На протяжении более чем 10 лет работы с PostgreSQL, периодически наблюдаю, как команды на начальном этапе, зачастую, не уделяют внимание ролевой модели базы, или как вся команда работает под суперпользователем postgres и забывает про версионирование схемы.
В процессе общения с различными командами в НЛМК у меня появилась идея предложить им «преднастроенный PostgreSQL». Как в итоге сделали — под катом.

Сахар для слоненка
Поэтому мы попробовали собрать требования к ролевой модели:
Шаблон имен наших ролей имеет вид:
${prefix}${db_name}_${schema_name}_${role_name}
Возможно, вам придется расширить права для ролей или как-то адаптировать их под себя.
Если мы просто добавим пользователя в эту роль, то он сможет создавать объекты во всех схемах и есть риск, что может забыть сделать set role.
Чтобы решить эту проблему, мы сделали отдельную роль _sudo со свойством NOINHERIT, которая является членом роли owner, и пользователь вынужден всегда делать set role явно, чтобы получить нужные права.
В git для проекта мы создаем следующую структуру:
<db_name>/
<schema_name>/
migrations.yml
<migrations>
<callbacks>/
<afterEach>/
00_after_each.sql
<beforeEach>/
00_before_each.sql
...
Для генерации структуры можно воспользоваться скриптом из того же репозитория в github.
В файле migrations.yml мы указываем запросы, которые будут выполнены до и после каждой версии миграции.
migrations.yml
00_before_each.sql, делаем SET ROLE на владельца схемы и устанавливаем search_path в имя схемы.
00_before_each.sql
В 00_after_each.sql, сбрасываем роль и search_path.
00_after_each.sql
Пример такой структуры можно посмотреть в директории migrations на github.
О PGmigrate....
Пример запуска примера из репозитория с github
pgmigrate.py -d <db_name>/<schema_name> -v -m <schema_name> --check_serial_versions -t latest migrate
На каждую роль *_view, *_write и *_sudo создается своя группа в AD. Периодически скриптом мы синхронизируем членов этой группы с соответствующими группами в PostgreSQL, создаем отсутствующих пользователей. Наш скрипт умеет работать со вложенными группами, и это позволяет в качестве членов групп использовать другие группы в AD, например группа «все разработчики BI».
Полезно также иметь общую группу в AD на каждый сервер, включающую все эти группы, чтобы в pg_hba.conf или в PGAdmin дополнительно ограничить доступ с помощью ldapsearchfilter:
Пример из pg_hba.conf:
Его архитектура представлена ниже:
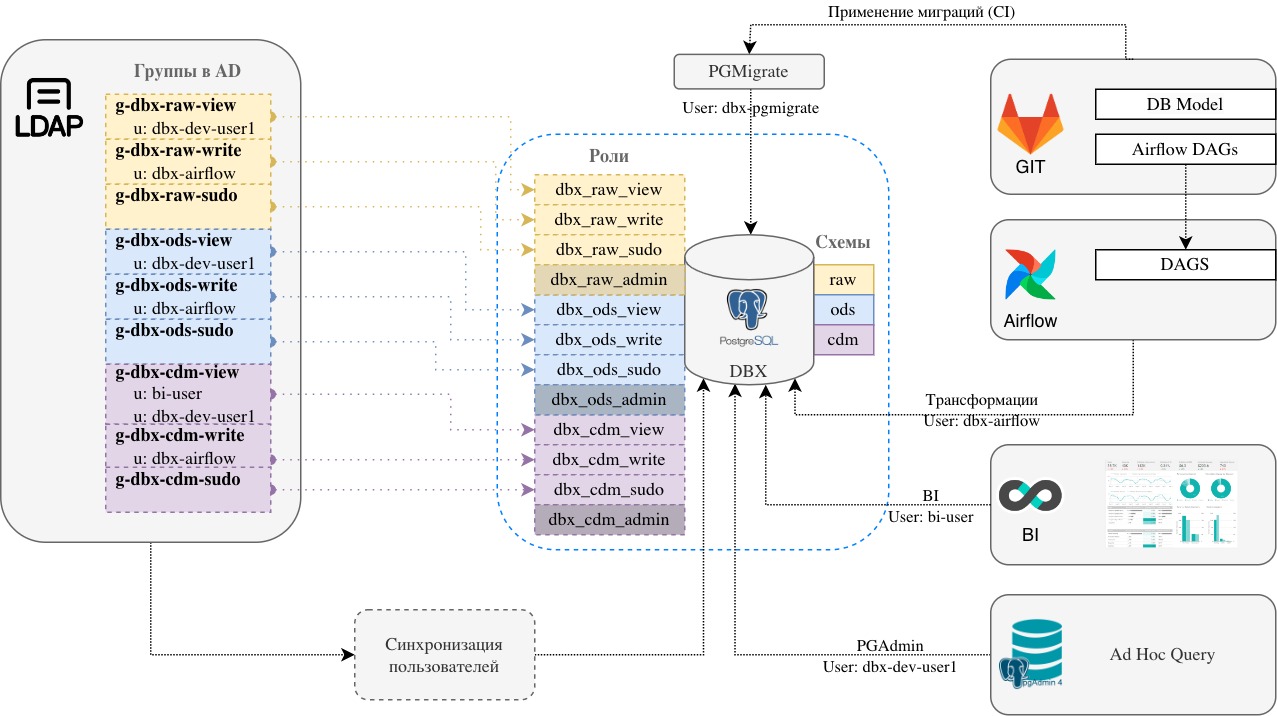
В базе данных созданы три схемы (слоя): raw, ods, cdm. На каждую схему в PostgreSQL созданы 4 роли(+1 для миграций — pgm).
В LDAP на каждую схему создано три группы, соответствующие *_view, *_write и *_sudo.
Код миграций лежит в GIT. Миграции выполняются под доменным пользователем dbx‑pgmigrate, который входит в локальные группы dbx_raw_pgm, dbx_ods_pgm, dbx_cdm_pgm в PostgreSQL.
Перекладка данных между схемами/слоями осуществляется сервисом Airflow, который подключается к БД под пользователем dbx‑airflow и имеет только write права на схемы.
Также на схеме присутствует BI сервис, который подключается к PostgreSQL под пользователем bi‑user и имеет права только на чтение в схему CDM. И сервис PGAdmin, через который пользователь dbx‑dev‑user1 может подключаться к PostgreSQL и выполнять запросы на чтение во всех трех схемах.
Надеюсь, предложенный подход вам будет полезен!

 habr.com
habr.com
В процессе общения с различными командами в НЛМК у меня появилась идея предложить им «преднастроенный PostgreSQL». Как в итоге сделали — под катом.
Сахар для слоненка
Ролевая модель
Основная задача заключалась в том, чтобы составители миграций, наши пользователи, не выдавали права на объекты в миграциях, а использовали простой и понятный подход вне их зоны контроля.Поэтому мы попробовали собрать требования к ролевой модели:
- единицей владения выступает схема и объекты внутри нее;
- у каждой схемы свой владелец — роль (пользователь), под которой создаются и меняются объекты в схеме;
- отдельная роль (группа) с правами на запись в объекты схемы (таблицы, sequence), но не имеющая права менять схему;
- отдельная роль (группа) на чтение.
Шаблон имен наших ролей имеет вид:
${prefix}${db_name}_${schema_name}_${role_name}
- prefix — префикс для ролей (опционально);
- db_name — имя базы данных;
- schema_name — имя схемы, для которой создана роль;
- role_name — имя роли.
- owner — владелец схемы. Роль типа NOLOGON. Эта роль непосредственно никому не присваивается, а передается через sudo роль (ниже будет пример);
- sudo — роль типа NOLOGON и NOINHERIT (роль не наследует права ролей, членом которых она является), ей присвоена роль owner. Переключение на роль owner выполняется через SET ROLE;
- view — роль типа NOLOGON, через которую предоставляется доступ только на чтение к сущностям в схеме;
- write — роль типа NOLOGON, через нее предоставляется доступ только на запись к сущностям в схеме;
- pgm — роль типа NOLOGON для инструмента миграции схем.
Возможно, вам придется расширить права для ролей или как-то адаптировать их под себя.
Зачем нужна отдельная sudo роль и owner?
В PostgreSQL есть функционал, который позволяет задать права по умолчанию для создаваемых объектов — DEFAULT PRIVILEGES, но объекты должны быть созданы именно из под этой роли. Мы задаем DEFAULT PRIVILEGES для роли owner. Перед тем, как что‑то создать, необходимо явно сделать set role *_owner.Если мы просто добавим пользователя в эту роль, то он сможет создавать объекты во всех схемах и есть риск, что может забыть сделать set role.
Чтобы решить эту проблему, мы сделали отдельную роль _sudo со свойством NOINHERIT, которая является членом роли owner, и пользователь вынужден всегда делать set role явно, чтобы получить нужные права.
Миграция схем
После создания схем и базовых ролей, следующим важным компонентом является инструмент миграции. Наш выбор пал на PGmigrate от Yandex. Он прост, позволяет использовать нашу ролевую модель и подход gitops.В git для проекта мы создаем следующую структуру:
<db_name>/
<schema_name>/
migrations.yml
<migrations>
<callbacks>/
<afterEach>/
00_after_each.sql
<beforeEach>/
00_before_each.sql
...
Для генерации структуры можно воспользоваться скриптом из того же репозитория в github.
В файле migrations.yml мы указываем запросы, которые будут выполнены до и после каждой версии миграции.
migrations.yml
00_before_each.sql, делаем SET ROLE на владельца схемы и устанавливаем search_path в имя схемы.
00_before_each.sql
В 00_after_each.sql, сбрасываем роль и search_path.
00_after_each.sql
Пример такой структуры можно посмотреть в директории migrations на github.
О PGmigrate....
Пример запуска примера из репозитория с github
Проверки в CI
Перед миграцией в master мы выполняем следующие проверки:- не изменены файлы уже примененных версий миграций;
- в скритах миграций нет set role или reset role;
- имя файла в миграции соответствует требованиям PGmigrate: V<version>__<description>.sql;
- версии в миграциях последовательно возрастают (pgmigrate умеет это проверять);
- изменяется только одна схема в директории со схемой (pgmigrate умеет это проверять, но непосредственно в момент применения миграций);
- наличие в скрипте миграции первой строкой указания использовать utf-8(/* pgmigrate-encoding: utf-8 */), чтобы избежать проблем с non‑ascii символами;
- применение всех миграций в CI на временной БД для проверки на наличие ошибок в SQL коде.
pgmigrate.py -d <db_name>/<schema_name> -v -m <schema_name> --check_serial_versions -t latest migrate
Пользователи и группы
Мы стараемся везде использовать LDAP аутентификацию и не создавать локальных учетных записей.На каждую роль *_view, *_write и *_sudo создается своя группа в AD. Периодически скриптом мы синхронизируем членов этой группы с соответствующими группами в PostgreSQL, создаем отсутствующих пользователей. Наш скрипт умеет работать со вложенными группами, и это позволяет в качестве членов групп использовать другие группы в AD, например группа «все разработчики BI».
Полезно также иметь общую группу в AD на каждый сервер, включающую все эти группы, чтобы в pg_hba.conf или в PGAdmin дополнительно ограничить доступ с помощью ldapsearchfilter:
Пример из pg_hba.conf:
Реальный пример
Рассмотрим пример проекта, который использует описанный выше подход.Его архитектура представлена ниже:
В базе данных созданы три схемы (слоя): raw, ods, cdm. На каждую схему в PostgreSQL созданы 4 роли(+1 для миграций — pgm).
В LDAP на каждую схему создано три группы, соответствующие *_view, *_write и *_sudo.
Код миграций лежит в GIT. Миграции выполняются под доменным пользователем dbx‑pgmigrate, который входит в локальные группы dbx_raw_pgm, dbx_ods_pgm, dbx_cdm_pgm в PostgreSQL.
Перекладка данных между схемами/слоями осуществляется сервисом Airflow, который подключается к БД под пользователем dbx‑airflow и имеет только write права на схемы.
Также на схеме присутствует BI сервис, который подключается к PostgreSQL под пользователем bi‑user и имеет права только на чтение в схему CDM. И сервис PGAdmin, через который пользователь dbx‑dev‑user1 может подключаться к PostgreSQL и выполнять запросы на чтение во всех трех схемах.
Итого
Команды постоянно вынуждены изучать новое, стек применяемых технологий только множится, и иногда на проекте, особенно на старте, может просто не быть выделенного DBA. Поэтому мы постарались проработать и упростить начало использования PostgreSQL в разрабатываемых сервисах.Надеюсь, предложенный подход вам будет полезен!
Сахар для слоненка — быстрый старт c PostgreSQL для команд в НЛМК
На протяжении более чем 10 лет работы с PostgreSQL, периодически наблюдаю, как команды на начальном этапе, зачастую, не уделяют внимание ролевой модели базы,...
habr.com