Рассмотрим концепцию мониторинга Kubernetes, познакомимся с инструментом Prometheus, поговорим про алёртинг.
Тема мониторинга объёмная, за одну статью её не разобрать. Цель этого текста — дать обзорное представление по инструментарию, концепциям и подходам.
Материал статьи — выжимка из открытой лекции школы «Слёрм». Если хотите пройти полное обучение — записывайтесь на курс по Мониторингу и логированию инфраструктуры в Kubernetes.

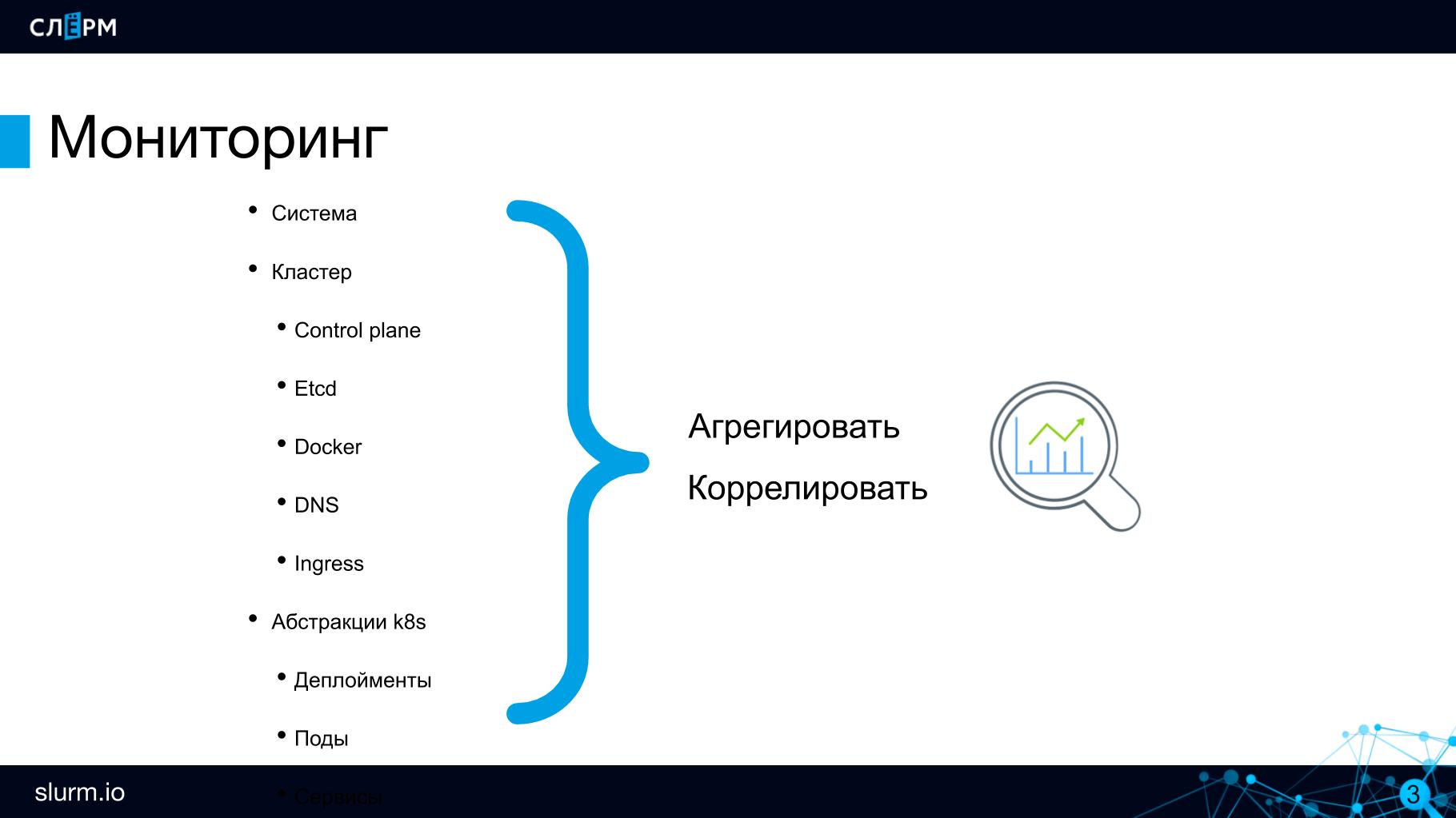
Физические серверы. Если кластер Kubernetes развёрнут на своих серверах, нужно следить за их здоровьем. С этой задачей справляется Zabbix; если вы с ним работаете, то не нужно отказываться, конфликтов не будет. За состоянием наших серверов следит именно Zabbix.
Перейдём к мониторингу на уровне кластера.
Control Plane компоненты: API, Scheduler и другие. Как минимум, надо отслеживать, чтобы API серверов или etcd было больше 0. Etcd умеет отдавать много метрик: по дискам, на которых он крутится, по здоровью своего кластера etcd и другие.
Docker появился давно и о его проблемах всем хорошо известно: множество контейнеров порождают зависания и прочие проблемы. Поэтому сам Docker, как систему, тоже стоит контролировать, хотя бы на доступность.
DNS. Если в кластере отвалится DNS, то за ним отвалится и весь сервис Discovery, перестанут работать обращения от подов к подам. В моей практике подобных проблем не было, однако это не значит, что за состоянием DNS не нужно следить. Задержки в запросах и некоторые другие метрики можно отслеживать на CoreDNS.
Ingress. Нужно контролировать доступность ингрессов (в том числе Ingress Controller) как входных точек в проект.
Основные компоненты кластера разобрали — теперь опустимся ниже, на уровень абстракций.
Казалось бы, приложения запускаются в подах, значит их нужно контролировать, но на самом деле нет. Поды эфемерны: сегодня работают на одном сервере, завтра на другом; сегодня их 10, завтра 2. Поэтому просто поды никто не мониторит. В рамках микросервисной архитектуры важнее контролировать доступность приложения в целом. В частности, проверять доступность эндпоинтов сервиса: работает ли хоть что-то? Если приложение доступно, то что происходит за ним, сколько сейчас реплик — это вопросы второго порядка. Следить за отдельными инстансами нет необходимости.
На последнем уровне нужно контролировать работу самого приложения, снимать бизнес-метрики: количество заказов, поведение пользователей и прочее.
Лучшая система для мониторинга кластера — это Prometheus. Я не знаю ни одного инструмента, который может сравниться с Prometheus по качеству и удобству работы. Он отлично подходит для гибкой инфраструктуры, поэтому когда говорят «мониторинг Kubernetes», обычно имеют в виду именно Prometheus.
Есть пара вариантов, как начать работать с Prometheus: с помощью Helm можно поставить обычный Prometheus или Prometheus Operator.
Чтобы разобраться с продуктом, я рекомендую сначала поставить обычный Prometheus. Придётся всё настраивать через конфиг, но это пойдёт на пользу: разберётесь, что к чему относится и как настраивается. В Prometheus Operator вы сразу поднимаетесь на абстракцию выше, хотя при желании покопаться в глубинах тоже будет можно.
Prometheus хорошо интегрирован с Kubernetes: может обращаться к API Server и взаимодействовать с ним.
Prometheus популярен, поэтому его поддерживает большое количество приложений и языков программирования. Поддержка нужна, так как у Prometheus свой формат метрик, и для его передачи необходима либо библиотека внутри приложения, либо готовый экспортёр. И таких экспортёров довольно много. Например, есть PostgreSQL Exporter: он берёт данные из PostgreSQL и конвертирует их в формат Prometheus, чтобы Prometheus мог с ними работать.
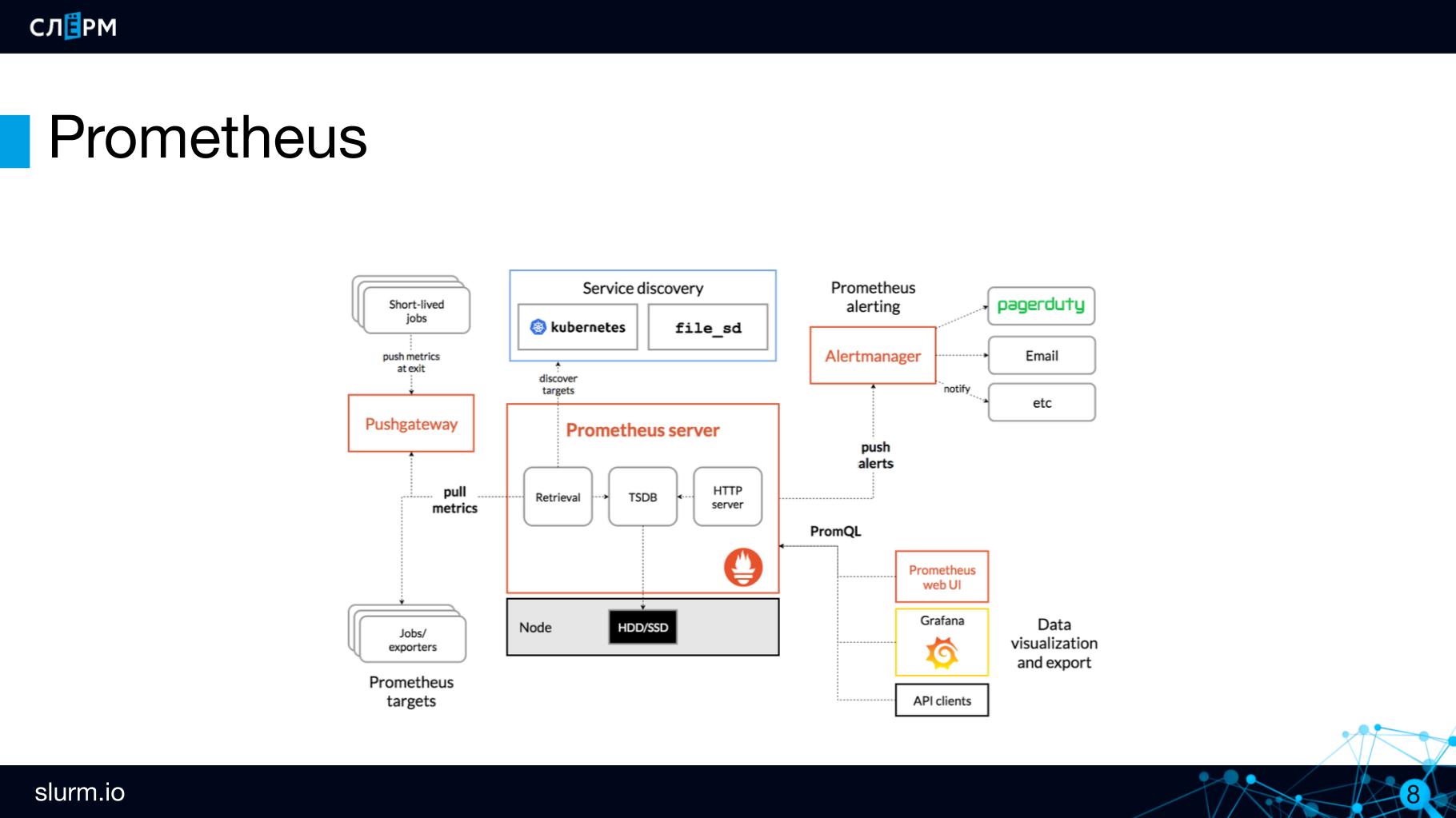
Prometheus Server — это серверная часть, мозг Prometheus. Здесь хранятся и обрабатываются метрики.
Метрики хранит time series database (TSDB). TSDB — это не отдельная база данных, а пакет на языке Go, который вшит в Prometheus. Грубо говоря, всё находится в одном бинаре.
Для объектов с короткой продолжительностью жизни (job или cron job), которые могут появляться между периодами скрапинга, есть компонент Pushgateway. В него пушатся метрики от краткосрочных объектов: job поднялся, выполнил действие, отправил метрики в Pushgateway и завершился. Через некоторое время Prometheus в своём ритме сходит и заберёт эти метрики из Pushgateway.
Для настройки уведомлений в Prometheus есть отдельный компонент — Alertmanager. И правила алёртинга — alerting rules. Например, нужно создавать alert в случае, если API серверов 0. Когда событие срабатывает, alert передаётся в alert manager для дальнейшей отправки. В alert manager достаточно гибкие настройки роутинга: одну группу алертов можно отправлять в телеграм-чат админов, другую в чат разработчиков, третью в чат инфраструктурщиков. Оповещения могут приходить в Slack, Telegram, на email и в другие каналы.
Ну и напоследок расскажу про киллер-фичу Prometheus — Discovering. При работе с Prometheus не нужно указывать конкретные адреса объектов для мониторинга, достаточно задать их тип. То есть не надо писать «вот IP-адрес, вот порт — мониторь», вместо этого нужно определить, по каким принципам находить эти объекты (targets — цели). Prometheus сам, в зависимости от того, какие объекты сейчас активны, подтягивает к себе нужные и добавляет на мониторинг.
Такой подход хорошо ложится на структуру Kubernetes, где тоже всё плавает: сегодня 10 серверов, завтра 3. Чтобы каждый раз не указывать IP-адрес сервера, один раз написали, как его находить — и Discovering будет это делать.
Язык Prometheus называется PromQL. С помощью этого языка можно доставать значения конкретных метрик и потом их преобразовывать, строить по ним аналитические выкладки.

 prometheus.io
prometheus.io
Простой запрос
container_memory_usage_bytes
Математические операции
container_memory_usage_bytes / 1024 / 1024
Встроенные функции
sum(container_memory_usage_bytes) / 1024 / 1024
Уточнение запроса
100 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m]) * 100)
У Prometheus есть свой, довольно минималистичный веб-интерфейс. Подходит разве что для дебага или демонстрации.

В строке Expression можно писать запрос на языке PromQL.
Во вкладке Alerts содержатся правила алертов — alerting rules, и у них есть три статуса:
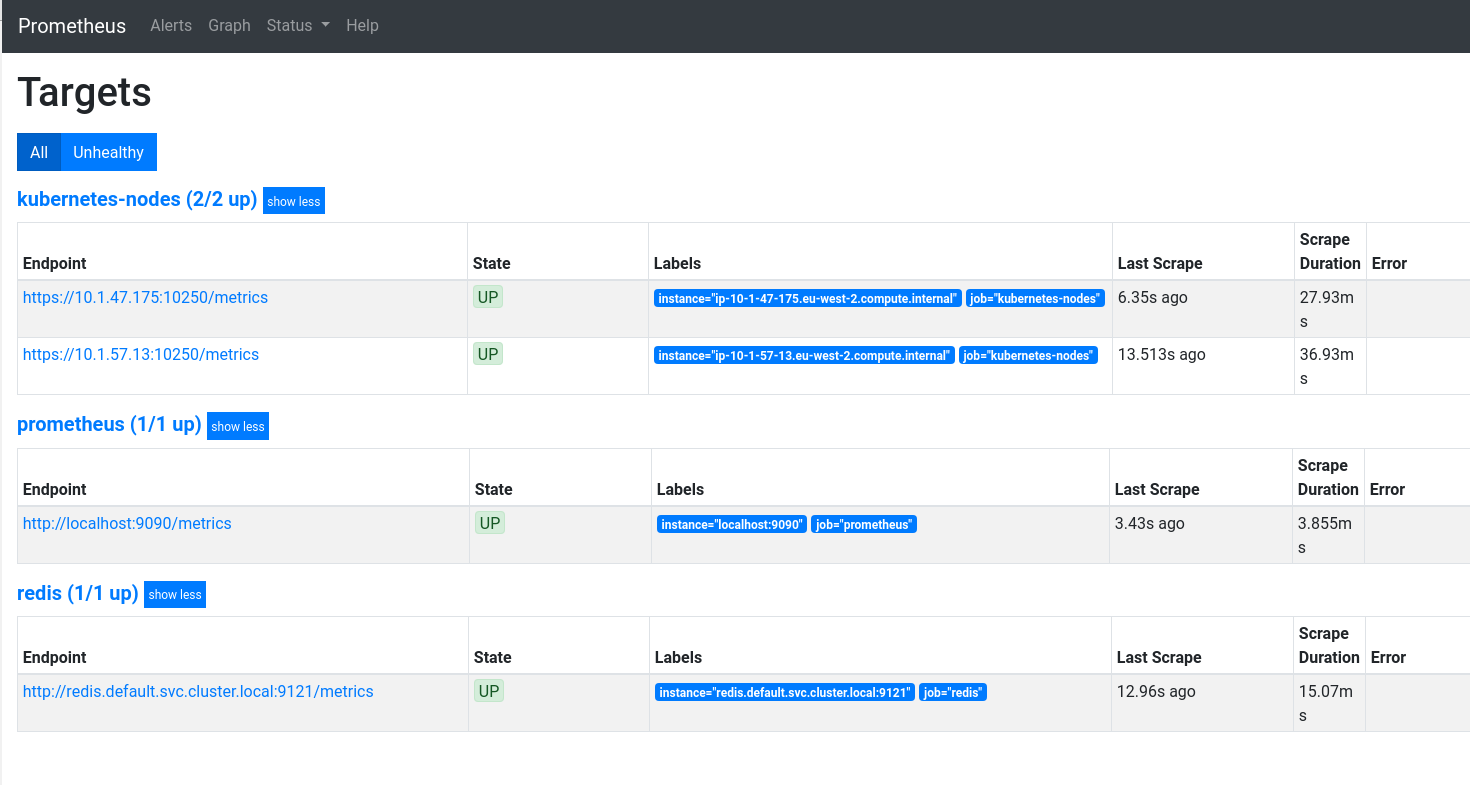
В меню Status найдёте доступ к информации о том, что из себя представляет Prometheus. Там же есть переход к целям (targets), о которых мы говорили выше.
Более подробный обзор интерфейса Prometheus смотрите в лекции Слёрм по мониторингу кластера Kubernetes.
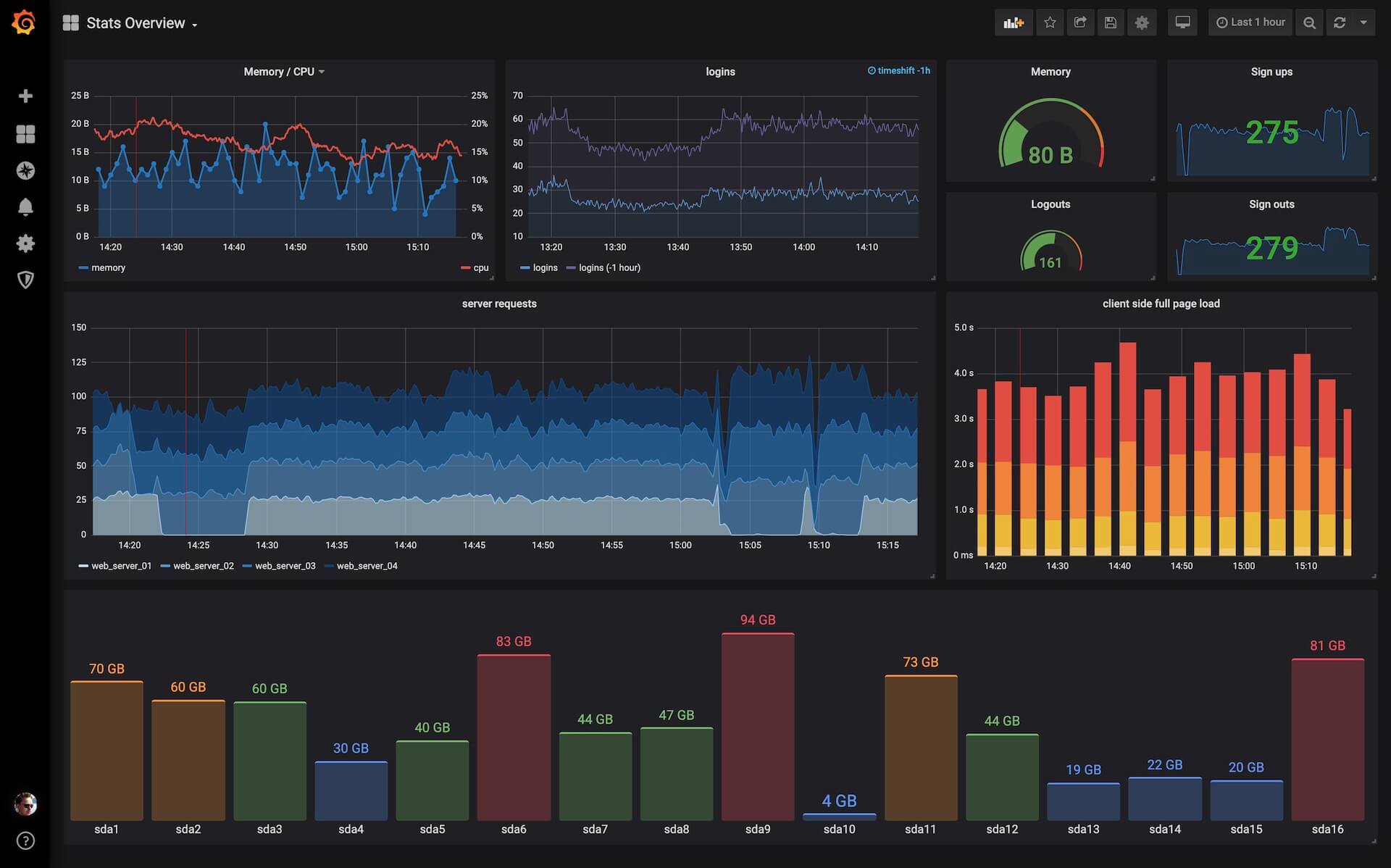
В веб-интерфейсе Prometheus вы не найдёте красивых и понятных графиков, из которых можно сделать вывод о состоянии кластера. Чтобы их строить, Prometheus интегрируют с Grafana. Получаются вот такие дашборды.
Настроить интеграцию Prometheus и Grafana совсем несложно, инструкции найдёте в документации: GRAFANA SUPPORT FOR PROMETHEUS, ну а я на этом закончу.
Источник статьи: https://habr.com/ru/company/southbridge/blog/516748/
Тема мониторинга объёмная, за одну статью её не разобрать. Цель этого текста — дать обзорное представление по инструментарию, концепциям и подходам.
Материал статьи — выжимка из открытой лекции школы «Слёрм». Если хотите пройти полное обучение — записывайтесь на курс по Мониторингу и логированию инфраструктуры в Kubernetes.
Что мониторят в кластере Kubernetes
Физические серверы. Если кластер Kubernetes развёрнут на своих серверах, нужно следить за их здоровьем. С этой задачей справляется Zabbix; если вы с ним работаете, то не нужно отказываться, конфликтов не будет. За состоянием наших серверов следит именно Zabbix.
Перейдём к мониторингу на уровне кластера.
Control Plane компоненты: API, Scheduler и другие. Как минимум, надо отслеживать, чтобы API серверов или etcd было больше 0. Etcd умеет отдавать много метрик: по дискам, на которых он крутится, по здоровью своего кластера etcd и другие.
Docker появился давно и о его проблемах всем хорошо известно: множество контейнеров порождают зависания и прочие проблемы. Поэтому сам Docker, как систему, тоже стоит контролировать, хотя бы на доступность.
DNS. Если в кластере отвалится DNS, то за ним отвалится и весь сервис Discovery, перестанут работать обращения от подов к подам. В моей практике подобных проблем не было, однако это не значит, что за состоянием DNS не нужно следить. Задержки в запросах и некоторые другие метрики можно отслеживать на CoreDNS.
Ingress. Нужно контролировать доступность ингрессов (в том числе Ingress Controller) как входных точек в проект.
Основные компоненты кластера разобрали — теперь опустимся ниже, на уровень абстракций.
Казалось бы, приложения запускаются в подах, значит их нужно контролировать, но на самом деле нет. Поды эфемерны: сегодня работают на одном сервере, завтра на другом; сегодня их 10, завтра 2. Поэтому просто поды никто не мониторит. В рамках микросервисной архитектуры важнее контролировать доступность приложения в целом. В частности, проверять доступность эндпоинтов сервиса: работает ли хоть что-то? Если приложение доступно, то что происходит за ним, сколько сейчас реплик — это вопросы второго порядка. Следить за отдельными инстансами нет необходимости.
На последнем уровне нужно контролировать работу самого приложения, снимать бизнес-метрики: количество заказов, поведение пользователей и прочее.
Prometheus
Лучшая система для мониторинга кластера — это Prometheus. Я не знаю ни одного инструмента, который может сравниться с Prometheus по качеству и удобству работы. Он отлично подходит для гибкой инфраструктуры, поэтому когда говорят «мониторинг Kubernetes», обычно имеют в виду именно Prometheus.
Есть пара вариантов, как начать работать с Prometheus: с помощью Helm можно поставить обычный Prometheus или Prometheus Operator.
- Обычный Prometheus. С ним всё хорошо, но нужно настраивать ConfigMap — по сути, писать текстовые конфигурационные файлы, как мы делали раньше, до микросервисной архитектуры.
- Prometheus Operator чуть развесистее, чуть сложнее по внутренней логике, но работать с ним проще: там есть отдельные объекты, абстракции добавляются в кластер, поэтому их гораздо удобнее контролировать и настраивать.
Чтобы разобраться с продуктом, я рекомендую сначала поставить обычный Prometheus. Придётся всё настраивать через конфиг, но это пойдёт на пользу: разберётесь, что к чему относится и как настраивается. В Prometheus Operator вы сразу поднимаетесь на абстракцию выше, хотя при желании покопаться в глубинах тоже будет можно.
Prometheus хорошо интегрирован с Kubernetes: может обращаться к API Server и взаимодействовать с ним.
Prometheus популярен, поэтому его поддерживает большое количество приложений и языков программирования. Поддержка нужна, так как у Prometheus свой формат метрик, и для его передачи необходима либо библиотека внутри приложения, либо готовый экспортёр. И таких экспортёров довольно много. Например, есть PostgreSQL Exporter: он берёт данные из PostgreSQL и конвертирует их в формат Prometheus, чтобы Prometheus мог с ними работать.
Архитектура Prometheus
Prometheus Server — это серверная часть, мозг Prometheus. Здесь хранятся и обрабатываются метрики.
Метрики хранит time series database (TSDB). TSDB — это не отдельная база данных, а пакет на языке Go, который вшит в Prometheus. Грубо говоря, всё находится в одном бинаре.
Prometheus Server работает по модели pull: сам ходит за метриками в те эндпоинты, которые мы ему передали. Сказали: «ходи в API Server», и он раз в n-ое количество секунд туда ходит и забирает метрики.Не храните данные в TSDB долго
Инфраструктура Prometheus не подходит для длительного хранения метрик. По умолчанию срок хранения составляет 15 дней. Можно это ограничение превысить, но надо иметь в виду: чем больше данных вы будете хранить в TSDB и чем дольше будете это делать, тем больше ресурсов она будет потреблять. Хранить исторические данные в Prometheus считается плохой практикой.
Если у вас огромный трафик, количество метрик исчисляется сотнями тысяч в секунду, то лучше ограничить их хранение по объёму диска или по сроку. Обычно в TSDB хранят «горячие данные», метрики буквально за несколько часов. Для более долгого хранения используют внешние хранилища в тех базах данных, которые действительно для этого подходят, например InfluxDB, ClickHouse и так далее. Больше хороших отзывов я видел про ClickHouse.
Для объектов с короткой продолжительностью жизни (job или cron job), которые могут появляться между периодами скрапинга, есть компонент Pushgateway. В него пушатся метрики от краткосрочных объектов: job поднялся, выполнил действие, отправил метрики в Pushgateway и завершился. Через некоторое время Prometheus в своём ритме сходит и заберёт эти метрики из Pushgateway.
Для настройки уведомлений в Prometheus есть отдельный компонент — Alertmanager. И правила алёртинга — alerting rules. Например, нужно создавать alert в случае, если API серверов 0. Когда событие срабатывает, alert передаётся в alert manager для дальнейшей отправки. В alert manager достаточно гибкие настройки роутинга: одну группу алертов можно отправлять в телеграм-чат админов, другую в чат разработчиков, третью в чат инфраструктурщиков. Оповещения могут приходить в Slack, Telegram, на email и в другие каналы.
Ну и напоследок расскажу про киллер-фичу Prometheus — Discovering. При работе с Prometheus не нужно указывать конкретные адреса объектов для мониторинга, достаточно задать их тип. То есть не надо писать «вот IP-адрес, вот порт — мониторь», вместо этого нужно определить, по каким принципам находить эти объекты (targets — цели). Prometheus сам, в зависимости от того, какие объекты сейчас активны, подтягивает к себе нужные и добавляет на мониторинг.
Такой подход хорошо ложится на структуру Kubernetes, где тоже всё плавает: сегодня 10 серверов, завтра 3. Чтобы каждый раз не указывать IP-адрес сервера, один раз написали, как его находить — и Discovering будет это делать.
Язык Prometheus называется PromQL. С помощью этого языка можно доставать значения конкретных метрик и потом их преобразовывать, строить по ним аналитические выкладки.
Querying basics | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
Простой запрос
container_memory_usage_bytes
Математические операции
container_memory_usage_bytes / 1024 / 1024
Встроенные функции
sum(container_memory_usage_bytes) / 1024 / 1024
Уточнение запроса
100 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m]) * 100)
Веб-интерфейс Prometheus
У Prometheus есть свой, довольно минималистичный веб-интерфейс. Подходит разве что для дебага или демонстрации.
В строке Expression можно писать запрос на языке PromQL.
Во вкладке Alerts содержатся правила алертов — alerting rules, и у них есть три статуса:
- inactive — если в данный момент алерт не активный, то есть по нему всё хорошо, и он не сработал;
- pending — это в случае, если алерт сработал, но отправка ещё не прошла. Задержку устанавливают, чтобы компенсировать мигания сети: если в течение минуты заданный сервис поднялся, то тревогу бить пока не надо;
- firing — это третий статус, когда алёрт загорается и отправляет сообщения.
В меню Status найдёте доступ к информации о том, что из себя представляет Prometheus. Там же есть переход к целям (targets), о которых мы говорили выше.
Более подробный обзор интерфейса Prometheus смотрите в лекции Слёрм по мониторингу кластера Kubernetes.
Интеграция с Grafana
В веб-интерфейсе Prometheus вы не найдёте красивых и понятных графиков, из которых можно сделать вывод о состоянии кластера. Чтобы их строить, Prometheus интегрируют с Grafana. Получаются вот такие дашборды.
Настроить интеграцию Prometheus и Grafana совсем несложно, инструкции найдёте в документации: GRAFANA SUPPORT FOR PROMETHEUS, ну а я на этом закончу.
Источник статьи: https://habr.com/ru/company/southbridge/blog/516748/