Недавно мной, совместно с коллегой, был реализован оператор для Kubernetes’a - Vector Operator. (Вот тут описано как мы пришли к решению, что там нужен свой оператор для Логирования в Kubernetes).
В рамках данной статьи я опишу разные интересные Задачи/Проблемы с которыми мы столкнулись в процессе разработки и как их решили.
При тестировании оператора в продакшн условиях, мы столкнулись с ошибкой, которая в логах выглядела так:
W1029 16:56:43.443740 81279 reflector.go:324] pkg/mod/k8s.io/client-go@v0.24.2/tools/cache/reflector.go:167: failed to list *v1.Secret: stream error when reading response body, may be caused by closed connection. Please retry. Original error: stream error: stream ID 155; INTERNAL_ERROR; received from peer
I1029 16:56:43.443865 81279 trace.go:205] Trace[1292523411]: "Reflector ListAndWatch" name kg/mod/k8s.io/client-go@v0.24.2/tools/cache/reflector.go:167 (29-Oct-2022 16:55:43.022) (total time: 60421ms):
kg/mod/k8s.io/client-go@v0.24.2/tools/cache/reflector.go:167 (29-Oct-2022 16:55:43.022) (total time: 60421ms):
Trace[1292523411]: ---"Objects listed" error:stream error when reading response body, may be caused by closed connection. Please retry. Original error: stream error: stream ID 155; INTERNAL_ERROR; received from peer 60421ms (16:56:43.443)
Trace[1292523411]: [1m0.4217365s] [1m0.4217365s] END
Аналитика
Когда мы выполняем Get какого-то объекта (дли примера - secret):
err := c.Get(ctx, client.ObjectKeyFromObject(desired), existing)
if err != nil {
return err
}
Контроллер пытается получить список ВСЕХ secret’ов, подписаться на изменение каждого и все это сохранить в cache. Secret’ов в кластере, где проходили тесты, очень много и operator просто не успевал выполнить получение всех secret’ов (он делает это одним запросом) и запрос отваливался по timeout.
Покопавшись в коде контроллера, мы поняли, что это его дефолтное поведение.
Решение
При регистрации менеджера нужно указать, какие ресурсы НЕ надо кэшировать. Указываем тут все ресурсы, с которыми работаем:
mgr, err := ctrl.NewManager(config, ctrl.Options{
Scheme: scheme,
...
...
ClientDisableCacheFor: []client.Object{&corev1.Secret{}, &corev1.ConfigMap{}, &corev1.Pod{}, &appsv1.Deployment{},
&appsv1.StatefulSet{}, &rbacv1.ClusterRole{}, &rbacv1.ClusterRoleBinding{}},
})
Одна из главных задач оператора - следить, что все объекты, которые он развернул находится в валидном состоянии. То есть если кто-то ручками в кластере поправит контролируемый оператором объект - оператор должен отловить это и вернуть все к “контролируемому” состоянию. (Возможно за исключением каких-то полей, но это вопрос про server-side apply, что достойно отдельной статьи и тут не рассматривается)
Аналитика
По умолчанию мы настроили Reconcile Vector’а, чтобы он срабатывал каждые 15 секунд. То есть каждые 15 секунд оператор запускает проверку, что все раскатанные ресурсы находятся в нужном состоянии.
Однако это выглядит как излишняя нагрузка. Чаще всего, запускаемый Reconcile ничего не делает.
Было бы прекрасно, если бы мы могли “подписаться” на все ресурсы, которые создаются для работы Vector’a и запускать Reconcile только если в этих ресурсах произошли какие-то изменения. И у нас есть такая возможность!
При инициализации Controller-Runtime Manager’а мы можем ему указать следующее:
func (r *VectorReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&vectorv1alpha1.Vector{}).
Owns(&appsv1.DaemonSet{}).
Owns(&corev1.Service{}).
Owns(&corev1.Secret{}).
Owns(&corev1.ServiceAccount{}).
Complete(r)
}
Если вкратце, то это означает:
W1029 16:56:43.443740 81279 reflector.go:324] pkg/mod/k8s.io/client-go@v0.24.2/tools/cache/reflector.go:167: failed to list *v1.Secret: stream error when reading response body, may be caused by closed connection. Please retry. Original error: stream error: stream ID 155; INTERNAL_ERROR; received from peer
I1029 16:56:43.443865 81279 trace.go:205] Trace[1292523411]: "Reflector ListAndWatch" namekg/mod/k8s.io/client-go@v0.24.2/tools/cache/reflector.go:167 (29-Oct-2022 16:55:43.022) (total time: 60421ms):
Trace[1292523411]: ---"Objects listed" error:stream error when reading response body, may be caused by closed connection. Please retry. Original error: stream error: stream ID 155; INTERNAL_ERROR; received from peer 60421ms (16:56:43.443)
Trace[1292523411]: [1m0.4217365s] [1m0.4217365s] END
Опять она. Возникает она по следующей причине.
При старте, Operator читает из Kubernetes API все обекты, типы которых перечисленны в Owns. Делает он это для того, чтобы проверить нет ли на момент старта Оператора каких-то объектов в кластере, у которых УЖЕ установлен Owner’ом наш Vector.
Логичное поведение, однако оно приводит к тому, что на высоконагруженных (скорее всего bare-metal) кластерах Kubernetes наш оператор будет постоянно спамить ошибками и падать. Да и нецелесообразно выглядит, когда оператор под капотом пытается выташить ВСЕ объекты какого-то типа из кластера.
Решение
Мы планируем иметь возможность импользование оператора на высогонагруженных и жирных кластерах Kubernetes, по этому нам пришлось вернуться к запуску Reconcile каждые 15 секунд.
Vector имеет определенную структуру для своего файла конфигурации. Архитектурно он состоит из 4 блоков:
Признаться честно - нам крайне не хотелось дублировать работу Vector’а и хранить где-то в операторе ВСЮ структуру конфигурационного файла и валидировать его, когда кто-то создает новые инструкции для сбора\обработки\отправки метрик\логов (В рамках Vector Operator’а такие инструкции задаются через Custom Resource VectorPipeline (или ClusterVectorPipeline)). Не хотелось нам это по нескольким причинам:
Нами было решено, что пользователь, когда создает CR VectorPipeline должен иметь возможность указать что угодно в блоках sources, transforms и sinks, однако оператор должен уметь доставать конкретные поля из того, что указал пользователь в CR и проверять их.
Например, если пользователь в CR VectorPipeline укажет поле extra_namespace_label_selector - должна выдаться ошибка, ведь Custom Resource VectorPipeline должен работать, и забирать логи, только в том NameSpace, где он определен. Поле extra_namespace_label_selector заполняется автоматически, иначе рядовой пользователь в кластере имея права создавать VectorPipeline сможет настроить сборку логов, например, с объектов в NameSpace kube-system, что, мягко говоря, несекьюрно.
Решение
По умолчанию при создании Custom Resource, все неуказаные в CRD поля - удаляются, но в kubebuilder есть опция кодогенератора:
// +kubebuilderruningreserveUnknownFields, которая добавляя в сгенеренную CRD поле x-kubernetes-preserve-unknown-fields: true, позволяет передавать любое количество дополнительных полей.
RAW данные в go структуре, которые описывает CRD имеют тип runtime.RawExtension.
type VectorPipelineSpec struct {
// +kubebuilderruningreserveUnknownFields
Sources *runtime.RawExtension `json:"sources,omitempty"`
// +kubebuilderruningreserveUnknownFields
Transforms *runtime.RawExtension `json:"transforms,omitempty"`
// +kubebuilderruningreserveUnknownFields
Sinks *runtime.RawExtension `json:"sinks,omitempty"`
}
Но дальше возникает проблема: как написано выше, часть конфига мы хотим контролировать, а часть отправлять как есть, соответсвенно после десериализации нам надо чаcть данных запихать в поля, которые у нас определены, а часть оставить как есть.
На помощь приходит пакет mapstructure, который декодирует мапы в структуры и с помощью специального тэга remain, делает то, что нам нужно.
Итого:
- Бинарный runtime.RawExtension мы десериализуем в map[string]interface{} - Полученный map[string]interface{} мы с помощью mapstructure декодируем в go структуру, причем те ключи, которые совпадают с названиями предопределенных полей, мы переносим в них, для последующей обработки и валидации, а все остальное в поле Options.
Структура самого конфига выглядит так:
type VectorConfig struct {
DataDir string `mapstructure:"data_dir"`
Api *vectorv1alpha1.ApiSpec `mapstructure:"api"`
Sources []*Source `mapstructure:"sources"`
Transforms []*Transform `mapstructure:"transforms"`
Sinks []*Sink `mapstructure:"sinks"`
}
type Source struct {
Name string
Type string `mapper:"type"`
ExtraNamespaceLabelSelector string `mapper:"extra_namespace_label_selector,omitempty"`
Options map[string]interface{} `mapstructure:",remain"`
}
type Transform struct {
Name string
Type string `mapper:"type"`
Inputs []string `mapper:"inputs"`
Options map[string]interface{} `mapstructure:",remain"`
}
type Sink struct {
Name string
Type string `mapper:"type"`
Inputs []string `mapper:"inputs"`
Options map[string]interface{} `mapstructure:",remain"`
}
Таким образом мы разрешили пользователям создавать CR VectorPipeline (или ClusterVectorPipeline) с любой структурой для sources, transforms и sinks, но не потеряли возможность анализировать, что именно создал пользователь.
Поскольку мы не контролируем структуру для source, transforms, sink, которые пользователь задает с помощью CR VectorPipeline, - K8s провалидирует абсолютно все, что там написано, даже если эту будет абсолютная белиберда, с которой Vector никогда не запустится.
Например вот такой CR VectorPipeline вполне себе заапрувится Kubernetes API
cat <<EOF | kubectl apply -f -
apiVersion: observability.kaasops.io/v1alpha1
kind: VectorPipeline
metadata:
name: example
spec:
sources:
source-test:
lol: "kek"
transforms:
transform-test:
kek: "lol"
sinks:
sink-test:
cheburek: "wow"
EOF
vectorpipeline.observability.kaasops.io/example created
Однако когда оператор попытается из этого сгенерировать конфигурационный файл для Vector’a, тот, несомненно, упадет с ошибкой.
Решение
Сгенеренный конфиг проходит два этапа проверки
Validation - это проверка области видимоcти. Например, на этапе валидации будут отбрасываться не кластерные vector pipeline, которые пытаются собрать логи из соседних namespace или journald.
Configcheck - проверка провалидированного конфига уже самим Vector'ом.
ConfigCheck решает нашу проблему. Каждый раз, когда пользователь создает\обновляет VectorPipeline происходит следующее:
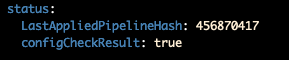
Соответственно таким нехитрым способом мы сделали валидацию для CR VectorPipeline. Причем пользователь, который создает VectorPipeline, может в любой момент посмотреть поле ConfigCheckResult и убедиться, что его VectorPipeline - валидный.

Оговорочка
Мы не считаем, что такой вариант проверки конфигов “идеален”. Идеально было бы, если ли бы все проверки запускались во время apply/create CR VectorPipeline. Для этого нам нужен грамотный Validate WebHook. Однако сейчас конфигчек исполняется “долго” (в среднем секунд 20). И получается, когда пользователь запускает команду create/apply - консоль “морозится” на ~20 секунд, пока под капотом выполняется ConfigCheck, что выглядит, как обычные “тормоза”.
В будущем у нас есть идеи как ускорить и улучшить этот процесс.
Как было описано выше, если пользователь создает VectorPipeline с невалидной конфигурацией, тогда в его VectorPipeline появился поле ConfigCheckResult в котором будет написано false. Отлично! Но как пользователю узнать что именно в его конфигурации неправильно?
Эта информация доступна в логах pod’а, в котором была запущена валидация конфигурации VectorPipeline, но поды эти создаются в Namespace, где описан Custom Resouce Vector и, соответственно, где развернут сам Vector. Зачастую у пользователя в кластере нет доступа к такому pod’у. Да и не очень красиво, что для того, чтобы узнать, что именно сломано в VectorPipeline - надо знать, что есть где-то какой-то pod, в котором об этом написано.
Решение
Было решено в Status VectorPipeline добавить поле Reason, которое появляется, когда ConfigCheckResult в состоянии false.
В этот Reason необходимо запихнуть логи из pod’а, который выполнял валидацию конфига, однако есть загвоздка. Controller Runtime, который используется и в KubeBuilder и в OpenSDK при регистрации оператора, не умеет доставать логи из подов. (На эту тему есть открытый issue аж с мая 2019 года и расчитывать, что он будет решен в ближайшее время не приходится).
Controller Runtime не умеет, да и черт с ним, зато дефолтный client-go отлично справляется с этой задачей. Регистрируем ClientSet:
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err)
}
Описываем функцию для того, чтобы достать логи из Pod’а:
func GetPodLogs(pod *corev1.Pod, cs *kubernetes.Clientset) (string, error) {
count := int64(100)
podLogOptions := corev1.PodLogOptions{
TailLines: &count,
}
req := cs.CoreV1().Pods(pod.Namespace).GetLogs(pod.Name, &podLogOptions)
podLogs, err := req.Stream(context.TODO())
if err != nil {
return "", err
}
defer podLogs.Close()
buf := new(bytes.Buffer)
_, err = io.Copy(buf, podLogs)
if err != nil {
return "", err
}
str := buf.String()
return str, nil
}
Пользуемся на здоровье.
Из минусов - у нас теперь используются 2 схожих client’а для работы с Kubernetes’ом:

При каждом старте оператора - он начинает реконсилить все существующие ресурсы (в часности VectorPipeline и ClusterVectorPipeline), и соответственно запускать валидации конфигурационных файлов (генерировать pod’ы/secret’ы) даже, если наши ресурсы не изменились (оператор не может никак определить были ли изменены ресурсы, пока он был выключен, соответственно запускает Reconcile для всего)
Решение
Для того, чтобы не запускать кучу лишних ConfigCheck’ов, мы добавили новое поле в Status VectorPipeline - LastAppliedPipelineHash. Сюда записывается Hash Конфигурации, которая была проверена.
Теперь Reconcile VectorPipeline выглядит так:

 habr.com
habr.com
В рамках данной статьи я опишу разные интересные Задачи/Проблемы с которыми мы столкнулись в процессе разработки и как их решили.
Controller Runtime Cache
ПроблемаПри тестировании оператора в продакшн условиях, мы столкнулись с ошибкой, которая в логах выглядела так:
W1029 16:56:43.443740 81279 reflector.go:324] pkg/mod/k8s.io/client-go@v0.24.2/tools/cache/reflector.go:167: failed to list *v1.Secret: stream error when reading response body, may be caused by closed connection. Please retry. Original error: stream error: stream ID 155; INTERNAL_ERROR; received from peer
I1029 16:56:43.443865 81279 trace.go:205] Trace[1292523411]: "Reflector ListAndWatch" name
kg/mod/k8s.io/client-go@v0.24.2/tools/cache/reflector.go:167 (29-Oct-2022 16:55:43.022) (total time: 60421ms):Trace[1292523411]: ---"Objects listed" error:stream error when reading response body, may be caused by closed connection. Please retry. Original error: stream error: stream ID 155; INTERNAL_ERROR; received from peer 60421ms (16:56:43.443)
Trace[1292523411]: [1m0.4217365s] [1m0.4217365s] END
Аналитика
Когда мы выполняем Get какого-то объекта (дли примера - secret):
err := c.Get(ctx, client.ObjectKeyFromObject(desired), existing)
if err != nil {
return err
}
Контроллер пытается получить список ВСЕХ secret’ов, подписаться на изменение каждого и все это сохранить в cache. Secret’ов в кластере, где проходили тесты, очень много и operator просто не успевал выполнить получение всех secret’ов (он делает это одним запросом) и запрос отваливался по timeout.
Покопавшись в коде контроллера, мы поняли, что это его дефолтное поведение.
Решение
При регистрации менеджера нужно указать, какие ресурсы НЕ надо кэшировать. Указываем тут все ресурсы, с которыми работаем:
mgr, err := ctrl.NewManager(config, ctrl.Options{
Scheme: scheme,
...
...
ClientDisableCacheFor: []client.Object{&corev1.Secret{}, &corev1.ConfigMap{}, &corev1.Pod{}, &appsv1.Deployment{},
&appsv1.StatefulSet{}, &rbacv1.ClusterRole{}, &rbacv1.ClusterRoleBinding{}},
})
Отказ от Reconcile по времени
ПроблемаОдна из главных задач оператора - следить, что все объекты, которые он развернул находится в валидном состоянии. То есть если кто-то ручками в кластере поправит контролируемый оператором объект - оператор должен отловить это и вернуть все к “контролируемому” состоянию. (Возможно за исключением каких-то полей, но это вопрос про server-side apply, что достойно отдельной статьи и тут не рассматривается)
Аналитика
По умолчанию мы настроили Reconcile Vector’а, чтобы он срабатывал каждые 15 секунд. То есть каждые 15 секунд оператор запускает проверку, что все раскатанные ресурсы находятся в нужном состоянии.
Однако это выглядит как излишняя нагрузка. Чаще всего, запускаемый Reconcile ничего не делает.
Было бы прекрасно, если бы мы могли “подписаться” на все ресурсы, которые создаются для работы Vector’a и запускать Reconcile только если в этих ресурсах произошли какие-то изменения. И у нас есть такая возможность!
При инициализации Controller-Runtime Manager’а мы можем ему указать следующее:
func (r *VectorReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&vectorv1alpha1.Vector{}).
Owns(&appsv1.DaemonSet{}).
Owns(&corev1.Service{}).
Owns(&corev1.Secret{}).
Owns(&corev1.ServiceAccount{}).
Complete(r)
}
Если вкратце, то это означает:
- Мы подписываемся на все изменения, связанные с ресурсом vectorv1alpha1.Vector. Это указывается в методе For
- Мы подписывается на все ресурсы, которые раскатываются оператором, у которых в Owners указан vectorv1alpha1.Vector. Это указывается в Owns
W1029 16:56:43.443740 81279 reflector.go:324] pkg/mod/k8s.io/client-go@v0.24.2/tools/cache/reflector.go:167: failed to list *v1.Secret: stream error when reading response body, may be caused by closed connection. Please retry. Original error: stream error: stream ID 155; INTERNAL_ERROR; received from peer
I1029 16:56:43.443865 81279 trace.go:205] Trace[1292523411]: "Reflector ListAndWatch" name
kg/mod/k8s.io/client-go@v0.24.2/tools/cache/reflector.go:167 (29-Oct-2022 16:55:43.022) (total time: 60421ms):Trace[1292523411]: ---"Objects listed" error:stream error when reading response body, may be caused by closed connection. Please retry. Original error: stream error: stream ID 155; INTERNAL_ERROR; received from peer 60421ms (16:56:43.443)
Trace[1292523411]: [1m0.4217365s] [1m0.4217365s] END
Опять она. Возникает она по следующей причине.
При старте, Operator читает из Kubernetes API все обекты, типы которых перечисленны в Owns. Делает он это для того, чтобы проверить нет ли на момент старта Оператора каких-то объектов в кластере, у которых УЖЕ установлен Owner’ом наш Vector.
Логичное поведение, однако оно приводит к тому, что на высоконагруженных (скорее всего bare-metal) кластерах Kubernetes наш оператор будет постоянно спамить ошибками и падать. Да и нецелесообразно выглядит, когда оператор под капотом пытается выташить ВСЕ объекты какого-то типа из кластера.
Решение
Мы планируем иметь возможность импользование оператора на высогонагруженных и жирных кластерах Kubernetes, по этому нам пришлось вернуться к запуску Reconcile каждые 15 секунд.
Дублирование структуры конфигурации Vector'a
ПроблемаVector имеет определенную структуру для своего файла конфигурации. Архитектурно он состоит из 4 блоков:
- Global - Важные настройки самого Vector’а. (Нужно ли ему включить API, директория, в которой он будет хранить cache, настройки параметров helthcheck’ов и т.д.)
- Source - Источники откуда должны тянуться данные
- Transforms - Инструкции для обработки данных
- Sink - Куда отправлять данные
Признаться честно - нам крайне не хотелось дублировать работу Vector’а и хранить где-то в операторе ВСЮ структуру конфигурационного файла и валидировать его, когда кто-то создает новые инструкции для сбора\обработки\отправки метрик\логов (В рамках Vector Operator’а такие инструкции задаются через Custom Resource VectorPipeline (или ClusterVectorPipeline)). Не хотелось нам это по нескольким причинам:
- Vector написан на Rust. И мы просто не могли в нашем операторе, который мы реализуем на Go, переиспользовать готовые структуры, которые уже определены в Vector’e
- Скопировать всю структуру конфигурационного файла Vector’а в структуры Go - рутинная, нудная задача
- Мы легко можем где-то ошибиться и, например, указать где-нибудь тип int, когда нужен float, как это было замечено в Logging Operator’e
- Обновления оператора на новые версии Vector’а - становится кромешным адом. Ничего не забыть, нигде не ошибиться. А такая ручная работа в итоге всегда приводит к ошибкам
- Если мы хотим поддерживать возможность установки разных версий Vector’а - нам нужно хранить и контролировать структуру для каждой версии
Нами было решено, что пользователь, когда создает CR VectorPipeline должен иметь возможность указать что угодно в блоках sources, transforms и sinks, однако оператор должен уметь доставать конкретные поля из того, что указал пользователь в CR и проверять их.
Например, если пользователь в CR VectorPipeline укажет поле extra_namespace_label_selector - должна выдаться ошибка, ведь Custom Resource VectorPipeline должен работать, и забирать логи, только в том NameSpace, где он определен. Поле extra_namespace_label_selector заполняется автоматически, иначе рядовой пользователь в кластере имея права создавать VectorPipeline сможет настроить сборку логов, например, с объектов в NameSpace kube-system, что, мягко говоря, несекьюрно.
Решение
По умолчанию при создании Custom Resource, все неуказаные в CRD поля - удаляются, но в kubebuilder есть опция кодогенератора:
// +kubebuilder
runingreserveUnknownFields, которая добавляя в сгенеренную CRD поле x-kubernetes-preserve-unknown-fields: true, позволяет передавать любое количество дополнительных полей.RAW данные в go структуре, которые описывает CRD имеют тип runtime.RawExtension.
type VectorPipelineSpec struct {
// +kubebuilder
runingreserveUnknownFieldsSources *runtime.RawExtension `json:"sources,omitempty"`
// +kubebuilder
runingreserveUnknownFieldsTransforms *runtime.RawExtension `json:"transforms,omitempty"`
// +kubebuilder
runingreserveUnknownFieldsSinks *runtime.RawExtension `json:"sinks,omitempty"`
}
Но дальше возникает проблема: как написано выше, часть конфига мы хотим контролировать, а часть отправлять как есть, соответсвенно после десериализации нам надо чаcть данных запихать в поля, которые у нас определены, а часть оставить как есть.
На помощь приходит пакет mapstructure, который декодирует мапы в структуры и с помощью специального тэга remain, делает то, что нам нужно.
Итого:
- Бинарный runtime.RawExtension мы десериализуем в map[string]interface{} - Полученный map[string]interface{} мы с помощью mapstructure декодируем в go структуру, причем те ключи, которые совпадают с названиями предопределенных полей, мы переносим в них, для последующей обработки и валидации, а все остальное в поле Options.
Структура самого конфига выглядит так:
type VectorConfig struct {
DataDir string `mapstructure:"data_dir"`
Api *vectorv1alpha1.ApiSpec `mapstructure:"api"`
Sources []*Source `mapstructure:"sources"`
Transforms []*Transform `mapstructure:"transforms"`
Sinks []*Sink `mapstructure:"sinks"`
}
type Source struct {
Name string
Type string `mapper:"type"`
ExtraNamespaceLabelSelector string `mapper:"extra_namespace_label_selector,omitempty"`
Options map[string]interface{} `mapstructure:",remain"`
}
type Transform struct {
Name string
Type string `mapper:"type"`
Inputs []string `mapper:"inputs"`
Options map[string]interface{} `mapstructure:",remain"`
}
type Sink struct {
Name string
Type string `mapper:"type"`
Inputs []string `mapper:"inputs"`
Options map[string]interface{} `mapstructure:",remain"`
}
Таким образом мы разрешили пользователям создавать CR VectorPipeline (или ClusterVectorPipeline) с любой структурой для sources, transforms и sinks, но не потеряли возможность анализировать, что именно создал пользователь.
Автоматическая проверка генерируемого конфига
ПроблемаПоскольку мы не контролируем структуру для source, transforms, sink, которые пользователь задает с помощью CR VectorPipeline, - K8s провалидирует абсолютно все, что там написано, даже если эту будет абсолютная белиберда, с которой Vector никогда не запустится.
Например вот такой CR VectorPipeline вполне себе заапрувится Kubernetes API
cat <<EOF | kubectl apply -f -
apiVersion: observability.kaasops.io/v1alpha1
kind: VectorPipeline
metadata:
name: example
spec:
sources:
source-test:
lol: "kek"
transforms:
transform-test:
kek: "lol"
sinks:
sink-test:
cheburek: "wow"
EOF
vectorpipeline.observability.kaasops.io/example created
Однако когда оператор попытается из этого сгенерировать конфигурационный файл для Vector’a, тот, несомненно, упадет с ошибкой.
Решение
Сгенеренный конфиг проходит два этапа проверки
Validation - это проверка области видимоcти. Например, на этапе валидации будут отбрасываться не кластерные vector pipeline, которые пытаются собрать логи из соседних namespace или journald.
Configcheck - проверка провалидированного конфига уже самим Vector'ом.
ConfigCheck решает нашу проблему. Каждый раз, когда пользователь создает\обновляет VectorPipeline происходит следующее:
- Генерируется secret, в который записывается конфигурационные файл Vector’а, который состроит из sources, transforms, sinks, которые описаны в VectorPipeline
- Запускается pod, в контейнере которого запускается Vector с флагом validate.
- Если pod успешно завершается (то есть валидация конфигурации, заданной в VectorPipeline корректна) в статусе VectorPipeline в поле ConfigCheckResult устанавливается значение true. Если же под завершился с ошибкой (то есть валидация закончилась с ошибкой) - в поле ConfigCheckResult устанавливается false.
Соответственно таким нехитрым способом мы сделали валидацию для CR VectorPipeline. Причем пользователь, который создает VectorPipeline, может в любой момент посмотреть поле ConfigCheckResult и убедиться, что его VectorPipeline - валидный.
Оговорочка
Мы не считаем, что такой вариант проверки конфигов “идеален”. Идеально было бы, если ли бы все проверки запускались во время apply/create CR VectorPipeline. Для этого нам нужен грамотный Validate WebHook. Однако сейчас конфигчек исполняется “долго” (в среднем секунд 20). И получается, когда пользователь запускает команду create/apply - консоль “морозится” на ~20 секунд, пока под капотом выполняется ConfigCheck, что выглядит, как обычные “тормоза”.
В будущем у нас есть идеи как ускорить и улучшить этот процесс.
Достаем логи из подов
ПроблемаКак было описано выше, если пользователь создает VectorPipeline с невалидной конфигурацией, тогда в его VectorPipeline появился поле ConfigCheckResult в котором будет написано false. Отлично! Но как пользователю узнать что именно в его конфигурации неправильно?
Эта информация доступна в логах pod’а, в котором была запущена валидация конфигурации VectorPipeline, но поды эти создаются в Namespace, где описан Custom Resouce Vector и, соответственно, где развернут сам Vector. Зачастую у пользователя в кластере нет доступа к такому pod’у. Да и не очень красиво, что для того, чтобы узнать, что именно сломано в VectorPipeline - надо знать, что есть где-то какой-то pod, в котором об этом написано.
Решение
Было решено в Status VectorPipeline добавить поле Reason, которое появляется, когда ConfigCheckResult в состоянии false.
В этот Reason необходимо запихнуть логи из pod’а, который выполнял валидацию конфига, однако есть загвоздка. Controller Runtime, который используется и в KubeBuilder и в OpenSDK при регистрации оператора, не умеет доставать логи из подов. (На эту тему есть открытый issue аж с мая 2019 года и расчитывать, что он будет решен в ближайшее время не приходится).
Controller Runtime не умеет, да и черт с ним, зато дефолтный client-go отлично справляется с этой задачей. Регистрируем ClientSet:
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err)
}
Описываем функцию для того, чтобы достать логи из Pod’а:
func GetPodLogs(pod *corev1.Pod, cs *kubernetes.Clientset) (string, error) {
count := int64(100)
podLogOptions := corev1.PodLogOptions{
TailLines: &count,
}
req := cs.CoreV1().Pods(pod.Namespace).GetLogs(pod.Name, &podLogOptions)
podLogs, err := req.Stream(context.TODO())
if err != nil {
return "", err
}
defer podLogs.Close()
buf := new(bytes.Buffer)
_, err = io.Copy(buf, podLogs)
if err != nil {
return "", err
}
str := buf.String()
return str, nil
}
Пользуемся на здоровье.
Из минусов - у нас теперь используются 2 схожих client’а для работы с Kubernetes’ом:
- client.Client (от Controller Runtime)
- kubernetes.ClientSet (от client-go)
Пропуск лишних Reconcile
ПроблемаПри каждом старте оператора - он начинает реконсилить все существующие ресурсы (в часности VectorPipeline и ClusterVectorPipeline), и соответственно запускать валидации конфигурационных файлов (генерировать pod’ы/secret’ы) даже, если наши ресурсы не изменились (оператор не может никак определить были ли изменены ресурсы, пока он был выключен, соответственно запускает Reconcile для всего)
Решение
Для того, чтобы не запускать кучу лишних ConfigCheck’ов, мы добавили новое поле в Status VectorPipeline - LastAppliedPipelineHash. Сюда записывается Hash Конфигурации, которая была проверена.
Теперь Reconcile VectorPipeline выглядит так:
- Генерируется конфигурация, которую необходимо проверить.
- Берется hash этой конфигурации и сравнивается с Hash в поле LastAppliedPipelineHash(Если поле заполненно). Если hash’и совпадают - значит эта конфигурация уже была проверена и не нужно повторно запускать процесс ConfigCheck.
Наступая на грабли. Опыт написания Kubernetes Operator’а
Недавно мной, совместно с @dkhadm , был реализован оператор для Kubernetes’a - Vector Operator . (Вот тут описано как мы пришли к решению, что там нужен свой оператор для Логирования в Kubernetes). В...
habr.com