Мы уже рассказывали о том, как применили семейство генеративных нейросетей YaLM для подготовки ответов в Поиске, Алисе или даже в Балабобе. Главная особенность наших моделей — метод few-shot learning, который позволяет без дополнительного обучения решать большинство задач в области обработки естественного языка. Достаточно лишь подготовить подводку на человеческом языке — и модель сгенерирует текст. Но что, если это не самый оптимальный путь?
Сегодня я расскажу читателям Хабра про апгрейд этого метода под названием P-tuning. Вы узнаете про недостатки оригинального метода few-shot и преимущества нового подхода. Покажу, где он уже применяется на примере покемонов. Добро пожаловать под кат.
В прошлой статье мы приводили пример задачи, который будет отчасти релевантен и здесь. Есть текстовая подводка, например:
Использование few-shot обычно означает, что для решения задачи имеется совсем немного вручную размеченных данных. Также нет готового решения, с которым можно сравниться, и часто недоступны метрики оценки качества. А даже если они есть, то данных настолько мало, что сигнал получается очень шумным.
Есть и другая проблема: на практике мы столкнулись с множеством артефактов в результатах, которые выдаёт модель. Она может начать придумывать куски информации, которые не имеют никакого отношения к изначальному тексту (но содержатся в значительной части примеров из подводки).
Например, такую подводку…
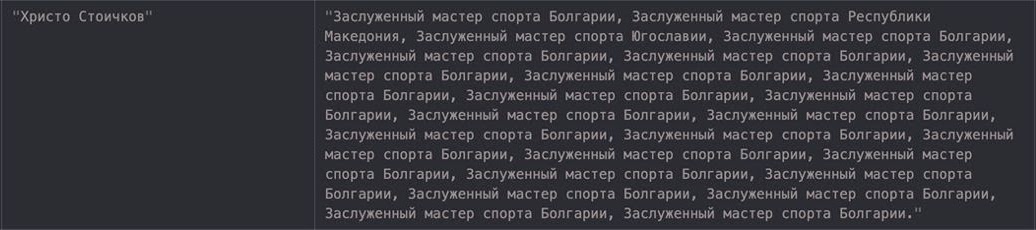
От перечисленных артефактов можно избавиться, вручную меняя подводку. Причём при, казалось бы, небольшом изменении тексты на выходе могут преображаться довольно сильно: становиться как лучше, так и хуже. Даже наличие в подводке лишнего перевода строки или неправильного форматирования влияет на ответ и может сильно ухудшить его качество. Поэтому инженерам приходится аккуратно составлять текст подводки, пробовать, перезапускать, глазами оценивать результаты — именно это я называю процессом ручного подбора.
Поэтому прототипирование с few-shot оказывается довольно трудоёмким и долгим. А самое главное, что этот процесс не даёт гарантии, что мы сможем найти подводку, которая подтолкнёт модель к наиболее качественному решению. А даже если найдём, то почти наверняка составленный нами текст будет не самым оптимальным. С перечисленными проблемами хочется бороться.
Задача остаётся прежней: на базе подводки составлять новый текст, пользуясь знаниями об устройстве языка и мира, заложенными в модель.
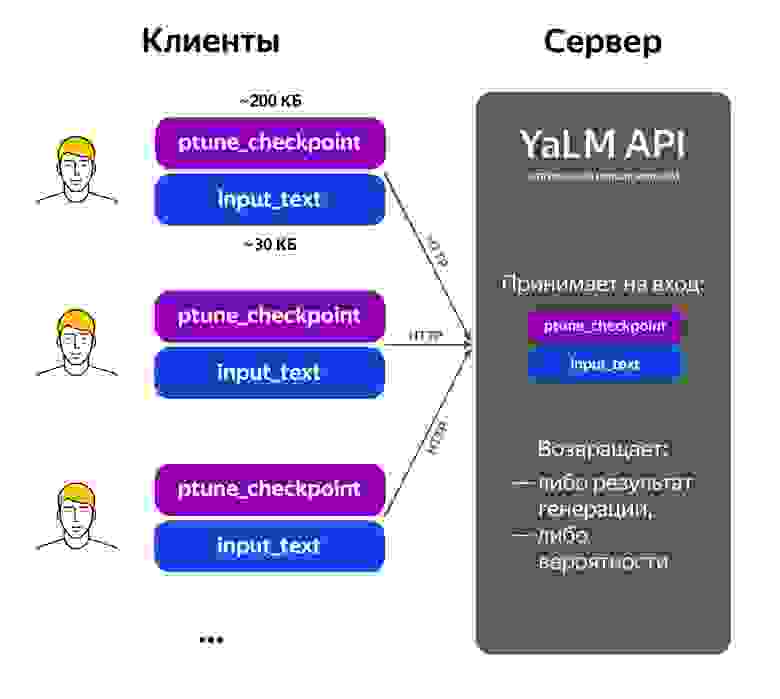
Как известно, системам машинного обучения гораздо проще работать не с исходными данными — в нашем случае с текстами, — а с их векторными представлениями, эмбеддингами. И в модель few-shot, и в P-tuning, о котором я сейчас расскажу, и в любые другие модели мы загружаем наборы векторов, получившиеся из текстов. С этими векторами производятся некоторые манипуляции, после чего мы превращаем их обратно в итоговый текст. Нам не обойтись без перехода на этот более глубокий уровень.
Выше я сказал, что подводка сильно влияет на результат и её приходится «дотюнивать» руками. Но, повторюсь, подводка всё равно затем превращается в векторы, и модель работает уже с ними. Что если «дотюнивать» сразу их — и поручить это самой модели?
Именно так и работает P-tuning. Набор эмбеддингов, получившихся из подводки, априори не является самым удачным. И модель пытается отыскать более оптимальный набор, меняя эти эмбеддинги так, чтобы итоговая задача решалась всё лучше. Поскольку мы оптимизируем не тексты, а числа, то это можно делать классическим методом уменьшения ошибки — градиентным спуском. Простое объяснение, как работает градиентный спуск, есть, например, здесь.
То есть модель сама подбирает себе наиболее оптимальную подводку — потому что мы перешли на понятный ей уровень абстракции. Если совсем грубо — «заговорили» на её языке (языке эмбеддингов, а не текстов), объясняя, какого результата мы от неё ждём.
Что из себя представляет оптимальная подводка

Авторы оригинальной статьи предложили следующий подход:
Мы проверили, что P-tuning отлично работает в связке с представителями семейства языковых моделей, но ничто не мешает использовать его и c другими популярными архитектурами, например с BERT или T5.
Для одного запуска P-tuning'a требуется не очень много вычислительных ресурсов (об этом ниже). А значит, имея в распоряжении GPU-кластер большого размера, становится возможным перебирать гиперпараметры. Да-да, вам это не снится, настал день, когда можно недорого перебрать гиперпараметры NLP-нейросети. Такая особенность делает метод ещё более применимым в задачах, близких к продакшену, где нужны максимальные показатели качества.
Устройство P-tuning'a наделяет его следующими свойствами:
В первую очередь мы собрали больше десяти датасетов для замеров качества моделей. Эти датасеты приближены к данным, на основе которых мы решаем задачи для пользователей: помогаем Алисе поддерживать интересный диалог, подсвечиваем важное в фактовом ответе на поиске, выявляем некачественный контент и так далее. Часть данных выгрузили из анонимизированных логов сервисов, часть собрали в Толоке.
Вот на каких задачах мы проверяли работоспособность технологии (по столбцам слева можно оценить результат):
Чтобы P-tuning использовался в Яндексе повсеместно (а он применим во всех задачах классификации и генерации текстов), нам нужно было предложить хороший дефолтный конфиг обучения. Мы подобрали такие гиперпараметры, от которых можно оттолкнуться при решении новых задач. Они далеко не всегда дают оптимальное качество в отдельно взятой задаче, но позволяют сразу получить многообещающий результат, который потом не так уж сложно «дотюнить» до требуемого. Это снизило порог входа для других разработчиков.
Мы считаем, что главная задача этой технологии — занять нишу там, где требуется более высокое качества текста, чем способен предложить few-shot, но не всегда хватает данных для тяжеловесного finetuning'а. Ниже покажу, как P-tuning уже работает в поиске Яндекса на примере редких покемонов.
К примеру, если поискать в поиске [Сновер], то можно увидеть блок с основной информацией про этого покемона. Если бы это был популярный покемон, то его описание подхватилось бы из «Википедии», к которой достаточно высокое доверие. Но для малоизвестных покемонов каждый элемент этого блока извлечён из неструктурированного текста на произвольном сайте с помощью нейросетей YaLM. И в этом случае нам важно убедиться, что контент в блоке качественный.

Именно с проверкой качества и помогает P-tuning. Выше мы рассматривали его как инструмент генерации текста по известной подводке, но перейти к оценке качества несложно. Например, в подводке может содержаться такой текст:
Это ещё одна из возможностей, которые даёт P-tuning. Допустим, у нас есть уже работающий сложный пайплайн, решающий какую-нибудь задачу приемлемо. Нам хочется его улучшить, мы придумываем дополнительный признак и хотим добавить его в пайплайн. Но, к сожалению, мы не можем просто так это сделать, потому что новый признак нельзя получить из уже имеющихся, и процесс получения новой разметки на этот признак пока не налажен. А узнать качество нового пайплайна хочется уже сейчас. Тогда мы можем использовать P-tuning в конфигурации для крошечных датасетов!
Даже в самой сложной задаче (если говорить про тексты) почти наверняка можно собрать несколько сотен примеров вручную. Затем обучаем P-tuning и получаем примерное значение признака для всего объёма данных. Это позволит нам оценить качество нового пайплайна и уже потом решить, нужна ли нам более массов разметка на значения этого признака.
Возьмём, например, задачу поиска ответов в интернете. Предположим, после анализа плохих ответов стало видно: многие проблемные ответы дают лишь часть необходимой информации. По запросу «Какие бывают собаки?» ответ «таксы» релевантен, но реальную потребность не удовлетворяет.
Тогда давайте из двух релевантных ответов выбирать более информативный. Для этого достаточно разметить вручную всего триста примеров, чтобы обучить P-tuning с неплохим качеством.
Такая модель уже позволяет определять информативные ответы с точностью 78%.
Мы опубликовали в бенчмарке Russian SuperGLUE результаты нашей модели на 3 миллиарда параметров, усиленной за счёт P-tuning. Она оказалась на третьем месте, обогнав все single-model-методы, а также более дорогостоящие в плане времени и ресурсов finetuning-модели с ощутимым отрывом в 2,5 процентных пункта. Отдельно отмечу, что мы обучаем только 40 тысяч параметров — это в тысячи раз меньше классического finetuning'a.
P-tuning позволяет относительно дёшево в смысле времени и вычислительных ресурсов применять огромные языковые модели в боевых продуктах. Благодаря этой технологии пользователи теперь будут видеть ещё более качественные тексты в Поиске и слышать их от Алисы. Я и вся команда YaLM надеемся, что эта статья мотивирует русскоязычное DL community посвятить время исследованию и использованию больших моделей в NLP.

 habr.com
habr.com
Сегодня я расскажу читателям Хабра про апгрейд этого метода под названием P-tuning. Вы узнаете про недостатки оригинального метода few-shot и преимущества нового подхода. Покажу, где он уже применяется на примере покемонов. Добро пожаловать под кат.
Какую задачу мы решаем?
В прошлой статье мы приводили пример задачи, который будет отчасти релевантен и здесь. Есть текстовая подводка, например:
И есть краткое продолжение:ТНТ — российский федеральный телеканал. По данным на 2019 год занимает седьмое место по популярности среди телеканалов России. Целевая аудитория телеканала — телезрители от 14 до 44 лет, ядро составляет молодёжь — зрители 18–30 лет.
Если передать во few-shot-модель несколько таких пар (подводка + продолжение) про разные сущности, а затем загрузить, скажем, описание сайта Booking.com и попросить модель составить продолжение («Короче, Booking.com — это…»), она ответит: «…сайт бронирования отелей». Так работает few-shot — учится составлять тексты по заданному нами принципу.Короче, ТНТ — это телеканал.
А что не так с few-shot?
Использование few-shot обычно означает, что для решения задачи имеется совсем немного вручную размеченных данных. Также нет готового решения, с которым можно сравниться, и часто недоступны метрики оценки качества. А даже если они есть, то данных настолько мало, что сигнал получается очень шумным.
Есть и другая проблема: на практике мы столкнулись с множеством артефактов в результатах, которые выдаёт модель. Она может начать придумывать куски информации, которые не имеют никакого отношения к изначальному тексту (но содержатся в значительной части примеров из подводки).
Например, такую подводку…
…модель продолжает так:Туристам доступно 2 маршрута: пешая экскурсия с гидом по подземным тоннелям базы и экскурсия на речном трамвайчике по основному тоннелю. Подземная база подводных лодок находится в…
Или другой пример работы few-shot — здесь текст продолжает бесконтрольно генерироваться, возникает множество повторов, противоречащие друг другу фразы и прочая бессмыслица:…в центре города, на глубине 10 метров. Сверху база не имеет отличительных знаков, и лишь на поверхности, рядом с базой, находится памятник, посвященный подводникам.
От перечисленных артефактов можно избавиться, вручную меняя подводку. Причём при, казалось бы, небольшом изменении тексты на выходе могут преображаться довольно сильно: становиться как лучше, так и хуже. Даже наличие в подводке лишнего перевода строки или неправильного форматирования влияет на ответ и может сильно ухудшить его качество. Поэтому инженерам приходится аккуратно составлять текст подводки, пробовать, перезапускать, глазами оценивать результаты — именно это я называю процессом ручного подбора.
Поэтому прототипирование с few-shot оказывается довольно трудоёмким и долгим. А самое главное, что этот процесс не даёт гарантии, что мы сможем найти подводку, которая подтолкнёт модель к наиболее качественному решению. А даже если найдём, то почти наверняка составленный нами текст будет не самым оптимальным. С перечисленными проблемами хочется бороться.
Как работает P-tuning?
Задача остаётся прежней: на базе подводки составлять новый текст, пользуясь знаниями об устройстве языка и мира, заложенными в модель.
Как известно, системам машинного обучения гораздо проще работать не с исходными данными — в нашем случае с текстами, — а с их векторными представлениями, эмбеддингами. И в модель few-shot, и в P-tuning, о котором я сейчас расскажу, и в любые другие модели мы загружаем наборы векторов, получившиеся из текстов. С этими векторами производятся некоторые манипуляции, после чего мы превращаем их обратно в итоговый текст. Нам не обойтись без перехода на этот более глубокий уровень.
Выше я сказал, что подводка сильно влияет на результат и её приходится «дотюнивать» руками. Но, повторюсь, подводка всё равно затем превращается в векторы, и модель работает уже с ними. Что если «дотюнивать» сразу их — и поручить это самой модели?
Именно так и работает P-tuning. Набор эмбеддингов, получившихся из подводки, априори не является самым удачным. И модель пытается отыскать более оптимальный набор, меняя эти эмбеддинги так, чтобы итоговая задача решалась всё лучше. Поскольку мы оптимизируем не тексты, а числа, то это можно делать классическим методом уменьшения ошибки — градиентным спуском. Простое объяснение, как работает градиентный спуск, есть, например, здесь.
То есть модель сама подбирает себе наиболее оптимальную подводку — потому что мы перешли на понятный ей уровень абстракции. Если совсем грубо — «заговорили» на её языке (языке эмбеддингов, а не текстов), объясняя, какого результата мы от неё ждём.
Что из себя представляет оптимальная подводка
Для интересующихся: как всё устроено внутри
Авторы оригинальной статьи предложили следующий подход:
- Давайте заменим эмбеддинги токенов подводки (на рисунке выше), которые мы во few-shot подбирали руками, на обучаемые векторы (которые будем предсказывать некоторой моделью) и будем учить только их, заморозив веса основной языковой модели.
- Моделировать эмбеддинги можно несколькими способами, авторы предложили использовать для этого LSTM и MLP:
- Наши эксперименты показывают, что такая модель хорошо работает на сотнях (и больше) примеров в обучении.
- Если же примеров только десятки, и больше получить нельзя, то стоит моделировать их просто новым Embedding-слоем, без LSTM и MLP, но инициализировать веса этого слоя весами эмбеддингов pretrained языковой модели, которые соответствуют токенам из вашей подводки, составленной руками заранее (впервые предложено в этой статье).
- Получается своего рода adversarial attack на часть входного текста в NLP-модель.
Мы проверили, что P-tuning отлично работает в связке с представителями семейства языковых моделей, но ничто не мешает использовать его и c другими популярными архитектурами, например с BERT или T5.
Для одного запуска P-tuning'a требуется не очень много вычислительных ресурсов (об этом ниже). А значит, имея в распоряжении GPU-кластер большого размера, становится возможным перебирать гиперпараметры. Да-да, вам это не снится, настал день, когда можно недорого перебрать гиперпараметры NLP-нейросети. Такая особенность делает метод ещё более применимым в задачах, близких к продакшену, где нужны максимальные показатели качества.
Преимущества P-tuning
Устройство P-tuning'a наделяет его следующими свойствами:
- P-tuning избавляет инженера от перебора подводок и всегда обеспечивает более высокое качество, чем few-shot (способен найти почти любую подводку, которая может быть создана руками).
- Модель чаще всего не производит артефактов, присущих few-shot.
- Так как параметры модели не обучаются, то для применения метода не требуется больших вычислительных ресурсов (вместо GPU-дней в finetuning'е получаем GPU-часы).
- Модель, которая ищет более оптимальную подводку, имеет относительно небольшое число параметров. Поэтому для её обучения не нужны огромные массивы данных — достаточно сотен или тысяч примеров, в то время как для finetuning-a нужны десятки тысяч.
- Так как P-tuning по своей природе влияет только на данные, поступающие на вход, то для одной и той же pretrained языковой модели можно «подключать» разные P-tuning-модели: весят они всего лишь килобайты. Это позволяет создать runtime API, в котором зафиксирована языковая модель, а пользователи сервиса (в данном случае разработчики) посылают запросы в виде пар «модель + текст». Благодаря API можно быстро создавать прототипы для новых задач.
Как мы готовили технологию
В первую очередь мы собрали больше десяти датасетов для замеров качества моделей. Эти датасеты приближены к данным, на основе которых мы решаем задачи для пользователей: помогаем Алисе поддерживать интересный диалог, подсвечиваем важное в фактовом ответе на поиске, выявляем некачественный контент и так далее. Часть данных выгрузили из анонимизированных логов сервисов, часть собрали в Толоке.
Вот на каких задачах мы проверяли работоспособность технологии (по столбцам слева можно оценить результат):
- Суммаризация новостей:
Кстати, вот рассказ, как сейчас работает суммаризация новостей в продакшене, — там же вы можете почитать о том, почему решение на основе YaLM не используется. - Поиск короткого ответа в тексте:

Кликабельно - Генерация вопросов к тексту (такие вопросы могут стать, например, заголовками в карточке объектного ответа на поиске):

Кликабельно


Чтобы P-tuning использовался в Яндексе повсеместно (а он применим во всех задачах классификации и генерации текстов), нам нужно было предложить хороший дефолтный конфиг обучения. Мы подобрали такие гиперпараметры, от которых можно оттолкнуться при решении новых задач. Они далеко не всегда дают оптимальное качество в отдельно взятой задаче, но позволяют сразу получить многообещающий результат, который потом не так уж сложно «дотюнить» до требуемого. Это снизило порог входа для других разработчиков.
Применение в поиске
Мы считаем, что главная задача этой технологии — занять нишу там, где требуется более высокое качества текста, чем способен предложить few-shot, но не всегда хватает данных для тяжеловесного finetuning'а. Ниже покажу, как P-tuning уже работает в поиске Яндекса на примере редких покемонов.
К примеру, если поискать в поиске [Сновер], то можно увидеть блок с основной информацией про этого покемона. Если бы это был популярный покемон, то его описание подхватилось бы из «Википедии», к которой достаточно высокое доверие. Но для малоизвестных покемонов каждый элемент этого блока извлечён из неструктурированного текста на произвольном сайте с помощью нейросетей YaLM. И в этом случае нам важно убедиться, что контент в блоке качественный.
Именно с проверкой качества и помогает P-tuning. Выше мы рассматривали его как инструмент генерации текста по известной подводке, но перейти к оценке качества несложно. Например, в подводке может содержаться такой текст:
Если модель с большей вероятностью продолжает такой текст словом «Да», чем словом «Нет», то можно считать описание нормальным. При этом текст оценивается с нескольких сторон. Во-первых, мы так ловим некачественный контент — тексты, в которых есть грамматические ошибки, неполные предложения и т. п. Во-вторых, проверяем факты, которые должна браться с сайтов, а не додумываться нейросетью.Существо с белым верхом и коричневой нижней частью тела, напоминающее заснеженное дерево. У него зеленые глаза и три точки на макушке.
Это нормальное описание?
Добавление нового аспекта качества в пайплайн
Это ещё одна из возможностей, которые даёт P-tuning. Допустим, у нас есть уже работающий сложный пайплайн, решающий какую-нибудь задачу приемлемо. Нам хочется его улучшить, мы придумываем дополнительный признак и хотим добавить его в пайплайн. Но, к сожалению, мы не можем просто так это сделать, потому что новый признак нельзя получить из уже имеющихся, и процесс получения новой разметки на этот признак пока не налажен. А узнать качество нового пайплайна хочется уже сейчас. Тогда мы можем использовать P-tuning в конфигурации для крошечных датасетов!
Даже в самой сложной задаче (если говорить про тексты) почти наверняка можно собрать несколько сотен примеров вручную. Затем обучаем P-tuning и получаем примерное значение признака для всего объёма данных. Это позволит нам оценить качество нового пайплайна и уже потом решить, нужна ли нам более массов разметка на значения этого признака.
Возьмём, например, задачу поиска ответов в интернете. Предположим, после анализа плохих ответов стало видно: многие проблемные ответы дают лишь часть необходимой информации. По запросу «Какие бывают собаки?» ответ «таксы» релевантен, но реальную потребность не удовлетворяет.
Тогда давайте из двух релевантных ответов выбирать более информативный. Для этого достаточно разметить вручную всего триста примеров, чтобы обучить P-tuning с неплохим качеством.
Такая модель уже позволяет определять информативные ответы с точностью 78%.
RussianSuperGLUE
Мы опубликовали в бенчмарке Russian SuperGLUE результаты нашей модели на 3 миллиарда параметров, усиленной за счёт P-tuning. Она оказалась на третьем месте, обогнав все single-model-методы, а также более дорогостоящие в плане времени и ресурсов finetuning-модели с ощутимым отрывом в 2,5 процентных пункта. Отдельно отмечу, что мы обучаем только 40 тысяч параметров — это в тысячи раз меньше классического finetuning'a.
Заключение
P-tuning позволяет относительно дёшево в смысле времени и вычислительных ресурсов применять огромные языковые модели в боевых продуктах. Благодаря этой технологии пользователи теперь будут видеть ещё более качественные тексты в Поиске и слышать их от Алисы. Я и вся команда YaLM надеемся, что эта статья мотивирует русскоязычное DL community посвятить время исследованию и использованию больших моделей в NLP.
Нейросеть, способная объяснить себе задачу: P-tuning для YaLM
Мы уже рассказывали о том, как применили семейство генеративных нейросетей YaLM для подготовки ответов в Поиске, Алисе или даже в Балабобе . Главная особенность наших моделей — метод few-shot...
habr.com