Elastic stack, также известный как ELK Stack (аббревиатура из программных компонентов: Elasticsearch, Kibana и Logstash), — это платформа построения озера данных с возможностью аналитики по ним в реальном масштабе времени. В настоящее время широко применяется для обеспечения информационной безопасности, мониторинга бесперебойности и производительности работы ИТ-среды и оборудования, анализа рабочих процессов, бизнес-аналитики.
В соответствии со стратегией компании, исходный код всех продуктов Elastic является открытым, разработка ведётся публично, а базовые функции доступны бесплатно, что выгодно отличает платформу от конкурентов.
Одним из платных наборов функций, в которых Elastic видит коммерческий потенциал и активно развивает, является анализ данных с использованием технологий машинного обучения. О его новых возможностях расскажем в нашей статье.
В текущей версии v7.11 доступны следующие наборы инструментов анализа данных с использованием технологий машинного обучения:
- Обнаружение аномалий на потоке данных (Anomaly detection)
- Аналитика табличных данных (Data frame analytics)
Об инструментах обнаружения аномалий Elastic ранее уже писали на Хабре. С того времени (Elastic версии 7.1) они продолжали активно развиваться, было улучшено качество алгоритмов и удобство их применения для прикладных задач. Но в этой статье мы решили осветить совершенно новый набор функций анализа табличных данных, появившийся в версиях с 7.2 до 7.11.Примечание: Попрактиковаться в использовании перечисленных выше наборов инструментов анализа данных можно будет 24 марта. Совместно с коллегами Elastic мы продемонстрируем, как применять Anomaly detection и Data frame analytics для выявления инцидентов информационной безопасности. Ссылка на регистрацию.
Data frame analytics — это набор функций Elasticsearch и визуализаций Kibana, позволяющих проводить анализ данных без их привязки к временным меткам. В отличии от Anomaly detection, где предполагается временная последовательность анализируемых данных.
Работа с Data frame analytics осуществляется через графический интерфейс с пошаговым мастером настройки. При этом, за счёт автоматической оптимизации параметров обучения (hyperparameters) пользователю не требуются глубокие знания стоящих за ними математических алгоритмов.
Возможности Data frame analytics Elastic версии 7.11 включают в себя:
- Выявление отклонений в значениях параметров (outlier detection) с использованием алгоритмов машинного обучения без учителя (unsupervised)
- Построение моделей машинного обучения с учителем (supervised) для решения задач:
a) Регрессии (regression), как определение зависимости одного значения от одного или нескольких других значений
b) Классификации (classification), как определение принадлежности произвольного объекта к одному из заданных классов
Выявление отклонений с использованием алгоритмов машинного обучения без учителя (Outlier detection)
Функция Outlier detection, как и ранее существовавшая в Elastic anomaly detection, предназначена для выявления аномальных значений (выбросов) каких-либо параметров и не предполагает обучение с учителем — модель строится каждый раз при запуске. Но в отличие от anomaly detection, значения признаков (фич, особенностей, характерных черт анализируемых объектов) в ней анализируются без учета временной последовательности.Исходными данными для функции выступает массив записей (JSON документов), в котором данные представлены в виде полей и их значений (поддерживаются числовые и логические типы значений). Каждая запись характеризует поведение какого-либо объекта. Поля в записи включают в себя поле, идентифицирующее объект, и поля со значениями, указывающими на аномальное поведение объекта, их называют признаками (feature).
Результатом функции является оценка отклонения для каждого признака и документа в диапазоне от 0 до 1, где 1 указывает на максимальную вероятность того, что соответствующий признак/документ является выбросом по сравнению с другими документами в анализируемых данных.
В качестве алгоритмов поиска выбросов по умолчанию в Elastic используется ансамбль следующих методов:
- Метод ближайшего соседа (distance of Kth nearest neighbor)
- Метод K ближайших соседей (distance of K-nearest neighbors)
- Локальный уровень выброса (local outlier factor)
- Локальный уровень выброса на основе расстояния (local distance-based outlier factor)
Для оценки и интерпретации результатов выявления отклонений Elastic рассчитывает степень влияния признаков на искомое значение.
В качестве иллюстрации приведём несколько примеров применения Outlier detection:
- анализ метрик производительности для выявления отклонений в нагрузке на сервера со стороны сразу нескольких приложений (здесь);
- анализ отпечатков бинарных гистограмм исполняемых файлов для обнаружения обфусцированных и вредоносных файлов (здесь);
- анализ публичных объявлений airnbnb.com (insideairbnb.com) для поиска необычных предложений (здесь).
Цель анализа в этом примере — выявить необычное поведение пользователей интернет-магазина. Из магазина в систему поступают события оформления заказа продукции, каждое из которых содержит полное имя заказчика (customer_full_name.keyword), количество покупок в заказе (products.quantity), стоимость заказа (products.taxful_price), id заказа (order_id).
Документы в исходном индексе выглядят так
Начнём с подготовки данных для анализа. Так как мы сравниваем между собой заказчиков, то исходные события необходимо группировать по полю customer_full_name.keyword. Признаками поведения заказчиков будут выступать суммарные значения количества заказов, количества покупок, стоимость заказов.
Чтобы сгруппировать события, используем функцию трансформации transforms, которая позволяет «на лету» формировать и сохранять в Elasticsearch результаты агрегации ранее собранных данных.
Примечание: Для расчёта нужных признаков используем функции Elastic по агрегации: числовые значения считаем через products.quantity.sum и products.taxful_price.sum, а количество заказов — order_id.value_count.

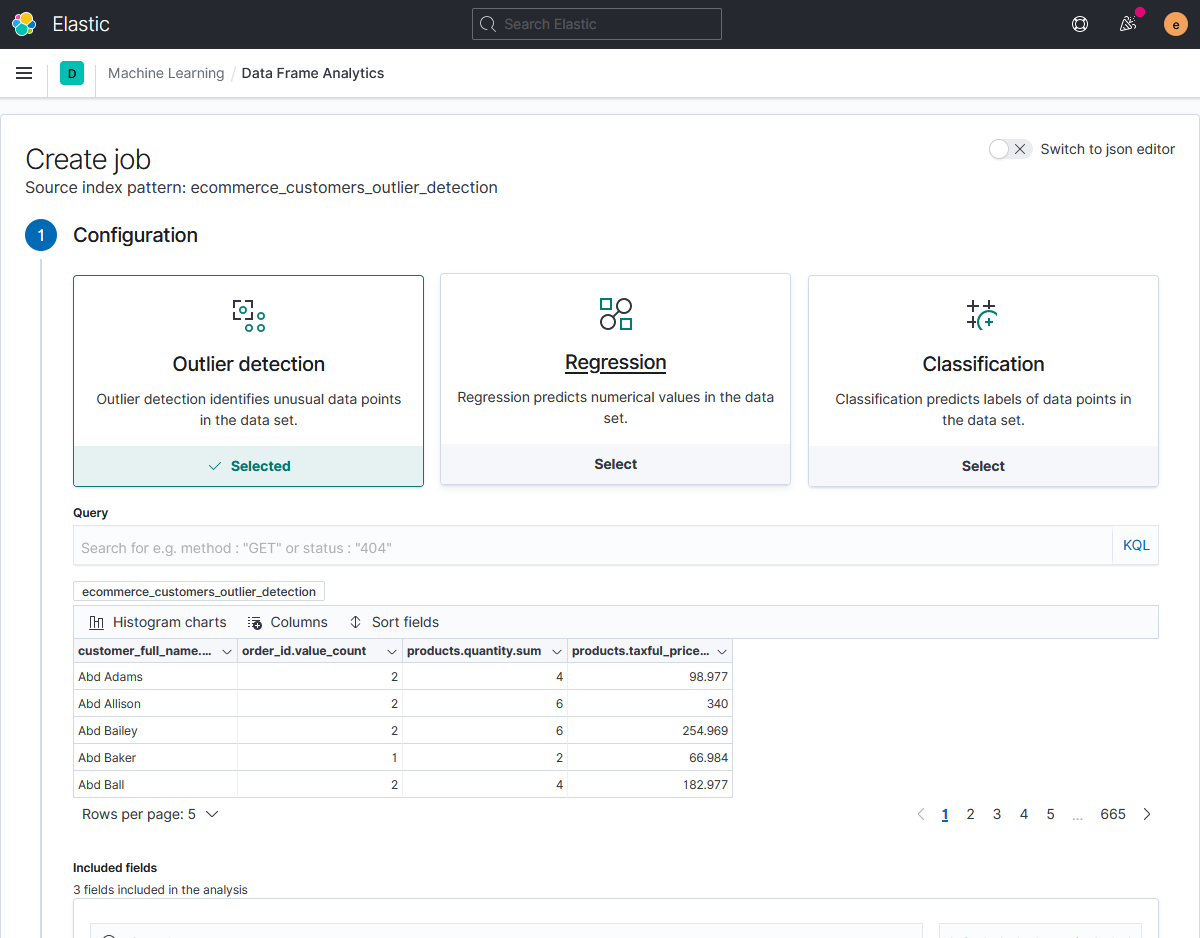
Результат агрегации, представленный в табличном виде, выглядит следующим образом:

Эти данные будем записывать в индекс ecommerce_customers_outlier_detection. Документы в нём соответствуют строкам указанной выше таблицы, а столбцы — полям в этих документах.
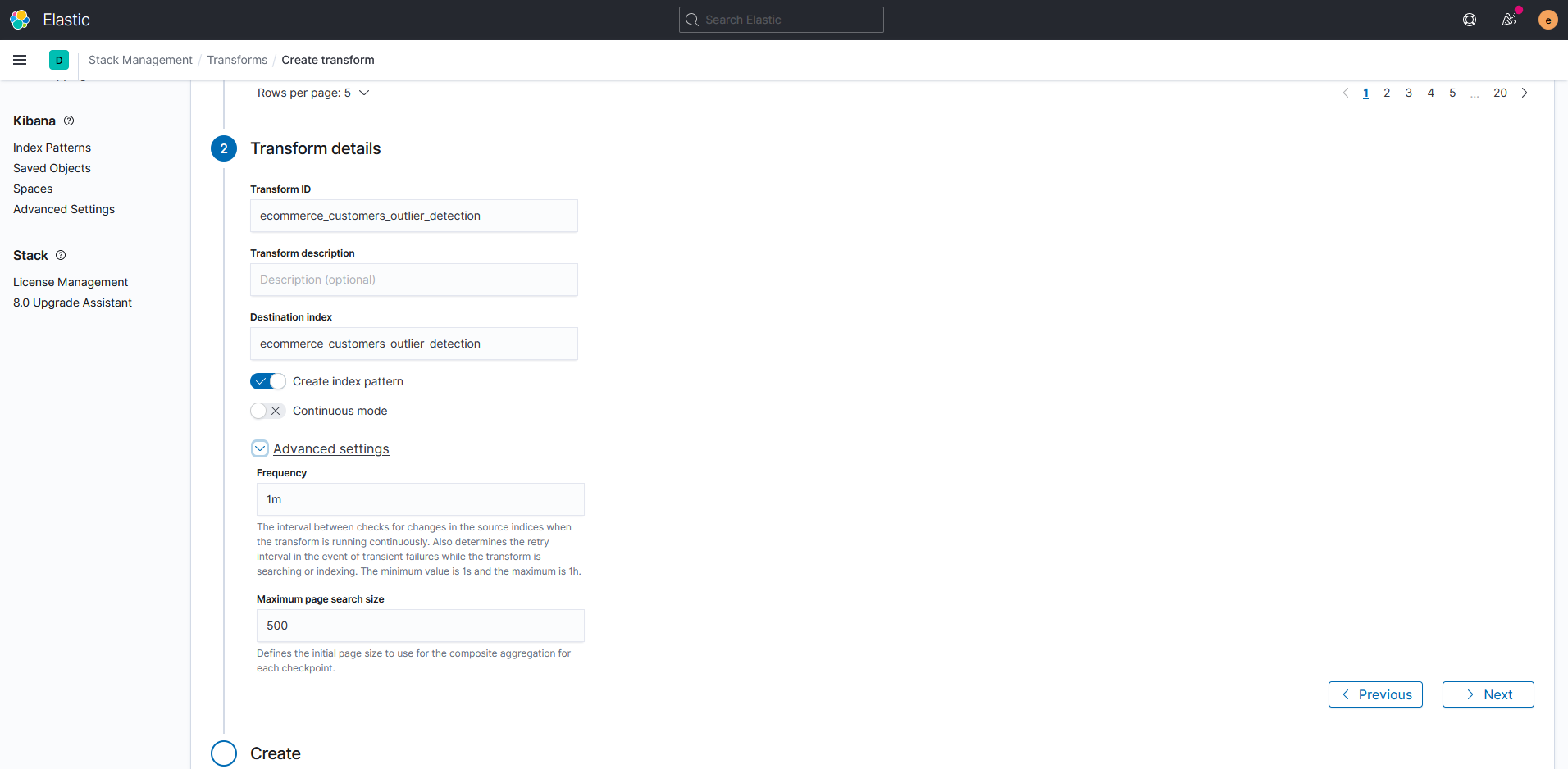
Чтобы просматривать индекс встроенными средствами Kibana, а не только через API, можно включить опцию "Create index template". Тогда соответствующий шаблон отображения индекса будет доступен в Kibana Discovery и при создании дашбордов в Kibana.
Опция "Continuous mode" включит выполнение трансформации в непрерывном режиме. Это обеспечит автоматическое обновление данных в индексе ecommerce_customers_outlier_detection с заданной периодичностью.
Примечание: Функцию транформации можно заменить правилом обработки данных, самостоятельно написанным для корреляционного движка watcher, также являющимся частью Elasticsearch.
Документы в результирующем индексе ecommerce_customers_outlier_detection выглядят следующим образом
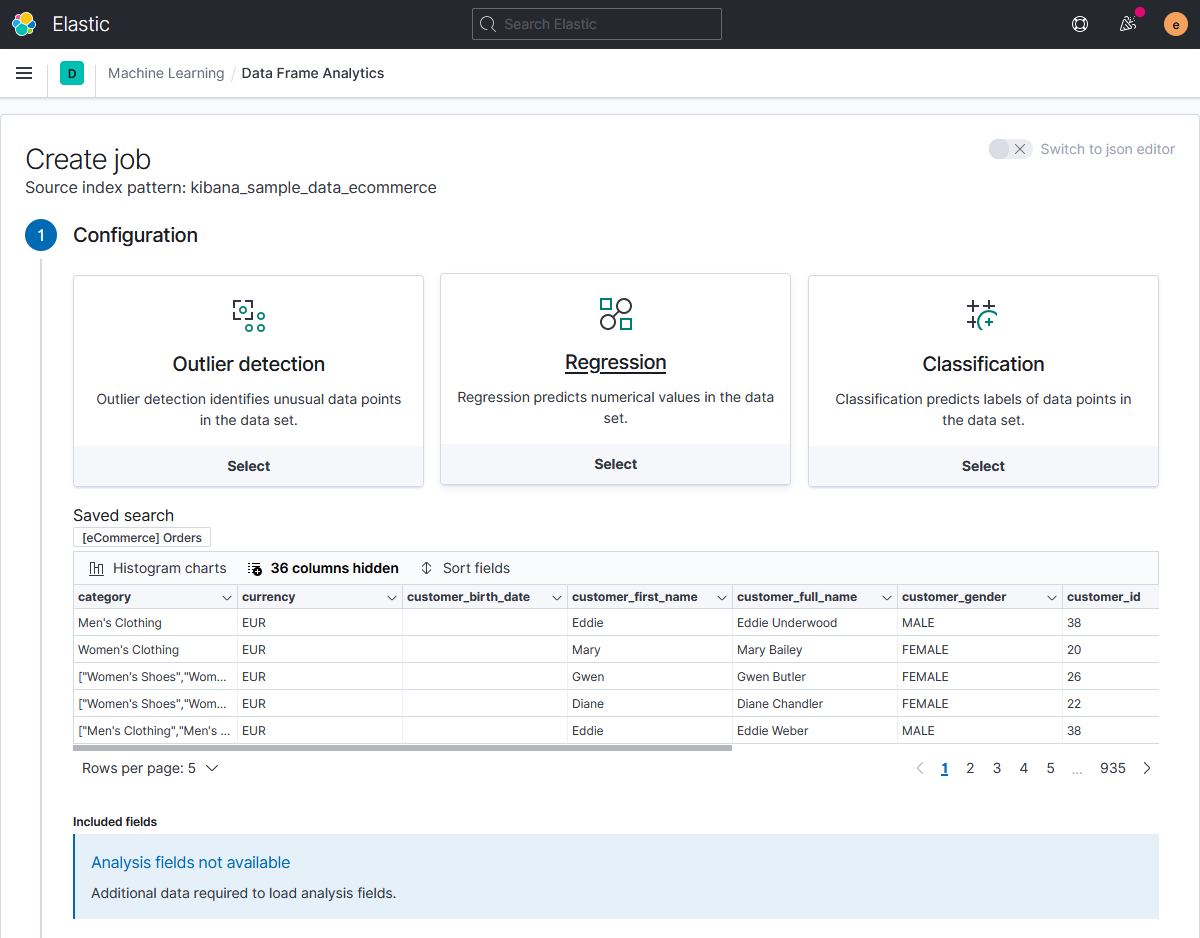
Теперь самое интересное — запускаем задачу машинного обучения (job — в терминах Elastic ML). Мастер создания задачи позволяет отфильтровать данные для анализа с использованием встроенных в Elasticsearch языков запросов KQL (Kibana query language) или Lucene.
Здесь же можно посмотреть анализируемые данные, а также наглядно визуализировать данные различных полей на диаграммах рассеяния.
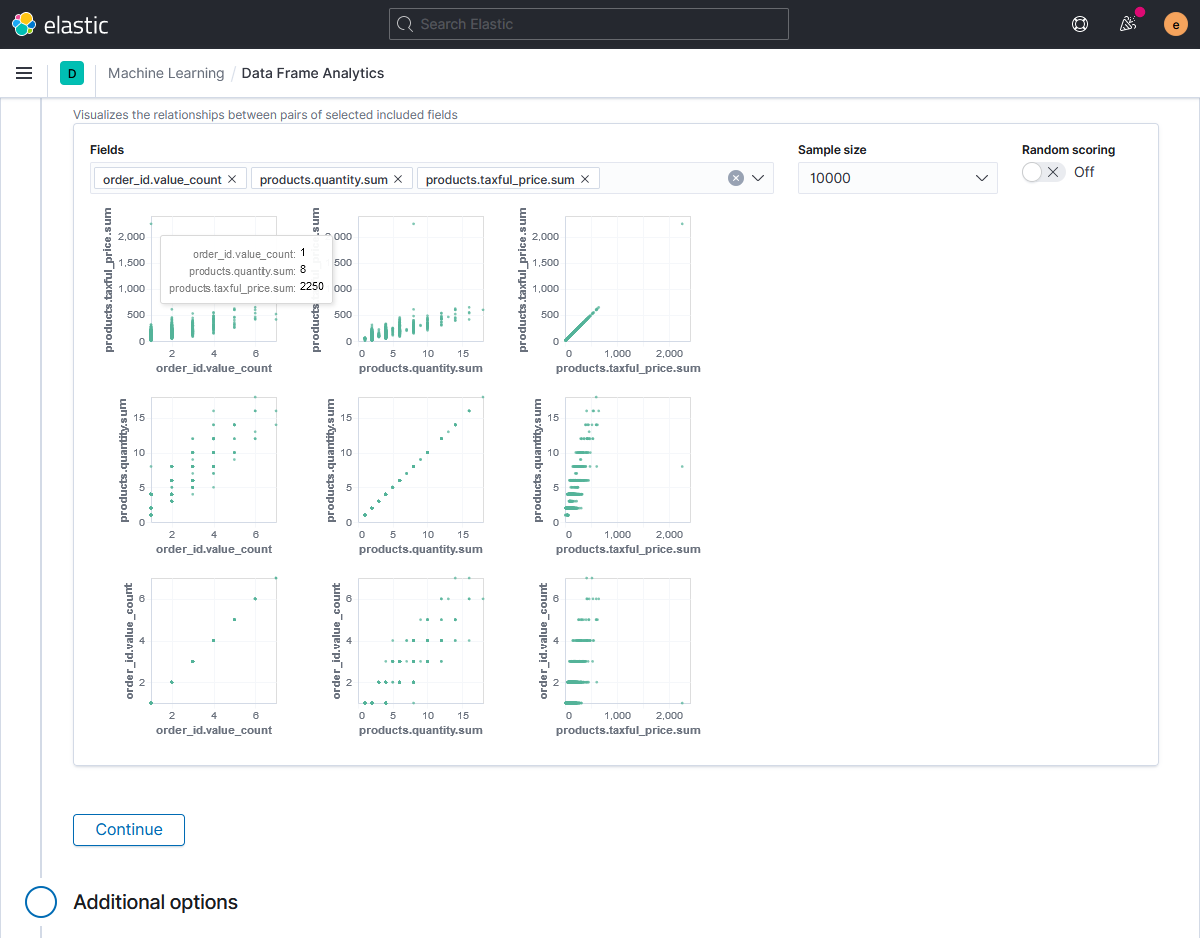
С помощью Advanced configuration параметров создания модели мы можем включить/выключить расчёт степени влияния признаков на модель (Compute feature influence), задать минимальное значение выброса для расчёта этого влияния (Feature influence threshold), а также объём выделенной под модель оперативной памяти (Model memory limit) и количество используемых заданием потоков процессора (Maximum number of threads), тем самым снижая или увеличивая нагрузку на кластер Elasticsearch.
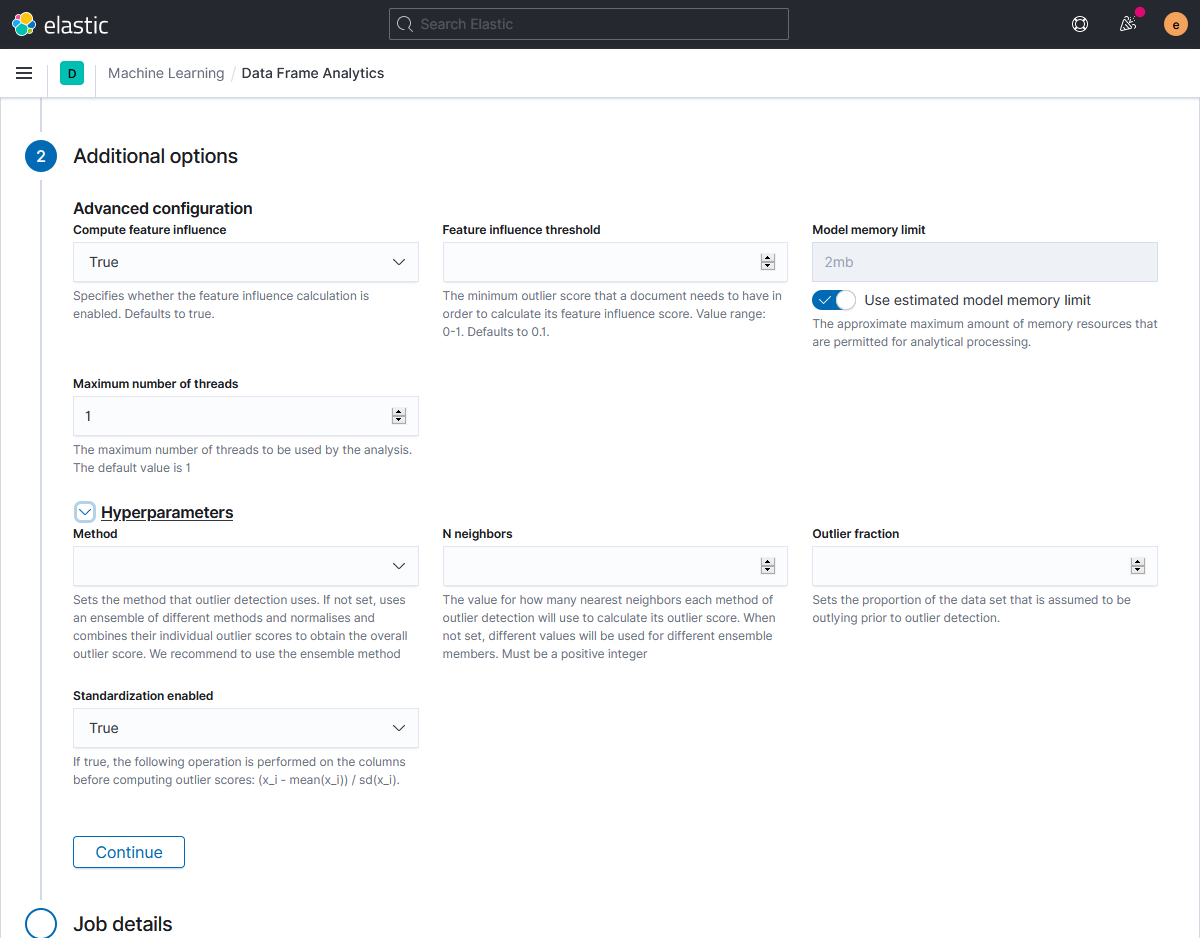
Блок Hyperparameters используется для управления параметрами обучения. Здесь можно выбрать:
- математический алгоритм (Method) обнаружения отклонений (lof, ldof, distance_kth_nn, distance_knn) или использования ансамбля алгоритмов (ensemble), когда значения отклонений определяются путём комбинации и оценки их результатов;
- количество используемых в расчётах соседей (N neighbors);
- переключатель использования предварительной стандартизации значений (Standardization enabled).
На завершающем шаге мастера указываем название и описание для задания, имя целевого индекса для сохранения результатов, имя поля с результатами анализа и необходимость создания шаблона в kibana.
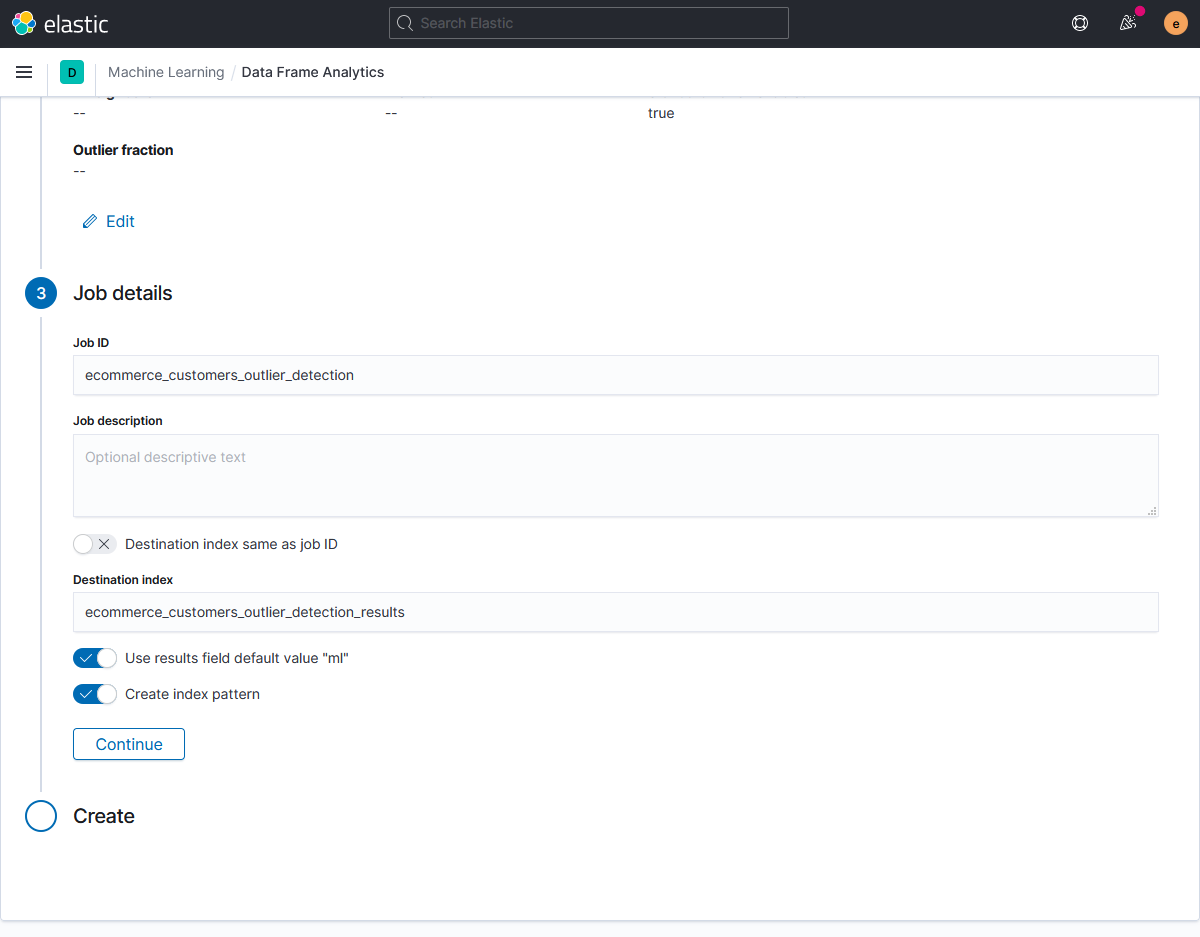
После запуска, задание проходит через этапы:
- создание результирующего индекса и добавление в него исходных данных (reindexing);
- загрузка данных из индекса (loading data);
- анализ данных и расчёт оценок выбросов (analyzing);
- запись значений оценок выбросов в результирующий индекс (writing results).
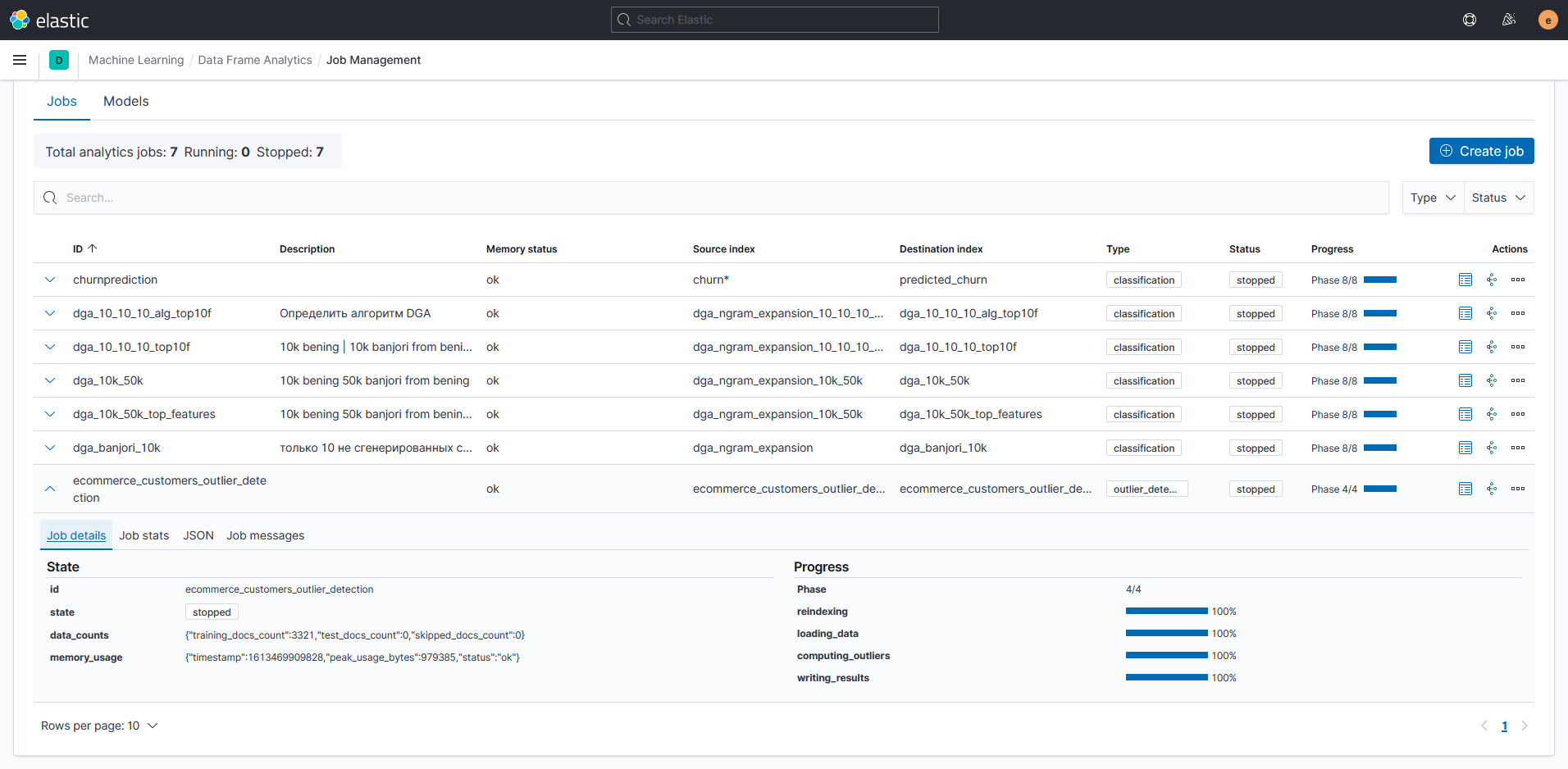
Результаты работы задания можно подробно рассмотреть через интерфейс Kibana Data frame analytics.
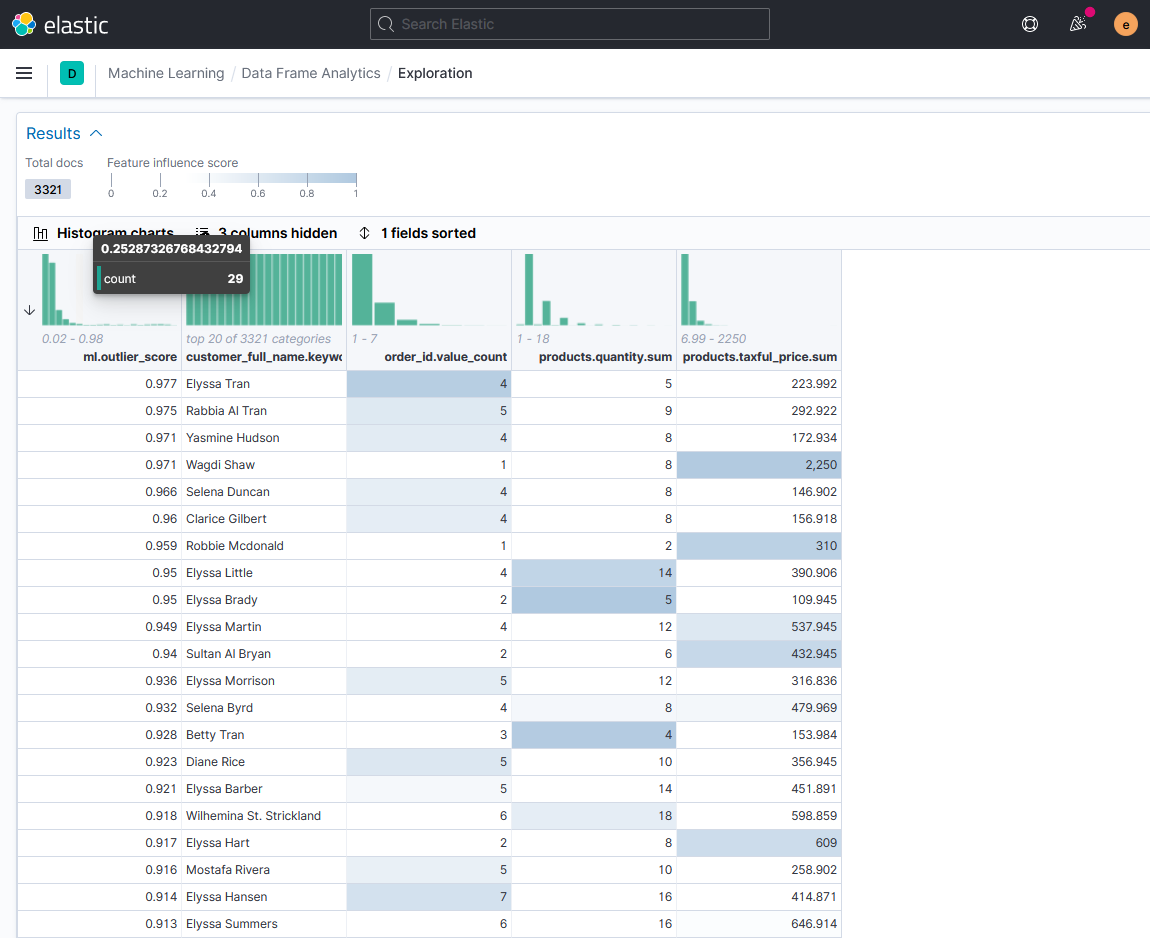
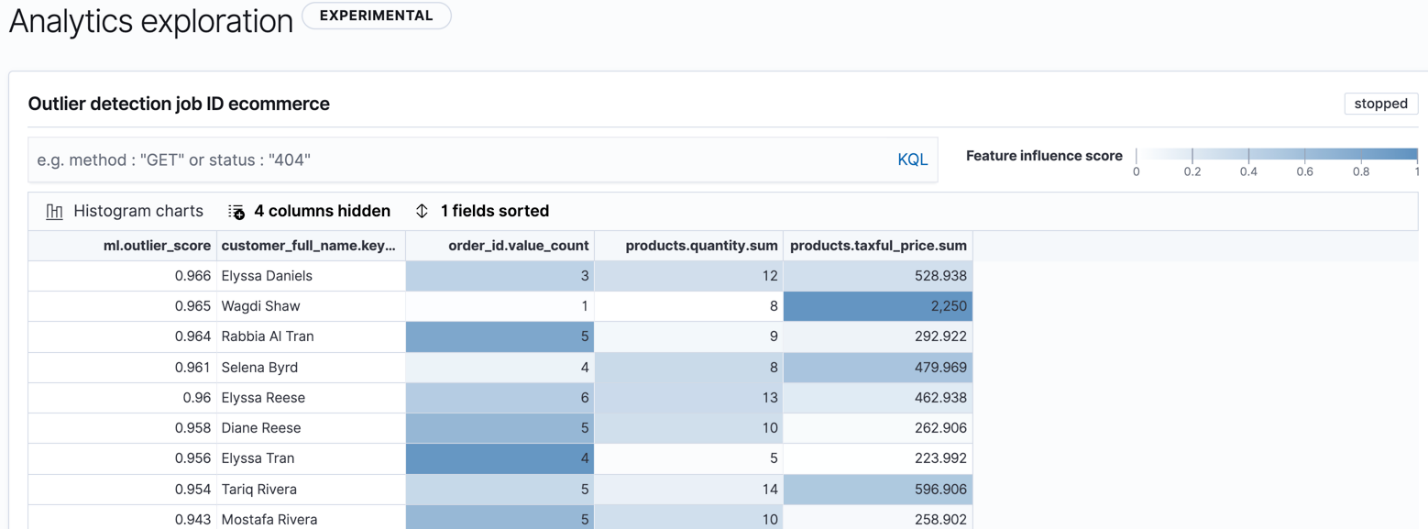
На таблице с результатами анализа видим значение совокупной оценки выброса для каждого заказчика (ml.outlier_score) и оценку влияния признаков по насыщенности цвета соответствующей ячейки. Соответствующее числовое значение оценки сохраняется в служебном индексе с результатами анализа в поле ml.feature_influence.
В итоговом индексе результат работы алгоритма выглядит следующим образом
Графически выбросы отображаются на диаграммах рассеяния. Здесь можно подсвечивать значения выбросов по выбранному порогу оценки.
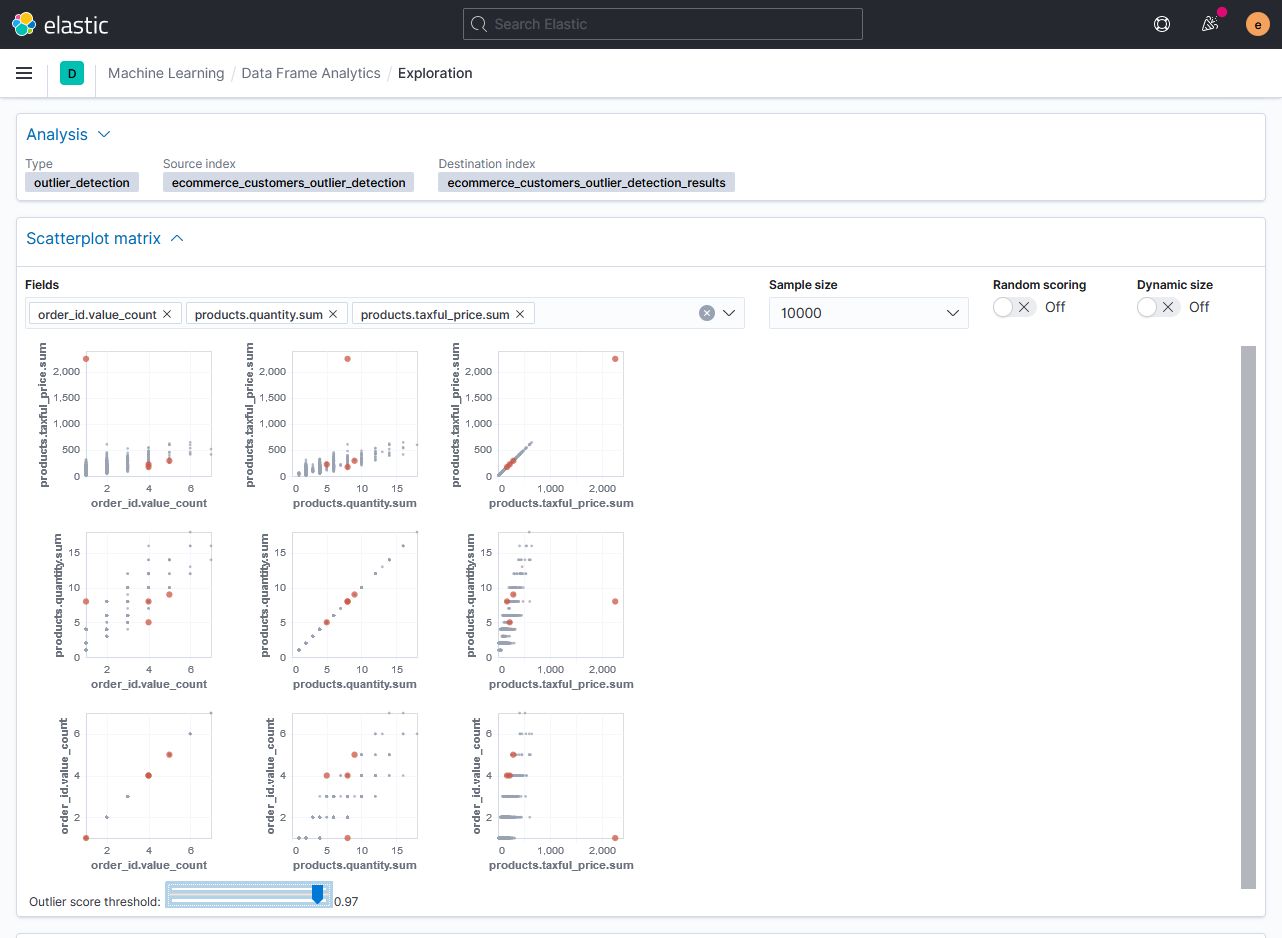
И включить отображение размера точек в соответствии со значением отклонения.
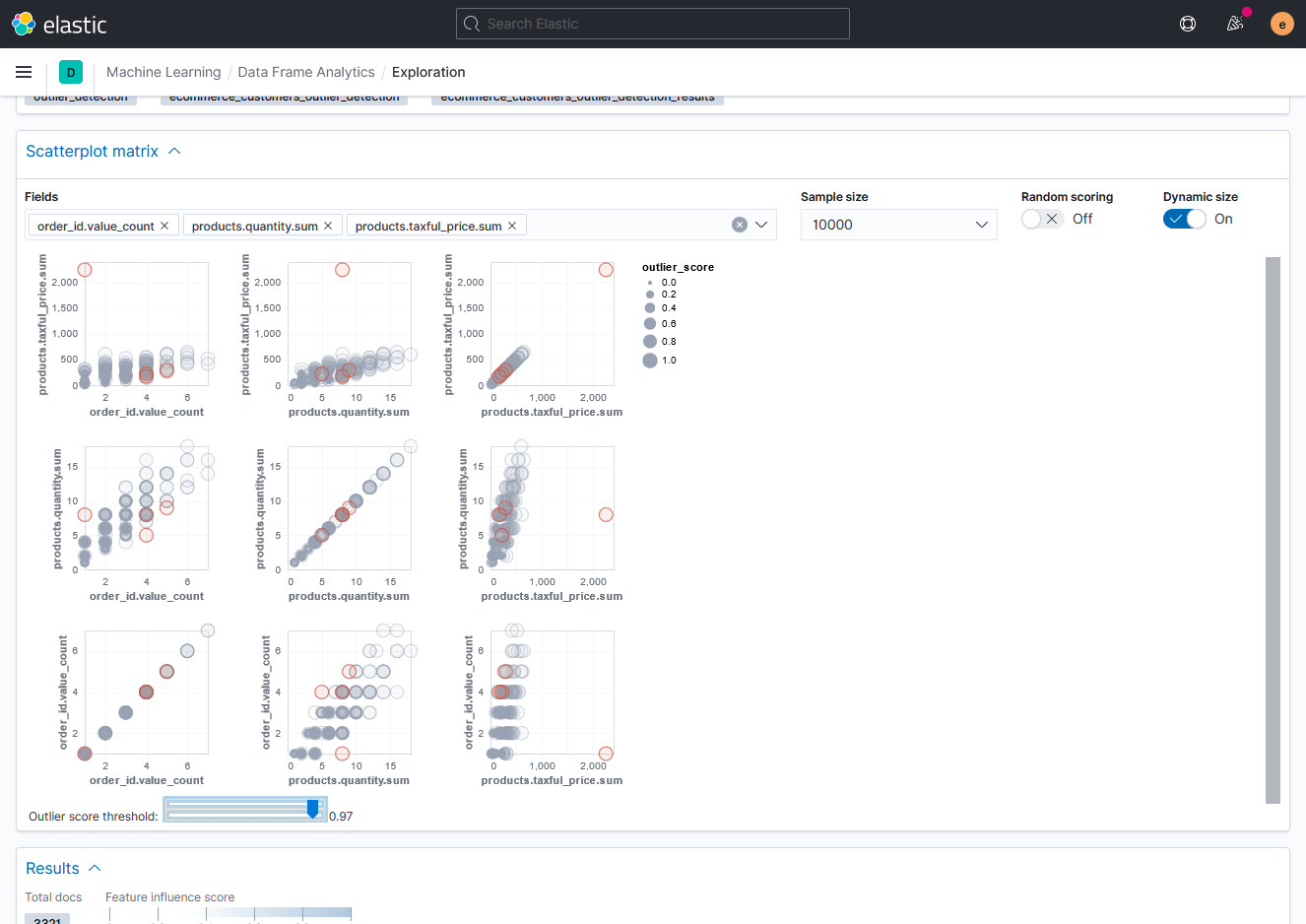
Примечание: Данные диаграммы разработаны с использованием языка Vega, доступного любому пользователю в конструкторе визуализаций Kibana.
Регрессия и классификация с учителем
Рассмотрим следующий набор функций Data frame analytics — контролируемое обучение (обучение с учителем). Они предоставляют пользователю возможность обучить в Elastic свою собственную модель и использовать её для автоматического предсказания значений. Модель можно загружать и выгружать из системы, а также оценивать её качество. Кроме того, через Eland поддерживается импорт в Elastic моделей, обученных с помощью библиотек scikit-learn, XGBoost или LightGBM. Вместе с возможностями платформы по сбору и обработке данных эти функции помогают реализовать в ней подход CRISP-DM (Cross-Industry Standard Process for Data Mining).В Elastic две функции обучения с учителем — регрессия и классификация. Если говорить проще, то цель функций — определение неизвестного значения объекта по значениям влияющих на него признаков. В случае регрессии речь идёт о предсказании числового значения, как характеристики объекта, а в случае классификации — об определении класса (группы), к которой относится объект.
Исходными данными (обучающим датасетом) для функции служит массив из уникальных записей (JSON документов). В каждой записи присутствует искомое поле (числовое для регрессии или категориальное для классификации) и поля признаков, влияющих на искомое поле. Значения искомого поля здесь используются для обучения модели и проверки её результатов. Результатом работы функции выступает обученная модель и новый массив данных, включающий исходный датасет, предсказанные значения и данными о степени влияния каждого признака. Датасет при этом можно использовать для оценки качества модели, а саму модель для анализа потока данных, поступающих в Elastic или ранее сохранённых в системе.
Схема реализации функций в Elastic
В качестве показателей поддерживаются числовые, логические и категориальные типы данных.
Обе функции используют собственные алгоритмы Elastic, построенные на базе градиентного бустинга деревьев решений XGBoost. Также возможно определение важности признаков по методу SHapley Additive exPlanations (SHAP).
Алгоритмы регрессии и классификации применяются для кредитного скоринга, оценки рисков, предсказания стоимости продукции, планирования производственных мощностей, обнаружения вредоносного программного обеспечения, мошеннических действий. Реализация этих функций на базе платформы анализа машинных данных с высокой скоростью сбора, индексации и поиска данных упрощает решение трудоёмких и ресурсоёмких задач, например, обнаружение активности сгенерированных доменов (DGA), анализ удовлетворённости клиентов, определение языка.
Далее разберем примеры использования регрессии и классификации и возможности платформы по интерпретации результатов их работы.
Регрессия
С помощью регрессионного анализа попробуем предсказать продолжительность задержки рейса, на примере из документации Elastic. Для анализа используем метеоданные, данные с табло вылета/прилёта и стоимость билетов.Документы в исходном индексе выглядят так
В данном случае функцию transforms применять не нужно, так как каждый документ датасета содержит данные только об одном полёте, и цель анализа — предсказать задержку в отношении каждого полёта. Но подготовить данные можно — исключим ошибочные записи с расстоянием перелёта 0 километров. В качестве предсказываемого (проверочного) поля указываем FlightDelayMin.
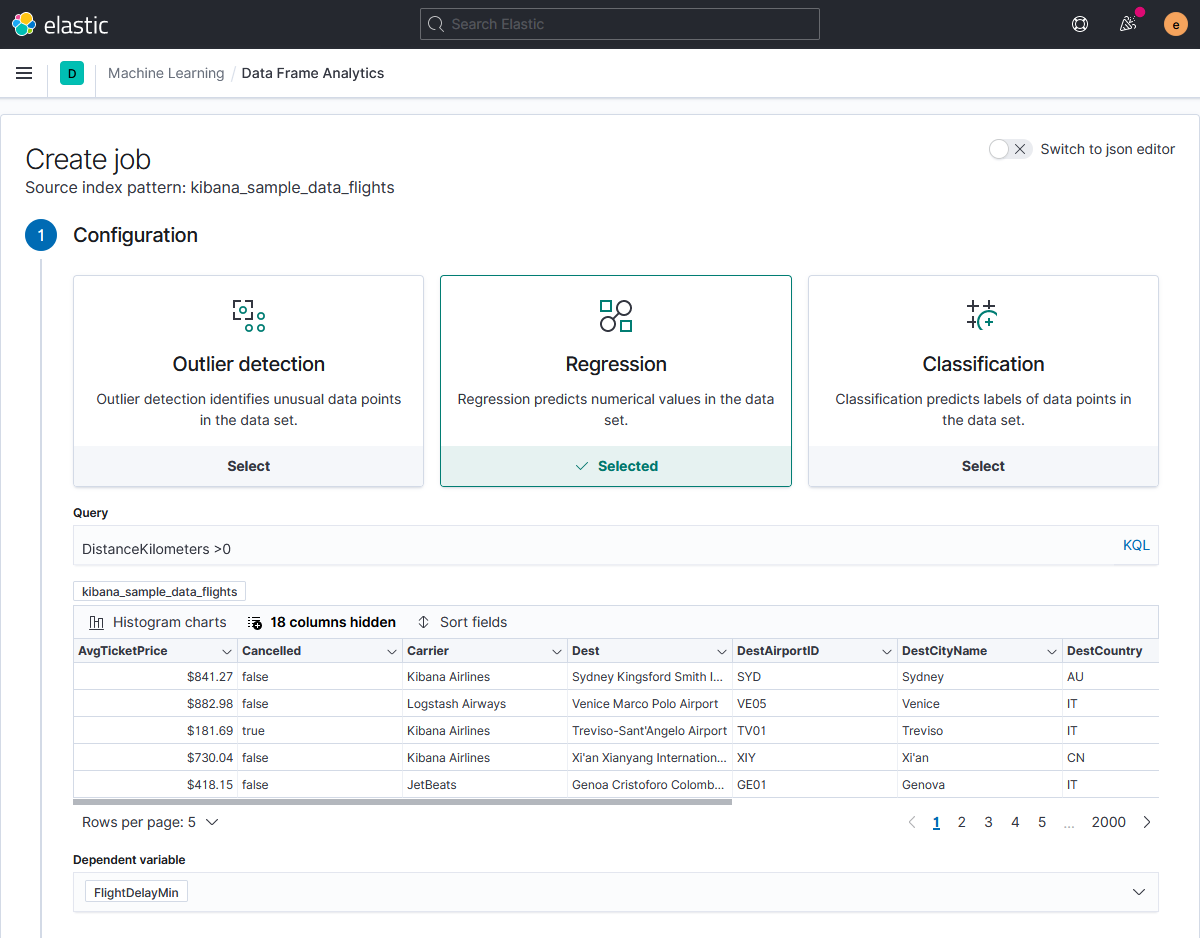
В таблице included Fields выбираем поля признаков длительности задержки рейса, которые будут учтены при построении модели.
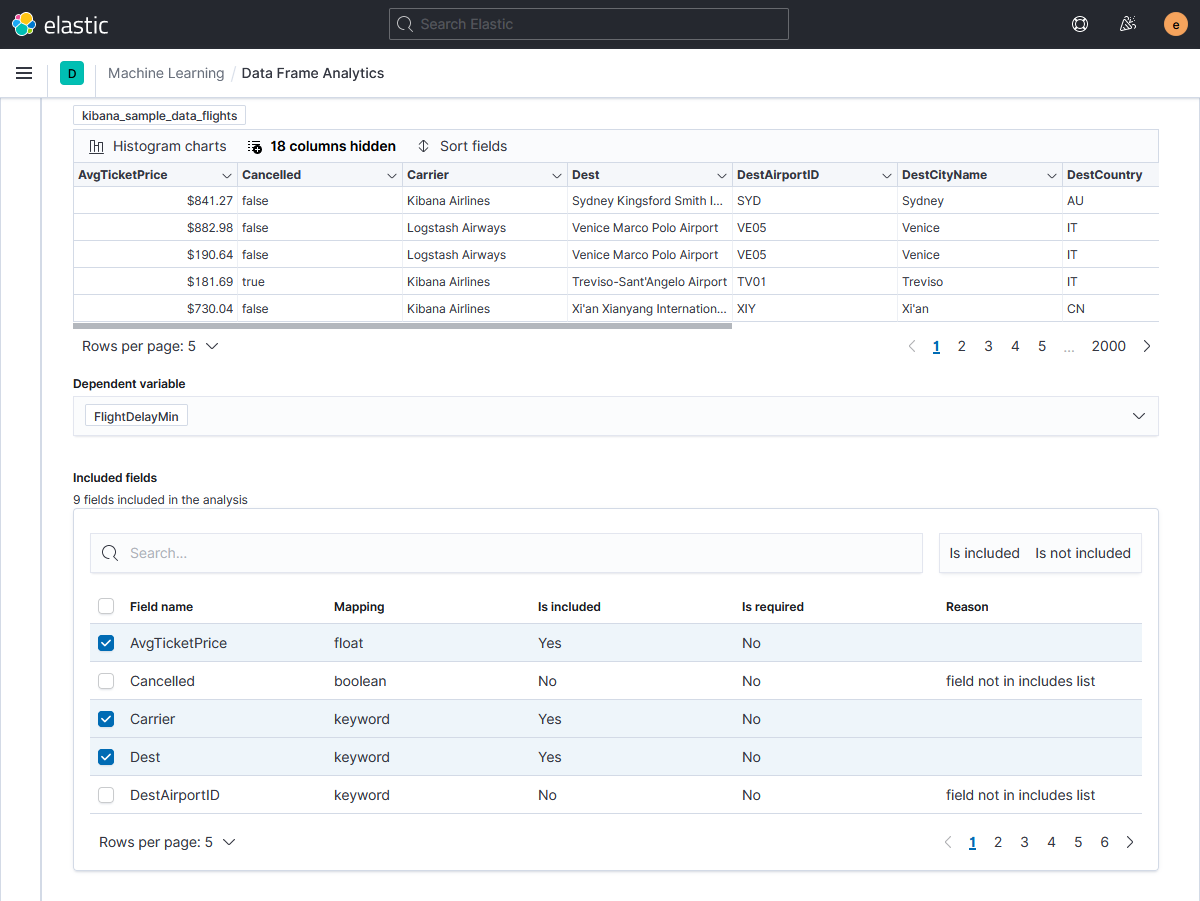
Как и при анализе выбросов, зависимости числовых признаков можно визуализировать на диаграмме рассеяния. В данном случае помимо взаимной зависимости параметров интенсивностью цвета на графиках отобразится их соотношение к предсказываемому значению.
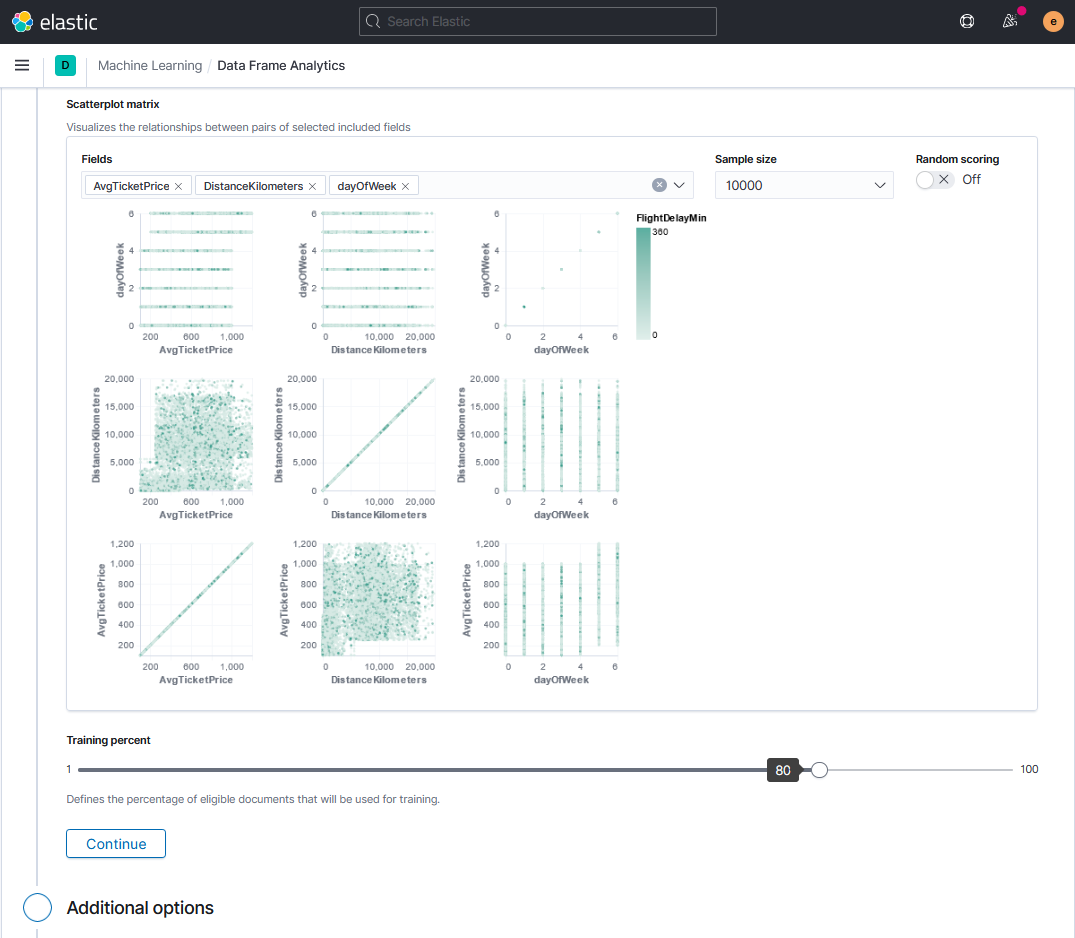
Обучение с учителем предполагает возможность проверки результатов предсказаний. Для этого используем исходный датасет, задав пропорцию разделения данных на учебные и тестовые.
Следующий шаг после выбора признаков — настройка параметров.

Advanced configuration:
- количество признаков, для которых в результирующий индекс будет записано значение влияния соответствующего признака на результат предсказания (Feature importance values);
- имя поля, в которое будет записан результат предсказания (Prediction field name);
- лимит на объём используемой заданием оперативной памяти (Model memory limit);
- максимальное количество используемых заданием потоков процессора (Maximum numbers of threads).
- коэффициент регуляризации Лямбда (Lambda);
- максимальное количество деревьев для бустинга (Max trees);
- коэффициент регуляризации Гамма (Gamma);
- размер градиентного шага Эта (Eta);
- доля выборки (Feature bag fraction);
- псевдослучайное число, используемое при выборе из датасета документов для обучения модели (Randomize seed).
Теперь посмотрим на результаты работы алгоритма. Они записываются в итоговый индекс Elasticsearch и представлены в отчёте в табличном виде.
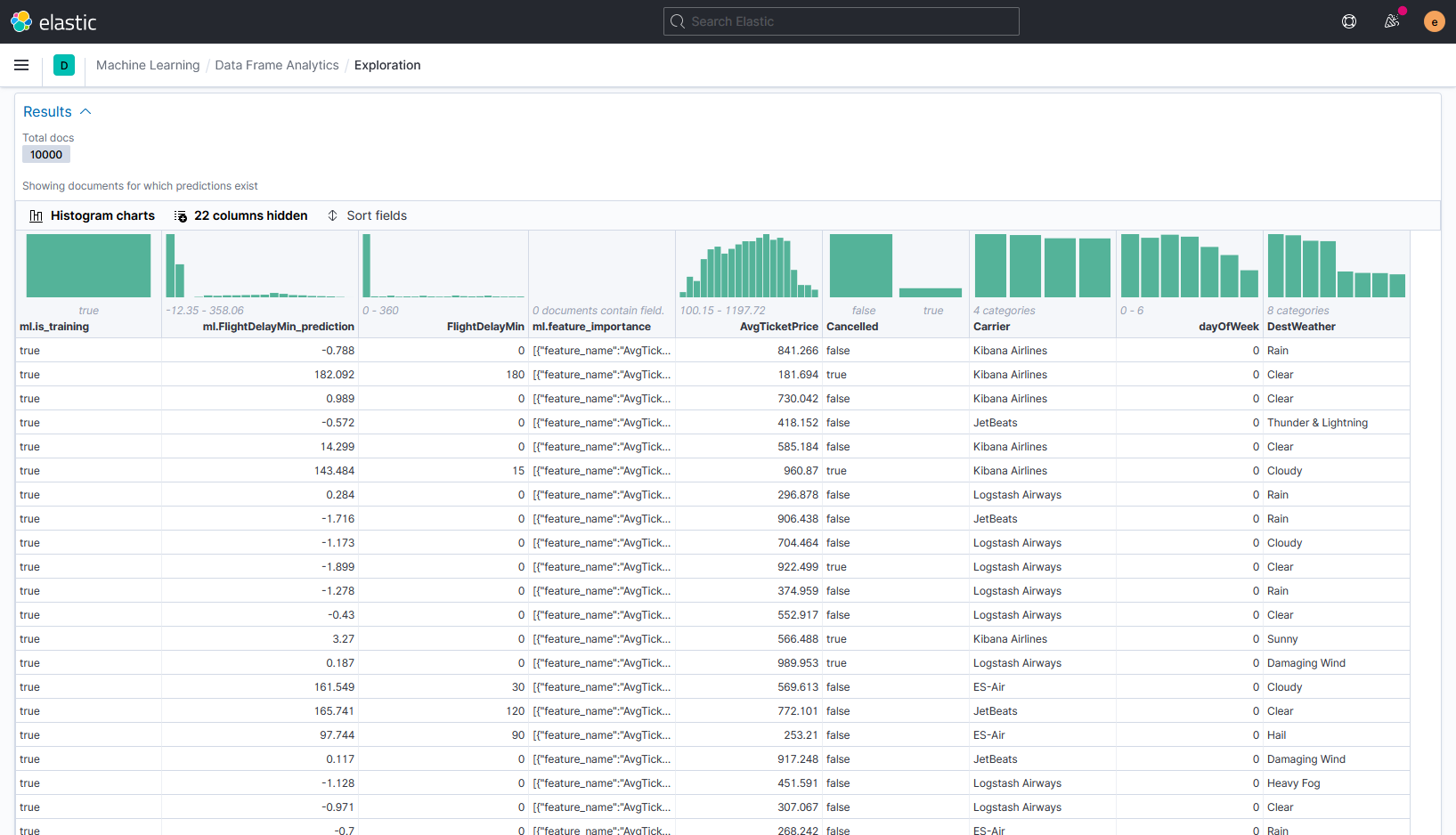
Здесь можно увидеть новые, по сравнению с датасетом, поля:
- Отметка об использовании данных для обучения (ml.is_training)
- Результаты предсказания задержки рейса (ml.FlightDelayMin_prediction)

При клике на поле ml.feature_importance увидим наглядный график принятия решения алгоритмом SHAP.
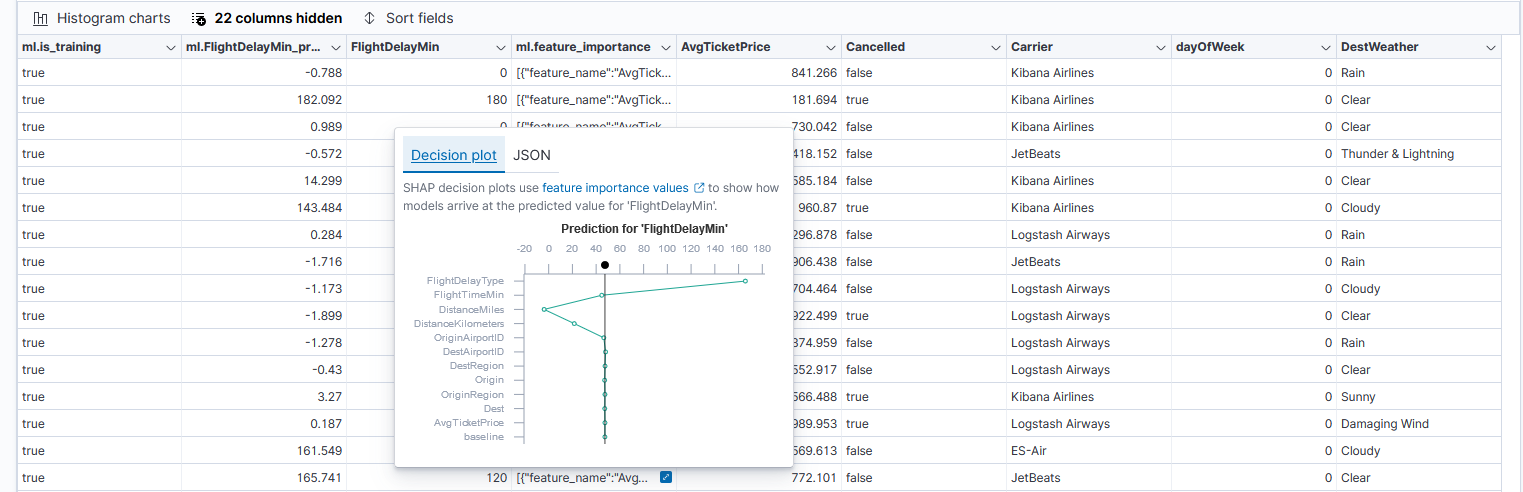
Точкой обозначено среднее значение прогнозов для всего датасета. Линией соединены значения степени влияния признаков, от меньшего к большему. Верхний признак сильнее всего влияет на решение, в нашем примере это причина задержки рейса (FlightDelayType).
Результаты доступны для просмотра и другими средствами визуализации Kibana
В этом же отчете можно увидеть метрики качества модели:
- среднеквадратическая ошибка (Mean Squared Error, MSE);
- коэффициент детерминации (R-squared, R2 );
- псевдо-функция потерь Хьюбера (Pseudo-Huber loss);
- среднеквадратичная логарифмическая ошибка (Mean squared logarithmic error, MSLE).

Метрики качества считаются отдельно, как для используемых при обучении данных, так и для тестовой выборки, что позволяет оценить применимость модели для новых, не используемых при обучении данных.
После того как модель сформирована, она может применяться для предсказания значений по новым данным. Для этого в Elasticsearch есть две возможности:
- анализ поступающих в Elasticsearch данных (Inference processor);
- анализ ранее сохранённых в Elasticsearch данных (Inference aggregation).
Пример c Inference aggregation
Классификация
Продолжим тему полетов и проанализируем данные об авиарейсах, предсказывая не длительность задержки, как в регрессии, а факт отмены рейса. Используем датасет из предыдущего примера, трансформация в агрегированный индекс здесь тоже не требуется.Порядок действий по созданию задания классификации совпадает с регрессионным анализом, только проверочным полем будет Cancelled.

Как и в предыдущих типах анализа, для числовых полей можно построить диаграммы рассеяния, при этом соответствующие значениям классы, в нашем случае true и false, выделяются цветом.
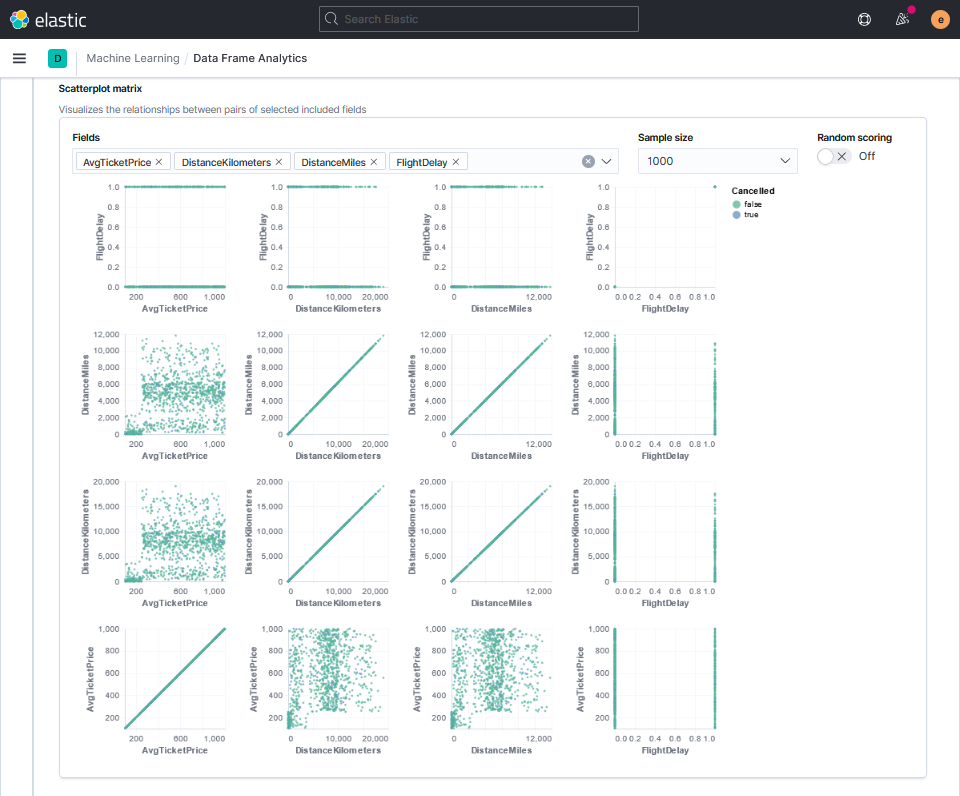
Остальные шаги аналогичны алгоритму регрессионного анализа, доступные в интерфейсе параметры тоже совпадают. Но возможности настройки задания ими не ограничиваются, через API доступных для редактирования гиперпараметров будет больше.
После завершения задачи можно оценить результаты предсказания отмены рейса.
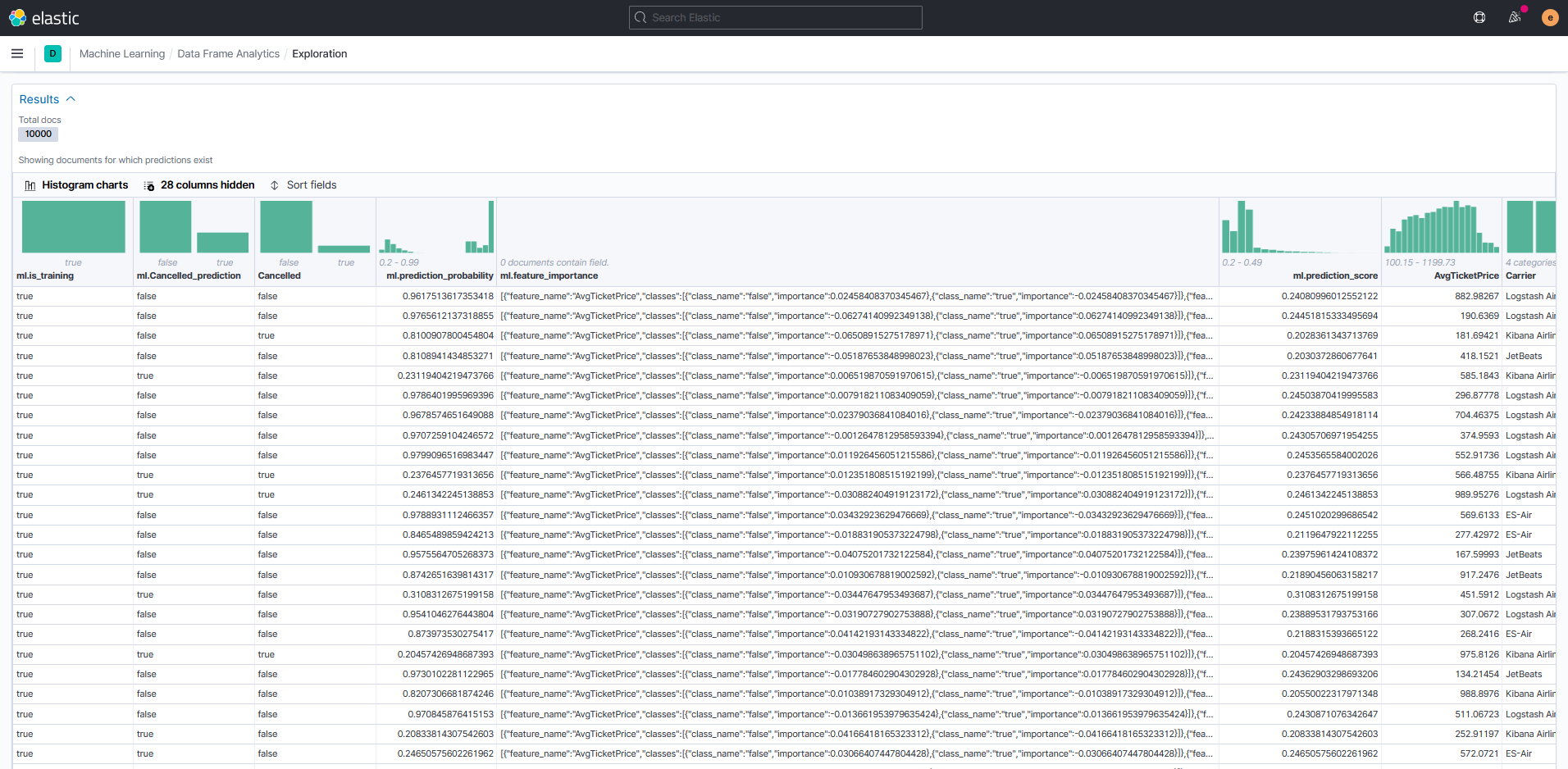
В таблице результатов данные датасета дополнены полями:
- отметка об использовании данных для обучения (ml.is_training);
- предсказанный статус отмены рейса (ml.Cancelled_prediction);
- вероятность предсказания (ml.prediction_probability);
- влияние признаков на результат (ml.feature_importance);
- оценка предсказания для всех искомых классов (ml.prediction_score).
В понимании параметров оценки поможет документация Elastic.
Как и в регрессии, в результатах доступен график усреднённых значений важности признаков.
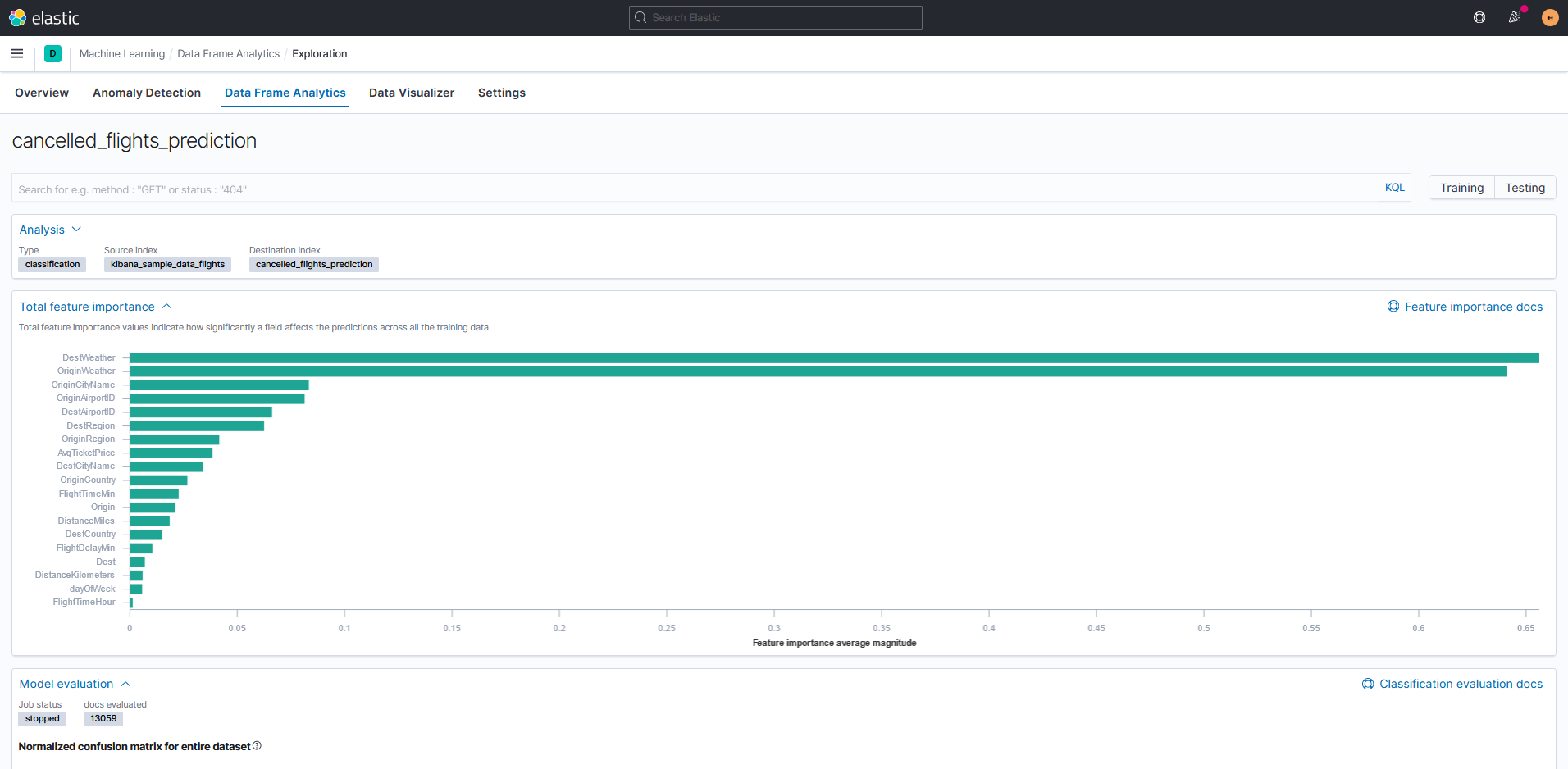
Для проверки результатов в классификации доступны следующие метрики:
- матрица ошибок (Confusion matrix);
- площадь кривой ошибок (area under receiver operating characteristic curve, AUC ROC).
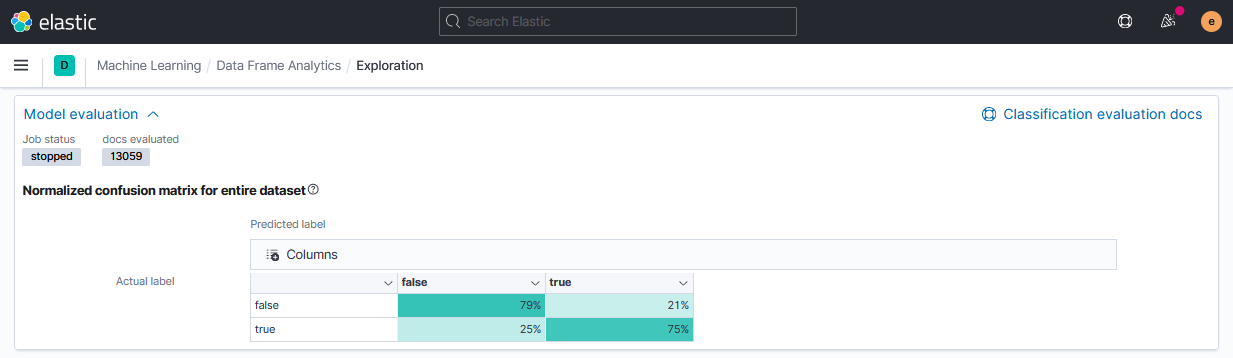
Кривая ошибок и значение площади AUC ROC в версии 7.11 не отображается, но значения можно получить через API. В 7.12 такая возможность уже будет добавлена.
Пример запроса AUC ROC
и ответа
Сохранённая модель доступна для использования в Inference processor и Inference aggregation, как в предыдущем примере.
Заключение
В заключение отметим, что функции машинного обучения в составе платформы Elastic могут использоваться для решения множества прикладных задач в самых разных отраслях, потенциал их применения только предстоит раскрыть.В будущем переход от бета-тестирования к релизным версиям описанных алгоритмов должен позволить анализировать большие потоки данных и может стать полезным инструментом для аналитиков центров мониторинга кибербезопасности, ИТ-инфраструктуры, приложений и бизнес-процессов.
Уже сейчас платформа даёт возможность ознакомиться и попробовать на практике технологии машинного обучения как искушённым аналитикам, так и инженерам без специальных знаний.
Источник статьи: https://habr.com/ru/company/step_logic/blog/546246/