В какой-то довольно близкий момент времени мне стало интересно устройство компиляторов в целом, а в частности трансляторов с языков высокого уровня в ассемблер. И оказалось, что статей на эту тему не так много, а с примерами и хоть сколько-нибудь детальным описанием я нашел вообще одну, выбор языков в которой был несколько странным.
Не говорю, что эта статья плоха, напротив, но основная проблема, на мой взгляд, была в том, что транслируется код в язык собственной виртуальной машины, а не в ассемблерный код. Поэтому я решил попробовать написать свою статью, для освещения этой проблемы.
С выбором ассемблера стоит сделать оговорку, почему именно такое экзотическое решение для 2023 года. На деле все просто: его, на мой взгляд, поймет любой, кто работает с современными вариантами ассемблера, а также студенты, которые просто касались этого языка в вузе.
Вернемся к фазам компиляции программы. Для их описания можно привести вот такое изображение с примером каждой фазы:
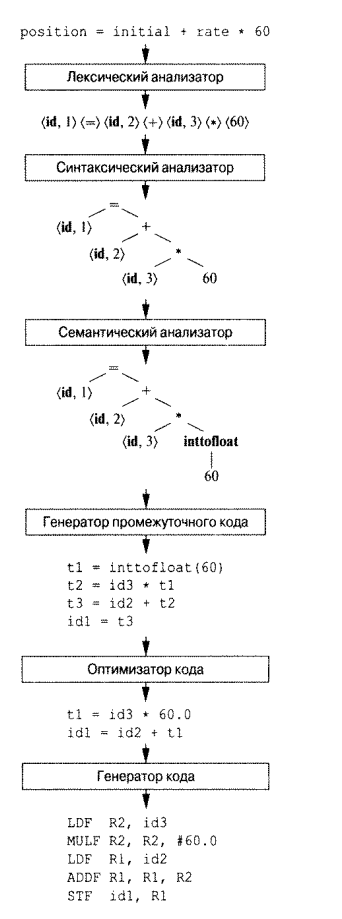
В рамках данной статьи я, как и в статье, упомянутой в заголовке, я несколько упрощу схему, а именно будут пропущены шаги семантического анализа (в предложенной модели в нем нет смысла) генератора промежуточного кода и его оптимизатора. При этом в статье будет освещен вопрос построения лексического и синтаксического анализаторов, а также генерация ассемблерного кода.
Для начала определимся, какие операции будут доступны в нашем компиляторе. В рамках данной статьи будет рассматриваться слегка усложненный калькулятор "с базара":
<program> ::= <statement>
<statement> ::= "if" <parenExpr> <statement> |
"if" <parenExpr> <statement> "else" <statement> |
"while" <parenExpr> <statement> |
"print" <parenExpr> |
"{" { <statement> } "}" |
<expr> ";" |
";"
<parenExpr> ::= "(" <expr> ")"
<expr> ::= <test> | <id> "=" <expr>
<test> ::= <arExpr> | <arExpr> "<" <arExpr>
<arExpr> ::= <term> | <arExpr> "+" <term> |
<arExpr> "*" <term> | <arExpr> "-" <term> |
<arExpr> "/" <term>
<term> ::= <id> | <int> | <parenExpr>
<id> ::= "a" | "b" | ... | "z"
<int> ::= <digit>, { <digit> }
<digit> ::= "0" | "1" | ... | "9"
Вся программа состоит из одного оператора. Этот один оператор может быть либо набором таких же операторов, заключенных в фигурные скобки, либо условным/циклическим оператором (if, if/else, while), либо оператором вывода числа (print), либо просто выражением.
Условные и циклические операторы содержат в себе выражение-условие (записанное в круглых скобках. Если значение выражения равно 0, то компилятор интерпретирует его как false, в ином случае - как true) и тело (являющееся полноценным оператором).
Обычные выражения заканчиваются точкой с запятой.
Выражения, используемые в условиях и операторе print представляют собой арифметические выражения, состоящие из доступных нам арифметических операций присваиваний (которые, как было указано раньше, возвращают новое значение переменной).
Арифметическое выражение состоит из арифметических действий над термами, которые в свою очередь являются именем переменной, целым числом или выражением в круглых скобках.
Определив грамматику, мы сможем перейти к созданию лексического анализатора.
//compiler.h
enum class tokensTypes
{
NUM, VAR, IF, ELSE, WHILE, LBRA, RBRA, LPAR, RPAR,
ADD, SUB, MUL, DIV, LESS, ASSIG,
SEMICOL, ENDFILE, ERROR, PRINT
};
//compiler.cpp
std::map<char, compiler::tokensTypes> compiler::specialSymbols
{
std: air<char, tokensTypes>{'{', tokensTypes::LBRA},
air<char, tokensTypes>{'{', tokensTypes::LBRA},
std:air<char, tokensTypes>{'}', tokensTypes::RBRA},
std:air<char, tokensTypes>{'(', tokensTypes::LPAR},
std:air<char, tokensTypes>{')', tokensTypes::RPAR},
std:air<char, tokensTypes>{'+', tokensTypes::ADD},
std:air<char, tokensTypes>{'-', tokensTypes::SUB},
std:air<char, tokensTypes>{'*', tokensTypes::MUL},
std:air<char, tokensTypes>{'/', tokensTypes:IV},
std:air<char, tokensTypes>{'<', tokensTypes::LESS},
std:air<char, tokensTypes>{'=', tokensTypes::ASSIG},
std:air<char, tokensTypes>{';', tokensTypes::SEMICOL},
};
std::map<std::string, compiler::tokensTypes> compiler::specialWords
{
std:air<std::string, tokensTypes>{"if", tokensTypes::IF},
std:air<std::string, tokensTypes>{"else", tokensTypes::ELSE},
std:air<std::string, tokensTypes>{"while", tokensTypes::WHILE},
std:air<std::string, tokensTypes>{"print", tokensTypes:RINT},
};
А также определим метод, который по строке и текущей позиции курсора в ней будет определять следующий токен:
// compiler.h
class token
{
public:
tokensTypes type;
unsigned short value;
char variable;
token(tokensTypes type, int value = 0, char variable = 'a');
};
// compiler.cpp
compiler::token compiler::getNexttoken()
{
if (nowPos == textLen) // Если файл прочитан, возвращаем конец файла
return token(compiler::tokensTypes::ENDFILE);
std::string str = ""; // В эту строку будет записываться текущий токен
char now = text[nowPos++];
// Пропускаем все незначимые символы
while ((now == ' ' || now == '\r' || now == '\n' || now == '\t')&& nowPos < textLen)
now = text[nowPos++];
// И снова проверяем на конец файла
if (nowPos == textLen)
return token(compiler::tokensTypes::ENDFILE);
// Пока не подойшли к символу, который однозначно говорит о конце токена, считываем
while (!(now == ' ' || now == '\r' || now == '\n' || now == '\t'))
{
// Если в строке нет символов, проверяем на причастностьк специальным символам или числам
if (str.size() == 0)
{
if (specialSymbols.count(now))
return token(specialSymbols[now]);
else if (isdigit(now))
{
do
{
str += now;
now = text[nowPos++];
} while (isdigit(now));
nowPos--;
break;
}
else
str += now;
}
else
{
if (specialSymbols.count(now)) // Если был встречен специальный символ
{ // Также заканчиваем парсинг токена
nowPos--;
break;
}
str += now;
}
if (specialWords.count(str)) //Проверяем на нахождение в списке зарезервированных слов
return token(specialWords[str]);
if (nowPos == textLen)
break;
now = text[nowPos++];
}
// Если в токене единственная строчная буква, то интерпретируем как имя переменной
if (str.size() == 1 && str[0] >= 'a' && str[0] <= 'z')
return token(tokensTypes::VAR, 0, str[0]);
unsigned short value = 0;
// Если токен - число, распознаем его
for (int i = 0; i < str.size(); i++)
{
if (isdigit(str))
value = value * 10 + (str - '0');
else
return token(compiler::tokensTypes::ERROR);
}
return token(compiler::tokensTypes::NUM, value);
}
В основном методе компиляции заполняем вектор токенов:
//compiler.cpp
bool compiler::compile(std::string& result)
{
token token = getNexttoken();
while (token.type != tokensTypes::ENDFILE)
{
if (token.type == tokensTypes::ERROR) // Если токен не распознан
{
result = "Lexical error"; // Возвращаем лексическую ошибку
return false;
}
tokens.push_back(token);
token = getNexttoken();
}
tokens.push_back(token);
}
На этом лексический анализатор можно считать завершенным.
// compiler.h
enum class nodeTypes
{
CONST, VAR, ADD, SUB, MUL, DIV,
LESSTHEN, SET, IF, IFELSE, WHILE,
EMPTY, SEQ, EXPR, PROG, PRINT
};
class node
{
public:
nodeTypes type;
int value;
node* op1;
node* op2;
node* op3;
node(nodeTypes type, int value = 0, node* op1 = nullptr, node* op2 = nullptr, node* op3 = nullptr);
~node();
};
С данными вводными определим методы, преобразующие последовательность токенов в синтаксическое дерево (кода много, поэтому скрыл под спойлер):
Hidden text
// compiler.cpp
bool compiler:arser:arse(std::vector<token>& tokens, compiler::node& result)
{
int count = 0;
compiler::node* node = new compiler::node(nodeTypes::EMPTY);
bool res = parser::statement(tokens, count, node);
if (count != tokens.size() - 1 || !res)
return false;
result = *node;
return true;
}
bool compiler:arser::statement(std::vector<token>& tokens, int& count, compiler::node*& node)
{
delete node;
node = new compiler::node(nodeTypes::EMPTY);
bool parsed = true;
switch (tokens[count].type)
{
case compiler::tokensTypes::IF:
count++;
node->type = nodeTypes::IF;
parsed = compiler:arser:arenExpr(tokens, count, node->op1);
if (!parsed)
return false;
parsed = compiler:arser::statement(tokens, count, node->op2);
if (!parsed)
return false;
if (tokens[count].type == tokensTypes::ELSE)
{
count++;
node->type = nodeTypes::IFELSE;
bool parsed = compiler:arser::statement(tokens, count, node->op3);
if (!parsed)
return false;
}
break;
case compiler::tokensTypes::WHILE:
count++;
node->type = nodeTypes::WHILE;
parsed = compiler:arser:arenExpr(tokens, count, node->op1);
if (!parsed)
return false;
parsed = compiler:arser::statement(tokens, count, node->op2);
if (!parsed)
return false;
break;
case compiler::tokensTypes::SEMICOL:
count++;
break;
case compiler::tokensTypes::LBRA:
count++;
while (tokens[count].type != tokensTypes::RBRA && count < tokens.size())
{
node = new compiler::node(nodeTypes::SEQ, 0, node);
bool parsed = compiler:arser::statement(tokens, count, node->op2);
if (!parsed)
return false;
}
count++;
break;
case compiler::tokensTypes:RINT:
count++;
node->type = nodeTypes:RINT;
parsed = compiler:arser:arenExpr(tokens, count, node->op1);
if (!parsed)
return false;
break;
if (!parsed)
return false;
default:
node->type = nodeTypes::EXPR;
parsed = compiler:arser::expr(tokens, count, node->op1);
if (tokens[count++].type != tokensTypes::SEMICOL)
return false;
if (!parsed)
return false;
}
return true;
}
bool compiler:arser:arenExpr(std::vector<token>& tokens, int& count, compiler::node*& node)
{
delete node;
if (tokens[count].type != tokensTypes::LPAR)
return false;
count++;
bool res = expr(tokens, count, node);
if (tokens[count].type != tokensTypes::RPAR)
return false;
count++;
return true;
}
bool compiler:arser::expr(std::vector<token>& tokens, int& count, compiler::node*& node)
{
delete node;
if (tokens[count].type != compiler::tokensTypes::VAR)
return test(tokens, count, node);
bool res = test(tokens, count, node);
if (!res)
return false;
if (node->type == nodeTypes::VAR && tokens[count].type == tokensTypes::ASSIG)
{
node = new compiler::node(nodeTypes::SET, 0, node);
count++;
res = expr(tokens, count, node->op2);
}
return res;
}
bool compiler:arser::test(std::vector<token>& tokens, int& count, compiler::node*& node)
{
delete node;
bool res = arExpr(tokens, count, node);
if (!res)
return false;
if (tokens[count].type == tokensTypes::LESS)
{
count++;
node = new compiler::node(nodeTypes::LESSTHEN, 0, node);
res = arExpr(tokens, count, node->op2);
}
return res;
}
bool compiler:arser::arExpr(std::vector<token>& tokens, int& count, compiler::node*& node)
{
delete node;
bool res = term(tokens, count, node);
if (!res)
return false;
tokensTypes now = tokens[count].type;
while (now == tokensTypes::ADD || now == tokensTypes::SUB || now == tokensTypes::MUL || now == tokensTypes:IV)
{
nodeTypes nT = nodeTypes::EMPTY;
switch (now)
{
case compiler::tokensTypes::ADD:
nT = nodeTypes::ADD;
break;
case compiler::tokensTypes::SUB:
nT = nodeTypes::SUB;
break;
case compiler::tokensTypes::MUL:
nT = nodeTypes::MUL;
break;
case compiler::tokensTypes:IV:
nT = nodeTypes:IV;
break;
}
node = new compiler::node(nT, 0, node);
count++;
bool res = term(tokens, count, node->op2);
if (!res)
return false;
now = tokens[count].type;
}
return true;
}
bool compiler:arser::term(std::vector<token>& tokens, int& count, compiler::node*& node)
{
delete node;
bool parsed;
switch(tokens[count].type)
{
case tokensTypes::VAR:
node = new compiler::node(nodeTypes::VAR, tokens[count].variable - 'a');
count++;
break;
case tokensTypes::NUM:
node = new compiler::node(nodeTypes::CONST, tokens[count].value);
count++;
break;
default:
bool res = parenExpr(tokens, count, node);
if (!res)
return false;
break;
}
return true;
}
Здесь каждое выражение распознается в соответствии с правилами грамматики, определенными выше. Стоит остановиться подробнее на том, как определяются дочерние узлы. Их можно разбить на несколько групп:
На этом синтаксический анализ окончен: в случае некорректно составленного кода, осталось добавить его в метод компиляции кода:
// compiler.cpp
bool compiler::compile(std::string& result)
{
token token = getNexttoken();
while (token.type != tokensTypes::ENDFILE)
{
if (token.type == tokensTypes::ERROR)
{
result = "Lexical error";
return false;
}
tokens.push_back(token);
token = getNexttoken();
}
tokens.push_back(token);
compiler::node tree = compiler::node(nodeTypes::EMPTY);
if (!compiler:arser:arse(tokens, tree))
return false;
}
Hidden text
const std::string compiler::linker:rogramsStart = R"STR(ASSUME CS:CODE, DSATA
DATA SEGMENT
vars dw 26 dup (0)
DATA ENDS;
CODE SEGMENT
PRINT MACRO
local DIVCYC, PRINTNUM;
push ax;
push bx;
push cx;
push dx;
mov bx, 10;
mov cx, 0;
DIVCYC:
mov dx, 0;
div bx;
push dx;
inc cx;
cmp ax, 0;
jne DIVCYC;
PRINTNUM:
pop dx;
add dl, '0';
mov ah, 02h;
int 21h;
dec cx;
cmp cx, 0;
jne PRINTNUM;
mov dl, 0dh;
mov ah, 02h;
int 21h;
mov dl, 0ah;
mov ah, 02h;
int 21h;
pop dx;
pop cx;
pop bx;
pop ax;
ENDM;
begin:
lea si, vars;
)STR";
const std::string compiler::linker:rogramsEnd = R"STR( mov ah, 4Ch;
int 21h;
CODE ENDS;
end begin)STR";
Из интересного в данном коде: выделение 26 слов (участков памяти по два байта) под переменные, а также вывод числа с помощью макроса PRINT (он выводит содержимое регистра AX, сохраняя состояние регистров в стеке перед выводом и восстанавливая его после, а также записывает в стек цифры числа, после чего выводит их одну за другой).
Следующим шагом будет определение используемых регистров для осуществления операций. В данном коде основным регистром, содержащим и обрабатывающим данные является регистр AX (в нем всегда находится левый операнд и результат операции), в качестве регистра, хранящего правый операнд, используется регистр BX.
При сборке ассемблерного кода вначале используется строка programsStart, затем к ней прибавляются операции кода, а завершается это строкой programsEnd.
Рассмотрим трансляцию каждого типа узлов дерева в ассемблерный код:
Hidden text
std::string compiler::linker::compileNode(compiler::node* block, int& labelCount)
{
std::string result = "";
int lCount1, lCount2, firstLabelNum, secondLabelNum, thirdLabelNum;
switch (block->type)
{
case nodeTypes:ROG:
result += compileNode(block->op1, labelCount);
break;
case nodeTypes:RINT:
result += compileNode(block->op1, labelCount);
result += " PRINT;\n";
break;
case nodeTypes::VAR:
result += " mov ax, [si + " + std::to_string(block->value * 2) + "];\n";
break;
case nodeTypes::CONST:
result += " mov ax, " + std::to_string(block->value) + ";\n";
break;
case nodeTypes::ADD:
result += compileNode(block->op1, labelCount);
result += " push ax;\n";
result += compileNode(block->op2, labelCount);
result += " mov bx, ax;\n";
result += " pop ax;\n";
result += " add ax, bx;\n";
break;
case nodeTypes::SUB:
result += compileNode(block->op1, labelCount);
result += " push ax;\n";
result += compileNode(block->op2, labelCount);
result += " mov bx, ax;\n";
result += " pop ax;\n";
result += " sub ax, bx;\n";
break;
case nodeTypes::MUL:
result += compileNode(block->op1, labelCount);
result += " push ax;\n";
result += compileNode(block->op2, labelCount);
result += " mov bx, ax;\n";
result += " pop ax;\n";
result += " mul bx;\n";
break;
case nodeTypes:IV:
result += compileNode(block->op1, labelCount);
result += " push ax;\n";
result += compileNode(block->op2, labelCount);
result += " mov bx, ax;\n";
result += " pop ax;\n";
result += " xor dx, dx;\n";
result += " div bx;\n";
break;
case nodeTypes::SET:
result += compileNode(block->op2, labelCount);
result += " mov [si + " + std::to_string(block->op1->value * 2) + "], ax;\n";
break;
case nodeTypes::EXPR:
result += compileNode(block->op1, labelCount) + '\n';
break;
case nodeTypes::LESSTHEN:
result += compileNode(block->op1, labelCount);
result += " push ax;\n";
result += compileNode(block->op2, labelCount);
result += " mov bx, ax;\n";
result += " pop ax;\n";
result += " cmp ax, bx;\n";
result += " jae LBL" + std::to_string(labelCount++) + ";\n";
result += " mov ax, 1;\n";
result += " jmp LBL" + std::to_string(labelCount++) + ";\n";
result += " LBL" + std::to_string(labelCount - 2) + ":\n";
result += " mov ax, 0;\n";
result += " LBL" + std::to_string(labelCount - 1) + ": nop\n";
break;
case nodeTypes::IF:
result += compileNode(block->op1, labelCount);
result += " cmp ax, 0;\n";
lCount1 = labelCount;
result += " jne LBL" + std::to_string(labelCount++) + ";\n";
lCount2 = labelCount;
result += " jmp LBL" + std::to_string(labelCount++) + ";\n";
result += " LBL" + std::to_string(lCount1) + ": nop\n";
result += compileNode(block->op2, labelCount);
result += " LBL" + std::to_string(lCount2) + ": nop\n";
break;
case nodeTypes::SEQ:
result += compileNode(block->op1, labelCount);
result += compileNode(block->op2, labelCount);
break;
case nodeTypes::IFELSE:
result += compileNode(block->op1, labelCount);
result += " cmp ax, 0;\n";
firstLabelNum = labelCount;
result += " je LBL" + std::to_string(labelCount++) + ";\n";
result += compileNode(block->op2, labelCount);
secondLabelNum = labelCount;
result += " jmp LBL" + std::to_string(labelCount++) + ";\n";
result += " LBL" + std::to_string(firstLabelNum) + ": nop\n";
result += compileNode(block->op3, labelCount);
result += " LBL" + std::to_string(secondLabelNum) + ": nop\n";
break;
case nodeTypes::WHILE:
secondLabelNum = labelCount;
result += " jmp LBL" + std::to_string(labelCount++) + "; \n";
firstLabelNum = labelCount;
result += " LBL" + std::to_string(labelCount++) + ": nop\n";
result += compileNode(block->op2, labelCount);
result += " LBL" + std::to_string(secondLabelNum) + ": nop\n";
result += compileNode(block->op1, labelCount);
result += " cmp ax, 0;\n";
thirdLabelNum = labelCount;
result += " je LBL" + std::to_string(thirdLabelNum) + "\n";
result += " jmp LBL" + std::to_string(firstLabelNum) + "\n";
result += " LBL" + std::to_string(thirdLabelNum) + ": nop\n";
break;
default:
break;
}
return result;
}
В данном коде стоит обратить внимание на следующее:
// compiler.css
std::string compiler::linker::compile()
{
std::string program = "";
program += programsStart;
int a = 0;
program += compileNode(tree, a);
program += programsEnd;
return program;
}
bool compiler::compile(std::string& result)
{
token token = getNexttoken();
while (token.type != tokensTypes::ENDFILE)
{
if (token.type == tokensTypes::ERROR)
{
result = "Lexical error";
return false;
}
tokens.push_back(token);
token = getNexttoken();
}
tokens.push_back(token);
compiler::node tree = compiler::node(nodeTypes::EMPTY);
if (!compiler:arser:arse(tokens, tree))
return false;
compiler:linker linker = compiler::linker(&tree);
result = linker.compile();
return true;
}
Остается лишь проверить работоспособность данного компилятора.
Для решения первой задачи используется следующий код на "нашем языке":
#include <iostream>
#include "compiler.h"
int main()
{
char* data = new char[166];
memcpy(data, "{a = 6; m = 283; s = m - 2; b = a; c = 1; while(0 < s) { if (0 < s - (s/2*2)){c = c * b; c = c - (c / m * m);} s = s / 2; b = b * b; b = b - (b / m * m);} print(c);}", 166);
compiler comp = compiler(data, 166);
std::string result;
comp.compile(result);
std::cout << result;
}
Как можно заметить, строка с кодом программы написана без какого-либо форматирования, это сделано для проверки корректности распознавания кода даже в условиях слабого форматирования. Посмотрим на ассемблерный код, сгенерированный нашим компилятором:
Hidden text
ASSUME CS:CODE, DSATA
DATA SEGMENT
vars dw 26 dup (0)
DATA ENDS;
CODE SEGMENT
PRINT MACRO
local DIVCYC, PRINTNUM;
push ax;
push bx;
push cx;
push dx;
mov bx, 10;
mov cx, 0;
DIVCYC:
mov dx, 0;
div bx;
push dx;
inc cx;
cmp ax, 0;
jne DIVCYC;
PRINTNUM:
pop dx;
add dl, '0';
mov ah, 02h;
int 21h;
dec cx;
cmp cx, 0;
jne PRINTNUM;
mov dl, 0dh;
mov ah, 02h;
int 21h;
mov dl, 0ah;
mov ah, 02h;
int 21h;
pop dx;
pop cx;
pop bx;
pop ax;
ENDM;
begin:
lea si, vars;
mov ax, 6;
mov [si + 0], ax;
mov ax, 283;
mov [si + 24], ax;
mov ax, [si + 24];
push ax;
mov ax, 2;
mov bx, ax;
pop ax;
sub ax, bx;
mov [si + 36], ax;
mov ax, [si + 0];
mov [si + 2], ax;
mov ax, 1;
mov [si + 4], ax;
jmp LBL0;
LBL1: nop
mov ax, 0;
push ax;
mov ax, [si + 36];
push ax;
mov ax, [si + 36];
push ax;
mov ax, 2;
mov bx, ax;
pop ax;
xor dx, dx;
div bx;
push ax;
mov ax, 2;
mov bx, ax;
pop ax;
mul bx;
mov bx, ax;
pop ax;
sub ax, bx;
mov bx, ax;
pop ax;
cmp ax, bx;
jae LBL2;
mov ax, 1;
jmp LBL3;
LBL2:
mov ax, 0;
LBL3: nop
cmp ax, 0;
jne LBL4;
jmp LBL5;
LBL4: nop
mov ax, [si + 4];
push ax;
mov ax, [si + 2];
mov bx, ax;
pop ax;
mul bx;
mov [si + 4], ax;
mov ax, [si + 4];
push ax;
mov ax, [si + 4];
push ax;
mov ax, [si + 24];
mov bx, ax;
pop ax;
xor dx, dx;
div bx;
push ax;
mov ax, [si + 24];
mov bx, ax;
pop ax;
mul bx;
mov bx, ax;
pop ax;
sub ax, bx;
mov [si + 4], ax;
LBL5: nop
mov ax, [si + 36];
push ax;
mov ax, 2;
mov bx, ax;
pop ax;
xor dx, dx;
div bx;
mov [si + 36], ax;
mov ax, [si + 2];
push ax;
mov ax, [si + 2];
mov bx, ax;
pop ax;
mul bx;
mov [si + 2], ax;
mov ax, [si + 2];
push ax;
mov ax, [si + 2];
push ax;
mov ax, [si + 24];
mov bx, ax;
pop ax;
xor dx, dx;
div bx;
push ax;
mov ax, [si + 24];
mov bx, ax;
pop ax;
mul bx;
mov bx, ax;
pop ax;
sub ax, bx;
mov [si + 2], ax;
LBL0: nop
mov ax, 0;
push ax;
mov ax, [si + 36];
mov bx, ax;
pop ax;
cmp ax, bx;
jae LBL6;
mov ax, 1;
jmp LBL7;
LBL6:
mov ax, 0;
LBL7: nop
cmp ax, 0;
je LBL8
jmp LBL1
LBL8: nop
mov ax, [si + 4];
PRINT;
mov ah, 4Ch;
int 21h;
CODE ENDS;
end begin
Получилось много и не очень красиво (а что ждать от взятия остатка через деление, умножение и вычитание?), сравним результаты работы программы и результата с первого попавшегося сайта:
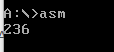

Как видим, результаты сошлись. Перейдем к алгоритму Евклида. Код на "нашем" языке для него будет следующим:
#include <iostream>
#include "compiler.h"
int main()
{
char* data = new char[85];
memcpy(data, "{a = 11004; b = 10087; while(0 < b) {c = a - (a / b * b); a = b; b = c;} print(a);}", 85);
compiler comp = compiler(data, 85);
std::string result;
comp.compile(result);
std::cout << result;
}
Получаем следующий ассемблерный код:
Hidden text
ASSUME CS:CODE, DSATA
DATA SEGMENT
vars dw 26 dup (0)
DATA ENDS;
CODE SEGMENT
PRINT MACRO
local DIVCYC, PRINTNUM;
push ax;
push bx;
push cx;
push dx;
mov bx, 10;
mov cx, 0;
DIVCYC:
mov dx, 0;
div bx;
push dx;
inc cx;
cmp ax, 0;
jne DIVCYC;
PRINTNUM:
pop dx;
add dl, '0';
mov ah, 02h;
int 21h;
dec cx;
cmp cx, 0;
jne PRINTNUM;
mov dl, 0dh;
mov ah, 02h;
int 21h;
mov dl, 0ah;
mov ah, 02h;
int 21h;
pop dx;
pop cx;
pop bx;
pop ax;
ENDM;
begin:
lea si, vars;
mov ax, 11004;
mov [si + 0], ax;
mov ax, 10087;
mov [si + 2], ax;
jmp LBL0;
LBL1: nop
mov ax, [si + 0];
push ax;
mov ax, [si + 0];
push ax;
mov ax, [si + 2];
mov bx, ax;
pop ax;
xor dx, dx;
div bx;
push ax;
mov ax, [si + 2];
mov bx, ax;
pop ax;
mul bx;
mov bx, ax;
pop ax;
sub ax, bx;
mov [si + 4], ax;
mov ax, [si + 2];
mov [si + 0], ax;
mov ax, [si + 4];
mov [si + 2], ax;
LBL0: nop
mov ax, 0;
push ax;
mov ax, [si + 2];
mov bx, ax;
pop ax;
cmp ax, bx;
jae LBL2;
mov ax, 1;
jmp LBL3;
LBL2:
mov ax, 0;
LBL3: nop
cmp ax, 0;
je LBL4
jmp LBL1
LBL4: nop
mov ax, [si + 0];
PRINT;
mov ah, 4Ch;
int 21h;
CODE ENDS;
end begin
Проверим результат работы кода:
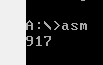

Как видно, все сходится.

 habr.com
habr.com
Не говорю, что эта статья плоха, напротив, но основная проблема, на мой взгляд, была в том, что транслируется код в язык собственной виртуальной машины, а не в ассемблерный код. Поэтому я решил попробовать написать свою статью, для освещения этой проблемы.
Выбор языков программирования
В качестве языка самого компилятора я выбрал C++, потому что, по данным гугла, в основном для компиляторов используется он, либо чистый "Си". Транслировать же будем в старенький asm, предназначенный для DOS.С выбором ассемблера стоит сделать оговорку, почему именно такое экзотическое решение для 2023 года. На деле все просто: его, на мой взгляд, поймет любой, кто работает с современными вариантами ассемблера, а также студенты, которые просто касались этого языка в вузе.
О чем будет и не будет идти речь в данной статье
Сразу сделаю оговорку: изображения в этой статье будут приведены из "Книги Дракона-2", но мое знакомство с ней было слишком мимолетным (достать картинки для статьи и пробежаться по диагонали по введению).Вернемся к фазам компиляции программы. Для их описания можно привести вот такое изображение с примером каждой фазы:
В рамках данной статьи я, как и в статье, упомянутой в заголовке, я несколько упрощу схему, а именно будут пропущены шаги семантического анализа (в предложенной модели в нем нет смысла) генератора промежуточного кода и его оптимизатора. При этом в статье будет освещен вопрос построения лексического и синтаксического анализаторов, а также генерация ассемблерного кода.
Определение грамматики лексического анализатора
Лексический анализатор, можно сказать, одна из простейших частей компилятора. На его этапе текст программы преобразуется в набор токенов, без проверки на корректность их последовательности.Для начала определимся, какие операции будут доступны в нашем компиляторе. В рамках данной статьи будет рассматриваться слегка усложненный калькулятор "с базара":
- Доступна базовая арифметика (+, -, *, / (целочисленное)). У арифметических действий нет приоритета друг над другом, но можно задать порядок действий с помощью скобок.
- Для удобства некоторых вычислений добавлены условные операторы и операторы циклов if, if/else, while.
- Вывод результатов вычислений в консоль осуществляется с помощью оператора print.
- Для сравнения величин перегружен единственный оператор < (который возвращает 1, если сравнение верно, и 0 в противном случае).
- Для повышения удобства пользователя, ему предоставлены 26 глобальных переменных, которые в тексте программы обозначаются строчными латинскими буквами.
- Пользователю доступен один тип данных: unsigned short.
- Пользователь может группировать операторы с помощью фигурных скобок.
- В качестве результата операции присваивания переменной значения, возвращается новое значение переменной.
- Пробелы, символы табуляции и переносы на новую строку не учитываются при анализе входного текста.
<program> ::= <statement>
<statement> ::= "if" <parenExpr> <statement> |
"if" <parenExpr> <statement> "else" <statement> |
"while" <parenExpr> <statement> |
"print" <parenExpr> |
"{" { <statement> } "}" |
<expr> ";" |
";"
<parenExpr> ::= "(" <expr> ")"
<expr> ::= <test> | <id> "=" <expr>
<test> ::= <arExpr> | <arExpr> "<" <arExpr>
<arExpr> ::= <term> | <arExpr> "+" <term> |
<arExpr> "*" <term> | <arExpr> "-" <term> |
<arExpr> "/" <term>
<term> ::= <id> | <int> | <parenExpr>
<id> ::= "a" | "b" | ... | "z"
<int> ::= <digit>, { <digit> }
<digit> ::= "0" | "1" | ... | "9"
Вся программа состоит из одного оператора. Этот один оператор может быть либо набором таких же операторов, заключенных в фигурные скобки, либо условным/циклическим оператором (if, if/else, while), либо оператором вывода числа (print), либо просто выражением.
Условные и циклические операторы содержат в себе выражение-условие (записанное в круглых скобках. Если значение выражения равно 0, то компилятор интерпретирует его как false, в ином случае - как true) и тело (являющееся полноценным оператором).
Обычные выражения заканчиваются точкой с запятой.
Выражения, используемые в условиях и операторе print представляют собой арифметические выражения, состоящие из доступных нам арифметических операций присваиваний (которые, как было указано раньше, возвращают новое значение переменной).
Арифметическое выражение состоит из арифметических действий над термами, которые в свою очередь являются именем переменной, целым числом или выражением в круглых скобках.
Определив грамматику, мы сможем перейти к созданию лексического анализатора.
Лексический анализатор
Опишем перечисление, в котором будут все типы токенов, получаемые при разборе исходного кода, а также словари, с помощью которых будет осуществляться сопоставление зарезервированных слов и специальных символов с токенами.//compiler.h
enum class tokensTypes
{
NUM, VAR, IF, ELSE, WHILE, LBRA, RBRA, LPAR, RPAR,
ADD, SUB, MUL, DIV, LESS, ASSIG,
SEMICOL, ENDFILE, ERROR, PRINT
};
//compiler.cpp
std::map<char, compiler::tokensTypes> compiler::specialSymbols
{
std:
air<char, tokensTypes>{'{', tokensTypes::LBRA},std:
air<char, tokensTypes>{'}', tokensTypes::RBRA},std:
air<char, tokensTypes>{'(', tokensTypes::LPAR},std:
air<char, tokensTypes>{')', tokensTypes::RPAR},std:
air<char, tokensTypes>{'+', tokensTypes::ADD},std:
air<char, tokensTypes>{'-', tokensTypes::SUB},std:
air<char, tokensTypes>{'*', tokensTypes::MUL},std:
air<char, tokensTypes>{'/', tokensTypes:IV},std:
air<char, tokensTypes>{'<', tokensTypes::LESS},std:
air<char, tokensTypes>{'=', tokensTypes::ASSIG},std:
air<char, tokensTypes>{';', tokensTypes::SEMICOL},};
std::map<std::string, compiler::tokensTypes> compiler::specialWords
{
std:
air<std::string, tokensTypes>{"if", tokensTypes::IF},std:
air<std::string, tokensTypes>{"else", tokensTypes::ELSE},std:
air<std::string, tokensTypes>{"while", tokensTypes::WHILE},std:
air<std::string, tokensTypes>{"print", tokensTypes:RINT},};
А также определим метод, который по строке и текущей позиции курсора в ней будет определять следующий токен:
// compiler.h
class token
{
public:
tokensTypes type;
unsigned short value;
char variable;
token(tokensTypes type, int value = 0, char variable = 'a');
};
// compiler.cpp
compiler::token compiler::getNexttoken()
{
if (nowPos == textLen) // Если файл прочитан, возвращаем конец файла
return token(compiler::tokensTypes::ENDFILE);
std::string str = ""; // В эту строку будет записываться текущий токен
char now = text[nowPos++];
// Пропускаем все незначимые символы
while ((now == ' ' || now == '\r' || now == '\n' || now == '\t')&& nowPos < textLen)
now = text[nowPos++];
// И снова проверяем на конец файла
if (nowPos == textLen)
return token(compiler::tokensTypes::ENDFILE);
// Пока не подойшли к символу, который однозначно говорит о конце токена, считываем
while (!(now == ' ' || now == '\r' || now == '\n' || now == '\t'))
{
// Если в строке нет символов, проверяем на причастностьк специальным символам или числам
if (str.size() == 0)
{
if (specialSymbols.count(now))
return token(specialSymbols[now]);
else if (isdigit(now))
{
do
{
str += now;
now = text[nowPos++];
} while (isdigit(now));
nowPos--;
break;
}
else
str += now;
}
else
{
if (specialSymbols.count(now)) // Если был встречен специальный символ
{ // Также заканчиваем парсинг токена
nowPos--;
break;
}
str += now;
}
if (specialWords.count(str)) //Проверяем на нахождение в списке зарезервированных слов
return token(specialWords[str]);
if (nowPos == textLen)
break;
now = text[nowPos++];
}
// Если в токене единственная строчная буква, то интерпретируем как имя переменной
if (str.size() == 1 && str[0] >= 'a' && str[0] <= 'z')
return token(tokensTypes::VAR, 0, str[0]);
unsigned short value = 0;
// Если токен - число, распознаем его
for (int i = 0; i < str.size(); i++)
{
if (isdigit(str))
value = value * 10 + (str - '0');
else
return token(compiler::tokensTypes::ERROR);
}
return token(compiler::tokensTypes::NUM, value);
}
В основном методе компиляции заполняем вектор токенов:
//compiler.cpp
bool compiler::compile(std::string& result)
{
token token = getNexttoken();
while (token.type != tokensTypes::ENDFILE)
{
if (token.type == tokensTypes::ERROR) // Если токен не распознан
{
result = "Lexical error"; // Возвращаем лексическую ошибку
return false;
}
tokens.push_back(token);
token = getNexttoken();
}
tokens.push_back(token);
}
На этом лексический анализатор можно считать завершенным.
Синтаксический анализ
Во время синтаксического анализа как проверяется корректность последовательности токенов, так и строится синтаксическое дерево. Для построения дерева также нужно определить узлы и их типы:// compiler.h
enum class nodeTypes
{
CONST, VAR, ADD, SUB, MUL, DIV,
LESSTHEN, SET, IF, IFELSE, WHILE,
EMPTY, SEQ, EXPR, PROG, PRINT
};
class node
{
public:
nodeTypes type;
int value;
node* op1;
node* op2;
node* op3;
node(nodeTypes type, int value = 0, node* op1 = nullptr, node* op2 = nullptr, node* op3 = nullptr);
~node();
};
С данными вводными определим методы, преобразующие последовательность токенов в синтаксическое дерево (кода много, поэтому скрыл под спойлер):
Hidden text
// compiler.cpp
bool compiler:
arser:arse(std::vector<token>& tokens, compiler::node& result){
int count = 0;
compiler::node* node = new compiler::node(nodeTypes::EMPTY);
bool res = parser::statement(tokens, count, node);
if (count != tokens.size() - 1 || !res)
return false;
result = *node;
return true;
}
bool compiler:
arser::statement(std::vector<token>& tokens, int& count, compiler::node*& node){
delete node;
node = new compiler::node(nodeTypes::EMPTY);
bool parsed = true;
switch (tokens[count].type)
{
case compiler::tokensTypes::IF:
count++;
node->type = nodeTypes::IF;
parsed = compiler:
arser:arenExpr(tokens, count, node->op1);if (!parsed)
return false;
parsed = compiler:
arser::statement(tokens, count, node->op2);if (!parsed)
return false;
if (tokens[count].type == tokensTypes::ELSE)
{
count++;
node->type = nodeTypes::IFELSE;
bool parsed = compiler:
arser::statement(tokens, count, node->op3);if (!parsed)
return false;
}
break;
case compiler::tokensTypes::WHILE:
count++;
node->type = nodeTypes::WHILE;
parsed = compiler:
arser:arenExpr(tokens, count, node->op1);if (!parsed)
return false;
parsed = compiler:
arser::statement(tokens, count, node->op2);if (!parsed)
return false;
break;
case compiler::tokensTypes::SEMICOL:
count++;
break;
case compiler::tokensTypes::LBRA:
count++;
while (tokens[count].type != tokensTypes::RBRA && count < tokens.size())
{
node = new compiler::node(nodeTypes::SEQ, 0, node);
bool parsed = compiler:
arser::statement(tokens, count, node->op2);if (!parsed)
return false;
}
count++;
break;
case compiler::tokensTypes:
RINT:count++;
node->type = nodeTypes:
RINT;parsed = compiler:
arser:arenExpr(tokens, count, node->op1);if (!parsed)
return false;
break;
if (!parsed)
return false;
default:
node->type = nodeTypes::EXPR;
parsed = compiler:
arser::expr(tokens, count, node->op1);if (tokens[count++].type != tokensTypes::SEMICOL)
return false;
if (!parsed)
return false;
}
return true;
}
bool compiler:
arser:arenExpr(std::vector<token>& tokens, int& count, compiler::node*& node){
delete node;
if (tokens[count].type != tokensTypes::LPAR)
return false;
count++;
bool res = expr(tokens, count, node);
if (tokens[count].type != tokensTypes::RPAR)
return false;
count++;
return true;
}
bool compiler:
arser::expr(std::vector<token>& tokens, int& count, compiler::node*& node){
delete node;
if (tokens[count].type != compiler::tokensTypes::VAR)
return test(tokens, count, node);
bool res = test(tokens, count, node);
if (!res)
return false;
if (node->type == nodeTypes::VAR && tokens[count].type == tokensTypes::ASSIG)
{
node = new compiler::node(nodeTypes::SET, 0, node);
count++;
res = expr(tokens, count, node->op2);
}
return res;
}
bool compiler:
arser::test(std::vector<token>& tokens, int& count, compiler::node*& node){
delete node;
bool res = arExpr(tokens, count, node);
if (!res)
return false;
if (tokens[count].type == tokensTypes::LESS)
{
count++;
node = new compiler::node(nodeTypes::LESSTHEN, 0, node);
res = arExpr(tokens, count, node->op2);
}
return res;
}
bool compiler:
arser::arExpr(std::vector<token>& tokens, int& count, compiler::node*& node){
delete node;
bool res = term(tokens, count, node);
if (!res)
return false;
tokensTypes now = tokens[count].type;
while (now == tokensTypes::ADD || now == tokensTypes::SUB || now == tokensTypes::MUL || now == tokensTypes:
IV){
nodeTypes nT = nodeTypes::EMPTY;
switch (now)
{
case compiler::tokensTypes::ADD:
nT = nodeTypes::ADD;
break;
case compiler::tokensTypes::SUB:
nT = nodeTypes::SUB;
break;
case compiler::tokensTypes::MUL:
nT = nodeTypes::MUL;
break;
case compiler::tokensTypes:
IV:nT = nodeTypes:
IV;break;
}
node = new compiler::node(nT, 0, node);
count++;
bool res = term(tokens, count, node->op2);
if (!res)
return false;
now = tokens[count].type;
}
return true;
}
bool compiler:
arser::term(std::vector<token>& tokens, int& count, compiler::node*& node){
delete node;
bool parsed;
switch(tokens[count].type)
{
case tokensTypes::VAR:
node = new compiler::node(nodeTypes::VAR, tokens[count].variable - 'a');
count++;
break;
case tokensTypes::NUM:
node = new compiler::node(nodeTypes::CONST, tokens[count].value);
count++;
break;
default:
bool res = parenExpr(tokens, count, node);
if (!res)
return false;
break;
}
return true;
}
Здесь каждое выражение распознается в соответствии с правилами грамматики, определенными выше. Стоит остановиться подробнее на том, как определяются дочерние узлы. Их можно разбить на несколько групп:
- Узлы типа CONST, VAR: не содержат дочерних узлов, но содержат значение, определяющее значение числа или позицию элемента в массиве
- Узлы типа ADD, SUB, MUL, DIV, LESSTHEN: содержат по два дочерних узла, где op1 - левый операнд, а op2 - правый.
- Узлы типа SET: содержат по два дочерних узла: op1 - узел типа VAR с переменной, которой присваивается значение, op2 - узел, собирающий значение, которое нужно присвоить переменной.
- Узлы типа IF и WHILE: также включают в себя по два дочерних узла: op1 - условие, истинность которого проверяется, op2 - выражение, которое выполняется в случае истинности.
- Узлы типа IFELSE: содержат три дочерних узла. Первые два такие же, как у узлов IF или WHILE, третий - выражения, которые выполняются в случае, если выражение ложно.
- Узлы типа SEQ: содержит два дочерних узла. op1 - предыдущее выполняемое действие, op2 - текущее действие. (Возможно, стоило сделать в "правильном" порядке: узел хранит следующее действие, но в таком виде реализация несколько проще)
- Узлы типа EXPR и PROG: содержат единственный дочерний узел op1, определяющий выражение
- Узлы типа PRINT: содержит единственный дочерний узел, описывающий выводимое значение
На этом синтаксический анализ окончен: в случае некорректно составленного кода, осталось добавить его в метод компиляции кода:
// compiler.cpp
bool compiler::compile(std::string& result)
{
token token = getNexttoken();
while (token.type != tokensTypes::ENDFILE)
{
if (token.type == tokensTypes::ERROR)
{
result = "Lexical error";
return false;
}
tokens.push_back(token);
token = getNexttoken();
}
tokens.push_back(token);
compiler::node tree = compiler::node(nodeTypes::EMPTY);
if (!compiler:
arser:arse(tokens, tree))return false;
}
Генерация кода
На основании дерева, нам необходимо построить ассемблерный код. Для начала выделим фрагменты, которые будут в любой программе: начало программы, макрос для вывода чисел в десятичном виде и выход из программы:Hidden text
const std::string compiler::linker:
rogramsStart = R"STR(ASSUME CS:CODE, DSATADATA SEGMENT
vars dw 26 dup (0)
DATA ENDS;
CODE SEGMENT
PRINT MACRO
local DIVCYC, PRINTNUM;
push ax;
push bx;
push cx;
push dx;
mov bx, 10;
mov cx, 0;
DIVCYC:
mov dx, 0;
div bx;
push dx;
inc cx;
cmp ax, 0;
jne DIVCYC;
PRINTNUM:
pop dx;
add dl, '0';
mov ah, 02h;
int 21h;
dec cx;
cmp cx, 0;
jne PRINTNUM;
mov dl, 0dh;
mov ah, 02h;
int 21h;
mov dl, 0ah;
mov ah, 02h;
int 21h;
pop dx;
pop cx;
pop bx;
pop ax;
ENDM;
begin:
lea si, vars;
)STR";
const std::string compiler::linker:
rogramsEnd = R"STR( mov ah, 4Ch;int 21h;
CODE ENDS;
end begin)STR";
Из интересного в данном коде: выделение 26 слов (участков памяти по два байта) под переменные, а также вывод числа с помощью макроса PRINT (он выводит содержимое регистра AX, сохраняя состояние регистров в стеке перед выводом и восстанавливая его после, а также записывает в стек цифры числа, после чего выводит их одну за другой).
Следующим шагом будет определение используемых регистров для осуществления операций. В данном коде основным регистром, содержащим и обрабатывающим данные является регистр AX (в нем всегда находится левый операнд и результат операции), в качестве регистра, хранящего правый операнд, используется регистр BX.
При сборке ассемблерного кода вначале используется строка programsStart, затем к ней прибавляются операции кода, а завершается это строкой programsEnd.
Рассмотрим трансляцию каждого типа узлов дерева в ассемблерный код:
Hidden text
std::string compiler::linker::compileNode(compiler::node* block, int& labelCount)
{
std::string result = "";
int lCount1, lCount2, firstLabelNum, secondLabelNum, thirdLabelNum;
switch (block->type)
{
case nodeTypes:
ROG:result += compileNode(block->op1, labelCount);
break;
case nodeTypes:
RINT:result += compileNode(block->op1, labelCount);
result += " PRINT;\n";
break;
case nodeTypes::VAR:
result += " mov ax, [si + " + std::to_string(block->value * 2) + "];\n";
break;
case nodeTypes::CONST:
result += " mov ax, " + std::to_string(block->value) + ";\n";
break;
case nodeTypes::ADD:
result += compileNode(block->op1, labelCount);
result += " push ax;\n";
result += compileNode(block->op2, labelCount);
result += " mov bx, ax;\n";
result += " pop ax;\n";
result += " add ax, bx;\n";
break;
case nodeTypes::SUB:
result += compileNode(block->op1, labelCount);
result += " push ax;\n";
result += compileNode(block->op2, labelCount);
result += " mov bx, ax;\n";
result += " pop ax;\n";
result += " sub ax, bx;\n";
break;
case nodeTypes::MUL:
result += compileNode(block->op1, labelCount);
result += " push ax;\n";
result += compileNode(block->op2, labelCount);
result += " mov bx, ax;\n";
result += " pop ax;\n";
result += " mul bx;\n";
break;
case nodeTypes:
IV:result += compileNode(block->op1, labelCount);
result += " push ax;\n";
result += compileNode(block->op2, labelCount);
result += " mov bx, ax;\n";
result += " pop ax;\n";
result += " xor dx, dx;\n";
result += " div bx;\n";
break;
case nodeTypes::SET:
result += compileNode(block->op2, labelCount);
result += " mov [si + " + std::to_string(block->op1->value * 2) + "], ax;\n";
break;
case nodeTypes::EXPR:
result += compileNode(block->op1, labelCount) + '\n';
break;
case nodeTypes::LESSTHEN:
result += compileNode(block->op1, labelCount);
result += " push ax;\n";
result += compileNode(block->op2, labelCount);
result += " mov bx, ax;\n";
result += " pop ax;\n";
result += " cmp ax, bx;\n";
result += " jae LBL" + std::to_string(labelCount++) + ";\n";
result += " mov ax, 1;\n";
result += " jmp LBL" + std::to_string(labelCount++) + ";\n";
result += " LBL" + std::to_string(labelCount - 2) + ":\n";
result += " mov ax, 0;\n";
result += " LBL" + std::to_string(labelCount - 1) + ": nop\n";
break;
case nodeTypes::IF:
result += compileNode(block->op1, labelCount);
result += " cmp ax, 0;\n";
lCount1 = labelCount;
result += " jne LBL" + std::to_string(labelCount++) + ";\n";
lCount2 = labelCount;
result += " jmp LBL" + std::to_string(labelCount++) + ";\n";
result += " LBL" + std::to_string(lCount1) + ": nop\n";
result += compileNode(block->op2, labelCount);
result += " LBL" + std::to_string(lCount2) + ": nop\n";
break;
case nodeTypes::SEQ:
result += compileNode(block->op1, labelCount);
result += compileNode(block->op2, labelCount);
break;
case nodeTypes::IFELSE:
result += compileNode(block->op1, labelCount);
result += " cmp ax, 0;\n";
firstLabelNum = labelCount;
result += " je LBL" + std::to_string(labelCount++) + ";\n";
result += compileNode(block->op2, labelCount);
secondLabelNum = labelCount;
result += " jmp LBL" + std::to_string(labelCount++) + ";\n";
result += " LBL" + std::to_string(firstLabelNum) + ": nop\n";
result += compileNode(block->op3, labelCount);
result += " LBL" + std::to_string(secondLabelNum) + ": nop\n";
break;
case nodeTypes::WHILE:
secondLabelNum = labelCount;
result += " jmp LBL" + std::to_string(labelCount++) + "; \n";
firstLabelNum = labelCount;
result += " LBL" + std::to_string(labelCount++) + ": nop\n";
result += compileNode(block->op2, labelCount);
result += " LBL" + std::to_string(secondLabelNum) + ": nop\n";
result += compileNode(block->op1, labelCount);
result += " cmp ax, 0;\n";
thirdLabelNum = labelCount;
result += " je LBL" + std::to_string(thirdLabelNum) + "\n";
result += " jmp LBL" + std::to_string(firstLabelNum) + "\n";
result += " LBL" + std::to_string(thirdLabelNum) + ": nop\n";
break;
default:
break;
}
return result;
}
В данном коде стоит обратить внимание на следующее:
- Для операций, в которых необходимо участие двух операндов, вычисляется сначала левый, который находится в регистре AX, после чего он отправляется в стек, а затем на его месте формируется второй операнд. Перед осуществлением операции правый операнд перемещается в регистр BX, а левый - в AX, после чего результат остается в AX.
- Адреса ячеек в памяти частично вычисляются на этапе компиляции: умножение на сдвиг происходит в компиляторе, потому что этот сдвиг известен заранее.
- Оператор LESSTHEN оставляет в регистре AX 1 в случае истины и 0 в ином случае.
- Операторы IF, IFELSE и WHERE сравнивают дополнительно сравнивают число с 0 (см. пункт 3 и требования к языку).
- Вместо условных переходов на неизвестное расстояние используется отрицание условия для перехода через один оператор, а переход на неизвестное расстояние осуществляется с помощью оператора jmp (чтобы избежать ошибки "Relative jump out of range by xxxxh bytes".
// compiler.css
std::string compiler::linker::compile()
{
std::string program = "";
program += programsStart;
int a = 0;
program += compileNode(tree, a);
program += programsEnd;
return program;
}
bool compiler::compile(std::string& result)
{
token token = getNexttoken();
while (token.type != tokensTypes::ENDFILE)
{
if (token.type == tokensTypes::ERROR)
{
result = "Lexical error";
return false;
}
tokens.push_back(token);
token = getNexttoken();
}
tokens.push_back(token);
compiler::node tree = compiler::node(nodeTypes::EMPTY);
if (!compiler:
arser:arse(tokens, tree))return false;
compiler:linker linker = compiler::linker(&tree);
result = linker.compile();
return true;
}
Остается лишь проверить работоспособность данного компилятора.
Проверка работоспособности компилятора
Отставить легкие проверки! Только хардкор. Для проверки будут решены задачи поиска обратного числа в кольце простых чисел (привет, теорема Эйлера), а также алгоритм нахождения НОД двух чисел.Для решения первой задачи используется следующий код на "нашем языке":
#include <iostream>
#include "compiler.h"
int main()
{
char* data = new char[166];
memcpy(data, "{a = 6; m = 283; s = m - 2; b = a; c = 1; while(0 < s) { if (0 < s - (s/2*2)){c = c * b; c = c - (c / m * m);} s = s / 2; b = b * b; b = b - (b / m * m);} print(c);}", 166);
compiler comp = compiler(data, 166);
std::string result;
comp.compile(result);
std::cout << result;
}
Как можно заметить, строка с кодом программы написана без какого-либо форматирования, это сделано для проверки корректности распознавания кода даже в условиях слабого форматирования. Посмотрим на ассемблерный код, сгенерированный нашим компилятором:
Hidden text
ASSUME CS:CODE, DS
ATADATA SEGMENT
vars dw 26 dup (0)
DATA ENDS;
CODE SEGMENT
PRINT MACRO
local DIVCYC, PRINTNUM;
push ax;
push bx;
push cx;
push dx;
mov bx, 10;
mov cx, 0;
DIVCYC:
mov dx, 0;
div bx;
push dx;
inc cx;
cmp ax, 0;
jne DIVCYC;
PRINTNUM:
pop dx;
add dl, '0';
mov ah, 02h;
int 21h;
dec cx;
cmp cx, 0;
jne PRINTNUM;
mov dl, 0dh;
mov ah, 02h;
int 21h;
mov dl, 0ah;
mov ah, 02h;
int 21h;
pop dx;
pop cx;
pop bx;
pop ax;
ENDM;
begin:
lea si, vars;
mov ax, 6;
mov [si + 0], ax;
mov ax, 283;
mov [si + 24], ax;
mov ax, [si + 24];
push ax;
mov ax, 2;
mov bx, ax;
pop ax;
sub ax, bx;
mov [si + 36], ax;
mov ax, [si + 0];
mov [si + 2], ax;
mov ax, 1;
mov [si + 4], ax;
jmp LBL0;
LBL1: nop
mov ax, 0;
push ax;
mov ax, [si + 36];
push ax;
mov ax, [si + 36];
push ax;
mov ax, 2;
mov bx, ax;
pop ax;
xor dx, dx;
div bx;
push ax;
mov ax, 2;
mov bx, ax;
pop ax;
mul bx;
mov bx, ax;
pop ax;
sub ax, bx;
mov bx, ax;
pop ax;
cmp ax, bx;
jae LBL2;
mov ax, 1;
jmp LBL3;
LBL2:
mov ax, 0;
LBL3: nop
cmp ax, 0;
jne LBL4;
jmp LBL5;
LBL4: nop
mov ax, [si + 4];
push ax;
mov ax, [si + 2];
mov bx, ax;
pop ax;
mul bx;
mov [si + 4], ax;
mov ax, [si + 4];
push ax;
mov ax, [si + 4];
push ax;
mov ax, [si + 24];
mov bx, ax;
pop ax;
xor dx, dx;
div bx;
push ax;
mov ax, [si + 24];
mov bx, ax;
pop ax;
mul bx;
mov bx, ax;
pop ax;
sub ax, bx;
mov [si + 4], ax;
LBL5: nop
mov ax, [si + 36];
push ax;
mov ax, 2;
mov bx, ax;
pop ax;
xor dx, dx;
div bx;
mov [si + 36], ax;
mov ax, [si + 2];
push ax;
mov ax, [si + 2];
mov bx, ax;
pop ax;
mul bx;
mov [si + 2], ax;
mov ax, [si + 2];
push ax;
mov ax, [si + 2];
push ax;
mov ax, [si + 24];
mov bx, ax;
pop ax;
xor dx, dx;
div bx;
push ax;
mov ax, [si + 24];
mov bx, ax;
pop ax;
mul bx;
mov bx, ax;
pop ax;
sub ax, bx;
mov [si + 2], ax;
LBL0: nop
mov ax, 0;
push ax;
mov ax, [si + 36];
mov bx, ax;
pop ax;
cmp ax, bx;
jae LBL6;
mov ax, 1;
jmp LBL7;
LBL6:
mov ax, 0;
LBL7: nop
cmp ax, 0;
je LBL8
jmp LBL1
LBL8: nop
mov ax, [si + 4];
PRINT;
mov ah, 4Ch;
int 21h;
CODE ENDS;
end begin
Получилось много и не очень красиво (а что ждать от взятия остатка через деление, умножение и вычитание?), сравним результаты работы программы и результата с первого попавшегося сайта:
Как видим, результаты сошлись. Перейдем к алгоритму Евклида. Код на "нашем" языке для него будет следующим:
#include <iostream>
#include "compiler.h"
int main()
{
char* data = new char[85];
memcpy(data, "{a = 11004; b = 10087; while(0 < b) {c = a - (a / b * b); a = b; b = c;} print(a);}", 85);
compiler comp = compiler(data, 85);
std::string result;
comp.compile(result);
std::cout << result;
}
Получаем следующий ассемблерный код:
Hidden text
ASSUME CS:CODE, DS
ATADATA SEGMENT
vars dw 26 dup (0)
DATA ENDS;
CODE SEGMENT
PRINT MACRO
local DIVCYC, PRINTNUM;
push ax;
push bx;
push cx;
push dx;
mov bx, 10;
mov cx, 0;
DIVCYC:
mov dx, 0;
div bx;
push dx;
inc cx;
cmp ax, 0;
jne DIVCYC;
PRINTNUM:
pop dx;
add dl, '0';
mov ah, 02h;
int 21h;
dec cx;
cmp cx, 0;
jne PRINTNUM;
mov dl, 0dh;
mov ah, 02h;
int 21h;
mov dl, 0ah;
mov ah, 02h;
int 21h;
pop dx;
pop cx;
pop bx;
pop ax;
ENDM;
begin:
lea si, vars;
mov ax, 11004;
mov [si + 0], ax;
mov ax, 10087;
mov [si + 2], ax;
jmp LBL0;
LBL1: nop
mov ax, [si + 0];
push ax;
mov ax, [si + 0];
push ax;
mov ax, [si + 2];
mov bx, ax;
pop ax;
xor dx, dx;
div bx;
push ax;
mov ax, [si + 2];
mov bx, ax;
pop ax;
mul bx;
mov bx, ax;
pop ax;
sub ax, bx;
mov [si + 4], ax;
mov ax, [si + 2];
mov [si + 0], ax;
mov ax, [si + 4];
mov [si + 2], ax;
LBL0: nop
mov ax, 0;
push ax;
mov ax, [si + 2];
mov bx, ax;
pop ax;
cmp ax, bx;
jae LBL2;
mov ax, 1;
jmp LBL3;
LBL2:
mov ax, 0;
LBL3: nop
cmp ax, 0;
je LBL4
jmp LBL1
LBL4: nop
mov ax, [si + 0];
PRINT;
mov ah, 4Ch;
int 21h;
CODE ENDS;
end begin
Проверим результат работы кода:
Как видно, все сходится.
Создание собственного компилятора
В какой-то довольно близкий момент времени мне стало интересно устройство компиляторов в целом, а в частности трансляторов с языков высокого уровня в ассемблер. И оказалось, что статей на эту тему не...
habr.com