Большинство инженеров, работающих с машинным обучением, уже знакомы с форматом данных ONNX. Его часто используют для хранения обученных моделей и конвертации их мeжду фреймворками.
В этой статье расскажу об ONNX и о том, почему этот формат данных широко используется. Посмотрим на особенности формата и конвертации в него и на экосистему полезных инструментов.
Изначально ONNX задумывался как открытый формат представления нейросети, который свяжет представление моделей в разных фреймворках.
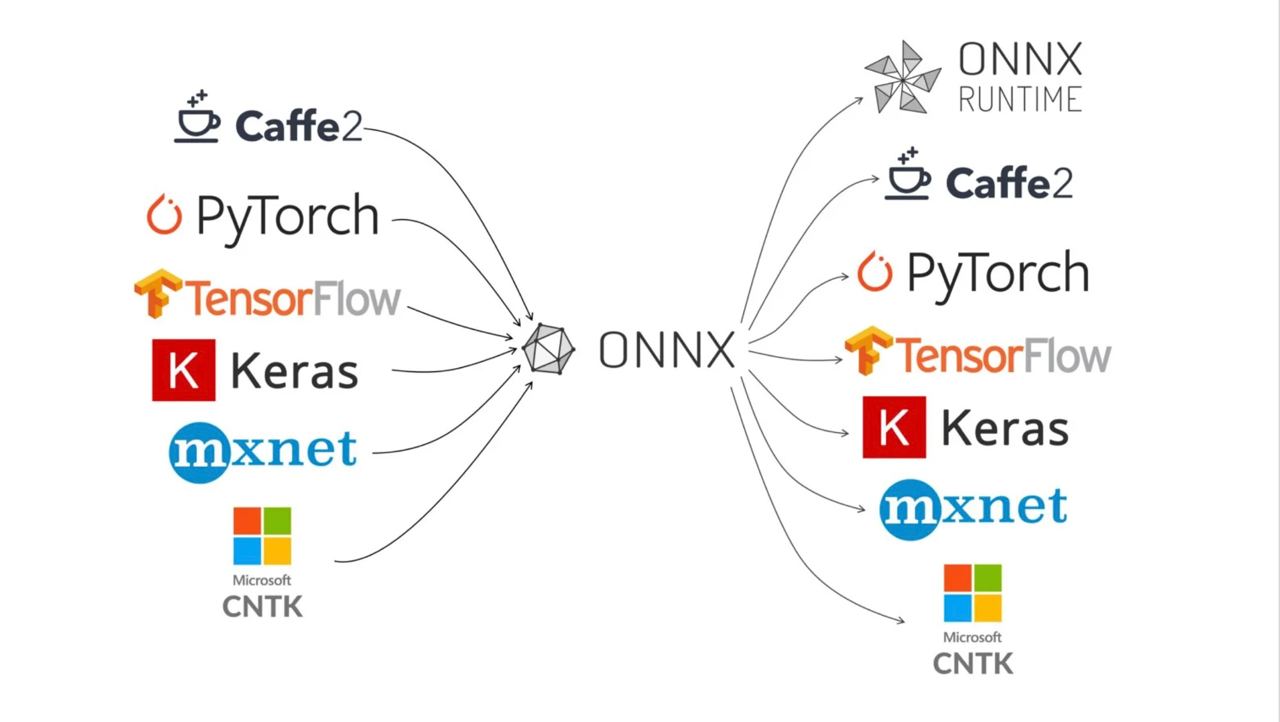
В первом релизе речь шла о Caffe2, PyTorch и CNTK. Сейчас многие крупные фреймворки стараются его поддерживать (картинка с официального сайта):

Поддерживаемые фреймворки с официального сайта
Кроме того, спустя год появился onnxruntime - фреймворк для инференса в формате ONNX, который реализовал различные оптимизаторы поверх ONNX формата.

ONNX как связь между обучением и инференсом
Давайте разберем на примере одной из ситуаций, благодаря которой ONNX быстро набрал популярность.
Нейронные сети к 2016 массово учили несколько лет. Тогда в проде у многих был TensorFlow (и сейчас еще есть). Его использовали одновременно для обучения и инференса. TensorFlow использует статический граф нейросети, логика итераций обучения написана на С++. Пользователю выдается Python API, что иногда приводит к изучению тонкости этих API и чтению некрасивых трейсов вместо работы над экспериментами с нейросетями.
В 2016 вышел фреймворк PyTorch, работающий по принципу “код и логика с вас, а мы даем движок расчета тензоров и автоградиент”. Так, на PyTorch начали переходить сначала исследователи, а потом и разработчики из индустрии.
Сложилась ситуация: в проде используется один фреймворк, но разработчики хотят работать на более эффективном и удобном для них PyTorch. Переписывать весь “боевой” код дорого и долго. Да и нет гарантий, что в будущем не появится фреймворк лучше.
Возникла потребность конвертировать представления нейросетей между фреймворками, при этом разрабатывать и поддерживать по конвертеру на каждую пару фреймворков - сложная и неэффективная задача. Так ONNX и удовлетворил этот запрос сначала для Microsoft, а потом и для open source.

ONNX конвертируется в обе стороны с большинством параметров
Основное - функции и операторы версионируются отдельно, а версия ONNX фиксируется в сериализуемой в protobuf модели.
Это даетпризрачную гарантию, что представление любой модели даже спустя время будет конвертироваться между ONNX и другими форматами. Иначе можно было бы сломаться при обновлении зависимостей в инфраструктуре.
Есть 2 способа конвертации:
Еще одна особенность: заявлено большое число поддерживаемых фреймворков. Однако сводится это к тому, что конвертеры могут быть разбросаны по github, а поддерживать их будут совсем другие люди и компании Тут есть ссылки на популярные конвертеры в ONNX. А конвертеры из ONNX в инференс фреймворки реализованы в рамках onnxruntime (см ниже).
Таким образом, варить в ONNX придется учиться, не стоит ожидать большой простоты. Но, в целом, это надо сделать один раз, т.к. фреймворки обучения и архитектуры моделей в продакшене обычно не меняются очень быстро.
Чтобы разрезать одну нейронку на несколько и строить пайплайны инфренса для эффективного масштабирования нагрузки. Например, такая утилита важна в случае с большими LLM, когда один батч инференса занимает десятки секунд на современных GPU.
Netron
Позволяет визуализировать и исследовать граф нейросети. Кроме анализа блоков для будущих экспериментов ее можно использовать в паре с GraphSurgeon, чтобы резать нейросети.
У себя в телеге разбирал пайплайнинг нейросетей, для которого ONNX приходится особенно кстати.
Кроме альтернативного варианта с использованием контейнера Docker можно сначала конвертировать модель в ONNX, а потом пользоваться интеграциями в фреймворки: execution providers в ONNX Runtime.
Как правило под каждого популярного производителя вычислителей есть собственный инфреренс фреймворк (как минимум, вычисление тензоров без расчета градиента).
Некоторые из серверных провайдеров:
*ex Facebook - признана экстремистской и запрещена в России
 habr.com
habr.com
В этой статье расскажу об ONNX и о том, почему этот формат данных широко используется. Посмотрим на особенности формата и конвертации в него и на экосистему полезных инструментов.
История ONNX
ONNX (Open Neural Network Exchange) - библиотека, реализующая хранение и обработку нейросетей, изначально называлась Toffe и разрабатывлась командой Pytorch (Meta*). В 2017 проект был переименован в ONNX, и с тех пор совместно поддерживается Microsoft, Meta* и другими большими компаниями.Изначально ONNX задумывался как открытый формат представления нейросети, который свяжет представление моделей в разных фреймворках.
В первом релизе речь шла о Caffe2, PyTorch и CNTK. Сейчас многие крупные фреймворки стараются его поддерживать (картинка с официального сайта):
Поддерживаемые фреймворки с официального сайта
Кроме того, спустя год появился onnxruntime - фреймворк для инференса в формате ONNX, который реализовал различные оптимизаторы поверх ONNX формата.
Важность общего формата
Общий формат хранения нейросети помогает сэкономить время, лишить привязки к конкретному фреймворку и дает возможность больше экспериментировать с инфраструктурой.
ONNX как связь между обучением и инференсом
Давайте разберем на примере одной из ситуаций, благодаря которой ONNX быстро набрал популярность.
Нейронные сети к 2016 массово учили несколько лет. Тогда в проде у многих был TensorFlow (и сейчас еще есть). Его использовали одновременно для обучения и инференса. TensorFlow использует статический граф нейросети, логика итераций обучения написана на С++. Пользователю выдается Python API, что иногда приводит к изучению тонкости этих API и чтению некрасивых трейсов вместо работы над экспериментами с нейросетями.
В 2016 вышел фреймворк PyTorch, работающий по принципу “код и логика с вас, а мы даем движок расчета тензоров и автоградиент”. Так, на PyTorch начали переходить сначала исследователи, а потом и разработчики из индустрии.
Сложилась ситуация: в проде используется один фреймворк, но разработчики хотят работать на более эффективном и удобном для них PyTorch. Переписывать весь “боевой” код дорого и долго. Да и нет гарантий, что в будущем не появится фреймворк лучше.
Возникла потребность конвертировать представления нейросетей между фреймворками, при этом разрабатывать и поддерживать по конвертеру на каждую пару фреймворков - сложная и неэффективная задача. Так ONNX и удовлетворил этот запрос сначала для Microsoft, а потом и для open source.
ONNX конвертируется в обе стороны с большинством параметров
Подробнее о ONNX
Внутри у ONNX есть свое промежуточное представление. Реализовано с помощью protocol buffers и служит промежуточным звеном для конвертаций между фреймворками. Все компоненты ONNX, включая промежуточное представление, версионируются возрастающим числом или согласно SemVer. Подробнее тут.Основное - функции и операторы версионируются отдельно, а версия ONNX фиксируется в сериализуемой в protobuf модели.
Это дает
Конвертации
Не все слои конвертируются в ONNX формат. Часть сконвертируется совсем не так, как вы бы могли захотеть, а часть после конвертации может начать некорректно вычислять значения.Есть 2 способа конвертации:
- Спецификация и реализация слоя написана явно. Соответственно для новых слоев поддержка появляется только спустя некоторое время,
- Через трейсинг операций над тензором. В таком случае вы либо фиксируете одну из размерностей (прощай нейронка, принимающая любой размер, например, изображений), либо, как минимум, придется немного пошаманить. А если трейсинг пройдет корректно, не факт, что реальные получившиеся вычисления в ONNX вам понравятся (даже после оптимизаций). У меня из красивого слоя иногда получались ужасные ONNX представления со странными связями (как посмотреть получившийся граф - ниже).
Еще одна особенность: заявлено большое число поддерживаемых фреймворков. Однако сводится это к тому, что конвертеры могут быть разбросаны по github, а поддерживать их будут совсем другие люди и компании Тут есть ссылки на популярные конвертеры в ONNX. А конвертеры из ONNX в инференс фреймворки реализованы в рамках onnxruntime (см ниже).
Таким образом, варить в ONNX придется учиться, не стоит ожидать большой простоты. Но, в целом, это надо сделать один раз, т.к. фреймворки обучения и архитектуры моделей в продакшене обычно не меняются очень быстро.
Экосистема
Благодаря ONNX появились универсальные инструменты, которыми можно пользоваться в не зависимости от исходного фреймворка.Утилиты
GraphSurgeonЧтобы разрезать одну нейронку на несколько и строить пайплайны инфренса для эффективного масштабирования нагрузки. Например, такая утилита важна в случае с большими LLM, когда один батч инференса занимает десятки секунд на современных GPU.
Netron
Позволяет визуализировать и исследовать граф нейросети. Кроме анализа блоков для будущих экспериментов ее можно использовать в паре с GraphSurgeon, чтобы резать нейросети.
У себя в телеге разбирал пайплайнинг нейросетей, для которого ONNX приходится особенно кстати.
Поддержка движками инференса
Очень облегчает жизнь. Несколько раз устанавливал из исходников TensorRT на сервер и пытался сконвертировать напрямую в них из PyTorch. При малейшем несовпадении версий - все разваливается и не компилируется. А потратить пол дня на конфликт зависимостей - не очень продуктивно и уж точно не приятно.Кроме альтернативного варианта с использованием контейнера Docker можно сначала конвертировать модель в ONNX, а потом пользоваться интеграциями в фреймворки: execution providers в ONNX Runtime.
Как правило под каждого популярного производителя вычислителей есть собственный инфреренс фреймворк (как минимум, вычисление тензоров без расчета градиента).
Некоторые из серверных провайдеров:
- onnxruntime (собственная реализация)
Оптимизированный движок инференса с открытым исходным кодом. Если все сломается, можете самостоятельнонайти багунаписать issue. Поддерживает большинство типов ускорителей и применений. Хороший бейзлайн для датацентрового инференса на CPU и уж точно один из самых универсальных Также может подойти, если закрытость других провайдеров не устраивает, - TensorRT
Оптимизирован для использования с GPU Nvidia. На текущий момент работает быстрее всего с ускорителями GPU Nvidia, - Openvino
Аналогично, только от Intel для их CPU, - ROCm для карт AMD,
- CANN для карт Huawei,
Подводя итоги
ONNX хорошо зарекомендовал себя как связующее звено в рамках MLOps процессов. Его использование в продакшен пайплайнах повышает гибкость разработки, не добавляя новых существенных проблем. Кроме того, ONNX предоставляет большую экосистему вспомогательных инструментов и конвертеров, позволяющих без особых усилий использовать передовые инференс фреймворки и меньше бояться, что при обновлении продакшена код превратиться в тыкву*ex Facebook - признана экстремистской и запрещена в России
Почему ONNX так популярен в ML: конвертации, утилиты и инференс
Большинство инженеров, работающих с машинным обучением, уже знакомы с форматом данных ONNX. Его часто используют для хранения обученных моделей и конвертации их мeжду фреймворками. В этой статье...
habr.com