Введение
Сегодня анализ данных стал неотъемлемой частью многих сфер деятельности, от науки до бизнеса. Python является одним из самых популярных инструментов для работы с данными, благодаря своей гибкости и обширному спектру доступных библиотек. Одной из таких библиотек является Pandas, предоставляющая удобные структуры данных и множество функций для анализа и обработки информации.В этих статьях (их будет несколько и их количество зависит от заинтересованности читателя) мы сосредоточимся на изучении некоторых полезных, но менее известных методов работы с данными в Pandas, которые могут значительно повысить вашу эффективность при анализе и обработке данных. Мы рассмотрим различные функции и техники для таких задач, как разделение данных на интервалы, квантильное разделение, применение скользящих окон для вычислений, смещение данных для временных рядов, преобразование вложенных структур данных, нормализация сложных JSON-структур и управление многоуровневыми индексами при работе с DataFrame и Series.
Изучение этих методов расширит ваш инструментарий и позволит справляться с более сложными и специфическими задачами, связанными с обработкой и анализом данных. Вместе мы углубимся в эти методы и рассмотрим конкретные примеры их использования, чтобы вы могли применять их на практике и улучшить свои навыки в области анализа данных с помощью Pandas.
Метод cut(). Разделение данных на интервалы в рамках RFM-анализа
Если вы, как и я, часто работали с различными пользовательскими базами, то обратили внимание на то, что одной из распространенных проблем является разделение пользователей на кластеры или группы с целью определения их поведенческих особенностей, предпочтений и лояльности. Этот подход может дать возможность более эффективно управлять коммуникацией с каждой группой, а также принимать более обоснованные решения по развитию бизнеса, учитывая различия в потребностях и интересах пользователей. Кроме того, кластеризация пользователей может помочь обнаружить скрытые зависимости между различными группами пользователей, что может привести к появлению новых идей и возможностей для улучшения продукта или услуги.Методика RFM-анализа (Recency, Frequency, Monetary) является одним из инструментов, позволяющих решить эту проблему. RFM-анализ разделяет пользователей на кластеры на основе трех параметров:
- Recency (R) — время с последней покупки (активности) пользователя,
- Frequency (F) — частота покупок (активности) пользователя,
- Monetary (M) — денежные траты (или доходы) пользователя.
Кроме того, RFM-анализ может быть более прозрачным и понятным, чем многие методы машинного обучения, что позволяет даже людям без специализированного образования в области анализа данных легче понимать полученные результаты. Это делает RFM-анализ доступным для большей аудитории, что может быть особенно полезно для малых и средних предприятий, где нет возможности привлекать специалистов в области анализа данных.
Метод cut() в Pandas может быть полезным при проведении RFM-анализа для категоризации пользователей на основе каждого из этих параметров. Основные аргументы метода cut() :
- x : Массив, серия или одномерный массив данных для разделения на интервалы.
- bins : Число интервалов, список границ интервалов или индекс для определения границ.
- labels : Список меток для категорий.
Предположим, что у нас есть следующие данные о пользователях:
import pandas as pd
data = pd.DataFrame({
'user_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'recency': [5, 30, 7, 22, 45, 10, 60, 4, 11, 29],
'frequency': [15, 5, 25, 12, 4, 19, 3, 10, 7, 22],
'monetary': [100, 80, 250, 120, 50, 175, 40, 110, 60, 210]
})
Эти данные, безусловно, являются «игрушечными», но на них будет легче понять принцип проведения такого рода аналитики. Наша задача — из непрерывных значений показателей Recency, Monetary и Frequency получить дискретные категории 1 , 2 , и 3 .
Разделим данные на категории с помощью метода cut() :
data['R'] = pd.cut(data['recency'], bins=3, labels=['3', '2', '1'])
data['F'] = pd.cut(data['frequency'], bins=3, labels=['1', '2', '3'])
data['M'] = pd.cut(data['monetary'], bins=3, labels=['1', '2', '3'])
Присваивание меток 3, 2 и 1 при проведении RFM-анализа имеет следующий смысл:
- Метка 3 обозначает высокий показатель для данного параметра, то есть пользователь относится к верхней группе по данному показателю.
- Метка 2 обозначает средний показатель, то есть пользователь относится к средней группе по данному показателю.
- Метка 1 обозначает низкий показатель, то есть пользователь относится к нижней группе по данному показателю.
Например, пользователь с RFM-кодом 333 относится к самому ценному кластеру, так как этот пользователь имеет недавнюю активность (высокий Recency), высокую частоту активности (Frequency) и высокий объем денежных трат или доходов (Monetary).
Пользователь с RFM-кодом 111, наоборот, будет являться менее ценным для бизнеса, так как он имеет давнюю активность, низкую частоту активности и низкий объем трат или доходов.
Вы заметили важный момент? Для показателя Recency метки идут в обратном порядке, потому что этот параметр оценивает время с последней активности пользователя, и меньшее значение Recency означает более недавнюю активность, что является положительным показателем.
В случае с Frequency и Monetary, большие значения означают высокую частоту активности и большие денежные траты, что также положительно, и поэтому метки идут в прямом порядке (1 — низкий, 2 — средний, 3 — высокий).
Возвратимся к нашему коду и создадим RFM-сегменты путем объединения R, F и M меток:
data['RFM'] = data['R'].astype(str) + data['F'].astype(str) + data['M'].astype(str)
print(data)
Теперь наши данные выглядят следующим образом:
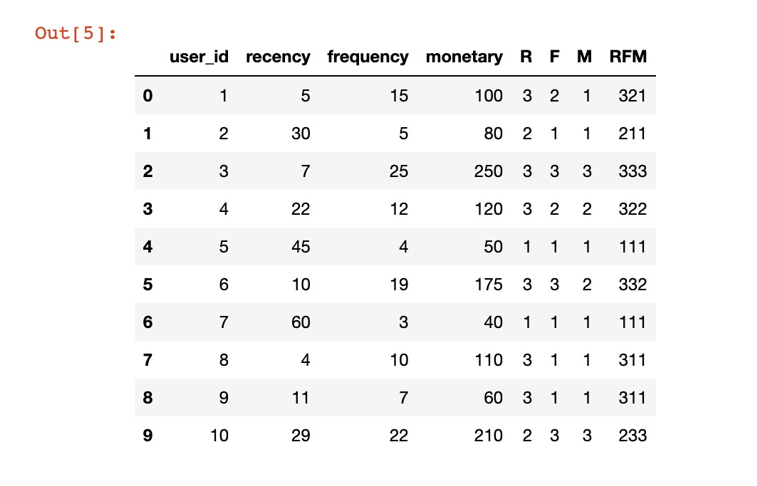
Теперь у нас есть 10 пользователей с разными значениями Recency, Frequency и Monetary. Метод cut() разделил эти параметры на 3 категории, и мы получили несколько RFM-сегментов пользователей, объединяя полученные метки.
В рамках RFM-анализа выделяются различные кластеры (сегменты) пользователей, основанные на комбинации меток R, F и M. Некоторые из наиболее общих сегментов включают:
- Ценные пользователи ( 333 ): это пользователи с наиболее недавней активностью, высокой частотой и высокими денежными тратами. Они представляют особый интерес для бизнеса и должны получать больше внимания и лучшие предложения.
- Новые пользователи с потенциалом ( 313 или 3x3 ): эти пользователи недавно активировались и уже потратили приличную сумму денег, но их частота активности все еще низкая. Их стоит стимулировать совершать больше активностей.
- Угасающие пользователи ( 1x1 ): это пользователи с давней активностью, низкой частотой и низкими денежными тратами. Они представляют наименьший интерес для бизнеса, и с ними стоит работать только в рамках общих маркетинговых кампаний.
- Вернувшиеся пользователи ( 13x ): эти пользователи имели давнюю активность, но недавно вернулись и проявили высокую активность и/или денежные траты. Им следует предложить специальные акции или скидки, чтобы удержать их и превратить в лояльных пользователей.
- Лояльные пользователи ( x3x ): пользователи с высокой частотой активности, независимо от их недавности и денежных трат. Им стоит предложить программы лояльности или специальные акции, чтобы поддерживать их интерес.
- Большие траты ( xx3 ): пользователи с высокими денежными тратами, независимо от их недавности и частоты активности. Их можно мотивировать с помощью персонализированных предложений, скидок на основе суммы покупок или эксклюзивных продуктов.
- Спящие пользователи ( 1x3 ): пользователи с высокими денежными тратами и частотой активности в прошлом, но давней активностью. Для их возвращения можно использовать реактивационные кампании, напоминающие о преимуществах и предложениях компании.
Затем присвоим каждой строке значение сегмента на основе соответствующих условий.
def assign_segment(row):
rfm = row['RFM']
if rfm == '333':
return 'Ценные пользователи'
elif rfm[0] == '3' and rfm[2] == '3':
return 'Новые пользователи с потенциалом'
elif rfm == '111':
return 'Угасающие пользователи'
elif rfm[0] == '1' and rfm[1] == '3':
return 'Вернувшиеся пользователи'
elif rfm[1] == '3':
return 'Лояльные пользователи'
elif rfm[2] == '3':
return 'Большие траты'
elif rfm[0] == '1' and rfm[1] == '3':
return 'Спящие пользователи'
else:
return 'Другие'
data['Segment'] = data.apply(assign_segment, axis=1)
print(data)
После выполнения этого кода, в DataFrame data появится новая колонка Segment , содержащая сегменты пользователей на основе их показателя RFM.
Обратите внимание, что мы также включили сегмент «Другие» для пользователей, которые не попадают ни в один из описанных выше сегментов. Это позволяет учесть все возможные комбинации меток RFM и гарантирует, что каждый пользователь будет отнесен к определенному сегменту.
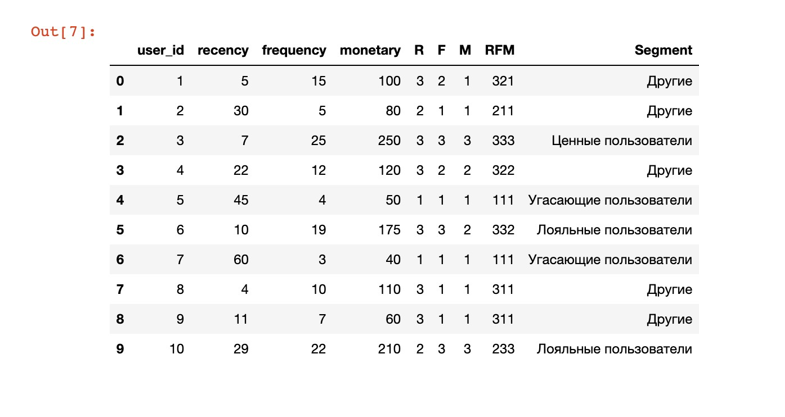
Сегмент «Другие» может быть дополнительно уточнен путем введения более точных правил сегментации, которые учитывают специфические особенности бизнеса и пользовательской базы. Вместо того, чтобы использовать обобщенный сегмент «Другие», можно определить новые сегменты, основанные на комбинациях показателей RFM, которые наиболее актуальны для конкретной отрасли или организации.
Кроме того, названия сегментов могут различаться и выбираются аналитиком, исходя из конкретных особенностей анализируемых данных и целей анализа. Главное выбирать названия сегментов, которые точно отражают их характеристики, и могут быть легко поняты и интерпретированы заказчиками и другими членами команды.
Метод qcut(). Квантильное разделение данных
При использовании метода cut() для разделения данных на интервалы можно заметить, что данные могут быть разделены неравномерно. Это происходит потому, что метод cut() разбивает данные на равные интервалы на основе значений показателей, не учитывая их распределение. Если в данных присутствуют выбросы или они имеют неравномерное распределение, это может привести к несбалансированному количеству пользователей в каждом интервале.Это можно заменить, если применить метод value_counts() к каждому из показателей Recency, Frequency и Monetary:
data['R'].value_counts(),data['F'].value_counts(),data['M'].value_counts()

Чтобы добиться более равномерного распределения сегментов, можно воспользоваться методом qcut() . Вместо разделения данных на равные интервалы по значениям, qcut()разделяет данные на квантили, гарантируя равное количество пользователей в каждом интервале.
data['R_qcut'] = pd.qcut(data['recency'], q=3, labels=['3', '2', '1'])
data['F_qcut'] = pd.qcut(data['frequency'], q=3, labels=['1', '2', '3'])
data['M_qcut'] = pd.qcut(data['monetary'], q=3, labels=['1', '2', '3'])
В данном случае, мы применяем метод qcut() для разделения данных на три квантиля (q=3) по каждому из показателей: Recency, Frequency и Monetary.
Затем, мы присваиваем метки ['3', '2', '1'] для обозначения высоких, средних и низких значений соответственно.
Квантили — это статистические показатели, которые разделяют набор данных на равные части. Квантили включают квартили (25%, 50% и 75%), децили (каждые 10%) и процентили (каждые 1%). В данном случае, мы разделили показатели на 3 равных отрезка с границами приблизительно находящимися на отметках 33,3% и 66,7%.
Можно посмотреть на границы квантилей с помощью функции quantile() :
recency_quantiles = data['recency'].quantile([1/3, 2/3])
frequency_quantiles = data['frequency'].quantile([1/3, 2/3])
monetary_quantiles = data['monetary'].quantile([1/3, 2/3])
print("Recency quantiles:", recency_quantiles)
print("Frequency quantiles:", frequency_quantiles)
print("Monetary quantiles:", monetary_quantiles)
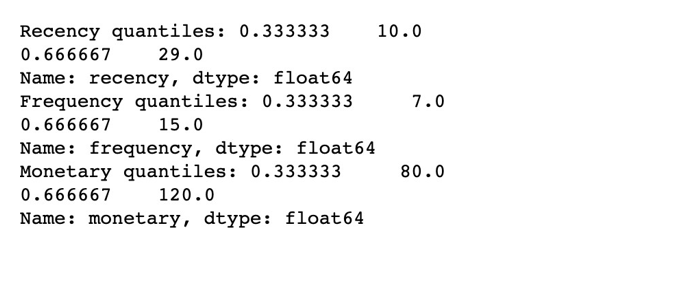
На примере показателя Recency, видим, что граница находящаяся на отметке 33,3% делит наши данные на те, что больше или меньше 10, а граница на отметке 66,7% — больше или меньше 29.
Если мы повторно воспользуемся value_counts (), то увидим, что теперь распределение данных между показателями Recency, Frequency, Monetary стало равномерным:
data['R_qcut'].value_counts(),data['F_qcut'].value_counts(),data['M_qcut'].value_counts()

Использование методов cut() и qcut() для сегментации пользователей имеет свои преимущества и недостатки, и выбор между ними зависит от конкретных целей исследования и качества сами данных в пользовательской базе.
Методcut()хорошо подходит для равномерно распределенных данных и может обеспечить хорошую сегментацию пользователей. Данные при этом будут разделены на равные интервалы, что удобно для интерпретации и визуализации данных.
Метод qcut() предпочтительнее, когда важно обеспечить равномерное распределение данных по сегментам, особенно для неравномерно распределенных данных или данных с выбросами. Однако, интервалы, созданные с помощью qcut(), могут быть непостоянными и сложными для интерпретации, особенно если данные имеют сложную структуру.
Заключение
Использование методов cut() и qcut()может быть полезно для сегментации пользовательских баз в рамках RFM-анализа, поскольку эти методы позволяют быстро и эффективно группировать пользователей на основе важных показателей, таких как Recency, Frequency и Monetary. Они просты в применении, легко интерпретируются и не требуют сложных вычислений или знаний в области машинного обучения.В сравнении c построением моделей машинного обучения, методы cut() и qcut() могут предложить более непосредственный и интуитивно понятный способ сегментации пользователей. Модели машинного обучения, такие как кластеризация, могут быть сложными и требовательными к ресурсам, а также могут потребовать дополнительных данных или предварительной обработки. В то время как cut() иqcut()позволяют сегментировать пользователей на основе их поведения, не требуя обучения модели или настройки гиперпараметров.
Однако стоит отметить, что методы cut() и qcut()не всегда могут заменить модели машинного обучения, особенно когда имеется сложная структура данных или требуется более глубокий анализ. В этих случаях модели машинного обучения могут быть более точными и прогностически эффективными. Тем не менее, для быстрой и простой сегментации пользователей в рамках RFM-анализа методы cut() и qcut() представляют собой прекрасный инструмент, который может быть полезным для многих аналитиков и маркетологов.
В следующей статье мы подробно рассмотрим применение скользящих окон для вычислений и смещение данных для анализа временных рядов.
Скользящие окна позволяют проводить агрегированные вычисления на подмножествах данных, что может быть полезно для определения трендов, сезонности и аномалий во временных рядах. Мы также изучим использование смещения данных для создания лаговых переменных и их применение в различных задачах прогнозирования. Эти методы являются важными инструментами для аналитиков и помогут лучше понять и предсказать динамику каких-либо процессов или явлений.

Полезные методы работы с данными в Pandas. Часть 1
Автор статьи: Роман Козлов Руководитель курса BI-аналитика Введение Сегодня анализ данных стал неотъемлемой частью многих сфер деятельности, от науки до бизнеса. Python является одним из самых...
 habr.com
habr.com