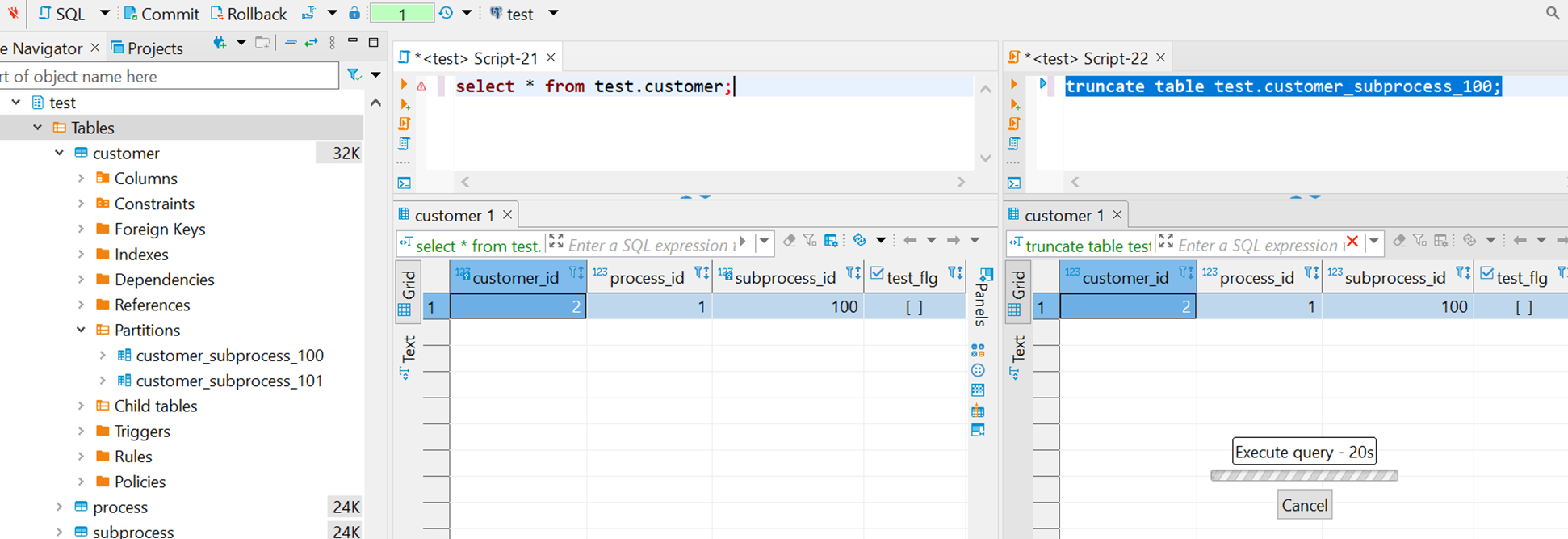
На мониторинге блокировок также видим эксклюзивную блокировку на партицию, которую сессия не может получить.
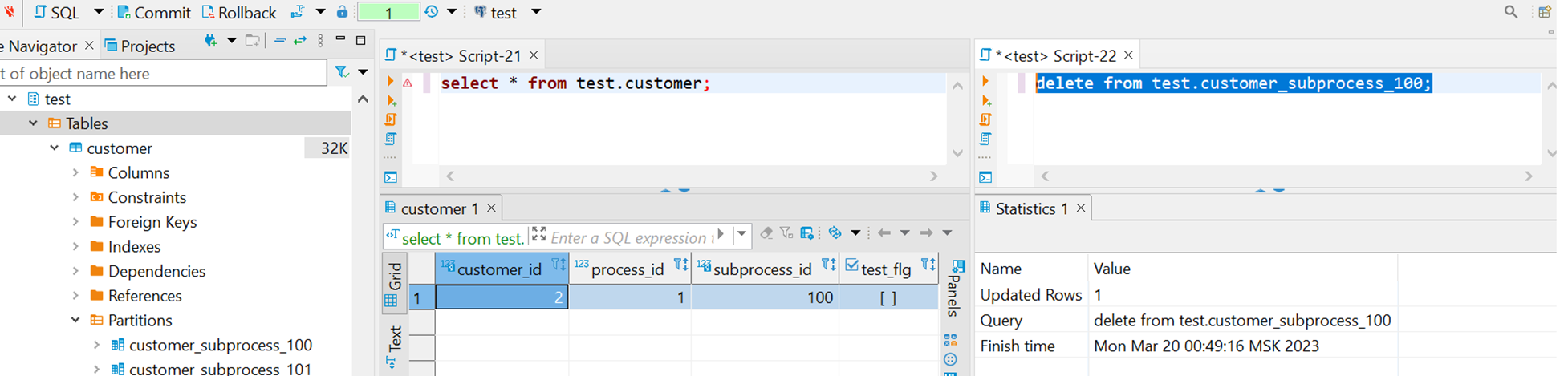
Поправим дело изменением запроса на delete from без предиката для полной очистки таблицы, при таком подходе видим, что сессии отработали и не мешают друг другу.
Стоит отметить, что после очистки важно выполнить VACUUM по таблице (партиции), чтобы держать по ней актуальную информацию в базе. Вопрос параллельной очистки может быть важен в случае параллельной перекачки данных для обеспечения идемпотентности: т.е. при любом старте перекачки в подпроцессе мы очищаем все связанные с ним партиции, чтобы всегда гарантированно перекачивать в пустые таблицы, если, например, в прошлой попытке перекачки пошло что то не так и она упала на полпути.
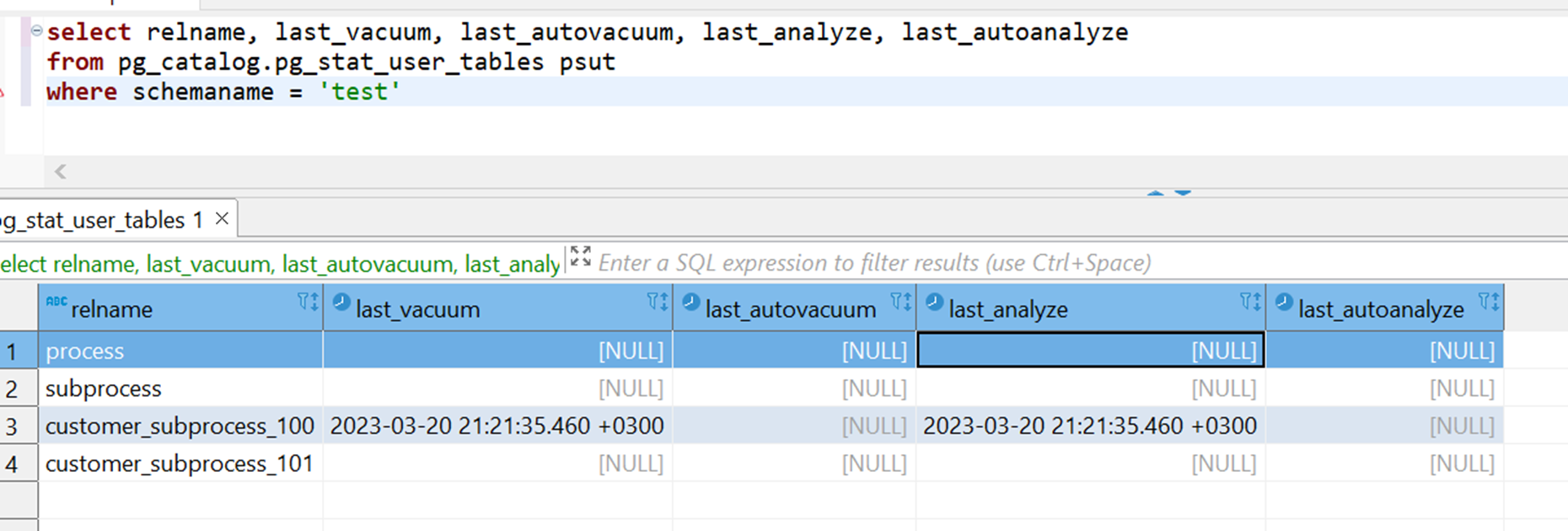
Ранее я несколько раз упомянул разные примеры с использованием VACUUM и необходимостью заниматься обслуживанием таблиц. Мониторить состояние таблиц можно с помощью представлений (view) pg_stat_user_tables или pg_stat_all_tables, и это особенно удобно при использовании партицирования, т.к. каждая партиция — тоже таблица, а таких партиций в таблицах может быть очень много. В представлениях указываются, среди прочего, дата последнего автовакуума и автоматического сбора статистики, даты их ручных вызовов, что может служить одним из индикаторов того, что в базе есть проблемы, если даты старые.
Другим удобным представлением является pg_stat_user_indexes. Т.к. в Oracle уже был набор индексов, то мы попробовали их перенести как есть на postgreSQL и провести нагрузочное тестирование. С помощью pg_stat_user_indexes стало понятно, какие индексы из созданных совсем не используются (в столбце idx_scan 0). Эти индексы стали кандидатами на удаление (исключая автоматически созданные индексы вроде индексов первичных ключей), а остальные индексы остались, что позволило не начинать с 0 их разработку, а частично переиспользовать то, что уже было.

Для случаев, когда необходимо получить данные по нескольким партициям, будут сканироваться все партиции этой таблицы, т.к. нет предиката с ключом партицирования. Посмотрим на примере: попробуем получить всех клиентов в расчете и построить план запроса.
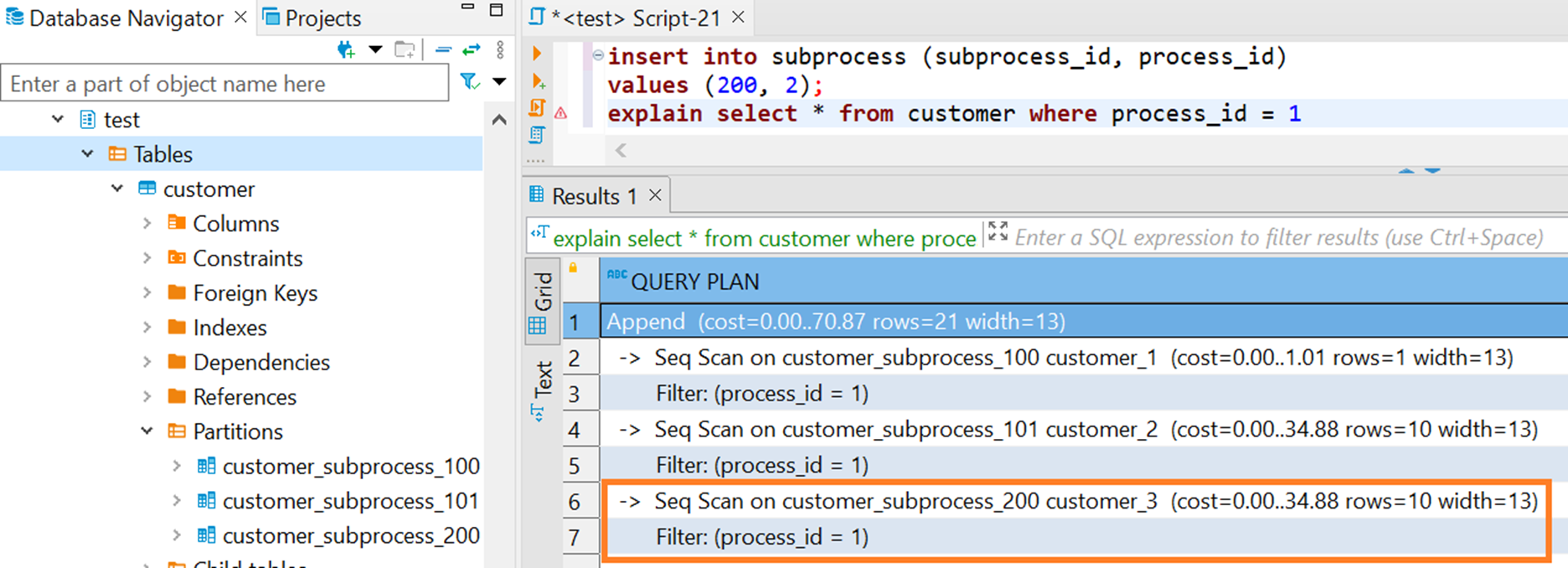
В примере на скриншоте партиции subprocess_100 и subprocess_101 относятся к process_id = 1, а subprocress_200 относится к process_id = 2, но при запросе на получение всех данных по process_id = 1 сканируется лишняя партиция subprocess_200 (да и в принципе все партиции таблицы). Если бы было больше партиций и данных в них, то даже такой запрос выполнялся бы до его прерывания по таймауту в базе (если еще он настроен), т.к. план запроса улетел бы в бесконечность.
Поправим ситуацию, добавив в каждую партицию ограничение по process_id, т.к. известно, что в рамках партиции оно принимает одно значение (т.к. подпроцесс принадлежит всегда только одному расчету).
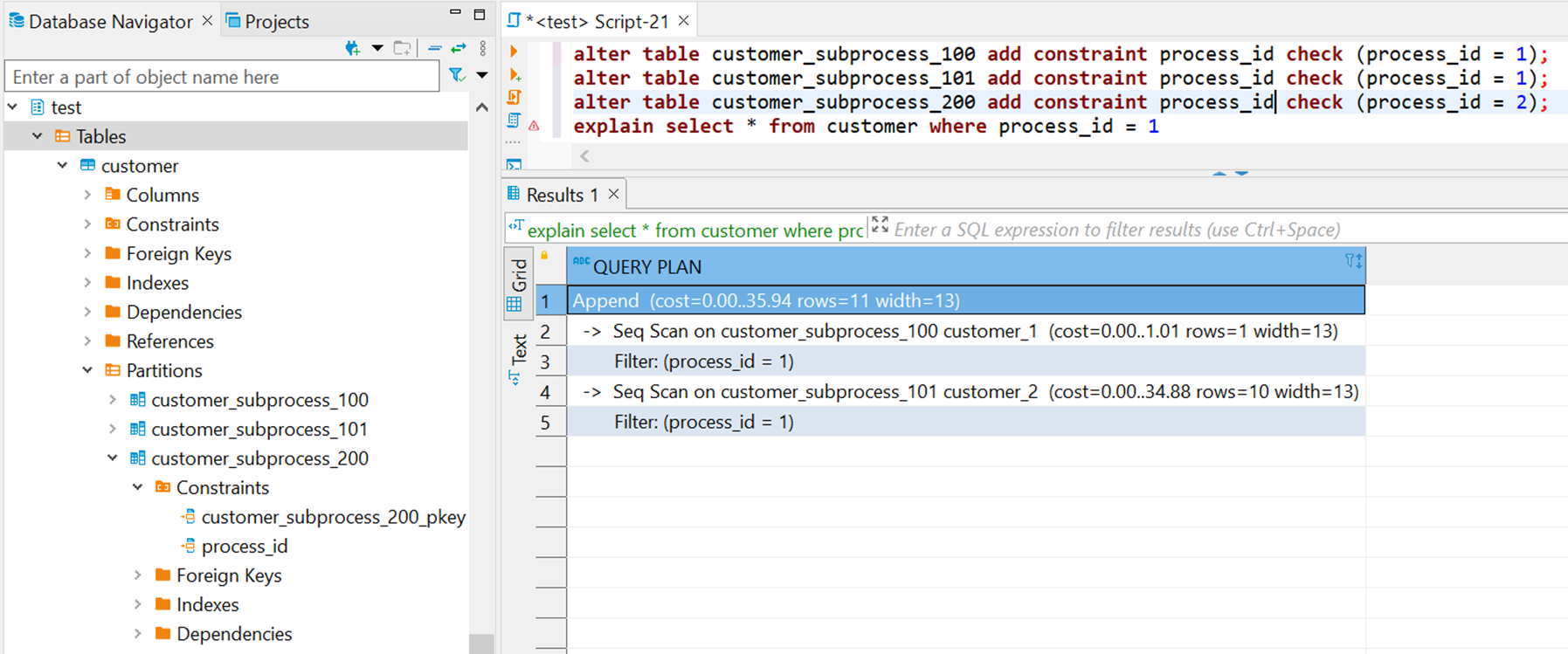
После добавления ограничений в плане запроса видно, что сканируются только нужные партиции.
Я уже упоминал ранее, что разделение одной базы на несколько по профилям нагрузки позволило оптимизировать выделяемые ресурсы для каждой базы в соответствии с ее задачами. Но, помимо этого, необходимо было в конфигурации базы увеличить параметр max_locks_per_transaction и найти оптимальное значение для temp_file_limit.
Справка по max_locks_per_transaction и temp_file_limit
max_locks_per_transaction
В max_locks_per_transaction можно упереться при использовании партиций, т.к. сами партиции тоже таблицы, а если над ними выполняются тяжелые аналитические запросы, то на них на все накладываются блокировки, что может быстро исчерпать выставленный в параметре лимит.
С temp_file_limit все немного сложнее. На практике столкнулись с проблемой, что необходимо, например, добавить новую колонку в таблице, но если данных в ней много, то при выполнении DDL-запроса создается временный файл, которому нужно будет больше места, чем указано в этом параметре. Тогда перед поставкой релиза необходимо оценивать объем создаваемых временных файлов, увеличивать на продуктивной среде, а после поставки возвращать обратно. Мониторить ситуацию с временными файлами помогает представление pg_stat_database.
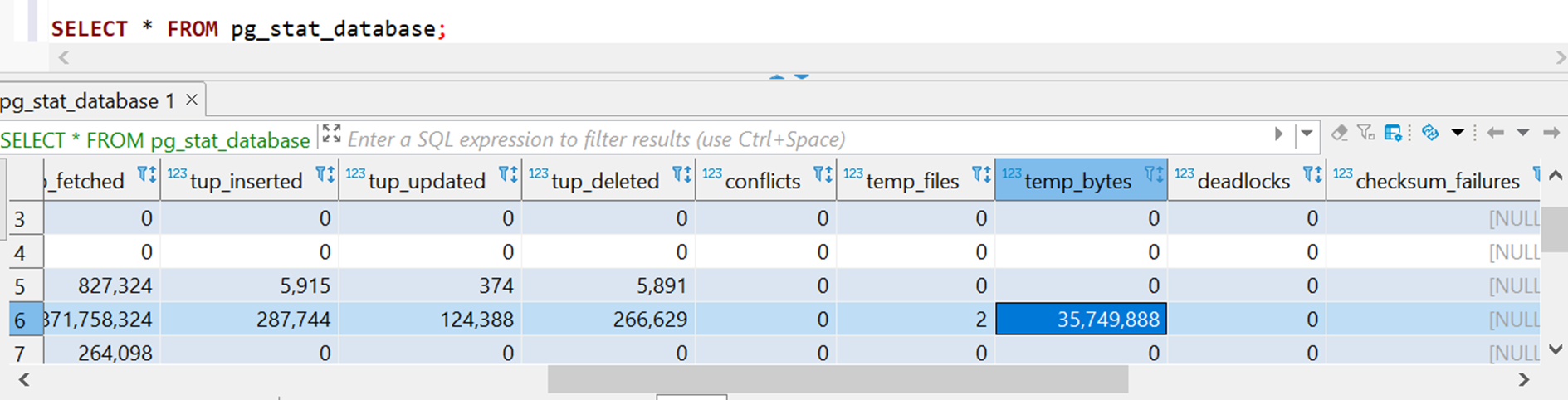
В нем в temp_files указывается количество созданных файлов, а в temp_bytes их объем.
Миграция данных, модели данных и хранимых процедур (и остальной накрученной логики в базе) составляют основу миграции, но сперва нужно решить вопрос, идущий в паре с ними: стоит ли рефакторить сразу модель данных и вообще части системы, вместо того, чтобы перенести как есть и отрефакторить потом? С одной стороны, нет, мы не хотим влиять на логику процедур, которая зависит от изменений в модели, ведь даже рефакторинг одной такой таблицы может привести к необходимости полного регресса всей системы. С другой стороны, после миграции на новую СУБД крайне вероятно потребуется провести регресс системы, полное функциональное и нефункциональное тестирование. Поскольку в моем проекте базу для такого тестирования только предстояло разработать, то было решено сразу внедрить и оптимизационные решения вроде рефакторинга модели.
Что касается миграции данных, то специфика системы, а именно отдельные расчеты клиентов, не требовала мигрировать данные предыдущих расчетов (десятки терабайтов), тем более что они уже были выгружены в КХД. Требовалось лишь перенести конфигурацию системы обычным liquibase с возможностью донастроить ее через UI.
Справочная информация о Liquibase
Большие изменения претерпела модель данных. Они коснулись, например, всех флагов, которые лежали в базе как число, а затем преобразовались в тип boolean в PostgreSQL. По многим атрибутам была проделана кропотливая работа, чтобы определить, кто источник данных и какой размер атрибута реально нужен, и, по возможности, его уменьшить. Во всех представлениях, с которыми работает ETL или внешние системы, была произведена обратная конвертация к исходному типу до конвертации, т.к. обычно в больших корпоративных структурах одно поле может тянуться в ряд систем, и соответственно, изменение типа в источнике может обрушить все интеграции по цепочке разом.
Есть ряд решений по автоматической миграции процедур типа Ora2PG и других, но поскольку в базе лежала только бизнесовая логика для расчета агрегатов, с которой мы уже какое то время работали на оракле и имели хорошее представление о ней, то вручную нам это перевести было намного проще. Другой вопрос — как это все тестировать? При обработке объемов клиентов порядка десятков миллионов возникает огромное количество сценариев, а не прекращающаяся разработка процедур в Oracle под нужды бизнеса вынуждает регулярно проводить повторное тестирование. С этим сильно помогли автотесты: они позволили, с одной стороны, покрыть все тестовые кейсы без необходимости постоянного прогона расчета с 0, и, с другой стороны, база автотестирования при добавлении нового инкремента функциональности позволяла достаточно быстро проводить регресс существующего функционала.
При доработке микросервисов было важно учесть следующее:
В связи с этим был выбран подход внедрения на продуктивную среду, верхнеуровнево изображенный на схеме взаимодействия микросервисов с БД ниже.
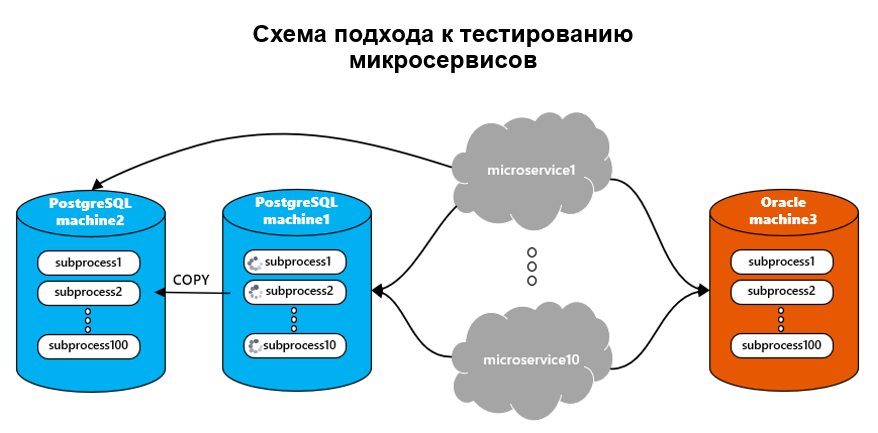
Сервисы имеют подключения к обеим базам данных, но конкретно поднятая версия сервисов работает только с одной базой, постгресом или ораклом. Режим работы с какой базой работает сервис переключается редеплоем сервисов, что можно делать, например массовым запуском пайплайнов. В самих сервисах репозитории с родным sql-кодом вынесены в каталог Oracle, рядом добавлены репозитории для PostgreSql, если были изменения в запросах. За переключение сервисов отвечал общий компонент, подключаемый как зависимость, в котором было описано с какой БД идет взаимодействие, и который определял используемые драйверы, адреса и реквизиты подключений и т.д.
Таким образом, можно было поднять сервисы с подключением к postgreSQL, провести расчет, потом передеплоить сервисы и переключить на Oracle, провести расчет на этих же данных и сравнить результаты. В случае расхождений результатов можно было сравнить версии репозиториев для Oracle и для postgreSQL для конкретной версии микросервиса, а чтобы догонять разработку по микросервисам, идущую в основой ветке, достаточно было сделать merge request по сервису из основной ветки в ветку с миграцией, чтобы увидеть разницу в коде для репозиториев в каталоге Oracle и синхронизировать с изменениями репозитории для postgreSQL.
В заключении хочу добавить, что миграция СУБД — это и творческая, и кропотливая работа, но в любом случае интересная, затрагивающая не только саму базу данных, но и все смежные с ней процессы. Спасибо за внимание!

 habr.com
habr.com
Описание бизнес-кейса и решения AS IS
Для начала расскажу немного о системе, в рамках которой была поставлена задача миграции СУБД. Система представляла из себя решение с микросервисной архитектурой, главной целью которой является расчет агрегатов по клиентам. Все данные расчета обрабатываются и хранятся в Oracle, верхнеуровневая схема взаимодействия с базой изображена на схеме ниже.
Расчет, далее буду его также называть процесс, обычно производится на количестве от 60 млн. до 100 млн. клиентов со всеми сопутствующими им данными (история обращений клиента, его финансовые показатели и т.д.), занимает порядка 3-4 дней и выглядит как загрузка данных по клиентам из витрины данных (Data Mart) объемом примерно 600 гб., далее расчет агрегатов по клиентам и обогащение данными по ним из внешних систем, а в конце отгрузка результата объемом ~2 тб. в корпоративное хранилище данных (КХД).
Сам расчет технически выглядит как исполняемая bpmn-схема с использованием Camunda, в которой оркестрируются вызовы микросервисов.
Справочная информация о Camunda
На уровне схемы процесс разделяется на несколько, обычно 10, подпроцессов, которые обрабатываются параллельно и оперируют над логически независимыми друг от друга данными.
Таким образом, с базой взаимодействуют 10 параллельных подпроцессов в рамках одного расчета, если в расчете 100 млн. клиентов, то в каждом подпроцессе их будет по 10 млн. и все данные по клиентам лежат в рамках подпроцесса. Таких расчетов на базе одновременно может быть несколько, у каждого из них есть свой SLA, и они должны считаться параллельно и независимо друг от друга. И собственно задача стояла — мигрировать систему с Oracle на PostgreSQL с учетом всей этой логики.
Тестирование Greenplum
Первой остановкой в поисках альтернативы Oracle стала СУБД Greenplum, которая уже использовалась клиентом для формирования отчетности на КХД и была предложена в качестве альтернативы Oracle из-за смешанного характера нагрузки в системе: расчет больше напоминал OLAP при расчете агрегатов на клиентах, но и включал в себя элементы OLTP при закачке данных из внешних систем.
Справочная информация о Greenplum
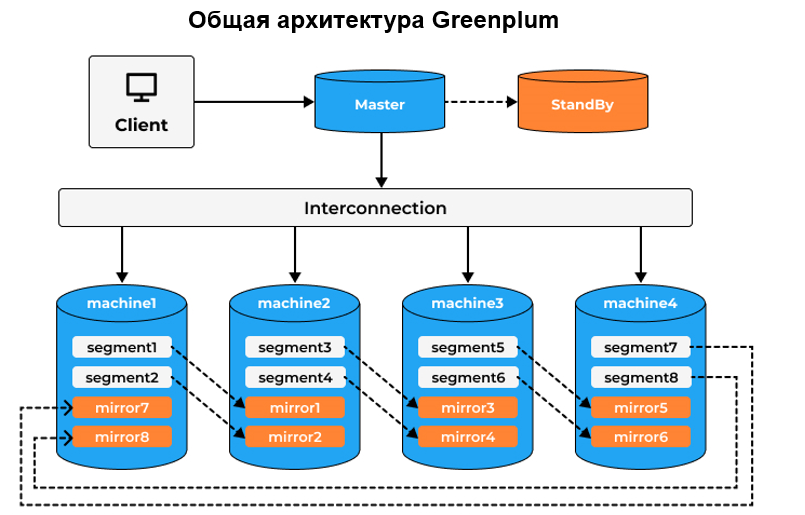
Типичная архитектура Greenplum приведена на схеме ниже. Есть мастер хост, который является координатором и входной точкой для пользователей и сегменты, в рамках которых происходит обработка и хранение данных. Мастер хост и сегменты являются инстансами PostgreSQL. Еще один компонент — interconnect — обеспечивает внутреннее взаимодействие в базе.Greenplum — аналитическая, распределённая СУБД, построенная на MPP-системе с открытым исходным кодом Greenplum. Она предназначена для хранения и обработки больших объёмов информации — до десятков петабайт.
Таким образом, одним из главных преимуществ Greenplum является удобная горизонтальная масштабируемость за счет добавления новых хостов с минимальным простоем и параллельная обработка процессов на этих хостах.
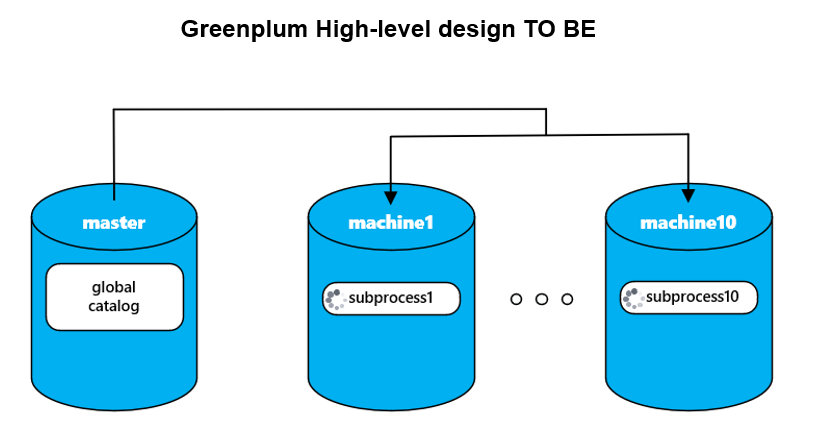
Целевая архитектура, которая тестировалась при внедрении Greenplum, приведена схематично на рисунке ниже.
В ней ожидалось, что каждому подпроцессу расчета выделится свой сегмент, на котором будут рассчитываться все клиенты из этого подпроцесса. А поскольку количество подпроцессов в расчете — изменяемый параметр, то это значило бы, что можно уменьшить время всего расчета за счет добавления новых хостов и сегментов и увеличения количества параллельных подпроцессов, что возможно благодаря хорошей горизонтальной масштабируемости Greenplum.
Если кратко, то основной причиной, почему это решение не взлетело, стала недостаточная эффективность обработки OLTP нагрузки при использовании Greenplum. Особенно это стало явно, когда в рамках подпроцесса ETL-механизм собирал данные по клиентам, по которым нужно было получить информацию во внешней системе. Тогда выполнялся запрос к базе на получение этих клиентов, но т.к. логически они лежали в рамках одного подпроцесса, а физически были равномерно распределены по хостам Greenplum, то СУБД приходилось их собирать воедино и уже после формировать ответ, вместо обработки всех данных по подпроцессу внутри одного хоста. В мониторинге при этом тестировании было видно высокое потребление сетевых ресурсов.
Помимо этого, есть еще несколько особенностей, которые сыграли не в пользу Greenplum:
- Устаревшая версия PostgreSQL. На момент тестирования прототипа инстансы PostgreSQL имели 8+ версию, что как минимум усложняло миграцию хранимых процедур из Oracle в PostgreSQL.
- Отсутствие поддержки у самого Greenplum, необходимость внедрения решений на основе Greenplum, которые обеспечены поддержкой их разработчиков.
- Необходимость обеспечивать поддержку ряда серверов (вместо одного с Oracle), на которых подняты инстансы PostgreSQL, а также наращивание «зоопарка» СУБД, которые нужно поддерживать.
По итогам тестирования было решено вместо горизонтального шардирования базы по хостам попробовать вертикальное шардирование таблиц на одном хосте PostgresSQL, и вот что из этого вышло.
Целевая архитектура TO BE с использованием PostgreSQL
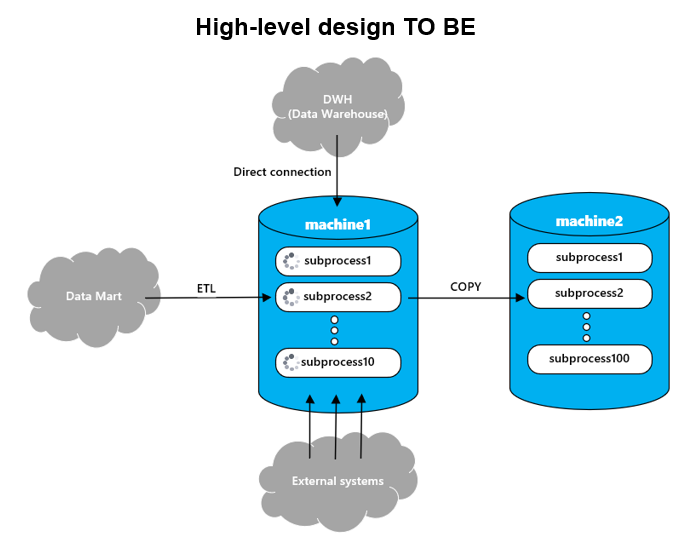
В новой архитектуре, изображенной на схеме выше, видно, что в итоге база была разделена на две, что связано, во-первых, с желанием вынести формирование отчетности с тяжеленными запросами на отдельную базу, и, во-вторых, вынести архивные данные, чтобы они не мешали идущим расчетам. В итоге на машине один (machine1), далее буду называть ее расчетная база, выполняются текущие расчеты, а на машине два (machine2), далее архивная база, формируется оперативная отчетность и в нее сливаются архивные данные завершенных расчетов.
Преимущества такой архитектуры:
- Уменьшение объема данных, задействованных в процессе расчета, повышает эффективность запросов и упрощает обслуживание таблиц.
- Разные профили нагрузки баз, OLAP и OLTP, позволяют подогнать под них конфигурацию самого постгреса (например, выделить больше места для хоста с отчетностью), подобрать индексы, нужные только для этого типа нагрузки и т.д.
- Приятным бонусом служит наличие утилиты pg_copy, позволяющей обеспечивать ETL-процессы между двумя инстансами постгреса в десятки раз быстрее некоторых других промышленных ETL-решений.
Структура базы данных тоже подверглась изменениям: теперь большинство таблиц, используемых для расчета (подпроцесса), стали партицированными по id конкретного подпроцесса. Так, если в двух параллельных расчетах выполняется по 10 подпроцессов, то, например, в таблице CUSTOMER с данными по клиентам будет 20 партиций, каждая из которых соответствует своему подпроцессу.
Помимо органичного внедрения партиций в этом бизнес-процессе было еще как минимум одно преимущество: обслуживание одной непартицированной таблицы, в частности вызов VACCUM, выполняется сложнее по сравнению с тем, если таблицу партицировать. В случае партицированной таблицы VACUUM можно вызывать отдельно для каждой партиции на меньшем объеме данных, что сильно упрощает задачу. Для примера в проекте на bpmn-схеме был сделан отдельный вызов микросервиса, который вызывает VACUUM ANALYZE после окончания перекачки всех данных в базу в рамках этого подпроцесса, и так по итогу по этим партициям уже запросы выполняются на актуальной статистике.
В следующих разделах погрузимся глубже в детали реализации и остановиться на некоторых важных моментах, которые всплыли в процессе миграции на PostgreSQL.
Проблемы и решения при миграции с Oracle на PostgreSQL
Первое, с чем столкнулись при внедрении партиций — необходимость ими управлять, т.е. создавать, очищать и т.д., при этом необходимо было обеспечить параллельность этих процессов. Далее рассмотрим их подробнее, а для демонстрации примеров была создана упрощенная тестовая схема с таблицами и сиквенсом.
DDL объектов тестовой схемы
set search_path="test"
create sequence test_customer_seq;
/* данные о расчетах */
create table PROCESS(
process_id int,
row_cnt int,
CONSTRAINT process_pk PRIMARY KEY (process_id)
)
/* данные подпроцессов в расчетах */
create table SUBPROCESS(
subprocess_id int,
process_id int not null,
row_cnt int,
CONSTRAINT subprocess_pk PRIMARY KEY (subprocess_id)
)
/* данные клиентов в расчетах */
create table CUSTOMER(
customer_id int default nextval('test_customer_seq') not null,
process_id int not null,
subprocess_id int not null,
test_flg bool default false,
CONSTRAINT customer_pk PRIMARY KEY (customer_id, subprocess_id)
) partition by list (subprocess_id);
Создание партиций
Пример: допустим есть активный расчет, который читает данные из таблицы, на скриншоте ниже это левая сессия с запросом к таблице CUSTOMER, который выполнился, но транзакция не завершена. В правой части в отдельной сессии пытаемся создать партицию для нового подпроцесса и видим, что она зависла.
В pgAdmin в мониторинге блокировок видим, что вторая сессия пытается наложить эксклюзивную блокировку на CUSTOMER, но безуспешно т.к. Granted = false, т.е. по сути наш запрос к таблице блокирует вторую сессию на создание партиции.
Поправим эту ситуацию присоединением таблицы в качестве партиции. На скриншоте все та же сессия с запросом к CUSTOMER, которую не закрываем, а во второй сессии создаем таблицу и присоединяем ее как партицию к основной таблице CUSTOMER для подпроцесса 101. Сессии успешно отработали, т.е. по итогу не блокируют друг друга.
Сам механизм создания партиции можно автоматизировать: например создать триггер на вставку записи в таблицу subprocess, чтобы все партицированные по subprocess_id таблицы создавали свои партиции в функции триггера, либо создать процедуру с созданием партиции и вызывать ее из сервиса по команде от оркестратора.
Очистка партиций
С очисткой партиций тоже похожая ситуация, здесь во второй сессии мы пытаемся почистить одну из партиций с помощью TRUNCATE, и она тоже безуспешно зависает.
На мониторинге блокировок также видим эксклюзивную блокировку на партицию, которую сессия не может получить.
Поправим дело изменением запроса на delete from без предиката для полной очистки таблицы, при таком подходе видим, что сессии отработали и не мешают друг другу.
Стоит отметить, что после очистки важно выполнить VACUUM по таблице (партиции), чтобы держать по ней актуальную информацию в базе. Вопрос параллельной очистки может быть важен в случае параллельной перекачки данных для обеспечения идемпотентности: т.е. при любом старте перекачки в подпроцессе мы очищаем все связанные с ним партиции, чтобы всегда гарантированно перекачивать в пустые таблицы, если, например, в прошлой попытке перекачки пошло что то не так и она упала на полпути.
Мониторинг обслуживания таблиц
Ранее я несколько раз упомянул разные примеры с использованием VACUUM и необходимостью заниматься обслуживанием таблиц. Мониторить состояние таблиц можно с помощью представлений (view) pg_stat_user_tables или pg_stat_all_tables, и это особенно удобно при использовании партицирования, т.к. каждая партиция — тоже таблица, а таких партиций в таблицах может быть очень много. В представлениях указываются, среди прочего, дата последнего автовакуума и автоматического сбора статистики, даты их ручных вызовов, что может служить одним из индикаторов того, что в базе есть проблемы, если даты старые.
Мониторинг использования индексов
Другим удобным представлением является pg_stat_user_indexes. Т.к. в Oracle уже был набор индексов, то мы попробовали их перенести как есть на postgreSQL и провести нагрузочное тестирование. С помощью pg_stat_user_indexes стало понятно, какие индексы из созданных совсем не используются (в столбце idx_scan 0). Эти индексы стали кандидатами на удаление (исключая автоматически созданные индексы вроде индексов первичных ключей), а остальные индексы остались, что позволило не начинать с 0 их разработку, а частично переиспользовать то, что уже было.
Ограничения (constraints) для оптимизации планов запросов
Для случаев, когда необходимо получить данные по нескольким партициям, будут сканироваться все партиции этой таблицы, т.к. нет предиката с ключом партицирования. Посмотрим на примере: попробуем получить всех клиентов в расчете и построить план запроса.
В примере на скриншоте партиции subprocess_100 и subprocess_101 относятся к process_id = 1, а subprocress_200 относится к process_id = 2, но при запросе на получение всех данных по process_id = 1 сканируется лишняя партиция subprocess_200 (да и в принципе все партиции таблицы). Если бы было больше партиций и данных в них, то даже такой запрос выполнялся бы до его прерывания по таймауту в базе (если еще он настроен), т.к. план запроса улетел бы в бесконечность.
Поправим ситуацию, добавив в каждую партицию ограничение по process_id, т.к. известно, что в рамках партиции оно принимает одно значение (т.к. подпроцесс принадлежит всегда только одному расчету).
После добавления ограничений в плане запроса видно, что сканируются только нужные партиции.
Конфигурация PostgreSQL
Я уже упоминал ранее, что разделение одной базы на несколько по профилям нагрузки позволило оптимизировать выделяемые ресурсы для каждой базы в соответствии с ее задачами. Но, помимо этого, необходимо было в конфигурации базы увеличить параметр max_locks_per_transaction и найти оптимальное значение для temp_file_limit.
Справка по max_locks_per_transaction и temp_file_limit
max_locks_per_transaction
temp_file_limitПараметр управляет средним числом блокировок объектов, выделяемым для каждой транзакции
Specifies the maximum amount of disk space that a process can use for temporary files, such as sort and hash temporary files, or the storage file for a held cursor
В max_locks_per_transaction можно упереться при использовании партиций, т.к. сами партиции тоже таблицы, а если над ними выполняются тяжелые аналитические запросы, то на них на все накладываются блокировки, что может быстро исчерпать выставленный в параметре лимит.
С temp_file_limit все немного сложнее. На практике столкнулись с проблемой, что необходимо, например, добавить новую колонку в таблице, но если данных в ней много, то при выполнении DDL-запроса создается временный файл, которому нужно будет больше места, чем указано в этом параметре. Тогда перед поставкой релиза необходимо оценивать объем создаваемых временных файлов, увеличивать на продуктивной среде, а после поставки возвращать обратно. Мониторить ситуацию с временными файлами помогает представление pg_stat_database.
В нем в temp_files указывается количество созданных файлов, а в temp_bytes их объем.
Миграция данных, модели данных и хранимых процедур
Миграция данных, модели данных и хранимых процедур (и остальной накрученной логики в базе) составляют основу миграции, но сперва нужно решить вопрос, идущий в паре с ними: стоит ли рефакторить сразу модель данных и вообще части системы, вместо того, чтобы перенести как есть и отрефакторить потом? С одной стороны, нет, мы не хотим влиять на логику процедур, которая зависит от изменений в модели, ведь даже рефакторинг одной такой таблицы может привести к необходимости полного регресса всей системы. С другой стороны, после миграции на новую СУБД крайне вероятно потребуется провести регресс системы, полное функциональное и нефункциональное тестирование. Поскольку в моем проекте базу для такого тестирования только предстояло разработать, то было решено сразу внедрить и оптимизационные решения вроде рефакторинга модели.
Что касается миграции данных, то специфика системы, а именно отдельные расчеты клиентов, не требовала мигрировать данные предыдущих расчетов (десятки терабайтов), тем более что они уже были выгружены в КХД. Требовалось лишь перенести конфигурацию системы обычным liquibase с возможностью донастроить ее через UI.
Справочная информация о Liquibase
Liquibase — это независимая от базы данных библиотека с открытым исходным кодом для отслеживания, управления и применения изменений схемы базы данных.
Миграция модели данных
Большие изменения претерпела модель данных. Они коснулись, например, всех флагов, которые лежали в базе как число, а затем преобразовались в тип boolean в PostgreSQL. По многим атрибутам была проделана кропотливая работа, чтобы определить, кто источник данных и какой размер атрибута реально нужен, и, по возможности, его уменьшить. Во всех представлениях, с которыми работает ETL или внешние системы, была произведена обратная конвертация к исходному типу до конвертации, т.к. обычно в больших корпоративных структурах одно поле может тянуться в ряд систем, и соответственно, изменение типа в источнике может обрушить все интеграции по цепочке разом.
Миграция хранимых процедур
Есть ряд решений по автоматической миграции процедур типа Ora2PG и других, но поскольку в базе лежала только бизнесовая логика для расчета агрегатов, с которой мы уже какое то время работали на оракле и имели хорошее представление о ней, то вручную нам это перевести было намного проще. Другой вопрос — как это все тестировать? При обработке объемов клиентов порядка десятков миллионов возникает огромное количество сценариев, а не прекращающаяся разработка процедур в Oracle под нужды бизнеса вынуждает регулярно проводить повторное тестирование. С этим сильно помогли автотесты: они позволили, с одной стороны, покрыть все тестовые кейсы без необходимости постоянного прогона расчета с 0, и, с другой стороны, база автотестирования при добавлении нового инкремента функциональности позволяла достаточно быстро проводить регресс существующего функционала.
Изменения в микросервисах
При доработке микросервисов было важно учесть следующее:
- Эти же микросервисы в основной ветке в Git продолжались разрабатываться под Oracle, пока в отдельной ветке Git мы занимались их доработкой в связи с миграцией на PostgreSQL;
- Клиент в качестве тестирования хотел иметь возможность запустить расчет на тестовых данных на Oracle, затем запустить расчет на PostgreSQL на этих же данных и сравнить результаты для валидации корректности бизнес-логики.
В связи с этим был выбран подход внедрения на продуктивную среду, верхнеуровнево изображенный на схеме взаимодействия микросервисов с БД ниже.
Сервисы имеют подключения к обеим базам данных, но конкретно поднятая версия сервисов работает только с одной базой, постгресом или ораклом. Режим работы с какой базой работает сервис переключается редеплоем сервисов, что можно делать, например массовым запуском пайплайнов. В самих сервисах репозитории с родным sql-кодом вынесены в каталог Oracle, рядом добавлены репозитории для PostgreSql, если были изменения в запросах. За переключение сервисов отвечал общий компонент, подключаемый как зависимость, в котором было описано с какой БД идет взаимодействие, и который определял используемые драйверы, адреса и реквизиты подключений и т.д.
Таким образом, можно было поднять сервисы с подключением к postgreSQL, провести расчет, потом передеплоить сервисы и переключить на Oracle, провести расчет на этих же данных и сравнить результаты. В случае расхождений результатов можно было сравнить версии репозиториев для Oracle и для postgreSQL для конкретной версии микросервиса, а чтобы догонять разработку по микросервисам, идущую в основой ветке, достаточно было сделать merge request по сервису из основной ветки в ветку с миграцией, чтобы увидеть разницу в коде для репозиториев в каталоге Oracle и синхронизировать с изменениями репозитории для postgreSQL.
Заключение
В заключении хочу добавить, что миграция СУБД — это и творческая, и кропотливая работа, но в любом случае интересная, затрагивающая не только саму базу данных, но и все смежные с ней процессы. Спасибо за внимание!
Миграция базы данных с Oracle на PostgreSQL в системе с микросервисной архитектурой
Привет! Эта статья рассказывает о моем опыте миграции СУБД с Oracle на PostgreSQL в системе с микросервисной архитектурой и является продолжением моего доклада на PGConf.Russia 2023. Я постарался...
habr.com