С реляционными базами данных я знаком очень давно, с конца 90-х. Мои первые шаги в мире компьютеров и программирования связанны именно с ними. Реляционным БД было отведено особое место в моей образовательной программе и стажировке на инженера-программиста. Они преследовали меня на протяжении всей моей карьеры. Я буквально провалился на самое дно кроличьей норы реляционных систем управления базами данных (РСУБД) – и до сих пор люблю их.
За годы работы я испробовал практически все РСУБД, а их попадалось мне немало: MySQL, Postgres, Oracle, Microsoft SQL Server, DBase, Access, SQLite, DB2, MariaDB, AWS RDS, Azure SQL, Google Cloud SQL. Нельзя любить РСУБД, если не любишь SQL, а это отдельная вселенная. И не все SQL одинаковы. Есть MySQL со своим собственным жаргоном, есть T-SQL от Microsoft и всемирно известный PL/SQL от Oracle. Наверное, не стоит упоминать, что все они несовместимы друг с другом.

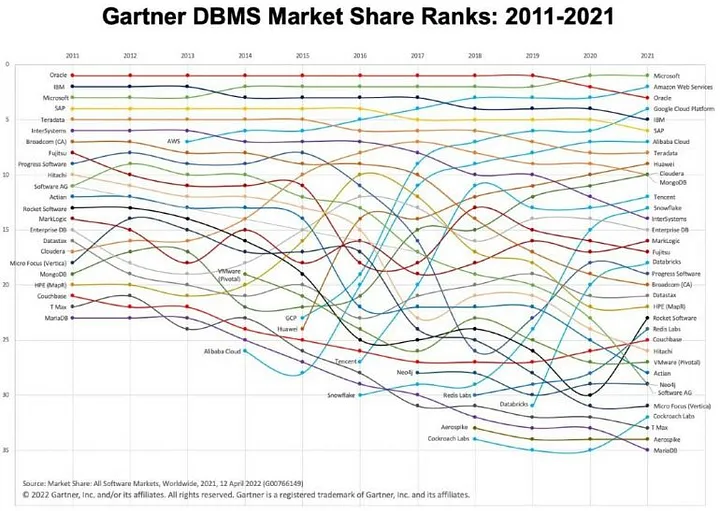
Считается, что первые РСУБД появились еще в начале 1970-х гг., когда был изобретен «структурированный английский язык запросов» (SEQUEL, позже сокращенный до SQL). В 1979 г. Oracle выпустила свою первую базу данных, а за три года до этого, в 1976 г., компания Honeywell представила Multics Relational Data Store. Считается, что это была первая в мире реляционная база данных. Не за горами 50-летие РСУБД как явления. Неудивительно, что они стали основой современного общества и экономики. Буквально каждый человек, если только он не живет в лесу, засветился хотя бы в одной базе данных.
Данные социального страхования, паспорт, полицейские записи, свидетельства о рождении – все это прекрасно хранится в массивных государственных реляционных базах данных, скорее всего, от Microsoft, IBM, SAP или Oracle. Хотите в отпуск? Билеты, брони – все находится в реляционных базах данных. Любая информация, переданная любой большой компании, вероятнее всего окажется в реляционной базе данных.
На примере этих баз данных видно, что основная масса разработчиков программного обеспечения не являются хорошими спецами по БД. Чаще всего это происходит из-за некомпетентности, вызванной тем, что на свете не так много качественных обучающих ресурсов по грамотной реализации реляционных баз данных. Большинство университетов, школ, книг и курсов сосредоточены на SQL, нормализации и транзакциях.
Эти кастомные базы данных содержат десятки связанных таблиц, невидимых для внешнего мира. Бесконечное количество триггеров, функций, процедур и представлений должны не просто организовывать хранение данных, но и осуществлять все бизнес-процессы компании. Приложения на прикладном уровне обеспечивают интерфейс для работы обычного пользователя с базой данных.

Microsoft Access 1.1
Поскольку специалисты по базам данных из 80-х ушли на пенсию еще несколько десятилетий назад, большинство из созданных ими на заказ систем так и живут, управляемые SQL-приложениями, которые в массе своей уже не поддерживаются. Для многих крупных организаций эти приложения превратились в эдакие «черные ящики». Совершенно не понятно, что они делают и как именно работают, не говоря уже о том, как их следует обслуживать. Тем не менее предприятия чрезвычайно зависят от этих приложений. Реверс-инжиниринг и тотальная переделка архитектуры – единственный выход из этой ситуации. Проекты по переносу легаси-БД часто обходятся в нелепо большие суммы, исчисляемые несколькими миллионами долларов.
Представьте себе страховую компанию, которая не понимает, как на их мэйнфрейме рассчитывается степень риска по договорам. Они даже не в курсе, какой будет страховая премия по конкретному страховому случаю. От осознания количества организаций, которые не имеют ни малейшего представления о том, как программное обеспечение управляет их бизнесом, становится и смешно, и страшно одновременно. Особенно дико, когда ты и есть клиент, чьи данные хранятся в подобном «черном ящике».
В чем проблема? Сами принципы построения РСУБД подталкивают к централизации данных внутри этой базы. База данных растет вместе с бизнесом, но вместе с тем увеличивается объем «мусорных» данных. В конце концов бизнес будет экономически неспособен отойти от реляционной базы данных.
Можно бесконечно цитировать сообщения СМИ о том, как реляционные базы данных разрушили бизнес или сломали привычный ход вещей. Велика новость!
Вот несколько примеров.

Настоятельно рекомендую ознакомиться с работами Рика Хулихана, его презентациями о базах данных и размышлениями о будущем этой технологи. Обязательно стоит поискать видео с ним на YouTube: Rick Houlihan on YouTube. Ниже я приведу фрагмент интервью, которое он дал журналу Software Engineering Daily.

Дата-центр 1980-х. Хранение данных было дорогим удовольствием. Очень дорогим
Поисковой системе не нужно выдавать каждому пользователю свежайшие результаты. Плюс, нужна индивидуальная выдача с учетом истории, интересов и т.п. Следовательно, требования ACID здесь совершенно не актуальны. Никто в здравом уме не станет использовать РСУБД для крупного интернет-поисковика или социальной сети.
Подход с использованием специально созданных систем управления данными работает только если придерживаться микросервисной архитектуры и избегать создания «микросервисных монолитов». Часто можно встретить микросервисную архитектуру, работающую в паре с монолитными базами данных, что делает микросервисный подход совершенно бесполезным.
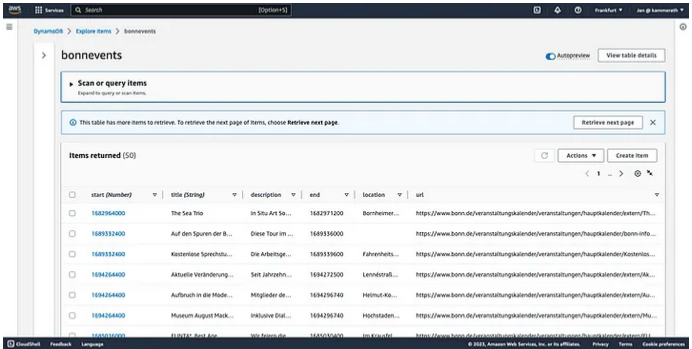
Если работа с данными требует выполнения сложных запросов, например, поисковых или аналитических, всегда можно перейти на специализированную поисковую или аналитическую систему, передав данные из своего хранилища в другую систему. Если вообще не нужны запросы и требуется просто хранить данные, то оптимальным вариантом будет использование объектно-ориентированной БД, например, AWS S3, Azure Blob Storage или Google Cloud Storage.
Документно-ориентированные базы данных, такие как MongoDB или AWS DocumentDB, пытаются стать альтернативой реляционным базам данных, хотя зачастую они работают по тем же принципам. Несмотря на переход от таблиц к документам, можно столкнуться с теми же самыми проблемами.
Если ничего из этого не подходит под ваши требования, значит, нужно создать свое специализированное программное обеспечение. Учитывая скорость разработки, доступную с такими языками, как Go, это уже не выглядит так страшно. Безусловно, стоит подумать о последствиях своего выбора.
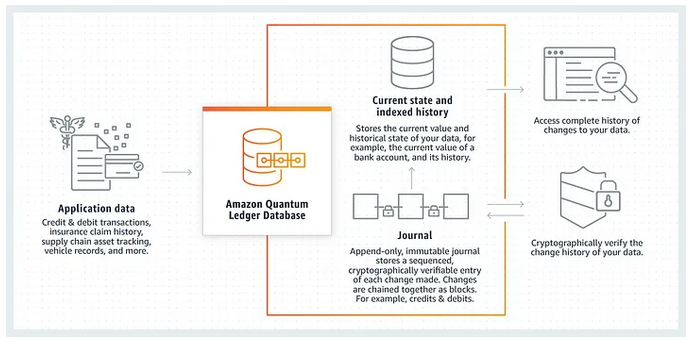
Я сам развернул Amazon QLDB в продакшн и уже не хочу возвращаться к реляционным базам данных. Преимущества криптографически проверяемого хранилища для транзакций позволяют добиться гораздо большей проверяемости. Для обработки финансовых транзакций QLDB, на мой взгляд, – оптимальный вариант. Однако все зависит от сценария использования, быть может вам вообще не нужна никакая криптографическая проверка.
 с его хранимыми процедурами, функциями, триггерами и представлениями. Проектирование реляционных баз данных в MySQL Workbench доставляет мне огромное удовольствие. Новейшие возможности MySQL 8 – это что-то потрясающее. В реляционных базах данных можно сделать очень многое – и все это в едином пространстве. Честно говоря, я иногда скучаю по временам, когда можно было просто написать все свое бизнес-приложение в MySQL, Oracle или SQL Server. Но я должен быть честен с самим собой: это было приемлемо в 80-е, но не теперь. Мы живем в 2023-ем, вычислительные системы и системы хранения данных изменились, как и дата-центры и приложения.
с его хранимыми процедурами, функциями, триггерами и представлениями. Проектирование реляционных баз данных в MySQL Workbench доставляет мне огромное удовольствие. Новейшие возможности MySQL 8 – это что-то потрясающее. В реляционных базах данных можно сделать очень многое – и все это в едином пространстве. Честно говоря, я иногда скучаю по временам, когда можно было просто написать все свое бизнес-приложение в MySQL, Oracle или SQL Server. Но я должен быть честен с самим собой: это было приемлемо в 80-е, но не теперь. Мы живем в 2023-ем, вычислительные системы и системы хранения данных изменились, как и дата-центры и приложения.

Вместе с появлением огромного разнообразия в области СУБД, хранилищ, технологий поиска и языков программирования прошли те времена, когда ты десятилетиями носился с одной и той же базой данных. Больше не будет бесконечных споров о том, что выбрать: MySQL, MSSQL, Oracle или Postgres. Сегодня вопрос о базах данных и хранилищах решается индивидуально. И вот уже я сам пишу небольшие пользовательские стратегии хранения данных, основанные на объектных хранилищах или хранилищах «ключ-значение».
Сегодня, прежде чем внедрить программу или систему, я думаю о том, какие данные будут храниться и как к ним будет осуществляться доступ. Затем я трачу многие часы на поиск правильного подхода к хранению данных. И если честно, реляционные БД я выбираю редко. Слишком уж часто я видел, к чему приводит долгосрочное использование централизованных реляционных баз данных.

 habr.com
habr.com
За годы работы я испробовал практически все РСУБД, а их попадалось мне немало: MySQL, Postgres, Oracle, Microsoft SQL Server, DBase, Access, SQLite, DB2, MariaDB, AWS RDS, Azure SQL, Google Cloud SQL. Нельзя любить РСУБД, если не любишь SQL, а это отдельная вселенная. И не все SQL одинаковы. Есть MySQL со своим собственным жаргоном, есть T-SQL от Microsoft и всемирно известный PL/SQL от Oracle. Наверное, не стоит упоминать, что все они несовместимы друг с другом.
Реляционные базы данных: они повсюду
Поверьте, они поистине вездесущи: финансы, транспорт, гостиничный бизнес, соцсети, стриминговые сервисы и т.д. Какую сферу ни возьми, обязательно наткнешься на реляционную базу данных. Кажется, весь мир только на них и работает, наполняя карманы в первую очередь Oracle, IBM и Microsoft. Если вам нужно что-то большое, прямо-таки огромное, вы обратитесь именно к ним. Разве что в финансовом секторе ваши специфические запросы могут привести вас к SAP. И так было во все времена.
Считается, что первые РСУБД появились еще в начале 1970-х гг., когда был изобретен «структурированный английский язык запросов» (SEQUEL, позже сокращенный до SQL). В 1979 г. Oracle выпустила свою первую базу данных, а за три года до этого, в 1976 г., компания Honeywell представила Multics Relational Data Store. Считается, что это была первая в мире реляционная база данных. Не за горами 50-летие РСУБД как явления. Неудивительно, что они стали основой современного общества и экономики. Буквально каждый человек, если только он не живет в лесу, засветился хотя бы в одной базе данных.
Данные социального страхования, паспорт, полицейские записи, свидетельства о рождении – все это прекрасно хранится в массивных государственных реляционных базах данных, скорее всего, от Microsoft, IBM, SAP или Oracle. Хотите в отпуск? Билеты, брони – все находится в реляционных базах данных. Любая информация, переданная любой большой компании, вероятнее всего окажется в реляционной базе данных.
Большинство реализаций БД просты
Самые популярные СУБД в мире — это MySQL для PHP-приложений и Microsoft Access для VBA. Как правило, речь идет о скромных приложениях, которые используют БД для хранения своих данных. Для многих из них РСУБД – непомерное излишество. Но популярность реляционных баз данных заставила разработчиков их использовать. Университеты, школы, курсы программирования – везде изучают SQL и РСУБД. И большинство разработчиков имеют склонность использовать реляционные базы данных.На примере этих баз данных видно, что основная масса разработчиков программного обеспечения не являются хорошими спецами по БД. Чаще всего это происходит из-за некомпетентности, вызванной тем, что на свете не так много качественных обучающих ресурсов по грамотной реализации реляционных баз данных. Большинство университетов, школ, книг и курсов сосредоточены на SQL, нормализации и транзакциях.
Среднестатистический разработчик будет шокирован этим заявлением. А для опытных инженеров баз данных считается нормой прятать всю структуру БД за представлениями и хранимыми процедурами.«Приложение вообще не должно знать, что у него есть таблицы» – опытный администратор БД, ушедший на пенсию в 2012 г. и пожелавший остаться неизвестным.
Монструозные базы данных стали незаменимы
В 1980-х гг. уже все организации перешли на реляционные базы данных. Под «всеми» я действительно имею в виду «всех». Возможно, если достаточно долго искать, найдется какая-нибудь правительственная компания, которая их не использует. Но там, скорее всего, и не будет современных компьютеров. Часто такие организации используют базы данных, созданные на заказ. Десятилетиями они крутятся на мэйнфреймах, наращивая объем данных и требуя дорогой поддержки со стороны производителей или поставщиков.Эти кастомные базы данных содержат десятки связанных таблиц, невидимых для внешнего мира. Бесконечное количество триггеров, функций, процедур и представлений должны не просто организовывать хранение данных, но и осуществлять все бизнес-процессы компании. Приложения на прикладном уровне обеспечивают интерфейс для работы обычного пользователя с базой данных.
Microsoft Access 1.1
Поскольку специалисты по базам данных из 80-х ушли на пенсию еще несколько десятилетий назад, большинство из созданных ими на заказ систем так и живут, управляемые SQL-приложениями, которые в массе своей уже не поддерживаются. Для многих крупных организаций эти приложения превратились в эдакие «черные ящики». Совершенно не понятно, что они делают и как именно работают, не говоря уже о том, как их следует обслуживать. Тем не менее предприятия чрезвычайно зависят от этих приложений. Реверс-инжиниринг и тотальная переделка архитектуры – единственный выход из этой ситуации. Проекты по переносу легаси-БД часто обходятся в нелепо большие суммы, исчисляемые несколькими миллионами долларов.
Представьте себе страховую компанию, которая не понимает, как на их мэйнфрейме рассчитывается степень риска по договорам. Они даже не в курсе, какой будет страховая премия по конкретному страховому случаю. От осознания количества организаций, которые не имеют ни малейшего представления о том, как программное обеспечение управляет их бизнесом, становится и смешно, и страшно одновременно. Особенно дико, когда ты и есть клиент, чьи данные хранятся в подобном «черном ящике».
В чем проблема реляционных баз данных?
Я лично сталкивался с компаниями, где каждый запрос на изменение, затрагивающее централизованную реляционную базу данных, становился задачей всего ИТ-отдела не на пару дней, а на долгие месяцы. Крайними при этом выставлялись или Oracle, или DB2. Централизованная база данных превратилась в единую точку отказа. Маркетинговые акции останавливались, когда база данных вдруг переставала работать, а успешное добавление столбца в таблицу требовало вознесения регулярных молитв. О производительности запросов вообще лучше промолчать.В чем проблема? Сами принципы построения РСУБД подталкивают к централизации данных внутри этой базы. База данных растет вместе с бизнесом, но вместе с тем увеличивается объем «мусорных» данных. В конце концов бизнес будет экономически неспособен отойти от реляционной базы данных.
Можно бесконечно цитировать сообщения СМИ о том, как реляционные базы данных разрушили бизнес или сломали привычный ход вещей. Велика новость!
Вот несколько примеров.
- «Внезапный сбой в работе системы бронирования авиабилетов», 2000 г. (Airline Reservation System Crashes Briefly);
- «Почему компьютерные системы авиакомпаний так часто выходят из строя?», 2016 г. (Why airlines' computer systems crashs so often);
- «Постыдный секрет: что стоит за масштабным сбоем в компьютерной системе Southwest Airlines?», 2022г. (The Shameful Open Secret Behind Southwest's Failure).
- «TSB Bank оштрафовали почти на 50 млн. фунтов стерлингов после неудачной модернизации компьютера», 2018 г. (TSB Bank fined nearly £50m after botched computer upgrade).
- «6 лет, 60 млн. евро – 0 результата. Как биржа труда осталась без программного обеспечения», 2017 г. (Six years, 60 million euros – but no software for the employment agency).
Реляционные базы данных из прошлого
РСУБД были изобретены в ту эпоху, когда компьютеры выглядели совсем иначе. Сферы их использования были совершенно другими, а объем данных, с которым приходилось иметь дело этим системам, сегодня уместится в любом смартфоне.Настоятельно рекомендую ознакомиться с работами Рика Хулихана, его презентациями о базах данных и размышлениями о будущем этой технологи. Обязательно стоит поискать видео с ним на YouTube: Rick Houlihan on YouTube. Ниже я приведу фрагмент интервью, которое он дал журналу Software Engineering Daily.
Во многих случаях, таких как стриминг, игры, соцсети, поиск в Интернете и др., нужны не согласованность и атомарность, а скорость и производительность.Джефф Мейерсон (основатель Software Engineering Daily):
Существует несколько объяснений того, почему NoSQL обрел популярность в самый расцвет SQL. Мы рассматривали некоторые из этих теорий в наших выпусках. Расскажи нам свою версию истории популярности NoSQL.
Рик Хулихан (MongoDB, бывший сотрудник AWS):
С удовольствием. На самом деле все сводится к тому, что, когда люди начали обрабатывать большие объемы данных, оказалось, что реляционные базы данных, которыми они пользовались столько лет, не так хорошо масштабируются. Это перекликается с тем, почему были изобретены реляционные базы данных: объем данных рос, стоимость обработки данных от него не отставала и мешала развиваться. РСУБД уменьшали давление на системы хранения, потому что нормализация позволяла дедуплицировать данные и таким образом освободить, так сказать, хранилище – а это было действительно самым дорогим ресурсом в дата центрах еще 3-4 года назад.
Но время летит, и теперь мы платим сущие копейки за гигабайты хранилища и время работы процессора. Теперь процессор – не просто фиксированный актив, которому простительно работать вхолостую. Это ценный ресурс, который мы можем использовать для других задач. Так что объединение данных и выполнение сложных запросов – это не то, на что мы хотели бы тратить свои деньги.
Дата-центр 1980-х. Хранение данных было дорогим удовольствием. Очень дорогим
Поисковой системе не нужно выдавать каждому пользователю свежайшие результаты. Плюс, нужна индивидуальная выдача с учетом истории, интересов и т.п. Следовательно, требования ACID здесь совершенно не актуальны. Никто в здравом уме не станет использовать РСУБД для крупного интернет-поисковика или социальной сети.
Каково решение? Специализированные системы
Очевидно, что некая база данных общего назначения, «для всех», вряд ли станет успешной. Попытка использовать РСУБД для транзакций, поиска, аналитики, скорее всего, никогда не даст оптимального результата. Тут уже и ежу станет понятно, что необходимы специализированные решения. Это могут быть даже базы данных, и даже реляционные, но помимо них требуются и особые системы узкого назначения.Подход с использованием специально созданных систем управления данными работает только если придерживаться микросервисной архитектуры и избегать создания «микросервисных монолитов». Часто можно встретить микросервисную архитектуру, работающую в паре с монолитными базами данных, что делает микросервисный подход совершенно бесполезным.
Базы данных: объектно- и документно-ориентированные, «ключ-значение»
В первую очередь для хранения данных следует выбирать из основных вариантов key-value, таких как приложения Apache Cassandra, AWS DynamoDB, Google Cloud Spanner или Azure Cosmos DB. Они легко масштабируются, долговечны, просты и подходят для всех базовых сценариев использования, где нужно просто разместить данные и получить к ним доступ с помощью нескольких ключей.
Если работа с данными требует выполнения сложных запросов, например, поисковых или аналитических, всегда можно перейти на специализированную поисковую или аналитическую систему, передав данные из своего хранилища в другую систему. Если вообще не нужны запросы и требуется просто хранить данные, то оптимальным вариантом будет использование объектно-ориентированной БД, например, AWS S3, Azure Blob Storage или Google Cloud Storage.
Документно-ориентированные базы данных, такие как MongoDB или AWS DocumentDB, пытаются стать альтернативой реляционным базам данных, хотя зачастую они работают по тем же принципам. Несмотря на переход от таблиц к документам, можно столкнуться с теми же самыми проблемами.
Специализированные или кастомные поисковые системы
Распространенным вариантом использования реляционных баз данных является поиск. Правда, для этого варианта использования реляционные базы данных далеко не идеальны. Поисковый функционал в большинстве случаев вообще не требует соблюдения требований ACID. Специально построенные поисковые системы, такие как Lucene, Solr, OpenSearch или ElasticSearch, обеспечивают значительно большую производительность и дешевле в эксплуатации. Кому-то могут подойти и уже существующие предложения от облачных провайдеров, например, Google Cloud Search.Если ничего из этого не подходит под ваши требования, значит, нужно создать свое специализированное программное обеспечение. Учитывая скорость разработки, доступную с такими языками, как Go, это уже не выглядит так страшно. Безусловно, стоит подумать о последствиях своего выбора.
Транзакционные базы данных или блокчейн
Обработка транзакций – вотчина реляционных баз данных. Но сейчас их потеснили системы баз данных на основе блокчейна, например, Amazon QLDB.
Я сам развернул Amazon QLDB в продакшн и уже не хочу возвращаться к реляционным базам данных. Преимущества криптографически проверяемого хранилища для транзакций позволяют добиться гораздо большей проверяемости. Для обработки финансовых транзакций QLDB, на мой взгляд, – оптимальный вариант. Однако все зависит от сценария использования, быть может вам вообще не нужна никакая криптографическая проверка.
Бросая вызов статус-кво
Мне нравится писать на SQL с его хранимыми процедурами, функциями, триггерами и представлениями. Проектирование реляционных баз данных в MySQL Workbench доставляет мне огромное удовольствие. Новейшие возможности MySQL 8 – это что-то потрясающее. В реляционных базах данных можно сделать очень многое – и все это в едином пространстве. Честно говоря, я иногда скучаю по временам, когда можно было просто написать все свое бизнес-приложение в MySQL, Oracle или SQL Server. Но я должен быть честен с самим собой: это было приемлемо в 80-е, но не теперь. Мы живем в 2023-ем, вычислительные системы и системы хранения данных изменились, как и дата-центры и приложения.
Вместе с появлением огромного разнообразия в области СУБД, хранилищ, технологий поиска и языков программирования прошли те времена, когда ты десятилетиями носился с одной и той же базой данных. Больше не будет бесконечных споров о том, что выбрать: MySQL, MSSQL, Oracle или Postgres. Сегодня вопрос о базах данных и хранилищах решается индивидуально. И вот уже я сам пишу небольшие пользовательские стратегии хранения данных, основанные на объектных хранилищах или хранилищах «ключ-значение».
Сегодня, прежде чем внедрить программу или систему, я думаю о том, какие данные будут храниться и как к ним будет осуществляться доступ. Затем я трачу многие часы на поиск правильного подхода к хранению данных. И если честно, реляционные БД я выбираю редко. Слишком уж часто я видел, к чему приводит долгосрочное использование централизованных реляционных баз данных.
Реляционные системы управления базами данных становятся проблемой. Что с этим делать?
С реляционными базами данных я знаком очень давно, с конца 90-х. Мои первые шаги в мире компьютеров и программирования связанны именно с ними. Реляционным БД было отведено особое место в моей...
habr.com