Меня зовут Алексей Владышев, я являюсь создателем Zabbix, и в данный момент я отвечаю за его архитектуру и roadmap.
Это вводная лекция, сначала я расскажу, что такое Zabbix, потом – как работает Zabbix с точки зрения высокоуровневой архитектуры и с точки зрения обнаружения проблем. Мы будем говорить о том, как обнаруживать проблемы применительно к Zabbix, как можно использовать Zabbix, чтобы обнаруживать проблемы.

Что такое Zabbix? Если вы зайдете на нашу страницу, вы увидите, что Zabbix – это Enterprise level Open Source monitoring solution, т.е. это открытое решение уровня enterprise для мониторинга. Я понимаю слово «enterprise» таким образом, что решение должно легко интегрироваться в существующую инфраструктуру. Т.е. если у вас есть большое предприятие, вы уже используете какие-то продукты – Helpdesk, Configuration Management, еще что-то – система должна легко интегрироваться.
Что отличает Zabbix от других продуктов? Я думаю, что большое отличие и достаточно большое преимущество заключается в том, что Zabbix – открытый продукт, это реально open source, т.е. у нас нет никаких закрытых версий, мы 24/7 строим продукт и отдаем его бесплатно. Пожалуйста, заходите на нашу страницу и используйте наш продукт. Есть и другие преимущества. Я не в целях рекламы, а просто в образовательном смысле – чем мы отличаемся? Zabbix является решением «все в одном», т.е. визуализация, обнаружение проблем, сбор информации различными способами – все это есть в Zabbix, вам не нужно строить вашу систему мониторинга из разных отдельных блоков.

Как работает Zabbix? Для тех, кто еще не очень представляет, мы собираем данные. Zabbix-сервер – это ядро Zabbix, в котором вся логика. Мы собираем данные различными способами. Эти данные, информация складывается в базе данных, история, потом используется информация для визуализации, и ядро занимается в том числе и анализом потока информации. Мы обнаруживаем проблемы и каким-то образом реагируем на проблемы. Есть различные виды реакции на проблемы.
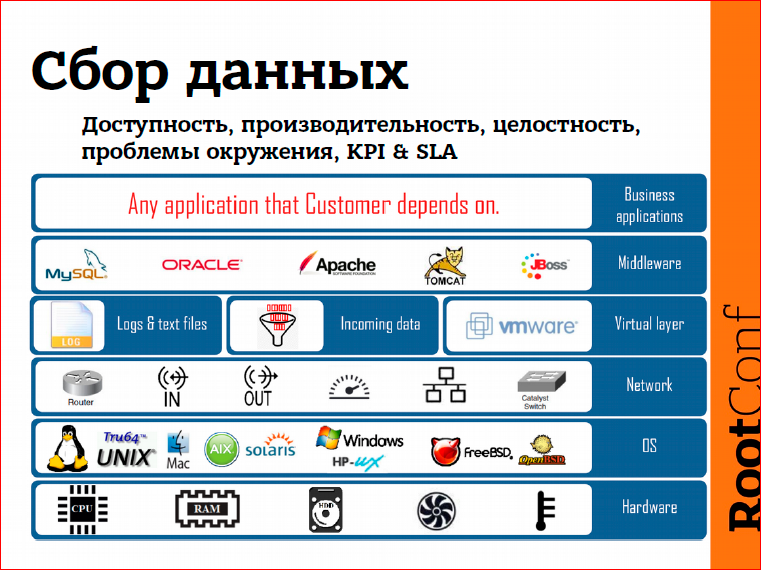
Что касается сбора данных, какие проблемы можем отлавливать? Это проблемы связанные с производительностью, с доступностью – доступен сервис или нет. Мы сразу же можем определить, насколько быстро работает система. Это проблемы с производительностью, с целостностью данных. Если у нас изменился какой-то конфигурационный файл или, может быть, image нашей системы, которую мы деплоим в cloude. Изменилась чек-сумма – Zabbix вам тут же скажет, что изменился наш файл.
Zabbix также немножко покрывает область бизнес-level мониторинга, т.е. фактически мы можем обнаруживать проблемы на различных уровнях нашей IT-инфраструктуры:

Каким образом можно собирать данные? Есть два способа: Pull – когда мы вытягиваем данные из устройства; и Push-метод – это когда само устройство сообщает нам, выдает нам информацию. Pull – это обычные проверки, допустим, SNMP, либо сервисные проверки, когда мы подключаемся к сервису, скажем, SSH, и если веб-страница корректно отвечает, значит все в порядке. Push – это в основном активный агент, различного вида Traps и SNMP Traps. Сбор данных работает через Push-метод.
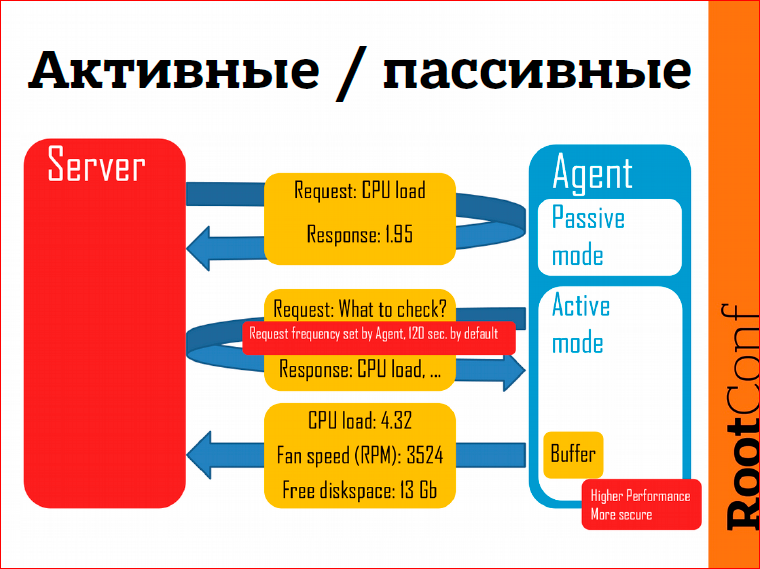
Что касается Zabbix агента. Агент – это такая программа, которую можно установить на Linux, Windows или другие операционные системы. Я хотел поговорить об активном режиме. Какие у него преимущества в плане обнаружения проблем? Если пассивный режим – это мы подключаемся к агенту, запрашиваем информацию, агент возвращает нам, скажем, загрузку процессора, то в активном режиме сам агент отправляет данные на сервер мониторинга. Здесь такие преимущества:

Вообще, стоит вопрос: как часто опрашивать устройство, как часто собирать данные?
Конечно, хотелось бы опрашивать данные раз в секунду, любые устройства опрашивать раз в секунду, собирать какие-то Гбайты информации. Как только проблема возникает, тут же, через секунду, мы понимаем, что у нас есть проблема. Но тут есть такой принцип: мы не должны навредить системе. Как в квантовой физике – наблюдатель влияет на процесс. Если мы зачем-то наблюдаем, мы уже влияем на процесс. То же самое с системой мониторинга. Если мы начинаем собирать слишком много информации слишком часто, мы системой мониторинга влияем на ту систему, которую мы мониторим. Поэтому здесь нужно выбирать золотую середину – с одной стороны не навредить, с другой стороны мы должны обнаружить проблему как можно быстрее.
В Zabbix есть несколько вариантов. Во-первых, мы можем мониторить какое-то устройство или метрику раз в n секунд или раз в минуту мы запускаем какую-то проверку. Есть возможность использовать различную частоту в зависимости от интервала времени. Предположим, нам не важно, что система не работает в нерабочее время, нам важно, чтобы система работала в рабочее время. Тогда мы говорим Zabbix: «Проверяй, пожалуйста, рабочие станции с 9:00 до 18:00» и все. Есть такая возможность.
В Zabbix 3.0 появится новая возможность проверки типа «готово к работе», «ready for business». Это означает, что мы сможем сказать Zabbix: «Сделай эти проверки в конкретное время». Допустим, открывается филиал банка в 9 часов утра, а в 8:55 у нас есть некий чек-лист, и мы проверяем, что филиал действительно готов к работе, что с workstation’ами все в порядке, что сервисы, от которых мы зависим, в порядке, что удачно закрылся предыдущий и открылся новый финансовый день и т.д. Т.е. начиная с Zabbix 3.0 можно запускать проверки в определенное время. Если мы скажем Zabbix: «Проверь, пожалуйста, этот сервис в 8:55», Zabbix проверит сервис в 8:55. Также будет возможность совершать эти проверки с периодичностью, например, в 9:00, в 10:00, в 11:00 – ровно в это время, как мы указали.

Как в потоке информации отлавливать проблемы? Идет огромный поток информации, Zabbix совершает в секунду тысячи, десятки тысяч различных проверок производительности, доступности, и мы предлагаем решение – триггеры. Если вы используете Zabbix, вы знаете, что такое триггеры. Это, по сути, описание проблемы, т.е. мы формулируем проблему. Сначала, может быть на своем языке, а потом мы это пытаемся перевести в формат триггерных выражений.
Простое триггерное выражение, например, загрузка процессора на сервере больше 5:

Это простейший триггер. Триггеры могут быть намного более сложные, мы можем использовать арифметически-логические операции. Здесь очень важно то, что мы не ограничены одной метрикой: мы анализируем не только одну метрику, мы можем анализировать практически все, т.е. брать данные с различных устройств, использовать их в описании проблемы. Также Zabbix’у для анализа доступна как real-time информация, которую мы только-только получили, так и информация, которая у нас есть в базе данных, т.н. историческая информация.

С чего обычно начинают новички, неофиты от мониторинга? Попадает им в руки Zabbix, такой мощный инструмент для того, чтобы обнаруживать проблемы, и сразу хочется узнать все обо всем. Хочется, как только что-то где-то произошло, сразу получить e-mail либо SMS. К чему это приводит? Приводит к тому, что, казалось бы, вроде бы все в порядке, вот система перегружена, создается триггер «текущая загрузка процессора больше 5», для доступности создаются триггеры, типа «сервис http недоступен», т.е. последняя проверка сказала, что веб-сервер недоступен, и мы считаем, что у нас есть проблема. Почему так делать не очень хорошо?

Такие триггеры, такие описания проблем слишком чувствительны. Загрузка процессора превысила 5, и мы считаем, что система перегружена, подключаемся через SSH, запускаем TOP, а загрузка процессора уже 4.5. Или Zabbix нам сказал, что веб-сервер не работает, на самом деле мы подключились, а он работает. Так что же происходит?
Такие вещи, эта чувствительность приводит к привыканию. Система мониторинга генерирует слишком много сообщений, и мы перестаем на них реагировать, потому что это не совсем реальные проблемы.
Просто приведу пример. В Латвии какое-то время назад был такой случай – в супермаркете сработала сигнализация, и люди, как обычно, на это не среагировали. Персонал, который должен вывести всех людей из супермаркета, подумал,: «А, сигнализация сработала, ничего страшного». Те люди, которые находились в супермаркете, подумали: «Ну, ладно, я завершу покупки и выйду». На самом деле это был предвестник того, что обрушилось все перекрытие, и погибло очень много людей.
Почему это произошло? Потому что люди привыкли, что вот сработала сигнализация, посмотрели вокруг, пожара нет. Ну, продолжаем работу или продолжаем веселиться… Но вот это привыкание – это очень-очень страшная вещь. Все-таки, если система мониторинга говорит о том, что у нас есть проблема, должна быть эта проблема, не должна система мониторинга быть уж слишком чувствительной.
Что же делать? Здесь важно правильно формулировать проблему и понимать суть. Нужно задаться вопросом: какую действительно проблему мы пытаемся описать. Что значит «система перегружена» или что означает «сервис недоступен»?

Система перегружена, скажем, загрузка процессора больше 5 (я сегодня сознательно применяю очень простые примеры, т.е. примеры могут быть более сложными, но это такой простой пример). Система перегружена – это не то, что вот сейчас у нас загрузка процессора = 5, а все-таки система должна быть нагружена в течение какого-то периода времени. И здесь мы можем анализировать историю. Т.е. скажем, последние 10 минут загрузка процессора была больше 5, тогда да, действительно система перегружена, может быть, какой-нибудь процесс завис, или еще что-то произошло.
В случае доступности сервиса что мы можем сделать? То же самое – посмотреть в историю: «А как было до этого?». Если последние 5 минут система нам отвечала, что http недоступен, то, наверное, http недоступен.
Тут еще важно понимать суть проверки. Как мы проверяем, что веб-сервер доступен? Проверяем мы следующим образом: мы делаем TCP-соединение, get-запрос, потом отсчитываем результат, и здесь что-то может пойти не так. Например, произошел timeout. Да, timeout произошел, но означает ли это, что веб-сервер не работает? Нет, не обязательно. Но если три раза у нас произошел timeout, как здесь, (#3) – это означает, что три последние проверки ответили, что сервер недоступен, тогда уже очень высока вероятность, что наш веб-сервер действительно недоступен, либо проблемы с сетью, например.
Поэтому мы все-таки должны смотреть на историю, т.е. основывать свое решение на последнем значении – это не совсем правильно в большинстве случаев.

О чем мне еще бы хотелось поговорить? Решение проблемы – не эквивалентно ее отсутствию. Что это означает?
Например, не хватает нам свободного места на диске (опять же, беру очень простые примеры). Как можно это сформулировать? Скажем, свободного места на диске осталось менее 10%. Вопрос в том: как только у нас появится 11% свободного места на диске, эта проблема решилась или не решилась? Мне кажется, что проблема все-таки не совсем решилась. Или у нас там 10% плюс 1 байт.
Так вот, в Zabbix есть механизм, который позволяет описывать различные условия для проблемной ситуации и для выхода из проблемной ситуации.

Свободного места на диске, скажем, меньше 10%, но я хочу выйти из этой проблемной ситуации только в том случае, когда у меня будет свободного места на диске 30%, не 10%, а 30%. Только в этом случае я на 100% уверен, что кто-то что-то сделал, что кто-то удалил какие-то файлы, системный администратор подключился, расширил нашу файловую систему, увеличил ее размер, в этом случае проблемы больше нет.
Для этого мы используем гистерезис. Гистерезис, по сути, означает следующее. Предположим, что мы смотрим на фотографию машины. Машина будто бы стоит, но мы не знаем ее состояния – она может стоять, может двигаться вперед, назад… Не зная историю, что до этого происходило, мы не можем сказать, в каком состоянии находится машина сейчас. Т.е. мы должны все-таки посмотреть немножечко на историю, что до этого произошло. И используя различные условия для входа в состояние проблемы и выхода из состояния проблемы, мы избавляемся от т.н. флаппинга.
Что такое флаппинг? Флаппинг – это когда используются очень простые описания проблем. Напрмер, загрузка процессора больше 5, или свободного места на диске меньше 10. Что произойдет, если у нас то 10%, то 8%, то 11%, то 7%? Это флаппинг. Проблема возникает, пропадает, возникает, пропадает. Мы приходим утром, открываем свой inbox и видим массу сообщений от Zabbix о том, что проблема была, проблема исчезла, была, исчезла, была, исчезла… К чему это приводит? К тому, что мы уже системе мониторинга не доверяем. Вот это флаппинг. И если мы используем различные условия для входа в проблему и выхода из проблемы, то мы избавляемся полностью от флаппинга.
Несколько примеров:

Система перегружена, загрузка процессора за последние 5 минут превышала тройку, но мы выходим из проблемы только тогда, когда последние 2 минуты загрузка процессора была меньше единицы. Здесь используется немножко другая логика, здесь первое условие – это вход в проблему, второе условие – мы остаемся в состоянии проблемы, пока есть хотя бы одно значение больше единицы.
Нет свободного места на диске. Мой пример – меньше 10%. Проблема, потому что это действительно проблема, мы тут на 100% уверены. И выходим из состояния проблемы, когда в течение последних 10-ти минут у нас было более 30% свободного места на диске. Потому что системный администратор может начать, скажем, двигать какие-то большие файлы с одной файловой системы в другую, копировать что-то. Если в течение 10-ти минут у нас есть стабильная ситуация, что свободного места на диске более 30%, мы считаем, что проблема пропала.
То же самое, SSH сервер не доступен. Три последние проверки сказали нам, что сервер недоступен, мы считаем, что сервер недоступен. Но восстановиться мы хотим только тогда, когда 10 последних проверок сказали нам, что сервер наконец-то доступен. Что происходит в реальности? У нас проблемы с сервисом, начинают его чинить, перезапускать, может быть, откатываться на какие-то старые версии, то система работает, то не работает. И вот здесь мы, как раз, описываем этот период доступности. 10 последних проверок все в порядке, вот сейчас мы точно можем пойти спать, потому что мы знаем, что сервисом все хорошо.

Аномалии. Вообще, что такое аномалии? Аномалия – это греческое слово, означающее отклонение от нормы, т.е. есть некая норма, и как только мы отклоняемся от нормы, это считается аномалией.

Как можно обнаружить аномалию? В Zabbix есть такая функциональность, когда мы за норму берем состояние системы в прошлом и сравниваем с тем, что есть в данный момент. Допустим, если средняя загрузка процессора за последний час превышает вдвое загрузку процессора за тот же период ровно неделю назад… Ни вчера, потому что если мы сравниваем со вчерашним днем, это можем быть сравнение воскресения с понедельником, пятницы с субботой – не совсем корректно. Скажем, если сегодня четверг, то мы сравниваем с тем, что было в прошлый четверг. Считаем, что это норма – то, что было в прошлый четверг. Если сегодня мы видим, что нагрузка процессора увеличилась, то Zabbix может отправить сообщение администраторам и сказать: «Эй, ребята, посмотрите, пожалуйста, какие-то у нас есть тут проблемы». Возможно, проблемы, не обязательно, конечно. Потому что это информативное сообщение. Может быть, сделали апгрейд какой-либо системы, появились регрессии в плане производительности, может быть еще что-то… Это важно.
Хорошая функциональность, я предлагаю каким-то образом начать ее использовать. Трудно сказать, принесет ли она какую-то реальную практическую пользу, но, по крайней мере, это та вещь, которая очень часто отображает предвестники более важных проблем, более серьезных проблем. Обратите на это внимание.

И зависимости. Казалось бы, вроде бы, избавились от флаппинга, от всех таких вещей, но мы все равно знаем, что у нас есть проблемы, которые зависят друг от друга.
Простейший пример на уровне сети – это когда у нас есть устройство за коммутатором. С коммутатором проблемы, система мониторинга думает, что все наши устройства отвалились, мы получаем массу SMS сообщений. Определить, что действительно произошло, что является первопричиной всех этих проблем, мы не можем.
В Zabbix мы просто определяем зависимости одной проблемы от другой. Скажем, CRM система зависит от базы данных, зависит от сети, зависит от какого-то middleware, еще чего-то. Сама база данных зависит от места на диске. В случае, если у нас нет места на диске, мы получим единственное сообщение о том, что у нас нет места на диске.
Как реагировать на проблемы?

Реакция может быть разной. Наверное, то, что надо использовать, может быть, не всегда, но часто это хорошая идея, все-таки автоматическое решение проблемы. Иногда это возможно.
Иногда мы знаем, что у нас есть приложение, которое поедает память. Поедает память и все, решения у нас нет, и это приложение просто надо время от времени перезапускать. Иногда возникает ситуация с тем, что мы получили какой-то kernel panic. Вот, время от времени получаем kernel panic, нам нужно перезапускать этот сервер. Это все можно поручить системе мониторинга. Т.е. в случае kernel panic по IPMI мы можем автоматически на уровне железа делать reset. В случае с сервисами мы можем перезапускать наши сервисы также в автоматическом режиме.
Реакция может быть просто сообщение пользователю или группе пользователей. Также реакцией может быть открытие каких-то тикетов в Helpdesk системе. Т.е. реагировать можно абсолютно по-разному, и конечно, способ реакции зависит от того, насколько серьезная проблема. Если проблема не очень серьезная, не стоит тут же отправлять SMS сообщение в 4 часа ночи, если эту проблему все равно будут решать в 10 часов утра на следующий день.

Еще есть возможность эскалировать проблемы. Т.е. возникла проблема, и дальше мы задаемся вопросом: что с этим делать, кого оповещать? Конечно, мы отправляем сообщение администраторам, администраторы что-то делают, но, я думаю, что очень эффективный вариант, это когда проблема эскалируется на уровень бюрократического дерева, на более высокий уровень, менеджеру, может быть, еще менеджеру, может быть, дальше – CEO. И CEO не будет получать сообщения вида «отвалился какой-то там диск volume, что-то там еще», CEO получит от Zabbix просто сообщение вида «последние полчаса мы теряем деньги». И все, и тогда все понятно.
Можно реагировать сразу – возникла проблема, мы тут же что-то делаем. Можно реагировать с задержкой, т.е. возникла проблема, ну, давайте подождем еще, может быть, 5 минут, и через 5 минут мы отправим сообщение. И тут еще важно следующее. Оповещение, если автоматика не сработала. Предположим, у нас есть сервис, он не работает, мы сконфигурировали Zabbix, чтобы этот сервер автоматически перезапускался. Как мы настраиваем эскалацию в этом случае? Настраиваем следующим образом: сначала мы перезапускаем сервис, и через 10 минут, если проблема все еще существует, отправляем оповещение пользователям. Либо идет дальше эскалация на более высокие уровни.
И повторные оповещения – это тоже очень важно, особенно для серьезных проблем. Какие-то вещи можно легко пропустить, можно пропустить SMS, можно пропустить e-mail сообщение, но для важных проблем надо все-таки использовать повторные сообщения. Это тоже очень хороший стимул, мы видим, что да, проблема существует, и нам надо работать, чтобы решить ее как можно раньше.

И, может быть, такой итог. Что тут важно?
» alex@zabbix.com
» twitter
» Zabbix
Источник статьи: https://habr.com/ru/company/oleg-bunin/blog/320678/
Это вводная лекция, сначала я расскажу, что такое Zabbix, потом – как работает Zabbix с точки зрения высокоуровневой архитектуры и с точки зрения обнаружения проблем. Мы будем говорить о том, как обнаруживать проблемы применительно к Zabbix, как можно использовать Zabbix, чтобы обнаруживать проблемы.
Что такое Zabbix? Если вы зайдете на нашу страницу, вы увидите, что Zabbix – это Enterprise level Open Source monitoring solution, т.е. это открытое решение уровня enterprise для мониторинга. Я понимаю слово «enterprise» таким образом, что решение должно легко интегрироваться в существующую инфраструктуру. Т.е. если у вас есть большое предприятие, вы уже используете какие-то продукты – Helpdesk, Configuration Management, еще что-то – система должна легко интегрироваться.
Что отличает Zabbix от других продуктов? Я думаю, что большое отличие и достаточно большое преимущество заключается в том, что Zabbix – открытый продукт, это реально open source, т.е. у нас нет никаких закрытых версий, мы 24/7 строим продукт и отдаем его бесплатно. Пожалуйста, заходите на нашу страницу и используйте наш продукт. Есть и другие преимущества. Я не в целях рекламы, а просто в образовательном смысле – чем мы отличаемся? Zabbix является решением «все в одном», т.е. визуализация, обнаружение проблем, сбор информации различными способами – все это есть в Zabbix, вам не нужно строить вашу систему мониторинга из разных отдельных блоков.
Как работает Zabbix? Для тех, кто еще не очень представляет, мы собираем данные. Zabbix-сервер – это ядро Zabbix, в котором вся логика. Мы собираем данные различными способами. Эти данные, информация складывается в базе данных, история, потом используется информация для визуализации, и ядро занимается в том числе и анализом потока информации. Мы обнаруживаем проблемы и каким-то образом реагируем на проблемы. Есть различные виды реакции на проблемы.
Что касается сбора данных, какие проблемы можем отлавливать? Это проблемы связанные с производительностью, с доступностью – доступен сервис или нет. Мы сразу же можем определить, насколько быстро работает система. Это проблемы с производительностью, с целостностью данных. Если у нас изменился какой-то конфигурационный файл или, может быть, image нашей системы, которую мы деплоим в cloude. Изменилась чек-сумма – Zabbix вам тут же скажет, что изменился наш файл.
Zabbix также немножко покрывает область бизнес-level мониторинга, т.е. фактически мы можем обнаруживать проблемы на различных уровнях нашей IT-инфраструктуры:
- это уровень железа – что-то произошло с какой-то железякой, мы тут же об этом узнаем,
- уровень операционной системы,
- сеть, в основном это мониторинг через SNMP,
- виртуальный уровень, т.е. «из коробки» мы предлагаем, например, мониторинг WMware инфраструктуры, vCenter и vSphere,
- дальше идет middleware,
- бизнес-приложения.
Каким образом можно собирать данные? Есть два способа: Pull – когда мы вытягиваем данные из устройства; и Push-метод – это когда само устройство сообщает нам, выдает нам информацию. Pull – это обычные проверки, допустим, SNMP, либо сервисные проверки, когда мы подключаемся к сервису, скажем, SSH, и если веб-страница корректно отвечает, значит все в порядке. Push – это в основном активный агент, различного вида Traps и SNMP Traps. Сбор данных работает через Push-метод.
Что касается Zabbix агента. Агент – это такая программа, которую можно установить на Linux, Windows или другие операционные системы. Я хотел поговорить об активном режиме. Какие у него преимущества в плане обнаружения проблем? Если пассивный режим – это мы подключаемся к агенту, запрашиваем информацию, агент возвращает нам, скажем, загрузку процессора, то в активном режиме сам агент отправляет данные на сервер мониторинга. Здесь такие преимущества:
- это работает быстро, по крайней мере, быстрее, т.к. сервер не должен заниматься постоянным опрашиванием устройств, сами устройства отправляют информацию,
- более безопасно с точки зрения агента, потому что агент не должен слушать никакие TCP-соединения или сетевые соединения.
- небольшое преимущество, то, что нам сегодня важно – в активном режиме есть буферизация. Если Zabbix-сервер недоступен по каким-то причинам, допустим, мы делаем апгрейд Zabbix-сервера, у нас downtime несколько минут, то данные будут накапливаться на стороне агента. Как только мы сервер запускаем, данные тут же отправятся на сторону сервера, и мы их сможем обрабатывать.
Вообще, стоит вопрос: как часто опрашивать устройство, как часто собирать данные?
Конечно, хотелось бы опрашивать данные раз в секунду, любые устройства опрашивать раз в секунду, собирать какие-то Гбайты информации. Как только проблема возникает, тут же, через секунду, мы понимаем, что у нас есть проблема. Но тут есть такой принцип: мы не должны навредить системе. Как в квантовой физике – наблюдатель влияет на процесс. Если мы зачем-то наблюдаем, мы уже влияем на процесс. То же самое с системой мониторинга. Если мы начинаем собирать слишком много информации слишком часто, мы системой мониторинга влияем на ту систему, которую мы мониторим. Поэтому здесь нужно выбирать золотую середину – с одной стороны не навредить, с другой стороны мы должны обнаружить проблему как можно быстрее.
В Zabbix есть несколько вариантов. Во-первых, мы можем мониторить какое-то устройство или метрику раз в n секунд или раз в минуту мы запускаем какую-то проверку. Есть возможность использовать различную частоту в зависимости от интервала времени. Предположим, нам не важно, что система не работает в нерабочее время, нам важно, чтобы система работала в рабочее время. Тогда мы говорим Zabbix: «Проверяй, пожалуйста, рабочие станции с 9:00 до 18:00» и все. Есть такая возможность.
В Zabbix 3.0 появится новая возможность проверки типа «готово к работе», «ready for business». Это означает, что мы сможем сказать Zabbix: «Сделай эти проверки в конкретное время». Допустим, открывается филиал банка в 9 часов утра, а в 8:55 у нас есть некий чек-лист, и мы проверяем, что филиал действительно готов к работе, что с workstation’ами все в порядке, что сервисы, от которых мы зависим, в порядке, что удачно закрылся предыдущий и открылся новый финансовый день и т.д. Т.е. начиная с Zabbix 3.0 можно запускать проверки в определенное время. Если мы скажем Zabbix: «Проверь, пожалуйста, этот сервис в 8:55», Zabbix проверит сервис в 8:55. Также будет возможность совершать эти проверки с периодичностью, например, в 9:00, в 10:00, в 11:00 – ровно в это время, как мы указали.
Как в потоке информации отлавливать проблемы? Идет огромный поток информации, Zabbix совершает в секунду тысячи, десятки тысяч различных проверок производительности, доступности, и мы предлагаем решение – триггеры. Если вы используете Zabbix, вы знаете, что такое триггеры. Это, по сути, описание проблемы, т.е. мы формулируем проблему. Сначала, может быть на своем языке, а потом мы это пытаемся перевести в формат триггерных выражений.
Простое триггерное выражение, например, загрузка процессора на сервере больше 5:
Это простейший триггер. Триггеры могут быть намного более сложные, мы можем использовать арифметически-логические операции. Здесь очень важно то, что мы не ограничены одной метрикой: мы анализируем не только одну метрику, мы можем анализировать практически все, т.е. брать данные с различных устройств, использовать их в описании проблемы. Также Zabbix’у для анализа доступна как real-time информация, которую мы только-только получили, так и информация, которая у нас есть в базе данных, т.н. историческая информация.
С чего обычно начинают новички, неофиты от мониторинга? Попадает им в руки Zabbix, такой мощный инструмент для того, чтобы обнаруживать проблемы, и сразу хочется узнать все обо всем. Хочется, как только что-то где-то произошло, сразу получить e-mail либо SMS. К чему это приводит? Приводит к тому, что, казалось бы, вроде бы все в порядке, вот система перегружена, создается триггер «текущая загрузка процессора больше 5», для доступности создаются триггеры, типа «сервис http недоступен», т.е. последняя проверка сказала, что веб-сервер недоступен, и мы считаем, что у нас есть проблема. Почему так делать не очень хорошо?
Такие триггеры, такие описания проблем слишком чувствительны. Загрузка процессора превысила 5, и мы считаем, что система перегружена, подключаемся через SSH, запускаем TOP, а загрузка процессора уже 4.5. Или Zabbix нам сказал, что веб-сервер не работает, на самом деле мы подключились, а он работает. Так что же происходит?
Такие вещи, эта чувствительность приводит к привыканию. Система мониторинга генерирует слишком много сообщений, и мы перестаем на них реагировать, потому что это не совсем реальные проблемы.
Просто приведу пример. В Латвии какое-то время назад был такой случай – в супермаркете сработала сигнализация, и люди, как обычно, на это не среагировали. Персонал, который должен вывести всех людей из супермаркета, подумал,: «А, сигнализация сработала, ничего страшного». Те люди, которые находились в супермаркете, подумали: «Ну, ладно, я завершу покупки и выйду». На самом деле это был предвестник того, что обрушилось все перекрытие, и погибло очень много людей.
Почему это произошло? Потому что люди привыкли, что вот сработала сигнализация, посмотрели вокруг, пожара нет. Ну, продолжаем работу или продолжаем веселиться… Но вот это привыкание – это очень-очень страшная вещь. Все-таки, если система мониторинга говорит о том, что у нас есть проблема, должна быть эта проблема, не должна система мониторинга быть уж слишком чувствительной.
Что же делать? Здесь важно правильно формулировать проблему и понимать суть. Нужно задаться вопросом: какую действительно проблему мы пытаемся описать. Что значит «система перегружена» или что означает «сервис недоступен»?
Система перегружена, скажем, загрузка процессора больше 5 (я сегодня сознательно применяю очень простые примеры, т.е. примеры могут быть более сложными, но это такой простой пример). Система перегружена – это не то, что вот сейчас у нас загрузка процессора = 5, а все-таки система должна быть нагружена в течение какого-то периода времени. И здесь мы можем анализировать историю. Т.е. скажем, последние 10 минут загрузка процессора была больше 5, тогда да, действительно система перегружена, может быть, какой-нибудь процесс завис, или еще что-то произошло.
В случае доступности сервиса что мы можем сделать? То же самое – посмотреть в историю: «А как было до этого?». Если последние 5 минут система нам отвечала, что http недоступен, то, наверное, http недоступен.
Тут еще важно понимать суть проверки. Как мы проверяем, что веб-сервер доступен? Проверяем мы следующим образом: мы делаем TCP-соединение, get-запрос, потом отсчитываем результат, и здесь что-то может пойти не так. Например, произошел timeout. Да, timeout произошел, но означает ли это, что веб-сервер не работает? Нет, не обязательно. Но если три раза у нас произошел timeout, как здесь, (#3) – это означает, что три последние проверки ответили, что сервер недоступен, тогда уже очень высока вероятность, что наш веб-сервер действительно недоступен, либо проблемы с сетью, например.
Поэтому мы все-таки должны смотреть на историю, т.е. основывать свое решение на последнем значении – это не совсем правильно в большинстве случаев.
О чем мне еще бы хотелось поговорить? Решение проблемы – не эквивалентно ее отсутствию. Что это означает?
Например, не хватает нам свободного места на диске (опять же, беру очень простые примеры). Как можно это сформулировать? Скажем, свободного места на диске осталось менее 10%. Вопрос в том: как только у нас появится 11% свободного места на диске, эта проблема решилась или не решилась? Мне кажется, что проблема все-таки не совсем решилась. Или у нас там 10% плюс 1 байт.
Так вот, в Zabbix есть механизм, который позволяет описывать различные условия для проблемной ситуации и для выхода из проблемной ситуации.
Свободного места на диске, скажем, меньше 10%, но я хочу выйти из этой проблемной ситуации только в том случае, когда у меня будет свободного места на диске 30%, не 10%, а 30%. Только в этом случае я на 100% уверен, что кто-то что-то сделал, что кто-то удалил какие-то файлы, системный администратор подключился, расширил нашу файловую систему, увеличил ее размер, в этом случае проблемы больше нет.
Для этого мы используем гистерезис. Гистерезис, по сути, означает следующее. Предположим, что мы смотрим на фотографию машины. Машина будто бы стоит, но мы не знаем ее состояния – она может стоять, может двигаться вперед, назад… Не зная историю, что до этого происходило, мы не можем сказать, в каком состоянии находится машина сейчас. Т.е. мы должны все-таки посмотреть немножечко на историю, что до этого произошло. И используя различные условия для входа в состояние проблемы и выхода из состояния проблемы, мы избавляемся от т.н. флаппинга.
Что такое флаппинг? Флаппинг – это когда используются очень простые описания проблем. Напрмер, загрузка процессора больше 5, или свободного места на диске меньше 10. Что произойдет, если у нас то 10%, то 8%, то 11%, то 7%? Это флаппинг. Проблема возникает, пропадает, возникает, пропадает. Мы приходим утром, открываем свой inbox и видим массу сообщений от Zabbix о том, что проблема была, проблема исчезла, была, исчезла, была, исчезла… К чему это приводит? К тому, что мы уже системе мониторинга не доверяем. Вот это флаппинг. И если мы используем различные условия для входа в проблему и выхода из проблемы, то мы избавляемся полностью от флаппинга.
Несколько примеров:
Система перегружена, загрузка процессора за последние 5 минут превышала тройку, но мы выходим из проблемы только тогда, когда последние 2 минуты загрузка процессора была меньше единицы. Здесь используется немножко другая логика, здесь первое условие – это вход в проблему, второе условие – мы остаемся в состоянии проблемы, пока есть хотя бы одно значение больше единицы.
Нет свободного места на диске. Мой пример – меньше 10%. Проблема, потому что это действительно проблема, мы тут на 100% уверены. И выходим из состояния проблемы, когда в течение последних 10-ти минут у нас было более 30% свободного места на диске. Потому что системный администратор может начать, скажем, двигать какие-то большие файлы с одной файловой системы в другую, копировать что-то. Если в течение 10-ти минут у нас есть стабильная ситуация, что свободного места на диске более 30%, мы считаем, что проблема пропала.
То же самое, SSH сервер не доступен. Три последние проверки сказали нам, что сервер недоступен, мы считаем, что сервер недоступен. Но восстановиться мы хотим только тогда, когда 10 последних проверок сказали нам, что сервер наконец-то доступен. Что происходит в реальности? У нас проблемы с сервисом, начинают его чинить, перезапускать, может быть, откатываться на какие-то старые версии, то система работает, то не работает. И вот здесь мы, как раз, описываем этот период доступности. 10 последних проверок все в порядке, вот сейчас мы точно можем пойти спать, потому что мы знаем, что сервисом все хорошо.
Аномалии. Вообще, что такое аномалии? Аномалия – это греческое слово, означающее отклонение от нормы, т.е. есть некая норма, и как только мы отклоняемся от нормы, это считается аномалией.
Как можно обнаружить аномалию? В Zabbix есть такая функциональность, когда мы за норму берем состояние системы в прошлом и сравниваем с тем, что есть в данный момент. Допустим, если средняя загрузка процессора за последний час превышает вдвое загрузку процессора за тот же период ровно неделю назад… Ни вчера, потому что если мы сравниваем со вчерашним днем, это можем быть сравнение воскресения с понедельником, пятницы с субботой – не совсем корректно. Скажем, если сегодня четверг, то мы сравниваем с тем, что было в прошлый четверг. Считаем, что это норма – то, что было в прошлый четверг. Если сегодня мы видим, что нагрузка процессора увеличилась, то Zabbix может отправить сообщение администраторам и сказать: «Эй, ребята, посмотрите, пожалуйста, какие-то у нас есть тут проблемы». Возможно, проблемы, не обязательно, конечно. Потому что это информативное сообщение. Может быть, сделали апгрейд какой-либо системы, появились регрессии в плане производительности, может быть еще что-то… Это важно.
Хорошая функциональность, я предлагаю каким-то образом начать ее использовать. Трудно сказать, принесет ли она какую-то реальную практическую пользу, но, по крайней мере, это та вещь, которая очень часто отображает предвестники более важных проблем, более серьезных проблем. Обратите на это внимание.
И зависимости. Казалось бы, вроде бы, избавились от флаппинга, от всех таких вещей, но мы все равно знаем, что у нас есть проблемы, которые зависят друг от друга.
Простейший пример на уровне сети – это когда у нас есть устройство за коммутатором. С коммутатором проблемы, система мониторинга думает, что все наши устройства отвалились, мы получаем массу SMS сообщений. Определить, что действительно произошло, что является первопричиной всех этих проблем, мы не можем.
В Zabbix мы просто определяем зависимости одной проблемы от другой. Скажем, CRM система зависит от базы данных, зависит от сети, зависит от какого-то middleware, еще чего-то. Сама база данных зависит от места на диске. В случае, если у нас нет места на диске, мы получим единственное сообщение о том, что у нас нет места на диске.
Как реагировать на проблемы?
Реакция может быть разной. Наверное, то, что надо использовать, может быть, не всегда, но часто это хорошая идея, все-таки автоматическое решение проблемы. Иногда это возможно.
Иногда мы знаем, что у нас есть приложение, которое поедает память. Поедает память и все, решения у нас нет, и это приложение просто надо время от времени перезапускать. Иногда возникает ситуация с тем, что мы получили какой-то kernel panic. Вот, время от времени получаем kernel panic, нам нужно перезапускать этот сервер. Это все можно поручить системе мониторинга. Т.е. в случае kernel panic по IPMI мы можем автоматически на уровне железа делать reset. В случае с сервисами мы можем перезапускать наши сервисы также в автоматическом режиме.
Реакция может быть просто сообщение пользователю или группе пользователей. Также реакцией может быть открытие каких-то тикетов в Helpdesk системе. Т.е. реагировать можно абсолютно по-разному, и конечно, способ реакции зависит от того, насколько серьезная проблема. Если проблема не очень серьезная, не стоит тут же отправлять SMS сообщение в 4 часа ночи, если эту проблему все равно будут решать в 10 часов утра на следующий день.
Еще есть возможность эскалировать проблемы. Т.е. возникла проблема, и дальше мы задаемся вопросом: что с этим делать, кого оповещать? Конечно, мы отправляем сообщение администраторам, администраторы что-то делают, но, я думаю, что очень эффективный вариант, это когда проблема эскалируется на уровень бюрократического дерева, на более высокий уровень, менеджеру, может быть, еще менеджеру, может быть, дальше – CEO. И CEO не будет получать сообщения вида «отвалился какой-то там диск volume, что-то там еще», CEO получит от Zabbix просто сообщение вида «последние полчаса мы теряем деньги». И все, и тогда все понятно.
Можно реагировать сразу – возникла проблема, мы тут же что-то делаем. Можно реагировать с задержкой, т.е. возникла проблема, ну, давайте подождем еще, может быть, 5 минут, и через 5 минут мы отправим сообщение. И тут еще важно следующее. Оповещение, если автоматика не сработала. Предположим, у нас есть сервис, он не работает, мы сконфигурировали Zabbix, чтобы этот сервер автоматически перезапускался. Как мы настраиваем эскалацию в этом случае? Настраиваем следующим образом: сначала мы перезапускаем сервис, и через 10 минут, если проблема все еще существует, отправляем оповещение пользователям. Либо идет дальше эскалация на более высокие уровни.
И повторные оповещения – это тоже очень важно, особенно для серьезных проблем. Какие-то вещи можно легко пропустить, можно пропустить SMS, можно пропустить e-mail сообщение, но для важных проблем надо все-таки использовать повторные сообщения. Это тоже очень хороший стимул, мы видим, что да, проблема существует, и нам надо работать, чтобы решить ее как можно раньше.
И, может быть, такой итог. Что тут важно?
- История. Мы основываем свое решение не только на real-time мониторинге, на оперативной информации, которую мы только-только получили, но и смотрим в историю. В историю нужно обязательно смотреть. Это важно.
- Отсутствие проблемы – не есть ее решение. Я привел несколько примеров, но на самом деле, вы многие используете Zabbix, посмотрите критическим взглядом на те триггеры, которые у вас сейчас есть. Комбинация анализа истории с гистерезисом, с разными условиями для проблемы и для выхода из проблемы – она на самом деле творит чудеса. Получается такое очень-очень умное обнаружение проблем. Нужно обязательно использовать эту функциональность.
- С аномалиями, опять же, мне трудно сказать, принесет ли это какую-то практическую пользу, но, по крайней мере, стоит попробовать. Что касается аномалии, в Zabbix 3.0, возможно, мы реализуем baseline monitoring. Что это означает? Baseline – это некая норма, т.е. этот baseline будет высчитываться из трендов. Если сейчас все триггеры работают с историей, то для baseline мониторинга мы будем брать информацию из трендов, из тенденций, и будет возможность, например, сравнивать поведение системы в рабочее время на прошлой неделе с поведением системы на этой неделе или сегодня. Т.е. мы что-то будем брать за основу, за нормальную ситуацию и сравнивать с тем, что есть сейчас. Это такой статистический анализ, основанный на тенденциях, на трендах.
- Автоматическое решение проблем. Наверное, у каждого из вас, если вы используете систему мониторинга, есть такой класс проблем, про который вы знаете, что эта проблема произойдет рано или поздно, и с этим ничего нельзя сделать. Я привел примеры каких-то случайных падений операционной системы – мы знаем, что такая проблема есть, она может произойти в любое время, соответственно, автоматическое решение проблем – это хорошее решение.
- И эскалируем проблемы. Отличный стимул для администраторов, если мы делаем эскалирование. Эскалирование не означает, что вот есть администратор, начальник, начальник начальника, начальник начальника начальника… Эскалирование – это означает, что мы сможем среагировать на проблему сразу одним способом, дальше попытаться, может быть, автоматически решить ее другим способом, и дальше, может быть, через 5 минут, если проблема все еще существует, попытаться решить ее следующим способом. Сначала мы перезапускаем сервис, проблема все еще существует, скажем, exchange не завелся с первого раза, что мы тогда можем сделать? Мы можем перезапустить сервер на физическом уровне и тогда уже смотреть, что произойдет.
Контакты
» alexvl» alex@zabbix.com
» Zabbix
Этот доклад — расшифровка одного из лучших выступлений на профессиональной конференции по эксплуатации и devops RootConf.
На сайте RootConf вы можете подписаться на рассылку про эксплуатацию и devops, где мы публикуем расшифрованные статьи, а также новости подготовки.
Ну и главная новость — мы начали подготовку весеннего фестиваля "Российские интернет-технологии", в который входит восемь конференций, включая RootConf.
Такие доклады, как этот, мы не очень любим — фактически, это ликбез про конкретную технологию. Такой доклад имеет шанс пройти только, если технологию/инструмент представляет сам разработчик инструмента — тогда это может получиться глубокое интересное выступление. И желающие могут задать свои вопросы создателю технологии напрямую.
Источник статьи: https://habr.com/ru/company/oleg-bunin/blog/320678/