Список полезных инструментов для дата саентист.
🛠 Lazy PredictLazy Predict позволяет быстро создавать прототипы для анализа данных и сравнивать несколько базовых моделей без необходимости вручную писать код или настраивать параметры.
Это помогает специалистам по анализу данных выявлять перспективные подходы в работе с даными и быстрее реализовывать модели.
pip install lazypredict
data = load_breast_cancer()
X = data.data
y= data.target
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=.5,random_state =123)
clf = LazyClassifier(verbose=0,ignore_warnings=True, custom_metric=None)
models,predictions = clf.fit(X_train, X_test, y_train, y_test)
print(models)
| Model | Accuracy | Balanced Accuracy | ROC AUC | F1 Score | Time Taken |
|:-------------------------------|-----------:|--------------------:|----------:|-----------:|-------------:|
| LinearSVC | 0.989474 | 0.987544 | 0.987544 | 0.989462 | 0.0150008 |
| SGDClassifier | 0.989474 | 0.987544 | 0.987544 | 0.989462 | 0.0109992 |
| MLPClassifier | 0.985965 | 0.986904 | 0.986904 | 0.985994 | 0.426 |
| Perceptron | 0.985965 | 0.984797 | 0.984797 | 0.985965 | 0.0120046 |
| LogisticRegression | 0.985965 | 0.98269 | 0.98269 | 0.985934 | 0.0200036 |
| LogisticRegressionCV | 0.985965 | 0.98269 | 0.98269 | 0.985934 | 0.262997 |
| SVC | 0.982456 | 0.979942 | 0.979942 | 0.982437 | 0.0140011 |
| CalibratedClassifierCV | 0.982456 | 0.975728 | 0.975728 | 0.982357 | 0.0350015 |
| PassiveAggressiveClassifier | 0.975439 | 0.974448 | 0.974448 | 0.975464 | 0.0130005 |
| LabelPropagation | 0.975439 | 0.974448 | 0.974448 | 0.975464 | 0.0429988 |
| LabelSpreading | 0.975439 | 0.974448 | 0.974448 | 0.975464 | 0.0310006 |
| RandomForestClassifier | 0.97193 | 0.969594 | 0.969594 | 0.97193 | 0.033 |
| GradientBoostingClassifier | 0.97193 | 0.967486 | 0.967486 | 0.971869 | 0.166998 |
| QuadraticDiscriminantAnalysis | 0.964912 | 0.966206 | 0.966206 | 0.965052 | 0.0119994 |
| HistGradientBoostingClassifier | 0.968421 | 0.964739 | 0.964739 | 0.968387 | 0.682003 |
| RidgeClassifierCV | 0.97193 | 0.963272 | 0.963272 | 0.971736 | 0.0130029 |
| RidgeClassifier | 0.968421 | 0.960525 | 0.960525 | 0.968242 | 0.0119977 |
| AdaBoostClassifier | 0.961404 | 0.959245 | 0.959245 | 0.961444 | 0.204998 |
| ExtraTreesClassifier | 0.961404 | 0.957138 | 0.957138 | 0.961362 | 0.0270066 |
| KNeighborsClassifier | 0.961404 | 0.95503 | 0.95503 | 0.961276 | 0.0560005 |
| BaggingClassifier | 0.947368 | 0.954577 | 0.954577 | 0.947882 | 0.0559971 |
| BernoulliNB | 0.950877 | 0.951003 | 0.951003 | 0.951072 | 0.0169988 |
| LinearDiscriminantAnalysis | 0.961404 | 0.950816 | 0.950816 | 0.961089 | 0.0199995 |
| GaussianNB | 0.954386 | 0.949536 | 0.949536 | 0.954337 | 0.0139935 |
| NuSVC | 0.954386 | 0.943215 | 0.943215 | 0.954014 | 0.019989 |
| DecisionTreeClassifier | 0.936842 | 0.933693 | 0.933693 | 0.936971 | 0.0170023 |
| NearestCentroid | 0.947368 | 0.933506 | 0.933506 | 0.946801 | 0.0160074 |
| ExtraTreeClassifier | 0.922807 | 0.912168 | 0.912168 | 0.922462 | 0.0109999 |
| CheckingClassifier | 0.361404 | 0.5 | 0.5 | 0.191879 | 0.0170043 |
| DummyClassifier | 0.512281 | 0.489598 | 0.489598 | 0.518924 | 0.0119965 |
▪Github
🛠 fastparquet
fastparquet – библиотека, ускоряющая ввод-вывод Pandas в 5 раз. fastparquet – это высокопроизводительная реализация формата Parquet на Python, предназначенная для бесперебойной работы с фреймами данных Pandas. Она обеспечивает быструю производительность чтения и записи, эффективное сжатие и поддержку широкого спектра типов данных.
Установите с помощью conda:
conda install -c conda-forge fastparquet
▪Github
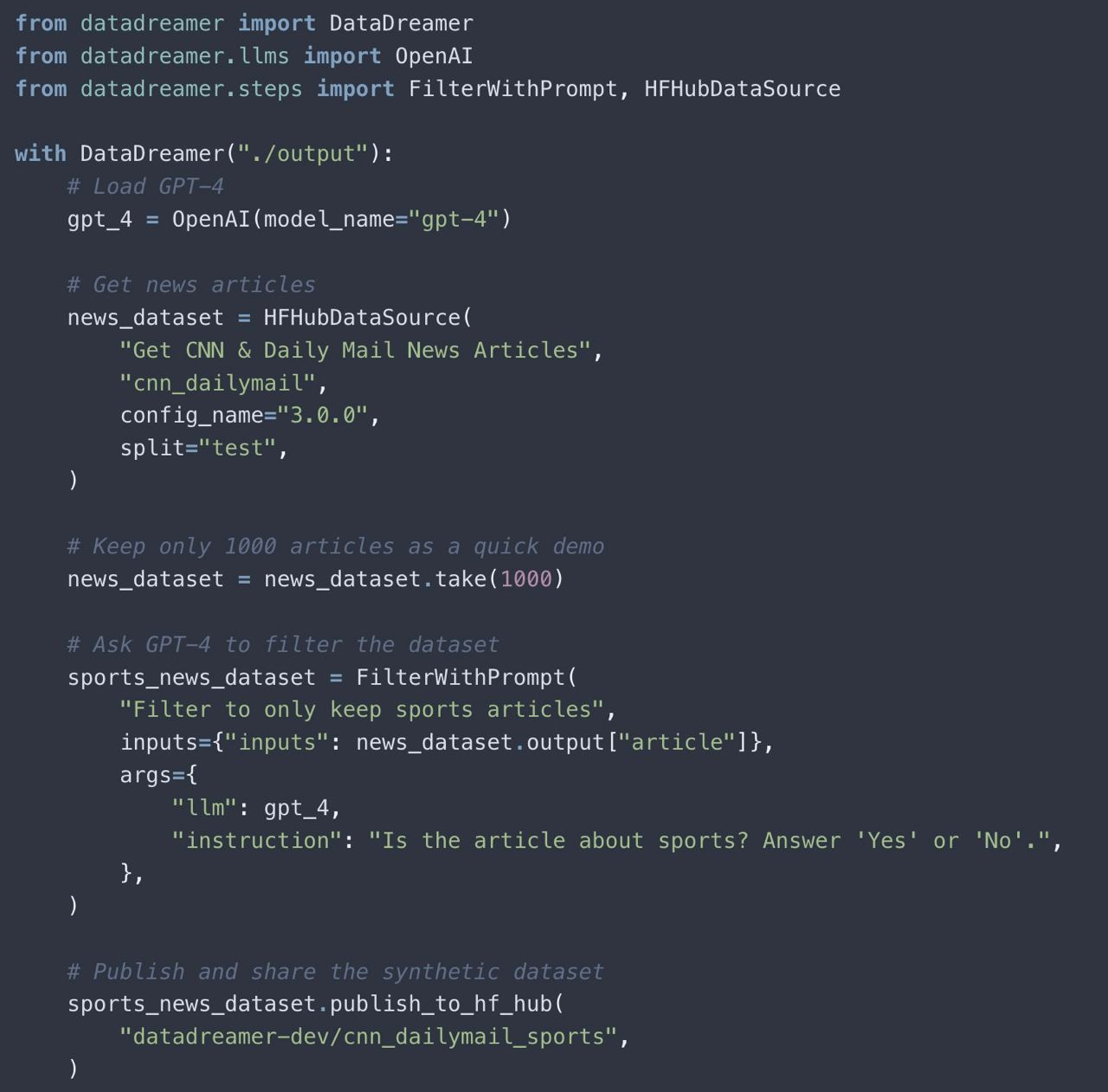
🛠 DataDreamer
DataDreamer – это мощная библиотека Python с открытым исходным кодом для легкого создания промптов, синтетических данных и рабочих моделей машинного обучения.
Установка:
pip install SciencePlots
▪ Github
▪ Документация
🛠 RAPIDS
NVIDIA сделала Pandas в 150 раз быстрее без изменений кода. RAPIDS автоматически определяет, работаете ли вы на GPU или CPU, и ускоряет код. При этом нет абсолютно никаких изменений в синтаксисе, просто перед импортом запускаем эту команду:
%load_ext cudf.pandas
import pandas as pd
Попробовать можно здесь:
▪ Github
🛠 SciencePlots
SciencePlots – полезная библиотека для быстрого создания графиков matplotlib для презентаций, исследовательских работ.
Самый простой способ установить SciencePlots - использовать pip:
pip install SciencePlots
▪Github
🛠 Tensorflow-GNN
Новая библиотека Tensorflow-GNN для работы с графовыми нейросетями
Эта крутая библиотека ориентирована на гетерогенные графы, то есть те, у которых узлы и рёбра могут быть различных типов.
▪Github
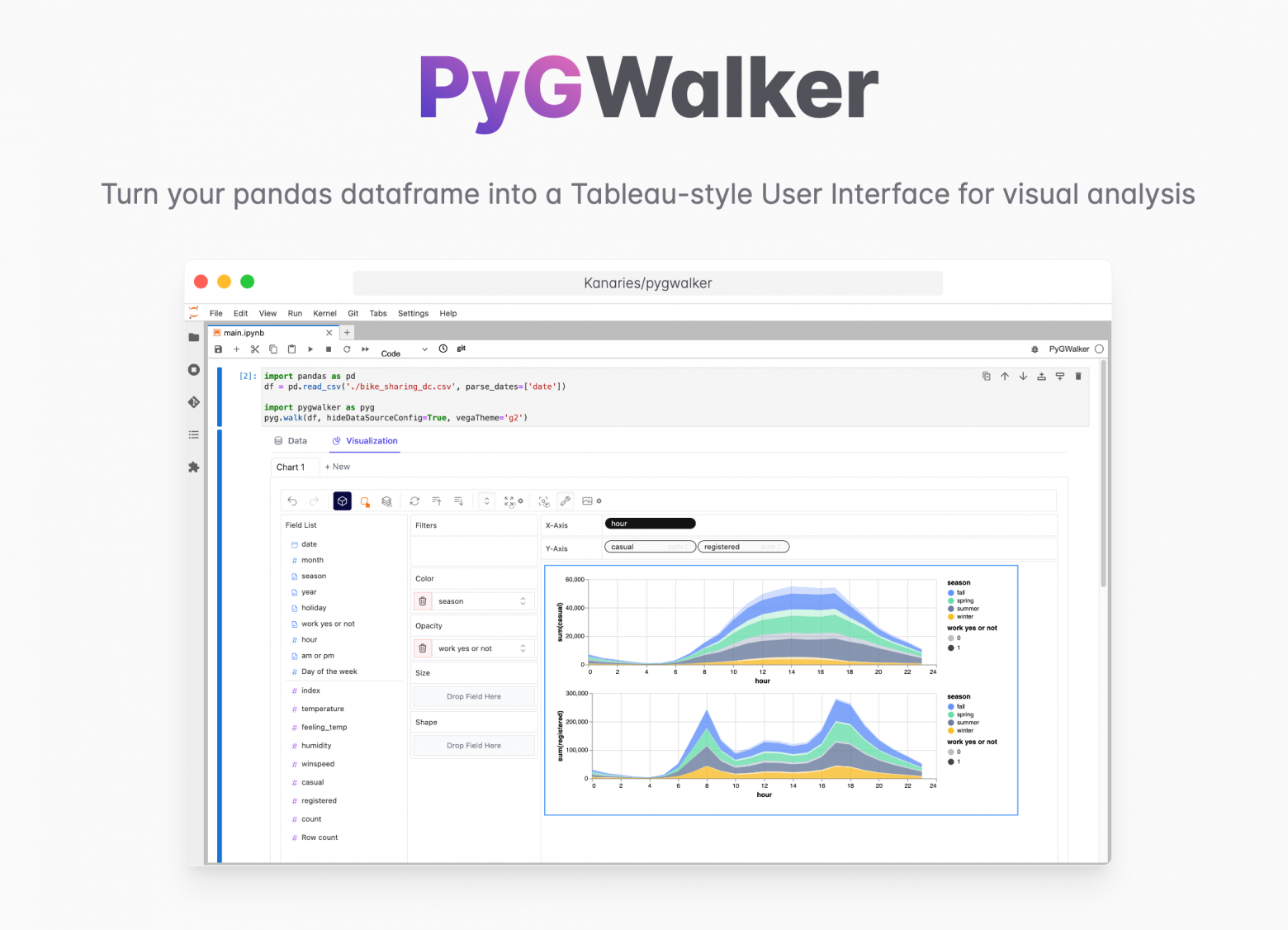
🛠 PyGWalker
▪PyGWalker – инструмент, который упрощает рабочий процесс анализа и визуализации данных в Jupyter Notebook, превращая фрейм данных pandas в пользовательский интерфейс в стиле Tableau для визуального исследования.
🛠 Feather
Feather – библиотека, которая предназначена для чтения и записи данных с устройств. Данная библиотека отлично подходит для перевода данных из одного языка в другой. Также она способна достаточно быстро считывать большие массивы данных
Python
pip install feather-formatR
install.packages("feather")🛠 YOLOv9
На днях вышел YOLOv9. Новый SOTA для обнаружения объектов в реальном времени.
▪Github
🛠 Dask
Dask – эта библиотека позволяет эффективно организовывать параллельные вычисления. Коллекции больших данных хранятся здесь как параллельные массивы/списки и позволяют работать с ними через Numpy/Pandas.
client = LocalCluster().get_client()
# Submit work to happen in parallel
results = []
for filename in filenames:
data = client.submit(load, filename)
result = client.submit(process, data)
results.append(result)
# Gather results back to local computer
results = client.gather(results)
▪Dask
🛠 Ibis
Ibis – обеспечивает доступ между локальным окружение в Python и удаленными хранилищами данных (например, Hadoop)
Мы рекомендуем начать с бэкенда по умолчанию (DuckDB).
pip install 'ibis-framework[duckdb,examples]'
import ibis
import ibis.selectors as s
2ibis.options.interactive = True
3t = ibis.examples.penguins.fetch()
4t.head(3)
▪Github
🛠 Jless
Jless — полезный инструмент для просмотра JSON-файлов в командной строке.Отображение данных в удобном виде — с подсветкой синтаксиса для отдельных элементов объекта. Инструмент позволяет обрабатывать и расширять массивы.

▪Github
🛠 Code to Flow

Code to Flow – бесплатная инновационная нейросеть для анализа, объяснения и визуализации кода.
Это мощный инструмент для разбиения кода на шаги и его объяснения.
Используя ИИ, Code to Flow работает с различными языками программирования и фреймворками.
Он пригодится как при обучении, так и при реальной работе, помогая лучше понимать структуру и логику кода.
▪ Попробовать
🛠 MakeReal в jupyter-tldraw

Теперь вы можете вручную рисовать графики мышкой и MakeReal будет превращать их в код c использованием matplotlib прямо в блокноте!
▪ GitHub
🛠 Twin Matcher
Идея для ML проекта

Создадим мл-приложение по поиску вашего близнеца среди знаменитостей

 ↓
↓Здесь приведен полный пример с исходным кодом, чтобы узнать, как создать полноценное ML-приложение, которое найдет похожую на вас знаменитость.
▪ GitHub
🛠 Lightwood

При работе мы дата саентисты тратим много времени на написание одного и того же кода для очистки, подготовки данных и построения моделей
 ️.
️.Рекомендую попробовать lightwood – AutoML фреймворк, который принимает на вход данные, целевую переменную и генерирует для вас целый конвейер машинного обучения.
pip3 install lightwood
▪ GitHub
🛠 Pandaral·lel
Если вы хотите распараллелить операции #Pandas на всех доступных процессорах, добавив всего одну строку кода, попробуйте pandarallel.
pip install pandarallel
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)
df.apply(func)
df.parallel_apply(fun
▪Github
▪Docs
🛠 Smaug-72B – лучшая модель с открытым исходным кодом в мире!

Она находится в топе HuggingFace LLM LeaderBoard, Smaug является первой моделью со средним баллом 80.
Это делает ее лучшей в мире LLM моделью с открытым исходным кодом.
В таблице приведено сравнение с открытыми и проприетарными моделями Mistral, Gemini Pro и GPT-3.5.
▪HF
🛠 PyForest
Писать одни и те же импорты снова и снова – это путсая трата времени. Попробуйте pyforest, этот инструмент сделает работу по импорту библиотек за вас.
С помощью pyforest вы можете использовать все свои любимые библиотеки Python, не импортируя их перед этим.
Если вы используете пакет, который еще не импортирован, pyforest импортирует его за вас и добавит код в первую ячейку Jupyter.
▪ Github
🛠 tfcausalimpact
Библиотека для поиска причинно-следственных связей на Python, основанная на пакете R от Google. Построена с использованием TensorFlow Probability.
Вы проводите маркетинговую кампанию и видите, что количество пользователей увеличивается. Но как узнать, связано ли это с вашей кампанией или это просто совпадение?
Вот тут-то и пригодится tfcausalimpact. Библиотека помогает прогнозировать будущие тренды и тенденции в данных и сравнивает ваши показатели с фактическими данными для получения статистических выводов.
pip install tfcausalimpact
▪ GitHub
🛠 Awesome Face Recognition

Огромный awesome список материалов: обнаружение лиц; распознавание; идентификация; верификация; реконструкция; отслеживание; сверхразрешение и размытие; генерация и синтез лиц; замена лиц; защита от подделки; поиск по лицу.
▪Github
🛠 PALLAIDIUM
PALLAIDIUM – генеративный искусственный интеллект для Blender VSE.
AI-генерация видео, изображений и аудио из текстовых промптов.
▪ Github
🛠 SQL-metadata

Если вы хотите извлечь определенные компоненты #SQL-запроса для последующей работы с ними на #Python, используйте sql_metdata.
Извлекает имена столбцов и таблиц, используемых в запросе. Автоматически выполняет разрешение псевдонимов столбцов, разрешение псевдонимов подзапросов, а также разрешение псевдонимов таблиц.
Также предоставляет полезные функции для нормализации SQL-запросов.
pip install sql-metadata
▪ Github
▪ Docs
🛠 RoMa
RoMa: простая в использовании, стабильная и эффективная библиотека для работы с кватернионами, векторами вращения, пространственными преобразованиями в PyTorch.
pip install roma
▪ Github
▪ Docs
🛠 DataTrove
DataTrove – это библиотека для обработки, фильтрации и очистки текстовых данных в очень больших масштабах. Она предоставляет набор готовых часто используемых функций обработки данных и фреймворк для простого добавления собственной функциональности.
Его конвейеры обработки не зависят от платформы и могут работать как локально, так и на кластере slurm.
Низкое потребление памяти и удобная конструкция делают его идеальным для больших рабочих нагрузок, например для обработки обучающих данных LLM.
from datatrove.pipeline.readers import CSVReader
from datatrove.pipeline.filters import SamplerFilter
from datatrove.pipeline.writers import JsonlWriter
pipeline = [
CSVReader(
data_folder="/my/input/path"
),
SamplerFilter(rate=0.5),
JsonlWriter(
output_folder="/my/output/path"
)
]
▪ Github
▪ Примеры
🛠 DeepSpeed-FastGen
DeepSpeed-FastGen обеспечивает высокопроизводительную генерацию текста для LLM с помощью MII и DeepSpeed-Inference.
Производительность генераций повышается в 2,3 раза, задержка в 2 раза ниже по сравнению с системами SotA, такими как vLLM
▪ Github
🛠 Jupyter-ai
Попробуйте поработать с Jupyter AI в Jupyter Notebook и Jupyter Lab для создания и редактирования кода с помощью генеративного искусственного интеллекта.
▪Github
🛠 NASA Earth Data
НАСА размещает на #AWS более 9 000 продуктов данных о нашей планете!
 В этом хранилище представлен полный список данных НАСА по наукам о Земле, доступных для исследований и анализа. Данные управляются и поддерживаются программой НАСА “Системы данных по наукам о Земле” (ESDS), которая обеспечивает доступность и удобство использования данных.
В этом хранилище представлен полный список данных НАСА по наукам о Земле, доступных для исследований и анализа. Данные управляются и поддерживаются программой НАСА “Системы данных по наукам о Земле” (ESDS), которая обеспечивает доступность и удобство использования данных.Узнайте, как легко найти и загрузить данных с помощью этого руководства

▪Github
▪Video
🛠 CleverCSV
CleverCSV – библиотека, которая устраняет различные ошибки синтаксического анализа при чтении CSV-файлов с помощью Pandas

▪Github
🛠Swarms in Torch
Это экспериментальный репозиторий, созданный для работы с роевыми алгоритмами.
Благодаря целому ряду полезных алгоритмов, включая Particle Swarm Optimization (PSO), Ant Colony, Sakana, Mambas Swarm и других, реализованных с помощью PyTorch, вы сможете легко использовать мощь роевых технологий в своих проектах.
pip3 install swarms-torch
from swarms_torch import ParticleSwarmOptimization
pso = ParticleSwarmOptimization(goal="Attention is all you need", n_particles=100)
pso.optimize(iterations=1000)
▪ Github
▪ Документация
🛠 Mergekit
mergekit – это инструмент для слияния предварительно обученных языковых моделей.
Может выполняться полностью на CPU или ускоряться с помощью всего 8 ГБ VRAM.
Проект поддерживает множество алгоритмов.
▪ Github
▪ Colab
🛠 Facets

Проект Facets предоставляет инструменты визуализации для понимания и анализа наборов данных машинного обучения: Facets Overview и Facets Dive.
Визуализации реализованы в виде веб-компонентов Polymer и могут быть легко встроены в блокноты Jupyter или веб-страницы.
Прмеры визуализаций можно найти на странице описания проекта Facets: pair-code.github.io/facets/
▪ Github
🛠 nbgather:
 Spit shine for Jupyter notebooks
Spit shine for Jupyter notebooksnbgather предоставляет инструменты для очистки кода, восстановления потерянного кода и сравнения версий кода в Jupyter Lab.
Загрузите расширение alpha с помощью следующей команды:
jupyter labextension install nbgather
▪ Github
🛠 DataStack
Datastack – это фреймворк с открытым исходным кодом, который позволяет легко создавать веб-приложения, информационные панели , формы ввода данных или прототипы в режиме реального времени, используя только Python – опыт работы с фронтендом не требуется.
В DataStack доступно много готовых виджетов, включая запись текста, выбор из выпадающего списка, списки, кнопки, формы ввода, HTML формы , iframe, разделитель страниц, dataframe, таблицы и многое другое.
pip install pydatastack
from datastack import datastack
ds = datastack(main=True)
ds.subheader('DataStack click counter app')
count = 0
def inc_count():
global count
count += 1
ds.button('Click', on_click=inc_count)
ds.write('counts: ' + str(count))
▪ Github
🛠 SuperDuperDB: Добавьте искусственный интеллект в свою базу данных.

Проект, который позволяет интегрировать, обучать и управлять любыми моделями ИИ непосредственно для работы с базами данных и данными.
Поддерживает основные баы данных SQL и табличные форматы: PostgreSQL, MySQL, SQLite, DuckDB, Snowflake, BigQuery, ClickHouse, DataFusion, Druid, Impala, MSSQL, Oracle, pandas, Polars, PySpark и Trino (а также MongoDB).
▪ Github
▪ Project
🛠 Grist – это гибрид базы данных и электронной таблицы, то есть:
 Столбцы работают так же, как и в базах данных: им присваиваются имена, и в них хранятся данные одного типа.Столбцы могут быть заполнены формулами в стиле электронных таблиц с автоматическим обновлением при изменении ссылающихся ячеек.
Столбцы работают так же, как и в базах данных: им присваиваются имена, и в них хранятся данные одного типа.Столбцы могут быть заполнены формулами в стиле электронных таблиц с автоматическим обновлением при изменении ссылающихся ячеек.▪ GitHub
Бонус: 10 интересных инструментов для дата саентистов, которые были признаны лучшими Python-библиотека 2023 года по версии Tryolabs.
▪ LiteLLM — библиотека, которая обеспечивает бесшовную интеграцию с различными языковыми моделями. Она позволяя использовать унифицированный формат как для ввода, так и для вывода вне зависимости от применяемой LLM.
▪ MLX — это проект от Apple для машинного обучения на процессорах Apple Silicon.
▪ Taipy — инструмент, который позволяет дата-сайентистам создавать интерактивный Web UI для ML-проектов.
▪ PyApp — упрощает распространение и установку Python-приложений. Это достигается за счёт встраивания Python в самоустанавливающийся пакет, совместимый со всеми операционными системами.
▪ Unstructured — набор инструментов для предварительной обработки текста.
▪ ZenML и AutoMLOps — два мощных инструмента для создания MLOps-пайплайнов.
▪ WhisperX — библиотека для распознавания речи, способная обнаружить нескольких говорящих на аудио.
▪ AutoGen — инструмент, который позволяет создавать LLM-приложения с несколькими агентами, способными общаться друг с другом для решения задач.
▪ Temporian — библиотека для легкой и эффективной предобработки и фича-инжиниринга временных данных в Python.
▪ Guardrails — инструмент помогает LLM возвращать структурированные, качественные ответы определённого типа.

40 Полезных инструментов Дата Саентиста
В мире науки о данных существует бесчисленное множество библиотек и инструментов, которые помогают ускорить работу и повысить эффективность анализа. Но что если я расскажу вам о некоторых полезных...
 habr.com
habr.com